제가 이번에 리뷰할 논문은, cross-category level 6D Pose Estimation이라는 새로운 방식의 6D Pose Estimation 방식입니다. 기존에 리뷰했던 논문들은 객체 별로 3D 모델이 필요한 instance-level의 방식과 여러 형태의 instance들을 이용하여 category마다 하나의 대표 3D 모델을 구해 이용하는 category-level의 방식이었습니다. 본 논문에서 제안한 cross-category level은 unknown object에 대해 대응할 수 있는 방식으로, category-level의 방식을 넘어 6D Pose estimation 방식의 일반화 성능을 높이기 위한 논문으로 해당 분야를 실제 활용 관점에서 보았을 때 굉장히 유의미한 방향이라 생각하여 리뷰를 하게 되었습니다. 그럼 리뷰를 시작해보겠습니다.
Abstract
해당 논문은 meta-learning 방식을 6D Pose Estimation에 적용하여 unknown 객체에도 대응할 수 있도록 category-agnostic 방식을 제안한 논문입니다. 강력한 일반화 성능을 가진 6D Pose Estimation을 위해 meta-learning 방식을 도입하여 encoder를 학습(latent representation의 texture 정보와 기하학적 정보를 포착하기 위해 적은양의 RGB-D 데이터와 GT keypoint를 이용)하였고, 이렇게 학습된 latent representation을 이용하여 meta-trained decoder에서 새로운 이미지에 대한 6D Pose 추정에 사용하였다고 합니다. 나아가, 기하학적 정보를 이용하여 새로운 keypoint를 예측하는 Graph Neural Network 기반의 decoder를 제안하여 기하학적인 제약조건을 반영한 keypoint 예측이 가능하도록 하였다고 합니다. LineMOD 데이터와 저자들이 새롭게 제안한 합성데이터인 MCMS를 이용하여 실험을 진행하였고, unseen object에 대해 잘 작동한다는 것을 확인하였고, 심지어 occlusion이나 truncation이 발생한 케이스에도 잘 작동한다는 것을 확인하였다고 합니다. 그리고 가장 중요한 내용으로, 저자들은 자신들이 처음으로 cross-category level 6D Pose estimation을 제안하였다고 합니다.
Introduction
6D Pose Estimation은 로봇의 grasping, AR 등 실제 활용 관점에서 중요한 비전 task입니다. 이를 해결하기 위해 instance-level의 방식은 사전에 정의된 object에 대해 학습을 하여 pose 정보를 추정하였습니다. 이러한 방식은 특정 object 에 overfitting이 되므로 일반화가 어렵고, 따라서 실제 적용까지 가기 어려웠습니다.
이러한 문제로 인해 category-level의 방식이 최근 연구가 되었습니다. 이러한 방식은 동일 카테고리에 속하는 여러 인스턴스들로 부터 통합된 표현을 생성하는 NOCS, CASS 연구가 있습니다. 그러나 통합된 하나의 표현을 이용할 경우 object 의 외관 변화로 인해 성능이 저하되는 문제가 있습니다.
이를 해결하고자 representation space에 추가적인 정보를 내포하기 위한 연구가 수행되었으나, 이러한 방식들은 각 카테고리에 대하여 사전 학습된 detector가 필요하므로, 여전히 category에 한정되어 일반화 성능이 떨어진다는 문제가 있습니다.

본 논문에서는 6D Pose 추정의 일반화성능을 높이기 위해, 새로운 meta-learning 기반의 방법론을 제안하여 category를 뛰어넘을 수 있는 첫 번째 연구라고 어필합니다. 여기서 meta-learning에 대해 간단히 설명하자면, 일부 예시를 이용하여 새로운 task에 빠르게 적용하는 것이 목표로, 그중에서도 CNPs라는 방식을 도입하였다고 합니다.(CNPs는 아래{}절의 설명을 참고해주세요!) 저자들이 제안한 방식은 포괄적인 외관과 기하학적 정보를 포착할 수 있는 latent space를 학습하기 위해 CNPs를 이용하였으며, 추론 과정에서는 새로운 객체들의 일부 예시만을 입력하면 각각의 표현을 출력할 수 있으며 fine-tuning도 필요하지 않다고 합니다.
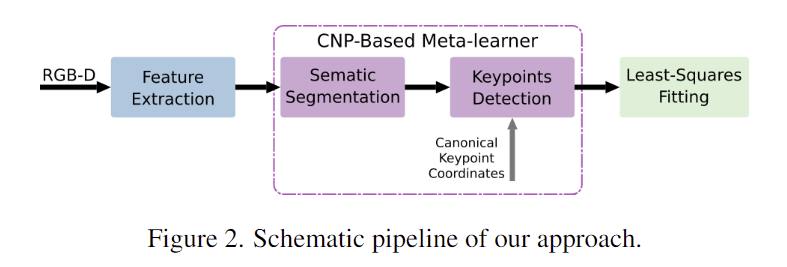
RGB-D 데이터를 입력으로 하여 양방향으로 RGB-D정보를 융합하는 방식의 FFB6D를 이용하여 특징을 추출하고, 융합 네트워크 상단에 meta-learning을 위한 CNP를 추가하였다고 합니다. CNP는 객체의 context 이미지 집합으로부터 대표적인 특징을 GT 라벨과 함께 가져오고, latent representation을 만들어냅니다. 새로운 target 이미지에 대한 pose 예측은 이렇게 구한 latent representation을 이용합니다.
이후 기하학적 정보를 이용하거나 keypoint 예측을 향상시키기 위해 GNN 기반의 디코더를 제안하였습니다. 사전에 정의된 keypoint를 통해 추가 입력을 받아 keypoint 사이의 message passing(GNN에서 해당 노드의 상태를 업데이트하기 위해 이웃한 노드의 정보를 이용하는 것)을 통해 local한 공간적 제약조건을 인코딩하는 decoder로, 이때 GNN에 들어가는 추가적인 입력은 annotation이 필요하지 않다고 합니다.
또한, cross-category level Pose Estimation을 평가하기 위한 데이터가 부족하여 합성 데이터인 Multiple Categories in Multiple Scenes(MCMS)를 제안하였습니다. MCMS는 데이터를 생성할 때 온라인 occlusion & truncation 검사를 수행하였다고 합니다.
논문의 Contriubtion을 정리해보면
- unseen object에 대한 강한 일반화성능을 갖추기 위해 meta-learning 기반의 프레임워크 제안
- GNN 기반의 keypoint 예측 모듈을 제안하여 기하학적 정보를 이용하고 local한 공간적 제약을 포착
- 다양성이 있는 fully-annotated 합성 데이터 제안
Related Work
Meta-Learning
Meta-learning은 모델을 새로운 task에 빠르게 적용할 수 있는 메타지식을 획득하는 것을 목표로 하는 학습 방식으로, metric-based, optimization-based, model-based 방식으로 구분된다고 합니다. 본 논문에서 사용하는 방식은 model-based 방식에 속하는 Neural Processes(NPs)를 기반으로 합니다. NPs는 함수 regression과 같은 단순한 task에서 잘 작동하지만 6D Pose Estimation 방식에 적용된 적은 없었다고 합니다. 저자들은 일반화 성능을 높이기 위해 CNP를 도입하였다고합니다.
Preliminary – Conditional Neural Processes
Conditional Neural Processes (CNPs)는 “context”라 하는 입력을 조건으로 일부 target 입력 x_t에 대한 추론을 수행하는 조건부 모델이비다. context는 하나의 특정 task의 입력들 x_c과 그에 대응되는 라벨들 y_c로 구성되며, 본 연구에서는 object들을 하나의 task로 보았다고 합니다.
CNP는 encoder, aggregator, decoder 3가지로 구성됩니다. encoder는 task C=\{(x_c^i,y_c^i) \}_{i=1}^{M_c}로부터 주어진 M_c 개의 context 쌍을 입력으로 하여 각 context 쌍에서 embeddings r_i=h_{\theta} (x_c^i,y_c^i), ∀(x_c^i,y_c^i) ∈ C 를 추출합니다.( h는 neueral network, \theta는 네트워크 파라미터) 그후 aggregator a 는 permutation invariant** 연산자 ⊗를 이용하여 ebedding을 요약하고 global latent variable을 생성합니다.: z=a(r_1,r_2,...,r_{M_c}) = r_1⊗r_2⊗...⊗r_{M_c} 이때, context set의 크기 M_c 가 달라질 수 있으므로, permutation invariant**한 작동을 위해 Max aggregation일 이용하였다고 합니다.(기존 연구를 통해 max aggregation 방식이 mean aggregation보다 성능이 좋다고 알려져 있다고 합니다) 마지막으로, decoder는 앞서 구한 representation z에 따라 target inputs 집합 T = \{ x_t^i \}^{M_t}_{i=1} 에 대한 예측을 수행합니다.: \hat{y}^i_t = g_ϕ(x_t^i,z), ∀x_t^i ∈ T(g는 decoder ϕ는 네트워크 파라미터)
CNP는 극히 일부의 샘플로부터 유의미한 latent representation을 추출할 수 있는 능력이 있어 cross-category level 방식에 적합하다고 합니다. 물체마다 정의된 keypoint 위치가 다르기 때문에 기존의 방법론들은 새로운 물체에 일반화를 하기 어려웠으나, 객체의 특징으로부터 잠재적인 keypoint를 추출하도록 meta-training을 수행하면 이를 해결할 수 있다고 저자들은 주장합니다.
**permutation invariant란? 출력 순서에 입력 순서가 영향을 주지 않는 것
Approach
본 논문은 본 적 없는 object에 대한 6D Pose estimation을 위해 keypoint 기반의 meta-learning 방식을 제안합니다. RGB-D 이미지가 입력으로 주어지고, 6D Pose Estimation은 강체의 transformation [R;t](R:rotation, t: translation)를 예측하는 것을 목표로 합니다. 카메라 좌표에서 keypoint를 예측한 뒤, keypoint와 객체 좌표의 keypoint의 변환관계를 regression으로 구하는 방식입니다. 이때 객체좌표의 keypoint는 FPS(Fathest Point Sampling, 가장 먼 점들을 선택하는 방식)알고리즘을 이용하여 미리 정해두었다고 합니다.
1. Overview
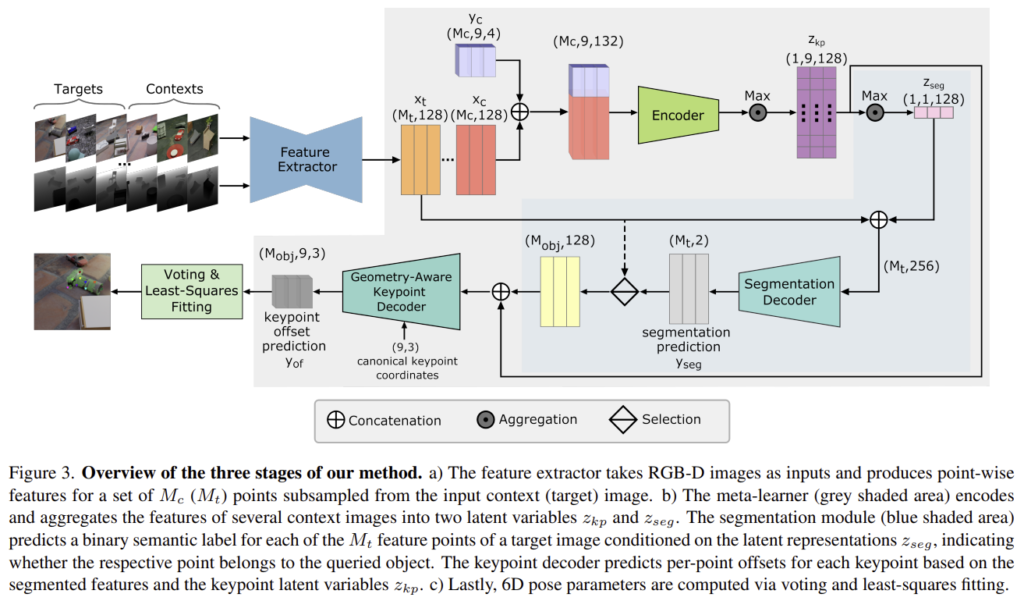
6D Pose Estimation을 위해 3가지 단계를 거칩니다.: feature extraction, keypoint detection, pose fitting
- feature extraction 단계에서는 FFB6D를 이용하여 RGB-D 입력으로부터 대표적인 특징을 추출합니다.
- CNP기반의 meta-learning 방식을 이용하여 context 샘플들과 target 샘플들로부터 representation을 구합니다. 각 task의 context inputs x_c와 그에 대응되는 labels y_c 가 함께 사용되고, 이렇게 구한 representation은 target inputs x_t 의 예측에 대한 사전 지식이 됩니다. 이후 두개의 decoder를 사용하여 semantic labels과 3D keypiont offset을 예측합니다.
- least-squares fitting을 이용하여 6D Pose 파라미터를 예측합니다.
2. Feature Extraction
이미지의 외관적 정보와 depth 정보의 기하학적 정보가 서로 상호보완적이라는 특성을 잘 살리기 위해, feature를 추출하는 과정에서 양방향으로 정보를 제공하여 융합하는 방식인 FFB6D를 이용하여 feature를 추출합니다.(자세한 내용은 이전 x-review를 참고해주세요.) feature extraction을 통해 샘플링된 seed point의 각 point별 feature를 얻게 됩니다.
3. Meta-Learner for Keypiont Detection
해당 과정은 keypoint를 추정하기 위해 query object의 segmentation과 keypoint detection 두 단계로 이루어지며, 두 과정 모두 앞서 구한 representation을 이용합니다.
Extraction of latent representation.
여러 객체로 이루어진 장면에서 새로운 객체를 식별하고 해당 keypoint를 구하기 위해서 query로 주어진 객체의 latent representation을 조건으로 하는 모듈이 필요합니다.(영상 내의 여러 객체 중 pose를 알고자 하는 객체에 대한 latent representation을 구하는 것!)
이를 위해 context samples 집합 \{ (x_{c,i}, y_{c,i} \}^{M_c}_{i=1} 이 필요합니다.( x_{c,i}: point 별 feature, y_{c,i} = \{y^u_{c,i} \}^{M_K}_{u=1}: GT label.)
- y^u_{c,i}=\{ y^u_{of}, y_{seg} \} = {seed point와 미리 정의된 3D keypoint 사이의 offset, seed point가 query object에 속하는지를 나타내는 라벨(0 or 1)}
이렇게 구성된 context sample이 입력으로 주어지면 encoder는 seed point별로 M_k개의 keypoint에 대한 embeddings를 생성합니다.
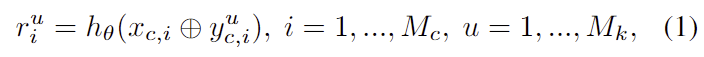
- M_c : context 이미지로부터 선택된 seed points 수
- M_k : 선택된 keypiont 수 (본 논문에서는 9로 설정하였다고 합니다.)
- ⊕: concatenation 연산자
이렇게 구한 embeddings는 max aggregation을 이용하여 종합되어 latent representation z^u_{kp} 가 됩니다. 그 다음 segmentation에 대한 representation을 추출하기 위해 keypoint representation에 대해 두번째 aggregation을 수행합니다.
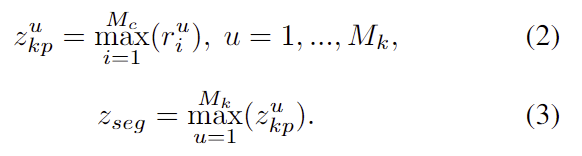
Conditional Segmentation.
위의 과정을 통해 z_{seg} 는 모양과 texture 속성과 같은 정보를 압축하고, 이를 통해 target 이미지에서 query object를 찾을 수 있습니다. segmentation decoder g_S는 z_{seg}와 target 이미지로부터 구한 feature x_t 를 입력으로 하여 각 seed point에 대한 semantic label을 예측합니다.
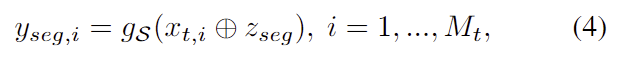
- M_t: target 이미지로부터 샘플링된 seed point 수
- x_{t,i}: 추출된 feature
point별 segmentation 예측 결과인 y_{seg}는 x_t에서 query object에 속하는 seed point의 feature x_{obj}를 구하는 데 사용됩니다.
Conditional Keypoint Offset Prediction.
keypoint offset을 구하는 decoder g_{\mathcal{K}} 는 segmentation 모듈로 추출한 feature와 latent 값인 z_{kp}를 입력으로 받아 각 keypoint에 대한 translation offsets y_{of} 를 예측합니다.
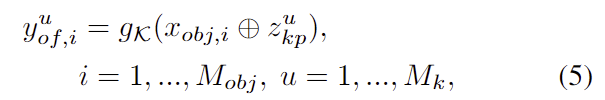
- M_{obj}: query object로 예측된 seed points의 개수
- x_{obj,i}: i번째 seed point의 feature
여기서 decoder g_{\mathcal{K}} 는 단순한 MLP를 기본으로 이용하였고, 기하학적 정보를 포함하기 위해 최종적으로는 GNN으로 이용하였다고 합니다.(4. Geometry-Aware Keypoint Decoder에서 설명)
Pose Fitting
keypoint deocder가 출력한 keypoint 후보를 기반으로 카메라좌표에서 최종적인 keypiont \{ p^*_i \}^{M_k}_{i=1} 를 구하기 위해 MeanSift[1]를 이용하였다고 합니다.( FFB6D의 방식을 따른 것..) 사전에 정의된 keypoint \{ p_i \}^{M_k}_{i=1} 가 주어지면 pose 추정은 least-squares fitting 문제로 바꾸어 오차 제곱을 최소화하는 pose 파라미터 [R;t]를 찾습니다.
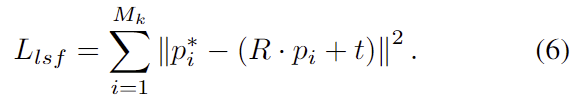
[1] D. Comaniciu and P. Meer. “Mean shift: a robust approach toward feature space analysis.” IEEE Transactions on Pattern Analysis and Machine Intelligence, 2002.
4. Geometry-Aware Keypoint Decoder
잎서 설명한 내용에 따르면, 해당 방법론도 사전에 정의된 keypoint를 이용합니다. 저자들은 이른 추가적인 정보라고 하며, object의 기하학적 구조 정보를 포함하고 있으므로 유용한 정보이며, 이를 강조하기 위해 위의 식(5)를 다시 수정하면 아래의 식으로 표현할 수 있습니다.(추가정보이긴 하지만 FPS 알고리즘을 이용하여 구할 수 있으므로 추가적인 annotation을 수행하지 않는 것은 맞지만, 이게 기존 방법론도 동일하기 때문에 장점이라 할 수 있을지는 잘 모르겠습니다..)
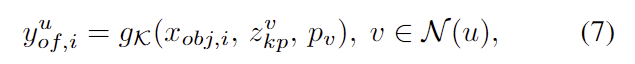
- \mathcal{N}(u): keypoint u와 이웃하는 keypoint 집합
- p_v: keypoint v의 3D 좌표
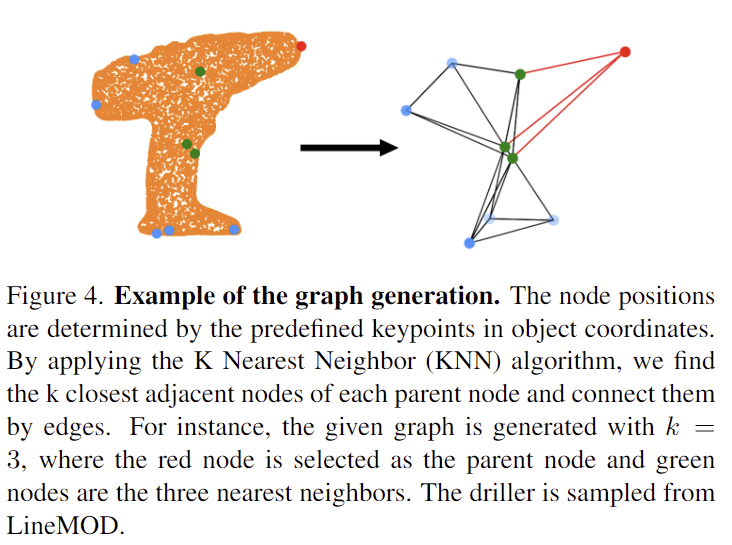
저자들은 keyponits 사이에 포함된 기하학적 정보를 활용하기 위해 MLP를 GNN기반의 decoder를 제안하여 각 keypoint에 대한 그래프를 만듭니다. keypiont는 노드가 되고, 가장 가까운 k개의 노드를 연결하여 그래프를 생성합니다. 위의 Figure 4는 k=3으로 설정하였을 때의 예시이며, 식(7)은 그래프를 따라서 message passing을 하기 위한 2가지 과정으로 나뉩니다.
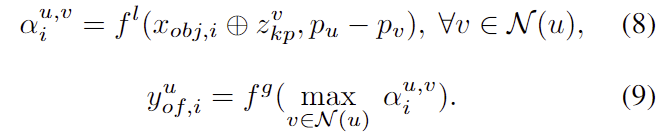
g_{\mathcal{K}}는 f^l 과 f^g 두 개의 하위 네트워크로 구분되며, 모든 edge를 따라 messages \alpha^{u,v}_i 를 업데이트하고, 각 노드 u에 도착하는 messages를 종합하여 해당 노드의 feature를 업데이트하여 keypoint offset y_{of,i}^u 으로 decoding합니다.
Experiments
Dataset
- LineMOD
6D Pose Estimation에서 많이 사용되는 데이터셋으로, 각 장면에 여러 object가 있으나, 하나의 객체의 pose와 mask 정보만이 주어짐.

- MCMS dataset
cross-category level 6D를 평가하기 위한 데이터 셋이 필요하여 저자들이 제안한 합성 데이터 셋으로, 장면 내의 모든 객체에 annotation이 달림.- Toy-MCMS: 실제 이미지를 무작위로 샘플링한 배경에 단일 객체를 포함하도록 구성. (Figure 5 참고)
- PBR-MCMS & Occlusion-MCMS: occlusion과 truncation 검사 기능이 있는 물리엔진 기반의 렌더링 방식을 이용. 각 이미지에 대한 5개의 object가 여러 texturer와 다양한 조명이 있는 장면에 배치한 뒤, 다양한 시점에서 이미지를 포착. (Figure 5 참고)
- PBR-MCMS: occlusion이 일어나지 않은 이미지들로 구성.
- Occlusion-MCMS: 5~20%의 이미지에서 query object가 occlusion.
Evaluation Metrics
6D Pose Estimation에서 많이 사용하는 ADD(-S) 평가 지표를 이용하였습니다. GT pose [R*;t*]와 예측된 pose [R;t]에 대해 아래의 식으로 구합니다.
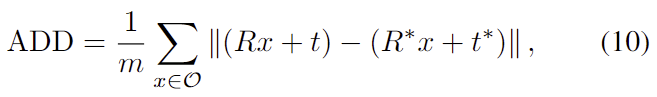
- \mathcal{O} : obejct의 mesh
- m: object mesh에 대한 vertices의 전체 개수
ADD는 GT와 예측 pose로 변환한 3d model의 point 사이의 평균 거리를 측정하는 것으로, 정확히는 ADD-0.1d를 리포팅하였고, 이는 물체의 직경에 10% 미만인 ADD의 비율을 의미합니다.
Implementation and Training Details
각 객체에 대해 9개의 keypoints를 정의하며, 8개는 FPS 알고리즘으로 구하고, 하나는 object의 중심으로 설정합니다. GNN 기반의 keypoint decoder에서 k=8로 설정하고 meta-learning을 위해 segmentation 모듈을 학습하기 위해 Focal Loss, point별 translation offset을 학습하기 위해 L1 Loss를 이용합니다. 두 loss는 각각 2.5와 1.0의 가중치를 주어 합하고, 학습 과정에서 각 iteration마다 18개의 object와 객체당 12개의 이미지를 임의로 샘플링합니다. context images는 2~8개로 무작위로 이용하고 나머지는 target images로 사용합니다.
Training setup.
- LineMOD 데이터의 경우 iron, lamp, phone을 test를 위한 novel object로 설정하고, 나머지 10개의 object를 학습으로 사용합니다. LineMOD는 포함된 객체의 수가 제한적이므로 keypoint offset 예측 모듈만을 평가합니다.
- Toy/PBR-MCMS 데이터의 경우 각각 20개와 19개의 카테고리에 대해 학습을 진행하고, 카테고리별 30개의 object와 object별로 50장의 이미지로 구성합니다. intra-category의 성능을 확인하기 위해 새로운 object(카테고리는 학습함) 30개에 대해 평가하였고, cross-category 성능을 평가하기 위해 5개의 새로운 카테고리를 이용하여 평가를 진행하였습니다.
Results
LineMOD
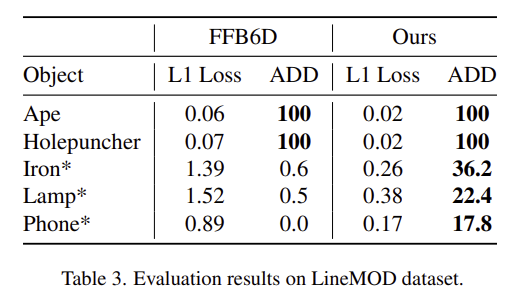
LineMOD를 이용하여 keypoint prediction 모듈의 성능과 일반화 성능을 평가한 결과입니다. keypoint prediction 모듈의 성능은 Ape와 Holepuncher에 대한 결과로 확인할 수 있습니다. 이 실험에서 더 유의미한 부분은 Iron, Lamp, Phone에 대한 실험 결과로, 학습 과정에 포함되지 않은 object이므로, FFB6D는 거의 예측을 재대로 하지 못하는 반면, 해당 논문의 방법론을 적용할 경우 예측이 가능한 것을 확인할 수 있습니다. 이를 통해 저자들이 제안한 방법론의 일반화 성능을 확인할 수 있습니다.
Toy- & PBR-MCMS
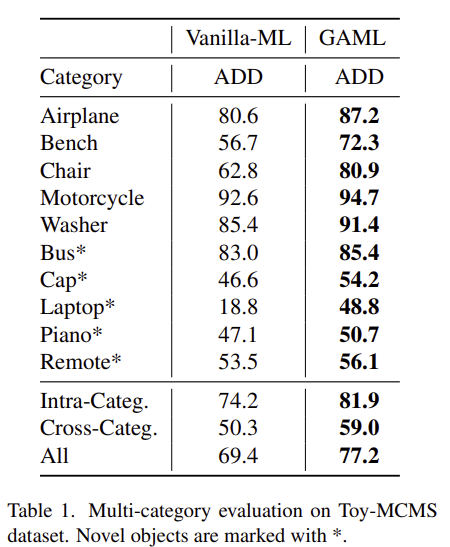
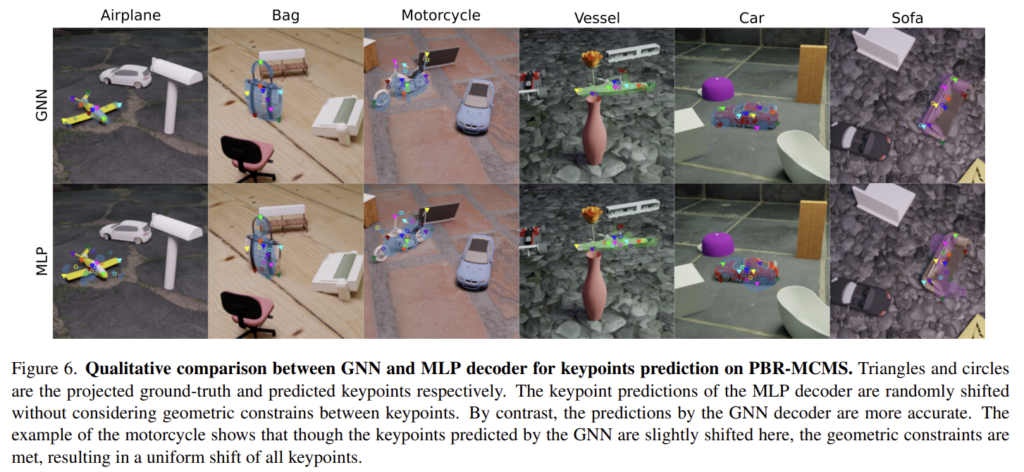
Table 1은 Toy-MCMS에 대한 결과로, GNN decoder를 이용한 GAML과, classic MLP를 이용한 Vanilla ML에 대한 결과가 리포팅 되어있습니다. Figure 6을 통해서 정성적 결과도 확인하실 수 있습니다.
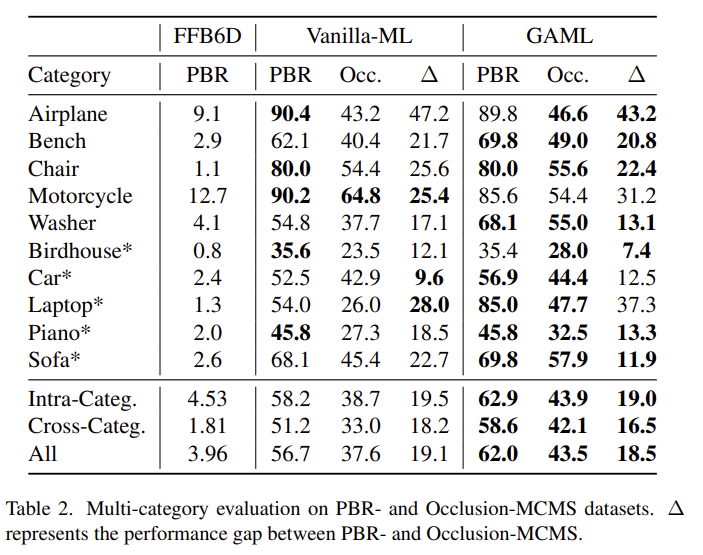
Table 2는 본 논문의 핵심인 meta-leaner와 베이스라인으로 삼은 FFB6D를 비교한 결과로, 새로운 object에 대해 FFB6D의 성능이 매우 나쁜 것을 확인할 수 있습니다. 위의 결과를 통해 저자들이 제안한 방식의 일반화 성능을 다시 한번 확인할 수 있습니다.
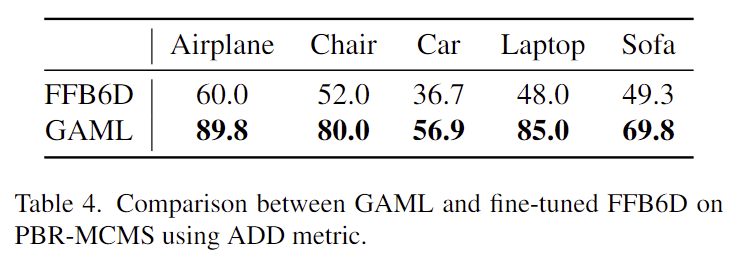
Table 4는 FFB6D는 새로운 객체에 바로 적용하기 어렵기 때문에 보다 공정한 비교를 위해 FFB6D를 PBR 데이터에서 학습한 뒤, 저자들이 이용한 contexts와 동일한 데이터를 이용하여 사전학습된 모델을 미세조정한 결과라 합니다. 위의 결과보다 안정적인 성능을 보이지만 미세조정을 거치면서 이전 object에 대한 성능이 저하될 수 있습니다.(표에 정확한 값이 없지만 기존 방식 자체가 각 object별로 완전히 fitting 시키는 방식이므로 이렇게 이야기하는 게 잘못된 말은 아니라고 생각합니다. 하지만, 실험 결과를 같이 리포팅 해야 더 설득력이 있을 것 같습니다…)
Occlusion-MCMS

Table 2와 Figure 7는 occlusion 및 truncation에 대한 결과를 볼 수 있는 표와 그림입니다. 학습 과정에서는 truncation이나 occlusion이 포함되지 않았으나 객체에 occlusion이 발생하더라도 여전히 일반화 성능을 가지고 있다고 이야기합니다.(해당 논문에서 이야기하는 일반화 성능은 LineMOD에서 새로운 object에 대해 평가한 결과를 기준으로 이야기하는 것 같습니다. 아예 작동하지 않느냐, 그래도 어느정도 작동하느냐를 의미하는 것으로 보입니다.)
Ablation study
Effect of K Neighbors in GNN
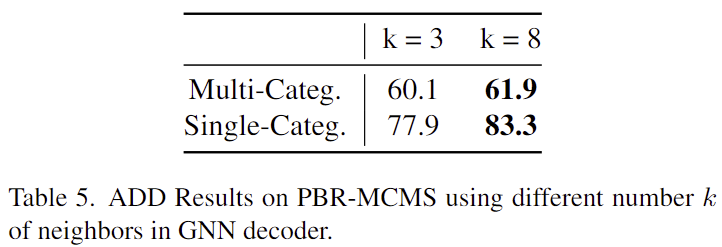
GNN 기반의 keypoint decoder를 구성할 때 k 값에 따른 성능입니다. 모든 keypoint를 이웃으로 사용할 경우(k=8) 더욱 좋은 성능을 보이는 것을 확인할 수 있습니다.
Limitations
저자들은 해당 방법론의 2가지 한계를 언급하였습니다.
- 드문 경우이지만 texture와 모양, 조명에 따른 feature 변동성에 의해 feature ambiguity 문제가 발생한다고 합니다.
두 개의 유사한 객체로 인해 부정확한 segmentation이 발생할 수 있고 이는 아래의 Figure 8-a에서 확인할 수 있습니다. - keypoint 기반의 방식들은 symmetry ambiguity 문제가 발생한다는 것 입니다.
특히 새로운 객체는 대칭 축을 알기 어렵기 때문에 대칭 축 주변의 keypoint 예측이 일치하지 않아 학습이 잘 되지 않을 수 있습니다. (아래의 Figure 8-b에서 확인할 수 있듯 화살표와 동그라미 색이 일치하지 않게 매핑이 되어있는 것을 보실 수 있습니다.)
