안녕하세요, 이번 주차 X-Review는 22년도 arXiv에 올라온 <Unsupervised Prompt Learning for Vision-Language Models>라는 논문입니다. 해당 논문은 Image Classification 문제를 다루며, 다른 dataset으로의 transfer 시 CLIP의 사전학습 represenation에 기대어 target 데이터셋의 라벨 없어도 vanilla CLIP보다 높은 성능을 달성할 수 있음을 시사하는 논문입니다. 이 과정에서 vanilla CLIP의 represenation에 대한 다양한 실험 결과와 분석을 보여주고 있습니다. 중국의 북경대와 Microsoft Research Asia의 공동 연구입니다.
우선 현재 제가 수행하고 있는 Weakly-supervised Temporal Action Localization(WTAL)은 temporal annotation이 주어지지 않은 채로 비디오 내 action의 localization 및 classification을 수행해야 합니다. 이 때 localization, classification 중 localization은 완전 unsupervised 관점으로 볼 수 있기에, 기존 WTAL 프레임워크에 CLIP을 붙여보려는 현 시점에서 어떤 식으로 접근하면 좋을지 알아보고자 읽게 되었습니다.

그럼 바로 Introduction을 통해 기존 파이프라인에 대해 본 논문이 갖는 차별점을 살펴보겠습니다.
1. Introduction
본 논문은 22년도 4월 arXiv에 게재되었습니다. 당시는 CLIP이 공개된지 1년 가량 된 시점이고, 동시에 ALIGN, FLIP 등의 다양한 거대 Vision-Language(VL) 모델들도 존재하였습니다. 이와 같은 VL 모델의 등장은 기본적인 visual framework를 바꾸게 됩니다. 이는 랩세미나에서도 제가 <Prompt Learning>을 주제로 말씀드렸던 적이 있는데, 기존엔 Image 등의 데이터를 입력받아 특징을 추출한 후 해당 특징을 분류, dense prediction 등 각 task에 알맞게 사용하여 왔습니다. 하지만 CLIP 등 VL 모델이 등장한 후 Visual encoder와 Text encoder, two-tower 형태로 모델이 설계되었고 vision 데이터가 text prompt에 기대어 여러 task를 수행하는 framework들이 많이 연구되고 있습니다.
자세한 CLIP의 설명은 제가 이전에 작성하였던 아래 링크의 X-Review로 대체하고, 본 리뷰에서는 배경지식이 있다고 가정하고 간단하게만 설명하겠습니다.
결국 핵심은 CLIP의 knowledge 내지는 represenation을 transfer하기 위해 기본적으로 prompt가 함께 사용된다는 것입니다. CLIP에서 사용된 가장 기본적인 하나의 prompt 예시는 “a photo of [CLS]”로, 이는 다들 어느정도 익숙하실 것으로 생각됩니다. 이는 그림 1-(a)에서도 확인할 수 있습니다.
하지만 위와 같은 hand-crafted prompt는 데이터셋마다 해당 도메인의 전문 지식을 갖춘 사람이 직접 설계해주어야 한다는 번거로움이 있고, 굉장히 미세한 prompt의 변화만으로도 큰 성능 차이를 불러오기에 최적의 prompt를 찾았다고 단언할 수도 없으며 최선의 prompt를 찾는 과정 자체가 큰 시간적 cost를 수반하게 됩니다. 이러한 단점을 보완하고자 prompt를 학습 기반으로 최적화시키고자 한 방법론이 아래 제가 이전에 작성한 X-Review 논문(CoOp)에 해당합니다. 제가 방금 언급한 문제점들의 근거는 아래 리뷰에서 찾아볼 수 있습니다.
CoOp은 fine-tuning 시 handcrafted prompt 대신 learnable vector를 던져주어 이 vector들이 visual-language feature가 가지고 있는 라벨 pair에 맞게 잘 align되도록 최적화를 수행하는 방식입니다. 적은 양의 sample만으로도 잘 최적화 되었다면, 이젠 inference 시 동일한 prompt를 던져 클래스를 예측할 수 있을 것입니다.
CoOp 이외에도 vanilla CLIP으로부터 더욱 정제된 transfer를 수행하고자 TIP-Adapter, CLIP-Adapter 등의 방법론이 21년도에 제안되었습니다. 위 방법론들이 기본적으로 vanilla CLIP보다는 높은 few-shot 성능을 보여주며 높은 일반성을 갖게된 것은 맞지만, few-, zero-shot 성능을 측정할 target 데이터셋에 대한 라벨이 반드시 존재해야 learnable prompt의 최적화를 진행할 수 있다는 단점이 존재합니다.
저자는 Target 데이터셋에 대한 추가 annoation 필요성을 줄이고, 광범위한 hand-crafted prompt engineering을 피하고자 Unsupervised Prompt Learning(UPL) framework를 제안하게 됩니다.
기본적인 UPL의 아이디어는 다음과 같습니다. 우선 사전학습된 CLIP represenation은 활용할 수 있으니, target 샘플들에 대한 pseudo-label을 생성할 수 있을 것입니다. (참고로 unsupervised setting이 각 샘플이 어떤 클래스에 매칭되는지 알 수 없을뿐, 데이터셋에 존재하는 전체 클래스는 당연히 알고 있는 상태입니다.) 여기까진 약 4억 개라는 대용량 image-text pair로 학습을 마친 CLIP의 표현력을 믿는 것이죠.
Pseudo label만 붙여줘도 이젠 few-shot 성능을 측정하기 위한 fine-tuning을 수행할 수 있게 된것입니다. 이후엔 CoOp에서는 실제 label로 수행했지만, 이와 유사하게 가지고 있는 pseudo label을 이용해 모든 클래스 공통의 learnable prompt를 최적화시켜주게 됩니다. 세세한 방법론들까지도 굉장히 naive하며 다른 논문에서 차용해온 것이 많은데, pseudo labeling 과정에서 vanilla CLIP이 보여주는 특성을 분석한 것들이 볼만한 논문이었습니다.
이제 contribution을 정리하고 방법론과 분석, 실험 결과들을 차례로 알아보겠습니다.
Contribution
- We present an Unsupervised Prompt Learning(UPL) framework to avoid time-consuming prompt engineering and better adapt vision-language models for downstream image recognition task. UPL is the first work to introduce unsupervised learning into prompt learning of vision-language models.
- We thoroughly analyze the characters of CLIP for pseudo-labeling. We propose top-K pseudo-labeling strategy, pseudo label ensemble and prompt representation ensemble to improve transfer performance.
- Our UPL significantly outperforms original CLIP with prompt engineering on ImageNet and other 10 image classification datasets by large margins.
2. Method
2.1 Overview of UPL
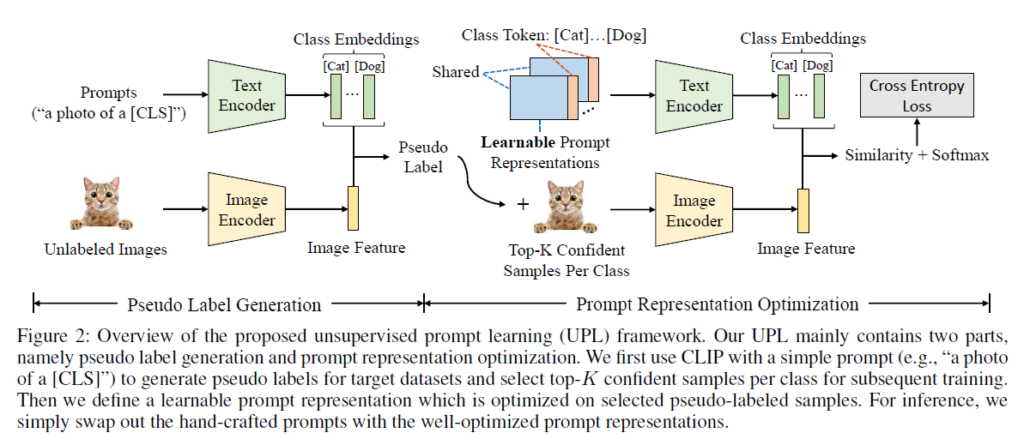
계속해서 이야기하고 있지만 UPL의 목적은 광범위한 prompt engineering을 없애고, target 샘플들에 대한 label 없이 CLIP의 사전학습 표현력을 transfer하는 것입니다. 이를 위해 UPL은 두 가지 모듈로 구성되어 있습니다. 첫 번째는 unlabeled sample들에 대한 pseudo label generation 과정, 두 번째는 pseudo labeled sample들을 이용한 prompt representation optimization 과정입니다.
먼저 pseudo label generation 단계는 사전학습된 CLIP을 통해 inference를 수행하는 과정과 같습니다. CLIP의 사전학습 과정에선 text encoder에 라벨 자체가 들어가지만, inference 시에는 “a photo of [CLS]”와 같은 hand-crafted prompt가 encoding 되었습니다. 같은 맥락으로 target 데이터셋의 클래스들에 대한 inference를 수행하여 예측값을 얻을 수 있게 됩니다.
이렇게 클래스 별로 pseudo label을 얻었다면 믿을만한 샘플들을 이용해 CoOp에서와 같이 context optimization을 수행하면 됩니다. Pseudo label을 얻는 과정인 inference 시에 hand-crafted prompt를 사용했다면 두 번째 단계인 prompt representation optimization 과정에선 text encoder에 넣어줄 문장 중 hand-crafted prompt를 learnable prompt로 대체하고, 앞서 만든 pseudo label을 정답삼아 최적화를 진행하게 됩니다. Semi-supervised learning에서의 self-training 과정과도 유사하다고 볼 수 있겠네요. Learnable prompt가 최적화되었다면 나머지 target 샘플들의 inference(실제 성능 측정) 과정에도 해당 learnable prompt를 사용할 수 있을 것입니다.
위 전체 과정은 그림 2에서 볼 수 있듯 간단하기에 흐름은 이해하셨으리라 생각이 되고, 이제 각 단계별 어떠한 detail들이 있는지 알아보겠습니다.
2.2 Pseudo Label Generation
2.2.1 Inference of CLIP
UPL은 이미 사전학습을 마친 CLIP에서부터 출발합니다. 기존 CLIP이 어떤 과정으로 inference를 수행하는지 간단히 설명하고 넘어가겠습니다. Target 데이터셋에 클래스가 C개 존재한다면, CLIP은 “a photo of a [CLS]”라는 hand-crafted prompt의 “[CLS]” 자리에 C개 클래스를 각각 넣어주고 byte pair encoding(BPE) representation으로 표현해 text를 vectorize 해줍니다. 이후 CLIP text encoder를 통과시켜 클래스 별 embedding \{f_{c}^{text}\}_{c=1}^{C}을 얻을 수 있습니다.
영상 I도 마찬가지로 CLIP image encoder에 통과시켜 f^{image}를 얻을 수 있을 것입니다. CLIP의 사전학습 과정이 f^{image}와 f^{text}를 공통의 embedding space에 투영시키는 것이었으므로 둘 간의 cos 유사도(<\cdot{}, \cdot{}>)를 기준으로 현재 이미지 I가 각 클래스의 text embedding과 response되는 정량적 값 p_{c}를 아래 수식 (1)과 같이 얻을 수 있습니다.
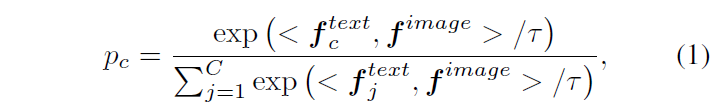
최종 예측값 \hat{y}은 당연히 p_{c}가 가장 큰 클래스에 해당할 것입니다. 모든 target 데이터셋의 샘플들에 대해 수식 (1)의 inference를 수행하면 pseudo label을 생성할 수 있을 것입니다.
2.2.2 Pseudo Label Generation
앞선 단계에서 제가 pseudo label을 만들어내었다고 표현했지만, 이 pseudo label은 어디까지나 noisy한 web 데이터들로 사전학습된 CLIP이 내뱉은 예측이기에 마냥 믿고 모두 사용하기엔 적합하지 않습니다. 따라서 본 단계에서는 모든 샘플들 중 믿을만한, 즉 다음 단계인 prompt represenation optimization 과정에서 사용할 수 있을만한 샘플들을 선정하는 과정이라고 생각하시면 혼동이 덜하실 것입니다.
Self-training 또는 semi-supervised learning에선, labeled sample들로 학습한 후 해당 모델로 나머지 unlabeled sample들에 대한 inference를 수행해 pseudo label을 만들어냅니다. 여기에서도 모든 샘플의 pseudo label로 학습하기보단 믿을만한 샘플들을 선정하는데, 보통은 pseudo label의 confidence score에 대한 thresholding을 진행하여 특정 값 이상의 confidence score를 갖는 샘플만을 추가 학습에 사용하게 됩니다. 하지만 저자들은 thresholding 전략을 CLIP pseudo label에 적용하면 두 가지 문제점이 발생한다고 합니다.
- CLIP의 사전학습에 사용된 데이터들과 target 데이터셋의 도메인이 다른 상황이기에, 1차적으로 생성된 pseudo label은 데이터셋 내 특정 클래스에 편향된 score를 보이게 됩니다. 쉽게 이야기하면 어떤 클래스의 pseudo label은 높은 confidence score의 비율이 높고, 반대로 몇몇 클래스 pseudo label의 confidence score는 전반적으로 모두 낮은 상태가 됩니다. (그림 3)
- Self-training 기법에서 thresholding 전략을 취할 수 있는 이유는 pseudo label의 실제 정확도와 이를 transfer 하였을 때의 성능이 대체적으로 비례하기 때문입니다. 하지만 분석 결과 CLIP의 pseudo label 정확도와 이를 downstream task로 transfer 했을 때의 성능이 큰 상관관계가 없다는 것이 드러나게 됩니다. 즉, 높은 confidence score를 갖는 pseudo label 샘플을 사용한다고 target 데이터셋에 대한 inference 수행 시 높은 성능을 보여주는 것이 아니며, 낮은 confidence score를 갖는 샘플을 사용했을 때 높은 inference 성능을 보여주기도 한다는 것입니다. (그림 4)
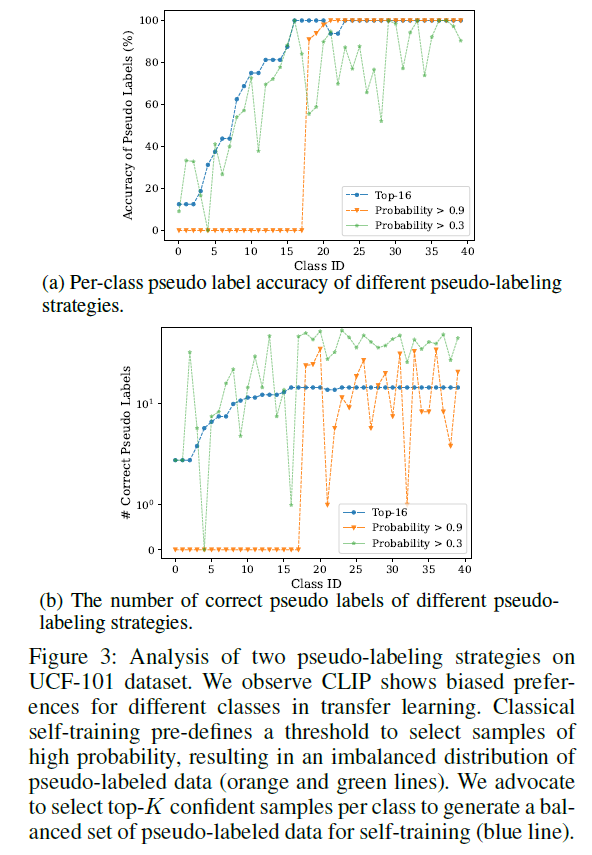
그렇다고 저자들이 pseudo label의 quality를 높이기 위한 별다른 모듈을 제안하는 것은 아니고, thresholding 대신 top-K 샘플링 전략을 취하는 것이 전부입니다. 그림 3을 보시면 위 분석에 대한 근거를 확인할 수 있습니다. 우선 UCF101의 클래스 개수는 101개인데 그림엔 40개 정도로 나와있는 이유가 명확하게 설명되어 있지는 않지만, 일단 저자가 이야기하려는 바를 살펴보겠습니다.
그림 3-(a)는 pseudo-labeling 전략(top-16, 0.9 thresholding, 0.3 thresholding)별 pseudo label의 정확도, 그림 3-(b)는 실제 라벨과 동일한 pseudo label의 개수를 보여주고 있습니다. 그림 3-(a)에서 0.9 threshodling을 하는 경우 앞쪽 클래스(낮은 class ID)들의 pseudo label은 거의 0%에 가까운 정확도를 보이고, 뒤쪽 클래스들은 거의 100%에 가까운 정확도를 보여주며 CLIP의 사전학습 표현력이 UCF101 데이터셋 클래스들에 대해서는 편향된 preference를 보여주는 것을 알 수 있습니다. 또한 0.3 thresholding 하는 경우 0.9 thresholding에 비해 정확도의 편향성은 좀 덜하지만 그림 3-(b)에서 알 수 있듯 정확한 샘플의 절대적 개수는 여전히 클래스 별로 큰 편차를 보이는 것을 알 수 있습니다. 이는 양질의 sample 관점에서는 class imbalance를 불러올 수 있겠죠. 그리고 무엇보다 0.3 이상의 score를 가지는 sample들이 모두 높은 quality를 보장해준다고 보기에는 어렵습니다.
사실 0.9나 0.3이 위와 같은 경향성을 보인다면 중간 지점인 0.7, 0.5 등으로 thresholding 하는 경우의 분석 결과도 보여주었으면 좋았을텐데, 이에 대한 설명은 따로 하고 있지 않습니다. 아마 비슷한 경향이 유지되어 그런듯 하고, 어느정도 완화되더라도 top-K 방식보다는 앞서 언급한 문제점들이 두드러질 것으로 예상됩니다.
따라서 저자는 파란색 선에 해당하는 top-K 전략을 취하는데 이는 상대적으로 클래스 별 pseudo label 정확도 편향이 덜하며 클래스 별 고정된 K개의 샘플만을 가져오기에 정확한 샘플의 비율도 클래스 간 편차가 덜한 것을 볼 수 있습니다. 저자들은 실험적으로 K=16을 사용했다고 합니다.
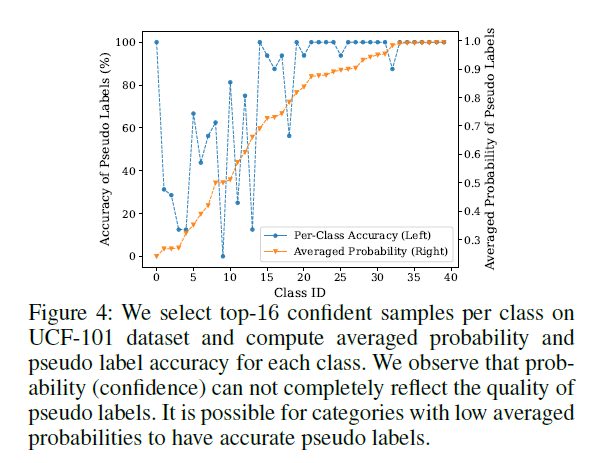
이어서 위 그림 4를 통해 top-16개 샘플들의 pseudo label이, confidence score가 높다고 정확한 것은 아니며 confidence score가 낮다고 부정확한 것은 아니라는 결과를 보여줍니다. 이는 top-K 방식이 앞서 이야기한 pseudo label의 정확도와 confidence score 상관관계를 높여줄 수 있다고 주장하기보단, CLIP의 pseudo label 자체가 그림 4와 같은 문제점을 보여주니, 적어도 그림 3에서 thresholding 방식이 보여주는 문제점을 보완할 수 있는 top-K sampling 방식을 취하자는 의도로 생각됩니다.
2.2.3 Pseudo Label Ensemble
아직 제가 본 방법론이 어떠한 CLIP backbone을 사용하는지 말씀드린 적이 없는데, CLIP은 실제로 ResNet-50, ResNet-101, ResNet-50×4, ResNet-50×16, ResNet-50×64, ViT-B/32, ViT-B/16, ViT-L/14 등 굉장히 많은 사전학습 backbone(vision encoder)을 제공합니다. 이 때 저자들은 backbone에 따라 target 데이터셋에 대한 pseudo label 정확도가 다양해진다는 점을 발견합니다.
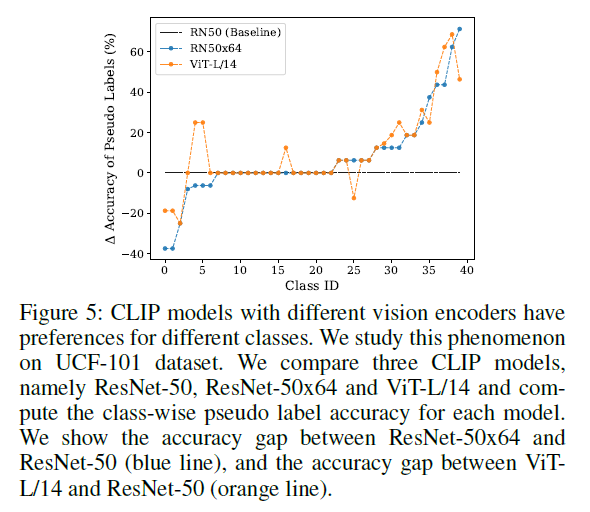
마찬가지로 UCF101 데이터셋에 대해, 그림 5는 RN50이 예측한 클래스 별 pseudo label 정확도를 기준으로 하였을 때 RN50x64와 ViT-L/14 각각의 예측 pseudo label 정확도 편차를 나타내고 있습니다. 대체적으로는 유사한 경향성을 보인다고 생각이 들지만, 명백히 모델에 따라 클래스 별 정확도의 편차가 존재하는 것은 사실입니다.
따라서 저자들은 하나의 backbone이 만들어 낸 pseudo label에 대해 top-K sampling을 취하는 대신, 총 M개의 backbone으로 수식 (1)을 적용해 m번째 backbone에 대한 confidence score p_{i}^{m}을 각각 만들고, 이를 평균낸 \bar{p}_{i} = \Sigma{}_{m=1}^{M} p_{i}^{m}/M 값을 top-K sampling에 사용하게 됩니다.
여기까지 수행하면 이제 unsupervised 기반의 prompt represenation optimization을 수행할 준비가 완료된 것입니다.
2.3 Prompt Represenation Optimization
Vanilla CLIP은 ImageNet 데이터셋에 대한 inference를 수행할 때 “a photo of a [CLS]”를 포함하는 80개의 다양한 hand-crafted prompt를 사용하였습니다. 하지만 Introduction에서도 언급하였듯 hand-crafted prompt의 작은 차이만으로도 큰 성능 차이가 발생하며 도메인 전문 지식을 요구한다는 점에서 CoOp은 학습 기반의 prompt 최적화 방식을 제안하였었습니다. 본 방법론도 여기서부터는 CoOp과 동일하게 앞서 얻은 클래스 별 top-K 샘플들로 context optimization을 수행하지만, CoOp은 supervised 기반 방법론이고 UPL은 target 데이터셋에 대한 라벨이 필요없다는 것이 가장 큰 차이점입니다.
2.3.1 Learnable Prompt Representation
먼저 총 길이 L을 갖는 learnable vector V \in{} \mathbb{R}^{D \times{} L}을 선언해줍니다. 이는 평균 0, 표준편차 0.02를 갖는 gaussian 분포로 랜덤 초기화됩니다. 보통의 learnable prompt 방법론들이 평균 0, 표준편차 0.01, 0.02 등의 분포로 초기화해주는 듯 하네요. D의 경우 CLIP text embedding의 차원으로 ViT는 512, RN50의 경우 1024 등등으로 backbone마다 사전에 정의되어 있는 값입니다. L은 prompt의 단어 개수입니다. “a photo of a [CLS]”의 경우 “[CLS]”를 제외하고 4개 단어, 이를 BPE로 encoding하는 경우 일반적으로 4보다는 커지게 되는데, learnable prompt 관련 기존 논문들이 16을 일반적으로 사용하기에 저자도 L=16으로 설정해주었다고 합니다. 물론 L=32로 사용하는 방법론들도 많습니다.
이제 총 C개 클래스에 대한 text embedding w_{c} (1<c\le{}C)을 만들고 (여긴 아직 CLIP encoder와는 무관합니다), 아래 수식 (3)과 같이 V뒤에 concat시켜 V_{c} \in{} \mathbb{R}^{D \times{} (L+1)}를 만들어줍니다. 실제로 클래스마다 V가 다른 것은 아니고, V는 하나의 단일 벡터이며 학습할 때마다 C개로 repeat되어 붙는다고 생각하시면 됩니다. 이전에 작성했던 리뷰인 CoOp에서의 Unified Context 방식이라고 볼 수 있습니다.
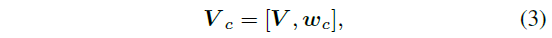
이후엔 CLIP text encoder g(\cdot{})에 \{V_{c}\}_{c=1}^{C}를 태워 text embedding을 만들고, 앞서 얻은 top-K개의 샘플 영상들을 CLIP image encoder에 태워 f^{image}를 만들 수 있습니다. 이젠 CLIP의 학습 과정과 동일하게 아래 수식 (4)를 적용할 수 있습니다.
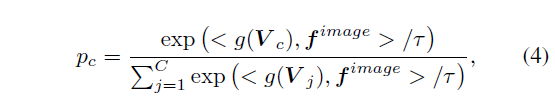
이제는 pseudo label이 있으니 p_{c}를 Cross Entropy Loss로 학습시킬 수 있겠죠. 이 때 중요한 것은 CLIP의 image, text encoder는 freeze 된 상태이며 learnable prompt V로만 gradient가 흐른다는 점입니다.
이렇게 클래스 별 top-K개 샘플로 prompt represenation이 잘 학습되었다면 Inference 단계에선 기존의 hand-crafted prompt 대신 최적화된 prompt V_{c}를 CLIP에 던져 클래스 별 유사도를 구할 수 있을 것입니다.
2.3.2 Prompt Represenation Ensemble
CLIP 논문에서도 아까 말씀드렸듯 ImageNet의 inference를 위해 80개의 hand-crafted prompt를 사용합니다. 위와 유사하게 본 방법론에서도 여러 개의 prompt를 ensemble하는 방식을 사용합니다. 평균 0, 표준편차 0.02에 해당하는 가우시안 분포의 learnable prompt N개를 초기화하고 독립적으로 최적화해줍니다. 사실 상 V_{c} \in{} \mathbb{R}^{D \times{} (L+1)}가 아닌 V_{c} \in{} \mathbb{R}^{N \times{} D \times{} (L+1)}가 되는 것입니다. N개의 prompt 각각에 대해 수식 (4)에 따라 확률을 구하고 평균내어 최종 예측을 수행합니다.
방법론 설명이 길었지만 기본 배경지식이 있었다면 쉽게 읽으셨을 것으로 생각됩니다. 이제 실험 부분으로 넘어가겠습니다.
3. Experiment
3.1 Implementation Details
3.1.1 Vision-Language Models
UPL의 baseline backbone은 ResNet-50입니다. 단일 ResNet-50으로 위 UPL의 프레임워크를 수행하면 UPL로 표기합니다. 하지만 위 그림 5에서 이야기했듯 vision encoder에 따라 클래스 별 preference가 다르기 때문에, ResNet-101, ResNet-50×4, ResNet-50×16, ResNet-50×64, ViT-B/32, ViT-B/16, ViT-L/14로부터 모두 image feature를 추출하고 confidence score를 평균 내어 pseudo label을 만들어 사용하는 방식은 \text{UPL}^{*}이라 칭합니다.
3.1.2 Datasets
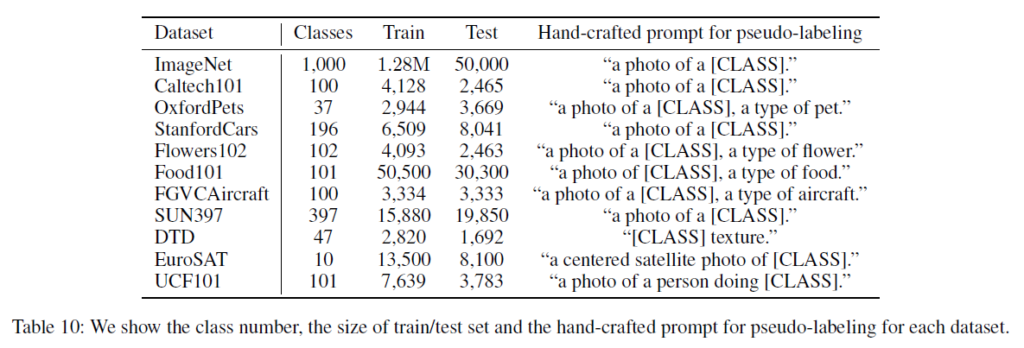
CLIP 논문과 동일한 11개의 데이터셋을 사용했고, 각 데이터셋의 특성은 위 표 10과 같습니다.
3.2 Main Results
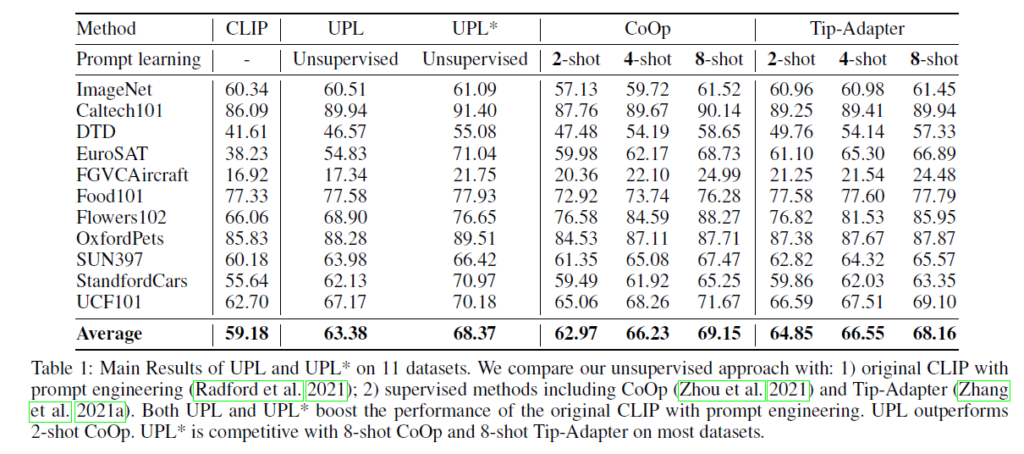
표 1은 11개 데이터셋에 대한 Vanilla CLIP의 zero-shot 성능, UPL과 \text{UPL}^{*} 성능, supervised 기반의 learnable prompt optimization을 수행하는 CoOp과 Tip-Adapter의 few-shot 성능을 보여줍니다. 우선 target 데이터셋에 대한 라벨이 전혀 없음에도 vanilla CLIP의 zero-shot setting보다 훨씬 더 향상된 성능을 보여주고 있습니다.
그리고 여러 backbone으로부터 얻은 score를 평균 내어 pseudo label을 만드는 \text{UPL}^{*}의 경우 생각했던 것보다 굉장히 큰 성능 향상을 불러오는 것을 알 수 있습니다. 물론 여러 backbone으로부터 image feature를 추출해야하는 부담은 있을 것이지만, 라벨이 없는 상황에서 추가되는 연산량과 성능 향상 간 trade-off를 비교했을 때 나름 합리적이라는 판단이 듭니다.
Few-shot에 대해 간단히 설명드리자면, 데이터셋 내 모든 클래스에 대해 2개 샘플씩 fine-tuning에 사용했다면 2-shot, 8개 샘플씩 fine-tuning에 사용했다면 8-shot에 해당합니다. 더 많은 샘플을 볼수록 성능이 높아질 것입니다. UPL이 top-16개의 샘플을 prompt representation optimization에 사용했기에, 비교를 위해 굳이 이름을 붙이자면 unsupervised 16-shot으로 볼 수 있습니다. \text{UPL}^{*}의 성능은 CoOp의 Tip-Adapter의 8-shot 성능과 견줄만하거나 앞서게 되는데, 라벨 없이 일부 데이터 양을 늘려 위와 같은 성능을 보여주는 것이 큰 contribution이었다고 생각합니다.
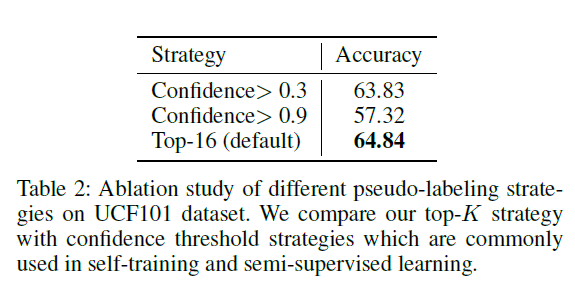
표 2는 pseudo label sampling 전략에 따른 정확도 성능입니다. 0.9 thresholding 기준으로 샘플링 시 class imbalance를 불러오며, 0.3 thresholding을 하는 경우 noisy한 낮은 quality의 샘플들도 학습에 사용됩니다. 반면 top-K sampling의 경우 class imbalance 문제를 완화하는 동시에 꽤 정확한 pseudo label을 제공함으로써 안정적 학습을 도모하여 가장 높은 성능을 보여주고 있습니다.
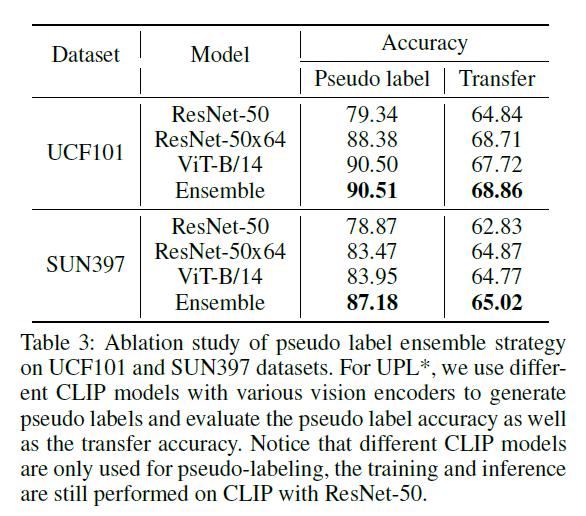
표 3은 데이터셋에 따라 backbone 별 pseudo label 정확도 및 inference 시 성능을 보여주고 있습니다. 우선 pseudo label의 정확도와 실제 transfer 시 정확도가 완전한 상관관계를 가지고 있지 않다는 것을 알 수 있습니다. 또한 backbone에 따라 성능의 경향성이 어느정도 보이긴 하지만 각 backbone으로 얻을 수 있는 확률을 ensemble하여 pseudo label을 만드는 \text{UPL}^{*}이 언제나 성능 향상을 불러오는 것을 확인할 수 있었습니다. 더 큰 backbone도 사용하였다고 밝혔는데, 이들에 대한 성능이 없어 아쉽습니다.
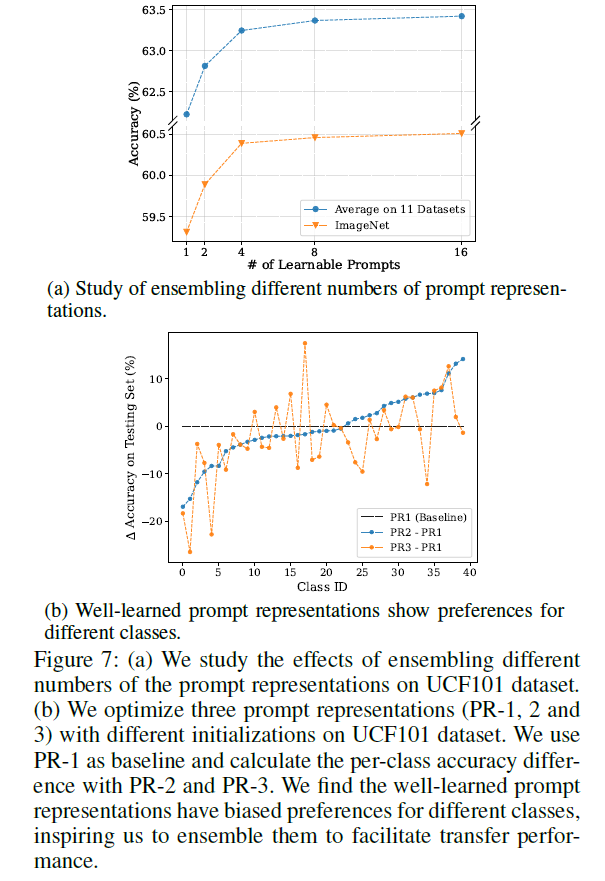
그림 7은 위 2.3.2에서 설명한 prompt ensemble 기법의 분석 결과입니다. 그림 7-(a)는 여러 개의 prompt를 최적화시키고 ensemble하는 경우 성능이 계속 오르지만 N=16에서 어느정도 수렴하는 것을 볼 수 있습니다. 그리고 그림 7-(b)는 prompt N개 중 잘 학습된 3개의 inference 정확도 편차를 나타낸 것입니다. 3개의 prompt는 모두 유사하게 초기화되었지만 PR1을 기준으로 PR2, PR3는 각각 클래스 별 큰 정확도 편차를 보여주기에 안정적인 성능을 위해 여러 prompt의 ensemble이 반드시 필요하다는 점을 보여줍니다.
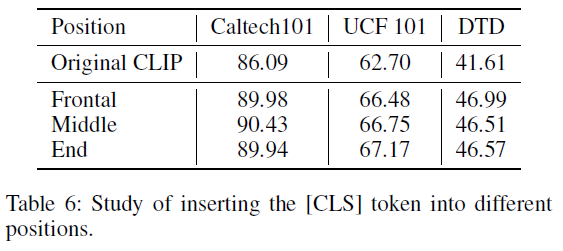
표 6은 그리 중요한 실험은 아니지만 혹시 궁금해하시는 분들이 계실까봐 담았습니다. 수식 (3)에 따르면 CLIP text encoder에 들어가는 문장 가장 마지막에 class embedding이 들어가는데, 이에 대한 데이터셋 별 성능입니다. Class embedding의 위치에 따라 성능이 크게 변화하지 않는다는 점을 통해, 저자는 UPL이 class embedding 위치에 관계 없이 다양한 영상에 강인한 learnable prompt를 만들어낸다고 주장합니다.
4. Conclusion
해당 논문은 방법론에 집중하기보다, CLIP을 이용해 pseudo label을 만들어내고 이를 transfer에 사용하는 과정에서 CLIP의 표현력이 어떤 특성을 가지며 무엇을 조심해야하는지, 어떠한 시각으로 분석을 수행해야하는지 알게 해준 논문입니다. 본 논문이 AAAI format으로 작성되어있지만 아직 arXiv에 게재되어있고, 그럼에도 60이라는 꽤 높은 인용수를 보여주고 있습니다. 논문의 실험 및 분석을 읽을수록 왜 아직 arXiv에 게재되어 있는지와 동시에 왜 꽤 높은 인용수를 가지고 있는지 알 수 있었던 논문입니다…
이상으로 리뷰 마치겠습니다. 감사합니다.
안녕하세요. 김현우 연구원님.
좋은 리뷰 감사합니다. CLIP에서 pseudo label을 만들고 다시 learnable prompt를 만드는 방식이 신선하네요.
특히 표1에서, 원래 CLIP에서는 좋지 않은 성능을 보이던 EuroSAT의 성능 향상 폭이 아주 큰 것이 인상적인데요. 이 부분은 CLIP 원저자들은 위성 사진류의 데이터의 부족을 원인으로 꼽았는데, Prompt를 통해 개선이 되는 것을 보면 그렇지 않을 수도 있겠습니다. 혹시 저자들이 이러한 부분에 대해서는 분석한 것이 있나요?
감사합니다!
안녕하세요. 좋은 리뷰 감사합니다.
제가 이해한 바를 작성하면, pseudo label을 clip inference를 통해서 만들고(이 때는 hand-crafted prompt를 이용) 클래스 별로 label을 얻으면 context optimization을 수행(이때는 learnable prompt사용) 이렇게 이해하였습니다.
여기서 class별 label을 얻는다는 것이 a photo of a [CLS]라는 prompt에서 [CLS] 자리에 모든 클래스를 하나씩 넣은 다음에 클래스 개수 만큼의 text feature를 얻은 다음 이를 image featgure와 결합하여 클래스 개수 만큼의 label을 얻는다고 생각하였는데 제가 이해한 바가 맞을까요? 그런 다음에 top k sampling을 통해서 label을 사용하는 것으로 이해하였습니다.
감사합니다.