이번에 리뷰할 논문은 Interspeech 2023에 발표된 MMER이라는 논문입니다. 해당 논문은 음성 감정 인식을 수행하기 위해 text데이터를 추가적으로 활용하는 멀티모달 감정인식 논문으로 multi-task learning을 사용하여 IEMOCAP 데이터셋에 대해 sota를 달성하였다고 하네요.
Introduction
인간은 대화를 할 때 언어를 통해 직접적으로 메시지를 전달함과 동시에 비 언어적 표현을 통해 암시적으로 감정을 표현합니다. 예를 들자면 말의 세기, 빠르기, 음정의 변화 등이 있겠네요. Speech Emotion Recognition은 인간의 발화에서 이러한 암시적인 감정을 알아내는 task입니다.
SER 연구는 음성만을 사용하는 단일 모달리티 기반 방법론이 대부분이었다고 합니다. 그러나 감정 인식 분야에서 점차 멀티 모달리티를 활용한 연구가 진행되었다고 합니다. 저자들은 특히 멀티모달 학습의 중요성을 강조하였는데요, 실제 인간이 감정을 표현할 때 신체 언어, 얼굴 표정, 단어 선택, 목소리의 억양 등 여러 모달리티의 요소를 종합적으로 활용하기 때문이라고 합니다.
저자들은 그 중에서도 음성과 텍스트 정보에 집중하였는데요, automatic speech recognition(ASR) 시스템의 성능이 향상됨에 따라 텍스트 모달리티를 음성 데이터에 대한 보완적인 정보로 활용할 수 있게 되었기 때문이라고 합니다. 텍스트 정보를 추가함으로써 prosodic bias을 제거하여 SER성능 향상을 가져올 것이라고 생각하였다고 하네요. 여기서 prosodic bias란 음성의 운율적인 특징에 편향되는 것을 의미합니다. 감정을 인식할 때 음성만을 사용하게 된다면 음성의 톤, 리듬, 강세와 같은 특징에 편향되어 문장에 사용된 어휘나 구문 정보를 고려하지 못하는 문제가 발생한다는 것이라고 이해하시면 될 것 같습니다.
저자들은 SER에 ASR을 접목하여 모델이 언어적 표현을 학습할 수 있도록 하였는데요, 하나의 모델이 SER을 수행하는 것 뿐 아니라 ASR이라는 auxiliary task를 함께 수행할 수 있도록 하는 multitasking learning을 방법론을 적용하고자 하였다고 합니다. 이 분야에서는 처음 시도하는 것이라고 하네요.
논문에서는 multimodal multitask learning을 이용한 SER모델인 MMER를 제안하였습니다. MMER는 음성에서 감정을 인식하기 위해 해당 음성의 script를 추가적으로 활용하는 모델입니다. 따라서 사전 학습 모델로 음성과 추출된 텍스트에서 각각 feature를 추출하고, multimodal interaction module을 통해 두 모달리티 간의 암시적인 temporal alignment를 학습한다고 합니다.
MMER는 SER 외에도 세 가지 auxiliary task을 수행합니다. 먼저 ASR task를 수행하는데요, ASR에서 CTC loss을 최소화함으로써, 음성과 텍스트 사이의 자연스러운 monotonic alignment과 텍스트에 숨겨진 의미론, 구문론적 정보를 학습한다고 합니다. 그 다음으로는 Supervised Contrastive Learning task를 수행합니다. 이는 모델이 멀티모달 데이터로부터 더 나은 감정 특징을 학습할 수 있도록 하기 위함이라고 하는데요, 모든 데이터에 감정 label이 주어지고, 동일한 감정을 가진 instance끼리는 positive, 그렇지 않은 instance는 negative로 구성하여 positive끼리는 feature space에서 서로 가까워지게 하였습니다. 마지막으로는 Augmented Contrastive Learning task를 수행하는데요, 논문에서는 ASR로 생성된 text를 back-translation기법을 사용하여 증강하고, TTS모듈을 사용하여 변형된 텍스트로부터 음성을 생성하여 원본 데이터와 비교함으로써 데이터의 변형에 강인하고, 음성과 텍스트의 다양한 표현을 학습하는 모델을 설계하였다고 합니다. 이를 통해 MMER은 IEMOCAP 벤치마크에서 SOTA를 달성하였다고 하네요.
Proposed Methology
먼저 speech emotion recognition이라는 task를 수식으로 정의하고 넘어가겠습니다. 음성 데이터셋 D가 총 N개의 발화 \{u_1, u_2, u_3, ⋯, u_N\} 과 각 발화에 해당하는 감정 label \{y_1, y_2, y_3, ⋯, y_N\}로 구성되어 있다고 가정해 보겠습니다. 여기서 각 발화 u_i는 음성 signala_i와 텍스트 t_i를 모두 가지고 있으며, 이에 따라 u_i \in (a_i ,t_i )로 표현하게 됩니다. 여기서 t_i는 데이터셋에 따라 사전에 labeling된 텍스트 정보일 수도 있고, ASR을 통해 자동으로 생성된 데이터일 수도 있습니다. 그냥 해당 음성에 대응되는 텍스트 데이터라고 생각해 주시면 될 것 같습니다.
위와 같이 설정하였을 때, SER은 각 발화 u_i에 해당하는 감정 y_i를 예측하는 것을 의미하며 이때 모델의 출력값은 사전에 알려진 j개의 감정 중 하나에 속하게 될 확률 분포에 해당합니다.
Multimodal Dynamic Fusion Network
아래의 [그림1]이 저자들이 제안하는 MMER의 전체적인 구조입니다.
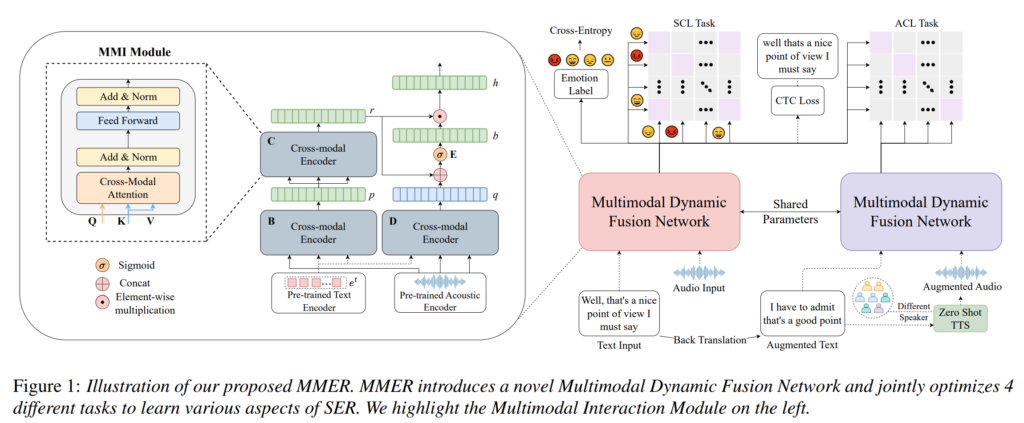
Feature Encoder
먼저 feature encoder에 대해 설명드리자면 논문에서는 audo encoder로 사전 학습된 wav2vec-2.0를 사용하였습니다. Facebook에서 출시한 960시간의 Librispeech에서 사전 학습된 체크포인트를 사용하였고, 모든 실험에는 wav2vec-2.0-base 아키텍처를 사용하였다고 합니다. 각 원시 오디오 입력 ai에 대해 wav2vec-2.0는e^{a_i} ∈ R^{J\times 768}의 출력을 제공하는데, 여기서 J는 원시 오디오 파일의 길이와 wav2vec-2.0의 CNN 특징 추출 레이어에 따라 결정됩니다. 이 레이어는 20ms의 스트라이드와 25ms의 홉 크기로 프레임을 추출하게 됩니다. Text encoder로는 transformers 계열의 RoBERTaBASE를 사용하였다고 하며, RoBERTa는 특징 추출기로만 사용하고 fine-tuning은 진행하지 않았다고 합니다.
Multimodal Interaction Module
저자들의 Multimodal Interaction Module (MMI)은 3개의 cross-modal encoder(CME) 블록으로 구성되어 있습니다. CME 블록은 일반적인 트랜스포머 레이어와 같은 구조를 가지고 있으며, [그림1]의 좌측과 같이 CMA 모듈, residual connections, feedforward layer로 구성되어 있습니다.
Speech-Aware Word Representations.
[그림 1]과 같이, utterence에서 audio와 text의 연관성을 학습하기 위해, 저자들은 wav2vec-2.0 임베딩 A \in R d\times J를 query로, 그리고 RoBERTa 임베딩 T \in R^{d\times M}를 key와 value로 사용하여 CME 블록 B의 CMA 모듈에 입력하였으며, 식으로 표현하면 아래의 [수식 1]과 같습니다.
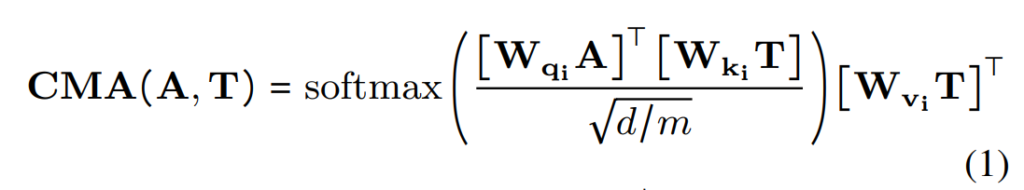
위의 [수식 1]에서 \{W_{qi} , W_{ki} , W_{vi}\} \in \R^{d/m\times h}은 각각 i번째 attention head의 q,k,v의 가중치를 나타냅니다. 이때 CME 블록 B의 출력은 P = (p_0,p_1, ⋯, p_{m−1})이며, 이전 블록에서 생성된 각 representation p_i가 i번째 음성 임베딩에 해당합니다. p_i가 토큰 임베딩에 해당하지 않는다는 사실을 해결하기 위해, P를 원래의 RoBERTa 임베딩 T를 쿼리로, P를 키와 값으로 사용하는 다른 CME 블록 C에 입력하여 최종적인 음성 인식 단어 표현 R = (r_0,r_1, ⋯, r_{j−1})을 얻게 됩니다.
Word-Aware Speech Representations
단어 인식 음성 표현을 얻고 각 단어를 밀접하게 관련된 프레임 또는 wav2vec-2.0 임베딩에 정렬하기 위해, T를 쿼리로, A를 키와 값으로 사용하여 또 다른 CME 블록 D를 사용합니다. 이 블록에서 얻은 최종 표현은 Q = (q_0,q_1, ⋯, q_{j−1})로 표시될 수 있습니다.
Acoustic Gate
음성 프레임은 무작위 잡음 및 기타 중복된 음성 신호와 같은 불필요한 정보를 인코딩할 수 있습니다. 따라서, 각 음성 프레임 임베딩의 기여를 동적으로 제어할 수 있는 음향 게이트 E를 구현하는 것이 중요한데요, 논문에서는 음향 게이트 g를 다음과 같이 구현하였습니다:
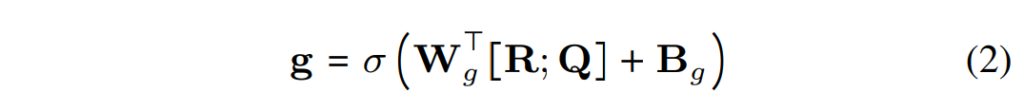
우선, W_g \in R^{2d\times d}는 가중치 행렬로, B_g \in R^d는 bias이며, \sigma는 sigmoid 함수입니다. 이후, 게이트 출력을 기반으로 최종의 단어 인식 음성 표현들이 Q = g.Q를 통해 얻어집니다. 이 단계 이후, 음성 인식 단어 표현과 단어 인식 음성 표현을 연결하여 최종의 cross-modal MMI 표현 M ∈ R 2d를 얻는데, 여기서 M = [Q ; R]이며, 이를 선형 변환 l(.)을 통해 d 차원 공간 변환합니다.
Multi-task Learning
앞서 언급했듯이, MMER의 학습에는 SER을 포함하여 총 4가지의 태스크를 수행하는데요, 각 task와 그에 사용되는 loss를 이어서 설명드리도록 하겠습니다.
Cross-Entropy Loss
먼저 기본적으로 SER을 수행하는데요, 여기에는 cross entropy loss가 사용됩니다. 크로스 엔트로피는 SER 학습에 가장 일반적으로 사용되는 손실입니다. 실제 감정 라벨과 함께 크로스 엔트로피 손실을 계산하기 위해, 우리는 먼저 wav2vec-2.0 음성 표현 (A)와 MMI 모듈 (M)을 독립적으로 시간 축을 따라 max pooling mp(.)을 적용한 후 임베딩을 연결하여 하나의 최종 임베딩 \R^{2d \times 4}를 얻습니다. 이 최종 임베딩은 그 다음 선형 변환과 softmax를 통과하며 이는 아래의 [수식 3]과 같이 나타낼 수 있습니다.
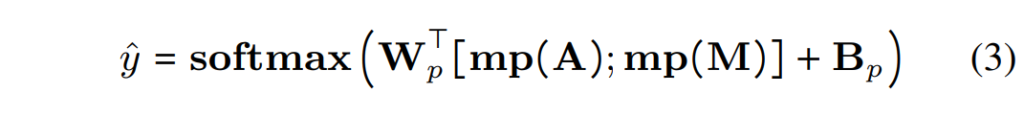
\hat y \in \R^4는 각 발화를 하나의 벡터로 나타낸 것이며, W_p \in \R^{2d \times4}는 가중치 를 의미합니다. CE는 최종 예측값인 \hat y과 정답 y사이의 loss로 L_{CE} = CrossEntropy(\hat y_i , y_i)를 통해 계산됩니다.
CTC Loss
MMER는 그 다음으로 CTC 손실을 최소화함으로써 ASR task를 해결하게 됩니다. ASR task를 해결하는 학습을 통해, 모델은 음성과 텍스트의 언어적 특성을 학습하게 됩니다. 이를 위해 먼저 wav2vec-2.0 인코더에서 나온 raw 임베딩 A를 선형 레이어를 통과시키며 이는 아래의 [수식 4]와 같습니다.
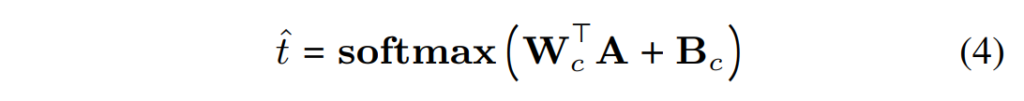
[수식 4]의 결과값인 \hat t의 크기는 {J\times V}이며, 여기서 J는 wav2vec-2.0 CNN feature extractor에 의해 출력되는 음성 프레임의 수이며, V는 우리의 어휘 크기 또는 코퍼스 내의 고유한 문자 및 기호의 수와 추가로 비어있는 토큰의 개수라고 합니다. W_c는 \( R^{d×V} \) 이고 Bc는 추가된 bias입니다. projection된 \hat t를 바탕으로 원본 t와의 CTC loss, 즉, L_{CTC} = CTC(t, \hat t)를 계산합니다. 여기서 ( t_i \in {t_0,⋯,t_i ,⋯,t_N })은 원래의 t_i의 전처리된 버전이며, 여기서는 모든 구두점을 제거하고 모든 문자를 대문자로 변환하였습니다.
Supervised Contrastive Learning
Supervised Contrastive Learning (SCL)은 Cross-Entropy에서 학습하지 못 하는 감정 특성을 추가적으로 학습하기 위해 사용하였습니다. 우리가 일반적으로 알고 있는 unsupervised 기반의 contrastive learning은 positive/negative pair를 구성할 때 동일한 데이터로부터 생성된 feature는 positive, 그렇지 않은 경우는 negative로 구성하게 됩니다. 즉, 비슷한 특징을 가진 instance끼리 feature space상에서 거리를 가까워지게 하는 것이죠. 이때 SCL은 동일 데이터의 augnentation을 줘서 positive를 생성하는 것이 아니라 라벨 값이 동일한 경우를 positive로 정의합니다. 즉, 보다 augmentation으로 생성할 수 있는 것 이상의 다양성을 확보할 수 있게 되는 것이죠.
저자들은 이러한 SCL을 MMER에 적용하였는데요, 감정 label이 존재할 때 각 batch의 representation을 감정 label에 따라 여러 subset으로 나눈 뒤, 각 subset에 대해, 동일 집합에 포함된 경우 positive, 다른 집합은 negative로 설정하여 contrastive learning을 진행하였다고 합니다.

Augmented Contrastive Learning
Augmented Contrastive Learning(ACL)은 MMER이 데이터에 존재하는 불변적인 특징을 학습하록 하기 위해 사용되었다고 합니다. 이전 연구에서는 SER이 발화자의 불변성을 학습함으로써 더 좋은 성능을 달성한 것을 보였는데요, 본 논문에서는 MMER의 멀티모달 특성을 고려하여 텍스트의 의미적 불변성을 추가로 학습하는 약간 다른 방법을 사용한다고 합니다.
MMER는 다양한 모달리티 표현 M 사이에서 또 다른 인스턴스 구별 대조 학습 작업을 해결하게 됩니다. 이때 representation은 augmented 텍스트와 음성 신호에서 학습이 진행됩니다. text augmentation에는 back translation이라는 기법을 사용하였다고 하는데요, 이는 기존 텍스트를 대상 언어로 번역한 다음 원래의 언어로 다시 번역하는 것이라고 합니다. 음성에도 augmentation을 수행하는데요, 이때 augmentation은 어떤 음성이 있을 때 동일한 감정, 텍스트를 다른 화자가 발화한 것처럼 하는 것이라고 하며, 이를 위해 zero-shot speaker-conditioned TTS 모델을 사용하여 augmented 텍스트로부터 발화를 생성하였습니다. 생성된 발화(텍스트 + 음성)을 바탕으로 위와 같이 contrastive learning을 수행하며 이를 ACL이라 하였습니다.
위의 모든 loss를 조합하여, 최종적으로 MMER을 학습하기 위한 Loss는 다음과 같습니다.
L = L_{CE} + \alpha L_{CTC} + \beta L_{SCL} + \gamma L_{ACL}Experiments
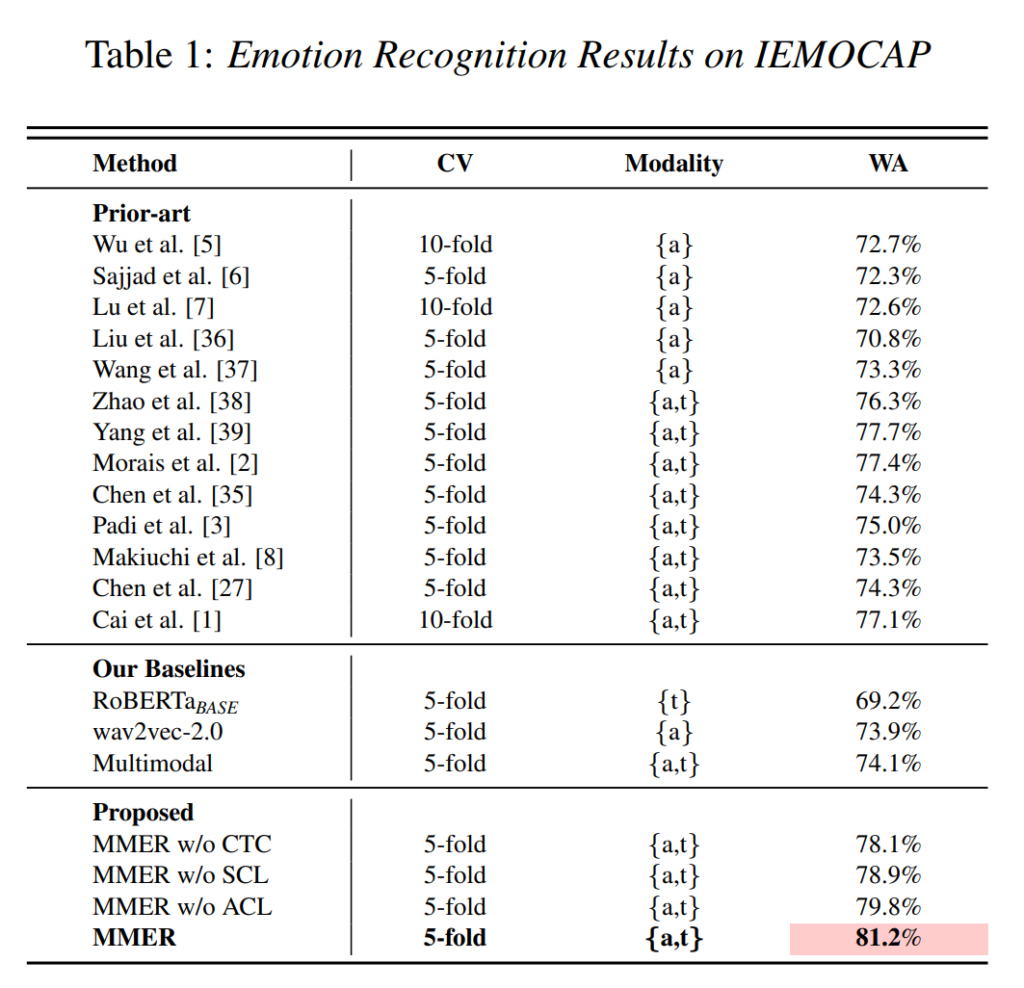
논문의 실험 부분은 SER task의 감정 분류 성능을 리포팅하였는데요, 먼저 [표 1]은 IEMOCAP 데이터셋에 대한 기존 방법론과의 비교 결과입니다. 저자들이 제안한 MMER이 sota를 달성한 것을 확인할 수 있습니다.
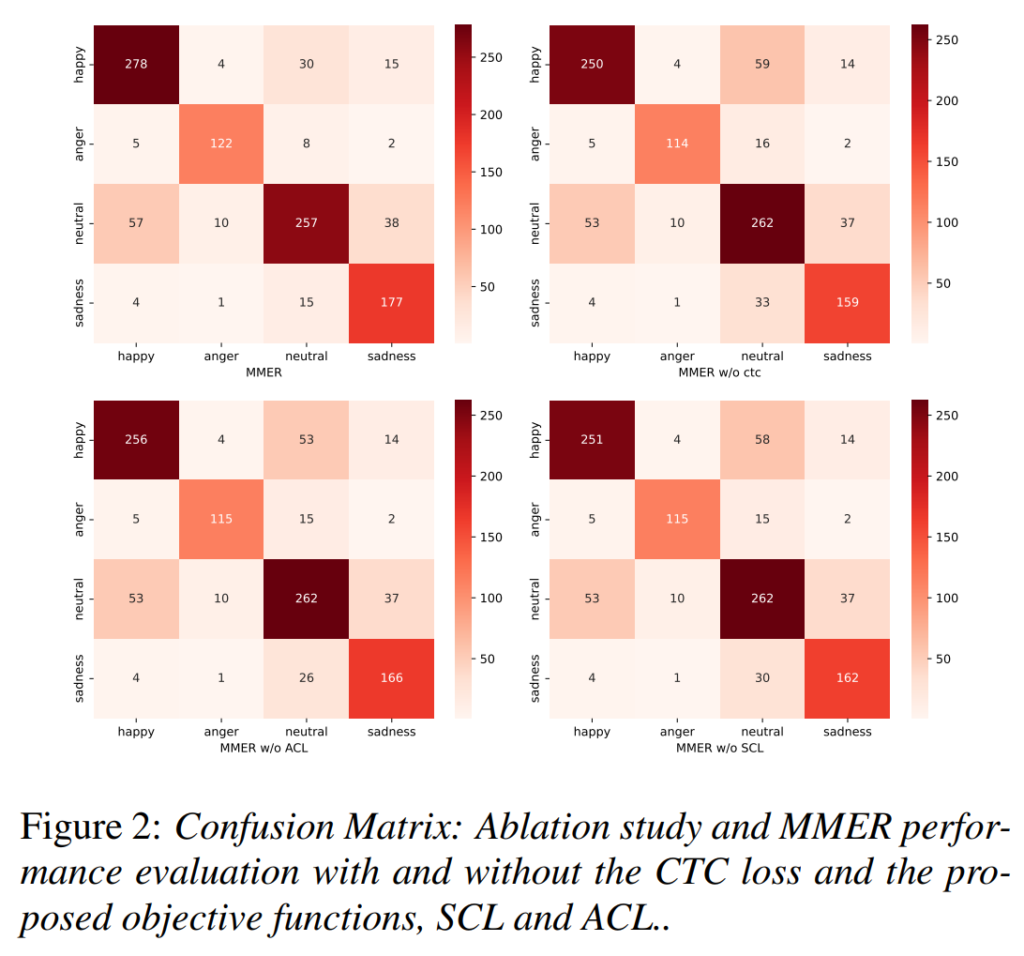
다음으로는 각 loss에 대한 ablation study 결과입니다. 저자들은 confusion matrix로 리포팅을 수행하였습니다. 논문에서는 ‘ACL이 neutal class에서 발생하는 편향 문제를 완화시키며, 반대로 CTC는 이를 약간 증폭시키는 것을 통해 멀티모달 학습에서는 음성의 중요한 단서를 무시하고 텍스트에서 더 많은 의미론적 정보를 학습한다’라고 주장하였는데요, 솔직히 아래의 결과만을 놓고는 이러한 해석이 유효한 것인지는 잘 모르겠습니다. 좀 더 다양한 경우로 ablation을 진행하였으면 좋았을 것 같네요.
안녕하세요. 좋은 리뷰 감사합니다.
본 논문에서 SCL은 Cross-Entropy에서 학습하지 못 하는 감정 특성을 학습하기 위해 사용하였다고 하셨는데 여기서 이야기하는 감정 특성이 어떤것일지 설명해주실 수 있을까요?
또한, ACL은 MMER이 데이터에 존재하는 불변적 특징을 학습하도록 하기 위해 사용하였다고 하는데, 여기서 이야기하는 불변적 특징도 무엇인지 궁금합니다.
마지막으로 Figure 2에 대한 논문의 해석이 유효한지에 대해 의문이고, 다양한 경우로 ablation을 진행하였으면 좋겠다고 하셨는데, 혜원님이 생각하시는 다양한 ablation이 어떤것인지 의견이 궁금합니다!
안녕하세요 이승현 연구원님 댓글 감사합니다.
우선 첫 번째 질문인 SCL이 학습하는 감정 특성에 대해 설명드리자면, 어떤 감정의 feature가 공통적으로 가지고 있는 특성을 의미한다고 이해하였습니다. 단순 CE와 달리 SCL은 동일 감정의 feature끼리 서로 거리가 가까워지도록 학습하므로 어떤 감정에 대해 해당 감정의 feature가 일반적으로 가지는 경향을 학습한다고 생각할 수 있을 것 같네요.
불변적 특징이란 어떤 문장이 있을 때, 그 문장이 말하고자 하는 핵심이라고 생각하시면 이해가 조금 쉬울 것 같습니다. [그림1]에 나온 문장 “Well, that’s a nice point of view i must say.”를 예로 들자면 해당 문장에 augmentation을 수행하면 “I have to admit that’s a good point.”가 됩니다. 이때 두 문장에 사용된 단어는 달라졌지만 ‘화자가 that이 지칭하는 무언가를 긍정적으로 생각한다’는 의미적 특징은 공통적으로 가지게 되겠죠. 이를 해당 문장의 불변적 특징이라고 이해하였습니다.
마지막은 [그림2] ablation 결과에 대한 저자들의 주장을 이해하지 못하였기 때문에 해당 주장에 대한 추가 실험의 필요성을 언급하였는데요, “ACL이 neutal의 편향 문제를 완화시키고, CTC는 이를 증폭시킨다.”는 주장을 듣고 ablation결과를 확인해 보면 어떤 loss를 제거하더라도 비슷한 양상을 보이고 있기에 보다 직접적으로 해당 class에 대한 feature 분포라도 추가적으로 보여주면 좋지 않았을까 합니다.