제가 이번에 리뷰할 논문은 RADepth라는 ECCV22년도에 게재된 논문입니다. Self-supervised Monocular Depth Estimation task를 다루고 있으며 보다 구체적으로는 다양한 resolution의 영상이 입력으로 들어온다고 하더라도 일관성 있는 성능을 달성하도록 한 방법론입니다.
Intro
해당 논문의 motivation과 contribution은 상당히 간단합니다. 보통 vision task에서는 모델을 학습할 때 항상 고정된 해상도로 영상을 resize해서 입력으로 사용합니다.(영상 전체를 resize하거나 혹은 random crop and resize를 하곤 하죠.)
마찬가지로 Self-supervised monocular Depth Estimation(SDE)에서도 보통 입력 영상을 640×192로 resize한 다음에 학습을 진행하고, 평가도 640×192 해상도의 영상을 입력으로 넣어서 수행합니다.
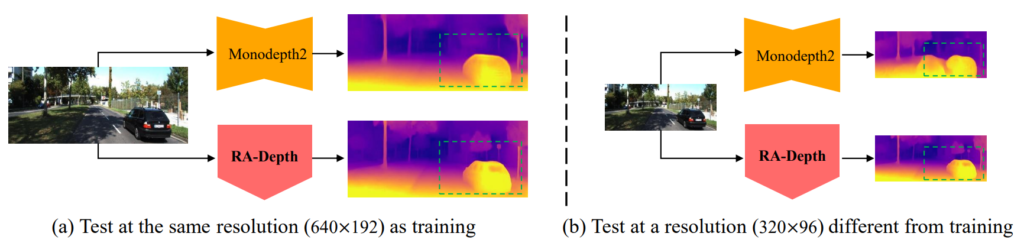
그렇다면 학습 때 보지 못했던 해상도의 이미지를 테스트타임 때 전달하면 어떻게 될까요? 보통 컨볼루션 연산은 영상의 해상도와 상관없이 모두 진행이 되기 때문에 연산을 하는데 있어서 에러는 발생하지 않습니다만, 당연히 학습 때 보지 못했던 영상 크기이기 때문에 모델의 정확도가 감소하게 됩니다.
이러한 문제점이 SDE에서도 발생하게 되는데, 그 성능의 drop이 상당히 크다라는 것이 저자가 지적하는 문제 중 하나입니다. 실제로 위에 그림1에서 보면, SDE의 가장 대표적인 방법론 중 하나인 monodepth2의 경우 640×192로 학습한 모델이 640×192로 평가하면 그럴듯한 깊이 맵을 추론하지만, 해상도를 절반 줄여서 평가할 경우 depth map의 shape 등이 상당히 뭉게지는 것을 볼 수 있습니다.
아무튼 이렇게 학습 때 보았던 해상도에 대해서만 정확한 추론을 한다는 것은 이미 학습된 모델이 다른 setup으로 평가되어야 할 때, 다시 fine-tuning을 하는 등 추가적인 학습 비용이 들 수 밖에 없다는 것을 의미합니다. 그리고 이러한 재학습 과정은 cost가 낭비된다고 저자는 주장하구요.
따라서 저자는 어떠한 해상도가 입력으로 들어온다고 하더라도 일관성 있는 깊이를 추정할 수 있도록 하는 새로운 학습 방법론을 제안합니다. 이에 대해서는 아래 방법론에서 자세히 다뤄보도록 하죠.
Method
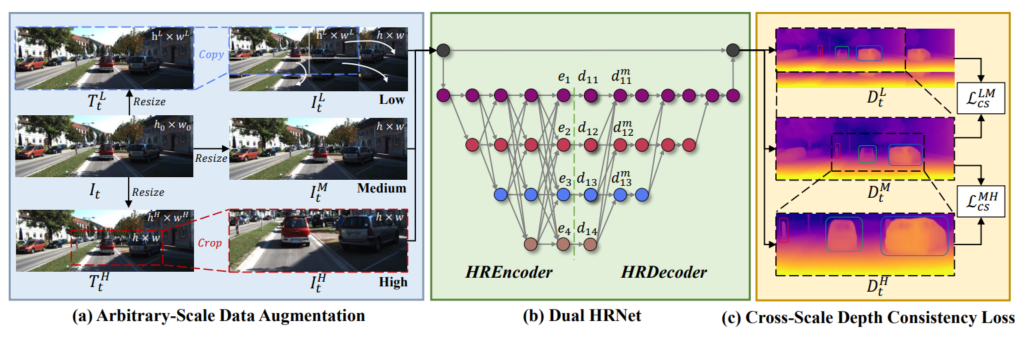
그림2는 본 논문에서 제안하는 Contribution을 그림으로 나타낸 것입니다. 대표적으로 a, b, c라는 크게 3가지 모듈을 제안하였으며 우선 a에 대해서 살펴보겠습니다.
Arbitrary-Scale Data Augmentation
첫번째 contribution은 다양한 해상도의 이미지를 생성하는 data augmentation 기법입니다. Depth Network의 입력으로 넣어야하는 이미지 I_{t}가 존재한다고 했을 때, I_{t}에 대하여 특정한 범위 내로 Resize 연산을 수행해서 만든 이미지를 각각 T_{t}^{L}, T_{t}^{H} 입니다. 여기서 L은 low resolution을, H는 High resolution을 의미하기 때문에 Resize도 그에 맞춰서 작아지거나 커지거나 하는 것으로 이해하면 될 것 같습니다.
그 다음 , I_{t}^{M} 영상에 T_{t}^{L} 를 붙여넣으면 I_{t}^{L} 영상을 만들 수 있으며, T_{t}^{H} 영상에 일부를 crop and resize하면 I_{t}^{H} 를 만들 수 있게 됩니다. 즉 쉽게 말하면 zoom in과 zoom out고 비슷한 느낌의 영상을 만들어서 원본 영상과 함께 총 3장의 영상을 모델에 입력으로 주어서 다양한 스케일의 영상에서 깊이를 추론하도록 하겠다는 것입니다.
여기서 한가지 중요한 점은, I_{t}^{L}, I_{t}^{H} 은 모두 I_{t}^{M}과 동일한 해상도를 지니고 있으며, 다만 시각적으로 보이는 것이 확대되어 있는지, 축소되어있는지 그 차이일 뿐입니다. 보다 디테일한 과정은 아래 수도코드를 참고하시면 좋을 것 같습니다.

Dual HRNet
위에서 만든 영상들은 이제 깊이 추정 네트워크에 입력으로 들어가 각각의 영상에 대한 깊이 맵을 추론해야만 합니다. 여기서 저자는 Dual HRNet이라고 하는 새로운 모델을 제안하는데, 사실 컨셉은 매우 간단합니다. RADepth 이전부터 DIFF, HRDepth 등의 방법론들이 HRNet이라고 하는 backbone network를 SDE task에 활용을 하였으며, RADepth도 마찬가지로 HRNet을 활용하게 됩니다.
여기서 Decoder 부분을 어떻게 개선하면 좋을까 하다가 HRNet의 인코더 구조와 유사하게 Decoder도 만들어보자 해서 마치 Encoder와 Decoder가 모두 HRNet 처럼 생겼으니 Dual HRNet이라고 이름을 붙이게 됩니다. 그림2의 b에서 HRNet Encoder가 어떻게 동작하는지 한눈에 알 수 있으며, HRDecoder도 이와 유사하게 모든 resolution에 대해서 계속해서 feed forward하는구나 라고 이해하시면 됩니다.
Cross Scale Depth Consistency loss
다음은 Cross Scale Depth Consistency loss에 대한 부분입니다. 사실 해당 loss가 제가 개인적으로 생각하였을 때는 가장 중요한 contribution이 아닐까 싶습니다. 먼저 저희가 데이터 증강 기법을 통해서 I_{t}^{L}, I_{t}^{M}, I_{t}^{H} 을 만들었으며 Dual HRNet이라는 깊이 추정 모델에 입력으로 넣어서 각각 D_{t}^{L}, D_{t}^{M}, D_{t}^{H} 이름의 depth map을 생성하였습니다.
그 다음에는 Self-supervised monocular depth estimation의 기본 학습 방식인 photometric loss를 통한 학습이 진행됩니다. photometric loss란 쉽게 말해 아래 수식 1과 같이 두 영상 사이에 픽셀 오차를 계산하는 것입니다.
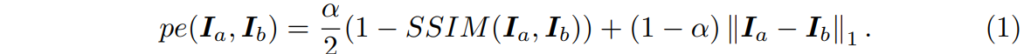
여기서 픽셀 오차를 계산한다는 것은 영상만으로 깊이를 학습해야하는 self-supervised learning이기 때문에, 모델이 추론한 깊이 결과와, camera pose network의 외부 파라미터 추론 값을 통하여 source image를 target image로 변환한 후 이 둘의 픽셀 값 차이를 줄여나감으로써 깊이 네트워크와 포즈 네트워크를 학습시킨다는 것이죠.
여기서 기존의 SDE 방법론들은 I_{t}^{M}에 대해서만 입력으로 사용하니, photometric loss도 한번만 계산하면 되지만, RADepth의 경우에는 I_{t}^{L}, I_{t}^{M}, I_{t}^{H} 3가지 입력에 대해 모두 depth를 계산하고 warping을 진행하여 photometric loss를 계산하게 됩니다. (여기서 중요한 점 중 하나는 warping을 수행할 때 두 카메라 간에 pose 값은 I_{t}^{M} 이미지로 추정한 pose 값만을 사용합니다. 즉 L와 H 영상에 대한 pose는 계산하지 않는다는 것이죠.)
아무튼 이렇게 photometric loss가 L, M, H에 대하여 모두 수행이 되고 이를 backward하여 학습을 수행하게 되는데, 이때 한가지 중요한 점이 있습니다. I_{t}^{L}, I_{t}^{M}, I_{t}^{H} 영상은 모두 하나의 이미지(정확히는 I_{t}^{M})를 기준으로 파생된 영상들이라는 점입니다.
따라서 I_{t}^{L}, I_{t}^{M}, I_{t}^{H} 은 모두 정확히 동일한 카메라 위치에서 동일한 대상을 촬영한 영상이기 때문에 이들의 외적으로 보이는 scale이 다 달라도 추론되는 깊이 값은 모두 같다고 볼 수 있습니다. 따라서 논문에 저자도 이를 의식하고, D_{t}^{L}, D_{t}^{M}, D_{t}^{H} 에 대하여 모두 같은 값을 가져야만 한다~라는 식으로 loss를 설계하였으며, 이를 Cross-scale Depth consistency loss라고 합니다.
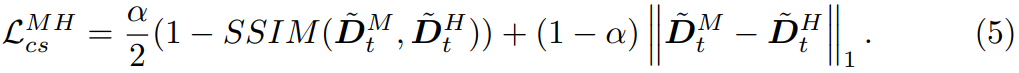
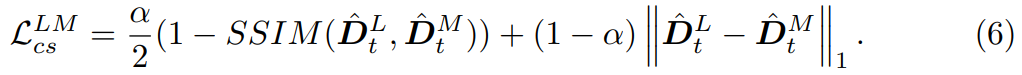
저자는 위와 같이 M을 기준으로 H와 L을 비교하는 방식으로 loss를 계산하였다고 합니다.
Experiments
실험 섹션 다루고 리뷰 마무리 짓도록 하겠습니다.
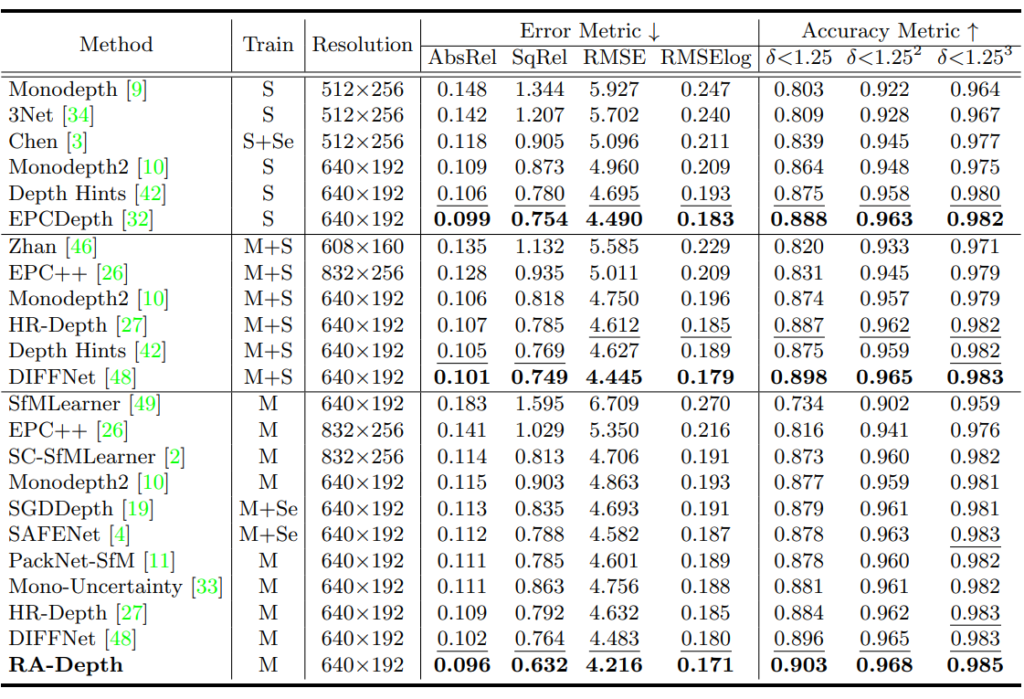
위에 표는 KITTI Dataset에 대하여 정량적 성능을 리포팅한 것으로, Train에 S, Se, M은 각각 학습 때 사용한 데이터의 종류로써 Stereo, Segmentation, Monocular video를 의미합니다. 그냥 가장 중요하게 보실 점은 맨 아래 M으로만 학습한 평가 세팅을 살펴보시면 되며, 여기서 RA-Depth가 가장 좋은 성능을 달성했다는 것을 살펴보시면 됩니다.
이게 참 재밌는 것이, 제안하는 방법론의 원래 목적은 학습 단계에서 봤던 해상도 외에 다른 해상도가 모델에 입력으로 들어올 때 여전히 일관성 있는 깊이 맵을 추론하도록 하는 것이 본 논문의 목표였던 것인데 저자가 제안하는 방식을 활용하게 되면 학습과 평가가 모두 동일한 해상도일지라도 성능에 개선점이 크게 난다는 것입니다.
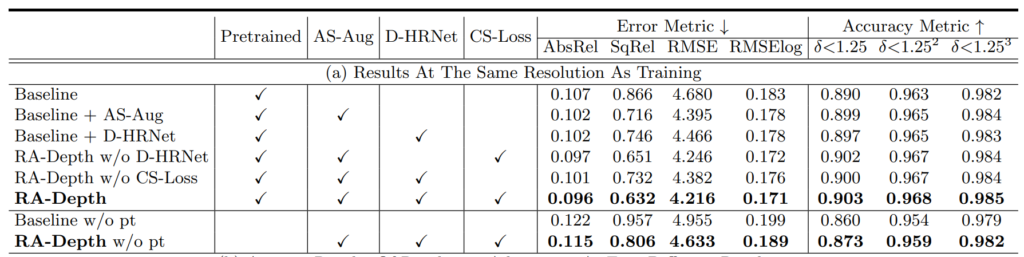
실제로 위에 ablation table을 살펴보시면 모델 학습과 평가가 동일한 해상도인 실험 세팅 기준, baseline에서 각각의 contribution을 붙일때마다 성능이 큰 폭으로 향상되는 것을 볼 수 있습니다.
근데 이제 Dual-HRNet은 다른 두가지 contribution(AS-Aug와 CS-Loss)에 비하면 그리 중요해보이지는 않으며, CS-Loss를 계산하기 위해서는 결국 AS-Aug가 들어가야한다는 점과, AS-Aug와 D-HRNet 조합 보다 As-Aug와 CS-Loss의 조합일 때 성능이 크게 향상된다는 점에서 결국 AS-Aug와 CS-Loss가 SDE task에 상당히 큰 영향력이 있다라는 것을 유추할 수 있습니다.
다음은 저자의 원래 목적이었던 test 단계에서 해상도를 달리 하면 어떻게 성능 변화하는지를 보여주는 실험입니다.
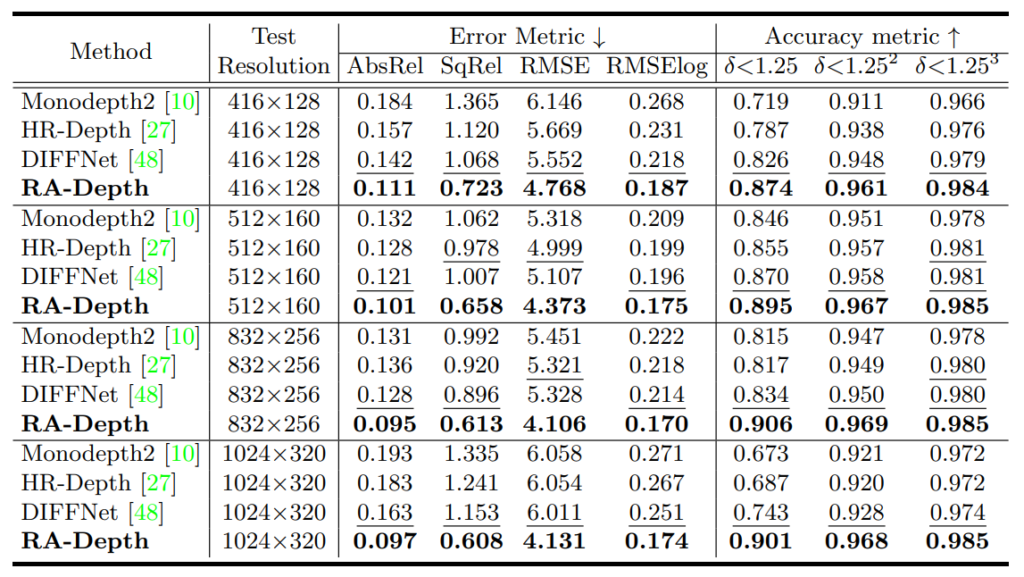
모델은 크게 416×128부터 1024×320까지 총 4가지의 각기 다른 해상도로 평가를 수행하였습니다. 모든 방법론들은 학습 때 640×192 크기의 영상으로 학습이 진행되었다는 점 말씀드립니다. 여기서 DIFFNet의 경우에는 640×192 해상도 기준으로 abs rel이 0.102까지 도달하는 등 상당히 좋은 성능을 달성했었음에도 불구하고, 학습 때 한번도 보지 못한 해상도들이 입력으로 들어오니 abs_rel 기준 0.121qnxj 0.163까지 매우 큰 성능 하락폭을 가지고 있음을 알 수 있습니다.
반면에 제안하는 RA-Depth의 경우에는 저해상도 입력이 들어오더라도 성능의 하락이 그리 크지 않았으며, 반대로 고해상도의 입력이 들어올 경우에는 특정 메트릭에서 성능 향상이 있는 등 상당히 해상도 변화에 강건한 모습을 보여주고 있습니다.
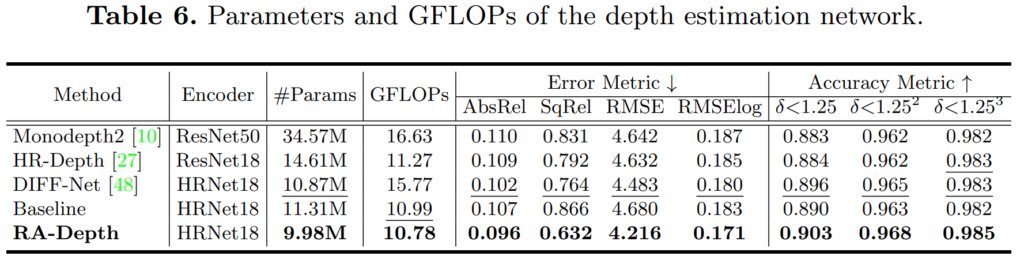
마지막으로 제안하는 방법론이 성능이 너무 좋다보니, 혹시나 모델의 크기 측면에서 다른 이점이 있는 것이 아닌가 할 수 있으실텐데 아래 표를 살펴보시면 가장 작은 모델 사이즈임에도 불구하고 가장 좋은 성능을 달성한 것을 볼 수 있습니다.
결국에 제안하는 학습 방법론 자체가 깊이 추정 네트워크에 상당히 큰 기여를 했다는 것이 제 개인적인 생각입니다.
결론
저자는 테스트 타임에서 다른 해상도가 들어왔을 때도 강건해야만 한다는 것을 가장 큰 논문의 motivation으로 접근을 했습니다만, 저는 해상도 관점보다는 SDE task에서 성능 개선을 저렇게 의미있게 향상시켰다는 점에 대단함을 느끼고 있습니다. 실제로 데이터 증강 기법과 consistency loss 이 둘만을 이용해서 영상 정보만으로도 의미있는 성능 향상을 이루어낸 것이 상당히 재밌네요.
안녕하세요 신정민 연구원님 좋은 리뷰 감사합니다.
본문의 photometric loss 부분에서 카메라의 pose를 I^M에 대해서만 추정하는 이유는 I^H와 I^L이 각각 I^M을 가지고 생성한 이미지이기 때문에 동일한 외부 파라미터를 가지고 있기 때문이라고 이해하였습니다.
그렇다면 궁금한 점이 있는데요, augmentation 기법으로 crop and resize를 사용한다고 하셨는데 이때 crop된 영상은 원본과 동일한 비율을 가지고 있는 건가요?
만일 원본 해상도가 640*192인데 crop된 이미지의 비율이 이와 다르다면 서로 다른 파라미터 값을 가지게 될 수 있는지도 궁금합니다.