안녕하세요 제가 이번에 리뷰할 논문은 real-time으로동작 가능한 6-DoF tracking논문입니다. 지금까지 리뷰한 논문을 물체와 카메라의 pose 정보를 비교한다면, 해당 task는 연속적인 sequence 내에서 물체가 어떻게 변하는지를 추정하는 task로, 물체의 6DoF Pose를 추정한다는 점은 동일합니다. 그럼 리뷰 시작하겠습니다.
Abstract
본 논문은 unknown object에 대하여 거의 실시간으로 작동(10 Hz) 가능한 6D Pose Tracking 방식으로, 단일 RGBD 영상을 이용하며, 동시에 객체에 대한 3D reconstruction(object의 3차원 모델을 생성하는 것)을 수행합니다. 해당 방법론은 강체를 대상으로 하며, texture-less한 object에 대해서도 동작한다고 합니다. 대략적인 작동은, 먼저 첫번째 프레임에서 객체를 segmentation한 뒤 6DoF tracking을 수행합니다. 본 논문의 핵심 아이디어는 Neural Object Field의 pose graph optimization 과정이라 합니다. pose 변화가 크거나, 완전 가려지거나(full occlusion) , 표면에 texture 정보가 없거나 빛이 반사되는 등의 challenge한 영상에서도 작동 가능하다고 합니다.
Introduction
6D Pose tracking과 3D reconstruction은 중요한 문제로, AR/로봇조작/sim2real 등의 분야에서 활용이 가능합니다. 기존 연구들은 두 문제를 분리하여 접근하였습니다. 먼저, 3D reconstruction은 neural scene representation 분야를 통해 real 데이터로부터 좋은 품질의 3D 모델을 생성할 수 있었다고 합니다. 그러나 이러한 방식은 (1) camera pose와 객체에 대한 GT mask가 주어진다는 가정이 있으며, (2) 정적 객체를 동적으로 촬영하기 때문에 완전하게 3D reconstruction이 불가능(객체가 놓인 바닥면은 촬영이 불가능하여 복원 X)하다는 단점이 있습니다. 6D Pose estimation과 tracking의 경우, instance-level 방식은 대상 object에 대해 texture 정보가 있는 3D 모델이 사전에 필요하다는 한계가 있으며, category-level의 방법론은 분포를 벗어난 인스턴스나 unseen object에 대해서는 잘 작동하지 않는다는 한계가 있습니다.
이러한 한계를 해결하기 위해, 본 논문은 두 문제를 함께 풀었다고 합니다. 우선 본 논문은 (1) object는 강체로 가정하며, (2) 비디오의 첫번째 프레임에 대해 2D object mask가 필요합니다. 이러한 조건과 별개로, 물체는 영상 내에서 자유롭게 이동할 수 있으며, occlusion도 가능합니다. 본 논문은 object-level의 SLAM과 유사하지만, occlusion이나 빛 반사, texture/기하학적 단서의 부족, 갑작스러운 움직임 등, 가정을 깨는 challenge한 상황을 허용합니다. 해당 논문의 핵심은 online pose graph optimization과정으로, 3D 형태와 외관을 동시에 reconstruction하는 Neural Object Field와 두 과정(reconstruction과 pose tracking)의 정보 교환을 촉진하기 위한 memory pool 입니다.
본 논문의 contribution은 다음과 같습니다.
- 새로운 unknown 동적 객체를 위한 새로운 6 DoF pose tracking과 3D reconstruction 방법론으로, tracking과 reconstruction 과정을 함께 디자인하여 거의 실시간으로 작동이 가능하며, tracking에 대한 오차를 크게 줄임
- 동적 object 중심의 설정으로 인해 발생하는 uncertain free space 문제를 해결하기위해 hybrid SDF representation 도입
- 3개의 benchmark에서 SOTA 달성
[ instance level/category level ? ]
- 동일 카테고리이더라도 카테고리내의 인스턴스들을 모두 구분하여 문제를 풀 경우 instance level
- 인스턴스들의 정규화를 통해 카테고리를 묶어 문제를 해결하는 경우 category level
[ pose graph ? ]
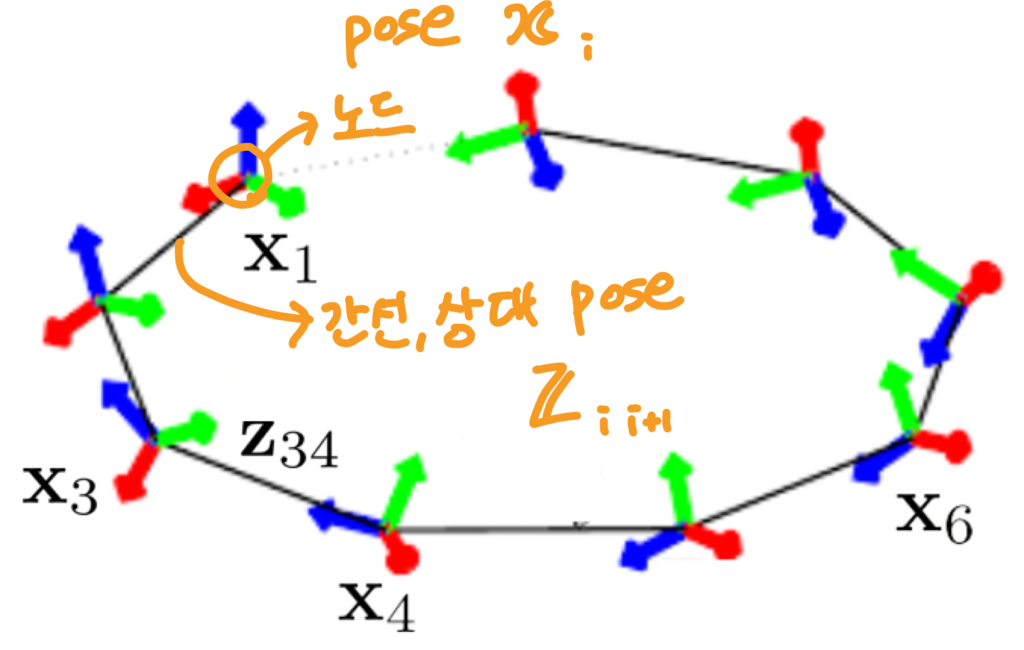
- 로봇 pose에 특화된 자료구조로, 로봇의 pose인 node와 각 노드 사이의 상대 pose인 edge로 표현
- pose graph optimization이란?
- front-end에서 누적된 error를 back-end로 전달하면서 pose graph optimization을 통해 error가 최소화되도록 모든 노드의 위치를 조정
- front-end: 로봇의 센서를 입력으로 받아 pose graph를 생성하는 부분
- back-end: 시간에 따라 누적되는 error를 최적화하는 부분
Approach
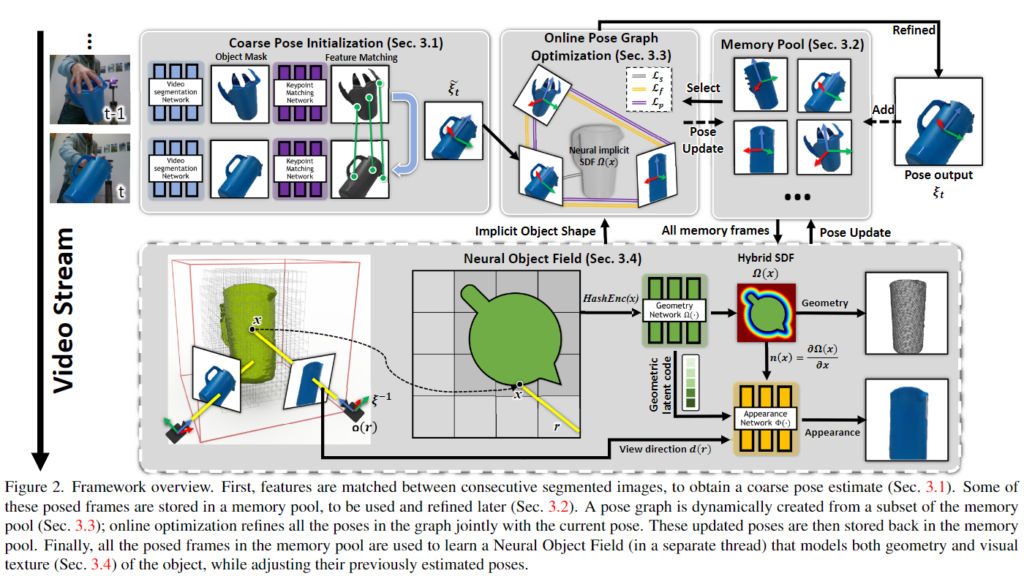
첫 프레임에 대상 object에 대한 mask가 있는, 단일 RGBD 비디오를 입력으로 사용하며, 모델은 연속적인 프레임을 통해 객체의 6D Pose 정보를 tracking하고, 동시에 reconstruction을 통해 texture 정보가 있는 3D model을 복원합니다. 모든 과정은 이후 앞선 정보들만 활용하며, object는 강체라는 가정이 있지만 texture 정보가 풍부하지 않아도 괜찮으며, instance-level의 CAD 모델이나 category-level의 정보가 없어도 됩니다.
1. Coarse Pose Initialization
대략적인 초기 pose \tilde{\mathcal{E}}_t를 생성하기 위해, 현재 프레임 \mathcal{F}_t과 이전 프레임 \mathcal{F}_{t-1}을 이용합니다. 먼저, object정보가 없어도 segmentation이 가능한 네트워크[1]를 이용하여 \mathcal{F}_t에 object 영역을 구합니다. 해당 segmentation 방식은 객체에 대한 사전지식이나 중간 매개물이 없어도 작동이 가능하므로, 다른 시나리오나 객체로 확장이 용이하기 때문에선택하였다고 합니다.
이후 \mathcal{F}_t와 \mathcal{F}_{t-1} 사이의 feature matching을 통해 feature간의 대응 관계를 구축합니다. depth 정보를 함께 이용하여 RANSAC 기반의 pose estimation을 수행하며, 구해진 pose 가설들 중, inlier 개수가 가장 많은 경우를 골라 현재 프레임의 coarse pose \tilde{\mathcal{E}}_t로 이용합니다.
2. Memory Pool
long-term tracking으로 인해 발생하는 문제들을 막기 위해, 과거 프레임의 정보를 유지하는 것이 중요합니다. 기존 연구는 일반적으로 제시된 pose를 global model과 융합하고, 융합된 모델을 이후의 프레임들과 비교에 사용하여 pose를 추정하였다고 합니다. 그러나, 이러한 방법론은 challenge한 시나리오에서 잘 작동하지 않는다고 합니다. 그 이유는 다음 2가지로 설명합니다.
- global model과 pose 추정치를 융합할 때, pose 추정치의 오차가 누적되므로, 이후의 프레임에 대한 pose를 추정할 대 추가적인 오류가 발생하기 때문입니다. 이러한 오류는 texture나 기하학적 단서가 부족하거나, 해당 프레임에서 object가 보이지 않을 때 발생하며, 시간이 지날수록 error가 누적됩니다.
- long-term complete occlussion 상황에서 큰 움직임으로 인해 global 모델과 물체가 다시 등장하는 프레임을 연결하는 것이 어렵기 때문입니다.
이에 저자들은 keyframe memory pool \mathcal{P}를 제안하여 정보가 풍부한 프레임을 저장하고자 합니다. keyframe memory는 첫 프레임 \mathcal{F}_0는 자동으로 memory pool \mathcal{P}에 추가하고, unknown object에 대하여 canonical 좌표계(표준 좌표계)로 세팅합니다. memory pool내의 프레임과 비교하여 새로운 프레임마다 coarse pose \tilde{\mathcal{E}}_t를 업데이트하여 업데이트 된 pose \mathcal{E}_t를 구합니다. 이후, 해당 프레임이 multi-view의 다양성 측면에서 정보가 풍부하다고 판단될 경우 memory pool에 추가하며, 이때 pool이 너무 커지지 않도록 compact하게 유지될 수 있도록 한다고 합니다.
구체적으로는, \mathcal{E}_t는 memory pool 안에 있는 프레임들과 비교를 수행하며, 이때 in-plane rotation은 추가적인 정보를 제공하지 않으므로, 카메라의 축에 대한 회전은 무시하고, 회전 거리를 고려한다고 합니다. 이를 통해 시스템이 공간 내의 유사한 view는 최소화하는 sparse한 프레임이 가능하여, 동일한 수의 메모리 프레임을 이용하여 더 넓은 범위의 pose를 최적화할 수 있도록 합니다.(multi-view 다양성을 고려한다는 것)
3. Online Pose Graph Optimization
새로운 프레임 \mathcal{F}_t와 coarse한 pose \mathcal{\tilde{E}}_t가 주어졌을 때, K 개의 memory frame의 하위 집합을 선택하여 online pose graph optimization을 수행합니다. 최적화된 pose가 최종 output pose \mathcal{E}가 되며, 해당 파트는 CUDA에서 구현되어 모든 프레임에 빠르게 적용하여 더 정확한 pose를 추정합니다.
이후 설명할 4. Neural Object Field도 최적화 과정을 지원하는 데 사용하며, memory pool 안의 모든 프레임은 해당 프레임이 Neural Object Field를 업데이트 하는 데 유리한지를 나타내는 이진 플래그 b(\mathcal{F})와 연결되어있습니다. 프레임이 처음 memory pool에 들어갈 때는 b(\mathcal{F})=FALSE로 설정되며, Neural Object Field에 의해 업데이트 되기 전까지는 계속 False, 업데이트가 이루어진 후에는 True로 설정된다고 합니다.
새로운 프레임 \mathcal{F}에 대한 pose와 동시에 online pose graph optimization을 위해 선택한 하위 집합의 pose도 플래그가 False일 경우 memory pool에 업데이트를 수행하고, 플래그가 True로 설정될 경우, Neural Object Filed 과정에 의해 업데이트는 계속 되지만 online pose graph optimization에 의하 수정은 진행하지 않습니다. 즉, 해당 flag에 따라 업데이트 여부가 달라지는 것입니다.
Selecting Subset of Memory Frame
효율성을 위해 pose graph optimization에 관여하는 memory pool 내의 frame은 K개로 제한합니다. 초반의 memory pool 안에 존재하는 프레임이 적을 경우에는 선택하지 않고 모두 사용하지만, memory pool이 커질 경우에 하위집합 선택 과정을 수행합니다. 이전 연구들 프레임간의 feature를 철저히 조사하는 방식을 이용하여 실시간 처리를 어렵게 하였으며, 이에 저자들은 현재 프레임의 대략적인 pose \mathcal{\tilde{E}}_t를 이용하여 memory pool의 하위 집합인 \mathcal{P}_{pg}를 효율적으로 선택하는 방식을 제안하였습니다.
momory pool 안의 프레임 \mathcal{F}^{(k)}에 대해
- point normal map을 계산한 뒤,
- visibility를 검사하기 위해 새로운 프레임 \mathcal{F}_t의 카메라 viewe에서 법선과 광선의 방향 사이의 내적을 계산합니다.
- 새로운 프레임 \mathcal{F}_t의 visibility가 임계값(해당 논문에서는 0.1로 설정)보다 높으면 \mathcal{F}_t와의 viewing overlap을 측정하기 위해 업데이트된 pose \mathcal{E}^{k}와 \mathcal{\tilde{E}}_t사이의 rotation 최단거리를 계산하고, inplane rotation은 무시합니다.
- 이후 \mathcal{F}_t와 함께 pose graph optimization을 수행하기 위해 viewing overlap이 큰 값부터 K개의 프레임을 선택하여 하위집합을 만듭니다.
Optimization
pose graph \mathcal{G} = (\mathcal{V,E})의 노드는 \mathcal{F}_t와 앞서 구한 memory pool의 하위 집합 \mathcal{V}=\mathcal{F}_t ⋃ \mathcal{P}_{pg}으로 구성되며, 해당 과정은 pose graph의 전체 loss를 최소화 하는 것을 목표로 합니다.
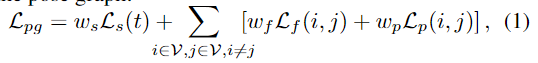
w_s, w_f, w_p는 loss에 대한 가중치로, 본 연구에서는 실험적으로 1로 설정하였다고 합니다. 각 loss term에 대해 살펴보면 다음과 같습니다.
i. \mathcal{L}_f
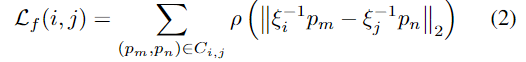
RGBD feature correspondence p_m,p_n의 유클리드 거리를 측정하는 loss로, 식(2)의 \mathcal{E}_i는 프레임 \mathcal{F}^{(i)}의 객체 pose이며, \rho는 L1 L2 loss의 장점을 결합하기 위해 제안된 loss로 outiler에 덜 민감하게 반응하는 Huber loss[2]를 의미합니다. C_{i,j}는 \mathcal{F}^{(i)}와 \mathcal{F}^{(j)} 사이의 correspondences로 1. Coarse Pose Initialization와 동일한 네트워크를 이용하여 대응 관계를 구합니다.
ii. \mathcal{L}_p
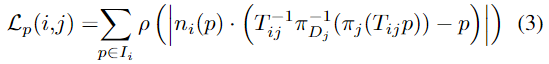
\mathcal{F}^{(i)}에서 \mathcal{F}^{(j)}로의 reprojection T_{ij}=\mathcal{E}_j\mathcal{E}_i을 이용하여 픽셀별 piont-to-plane 거리를 측정합니다. \pi_j는 \mathcal{F}^{(j)}의 이미지 I_j의 projection mapping, \pi^{-1}_{D_j}는 각 픽셀의 depth 이미지 D_j로의 inverse projection mapping을 나타냅니다. n_i()p는 \mathcal{F}^{(j)}의 픽셀 위치 p의 normal map을 나타냅니다.
iii. \mathcal{L}_s
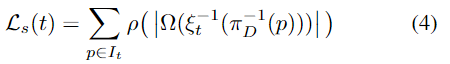
단항 loss로 현재 프레임을 이용하여 point-wise로 형태를 측정합니다. \Omega(.)는 아래의 4.Neural Object Field에서 다룰 Neural Object Filed로부터 구한 거리로, 해당 과정에서는 가중치가 고정되며, 초기 pose 예측이 어느정도 안정된 다음부터 고려하는 항이라 합니다.
pose는 카메라 pose에 대한 값으로 표시되며, 매개변수화 되어 초기 프레임의 좌표를 anchor point로 고정합니다. Gauss-Newton 알고리즘을 통해 pose graph optimization을 수행하며, 이때 memory pool 내의 b(\mathcal{F})=False인 프레임들의 pose 업데이트도 함께 수행됩니다.
4. Neural Object Field
본 논문의 핵심은 memory frames의 pose를 조정하면서 동시에 객체의 일관적인 3D 모형과 외관을 multi-view로 학습하는 것입니다. 이는 비디오별로 학습을 하며, unknown 객체에 대한 사전학습이 필요하지 않습니다. Nueral Object Field는 online pose tracking과 함께 학습되며, 시작 단계에서는 memory pool의 모든 프레임을 이용합니다. 학습이 수렴되면 최적화된 pose는 이후의 pose graph optimization을 위해 memory pool로 업데이트되어 tracking drift를 완화하는 역할을 합니다. 학습된 SDF는 online pose graph로 업데이트되어 위에서 설명한 \mathcal{L}_s를 계산합니다. Neural Object Field는 새로운 momory frames를 가져와 반복하여 학습합니다.
Object Field Representation
2가지 함수로 표현이 됩니다.
- Geometry function \Omega: x→s
- 3D Point를 입력으로 받아 방향 s를 출력합니다.
- Appearance function \Phi: (f_{\Omega(x)},n,d)→c
- geometry 네트워크로부터 얻은 중간 feature vector f_{\Omega(x)}, point의 법선 n, view direction d를 입력으로 하여 색상 c를 출력합니다.
- object field에 있는 point의 법선은 signed distance field에 1차 도함수를 이용하여 구할 수 있습니다.
: n(x) = { {\delta \Omega (x)} \over {\delta x} }
암시적인 object 표면은 singed distance field의 레벨이 0인 집합을 이용하여 얻습니다.( S = \{ x∈\mathbb{R}^3 | \Omega(x) =0 \}) SDF object representation인 \Omega는 NeRF와 비교하였을 때 두가지 장점이 있다고 합다.
- 저자들의 효율적인 ray sampling과 depth guided truncation을 결합하여 online tracking 학습이 빠르게 수렴
- 법선에 따른 암시적 정규화를 통해 smooth하고 정확한 표면을 추출할 수 있음
Rendering
object pose \mathcal{E}_t가 주어지면 픽셀을 이용하여 이미지를 렌더링합니다. 3D points는 아래의 식을 통해 서로 다른 위치로 샘플링됩니다.
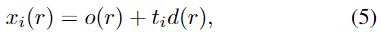
이때, o(r) 및 d(r)는 ray의 원점(카메라 초점)과 ray 방향이고, \mathcal{E}_t에 따라 달라집니다. t_i 는 ray를 따라서 위치가 결정됩니다.
ray r의 색상 정보 c는 표면 근처 영역을 합쳐 구하며, 아래의 식으로 나타낼 수 있습니다.
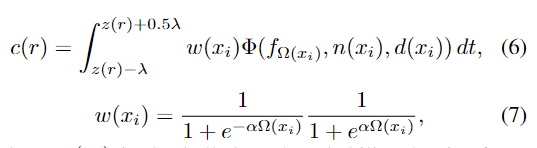
이때, w(x_i)는 종 모양의 확률 밀도함수로 point와 암시적 객체 표면의 거리 \Omega 를 나타냅니다. \alpha는 확률 밀도 분포를 soft하게 만들기 위한 항이며, 확률은 표면과 ray가 교차할 때 최대 값을 가집니다. 또한, z(r)은 depth 이미지에서의 광선의 depth 값이고, \lambda는 truncation거리 나타냅니다.
Efficient Hierarchical Ray Sampling
효율적인 rendering을 위해, pose 정보가 있는 memory frames의 point cloud를 단순히 병합하여 octree 표현으로 나타냅니다. 이후, 계층적 샘플링을 수행합니다. 먼저 복셀로 둘러싸인 N points를 균일하게 샘플링합니다. SDF 예측을 기반으로 한 중요도 샘플링을 수행하는 대신, 정규분포에서depth 값을 기반으로 N개의 point를 샘플링합니다.
Hybrid SDF Modeling
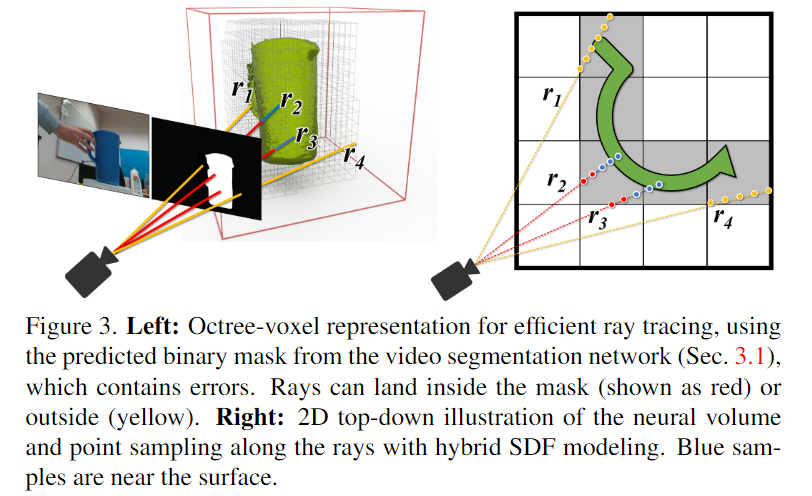
저자들은 외부적 요인에 의한 occlusion으로 인해 hybrid signed distance model을 제안하였습니다. 3가지 공간으로 나누어지며, Figure 3을 참고하시기 바랍니다.
- [Uncertain free space]
먼저 segmentation mask의 배경이나 depth 누락으로 신뢰할 수 없는 영역이 포함된 픽셀에 해당하는 points들로, Figure 3에서는 손에 의해 가려진 부분에 해당하는 r_1도 배경으로 고려합니다. uncertain free space는 완전히 신뢰하거나 무시하는 대신에 잠재적으로 물체의 표면 외부에 작은 값\epsilon을 할당하여 다중에 신뢰할 수 있어질 경우 적응이 가능하도록 하였습니다.
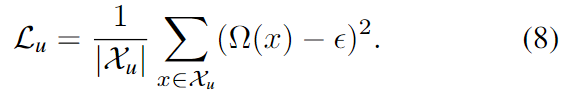
- [Empty space]
Figure 3에서 빨간 색에 해당하는 부분으로, 해당 포인트들은 depth 정보를 이용하여 truncation distance까지 판독이 가능하여 확실히 물체 표면에 존재합니다. L1 loss를 이용하여 truncation signed distance를 구합니다.
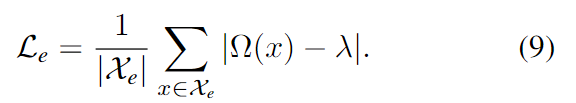
- [Near-surface space]
해당 포인트들은 Figure 3에서 파란 점에 해당하며, surface 주변의 z(r) + 0.5 \lambda 안의 거리에 있는 points 입니다. 해당 포인트들이 SDF 학습에 중요한 역할을 하며, 효율성을 위해 표면 근처의 sDF를 근사화합니다. 이때, d_x = || x-o(r)||_2 와 d_D = || \pi^{-1}(z(r)) ||_2 는 원점으로부터 sample point 까지의 거리와 측정된 depth값을 의미합니다.
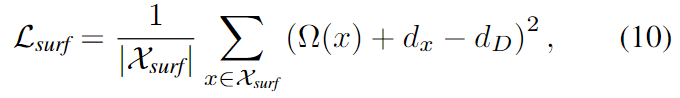
Training
아래의 식을 이용하여 학습이 진행됩니다.
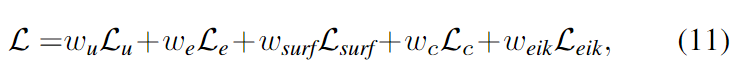
이때, L_c는 L2 loss를 나타냅니다.
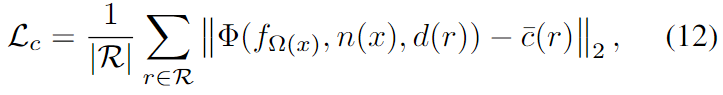
L_{eik}는 SDF near-surface space에 대한 정규화로 아래의 식으로 정의됩니다.
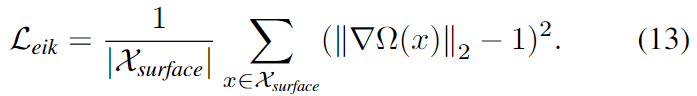
또한 학습을 수행할 때, mask를 예측하는 과정에 노이즈가 포함될 수 있으므로, mask에 대한 supervision은 수행하지 않습니다.
Experiments
Datasets
3가지의 real-world 데이터셋을 이용합니다.
- HO3D
- RGBD 비디오로 구성되며, YCB object와 이를 조작하는 사람의 손을 근거리에서 realsense 카메라로 촬영한 데이터
- GT는 multi-view를 통해 자동으로 구해짐
- 가장 최신 버전인 HO-3D_v3을 이용하였으며, 공식적인 evaluation set을 이용
- 4개의 서로 다른 object, 13개의 비디오 sequence, 총 20428개의 frame으로성
- YCBInEOAT
- RGBD 비디오로 구성되며 Azure Kinect 카메라로 촬영한 YCB 객체와 이를 조작하는 로봇 팔
- CAD 모델을 이용하는 pose estimation을 위해 구축된 데이터이지만 저자들은 사전 정보를 제공하지 않고 평가를 진행
- 5개의 서로 다른 obejct, 9개의 비디오, 총 7449개의 frame으로 구성
- BEHAVE
- RGBD 비디오로 구성되며 Azure Kinect 카메라로 object를 조작하는 사람 촬영
- 원거리에서 촬영
- 심각한 occlusion이 자주 발생하는 단일 view로 평가
- rigid object만을 이용하여 공식 evalutation set으로 평가
- 16개의 서로 다른 객체, 70개의 비디오, 총 107982 frame으로 구성
Metrics
6D Pose Estimation에서 사용하는 ADD/ADD-S metrics를 이용하여 평가를 수행하였습니다. (자세한 것은 이전 리뷰를 참고해주세요!)
Comparison Results on HO3D
Table 1과 Figure 5를 통해 결과를 리포팅하였으며, 6D Pose Estimation과 3D Reconstruction에서 모두 다른 방법론보다 크게 성능이 개선된 것을 확인할 수 있습니다.
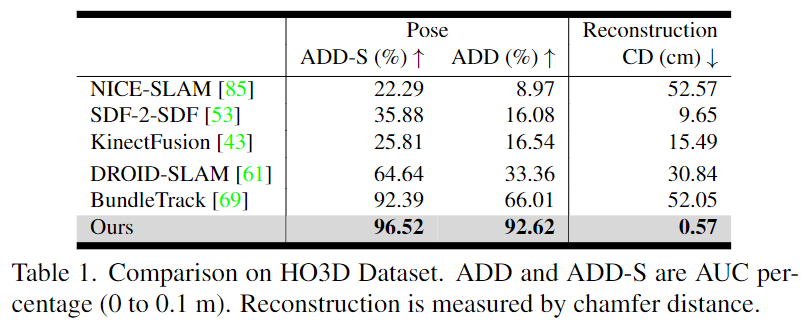
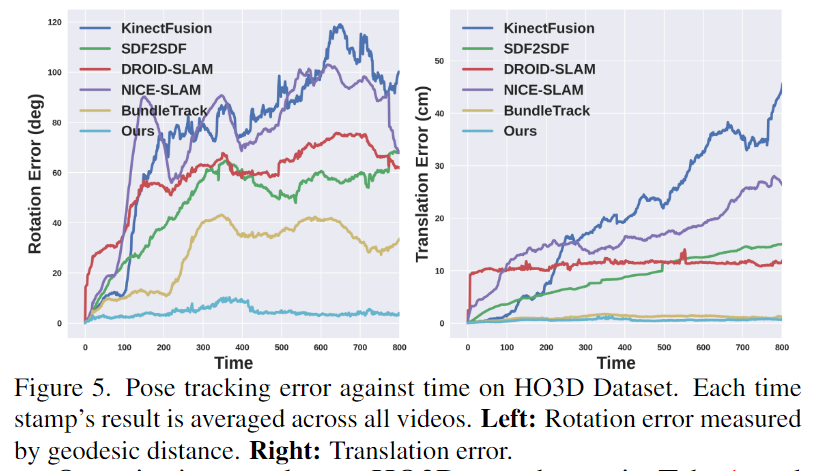
Figure 4는 정성적 결과로, 손에 의해 심각하게 가려지거나 self-occlusion, 적은 texture cue, 조명 반사와 같은 challenge한 환경이 포함된 비디오로, 이러한 어려운 조건에도 불구하고 다른 방법론 대비 고품질의 3D reconstruction을 얻을 수 있는 것을 확인할 수 있습니다. 그리고 2번째 열의 이미지의 경우 GT보다 정확할 때도 있다고 이야기합니다.

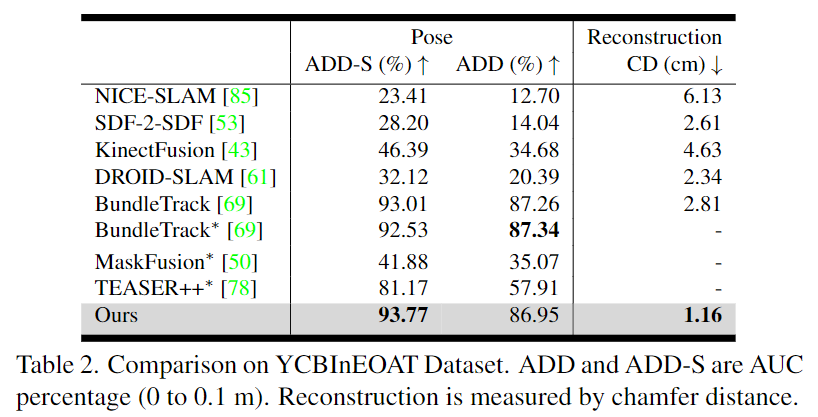
Comparison Results on YCBInEOAT
로봇 팔과 물체 사이의 상호작용을 촬영한 데이터셋으로, 카메라의 제한적 view와 로봇 팔로 인한 occlusion 문제가 발생합ㄴ디ㅏ. 저자들으리 방법이 ADD-S와 3D reconstruction에서 가장 좋은 결과를 보였으며, ADD의 경우 SOTA 성능과 비슷한 성능을 달성하였습니다. 저자들은 ADD의 SOTA 성능인 Bundle Track 방식의 경우 reconstruction에서는 좋지 못한 결과를 보인다는 것을 함께 언급하며 저자들이 제안한 방식을 어필합니다.
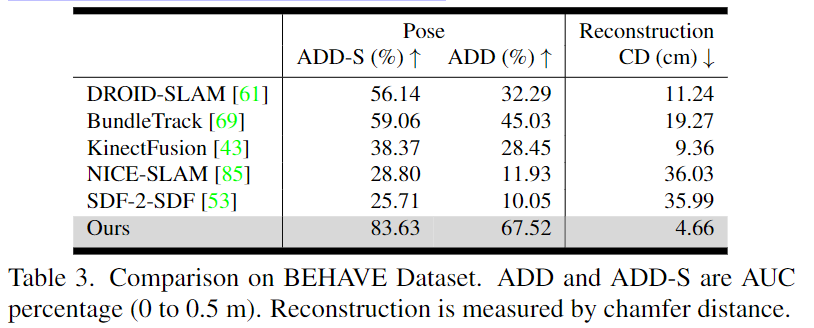
Comparison Results on BEHAVE
해당 데이터의 경우 단일뷰이며, zero-shot세팅이므로 광장히 hard한 케이스라 합니다.; (1) 사람이 물체를 들고 카메라로부터 멀리 떨어지는 경우 complete occlusion이 발생하고, (2) 인간이 물체를 들고 흔들어 심각한 motion blur와 갑작스련 이동이 자주 발생하는 데이터이며, (3) 속성과 크기가 매우 다양한 대상들을 포함합니다. 또한 (4)비디오가 카메라에서 멀리 떨어져 있으므로 depth를 감지하기 어렵습니다. 이러한 데이터 셋의 어려움에도 불구하고 저자들이 제안한 방식은 가장 뛰어난 성능을 보이며 기존 방식과도 성능이 크게 개선된 것을 확인할 수 있습니다.
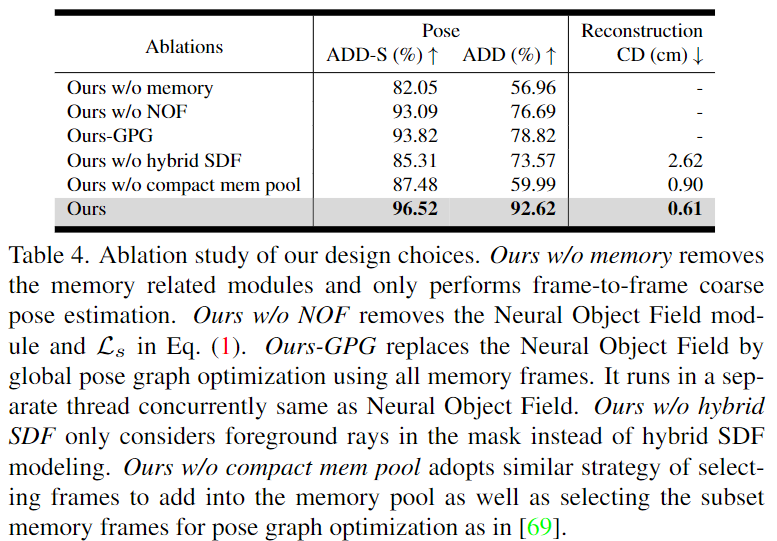
Ablation Study
각 요소에 대한 ablation study 결과입니다. 저자들은 memory가 없을 경우 tracking drift를 완화하기 위한 장치가 없어지므로 성능이 크게 떨어진다고 분석하였습니다. hybrid SDF가 없을 경우 윤곽 정보를 무시하고 memory frame의 pose를 보정할 때 오차로 인해 bias가 생길 수 있고 이로 인해 pose tracking의 안정석이 떨어지고 3d reconstruction 정확도가 떨어진다고 분석하였습니다.
Conclusion
본 연구는 단일 RGBD 비디오에서 6 DoF object tracking과 3D Reconstruction을 위한 새로운 방법론을 제안하였습니다. 이는 초기 frame에서 segmentation을 수행한 뒤, online graph pose optimization과 Neural Field representation을 함께 활용하여 빠른 움직임과 부분적/전체 occlusion, texture 부족, 빛 반사등의 challenge한 상황에서도 작동 가능하며, 다양한 데이터에서 SOTA 성능을 보였습니다.
Reference
[1] Ho Kei Cheng and Alexander G Schwing. “XMem: Long- term video object segmentation with an Atkinson-Shiffrin memory model.” In ECCV , 2022.
[2] Peter J Huber. Robust estimation of a location parameter. In Breakthroughs in statistics, pages 492–518. Springer, 1992.
안녕하세요, 좋은 리뷰 감사합니다.
NeRF를 이용한 방법론이 6D pose estimation에 최근에 많이 적용되고 있는 것 같습니다.
1. Approach 중 첫 번째인 Coarse Pose Initialization 섹션에서 Feature matching 은 어떤 것을 사용하나요? 일반적으로 사용하는 SIFT와 같은 전통적인 detector를 사용하는지 아니면 최근에 사용하는 딥러닝 기반의 detector를 사용하나요?
2. 1번 질문에 대한 추가적인 질문으로, coarse to fine 기법을 사용하는 줄 알았는데 coarse pose만 사용하는 것은 refinement를 굳이 하지 않아도 됐던 것인지 관련된 ablation study가 있는지 궁금합니다.
3. Approach 중 네 번째인 Neural Object Field 중 기존의 NeRF에 적용되었던 Hierarchical Ray sampling과 다르게 “octree” representation에 대해 간단하게 설명해주시면 감사하겠습니다.
추가적으로 발표자료 만드는 데에 시간을 많이 써주셔서 이승현 연구원님의 개인 연구할 시간을 많이 뺏은 것 같아 죄송한 마음이 큽니다. 다음 주도 잘해보겠습니다.
감사합니다.
안녕하세요. 리뷰 읽어주셔서 감사합니다.
1. feature간의 대응 관계를 생성하기 위해 transformer 기반의 t와 t-1 프레임의 feature matching 네트워크를 이용합니다. 해당 논문에서 이용하는 featuer matching 방식은 Loftr라는 방식입니다. 딥러닝 기반의 featuer matching 방식으로, 이전에 정민님이 리뷰하신 적이 있는 방법론이네요. 자세한 내용은 아래의 링크를 참고해주세요!(http://server.rcv.sejong.ac.kr:8080/2023/06/30/cvpr2021-loftr-detector-free-local-feature-matching-with-transformers/)
2. 해당 네트워크는 refinement라는 과정 대신, memory pool 내의 프레임들과의 비교를 통해 pose update를 수행합니다. 즉 pose 정보를 더 정교화 하는 과정은 유사하게 수행됩니다.
3. octree는 8진 트리 형식으로, 노드가 8개로 생성이 됩니다. 아래의 그림이 octree관련 표현입니다.

[1] Jiaming Sun, et al., “Loftr: Detector-free local feature matching with transformers.” CVPR 2021
안녕하세요 ! 좋은 리뷰 감사합니다.
long-term tracking으로 인해 발생하는 문제를 막기 위해서 과거 프레임의 정보를 유지하는 것이 중요하다고 말씀해주셨는데, 이 문제점이라는 것이 어떤 것을 의미하는 것인지 잘 유추가 되지 않아 추가 설명해주시면 감사하겠습니다 ! 또한 멀티뷰의 다양성 측면을 고려하여 정보가 풍부하다고 판단될 경우에만 메모리 풀에 추가하는 것인데 정보가 풍부하다는 것은 결국 메모리 풀에 들어가 있는 이전 프레임과 비교했을 때 포즈 정보의 차이가 일정 이상 날 경우를 의미하는 것이 맞을까요 ? sparse한 프레임이 가능하다고 말씀해주셔서 이전 프레임과 너무 유사한 위치에서 촬영되었을 경우 메모리 풀에 넣지 않는다고 이해하는 것이 맞는지 궁금합니다.
감사합니다.
안녕하세요. 리뷰 읽어주셔서 감사합니다.
먼저, 여기서는 long-term tracking drift 문제로, 장기간에 걸쳐 오차가 누적되는 것과, occlusion이 발생하는 등 중간에 challenge한 시나리오가 포함될 경우, 가려지던 object다 다시 나타나는 것을 모델이 스스로 연관 짓기 어렵다는 것입니다.
또한, 저자들은 overlap이 0.1 이상이며, in-plane rotation이 아닌 경우를 memory pool에 추가하므로 sparse하고 다양성을 확보한 pool frames를 만들 수 있다고 이야기합니다.
안녕하세요 이승현 연구원님 좋은 리뷰 감사합니다.
우선 논문의 task는 실시간 6d pose tracking, 3d reconstruction으로 rgbd 비디오 데이터를 사용하여 neural object field의 pose graph optimization과 memory pool을 사용하여 두 task를 동시에 수행하는 것으로 이해하였습니다.
논문을 읽고 몇 가지 질문이 있는데요, 우선 기초적인 질문일 수 있지만 neural scene representation 분야란 무엇인지 알려주실 수 있나요? 설명해 주신 바에 따르면 3d reconstruction의 한 분야인 듯 한데요, 학습에는 depth map과 해당 map에서 물체의 위치를 나타내는 gt mask가 주어지고, 정적인 객체를 여러방향에서 촬영하여 생성한 reconstruction을 gt와 비교하는 supervised 방식으로 학습하는 것으로 이해하였습니다. 그런데 여기서 object에 대한 gt mask가 무엇인지도 궁금합니다.
다음으로는 memory pool생성 과정에서 질문이 있는데요, multi-vierw의 다양성 측면에서 정보가 풍부하다는 것이 어떤 의미인가요? 이미 memory pool에 포함된 프레임과 회전 거리를 비교하였을 때 거리가 먼 것을 선택하여 pool에 추가하는 것으로 이해하였는데 그렇다면 기존 프레임과 일정 threshold 이상의 거리를 가지는 경우를 의미하는 것일까요?
마지막으로는 다소 논문의 내용과 거리가 있을 수 있지만 개인적으로 궁금한 점이 있는데요, 일반적으로 6d pose estimation과 3d reconstruction을 동일한 모델로 동시에 진행할 수 있는 건가요? [Fig.5]에서 기존 방법론과의 비교할 때 하나의 방법론으로 두 task를 모두 리포팅하고 있는데, 저자들의 방법론은 애초에 두 task를 함께 고려했더라도 기존 방법론들도 그러한 것인지 궁금합니다.
감사합니다.
좋은 논문 좋은 리뷰 감사합니다.
논문이 엄청 어렵네요…
파이프라인이 복잡해서 그런지 머릿속에 그림이 안그려지네요…
online pose graph optimization 수행하기 위한 Neural Object Field과 memory pool의 수행 과정을 직관적으로 설명 부탁드려도 될까요?
Neural Object Field이 어떻게 활용되는지 잘모르겠습니다 ㅜㅠ