안녕하세요. 열 여섯 번째 X-Review입니다. 이번 논문은 NIPS 2018에 게재된Poison Frogs! Targeted Clean-Label Poisoning Attacks on Neural Networks로, 딥러닝 모델에 backdoor 공격을 하는 논문입니다. 바로 시작하도록 하겠습니다.
머신러닝 분야에는 Data poisoning이라고 하는 공격 기법이 존재합니다. Data poisoning이란 공격하는 사람이 학습 데이터셋에 감염된 데이터셋을 추가하여 테스트 시점에서 모델의 동작을 조작하는 것입니다. 다시 말하자면, 공격자가 감염시킨 데이터를 가지고 학습을 하게 되면 실제로 모델의 사용될 때 공격자가 의도한 결과를 내도록 하는 데이터를 감염시키는 공격이라고 할 수 있겠습니다.
본 논문에서는 neural 네트워크에 대한 poisoning 공격을 살펴보고 있습니다. 본 논문에서 제안된 공격은 “clean-label” 방식을 사용하는데, “clean-label”이란 공격하는 사람이 학습 데이터의 label을 건드리지 않더라도 공격을 수행할 수 있는 방식입니다. label이 적절히 붙어 있다고 하여 clean label이라고 하는 것이죠.
또, 기존의 neural network의 공격들은 주로 classifier의 성능을 전반적으로 하락하도록 하는 것이 목적이었다면 본 논문에서 제안된 공격은 특정한 test instance에 대한 분류기의 행동(?)만을 조절하는 “targeted attack” 이라는 점이 특징입니다.
예를 들어서, 공격자가 라벨링이 잘 되어 있는 하나의 무해한 이미지(아무 문제 없어 보이는)를 학습 데이터셋에 추가하는 것만으로도 공격을 수행할 수 있겠습니다. 공격자는 라벨링 과정을 제어할 필요가 없기 때문에 poison 데이터를 웹에 남겨두고, 누군가 크롤링하여 학습 데이터로 사용하는 것을 기다리기만 하면 공격을 할 수 있게 되겠죠.
본 논문은 clean-label attack, targeted attack 방식에 대해 다룬 논문입니다.
1. Introduction
전부터 DNN은 Adversarial Attack에 매우 취약하다는 사실이 알려져 있습니다. Adversarial Attack을 할 때 사용되는 Adversarial examples은 DNN이 잘못된 결과를 도출하도록 공격자가 조작한 데이터들을 의미하며 이들은 겉으로 보기에는 아무런 문제가 없는 것처럼 보입니다.
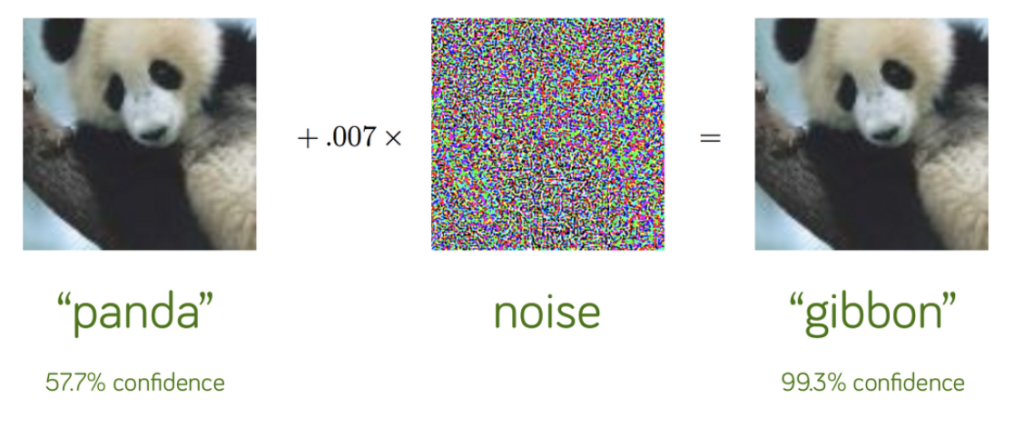
예를 들어, 57.7%로 판다를 분류하는 분류기가 있다고 합시다. 여기 원본 판다 이미지에 특정 노이즈를 합성하여 우측과 같은 눈으로 보기에는 아무런 차이가 없는 판다의 이미지를 분류하도록 하면, 99.3%로 Gibbon이라는 동물로 분류를 하는 것을 볼 수 있습니다.
이런 **Adversarial Attack은 Evasion Attack (회피 공격)**이라고 볼 수 있는데, 이 회피 공격은 공격자가 학습할 때는 전혀 관여하지 않고 오직 테스트를 할 때만 관여한다고 하여 붙여진 명칭입니다. 하지만 이런 공격은 공격자가 테스트 데이터를 제어할 수 없는 상황에서는 공격을 할 수 없습니다.
그렇기에 본 논문에서 소개하는 Attack 기법은 poison instance를 학습할 때 사용하도록 하여 모델의 성능을 조작하는 것을 목표로합니다. 특히 어떠한 특정 test instance에 대한 분류기의 동작을 조작하는 것을 목표로 하는데, 이 기법은 라벨링 과정에 관여를 전혀 할 필요가 없는 clean label 공격이기 때문에 모델을 학습하는 사람의 입장에서는 겉으로 보기에 poison 학습 데이터가 올바르게 라벨링 된 것처럼 보이게 됩니다. 그렇기에 이 공격은 탐지하기 어려울 뿐만 아니라 공격하는 사람이 데이터를 수집하고 라벨링 하는 과정에 내부적으로 접근하지 않고도 공격에 성공할 수 있다는 장점이 있죠.
1.1 Related work
고전적인 Poison Attack은 특정한 target instance를 표적으로 삼는게 아니라 무차별적으로 테스트 정확도를 떨어뜨리도록 하였기 때문에 쉽게 감지가 가능하였습니다. 2017년부터 DNN에 대한 poison attack 관련 연구가 등장하기 시작했는데, 한 [Steinhardt et al. 2017]에서는 단 3%의 학습 데이터셋을 poison dataset으로 바꾸기만 하더라도 11%의 성능 하락을 이끌어 냈다는 결과도 보였습니다.
하지만 이보다 더 위험한 공격 방식은 특정 test instance를 표적으로 삼는 것이라고 합니다. 본 논문이 등장하기 전까지만 해도 특정 test instance를 표적으로 삼는 공격 방식은 evasion attack과 동일한 단점을 가지고 있었는데, 이는 잘못된 prediction을 이끌어 내기 위해서는 test instance를 수정해야 한다(중독시켜야 한다)는 점입니다. 또, 대부분의 연구에서는 공격하는 사람이 학습 데이터셋의 라벨링 과정에도 개입할 수 있어야 한다는 전제가 들어가기도 하였죠. 저자는 이러한 조건들은 real-world에서는 적합하지 않다고 보았습니다.
그렇기에 저자들이 제안한 방식은 라벨링 과정에도 개입하지 않아도 공격이 가능하기에 상당히 현실적인 공격 방식이라고 말합니다. 이러한 방식과 유사하게 공격을 하는 논문[Suciu et al. 2018]이 있기는 한데, 이 논문에서는 학습 데이터의 mini batch중에 적어도 12.5%는 poison data로 채워야 공격이 가능하기 때문에 상당히 비현실적이라고 할 수 있습니다. 반면에 본 논문에서 제안한 공격 기법은 이보다 훨씬 적은 poison data(0.1% 미만)으로도 공격이 가능하다고 하네요.
1.2 Contributions
정리하자면 본 연구는 공격자가 추가한 학습 데이터셋에 공격하는 사람이 악의적으로 라벨을 붙이는 것이 아니라, clean한 label을 붙어도 공격이 가능한 clean-label 공격에 대한 연구입니다.
이 방식은 공격하는 사람이 학습 데이터에 대한 어떠한 지식은 없지만, 모델과 그 parameter에 대한 지식이 있어야 한다는 가정이 붙습니다. 이런 가정은 전이 학습 상황에서 사용될 수 있을텐데, ResNet과 같은 자주 쓰이는 pretrained network의 feature extractor가 존재하고 보통 전이 학습 때는 사전학습된 모델의 앞쪽 layer들을 freeze시켜놓고 뒷단의 fc layer만 추가적으로 학습 하는 경우가 많기 때문에 공격자가 모델과 그 파라미터를 알아야 한다는 가정은 합리적인 가정이라고 볼 수 있다고 합니다.
공격하는 사람의 목표는 poison instance가 포함되어 있는 데이터셋에 대해 재학습한 네트워크가 하나의 클래스의 test instance에 대해 자신이 조작한 다른 클래스로 잘못 분류하도록 하는 것입니다.
이런 점은 공격하는 사람이 의도한 class에 대한 틀린 예측을 제외하고는 전부 잘 예측하기 때문에 분류기의 성능 자체에는 변화가 미비합니다. 그렇기에 이를 방어하기에는 어렵겠죠.
본 논문에서는 poison data가 추가된 dataset에 대해 network의 fc layer만 재학습 하는 transfer learning 상황에서 개와 물고리를 분류하는 작업에서 100%의 공격 성공률을 보였다고 합니다.
또, 네트워크의 모든 layer가 재학습되는 end-to-end 상황에서도 처음으로 clean-label 공격을 시도했는데 이 때에도 50개의 poison instance를 학습에 사용하게 된다면 최대 60%의 공격 성공률을 보였다고 하네요.
2. A simple clean-label attack
이제 학습 데이터에 넣으면 test 할 때의 분류기의 동작을 조작할 수 있는 poison instance를 어떻게 생성하는지에 대해 알아봅시다.
공격하는 사람은 먼저 test 데이터셋에서 공격하고자 하는 하나의 target instance를 선택합니다. 그 다음으로 데이터셋 내의 class 중에서 target instance와 다른 class인 base instance를 선택하고 이를 조금씩 눈에 띄지 않게 변경하여 poison instance로 만듭니다. 마지막으로 모델은 이 poison instance에 대해 학습하게 되면 test 할 때 모델이 target instance를 base instance로 착각하게 되면 공격이 성공한 것으로 볼 수 있습니다.

예를 들어 위 그림처럼 SPAM을 공격하고자 하는 target instance로 선택하였다면 이와 다른 class의 데이터셋을 base instance로 설정합니다. 그림에서 메일 이미지가 되겠네요. 이 메일 이미지를 feature space상에서 SPAM과 유사한 feature를 가지도록 눈에 띄지 않는 변화를 가해가면서 학습을 진행하게 되면 test시 target instance 스팸을 넣게 되면 스팸이 아닌 메일로 예측을 하게 되는 것입니다.
2.1 Crafting poison data via feature collisions
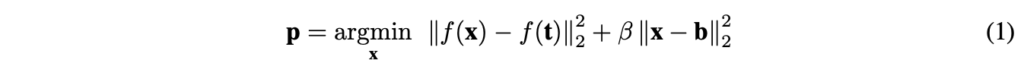
Input 이미지 x가 softmax layer를 거치기 전까지의 layer를 거치면 f(x)라는 output이 나온다고 합시다. 간단하게 f(x)는 feature extractor를 거치고 난 후의 feature 이라고 보면 되겠습니다. 함수 f는 복잡도와 비선형성이 높기 때문에 실제로 feature space에서는 target instance와 같은 feature 값을 가지는 많은 이미지 x를 얻을 수 있습니다. 또 동시에 사람이 눈으로 보기에는 (input space에서는) base instance인 b와 유사하게 보이도록 할 수 있습니다. 결과적으로 위 수식을 거친 target instance를 poison instance라고 부를 수 있는 것이죠.
위 그림으로 다시 말하자면, SPAM이미지와 feature space상에서 메일 feature와 유사한 feature를 가지는 input 이미지 x를 찾는데, 이 x는 눈으로 보기에는 base instance와 유사하도록, 아무 이상 없도록 만들면 poison instance가 된다는 것입니다.
2.2 Optimization precedure
[식 1]의 최적화를 수행해서 p를 구하는 절차는 아래 알고리즘에 나와있습니다.

poison 이미지 p를 얻는 방법은 간단한데, 한 iteration마다 foward step과 backward step을 반복하는 것이 보입니다. forward step에서는 feature space 상에서 target instance feature와 가까워지도록 합니다. 보면 target instance feature간의 거리를 구한 후 이를 줄이는 방향으로 step을 하게 되죠. 이후의 backward step을 통해 업데이트 중인 poison 이미지가 눈으로 보기에는 base instance 이미지와 유사해지도록 만듭니다. 이런 과정을 iteration마다 반복하게 되면 poison image가 만들어지는 것입니다.
3. Poisoning attacks on transfer learning
이제 이 poison image를 생성하는 과정을 알아봤으니, 이를 이용하여 공격한 결과를 살펴봅시다.
먼저, 사전학습된 feature extractor를 사용하고 최종 network layer(fc layer)만 학습하여 수행하고자 하는 task에 맞게 network를 조정하는 전이 학습에서의 결과입니다.
3.1 A one-shot kill attack
여기서는 두 가지의 poisoning 실험을 수행했는데, 먼저 마지막 layer(fc layer)를 제외한 모든 layer를 freeze시켜놓은 경우에서의 공격과, 모든 layer를 학습하는 경우에서의 공격 실험을 수행하였습니다.
이런 전이 학습에 대한 공격에서는 “one-shot kill”이 가능합니다. 이게 무슨 말이냐 하면, 학습 데이터에 단 하나의 poison instance 하나만 추가하게 된다면 100% 성공률로 target을 잘못 분류할 수 있다는 것입니다.
본 논문에서는 InceptionV3를 feature extractor를 freeze 시키고 fc layer만 학습하여 개와 물고기를 분류하는 실험을 진행하였습니다. 각 클래스마다 학습 데이터셋을 900장 사용하였고(target instance까지 1801장이 총 학습 데이터셋) test 데이터셋은 1099장을 사용하였습니다. 그 다음 이 test 데이터셋에서 target instance와 base instance를 뽑아내어 앞서 설명한 방식에 따라 poison dataset을 만들었습니다.
결과적으로 각각의 test image에 대해 공격을 수행해보았을 때 단 하나의 실패 사례 없이 모두 공격에 성공하였습니다.
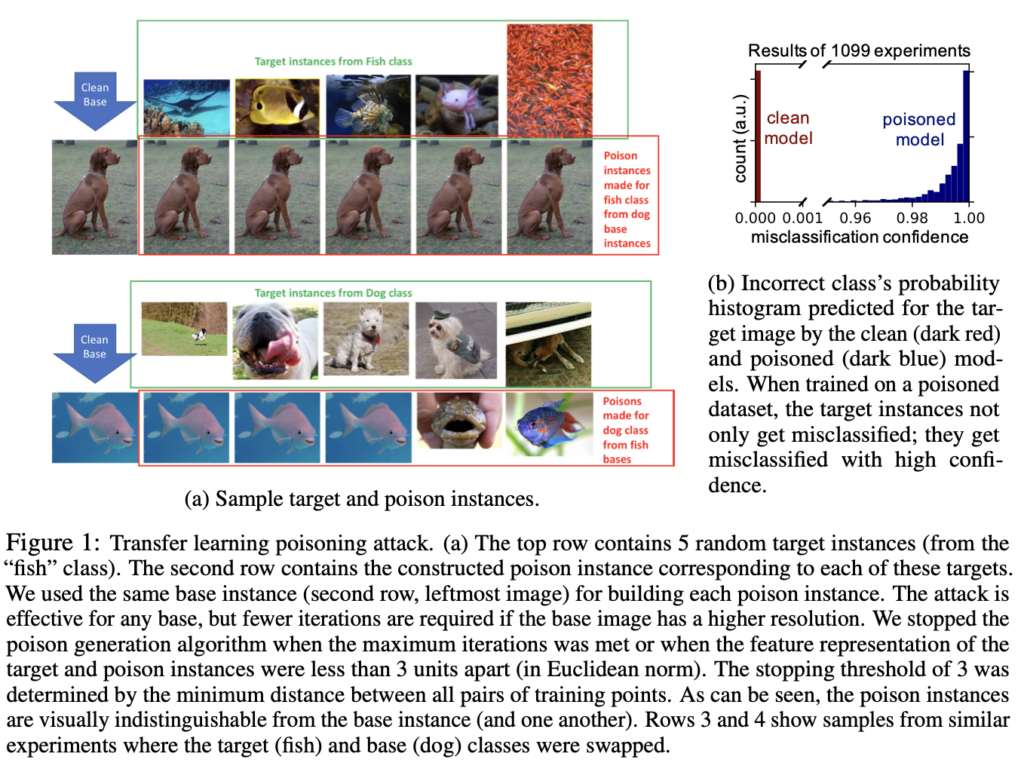
위의 그림의 (a)를 보면 방금 설명한 transfer learning posioning attack 과정을 알 수 있습니다. 위쪽 그림들에서 clean base라고 하는 강아지 그림이 base instance에 해당하겠고, fish class의 모든 target instance에 대해 poison dataset을 생성하도록 하였습니다. 예를 들어 첫 번째 물고기 그림인 가오리(아닐수도) target instance에 대해서 poison dataset을 생성하고자 한다면 feature space 상에서는 가오리의 feature와 base instance인 강아지의 feature가 동일해지도록 학습하는 동시에 육안으로 보기에는 전혀 차이가 없도록 학습하여 poison instance를 생성하는 것이지요. 이는 반대로 물고기를 base instance로 설정하였을 때도 동일한 방식으로 진행됩니다.
[Fig1 – (b)]를 보면, poisoned model에 대해서 실제로 attack을 수행하면 매우 높은 confidence로 오분류가 수행되는 것을 확인할 수 있습니다. 위 실험은 이진 분류 문제였지만, “고양이” class를 도입한 결과 96.4%의 정확도를 보여 class가 늘어난 경우에도 poison에 성공한다고 할 수 있겠습니다.
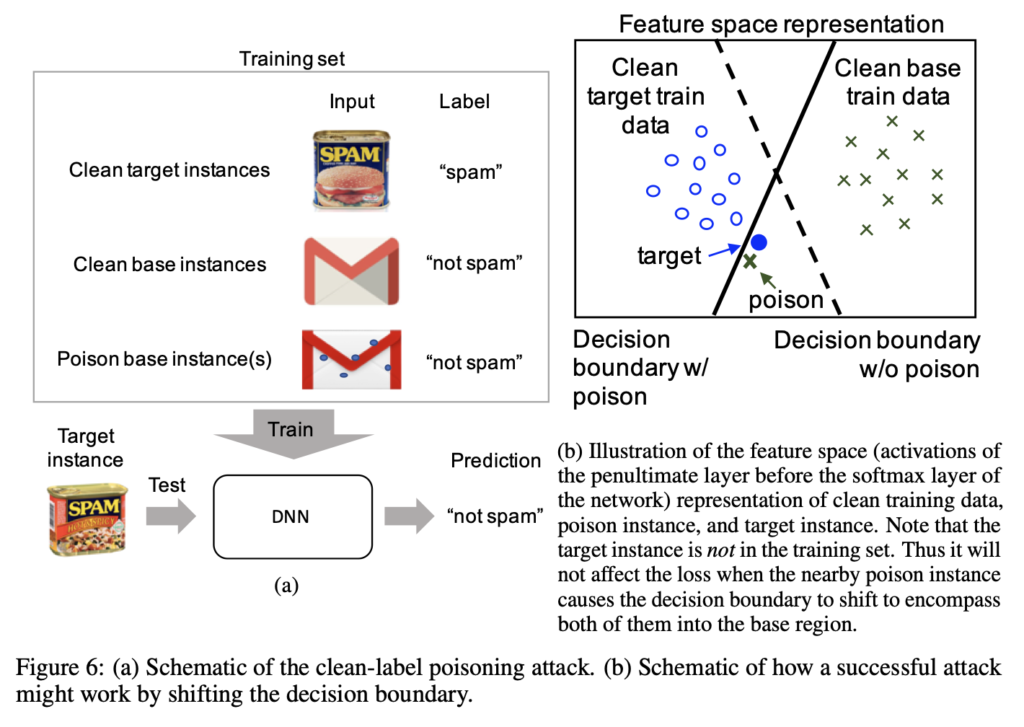
위 그림의 (b) 부분은 feature space상에서 training data를 representation한 것입니다. 보시면, clean base train data를 중독시킨 데이터가 decision boundary 상에서 target train data에 더 가까이 위치해 있는 것을 볼 수 있습니다.
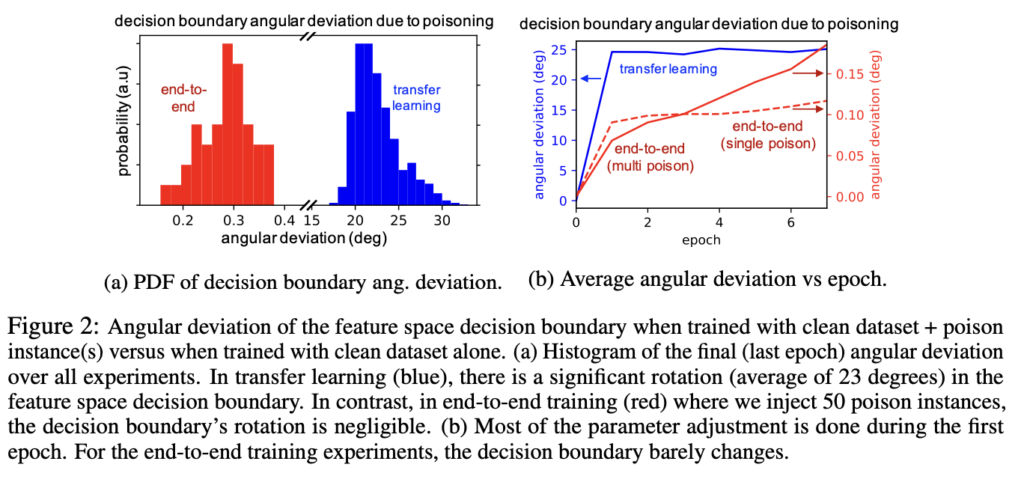
추가적으로 [Figure2]를 보면 end-to-end로 학습한 경우와 transfer learning의 경우에서 decision boundary의 각도 변화를 살펴볼 수 있습니다. 즉, 일반적으로 학습이 이뤄진 네트워크와 poisoning된 decision boundary의 각도 차이를 보여주는 것인데, 실제로 trasfer learning 상황에서는 각도가 평균 23도 정도 바뀌지만 end-to-end 학습에서는 약 0.2~0.38정도로 미비한 변화밖에 일어나지 않는 것을 확인할 수 있습니다.
4. Poisoning attacks on end-to-end training
방금까지 end-to-end에서는 poisoning attack이 어렵다는 것을 알게 되었습니다. 이유는 단순하게 모든 layer가 학습 가능하기 때문인데요, 그렇기에 본 논문에서는 “watermarking”이라는 방식과 여러개의 poison instance를 사용하여 end-to-end network에서 효율적으로 공격을 하는 방식을 설명합니다.
이 때는 cifar10 데이터셋을 사용하여 실험을 진행하였고, AlexNet을 학습하도록 하였습니다.
4.1 Single poison instance attack
먼저 1개의 poison instance로 network를 공격하는 것을 생각해봅시다. end-to-end에서 poison attack이 transfer learning 때보다 더 어려운 이유를 아래 그림을 통해 살펴보고 가겠습니다.
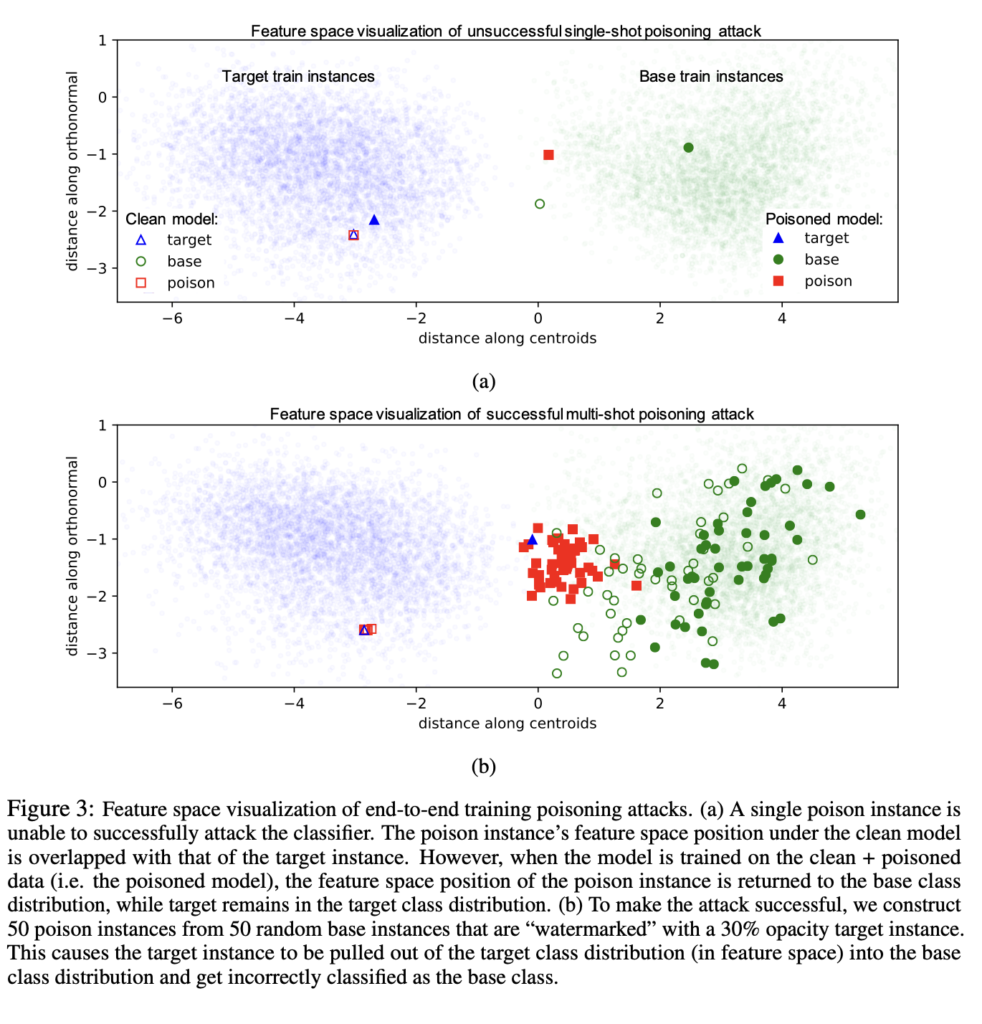
위 [Fig 3 ]은 193차원의 feature vector를 2차원에 투영하여 시각화한 target, base, poison instance의 feature space representation을 보여줍니다. 그림에서 도형 안쪽이 채워지지 않은 것은 clean model이고 채워진 도형은 poisoned model입니다. (a) 같은 경우에는 오직 단 한개의 poison instance가 데이터셋에 포함되었을 경우이고(single-shot), (b) 같은 경우에는 여러개의 poison instance를 데이터셋에 포함시켜서 하나의 target instance를 base instance로 분류하도록 하는 상황입니다(multi-shot).
먼저 single shot poisoning attack 결과를 보면 공격에 실패했다는 것을 알 수 있는데 파란색 채워져있는 삼각형인 target instance의 경우 여전히 target train instance 분포에 포함되어 있기 때문입니다. 반면에 multi shot poisoning attack 결과를 보면 target instance가 single shot일 때보다 더 많이 당겨져서 base instance 분포와 더 가까이 위치한 것을 볼 수 있습니다.
하지만, 저자가 여기서 발견한 이상한 점은, end-to-end 학습에서는 전이학습에 비해 decision boudary의 회전 각이 작다는 것입니다. 본 논문에서는 이런 poison instance로 retraining을 진행하는 과정에서 shallow layer의 lower-level feature extraction 커널이 많이 바뀔 수 있기 때문에 poison instance가 base instance feature와 같은 feature 를 갖도록 하는 경향이 있기에 전이학습보다 공격이 어려운 경우라고 합니다. 그렇기에 end-to-end에서는 단 하나의 single instance만을 가지고 공격하기에는 어렵다고 할 수 있겠습니다.
4.2 Watermarking: a method to boost the power of poison attacks
그래서 본 논문에서는 “watermarking”이라고 하는 기법을 추가적으로 도입하여 feature space 상에서 poison instance와 target instance가 멀어지지 않도록 합니다.

실제로 개와 새를 분류하는 분류기에 대한 공격 실험에서, 하나의 bird target instance에 대해 60개의 random poison instance를 만들어서 공격을 수행하고자 하였고, 위 그림에서 각 poison instance는 한장의 새 이미지에 대해 보이지 않는 adversarial watermark가 섞여 있는, 겉으로 보기에는 아무 이상 없는 강아지 사진입니다.
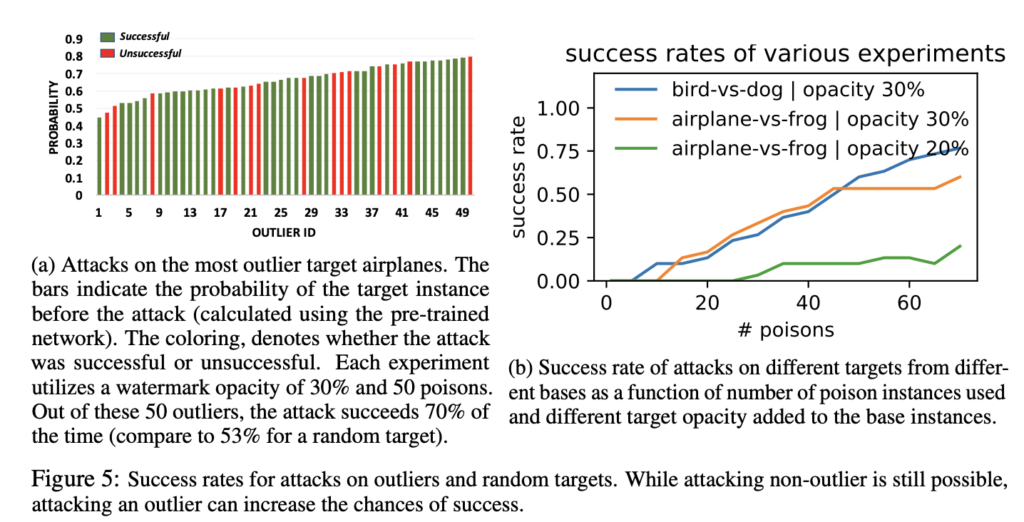
위 그림(a)은 단순하게 outlier를 target instance로 선택하면 더 성공률이 높다는 것을 보여줍니다. 단순하게 생각하면 outlier라는 것은 target instance 분포에서 중심에 있지 않고 멀리 떨어져 있을 것인데, 그렇다면 base instance 분포로 보다 더 이동하기 쉽기 때문에 공격이 더 잘 되는 것입니다.
(b)는 poison instance의 개수가 많아질수록 공격 성공률이 높다는 것을 보여줍니다.
이번 논문에서는 따로 experiments을 다루는 부분 없네요 . . 리뷰 마치도록 하겠습니다.
안녕하세요. 정윤서 연구원님.
새로운 주제의 X-review 흥미롭게 잘 봤습니다.
궁굼한 점이 두가지 있는데 먼저 성공률이라는 지표가 몇 번 등장하는데, 구체적으로 어느 수준의 정확도 차이가 발생하여야 성공으로 치는 건가요? 그리고 본 모델은 공격 대상이 될 모델의 사전학습 모델을 알아야 공격이 가능한 것으로 이해하였는데, 그렇다면 혹시 한 이미지를 여러가지 모델 (ResNet, AlexNet 등)을 타겟으로 하도록 변형할 수 있을까요?
좋은 리뷰 감사합니다!
안녕하세요. 댓글 감사합니다.
본 리뷰에서 언급한 성공률이라는 지표는, 공격을 시도한 횟수 중 공격이 성공한 횟수를 의미합니다. 그렇기에 지오님이 적어주신 것처럼 어느 수준의 정확도 차이가 발생해야 성공으로 치는 것이 아닌, 특정 target instance에 대해 attack을 하였을 때 이를 base instance로 오분류한 경우를 성공으로 보는 것입니다.
본 모델은 공격 대상이 될 모델의 사전학습 모델을 알아야 공격이 가능한 것으로 이해하였는데, 그렇다면 혹시 한 이미지를 여러가지 모델 (ResNet, AlexNet 등)을 타겟으로 하도록 변형할 수 있을까요?
→ 네 가능합니다.
리뷰 잘 읽었습니다.
새로운 분야의 리뷰라서 그런지 흥미로웠습니다.
무엇을 계기로 본 논문을 리뷰하게 되었는지 궁금합니다.
그리고 결국 해당 논문의 attack 방식은 공격하는 사람이 의도한 class에 대한 틀린 예측을 제외하고는 전부 잘 예측하기 때문에 특정 공격 class를 지정(?) 하는 것으로 보여집니다. 그럼 이런 attack 방식은 실제 어떤 상황에 적용이 될 수 있나요? 실제 적용 케이스가 궁금합니다. (악의적으로 쓰이진 않겠죠..?ㅎ)
감사합니다.
안녕하세요. 댓글 감사합니다.
리뷰할 논문 찾다가.. 제목이 독 개구리이길래 궁금해서 읽어봤습니다. . 제가 개구리를 좋아해서요. .
이런 attack 방식은 실제 어떤 상황에 적용이 될 수 있나요? 실제 적용 케이스가 궁금합니다. (악의적으로 쓰이진 않겠죠..?ㅎ)
→ input image에 ‘GO’라는 이미지로 분류할 수 있도록 stop 클래스들을 조작한다면 자율주행 시스템이 Stop이라는 표지판을 보고도 Go로 분류하게 될 수 있다는 케이스가 있네요 . . 악의적으로 보통 쓰이지 싶네요.
안녕하세요. 좋은 리뷰 감사합니다.
[Fig 3]의 multi-shot에서 poisoned model이 base instance 분포 쪽으로 엄청 이동한 것은 아닌 것 같은데, 학습을 더 해나간다고 해도 저 위치가 최선인 것인가요 ?
또, [Figure5 – b]에서 poison instance의 개수가 많아질수록 공격 성공률이 높아진다는 전체적인 그래프의 해석은 가능했지만, opacity라는 것이 무엇인지 정확히 나와있지 않아 질문드립니다. opacity라는 것은 watermarking 기법의 적용 정도 차이로 이해하면 될까요? 이 opacity가 20에서 30으로 단 10% 차이만으로 성공률 차이가 크게 나는 것 같은데 이런 이유도 궁금합니다.
감사합니다.
안녕하세요. 댓글 감사합니다.
1. multi-shot에서 poisoned model이 base instance 분포 쪽으로 엄청 이동한 것은 아닌 것 같은데, 학습을 더 해나간다고 해도 저 위치가 최선인 것인가요 ?
→ base instance 분포 쪽으로 더 이동하려면 watermark의 opacity를 더 키우면 될 것 같습니다.
2. opacity라는 것은 watermarking 기법의 적용 정도 차이로 이해하면 될까요?
→ 네 맞습니다.
3. 이 opacity가 20에서 30으로 단 10% 차이만으로 성공률 차이가 크게 나는 것 같은데 이런 이유도 궁금합니다.
→ 아무래도 watermark의 불투명도를 높게 가져갔기 때문에 base instance와 feature space상에서 가깝게 위치할 수 있게 되기 때문입니다. . 다만, 30%보다 더 불투명도를 높이게 되면 사람이 시각적으로 보았을 때 변화를 인지할 수 있을 정도가 되기 때문에 30%가 최적의 opacity로 보고 실험한 것 같습니다.
정윤서 연구원님, 좋은 리뷰 감사합니다. 평소에 생각해보지 못한 분야의 논문이라 굉장히 신선하네요. 리뷰를 읽다보니 몇가지 궁금한게 있습니다. 1. 공격 대상의 data pool에 poison data를 추가시켜서 공격 대상 딥러닝 모델의 성능을 저하시킬 수 있는데, 이런 분야가 연구되는 이유는 무엇인가요? 이 연구를 어디에 활용할 수 있고, 연구의 motivation이 무엇인가요? 해당 논문을 찾아본 이유와 비슷할 것 같아 궁금합니다. 2. 결국 해당 방법론도 특정 데이터들을 기반으로 poison data를 학습시켜나가는 딥러닝 알고리즘 으로 보이는데, 그럼 감염시키고 싶은 상대가 가지고 있는 데이터를 공격자 또한 가지고 있다는 전제가 되어있는건가요? poison data를 만들 데이터를 미리 공격자가 가지고 있는 것인지 궁금합니다!
안녕하세요. 댓글 감사합니다.
1. 공격 대상의 data pool에 poison data를 추가시켜서 공격 대상 딥러닝 모델의 성능을 저하시킬 수 있는데, 이런 분야가 연구되는 이유는 무엇인가요? 이 연구를 어디에 활용할 수 있고, 연구의 motivation이 무엇인가요?
→ 딥러닝 모델은 보안상 취약점이 존재하기에 이런 공격에 대한 방어를 위한 것이 아닐까 .. 생각해봅니다.
2. 감염시키고 싶은 상대가 가지고 있는 데이터를 공격자 또한 가지고 있다는 전제가 되어있는건가요? poison data를 만들 데이터를 미리 공격자가 가지고 있는 것인지 궁금합니다!
→ 본 논문에서는 공격자가 미리 target한 instance에 대해 poised된 instance를 생성한 다음 이를 웹 상에 올려놓으면, 누군가가 크롤링하여 데이터셋을 취득함으로써 공격을 할 수 있게 된다고 합니다.
안녕하세요 정윤서 연구원님 좋은 리뷰 감사합니다.
해당 task는 학습 시 학습 데이터에 noise를 추가하여 학습 결과가 특정 instance에 대한 모델의 결과를 조작하는 것이라고 이해하였습니다.
리뷰를 읽었으나 제가 이해하지 못 한 부분이 있는데요, ‘attack이 성공한다’는 것의 의미가 어떤 class이미지를 특정 class로 잘못 분류하게 되는 것이라고 설명해 주셨는데 판다 이미지를 예로 들자면 panda라는 이미지를 gibbon으로 분류하게 되었다면 이때 target은 panda, base는 gibbon이 되는 것인가요?
또한 “공격이 성공했다”라고 했을 때 target을 base로 예측한 경우, 즉 다른 class에는 영향이 없는 상황이어야 하는 지 궁금합니다. 단순히 target의 예측 정확도가 떨어진 것만으로는 attack의 성공이라고는 할 수 없는 건가요?
안녕하세요. 댓글 감사합니다.
1. 판다 이미지를 예로 들자면 panda라는 이미지를 gibbon으로 분류하게 되었다면 이때 target은 panda, base는 gibbon이 되는 것인가요?
→ 네 맞습니다.
2. “공격이 성공했다”라고 했을 때 target을 base로 예측한 경우, 즉 다른 class에는 영향이 없는 상황이어야 하는 지 궁금합니다. 단순히 target의 예측 정확도가 떨어진 것만으로는 attack의 성공이라고는 할 수 없는 건가요?
→ 공격이 성공했다라고 작성한 부분은 한 이미지에 대한 결과를 말하고자 한 것입니다. 다른 class에는 영향이 없어야 하는지가 무슨 말인지 잘 이해는 못했지만, 본 논문에서 연구한 attack 기법은 targeted attack으로 어떤 특정 test instance에 대한 attack을 하고자 한 것이라고 보면 되기에 특정 test instance에 대해 공격을 할 때는 이를 제외한 다른 class에는 영향을 미치고자 하는 의도 자체가 없는 것 같습니다.