이런 분들께 이 논문을 추천드립니다.
- CLIP을 비디오에 적용하는 방식에 흥미가 있으신 분
이 논문을 깊게 이해하려면 다음 지식이 필요합니다.
안녕하세요. 백지오입니다.
스무 번째 X-REVIEW는 Video-Text Retrieval task에서 baseline 모델로 자주 등장하여 언제 읽어야지 하고 있던 CLIP4Clip입니다. 비디오의 클립(전체 비디오를 몇 초 정도의 짧은 영상으로 분할한 것)을 검색하기 위하여 Image-Text pretrained model인 CLIP을 사용한 연구로, 이미지에서 학습된 CLIP 모델을 비디오에 잘 적용하기 위한 다양한 실험이 돋보이는 연구입니다.
2021년, 대규모 이미지-텍스트 데이터셋에서 사전학습된 CLIP 모델이 등장하여 이미지 분야는 물론이고 비디오 분야에서도 기존 SOTA 모델들을 크게 앞서는 놀라운 성과들을 내기 시작했습니다. 이미 CLIP이 비디오에서 좋은 성능을 보여주기는 하였지만, 연구자들은 애초에 이미지에서 학습된 CLIP을 비디오 분야에 맞게 적용한다면 성능을 한층 더 상승시킬 수 있으리라는 생각에, CLIP을 비디오에 적용하는 다양한 방법론이 연구되었습니다.
본 논문도 그러한 논문의 일환으로, 논문은 다음과 같은 의문과 함께 시작합니다.
- Video-Text Retrieval task에서 CLIP의 image feature가 충분히 효과를 내고 있는가?
- CLIP을 대규모 video-text 데이터셋에서 추가 사전학습(post-pretraining)하여 성능을 향상할 수 있을까?
- 비디오에 존재하는 프레임(이미지)간의 temporal dependecy를 모델링하기 위한 실용적인 방법은 무엇일까?
- Video-text retrieval task에 대한 하이퍼파라미터 sensitivity는 어느 정도인가?
Introduction
기존의 video-text retrieval 모델은 학습 시 사용하는 입력에 따라 raw video (pixel-level) 방법과 video feature (feature-level) 방법으로 구분할 수 있습니다. raw video 방법들은 말 그대로 비디오를 입력으로 사용하는데, 1초에 30장 이상의 이미지로 구성된 비디오의 특성상 매우 막대한 컴퓨팅 비용이 요구되는 단점이 있었습니다. 반면 최근 주류로 떠오른 video feature 방법은 주로 HowTo100M과 같은 대규모 비디오 데이터셋에서 사전학습된 frozen feature extractor 모델을 사용해 추출한 feature를 입력으로 사용하여 사전학습의 이점과 컴퓨팅 비용의 감소를 얻을 수 있었습니다.
특히 ClipBERT에서 제안한 sparse sampling 전략을 통해 이러한 feature extractor를 비교적 저비용으로 학습할 수 있게 되어 사전학습된 video feature extractor 모델을 사용하는 것의 이점이 많은 상황입니다.
(sparse sampling: 수백 수천 프레임의 비디오 전체를 한번에 입력하지 않고, 비디오에서 1초에 1장과 같이 일부 프레임들만 추출하여 입력으로 사용하는 방식입니다.)
한편, Frozen과 같은 방법론들은 비디오 데이터에 더불어 이미지를 1 프레임짜리 영상으로 취급하여 학습에 함께 활용하기도 하였는데요. 저자들은 사전학습된 video feature extractor를 사용하거나 아예 처음부터 이러한 모델을 학습시키는 대신, image-text pretrained model인 CLIP을 비디오 분야에 맞게 잘 가져와서 video-text retrieval에 활용해보고자 하였습니다. CLIP for video clip retrieval, CLIP4Clip을 제안하게 된 것이죠.
저자들은 먼저 CLIP을 HowTo100M 데이터셋에서 비디오 분야에 알맞게 추가 사전학습시키고, video-text retrieval에 CLIP을 적용하기 위한 세 가지의 유사도 계산 방법을 제안하여 이들에 대한 비교 실험을 진행합니다.
저자들이 주장하는 Contribution은 다음과 같습니다.
- 사전학습 CLIP 기반의 세 가지 유사도 계산 방법을 제안
- Noisy 한 대규모 데이터셋을 통해 CLIP을 post-pretraining
- MSR-VTT, MSVD, LSMDC, ActivityNet, DiDeMo 데이터셋에서 SOTA 달성
또한, 논문에서 진행한 실험들을 통해 다음과 같은 인사이트를 도출하였습니다.
- 한 장의 이미지는 video-text retrieval에서 video encoding과 상당히 차이가 있다.
(이미지를 single-frame video로 취급하기엔 무리가 있다.) - CLIP을 대규모 비디오 데이터셋에서 post-pretraining 하는 것이 큰 성능차이를 불러오며, 특히 zero-shot에서 그러하다.
- CLIP을 비디오에 적용할 때, CLIP이 이미 강력한 성능을 보이는 만큼 소규모 데이터셋에서는 오히려 추가 파라미터를 도입하지 않는 것이 낫다. 반면에 대규모 데이터셋에서는 temporal modeling에 추가적인 파라미터를 도입해도 좋다.
CLIP4Clip Framework
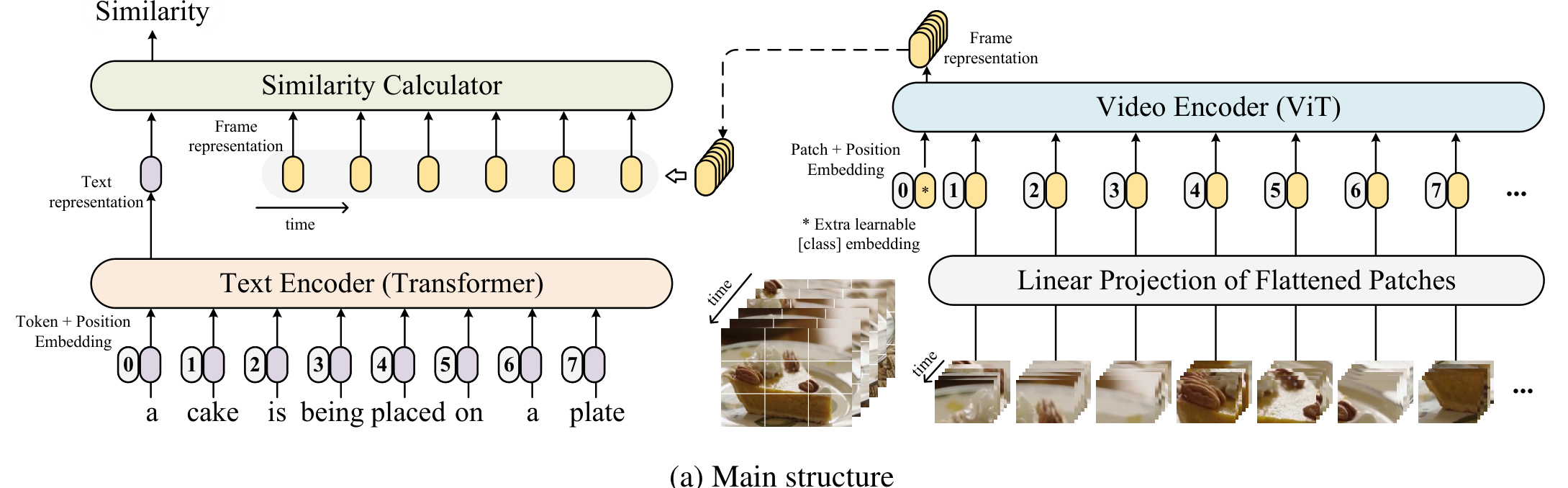
비디오 혹은 클립의 집합 $v_i \in \mathcal V$와 비디오에 해당하는 캡션들의 집합 $t_j\in \mathcal T$가 주어질 때, 비디오와 캡션의 유사도를 구하는 함수 $s(v_i, t_j)$를 학습시키는 것이 video-text retrieval의 목적입니다.
이때, 비디오 $v_i$는 $|v_i|$개의 프레임으로 구성됩니다. $v_i = \{v_i^1, v_i^2, \cdots v_i^{|v_i|}\}$
CLIP4Clip은 비디오를 입력 삼아 end-to-end(E2E)로 학습되며, 그림 1과 같이 video encoder, text encoder, similarity calculator로 구성됩니다.
Video Encoder
먼저, 각 프레임을 CLIP ViT-B/32로 인코딩해줍니다. 이때, CLIP과 ViT의 설정과 동일한 방식으로 인코딩이 진행됩니다.
- 프레임을 작은 패치들로 분할하고, 패치들을 CNN을 통해 Linear Projection 해줍니다.
- Projection 된 feature map들을 1차원으로 평탄화해 주고, 이들을 ViT의 입력 토큰들로 사용합니다.
- ViT는 각 토큰들에 대한 출력을 생성합니다.
- 이때, 추가적으로 0번째에 입력되는 [CLS] 토큰에 대한 ViT의 출력이 $v_i$ 프레임 전체에 대한 representation vector $z_i$로 간주됩니다.

이때, Linear Projection에 사용되는 CNN은 기본적으로 2D CNN이지만, 저자들은 영상의 Temporal 한 정보를 modeling 하기 위하여 $[t\times h\times w]$의 kernel을 갖는 3D CNN을 사용하는 실험을 진행하였습니다.
Text Encoder
텍스트 인코더 역시 CLIP의 트랜스포머 인코더를 사용하였습니다. 캡션을 토큰화하여 입력하고, 마지막 [EOS] 토큰에 대응하는 출력 $w_j$가 전체 텍스트 $t_j$의 representation에 해당합니다.
Similarity Calculator
앞서 비디오(클립)를 각 프레임의 representation vector $Z_i = \{ z_i^1, z_i^2, \cdots , z_i^{|v_i|} \}$, 해당 비디오에 대한 텍스트의 representation vector $w_j$를 얻었는데요. 이를 이용해 비디오와 텍스트의 유사도를 구해줄 차례입니다.
저자들은 이를 위한 3가지 방법을 제안하고 각 방법을 비교하였습니다.
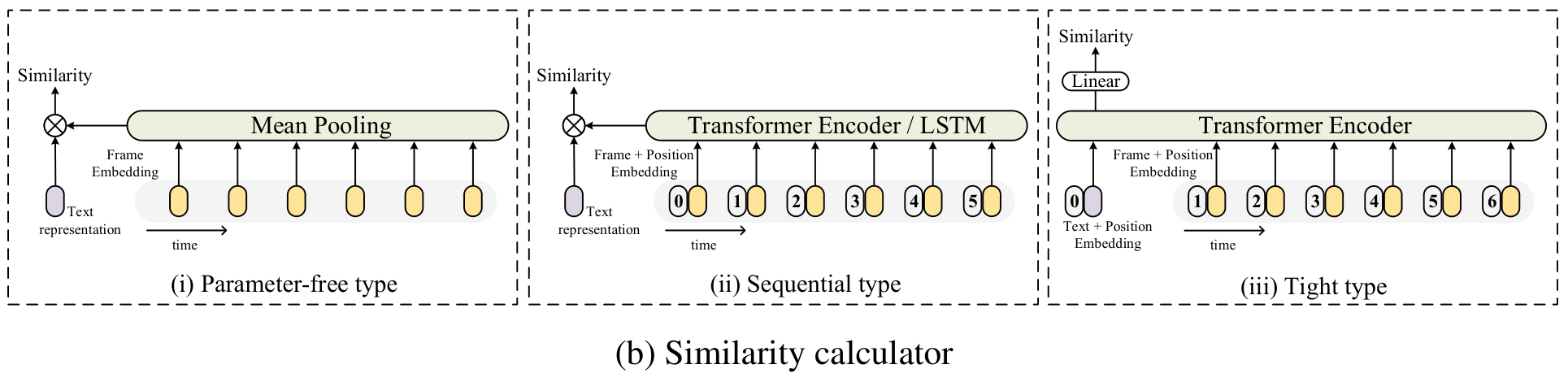
먼저, 가장 단순하며 추가적으로 학습해야할 파라미터가 추가되지 않는 parameter free 방법인 mean pooling 방식입니다. 각 프레임에 해당하는 벡터 $z_i$들의 평균을 내어 해당 벡터 $\hat z_i$ 를 비디오 representation로 삼습니다. 이어서 아래 수식을 통해 코사인 유사도를 구해줍니다.
$$ s(v_i, t_j) = \frac{w_j^\top \hat z_i}{||w_j|| ||\hat z_i ||}$$
두 번째 방법은 Sequential type입니다. LSTM이나 트랜스포머 인코더를 통해, 프레임 벡터 $z_i$들에 대한 temporal modeling을 수행한 다음, mean pooling을 수행하여 코사인 유사도를 구합니다. 이때, 트랜스포머를 사용할 경우 position embedding $P$를 사용합니다.
세 번째 방법은 Tight type으로 아예 각 프레임의 벡터와 텍스트 벡터 $w_j$까지 다 트랜스포머에 입력합니다. 그 결과 출력된 [CLS] 토큰의 출력 multi-modal fused feature $U$를 Linear Layer에 입력하여 유사도를 계산합니다. 이때, position embedding $P$와 type embeding $T$를 사용합니다. ($T$는 modal이 text인지 video frame인지를 구분하는 두 종류의 임베딩이 포함됩니다.)
Training
저자들은 학습 시 uniform sampling을 통해 1초에 1장의 프레임을 샘플링하여 사용하였습니다. $B$개의 영상-텍스트 쌍이 주어질 때, 먼저 $B\times B$의 유사도 행렬을 구한 후, symmetric cross entropy loss $\mathcal L$을 사용해 학습을 진행했습니다.
$$\mathcal L_{v2t} = -\frac{1}{B}\sum^B_i\log\frac{\exp(s(v_i, t_i))}{\sum^B_{j=1}\exp(s(v_i, t_j))}$$
$$\mathcal L_{t2v} = -\frac{1}{B}\sum^B_i\log\frac{\exp(s(v_i, t_i))}{\sum^B_{j=1}\exp(s(v_j, t_i))}$$
$$\mathcal L = \mathcal L_{v2t} + \mathcal L_{t2v}$$
HowTo100M에서 post-pretraining을 수행한 후, target dataset에서 fine-tuning을 수행하였고, 이때 post-pretraining에 대한 실험을 HowTo100M에서 추출한 일부 데이터셋을 통해 추가적으로 진행했습니다. (아래에서 자세히 다루겠습니다.) post-pretraining은 parameter free 방식과 MIL-NCE loss로 진행하였고, Adam optimizer를 사용하였습니다. 이외에 하이퍼 파라미터는 learning rate $1e-8$, token length 32, frame length 12, batch size 48로 V100 8장에서 학습을 진행했다고 합니다. 5 에포크 학습에 2주일이 소요되었는데, 본 논문에서 수행한 post-pretraining 관련 연구를 추후 연구의 preliminaries로 활용할 수 있을 것이라 하네요. 확실히 다른 연구자들이 post-pretraining에 힘 뺄 필요가 없게 탄탄히 실험한 모습입니다.
Experiments
실험은 SOTA와의 비교와 하이퍼파라미터에 대한 Ablation Study, post-pretraining, sampling, patch linear projection 방식 등에 대한 실험으로 구성되어 있습니다.
먼저 디테일을 살펴보겠습니다.
앞서 언급한 것처럼, CLIP4Clip은 사전학습된 CLIP ViT-B/32를 사용하였습니다.
이때, Similarity Calculator의 경우 CLIP의 사전학습 파라미터를 재사용하여 초기화하였습니다. positional embedding $P$는 CLIP의 text encoder에서 가져왔고, 트랜스포머 인코더는 CLIP의 visual encoder에서 가져왔다고 합니다.
단, 가중치를 가져올 곳이 없는 LSTM이나 Linear layer와 같은 이외의 파라미터는 랜덤 하게 초기화하였습니다.
Linear Projection 시 사용되는 3D CNN은 $t=3, h=32, w=32$의 커널 사이즈를 가지며, temporal 차원에 대하여 stride와 padding 1이 적용되었습니다. 가중치는 CLIP의 2D Linear 계층에서 central frame initialization 방식으로 가져다 썼다고 합니다. ($[0, E_{2D}, 0]$과 같이, 추가된 차원은 0으로 두고 한 층만 2D 계층에서 가져왔습니다.)
파인튜닝 시에는 역시 Adam optimizer를 이용하였고, 코사인 스케쥴링으로 lr decay를 적용했습니다. video, text encoder와 linear projection에 대해 learning rate $1e-7$을 적용하고 다른 추가 모듈들에는 $1e-4$의 더 큰 값을 주었습니다. token length 32, frame length 12, batch size 128로 V100 4장에서 5 에포크 학습을 진행하였습니다. LSTM의 경우 1 계층, sequential이나 tight 방식에서 사용하는 트랜스포머는 4 계층으로 설계하였습니다.
단, ActivityNet과 DiDeMo 데이터셋에서는 video-paragraph retrieval task이기 때문에 caption의 token length를 64로 더 크게 주어 16장의 V100에서 실험했습니다.
Comparison with SOTAs
5개 데이터셋에서의 SOTA 모델들과, 본 논문에서 제안한 3가지 방식에 해당하는 -meanP, -seqLSTM, -seqTransf, -tightTransf 버전의 비교를 수행하였습니다. 그 결과, 5개 데이터셋에서 모두 큰 차이로 SOTA를 달성할 수 있었다고 합니다.
표에서 TrainD는 학습 데이터셋을 의미하는데, H는 HowTo100M, W는 CLIP 사전학습에 사용되는 WiT를 의미하며, 이외에는 각 모델이나 데이터셋 학습에 사용되는 다양한 데이터셋들을 의미합니다. 논문의 표 설명에 적혀있기는 하나 가독성을 위해 리뷰에 가져오지는 않았습니다.
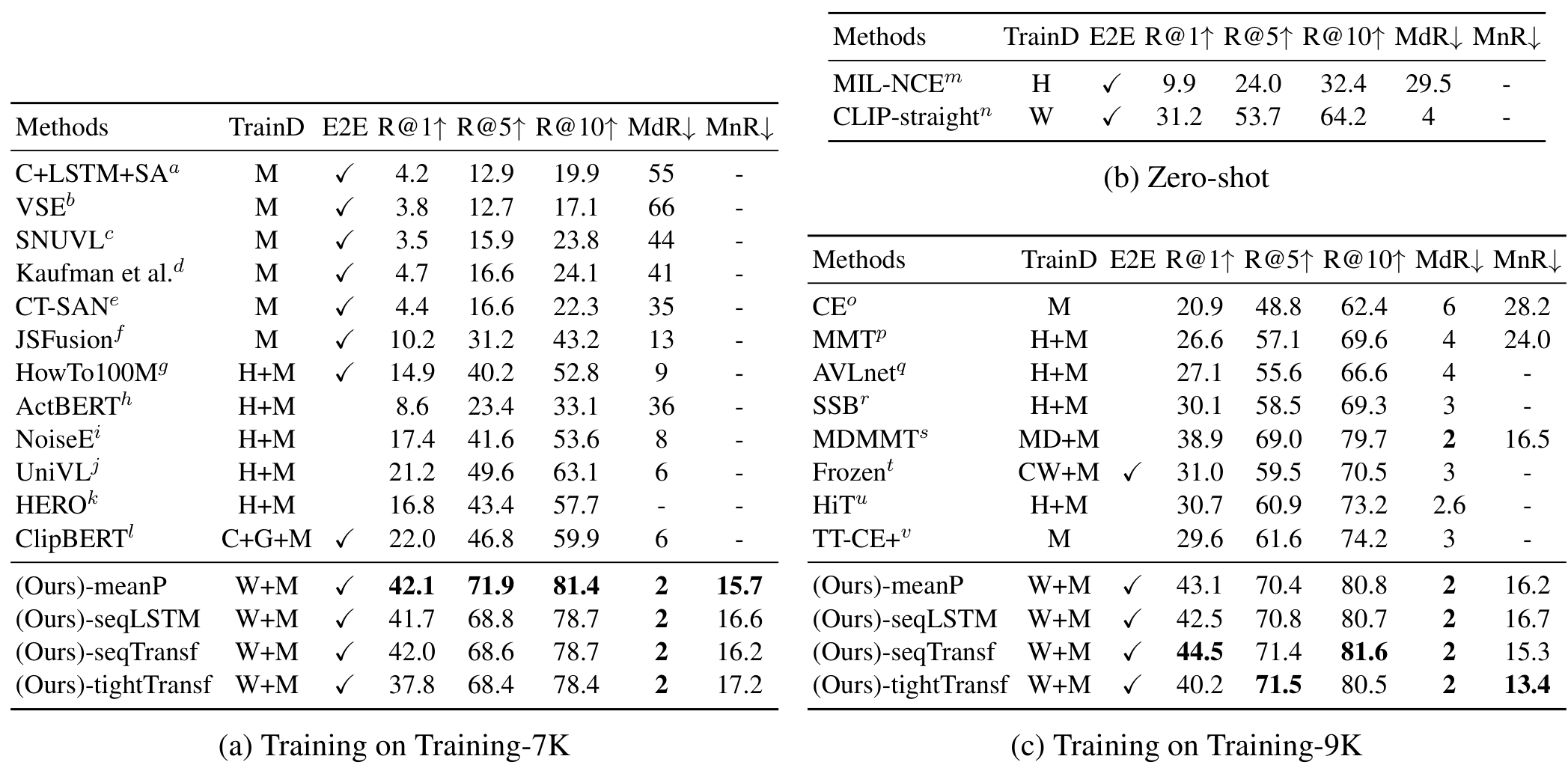
먼저, MSR-VTT는 학습 데이터가 7K인 설정과 9K인 설정이 있는데요, 학습 데이터가 적은 7K 설정에서는 추가적으로 학습해야 할 파라미터가 없는 -meanP 방식이 가장 좋은 반면, 9K 설정에서는 다른 방식들이 더 좋은 성능을 보였습니다. 이를 통해 저자들은 파인튜닝을 진행할 데이터가 적을 경우 parameter free 방식이, 충분할 경우 추가 파라미터를 사용하는 sequential 방식이나 tight 방식이 유리하다는 결론을 도출하였습니다.
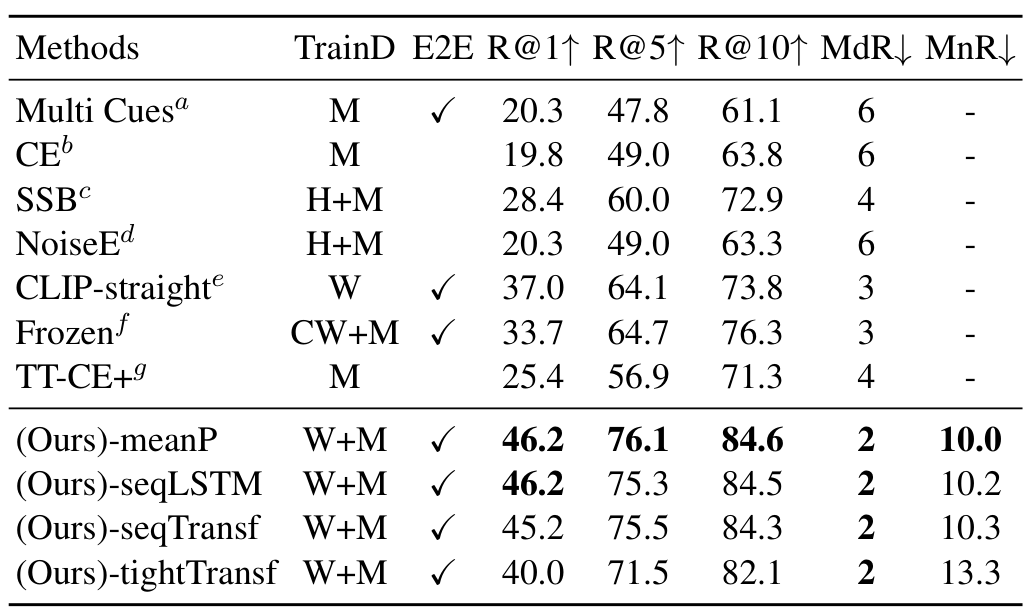
MSVD 역시 학습 데이터가 많지 않아 -meanP 방식이 좋은 성능을 보였습니다.
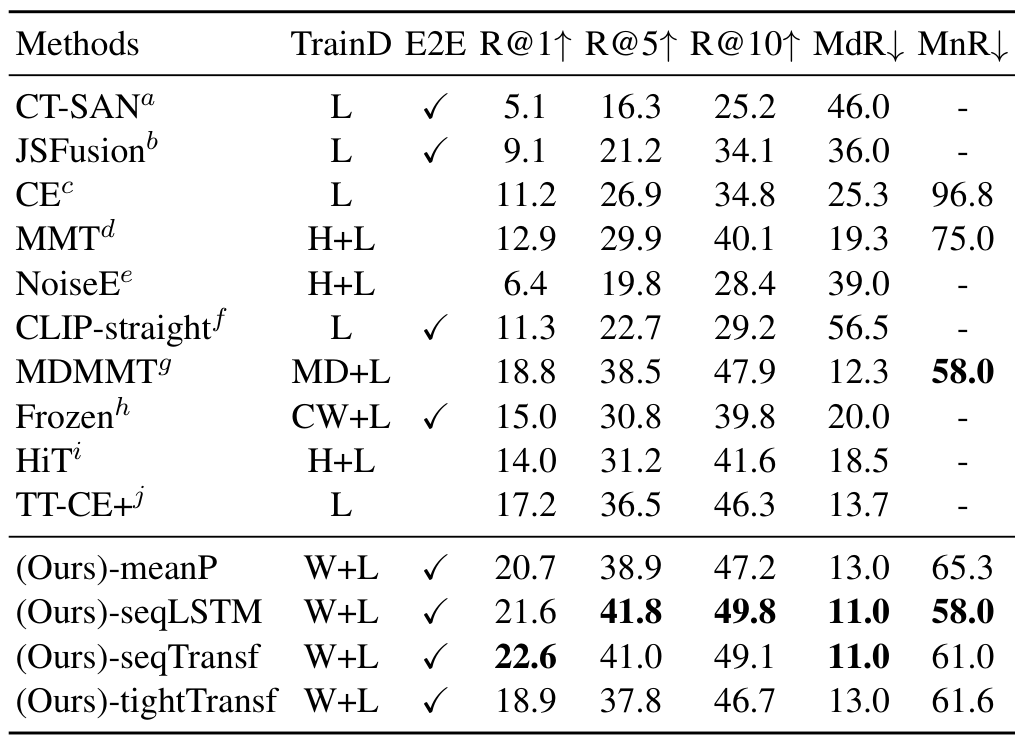
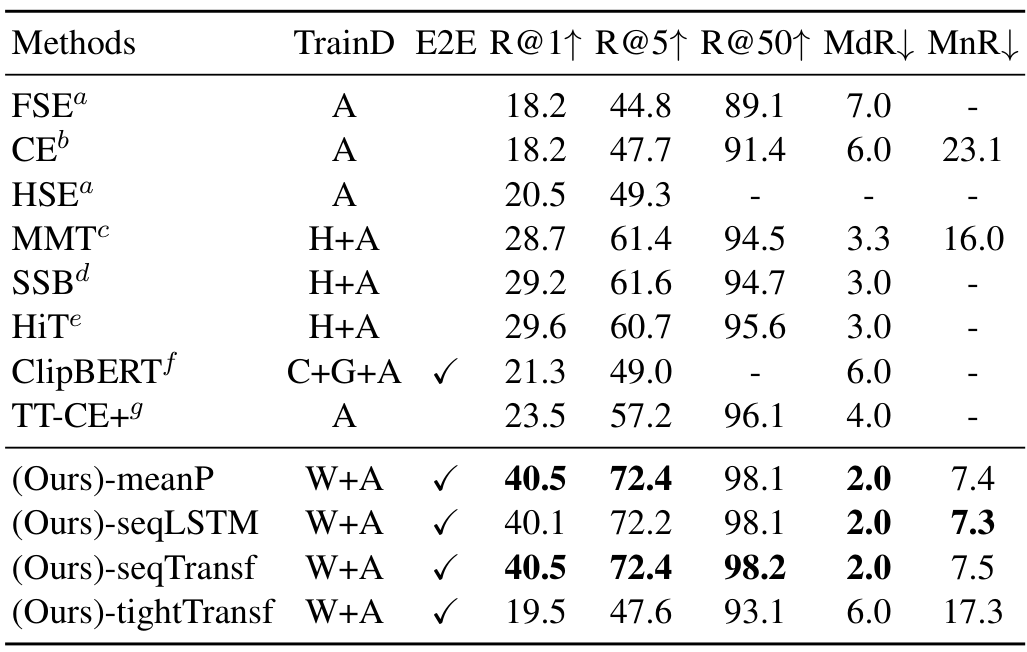
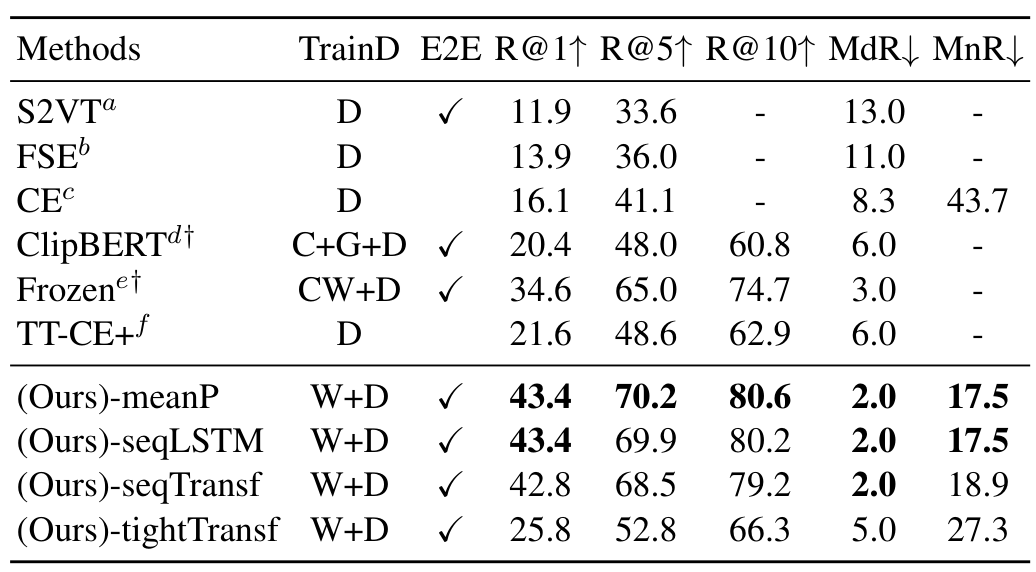
전체적으로 CLIP4Clip과 CLIP-straight의 성능이 높은 경향을 보이는 것으로 보아 CLIP을 사용하는 것에서 오는 성능 향상 폭이 큰 편입니다. 대체로 파인튜닝 데이터셋의 양에 따라 parameter-free 방식 혹은 sequential 방식이 SOTA를 달성하였고, sequential 방식 중 LSTM과 Transformer 방식은 비슷한 성능을 보였다고 합니다.
한편, tight 방식은 성능이 별로 좋지 못했는데, 이에 대해서 방법이 부적절하다기보다는 데이터가 부족하여 그런 것으로 보인다는 결론을 내었는데, 정작 그 이유가 상세히 설명되어 있지는 않아 아쉽습니다.
Hyperparameters and Learning Strategy

하이퍼파라미터에 대한 Ablation 입니다. 배치 사이즈는 클수록 좋으며, 128과 256부터는 비슷한 당연하다면 당연한 결과입니다. 비디오의 시간적 정보와 연관이 있는 frame length는 1과 6 사이에서 큰 성능 차이가 발생하는데요. 이를 기반으로 저자들은 한 장의 이미지를 single-frame video로 보기에는 무리가 있다고 주장합니다. 최소한 6장, 즉 6초씩은 추출해 줘야 비디오에서 어떤 시간적 정보를 얻을 수 있는 것으로 보입니다. 한편 그 이상으로는 프레임을 많이 뽑아도 별다른 차이가 나지 않네요. 한편, CLIP을 학습 시에 freeze 하는 것과 fine tuning 하는 것에 대한 비교를 수행한 결과, CLIP 역시 낮은 learning rate에서 학습되게 두는 것이 좋다고 합니다. 별로 새롭지는 않은 결과네요.
Post-pretraining
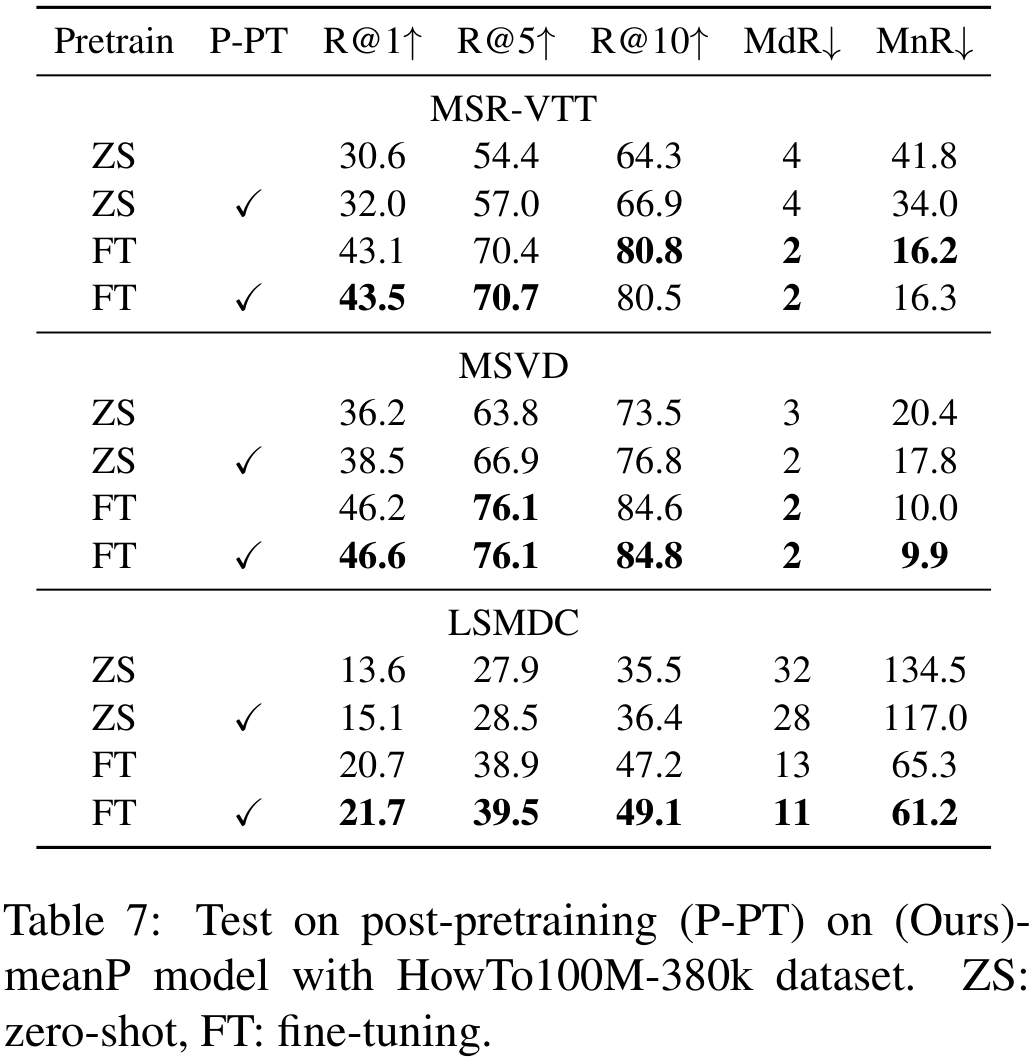
이미지에서 사전학습된 CLIP을 비디오 데이터셋에서 post-pretraining하는 것에 대한 실험입니다. post-pretraining을 통해 zero-shot과 finetuning 성능이 모두 증가하는 것을 볼 수 있습니다. 특히, zero-shot의 성능 차이가 커서 저자들은 향후 이 분야를 연구할 것이라 합니다.
개인적으로 아직 CLIP이 비디오에서 잠재력을 완전히 발휘한 것이 아니라는 것이 보여서 기대되는 결과인 것 같습니다.
Sampling Strategy
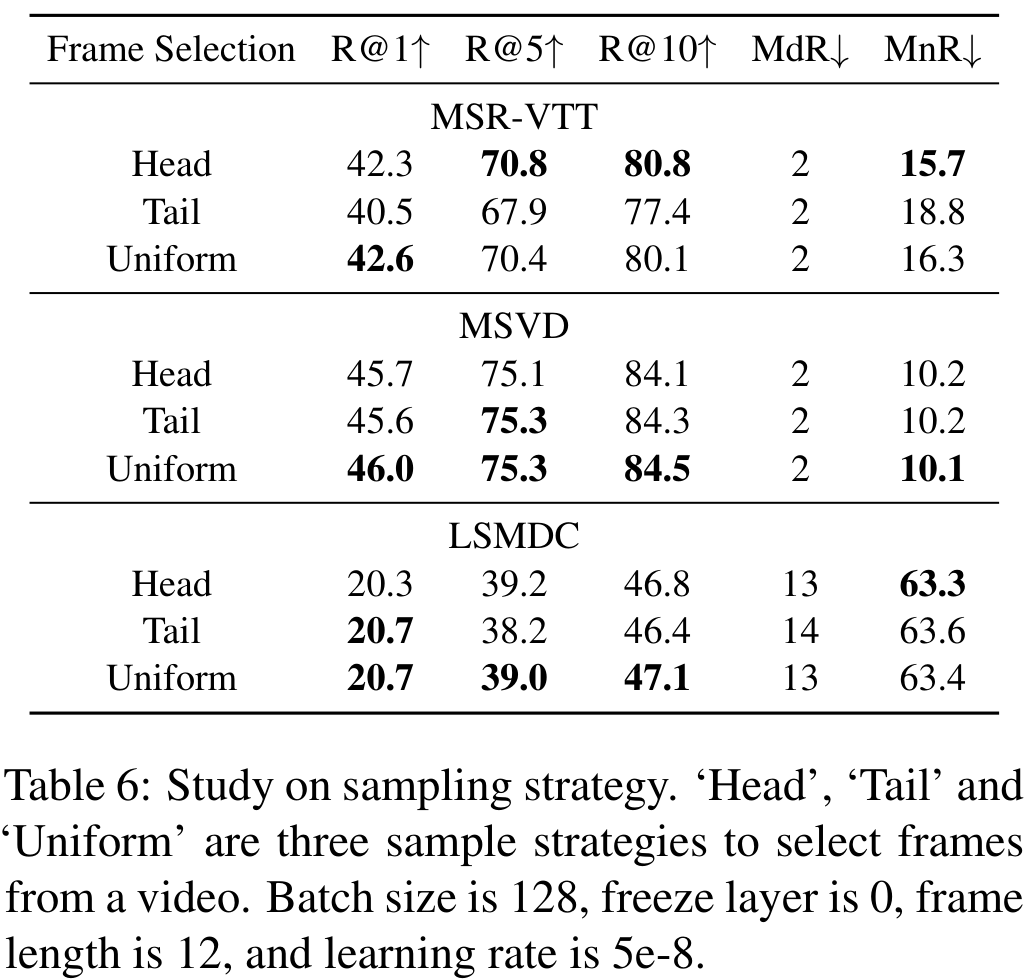
영상에서 1초에 1장의 프레임을 추출할 때, 정확히 어느 위치에서 추출하는 것이 좋은지에 대한 실험입니다. Head는 추출해야 할 프레임 중 첫 프레임, Tail은 마지막 프레임, Uniform은 균등한 추출, 즉 중심을 의미합니다. 최근에 저희 팀 연구 중에도 이에 대한 의문이 있었는데, 미리 이 논문을 봤으면 좋았을 걸 그랬네요.
저희가 실험했을 때는 대체로 유사한 결과가 나왔던 것 같은데, 본 논문에서 역시 uniform과 head가 비슷하고, tail이 조금 떨어지는 성능을 보였다고 합니다. 결과적으로 uniform이 가장 좋기는 해서, uniform을 사용했다고 합니다.
2D/3D Patch Linear

프레임을 visual encoder에 입력할 때, Linear Projection 과정에서 3D CNN을 통해 temporal modeling을 수행한 것에 대한 실험입니다. 의외로 2D가 더 나은 성능을 보였는데, 이는 CLIP이 2D Linear를 사용하는 것을 전제로 학습되어 그런 것으로 보인다고 합니다. 즉, 더 큰 데이터셋에서 잘 post-pretraining 하면 3D가 더 좋을 수도 있다는 것이죠.
저자들은 이 또한 추후에 연구해 볼 것이라 합니다.
Conclusion
저자들은 CLIP을 비디오 데이터셋으로 추가 사전학습한 후, 적절한 유사도 계산 방식을 통해 video-text retrieval task를 풀고자 하였습니다.
이를 위해 CLIP을 비디오에서 잘 post-pretraining하기 위한 방법, temporal modeling을 고려한 유사도 계산 방법 등을 제안하여 다양하게 실험하였고, 결과적으로 5개 데이터셋에서 높은 성능으로 SOTA를 달성했습니다.
또한 여러 실험을 진행하는 과정에서 아래와 같은 다양한 인사이트를 얻었습니다.
- Image Feature는 Video에 도움을 줄 수 있다.
- 이미 잘 학습된 CLIP을 video에서 post-pretraining하여 성능을 더욱 향상할 수 있다.
- 3D patch linear와 sequential한 유사도 계산 방식의 잠재력이 있다.
- Video-text retrieval task에서 CLIP이 learning rate sensitive 하다.
개인적으로는 CLIP을 비디오에 가져오면서 고려해야 할 요소들을 정말 다양하게 실험해 준 논문이라, 가려웠던 부분들이 많이 시원해진 느낌입니다. 논문 분량 제한 때문인지 일부 주장에 비약이나 근거가 약해 보이는 부분이 있기는 하지만, 이런 부분들은 대부분 추가 연구를 해보겠다고 해서 저자들의 향후 work가 기대되는 논문입니다.
재밌게 읽었네요.
오늘도 읽어주셔서 감사합니다.
안녕하게요 좋은 리뷰 감사합니다.
생각보다 많은 데이터셋에서 단순 평균 방식이 좋은 성능을 보여주내요..
학습 부분에서 언급된 lr 1e-8과 그림 3에 언급되는 lr 5e-8은 각각 어떻게 적용되는 것인가요? 그리고 tight transformer 방식을 좀 더 고도화시킨 방법들이 있는지 궁금합니다.
안녕하세요.
training 파트에서 언급된 LR은 CLIP 모델을 HowTo100M에서 post-pretraining 시 사용한 LR이며, 그림 3에서 언급된 LR은 post-pretraining 후 실험 데이터셋에서 finetuning을 할 때 사용할 하이퍼 파라미터 탐색 ablation study에서 사용한 LR을 말하는 것입니다.
tight transformer 방식을 고도화시킨 방법은 저자의 추후 논문이나 인용 논문 중에 찾아보았는데 아직은 없는 것 같습니다.
감사합니다!
안녕하세요 백지오 연구원님 좋은 리뷰 감사합니다.
결국 이 논문의 목적은 clip에 video를 사용할 때 어떤 조건이 적합한지에 대한 design choice를 설정하고 이를 실험적으로 평가 한 것으로 이해하였습니다. 특히 video와 text representation 간의 similarity를 구하는 방법들간의 비교가 핵심적인 부분이라고 이해하였습니다.
실험 부분에서 질문이 있는데요, comparison with sota부분에서의 실험은 LSMDC를 제외하면 Recall 거의 20%가까이 상승한 것을 볼 수 있는데요, 논문에서 이유를 언급한 부분은 없는지 궁금합니다. 기존 방법론들을 학습 데이터에 WiT가 포함되지 않은 것을 보면 비교한 sota방법론들은 clip기반의 모델이 아니기 때문인가요?
안녕하세요.
네, 말씀하신 것처럼 CLIP(WiT)을 naive하게 적용한 이전 모델인 CLIP-straight도 기존 baseline들에 비해 10~20의 성능 향상이 있었기에, 성능 향상의 많은 부분에 CLIP을 사용한 것이 기여한 것 같다고 언급되어 있습니다.
감사합니다.