안녕하세요, 열여섯번째 x-review 입니다. 이번 논문은 2019년도 ICCV workshap에 게재된 depth completion 논문 입니다. 이번에 KROC 논문을 depth completion 쪽으로 작성하게 되어 늘 읽어오던 3D detection이 아니라 새로운 task의 논문을 오랜만에 읽게 되었습니다. 저도 아직 background 지식이 많이 없어서 내용이 조금 부족해보일 수도 있습니다 ㅎ ㅎ .. ? 그럼 바로 리뷰 시작하겠습니다 !

1. Introduction
depth 센서는 현재 자율 주행이나 AR 등에서 recognition을 목적으로 사용되는 application 중 하나이지만, 널리 사용되는 depth 센서인 kinect나 Realsense는 아직까지 물체의 edge 정보가 완전히 보존되거나, 노이즈가 없는 depth map을제공하지는 못합니다. 촬영되는 scene에 빛이 포함되거나 투명한 부분, 혹은 depth 센서가 지정한 최소, 최대 depth를 벗어나는 영역에 대해서는 depth 값이 채워지지 못한 depth map을 제공하게 됩니다. 해당 논문에서 사용하는 Matterport3D를 예시로 들자면 데이터셋에서 제공하는 raw depth의 15% 가량이 그러하다고 하네요. 즉, depth 센서가 놓친 영역에 대한 depth 정보를 채워넣는 것이 중요하며, 그러한 작업이 바로 depth completion 입니다.
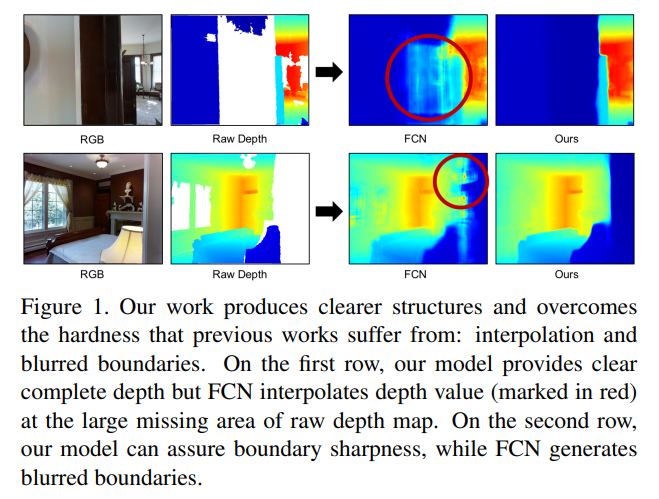
전통적인 방법은 multie view로 촬영한 depth 정보를 사용하는 것인데 바로 SLAM으로 여러 구도에서 촬영한 정보를 통해서 reconstruction한 후에 특정 위치에서의 depth 정보를 얻게 됩니다. 그러나 본 논문에서는 멀티 뷰에서의 reconstruction을 활용하는 것이 아니라 하나의 view를 이용하고자 합니다. 그 이유라고 함은 멀티 뷰에 비해 싱글 뷰를 사용하였을 때가 inference 속도와 계산 비용이 훨씩 효율적이기 때문이라고 하네요. 하지만 싱글 뷰로 depth completion을 하는 기존의 방법론들은 비어있는 영역을 주변의 픽셀 값을 그대로 사용하여 채워넣거나 혹은 단순 보간만을 수행하게 됩니다. 문제가 되는 것은 Figure1에서 FCN이라는 방법론처럼 경계가 흐릿해지면 전체적인 구조가 완전하게 채워지지 않는다는 점 입니다. 그래서 본 논문에서는 딱 이 두 한계점(정확한 depth 값 추정, 완전한 구조 형성)을 문제점으로 정의하고 해결하고자 하였습니다.
우선, 기존 연구에서는 전체 feature map이 네트워크를 통과하여 convolution 연산을 수행하였지만 어쩌면 당연하게도 전체 영역에서 비어있는 depth를 채우기 위해 더 중요하게 사용할 수 있는 영역과 비교적 덜 중요한 영역이 나뉘어져 있을테니 모델이 의미있는 부분에 더 집중할 수 있도록 self attention 네트워크를 사용하였다고 합니다. 그리고 추가적으로 self attention 네트워크를 통과하기 전에 depth representation 네트워크를 거치면서 좀 더 정확한 depth 값을 추정할 수 있었다고 합니다. 또한 boundary consistency라는 과정을 추가하면서 앞서 이야기한 모호한 구조에 대해 해결하고자 하였습니다. depth completion을 완료한 depth map을 입력으로 받아서 정확한 바운더리를 예측하고자 새로운 네트워크를 구성하여 depth map을 refine하는 과정을 추가한 것 입니다. 저자가 말하기를 depth completion에서 처음으로 self attention을 적용하였고 boundary 정보를 feature로 사용한 첫 논문이라고 하네요 !
여기서 본 논문의 main contribution을 정리하며 다음과 같습니다.
- 처음으로 self attention을 depth completion task에 활용
- depth map을 개선하기 위한 새로운 boundary consistency 개념 도입
- Matterport3D 데이터셋에서 SORA 달성
2. Related Work
Image Inpainting
본 논문에서는 Image Inpainting에서의 방법들을 이용하고 있는데, Image Inpainting에서 RGB 이미지의 값을 지우고 최대한 real인 것처럼 지워진 RGB의 값을 inpaint하는 것이 depth completion의 누락된 hole을 채우는 것과 매우 유사하다고 판단하였기 때문입니다. 물론 depth completion은 정해진 정답 depth 값이 있는 상황에서 최대한 정답에 가깝도록 예측해야 하는 반면에 image inpainting은 정답이라기보다는 최대한 real인 것처럼 느껴지는 것을 목표로 한다는 차이가 존재하긴 합니다. 어쨌든 image inpainting을 통해 말하고자 하는 것은 image inpainting에서도 gated convolution이라는 연산을 통한 self attention으로 좋은 결과를 확인했기에 이를 본 논문에서 동일하게 도입하고자 한다는 것이었습니다. 이와 관련된 내용은 아래의 Method에서 더 자세하게 다루도록 하겠습니다.
2. Method
하나의 RGB-D 이미지가 주어질 때의 depth completion을 진행할텐데 해당 방법론이 어떻게 단순 보간에 그쳤던 이전 방법론들의 한계점을 극복하였는지, 두번째는 depth map을 좀 더 완벽한 형태로 만들기 위해 어떤 방법을 사용하였는지에 초점을 두고 봐주시면 좋을 것 같습니다.
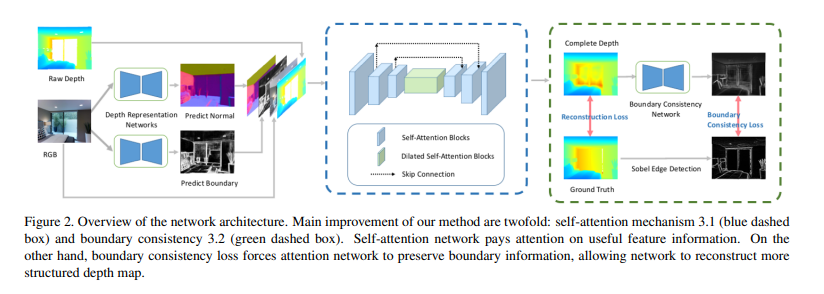
2.1. Self-Attention Mechanism
우선 반복적으로 이야기하고 있는 주변 픽셀의 값을 그대로 사용(=복사)하거나 보간을 수행하는 문제가 무엇인지 더 자세하게 이야기해보면, depth 센서가 놓친 영역에 대한 평균값을 예측하려고 하면 loss가 급격하게 떨어지면서 정확한 값을 예측하지 못하고 단순하게 보간을 수행하는 local minima에 쉽게 빠지게 된다고 합니다. 이러한 관점에서 저자는 각각의 컨볼루션 레이어에 self attention을 사용하여 더 정확한 depth 값을 예측하고 복사하는 local minima에 쉽게 빠지는 현상을 없애고자 하였습니다.
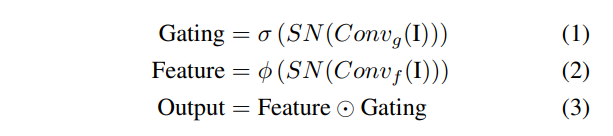
논문에서 사용한 self attention 수식은 위와 같은데, 이는 image impainting 분야에서는 제안된 gated convolution과 SN-PatchGAN을 거의 그대로 사용하였습니다. 저자가 앞선 related work에서도 언급한것처럼 depth completion에서 비어있는 depth 값을 채우는 것과 이미지에서 마스킹 되어있는 픽셀 값을 painting 하는 것이 매우 유사하다고 분석하여 위의 기법을 depth completion으로 끌고와서 사용한 것이죠. 우선 gated convolution을 사용하게 된 이유를 좀 더 생각해보면 기존 컨볼루션은 공유된 컨볼루션 필터가 모든 feature을 동일하게 취급하기에 누락된 depth 값을 추정하기에 적합하지 않다고 판단하였습니다. 누락된 부분을 채우기 위해서 누락된 영역과 아닌 영역을 invalid/valid로 판단하게 되는데 일반적인 컨볼루션 연산의 경우 valid/invalid에 상관없이 모든 feature에 동일한 필터를 적용하게 되어 놓친 영역을 채워넣기에 한계가 있다는 것 입니다. 그래서 제안된 거이 gated convolution으로 입력으로 들어오는 데이터로부터 자동으로 마스크를 학습하게 되는데 이를 soft mask라고 부릅니다.
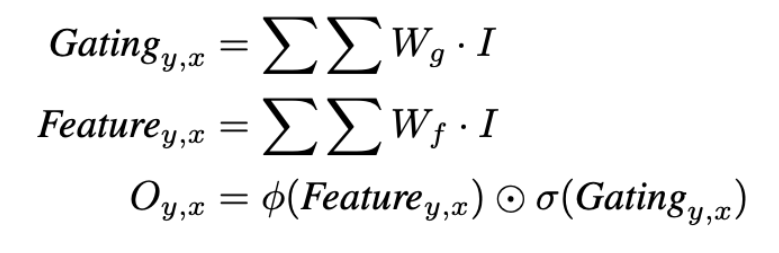
위의 식이 gated convolution 수식인데 본 논문에서 쓰인 수식과 매우 유사한 것을 확인할 수 있습니다. 일반적인 컨볼루션 연산을 하는 것과 마찬가지로 Freature_{y, x}를 추출한 다음에 동일한 데이터에서 soft mask인 Gating_{y,x}를 얻게 됩니다. Gating_{y,x}에 시그모이드 함수를 적용해서 gating을 valid/invalid로 만들고, Freature_{y, x}에는 어떤 활성화 함수를 취하고 이 둘을 element-wise multiplication 하여 valid일 확률이 강한 feature에 더 attention할 수 있도록 연산을 하게 됩니다.
그럼 이걸 그대로 식(1)-(3)까지 적용하여 보면 되는데요, 컨볼루션 블럭은 Conv_f와 Conv_g가 있는데 각각 특징 추출과 gating 컨볼루션이며 SN은 sprectral normalization이라는 GAN에서 쓰이는 가중치 정규화 방법을 의미합니다. 사실 여기서 SN을 왜 사용했는지 정확히 이해는 되지 않습니다만 .. 위의 gated convolution 식을 가져온 논문에서 제안한 SN-PatchGAN에서 GAN의 학습을 안정화 하기 위해 spectral noramlization을 사용한 것을 그대로 끌고온 것이라고 생각하고 있습니다. 다음으로 \phi는 활성화 함수를 의미합니다. Conv_g가 전체 영역 중에 더 중요하다고 판단되는 영역을 학습하게 되기 때문에 (valid faeture을 의미하겠죠) self attention을 통해 모델은 중요한 정보에 더 초점을 맞추어 정확한 깊이 정보를 예측할 수 있게 됩니다.
2.2. Boundary consistency
Figure1부터 시작해서 논문에서 계속해서 비교 대상으로 삼고 있는 FCN 모델은 위에서 이야기한 것처럼 복사 및 보간으로 completion이 수행되기 쉽기 때문에 edge가 원래 형태가 아닌 왜곡이 되거나 경계가 흐릿한 depth map을 예측할 가능성이 높습니다. depth completion은 복잡한 regression에 해당하기에 인접한 픽셀 값이 크게 다른 날카로운 경계의 depth map을 생성하는 방법을 학습하는 것이 어렵다고 합니다. 이러한 문제를 해결하기 위해서 고안해낸 것이 boundary consistency 네트워크 입니다. boundary constistency는 U-Net 구조를 변형하여 입력으로 completion 네트워크를 거친 depth map을 받아 boundary를 예측하는 네트워크 입니다. 해당 네트워크에서의 self attention은 더 정확한 바운더리 값을 예측하여 sharp한 엣지를 생성하기 위한 역할을 합니다. 이렇게 예측한 바운더리는 GT depth 이미지에서 소벨 필터를 통해 검출한 엣지와의 loss를 계산하게 됩니다. GT detph에 대해 소벨 필터를 적용한 이유는 다른 방법들과 비교했을 때 더 선명한 엣지를 검출할 수 있고 노이즈에 민감하지 않다는 장점 때문이라고 합니다.
2.3. Depth Representation
Figure2에서 아직 설명하지 않은 부분이 있는데, 바로 depth completion 네트워크를 들어가기 전 depth representation 네트워크 부분 입니다. 해당 파트 역시 본 논문에서 새롭게 제안한 것은 아니고 이미 이전 방법론에서 강인하다고 증명된 representation 방식인 surface normals와 occlusion boundary를 사용한 것 입니다. surface normals란 조도 변화와 관련있으며 RGB 이미지에서 각 픽셀에 물체들의 표면에 대한 방향을 할당해준다고 보시면 됩니다. 입력 이미지가 들어오면 FC layer을 통과시켜 픽셀에 대한 3차원 벡터를 계산하게 되고 GT Normals와 각 픽셀들에 대한 벡터의 각도를 비교하는데 본 논문의 네트워크에서는 사전학습된 모델을 사용하는 것으로 보입니다. 이렇게 surface normals는 scene의 표면에 대한 추가적인 정보를 제공할 수 있습니다. occlusion boundary 역시 RGB 이미지에서의 local한 texture 정보를 제공하게 됩니다. 이러한 두 개의 representation이 depth completion 네트워크의 입력값으로 RGB와 raw depth와 함께 들어가게 됩니다.
2.4. Loss Functions
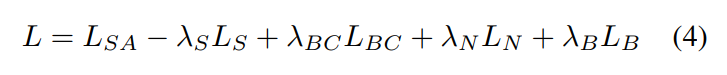
마지막으로 Loss Function에 대해 살펴보도록 하겠습니다. 여기서 representation loss는 L_N, L_B로 L_N = 1/p \sum_p \lVert N(p) - N_0(p) \rVert^2 , L_B = 1/p \sum_p \lVert B(p) - B_0(p) \rVert^2 로 표현할 수 있는데 여기서 N_0, B_0는 GT를 의미하며 p는 픽셀을 뜻합니다. depth completion 네트워크에는 RGB 이미지와 raw depth, 그리고 depth representation 결과까지 합하여 입력으로 들어가서 depth D를 완성합니다. D_0를 GT depth라고 정의하게 되는데 GT depth는 한 scene을 멀티 뷰로 촬영한 후에 렌더링함으로써 얻을 수 있습니다. 식(4)에서 L_{SA}가 completion 네트워크의 loss를 뜻하며 L_{SA} = 1/p \in obs \sum_p \lVert D(p) - D_0(p) \rVert로 표현할 수 있습니다. 여기서 예측해야할 비어있는 depth 영역에 대해서는 GT detph인 D_0에서의 영역도 loss 계산에서 무시한채로 진행해야 합니다. 즉 p \in obs는 observed 픽셀, 비어있지 않은 픽셀들을 의미하게 되죠. L_S는 SSIM(Structural Similarity Index)로 Figure2에서 Reconstruction loss를 의미하는 듯 합니다. GT depth map과 completion 네트워크를 거쳐 예측한 depth map 사이의 유사도를 계산할 때 luminance, contrst, structure 3가지 요소를 이용하여 판단하는 SSIM를 사용하여 더 높은 SSIM index를 가질수록 구조적으로 더 완전한 depth을 만드는 방향으로 계산되도록 하였습니다. 마지막으로 depth completion을 마치고 나면 boundary consistency 네트워크를 통해 depth map을 개선하게 된다고 했는데 이에 해당하는 loss가 L_{BC}로 L_{BC} = 1/p \sum_p \lVert B(p) - B_0(p) \rVert^2 라고 표현합니다. GT depth에서 소벨 필터를 적용한 B_0를 만들어 loss를 계산함을 의미합니다.
3. Experimental Results
3.1. Dataset
본 논문에서는 Matterport3D 데이터셋을 사용하였는데요, 널리 사용되는 NYUv2 데이터셋을 사용하지 않은 이유에 대해서는 RGB-D 이미지에 대한 GT depth가 있어야 하는데 이를 제공하지 않기 때문이라고 합니다. 사용한 Matterpor3D 데이터셋은 indoor scene의 large RGB-D 데이터셋으로 구성되어 있습니다. GT depth는 멀티 뷰 reconstruction으로부터 생성하였다고 하네요.
3.2. Performance
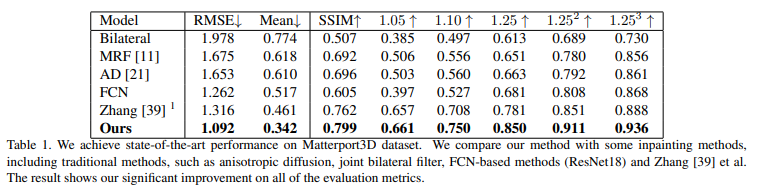
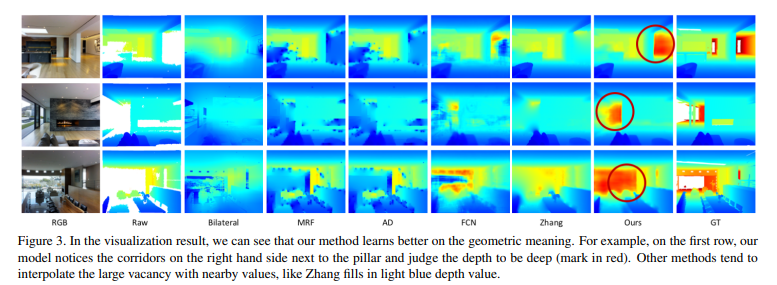
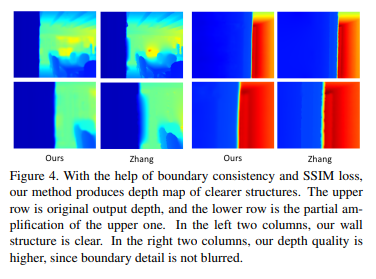
Table1은 전통적인 방법들과 이전 SOTA 모델과의 성능을 비교한 Table로 모든 평가 메트릭에서 SOTA를 달성한 것을 확인할 수 있습니다. 특히 RMSE와 Mean에서 큰 차이를 보이며 좋은 성능을 보이고 있습니다. 여기서 {1.05, 1.10, 1.25, 1.25^2, 1.25^3}는 델타 퍼센트로 상대적인 깊이 차이를 측정하는 메트릭으로 깊이 센서에 가까운 픽셀일수록 더 정밀하게 예측하는 것이 필요함을 보여줍니다.
Figure3는 정성적인 결과로 이전 방법론들에서는 단순 복사, 보간으로 인해 raw depth에서 누락된 부분에 대한 정확한 depth map을 만들어내지 못하는 반면에 Ours의 빨간 동그라미 친 부분을 보면 놓친 부분에 대해서 GT와 비교했을 때 다른 방법론들보다 확연하게 차이가 나는 것을 볼 수 있으며 이는 본 논문의 self-attention을 적용한 depth completion 네트워크가 효과가 있음을 의미하고 있습니다.
또한 Figure4에서 boundary consistency 네트워크가 포함된 본 논문의 방법론이 타 방법론보다 벽의 엣지와 같은 구조적인 디테일까지 놓치지 않고 depth map에서 표현되는 것을 볼 수 있습니다.
3.3. Ablation Studies
3.3.1. Self-Attention
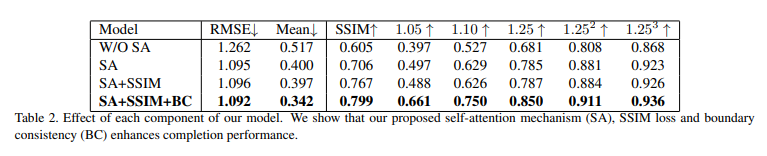

다음은 self attention을 detph completion에 사용하는 것이 얼마나 효과적인지 확인하기 위한 ablation study 입니다. Table2의 W/O SA는 단순 FCN 구조를 의미하며 SA → SA + SSIM Loss → SA + SSIM + BC 순으로 좋은 성능을 보이고 있는데 특히나 SA가 추가되면서 큰 폭의 차이를 두고 성능이 향상되는 것을 확인할 수 있습니다. 이를 통해 self attention이 feature들 중 더 중요한 feature에 집중하면서 누락된 depth 값을 채우는데에 기하학적으로 중요한 정보등를 제공할 수 있음을 의미하고 있습니다.
3.3.2. Boundary Consistency
연결해서 Boundary Consistency의 효과까지 보면, BC까지 사용했을 때의 정량적 평가에서도 가장 성능이 높고 정량적 결과에서도 Figure5의 SA+SSIM+BC의 좌하단 의자를 보면 엣지가 선명하고 바닥같은 경우에도 매끄러운 표면을 표현할 수가 있게 됩니다.
안녕하세요. 좋은 리뷰 감사합니다.
depth completion의 경우, depth sensor 정보로부터 누락된 부분을 보완하기 위한 연구로, 결국 센서의 특성에 따라 정보 누락이 발생할 것이라고 생각합니다. 해당 논문에서 사용하는 Matterport3D 데이터는 실제 데이터인지, 아니면 생성 데이터인지 궁금합니다.
또한, 명확한 경계를 생성하기 위해 boundary consistency를 고안해내었다고 하셨는데, 이를 depth에 소벨 필터를 적용하셨다고 하는데, depth 정보에 누락이 있는 만큼, RGB의 윤곽정보가 이를 보완할 수 있지 않을 까 하는데, 아시는 선에서 depth completion 연구에서 RGB의 윤곽을 이용하는 연구는 없는지도 궁금합니다.
안녕하세요 ! 리뷰 읽어주셔서 감사합니다.
Matterport3D 데이터셋은 panoramic view에서 촬영한 real indoor scene으로 이루어져 있는 데이터 입니다. 또한 RGB의 윤곽정보를 completion 네트워크에 들어가기 이전에 representation 네트워크로 occlusion boundary를 생성하여 입력으로 사용하는 것 같기는 한데 .. 이를 입력으로 사용한 결과물을 다시 개선하기 위해 boundary consistency를 적용하는 것이라 본 논문에서는 depth map의 경계를 사용하는 것이 더 효과적이었다고 판단한 것 같습니다. 그리고 저자가 바운더린를 메인 feature로 사용한 첫 논문이라고 언급하긴 했는데, 이전에 RGB의 윤곽을 이용한 연구가 있는지까지는 제가 파악하진 못하였습니다 하하
안녕하세요 손건화 연구원님 좋은 리뷰 감사합니다.
결국 depth completion이란 센서가 인식하지 못 한 depth를 동일 이미지 내 다른 부분의 정보를 통해 예측하는 것이라고 생각 할 수 있겠네요. 논문에서는 깊이 정보를 보완할 때 self-attention을 사용하여 이미지 전체가 아닌 특정 부분과 관련 있는 구역에 집중하도록 하여 기존 방법론들보다 정확한 깊이 추정을 수행하였으며, 경계면을 예측하는 네트워크를 추가하여 dense map의 경계를 명확히 하였다고 이해하였습니다.
리뷰를 읽고 궁금한 점이 있는데요, Depth Representation Network는 어떻게 학습을 진행하는 건가요? 해당 네트워크는 rgb이미지를 통해 surface normal과 occlusion boundaries를 예측하는 네트워크라고 이해하였으나 해당 정보를 gt로 가지고 있는건지, 아니면 사전 학습된 네트워크를 통해 추출한 것인지 궁금합니다.
마지막으로는 실험 결과의 Mean 이라는 metric은 어떤 것을 의미하는지 간단하게만 설명해 주실 수 있나요?
감사합니다.
안녕하세요 ! 리뷰 읽어주셔서 감사합니다.
representation 네트워크는 본문에서도 언급하였듯이 사전학습된 네트워크를 추출합니다.
Mean은 mean error을 의미하며 이는 실제 GT depth와 예측한 depth 값 사이의 차이, 즉 오차를 모두 구하여 평균 낸 값을 의미합니다.
안녕하세요. 좋은 리뷰 감사합니다.
본 논문의 depth completion 방식은 싱글 뷰 RGB-D 이미지를 대상으로 이루어진다고 이해하였는데, Loss Function 파트에서 GT depth를 만들 때 한 scene을 멀티뷰로 촬영한 다음에 렌더링한다고 말씀을 해주셔서 .. depth completion을 하는 이미지와 GT depth를 만드는 것은 별개로 이해하는 것이 맞는건가요 ? 멀티 뷰로 촬영한 것을 통해 GT depth를 뽑는 과정이 명확하게 와닿지 않아 추가 설명해주시면 감사하겠습니다.
또 한 가지 궁금한 점은 Boundary consistency 네트워크는 completion한 depth map의 바운더리, 즉 경계 부분을 refine 하기 위해 추가한 모듈인 것 같은데 거기서 reconsturction loss로 GT depth와 completion한 depth 사이의 loss를 계산하는 이유가 있을까요? 바운더리를 위한 loss로는 L_BC로도 충분할 것 같다고 생각이 들어 질문 드립니다.
감사합니다.
안녕하세요 ! 리뷰 읽어주셔서 감사합니다.
말씀하신 것처럼 싱글 뷰로 depth completion을 하는것과 reconstruction을 하는 것은 별개로 reconstruction은 GT depth를 만들기 위함이기 때문에 멀티 뷰로 촬영한 것 입니다. 멀티뷰로 촬영하여 각 sequence 영상마다의 pose 정보를 가지게 되면 이를 다시 depth map으로 projection하는 것이 가능하게 됩니다.
그리고 reconstruction loss를 사용하는 이유는 boundary consistency loss와 목적은 비슷하나, 논문에서도 해당 loss를 통해 왜곡이 줄어들고 더 나은 퀄리티를 가진 depth map을 얻기 위함이라고 서술되어 있는만큼 boundary consistency 네트워크를 들어가기 전에 좀 더 구조적으로 GT와 유사한 방향이 될 수 있도록 refine할 수 있는 또 하나의 수단이라고 이해해주시면 좋을 것 같습니다.