이번 리뷰 논문은 3D optical flow ~ scene flow에 관한 논문이며, 포인트 클라우드와 영상 정보를 어떻게 하면 잘 융합하여 사용할지에 대해서 다룬 방법론에 해당합니다. 2021 KITTI Benchmark에서도 1등을 달성한 방법론에 해당합니다.
Intro
연구원분들 대부분 Scene flow에 대해 처음 들어 보셨을 거라고 생각합니다. Scene flow는 영상 내 움직임을 예측하는 optical flow (x, y 축)와 z 축 정보를 가진 두 시점 depth의 range flow가 결합되어져 3차원에서의 움직임을 예측하는 방법론이라고 보시면 됩니다. 해당 태스크는 자율 주행 뿐만이 아니라 로봇 관점에서도 3차원 측면에서의 움직임을 인식하고 더 나아가 움직임을 예측하기 위한 중요한 역학 정보를 제공하는 역할을 합니다. 그렇기에 고도화된 무인화를 수행하기 위해서는 반드시 선행되어야 하는 연구에 해당하죠.
해당 연구는 크게 영상 기반과 포인트 클라우드 기반으로 분류가 가능합니다. 영상 기반은 detach estimation과 joint estimation으로 나눠 집니다. 먼저, detach estimation은 scene flow를 예측하기 위해 구성되는 Depth & camera pose와 2D optical flow를 예측하고 두 정보를 결합하여 scene flow을 예측하는 구성으로 이뤄집니다. 상대적으로 더 나은 성능을 보여주지만, 별도의 네트워크들이 독립적으로 운용되기 때문에 서로 상호보완적으로 연산을 수행하기 어렵다는 단점이 있습니다. joint estimation은 scene flow를 예측하기 위해 필요한 정보들을 한번에 예측하는 방법론에 해당하며, 동시다발적으로 단일 혹은 다중 입력으로부터 여러 도메인의 출력값을 예측하며 각 도메인의 특성을 상호보완적으로 활용하거나 상황에 맞게 변형이 쉽다는 장점이 있습니다. 허나, 입력값과 출력값이 커지기 때문에 모델의 크기가 커지고 예측해야하는 대상들이 많아지기 때문에 성능이 떨어진다는 문제가 있습니다.
포인트 클라우드 기반은 두 시점의 포인트 클라우드로부터 포인트 별로 매칭시켜 얼마나 변화가 되었는지를 예측하는 3D scene flow estimation 기법이 있습니다. ICP를 아시는 분들은 ICP와 동일한 기법이라고 보시면 좋을 것 같아요.
앞에서 설명 드린 내용은 아래의 그림을 참고하시면 이해하시기 편할 것 같습니다.
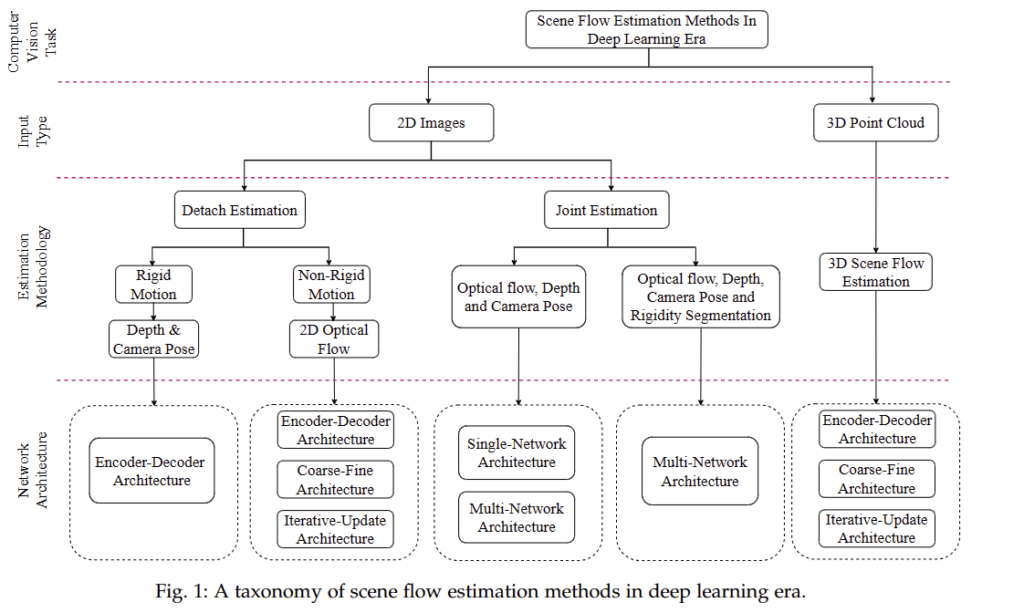
만약에 Scene flow에 깊은 관심이 있으신 분들은 해당 서베이 자료 [1]를 읽어 보시길 추천 드립니다. 위 그림의 출처도 [1]에 해당합니다.
+ 서베이 논문인데 무려 TPAMI임! ㅋㅋ
[1] Xiang, Xuezhi, et al. “Deep Scene Flow Learning: From 2D Images to 3D Point Clouds.” IEEE Transactions on Pattern Analysis and Machine Intelligence (2023).
리뷰 논문은 Image와 Point cloud (~depth)를 입력으로 받아 optical flow와 scene flow를 동시에 예측하는 Joint estimation에 해당합니다. 해당 논문에서 scene flow를 예측하는데 굳이 optical flow를 예측하는 이유에 대해서 의문점을 가질 수 있습니다. 이러한 이유는 관측 물체에 대해서 언급을 해야 합니다. 물체는 크게 차량, 오토바이, 건물 같은 형태가 변하지 않는 rigid와 사람, 동물과 같은 고정되지 않은 동적인 형태를 가진 non-rigid로 구분할 수 있습니다. rigid에 대한 flow는 형태적인 변화가 없기 때문에 기하학적인 관점에서 비교해도 문제가 없습니다. 반면에 non-rigid인 경우에는 물체 형태에 대한 변화가 이뤄지기 때문에 local한 영역 간의 기하학적인 정보를 고려하여 매칭이 어렵다는 문제점이 있습니다. 어느정도 의미론적인 관점에서 매칭을 수행해야하는 단점이 존재하죠. 즉, 포인트 클라우드의 기하학적 정보만을 이용하면 어렵고, 영상의 컨테스트 정보를 활용하여 예측을 수행해야합니다. flow 쪽 태스크에서는 non-rigid/rigid의 특성 때문에 point cloud에서는 rigid에 대해서 주로 다루고 non-rigid를 다룰려면 영상 정보를 활용하는 경향이 있습니다.
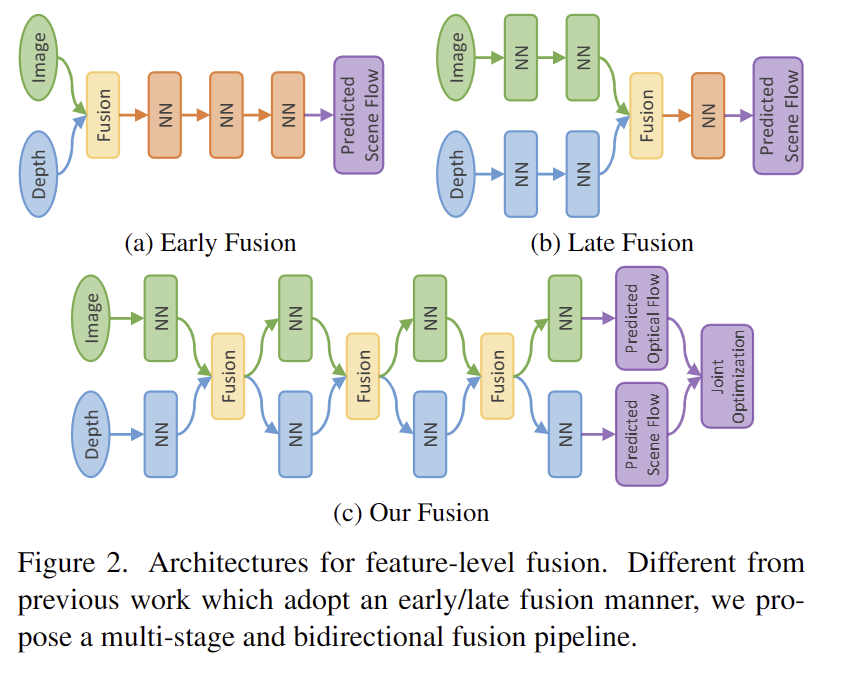
리뷰 논문 이전에도 RGB-Depth를 함께 사용하는 방법을 제안하긴 했습니다. 저자는 이전 방법론들이 두 정보를 융합하는 방법에 대해 문제점을 지적합니다. 가장 먼저 RAFT-3D는 영상과 dense depth map을 결합하여 2D network를 통해 pixel-wise 3d motion을 추정하는 방법을 이용합니다. 해당 방법은 fig 2-(a) early fusion에 속하며, 2D CNN의 초기층에서는 대부분 3D structural information을 생성하기 힘들다는 단점이 존재합니다. DeepLiDARFLow는 image와 image plane에 투영된 LiDAR 특징 정보를 융합하여 사용합니다. 이는 fig 2-(b) late fusion에 해당합니다. 해당 방법은 융합 단계에서 발생한 오류를 수정할 기회가 없으며 해당 에러는 이후 레이어에도 계속 누적되어져 두 모달리티의 정보들이 제대로 활용되지 못한다는 단점이 존재합니다.
정리하면 위 방법론들은 single-stage의 형태를 고수하기 때문에 각 모달리티의 특성을 보완적으로 활용하지 못한다는 단점이 존재했기에, multi-stage and bidi- rectional fusion; fig 2-(c)를 제안한다고 합니다.
두 모달리티를 융합하는 데에 2가지 도전적인 부분이 있다고 합니다. 가장 먼저, 영상 특징은 조밀한 grid 구조를 가지는 반면에 포인트 클라우드는 연속적인 영역에 sparse하게 분포되어 있다는 특징을 가집니다. 이러한 특성으로 인해 두 모달리티의 정보는 1-1 대응이 이뤄진다고 보장하기 힘듭니다. 두번째로 LiDAR 정보는 포인트 밀도가 다양하다는 특성을 가지고 있으며, 대체로 가까울 수 록 밀도가 높은 특성을 가집니다.
저자는 우선 첫번째 문제를 해결하기 위해 학습 가능한 보간 및 샘플링을 수행하는 학습 가능한 융합 방법인 bidirectional camera-LiDAR fusion module (Bi-CLFM)을 제안합니다. 두번째 문제를 해결하기 위해서 inverse depth를 고려하여 비선형적으로 스케일링을 수행하여 포인트의 분포 균형을 맞추는 새로운 transformation operator인 inverse depth scaling (IDS)을 제안합니다.
기존 SOTA 방법론들과 실험적으로 비교한 결과, 더 적은 파라미터로 더 나은 성능을 보이는 결과를 보여줍니다.
Method
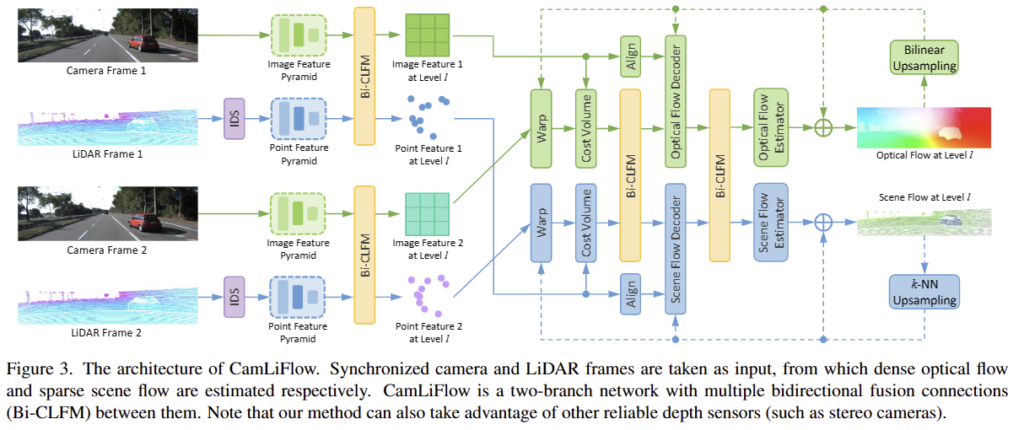
CamLiFlow
해당 모델의 전반적인 파이프라인은 다음과 같습니다. 동기화된 camera와 LiDAR frame 쌍이 주어졌을 때, CamLiFlow는 조밀한 optical flow와 sparse scene flow를 함께 예측합니다. Fig 3과 같이 CamLiFlow는 2D 영상과 포인트 클라우드에 대해 각각 image branch와 point branch라는 두 개의 대칭 브랜치로 구성됩니다. 두 브랜치 모두 coarse-fine 구조를 가진 PWC architecture를 기반으로 구축됩니다. 각 모달리티에서 추출된 특징은 multiple levels and stages에서 bidirectional manner로 융합이 진행되어집니다.
+ PWC architecture는 coarse-fine 구조를 가진 영상 기반의 optical flow 예측 모델입니다. 해당 모델은 coarse-level에서 계산된 flow를 업샘플링하여 fine-level로 매칭을 진행하는 모델로 모델 내부에서 반복적으로 매칭을 보완하기에 두 모달리티의 상호보완적인 정보 교류를 이루기에 적합하다고 판단하여 채택한 것으로 추측하고 있습니다.
Bidirectional Camera-LiDAR Fusion Module
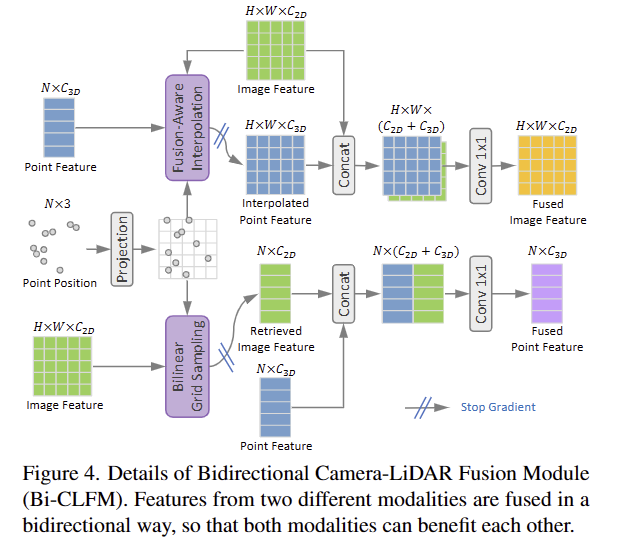
위에서 언급한 바와 같이 camera와 LiDAR 간의 융합은 영상 특징과 포인트 특징의 구조가 일치 하지 않기 때문에 어렵습니다. 이러한 문제를 극복하고자 저자는 Bi-CLFM을 제안합니다.
전반적인 구조는 fig 4와 같으며, Bi-CLFM은 image feature F, point feature G, point potions P를 입력으로 하여 두 모달리티 모두에게 도움이 될 수 있도록 양방향으로 융합되는 방식을 이용합니다. 참고로 특정 모달리티에 오버피팅 되는 것을 방지하기 위해서 특정 위치에서 gadient를 중지하는 방법을 사용합니다.
2D->3D. 먼저, 2D feautre에서 대응되는 지점을 찾기 위해 포인트를 image plane에 사영시킵니다.
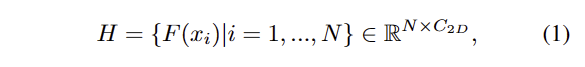
bilinear interpolation(not inter)을 통해 영상 특징과 대응되는 포인트로 정렬을 수행하여 재정의된 영상 특징 H를 3D featute G와 결합하고1×1 conv를 통해 기존 영상 특징의 차원 크기로 차원을 줄입니다.
3D->2D. 여기서도 동일하게 포인트를 image plane에 사영시킵니다. 포인트 클라우드는 희소하기 때문에 조밀한 영상 특징과 일치시키기가 어렵습니다. 저자는 dense image feature와 sparse point feature를 일치하도록 하는 학습가능한 fusion-aware interploation이라는 기법을 제안하여 포인트 특징을 보간하고 두 특징 정보를 결합한 후, 1×1 conv를 통해 기존 포인트 특징의 차원 크기로 줄입니다.
Fusion-Aware Interpolation.
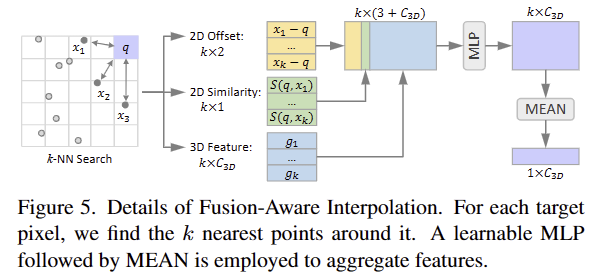
앞서 언급한 조밀한 영상 특징과 희소한 포인트 특징가 일치하지 않는 문제를 해결하기 위해 학습가능한 fusion-aware interploation을 제안하였다고 하였습니다. 해당 보간법은 fig 5와 같으며, dense map의 각 target pixel q에 대해 image plane 위에 투영된 점 중에서 k nearest neighbors 찾습니다. 각 정보에 대한 관계를 내포하기 위해 MLP를 통해 결합 후 Mean으로 aggregate feature를 생성합니다. 이는 다음과 같이 표현됩니다.
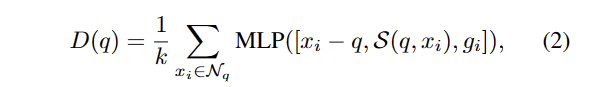
여기서 N_q 는 all the neighborhood points이고, g_i 는 i point의 3D feature, [ ]은 concatenation을 의미합니다. MLP의 입력에는 q와 q의 이웃 정보의 2D similarity measurements S()도 포함됩니다. 이는 아래와 같습니다.
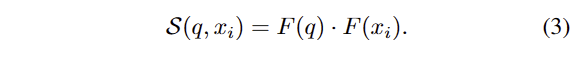
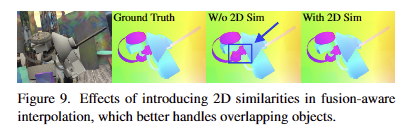
F()는 영상 (2D) 특징 정보에 해당합니다. 2D similarity measurements을 도입하여 밀도가 높은 2D 특징을 사용해 희소한 3D 특징 정보를 밀도 있는 구성이 가능할 뿐더러, 개체가 겹치는 복잡한 장면에서도 강인한 성능을 보여줍니다. (Fig 9 참고)
Multi-stage Fusion Pipeline
해당 섹션에서는 In that section, multi-stage와 Bi-CLFM을 이용한 bidirectional fusion pipeline을 구축합니다. 여기서는 feature extraction, warping, cost volume, flow estimation을 구성하는 PWC를 backbone으로 사용합니다. 각 스테이지에서 두 모달티는 분리된 브랜치에서 modality-sepcific archtecture에서 학습을 진행하고 각 스테이지의 끝에서 Bi-CLFM을 수행하여 각 모달리티의 상호 보완적인 정보 교류를 수행합니다.
Feature Pyramid. 각 모달리티에 대한 feature pyramid를 구성합니다. each level l 에 대해 영상 특징은 residual blocks을 이용하여 2배 다운샘플링을 수행하고 포인트 특징은 동 크기로 furthest point sampling ~ PointConv을 이용하여 다운샘플링을 수행합니다.
Warping. 각 pyramid level l에서의 영상 특징과 포인트 특징은 해당하는 reference frame에 예측된 flow 정보를 통해 warping을 수행합니다. 여기에서는 파라미터 학습이 이뤄지지 않기 때문에 모달리티 간의 교류를 진행하지 않았다고 합니다. (PWC 그대로 사용했다는 거죠)
Cost Volume. 여기서는 referenece frame과 warped target frame 간의 matching costs를 저장합니다. 영상 특징은 [2]을 따라서 포인트 특징은 [3]을 따라서 설계합니다. 여기서는 학습 가능한 파라미터가 존재하기 때문에 두 cost volume에 Bi-CLFMM을 수행합니다.
[2] Deqing Sun, Xiaodong Yang, Ming-Yu Liu, and Jan Kautz. Pwc-net: Cnns for optical flow using pyramid, warping, and cost volume. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 8934–8943, 2018. 2, 3, 4, 6, 12
[3] Wenxuan Wu, Zhiyuan Wang, Zhuwen Li, Wei Liu, and Li Fuxin. Pointpwc-net: A coarse-to-fine network for super- vised and self-supervised scene flow estimation on 3d point clouds. arXiv preprint arXiv:1911.12408, 2019. 2, 3, 4, 5, 6, 12
Flow Estimator. 영상 특징을 이용하는 optical flow는 DenseNet을 따르고 포인트 특징을 이용하는 scene flow는 PointConv로 구성된 [3]을 따릅니다. Flow Estimator 끝에서 두 번째 레이어에서 Bi-CLFM을 한번 더 수행합니다. fig 3에서는 두 번째 레이어를 “flow decoder” 끝단을 “flow estimator”라고 명시해두었습니다.
Inverse Depth Scaling
위에서 언급한 2번째 문제점 처럼 포인트는 밀도가 다양하며 특히 가까운 거리에서 더 밀집한 경향을 보입니다. 저자는 해당 문제를 해결하기 위해서 새로운 transformation operator인 inverse depth scaling (IDS)을 제안합니다. 먼저, ( P_x, P_y, P_z /[latex])와 ( [latex] P^'_x, P^'_y, P^'_z /[latex])를 transformation 전과 후의 포인트 좌표라고 정의합니다. IDS에서는 정의한 삼차원을 inverse depth [latex] 1/P_z 로 나눠줍니다.
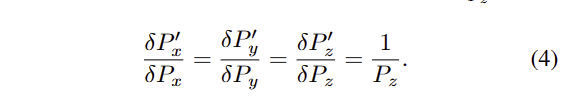
ransformed coordinates ( P^'_x, P^'_y, P^'_z ) 은 수식 4를 이용하여 다음과 같은 수식으로 추론할 수 있습니다.
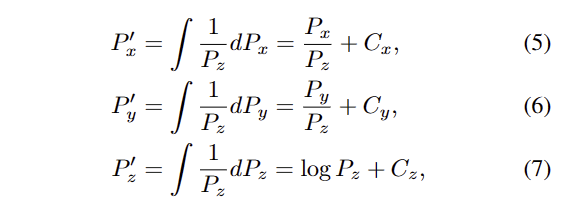
여기서 C_x, C_y 는 0으로 설정되고 C_z 는 깊이가 0으로 표현되는 것을 막기 위해 1로 설정합니다.
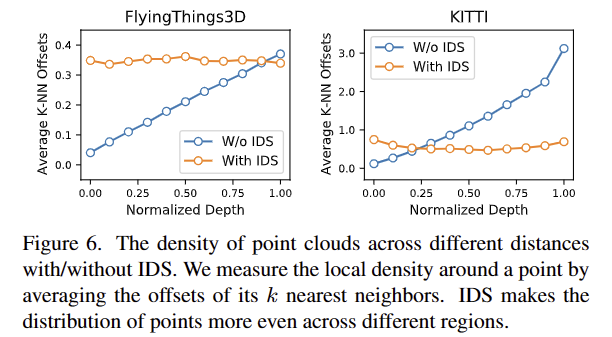
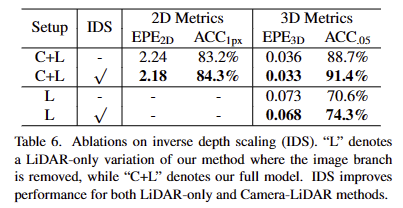
Fig 6에서 보이는 바와 같이 IDS를 수행 여부에 따라 거리에 따른 점의 밀도를 볼 수 있습니다. (fig 6에서는 시각화를 위해 국소적인 영역을 k=16으로 했다고 합니다.) 해당 연구에서는 포인트 클라우드를 모델에 태우기 전에 IDS를 수행했다고 합니다.
+ 즉, 좌표 축을 normalized depth를 했다. 그니깐 먼 거리이면 조밀하게 모이게 만들었다는 의미 정도로 받아 들이시면 될 것 같습니다.
Multi-task Loss
optical flow와 scene flow에 대해 지도 학습 기반으로 학습을 진행합니다.
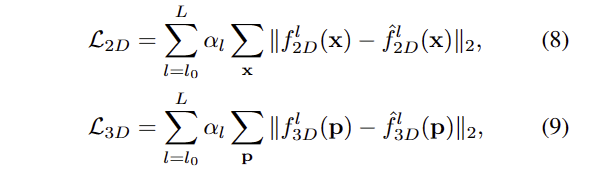
여기서 f_{2D}^l, f_{3D}^l 는 lth level의 optical flow와 scene flow에 해당합니다. 이 에 대한 L2 loss를 수행합니다.
fine-tunning을 수행할 때에는 보다 강하게 지도 정보를 부여하 loss를 사용합니다. 이는 아래와 같습니다.
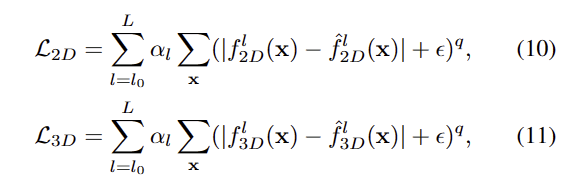
L1 Loss 기반에 q=0.4를 부여하여 이상값에 대한 페널티를 줄이고 \epsilon = 0.01로 설정하였습니다.
전체적인 loss는 다음과 같습니다.
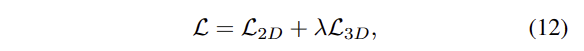
해당 논문에서는 lamda를 1로 설정했다고 합니다.
Experiment
실험은 RGBD 양식인 synthetic dataset인 FlyingThings3D와 real-world datasets인 KITTI Scene Flow (200 training scenes and 200 test scenes)에서 실험을 진행합니다.
FlyingThings3D
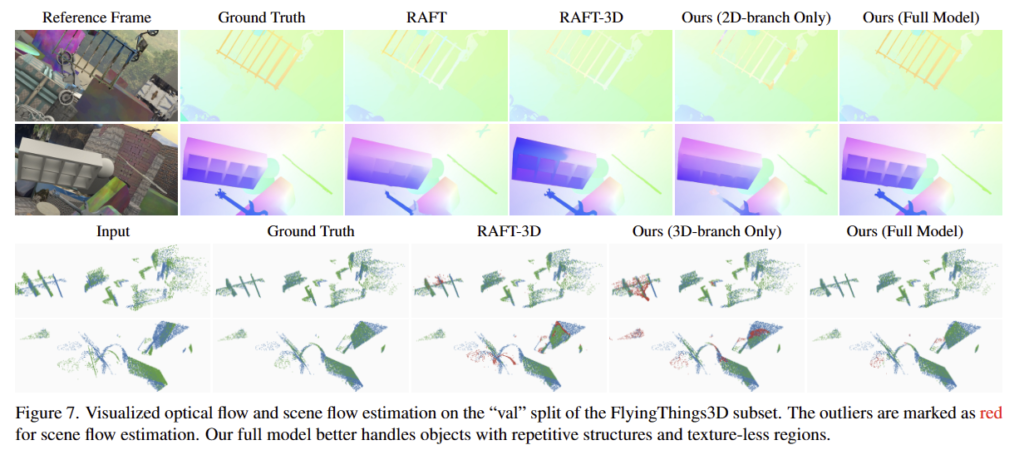
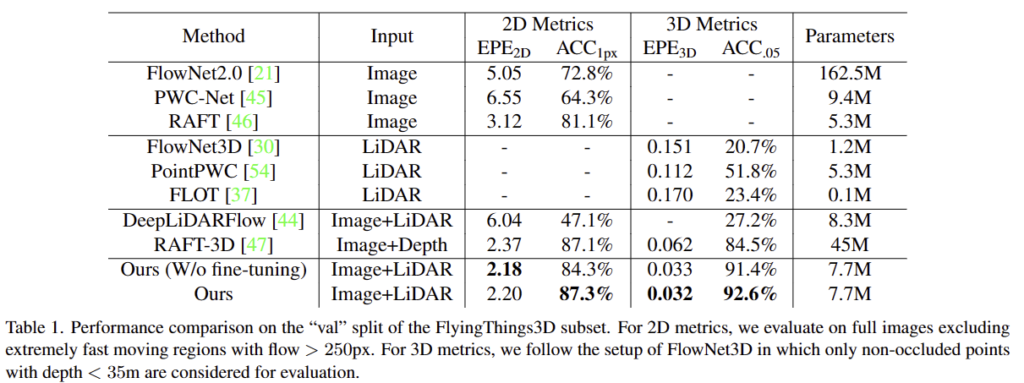
KITTI Scene Flow
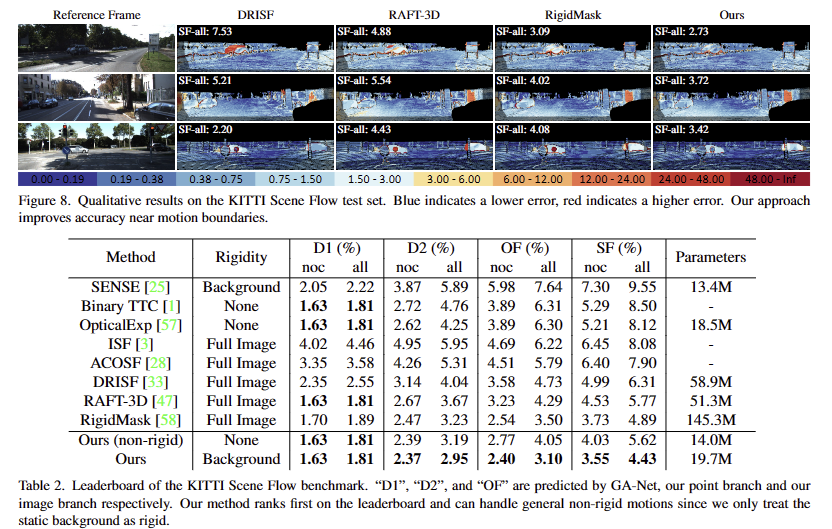
+ Testing에는 깊이 정보가 제공되지 않음. GA-Net에 stereo를 입력하여 < 90m 이하의 깊이 정보를 포인트 클라우드로 사용했다고 함.
+ Refinement of Background Scene Flow. 2D semantic segmenation인 DRNet-Slim를 이용하여 배경을 구분하고 이에 대한 neural-guided RANSAC을 이용해 ego motion을 예측하고 첫 영상의 the ego-motion and the disparity을 이용하여 Refinement of Background Scene Flow함.
++ 정확한 방법을 모르겠습니다.. 하하..
Ablation Study
Unidirectional Fusion vs. Bidirectional Fusion.
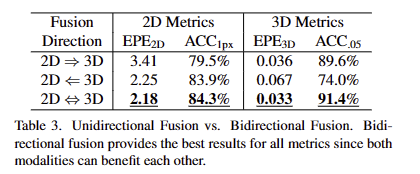
Early/Late-Fusion vs. Multi-Stage Fusion.
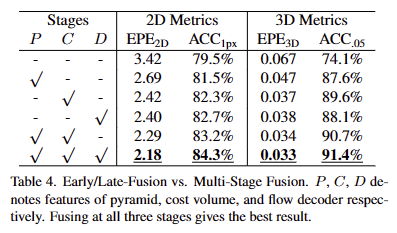
Fusion-Aware Interpolation.
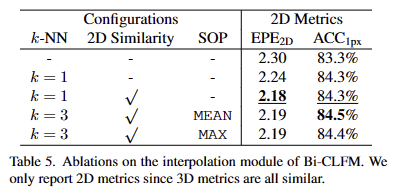
맨 위 행은 빈 위치는 0으로 채워서 보간을 진행한 방법임. 정성적인 결과는 fig 9를 확
+ 해당 부분에 대한 고찰이 있었으면 좋았을텐데 없네요...ㅡㅜ
Inverse Depth Scaling.
Analysis
Timing.
118ms in total with a Tesla V100 GPU

좋은 리뷰 감사합니다.
해당 리뷰는 Scene Flow를 위해 RGBD feature를 잘 융합하는 방식에 대한 연구라고 이해하였습니다.
RGBD(LiDAR) 데이터를 융합하기에는 아래와 같은 2가지 문제가 있고,
(1) 영상은 조밀한 grid, point cloud는 연속적인 영역에 sparse하게 분포되어있으므로 1대1 대응을 보장할 수 없다는 것과
(2)LiDAR 정보는 point 밀도가 다양(가까울수록 밀도 높은 특성..)하다는 것
이를 해결하기 위해 아래의 두가지를 제안한 것으로 이해하였습니다.
(1): bidrectional camera-LiDAR fusion 제안
(2): inverse depth를 이용하여 depth를 비선형적으로 scaling하여 분포 균형을 맞추는 IDS(inverse depth scaling) 제안
그중 Bidirectional Camera-LiDAR Fusion Module에 대한 내용에서 궁금한 점이 있습니다. camera와 LiDAR 데이터를 다루는 2가지 브랜치가 있고, 특정 모달리티에 오버피팅되는 것을 방지하기 위해 특정 위치에 gradient를 중지한다고 하셨는데, 이는 Figure 4에서 Stop Gradient에 해당하는 것인가요?? 각 부분의 gradient를 중지하는 것이 어떻게 오버피팅을 막을 수 있는 것인지 잘 이해가 되지 않아 추가로 설명 부탁드려도 될까요..?
또한, Figure 8의 경우 해당 논문이 motion boundary에서 정확도가 계선되었다고 하는데, 저자들이 제안한 방식이 motion boundary에서 잘 작동하는 이유가 무엇인지 궁금합니다.
감사합니다.
Q. 그중 Bidirectional Camera-LiDAR Fusion Module에 대한 내용에서 궁금한 점이 있습니다. camera와 LiDAR 데이터를 다루는 2가지 브랜치가 있고, 특정 모달리티에 오버피팅되는 것을 방지하기 위해 특정 위치에 gradient를 중지한다고 하셨는데, 이는 Figure 4에서 Stop Gradient에 해당하는 것인가요?? 각 부분의 gradient를 중지하는 것이 어떻게 오버피팅을 막을 수 있는 것인지 잘 이해가 되지 않아 추가로 설명 부탁드려도 될까요..?
A. 넵 맞습니다. LiDAR (point cloud)와 RGB 브랜치에서는 서로의 데이터 표현법에 맞춰서 데이터를 변형하면서 퓨전을 진행합니다. 익히 알듯이 가장 좋은 퓨전 방법은 도메인 특성을 살리되, 공통 특성을 합치는 방식이 가장 좋죠. 이런 철학으로 인해 홈 브랜치는 홈 도메인이 가장 강하기 때문에 어웨이 도메인이 홈 도메인의 특성을 강하게 배울 여지가 있습니다. 그렇기에 어웨이 도메인으로 향하는 gradient는 차단하는 거승로 보입니다.
Q. 또한, Figure 8의 경우 해당 논문이 motion boundary에서 정확도가 계선되었다고 하는데, 저자들이 제안한 방식이 motion boundary에서 잘 작동하는 이유가 무엇인지 궁금합니다.
A. motion boundary를 뭘 의미하는지 이해를 못했어요… 좀 더 자세히 알려주실 수 있으신가요?
안녕하세요 김태주 연구원님 좋은 리뷰 감사합니다.
리뷰를 읽고 제가 이해한 바를 정리해보자면 논문에서 제안하는 CamLiFlow는 scene flow의 예측을 위해 rgb 영상과 point cloud를 사용하는 join estimation 기반의 방법론입니다. rgb 영상과 point를 융합하여 사용하는 것에는 두 가지 문제점이 있는데, 하나는 두 모달리티의 밀도 차이에 의해 일대일 대응이 어렵다는 것입니다. point cloud는 sparse한데 rgb image는 dense한 grid로 이루어졌기 때문입니다. 두 번째로 point cloud는 point의 밀도가 고르지 않다는 것입니다.
이러한 문제를 해결하기 위해 저자들은 Bidirectional Camera-LiDAR Fusion Module과 Multi-stage Fusion을 제안하였으며 결과적으로 Kitti 에서 sota를 달성하였습니다.
리뷰를 읽고 간단한 질문이 있는데요, [그림4]point position과 point feature는 각각 어떤 것을 의미하는지 설명해주실 수 있을까요? [그림3]을 보면 image feature pyramid에서 rgb이미지의 특징을 추출하고, point feature pyramid에서 point feature를 추출한다는 것은 이해했는데point position이라는 것은 어떻게 구하는 건지 궁금합니다.
감사합니다.
Q. 리뷰를 읽고 간단한 질문이 있는데요, [그림4]point position과 point feature는 각각 어떤 것을 의미하는지 설명해주실 수 있을까요? [그림3]을 보면 image feature pyramid에서 rgb이미지의 특징을 추출하고, point feature pyramid에서 point feature를 추출한다는 것은 이해했는데point position이라는 것은 어떻게 구하는 건지 궁금합니다.
A. point position은 point의 {x, y, z} 입니다.