안녕하세요, 과제에 대한 추가적인 연구가 필요하게 되어 이번에는 딥러닝 기반의 Feature Matching을 수행하는 SuperPoint를 리뷰해보았습니다. 추후 과제의 목표를 임베디드 보드에 탑재하는 것으로 하는데 FPS도 잘 나오네요. 최근에 SuperGlue도 제안이 되었지만, Graph Convolution을 다루는기도 하고 convolution을 통한 방법론이 저한테는 좀 더 적절하다고 판단하여 SuperPoint를 선택했습니다.
해당 task는 컴퓨터 비전에 대한 근본적인 연구인 것 같습니다. 저희가 URP를 통해 calibration 과정을 직접 해보았을텐데 해당 과정 중에도 이미지 내의 Feature point를 어떻게 추출하는지 다른 viewpoint에 대해 해당 Feature point가 어디에 매칭이 되는지도 알 것이라고 생각합니다. 이번 논문은 그 feature point를 뽑는 detector를 제안한 논문입니다. 저희가 아는 detector들은 SIFT, ORB 이런 것들이 있네요. 딥러닝 기반의 방법론이면 느릴 줄 알았는데 생각보다 빠른 속도로 진행해서 놀랬습니다.
리뷰 시작하겠습니다.

1. Introduction
SLAM(Simultaneous Localization And Mapping), SfM(Structure-from-Motion), Camera Calibration, Image Matching과 같은 기하학적 컴퓨터 비전 테스크의 첫 번째 단계는 이미지에서 interest point을 추출하는 것입니다. interest point는 다양한 light condition과 viewpoint에도 안정적이고 가장 중요한 repeatable한 이미지 내의 2D 위치를 나타내게 됩니다. multi-view 기하학으로 알려진 수학 및 컴퓨터 비전의 하위 분야는 이미지에서 interest point를 안정적으로 추출하고 일치시킬 수 있다는 가정 하에 설계된 정리와 알고리즘으로 구성됩니다. 하지만 실제 컴퓨터 비전 시스템의 입력은 이상적인 점 위치가 아닌, raw 이미지입니다.
convolution으로 구성된 신경망은 이미지를 입력으로 사용하는 거의 모든 테스크에서 표현력이 우수한 것도 잘 알고 계실 것이라고 생각합니다. 특히, 2D Keypoint를 예측하는 convolution 신경망은 human pose estimation, object detection, room layout estimation과 같은 다양한 테스크에서 연구가 진행되고 있습니다. 하지만 이러한 테스크의 핵심은 라벨링이 다 되어 있는 2D GT location의 데이터셋입니다.
Interest point detection를 large-scale의 지도학습 기반의 문제로 분류하고 이를 detection하기 위해 최신 convolution 신경망 아키텍처를 학습하는 것은 자연스럽습니다. 하지만 저자는 입가나 왼쪽 발목과 같은 신체 부위를 detect하도록 네트워크를 학습시키는 인체의 keypoint 추정과 같은 의미론적 테스크와 비교해보았을 때, interest point detection의 개념은 의미론적으로 잘못 정의되어 있다고 하지만 interest point에 대해 강력한 supervision 기능을 갖춘 convolution 신경망을 학습하는 것은 결코 쉬운 일이 아닌데요.
그래서 저자는 사람의 supervision을 통해 실제 이미지에서 interest point를 정의하는 것 대신에 self-training을 통해 self-supervised 하도록 하는 해결책을 제안하게 됩니다. 이러한 방법을 통해 사람이 large-scale에 대해 직접 annotation을 하지 않고 interest point detector 자체의 supervision을 통해 실제 이미지에서 pseudo-GT interest point 위치를 가지도록 설계합니다.
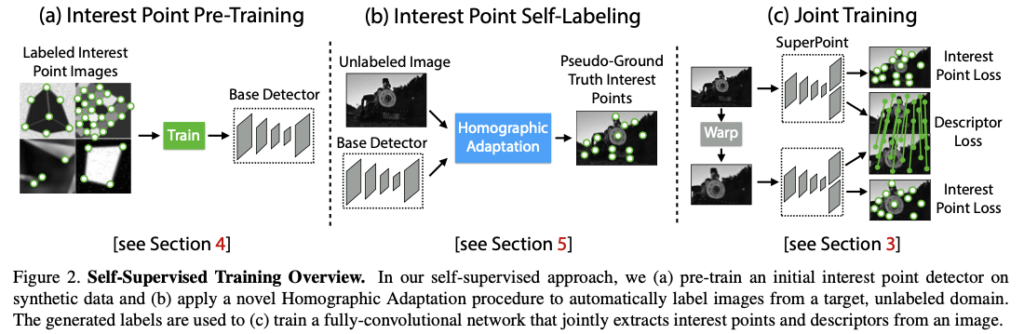
Pseudo-GT interest point를 생성하기 전에 먼저 그림2(a)에 해당하는 Synthetic Shapes 라는 합성 데이터셋에 대해 생성한 수백만 개의 예제샘플에 대해 Fully-Convolution 신경망을 학습합니다. 합성 데이터셋은 interest point의 위치가 모호하지 않은 단순한 기하학적 shape으로 구성되어 있습니다. 이렇게 학습된 detector를 MagicPoint라고 부르고, 합성 데이터셋에서 기존의 interest point보다 훨씬 뛰어난 성능을 보여줍니다. MagicPoint는 domain adaptation에 대한 어려움에도 불구하고 실제 이미지에서 우수한 성능을 발휘합니다. 그러나 다양한 이미지의 texture와 pattern에 대한 기존의 interest point detector와 비교할 때 MagicPoint는 potential한 interest point 위치를 놓치는 경우가 많았다고 합니다. Real 이미지에서 이러한 성능에 대한 격차를 해소하기 위해 Homography Adaptation을 제안합니다.
homography Adaptation은 interest point detector의 self-supervised 학습을 가능하게 하도록 설계되었습니다. 이렇게 하면 입력 이미지를 여러 번 왜곡하여 interest point detector가 다양한 viewpoint와 scale에서 장면을 볼 수 있도록 도와줍니다. MagicPoint detector와 함께 Homograpy Adaptation을 사용하여 detector의 성능을 향상시키고 pseudo-GT interest point을 생성하는 것이 그림2(b)입니다. 해당 결과에 대한 detector의 이름을 SuperPoint로 명명했습니다. robust하고 repeatable한 interest point를 detect한 후 가장 일반적인 단계는 이미지 매칭과 같은 더 높은 수준의 sementic task를 위해 각 포인트에 고정된 차원을 가지는 descriptor 벡터를 적용하는 것입니다. 따라서 마지막으로 SuperPoint를 descriptor의 서브네트워크와 결합하게 되는데 이는 그림2(3)을 나타냅니다. SuperPoint 아키텍처는 멀티스케일의 feature map으로 구성되어 있기 때문에 interest point에 descriptor를 계산하는 추가적인 네트워크를 설계합니다.
2. Related Work
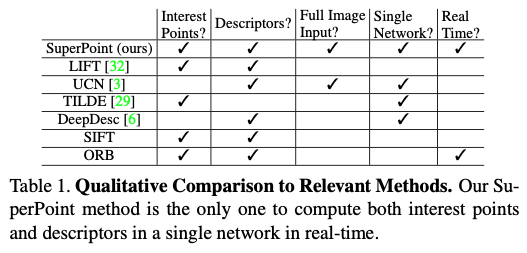
표(1)은 각 detector들에 대해 비교하여 정리를 해놓은 것입니다. 저자의 approach는 다른 self-supervised 방법인 syn2real domain adaptation 방법과도 비교할 수 있습니다. homography adaptation과 유사한 접근 방식은 equivariant landmark transform이라고 합니다. 또한 Deep Image Homography estimation도 유사한 self-supervised strategy를 사용하여 global transformation을 추정하기 위해 학습 데이터를 생성합니다. 하지만 해당 방법론들도 SLAM 및 SfM과 같은 테스크를 수행하는 것에 비해 일반적으로 필요한 interest point와 point correspondence가 없다고 합니다.
3. SuperPoint Architecture
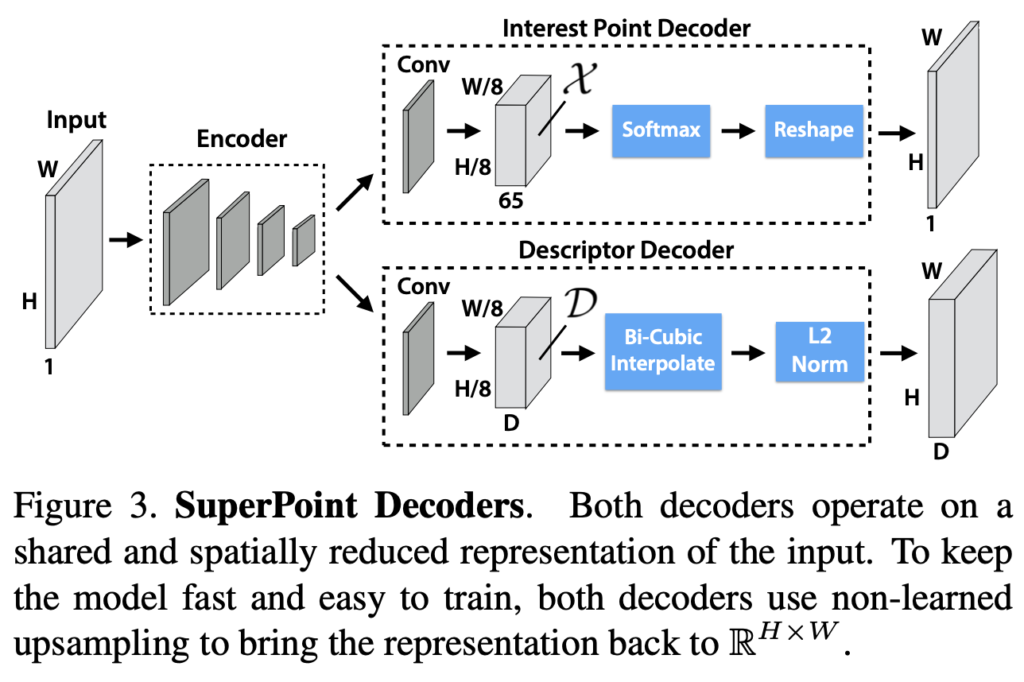
원본 크기의 이미지에서 연산을 진행하는 single forward pass에서 고정된 길이를 가지는 descriptor와 함께 interest point를 detect하는 것을 생성하도록 설계한 그림(3)과 같은 SuperPoint라는 신경망 아키텍처를 설계했습니다. 해당 모델에는 입력된 이미지의 차원을 다루고 줄이기 위한 single shared encoder가 있고 앞선 encoder를 통과하고 2개의 docoder로 된 헤드로 나뉘게 됩니다. 각각은 interest point detection을 위한 헤더와 interest point description을 위한 각각의 branch 마다의 가중치를 학습하도록 설계했습니다.
3.1. Shared Encoder
encoder에는 이미지의 차원을 줄이기 위해 VGG와 같은 네트워크 구조를 backbone으로 사용하게 되는데요. 해당 encoder에는 conv layer, down-sampling을 위한 max-pooling, non-linear activation function으로 이루어져 있습니다. 해당 max-pooling은 3개를 사용하였으며 원본 입력 크기의 1/8크기를 가지는 W, H를 정의하게 되는데요. low-dim feature map에서의 output을 cell이라고 하고 encoder에서 2×2 non-overlapping max pooling 연산 3개를 수행하면 8×8 픽셀이 생성되게 됩니다.
3.2. Interest Point Decoder
해당 interest point detection의 경우 출력의 각 픽셀은 입력에서의 해당 픽셀에 대한 ‘pointness’일 확률에 해당하게 됩니다. dense한 예측을 위한 일반적인 아키텍처 설계에는 encoder-decoder에 대한 pair가 있고 pooling 또는 interpolation convolution을 통해 공간에 대한 resoluton을 낮춘 다음 up-convolution을 통해 원본 resolution으로 다시 upsampling합니다. 하지만, upsampling 같은 경우 computational cost가 크게 드는 경향이 있다고 합니다. 또한 aliasing 현상과 같은 계단 현상이 나타날 가능성도 있다고 합니다. 그래서 저자는 interest point detection head를 앞선 문제들을 해결하기 위해 명시적인 decoder를 설계하였다고 합니다. 그림에 보면 65개의 채널을 가지는 것을 볼 수 있을텐데요. 이는 8×8 겹치지 않는 그리드 영역 + no interest point(dustbin)에 해당합니다. 해당 \mathcal X에 대한 softmax를 취하고 dustbin이 제거되면 reshape을 진행합니다.
3.3. Descriptor Decoder
descriptor head에서는 \mathcal D \in \mathbb R^{H_{c} \times W_{c} \times D}를 계산하게 되는데, 이때 \mathbb R^{H \times W \times D}로 가지는 출력을 가지도록 설계를 하고 L2-정규화된 고정된 길이의 descriptor의 dense map을 출력하기 위해 descriptor의 semi-dense grid를 출력합니다. 이때 해당 grid는 8픽셀마다 하나씩 하도록 설계합니다. 이와같이 설계한 이유는 descriptor를 dense하게 학습하는 것보다 semi-dense하게 학습하면 메모리를 줄는 효과가 있다고 합니다. 그 다음, decoder에서는 descriptor의 bicubic interpolation을 수행하고 L2-정규화를 수행하여 학습하지 않는 descriptor decoder를 설계했다고 합니다.
3.4. Loss function
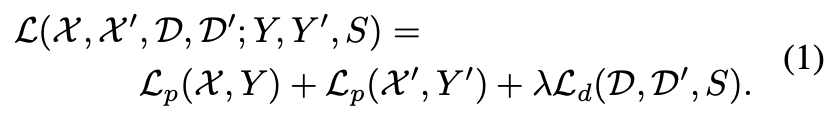
loss function으로 식(1)과 같이 사용하게 되는데요. \mathcal L_{p}는 interest point detector에 대한 loss이고 \mathcal L_{d}는 descriptor에 대한 loss를 나타냅니다. 저자는 합성적으로 왜곡된 이미지 쌍을 사용하게 되는데요.
(a) Pseudo-GT interest point 위치
(b) 두 이미지를 연관시키는 무작위로 생성된 homography \mathcal H의 GT correspondence
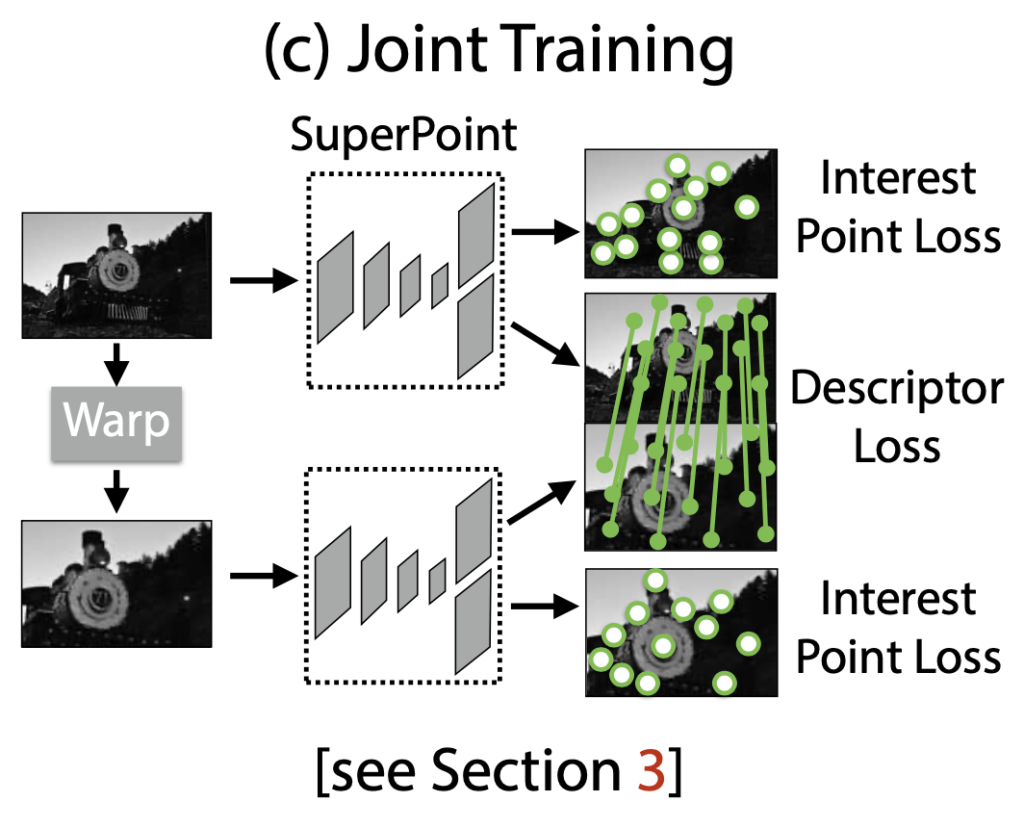
위 그림과 같이 이미지 Pair에 대한 각 loss를 동시에 계산합니다.
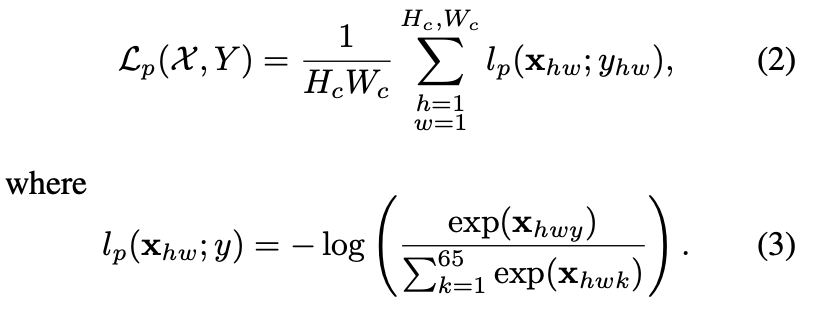
좀 더 수식적인 설명을 해보면, detector loss function인 \mathcal L_{p}는 이전에 정의했던 cell x_{hw}에 대한 cross-entropy loss이고 해당 GT interest point 라벨 Y와 개별적인 항목의 집합을 y_{hw}로 나타냅니다.
descriptor loss \mathcal L_{d}는 모든 descriptor의 cell pair에 적용되고, 첫 번째 이미지에서 d_{hw}이고, 두 번째 이미지에서 d’_{h’w’}입니다. 이때 (h, w)셀과 (h’, w’) 셀 차이의 homography로 인한 상관관계는 식(4) 같이 쓸 수 있습니다.
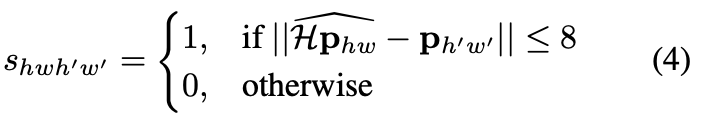
이때, \mathbf p_{hw}는 (h, w) 셀의 센터 픽셀의 위치를 의미하고, \widehat{\mathcal H \mathbf p_{hw}}은 homography를 해당 cell의 위치에 곱하여 마지막 coordinate로 나누어 표현합니다. 즉 homogeneous coordinate로 표현하는 것으로 보면 될 것 같습니다. 최종적으로 descriptor에 대한 loss function은 식(5)와 같이 정의할 수 있습니다.
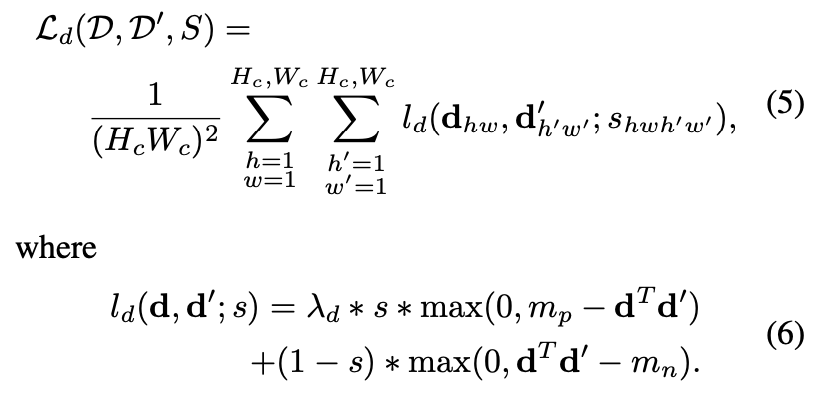
4. Synthetic Pre-Training
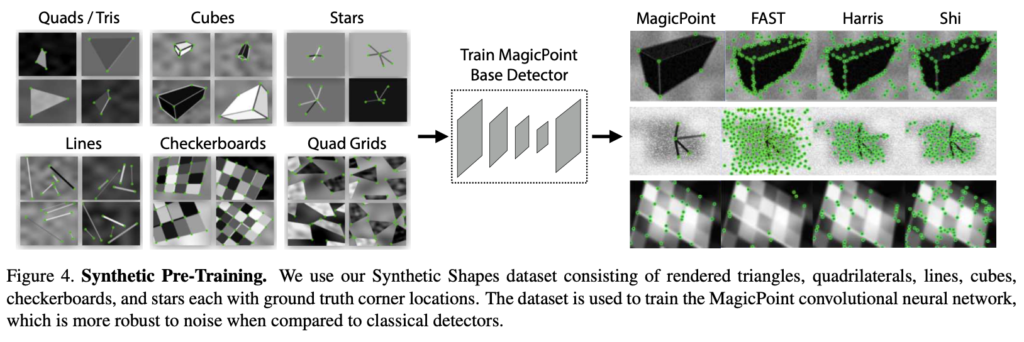
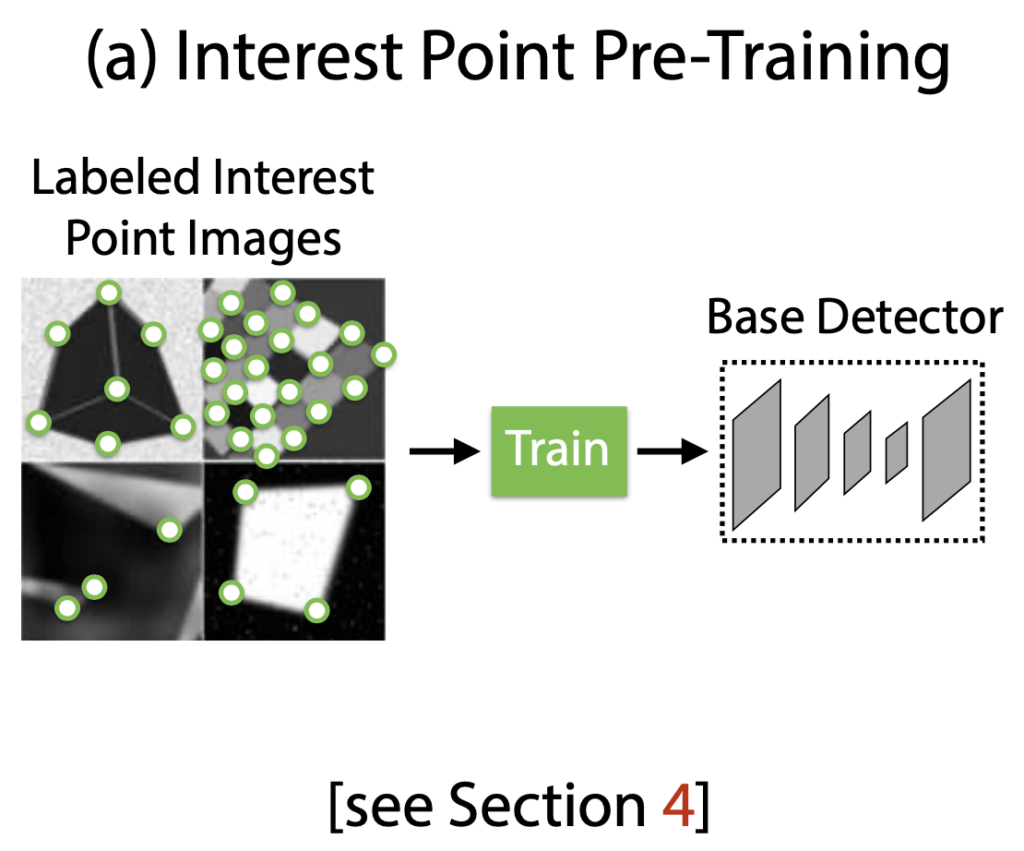
이번 section에서는 pseudo-labeling을 어떻게 했는지에 대해 살펴보겠습니다. 라벨이 지정되지 않은 이미지에 대해 interest point label을 생성하기 위해 homography adaptation과 함께 사용되는 MagicPoint라는 base detector를 self-supervision으로 학습하는 방식에 대한 설명들이 되겠습니다.
4.1 Synthetic Shapes
저자는 large-scale의 synthetic 데이터셋을 구축하고 이름을 Synthetic Shapes라고 합니다. 해당 데이터셋은 synthetic 데이터 quadrilaterals, triangles, lines, ellipses에 대해 렌더링을 거치고 2D geometry를 구성했다고 합니다. 예시들은 그림(4)를 보시면 됩니다. 데이터셋의 작은 타원의 중심과 선분의 끝점을 사용하여 interest point를 모델링함으로써 ambiguity를 제거할 수 있습니다.
합성이미지가 렌더링되면 각 이미지에 homographic warpping을 적용하여 학습 샘플들을 늘립니다. augmentation을 통해 학습 샘플을 늘린다고 생각하시면 될 것 같습니다.
4.2. MagicPoint
descriptor head를 제외한 나머지 SuperPoint 아키텍처를 앞서 언급한 합성데이터를 통해 사전학습한 모델을 저자는 MagicPoint라고 이름을 지었습니다.
그림(4)의 우측을 보면 다른 전통적인 방법과 비교해봤을 때, 상당한 성능 차이를 볼 수 있을 것 입니다.

합성데이터 셋의 존재하는 1000개의 이미지에 대한 mAP를 측정한 결과를 표(2)에 리포팅한 결과 입니다. 기존의 detector들은 이미지에 noise가 존재할 때 어려움을 겪는 것을 그림(4)의 결과를 통해 정량적으로 평가할 수 있습니다.
앞선 실험을 통해 MagicPoint는 합성데이터에 대해 매우 잘 동작한다는 것을 알게 되었지만, 실제 이미지에는 정상적으로 잘 동작할까요? 결과적으로는 맞다고 말을 할 수 있지만 저자가 원하는 만큼의 성능은 나오지 않았다고 합니다.
5. Homographic Adaptation
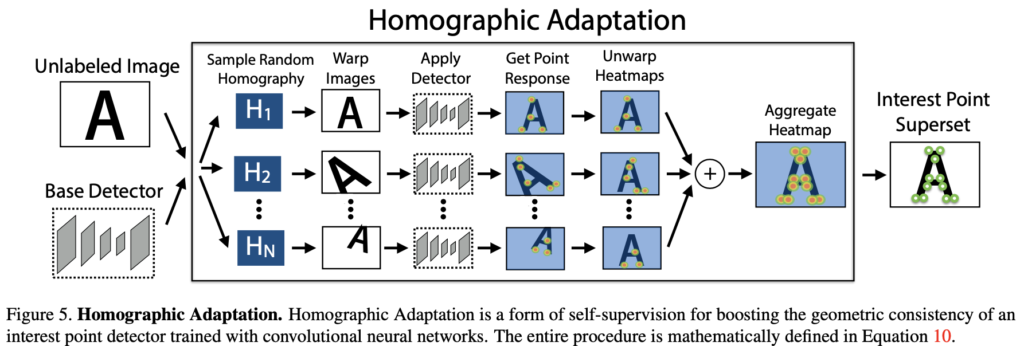
저자는 Real 데이터에 대해서도 원하는 만큼의 결과를 얻기 위해 새로운 방법론을 제안하게 됩니다. base interest point detector와 타겟 도메인의 라벨이 지정되지 않은 MS-COCO와 같은 대규모 데이터셋으로부터 self-supervise를 하도록 설계합니다. 먼저 타겟 도메인의 각 이미지에 대한 interest point의 위치의 pseudo-GT을 생성하고나서 기존의 supervised 방법론을 통해 학습을 진행합니다. 해당 방법론의 핵심은 입력 이미지의 warpping을 copy한 것에 대한 Random Homography를 적용하고 해당 결과를 결합하는 것을 Homographic Adaptation이라고 정의합니다. 즉, Homography Adaption을 통해 두 이미지 사이의 camera motion을 알 수 있도록 하는 것이며 각 첫 번째 이미지 위의 keypoint 위치들이 두 번째 이미지 위에 그대로 옮길 수 가 있게 됩니다. 이를 self-labeling을 하는 방법이라고 합니다.
5.1. Formulation

식(7)의 f_{\theta}는 adaptation하고자 하는 초기 interest point 함수를 나타내며, I는 입력 이미지를 나타내고, \mathbf x는 앞선 함수를 통해 나온 결과 interest point를 나타냅니다.
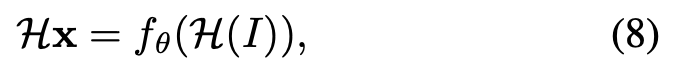
\mathcal H은 random homography를 나타냅니다. 이상적인 interest point 연산자는 homography에 대해 covariant해야 합니다. 출력이 입력에 따라 변환되는 경우, 함수 f_{\theta}는 \mathcal H covariant입니다. 즉, 모든 Homography에 대해 만족하므로 식(8)을 도출 할 수 있게 됩니다.
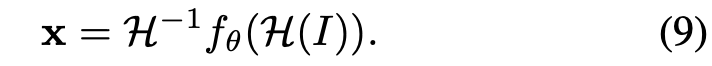
식(8)의 homography-related term(좌변)에 inverse 취해주면 식(9)를 얻을 수 있습니다.
실제로는 detector는 완전하게 covariant하지 않게됩니다. 다른 homography equation을 사용했으므로, 다른 interest point \mathbf x를 가지게 됩니다. homography의 기본 아이디어는 충분히 큰 random \mathcal H 샘플에 대해 summation을 수행하는 것입니다. 따라서, 향상된 superpoint detector인 식(10)과 같이 \hat F(I; f_{\theta})를 사용하게 됩니다.
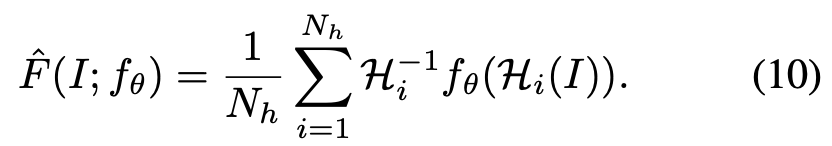
5.2. Choosing Homography
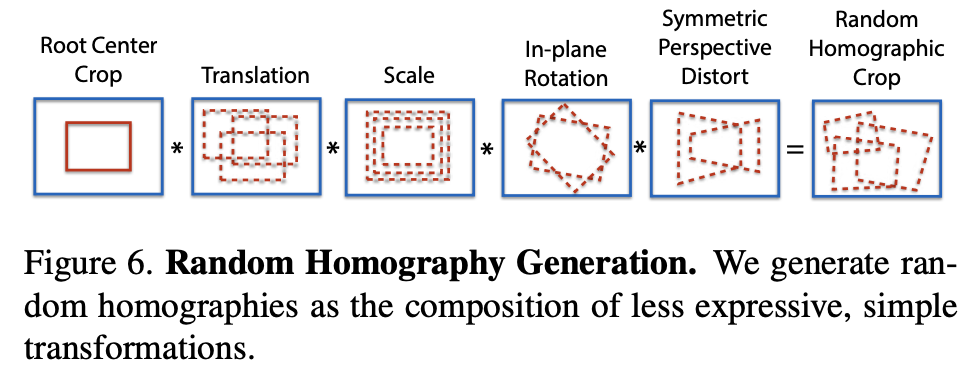
모든 3×3 행렬이 homography adaptation에 적합한 것은 아닙니다. 좋은 homography란 camera transformation을 그럴듯하게 표현하는 것을 의미합니다. 이를 위해 저자는 homography를 좀 더 단순하면서 표현력이 덜한 transformation로 변환시킵니다. 각 변환에 대해 샘플링을 한 과정을 그림(6)과 같이 나타낼 수 있습니다. 이때, homographic warp 정도를 N_{h}라는 하이퍼파라미터를 사용하여 조절하였다고 합니다.
5.3. Iterative Homographic Adaptation

그림(7)을 통해 맨 처음 행이 initial이고 밑으로 갈수록 반복적인 Homographic Adaptation을 통해 성능이 조금씩 향상되는 것을 볼 수 있습니다.
6. Experiments
6.1. System Runtime
모델의 sing forward pass는 480 × 640 크기의 입력으로 약 11.15ms에 실행되는데 이때 point detection과 semi-dense descriptor map을 둘 다 생성합니다. semi-dense descriptor에서 더 높은 480 × 640 해상도의 descriptor를 샘플링하려면 전체 dense descriptor map을 생성할 필요 없이 detection된 1000개 위치에서 샘플링하면 됩니다. 해당 경우에는 Bicubic interpolation과 L2-Norm을 진행하게 되는데 이때는 CPU 연산을 하므로 약 1.5ms가 걸리고, GPU에서 시스템의 총 런타임은 약 13ms 또는 70FPS로 추정된다고 합니다.
6.2. HPatches Repeatability
실험에서는 MS-COCO 이미지에 대해 SuperPoint를 학습시키고 HPatches 데이터셋에서 평가를 진행했다고 합니다. HPatches에는 696개의 고유한 이미지가 포함된 116개의 장면이 포함되어 있습니다. 처음 57개 장면은 조명의 변화가 크고 나머지 59개 장면은 시점의 변화가 큽니다.
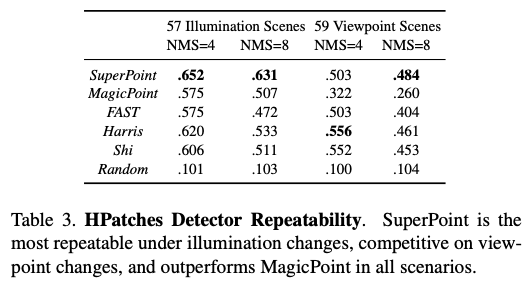
요약하면, MagicPoint를 SuperPoint로 변환하는 데 사용된 homography adapdation 기법은 특히 큰 시점 변경 시 반복성을 크게 향상시킵니다. 결과는 표(3)에 나와 있습니다.
SuperPoint 모델의 interest point detection 정도를 평가하기 위해 해당 데이터셋에서 반복성을 측정하게 됩니다. MagicPoint 모델(Homography Adaptation 적용 전)과 OpenCV를 사용하여 구현된 FAST, Harris, Shi와 비교합니다. NMS를 변경하면서 각 scene 조건에 대한 scene에 실험을 진행하였고 이때는 \epsilon=3으로 고정 후, 해당 픽셀을 정확한 거리로 사용했다고 합니다.
SuperPoint 모델은 조명이 변경될 때 기존 디텍터보다 성능이 뛰어나며, 다음과 같은 조건에서는 기존 디텍터와 동등한 성능을 발휘합니다. 기존 디텍터와 동등한 성능을 발휘합니다.
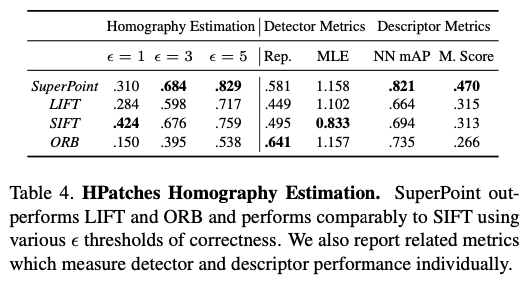
6.3. HPatches Homography Estimation
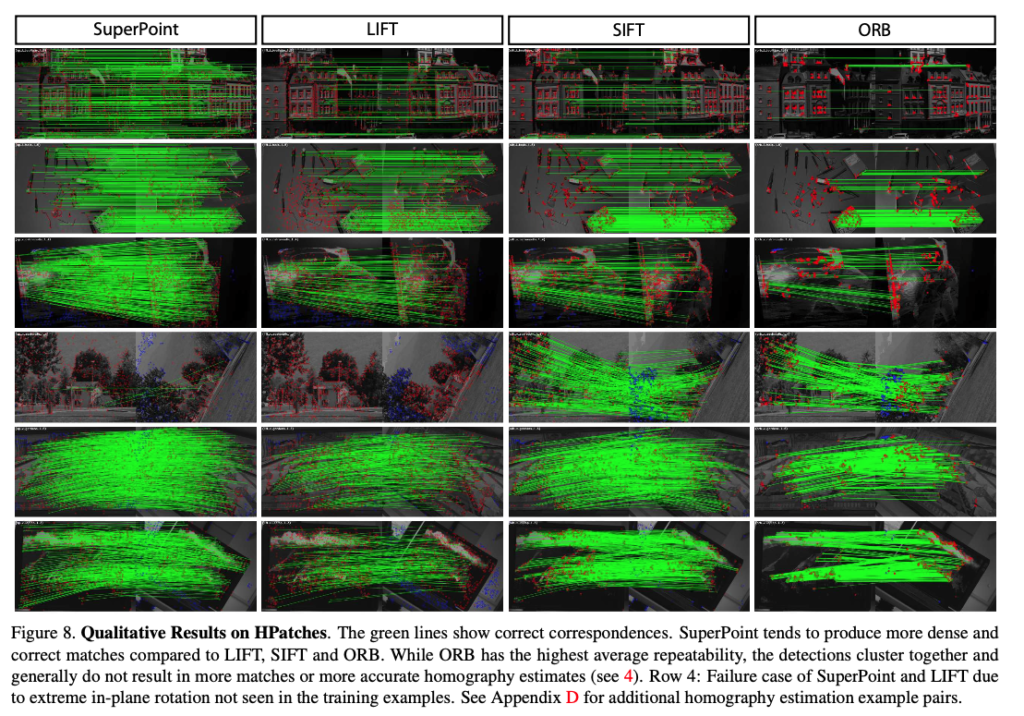

실험결과가 조금 잘 안보이긴 하는데 설명을 덧붙여보면, 나머지 이미지 보다 차이점이 뚜렷해 보이는 1행 6행에 대해 살펴보겠습니다.
1행에 대한 기본적인 viewpoint의 차이에 대한 detector의 성능을 본 모습입니다. 제가 생각했던 것은 SLAM에도 ORB descriptor를 사용하는 것으로 알고 있는데 생각보다 성능이 많이 안 좋은 것을 보고 놀랬습니다. 이렇게 feature matching의 성능이 안 좋으면 camera pose가 정확하게 계산될 수 없을 거라고 생각이 드네요.

2행은 rotation이 꽤 많이 들어간 이미지로부터 detector의 성능을 실험을 한 모습입니다. 해당 모습을 보면 SuperPoint가 성능이 가장 좋아 보이긴 하지만 완전하게 rotation-invariant 하지 않은 것을 볼 수 있습니다.
7. Conclusion
저자는 Homography adaptation이라는 self-supervised domain adaptation 프레임워크를 사용하여 학습된 interest point detection 및 descriptor를 위한 Fully-Convolution으로 이루어진 신경망 아키텍처를 제안했습니다. 향후 연구로는 homography adaptation이 semantic segmentation 및 object detection에 사용되는 모델에 적용하여 성능을 향상시킬 수 있는지 여부를 조사할 예정이라고 합니다. 또한 interest point detection과 description이 서로 어떤 이점을 주고 받는지 살펴볼 예정이라고 합니다.
이상으로 리뷰를 마치겠습니다.
리뷰 잘 읽었습니다.
자세하게 잘 설명해 주셔서 이해하는데에 어려움이 없었습니다.
5절에 homographic adaptation 절에 대해서 추가적인 질문을 드리고 싶습니다. 해당 과정은 Figure 2 (b)에 해당하고, 간단한 기하학 도형을 통해 학습된 magicpoint 가 실제 real domain에서도 point를 잘 detect 하도록 하기 위해서 수행하는 것으로 이해했습니다.
(이해한것이 맞을까요? ㅎ)
1. 아무튼 여기서 ‘interest point의 위치의 pseudo-GT을 생성하고나서 기존의 supervised 방법론을 통해 학습을 진행’ 한다고 하셨는데, 구체적으로 어떻게 진행되는지 이해가 잘 안돼서 한번만 더 설명해 주시면 감사하겠습니다.
2. 또한 저자가 real 데이터에서도 원하는 결과를 얻고자 5절의 내용을 수행했다고 하셨는데, 해당 과정이랑 domain gap을 완화하는 것과의 상관성을 잘 모르겠습니다. (제가 homographic adaptation) 절에 대해 충분한 이해를 하지 못해서 드리는 질문일수도 있습니다.
감사합니다!
리뷰 읽어주셔서 감사합니다.
먼저, 권석준 연구원님께서 잘 이해해주신 것 같습니다.
1. 그림(5)를 가지고 설명을 했어야 했는데, 조금 빈약했던 것 같습니다. 먼저 MS-COCO와 같은 데이터셋은 분명 unlabeled 이미지일 것입니다. 이를 가지고 self-supervised 방법론을 적용하게 되는데요. 이때 라벨링을 적용하기 위해 pseudo-GT 만들어주기 위해 Base detector로부터 interest point를 찾고 homography → warpping을 적용하고 등등을 하는 과정이 식(7), 식(8), 식(9)이고 마지막으로 식(10)을 통해 aggregation 합니다. 이렇게 aggregation 된 영역을 GT로 supervised learning을 하는 것이라고 생각하시면 되겠습니다.
2. 저도 처음에 이해가 잘 안됐던 내용 중 하나입니다. 사실 Homography Adaptation은 domain의 격차를 줄이고자 제안된 방법론이라고는 하지만 self-labeling을 위한 방법론이고 이러한 self-labeling을 통해 pseudo-GT를 생성할 수 있으므로 MS-COCO와 같은 real 데이터에서도 강건하게 작용할 수 있다라는 것이 핵심인 것으로 이해를 했습니다.
감사합니다.
안녕하세요. 좋은 리뷰 감사합니다.
interest point decoder 같은 경우 출력 픽셀은 입력에서의 해당 픽셀에 대한 pointness일 확률에 해당한다고 하셨는데, 이는 해당 입력 pixel이 keypoint인지 아닌지 classification을 하는 것으로 이해해도 괜찮을까요 ?
또, detector metrics와 descriptor metrics에 대해 각각 설명해주실 수 있으실지 . . .
감사합니다.
리뷰 읽어주셔서 감사합니다.
1. 네, softmax를 태우니 classification으로 해석할 수 있겠습니다.
2. Homography estimation의 평가지표가 크게 2개로 나뉘어집니다.
– Detectror Metrics(Rep., MLE)
– REP : repeatability로, 이미지 pair 한쌍에 대해서 detector에 대한 repeatability를 계산합니다. 이때 epsilon을 사용하여 두 점 사이의 정확한 거리에 대한 threshold를 정하여 나타냅니다.
– MLE : Corner Detection에 대한 AP를 계산하고, 해당 AP에 대한 분석을 보완하고 정확한 detection을 위해 Corner Localization Error를 구합니다. 해당 LE(Localization Error)에 대한 평균을 계산합니다.
– Descriptor Metrics(NN mAP, M. Score)
– NN mAP : Nearest Neighbor mAP로 epsilon에 대한 threshold에 대해 descriptor가 어느정도로 변별력을 갖는지를 평가합니다. 해당 평가지표는 Nearest Neighbor matching strategy를 사용하여 AUC를 측정하게 되는데, 이미지 쌍에 대해 균등하게 계산되어 평균을 계산합니다.
– M. Score : Matching Score로 interest point를 찾는 detector와 descriptor를 합친 전반적인 성능을 측정합니다. 이때, GT에 대응되는 비율을 측정하게 됩니다. 이때, 해당 평가 지표는 이미지 쌍에 대해 균등하게 계산됩니다.
해당 내용들의 구체적인 수식은 Appendix에서 다루고 있으니 참고해주시면 감사하겠습니다.
감사합니다.
양희진 연구원님, 좋은 리뷰 감사합니다. 결국 모델이 human supervision 없이 스스로 interest point를 찾아내게 하는 방법론으로 이해했습니다. 제가 마지막으로 공부한 feature extractor가 handcrafted feature를 추출하는 SIFT였는데, 이제 이것도 CNN모델이 완전이 대체하는 것 같습니다. 질문이 있는데, superpoint architecture 부분 3.4 Loss function에서 interest point detector에 관함 손실함수 항이 (X,Y)와 (X’,Y’) 두 개 입니다. 항을 두 개 사용하는 이유에 대한 설명이 가능할까요?
리뷰 읽어주셔서 감사합니다.
질문 주신 해당 내용에 대해서는 논문에서 설명이 없어 제 나름대로의 해석을 해봤는데, descriptor의 경우 해당 이유로 ‘을 쓰는 것을 보고 해당 task의 경우 multi-view이므로 한 이미지 쌍에 대한 loss를 구해야하므로 term이 두 개로 나뉘어진 것으로 이해를 했습니다.
감사합니다.
안녕하세요 리뷰 잘 보았습니다.
superpoint에서 가장 중요한 부분이 homography adatpation이라고 저는 개인적으로 생각하는데, 리뷰에 설명하신 내용이 조금 모호하게 나타나서 이해하는데 어려움이 조금 있네요. 마침 권석준 연구원이 이에 관해서 질문을 했었고 그에 대한 답변을 보았는데 아직도 이해가 되지 않는 부분이 있어 글을 남깁니다.
MS COCO와 같은 unlabeld data가 있을 때, 해당 데이터 (이때 어떠한 기하학적 변환을 적용하지 않은 영상)에 대하여 base detector로 하여금 keypoint 및 descritpor를 먼저 추출하는 것이 아니라 입력 데이터에게 다양한 homography를 적용한 후 base detector를 통해 각각의 keypoint 및 descriptor를 추출한 다음 다시 inverse homography하여서 원본 상태로 되돌려 aggregation하는 것 아닌가요? 수식 9번에서도 영상에 먼저 호모그래피를 적용한 후 detector를 태운 후 다시 inverse homography를 적용해 key point x를 추정하는 것 같구요.
요약하면 희진님이 작성해주신 내용들과 실제 homography adaptation의 목적과 과정이 깔끔한 매칭이 잘 안된다고 생각이 들어요.
만약 저가 Homography Adaptation의 목적에 대하여 설명한다면, supervised learning을 하기 위한 pseudo label을 만들어야 하는데, 이때 단순히 1장의 원본 영상에서 추론된 결과값을 pseudo GT로 삼는 것이 아니라 N개의 호모그래피를 통해 다양한 기하학적 변환을 적용하고 이들 각각에 대하여 추론된 결과값들을 합쳐서 GT 집합(superset)을 만들고자 하는 것이다.
이에 대해 더 자세히 설명하면 원본 영상 I에 각각 random homography를 적용을 해서 N개의 Image를 만들고 이들을 독립적으로 base detector에 태워서 key point들을 추출하게 되는데, 이때 해당 포인트들이 다시 원본 영상 I와 동일한 기하학적 위치에 자리잡기 위해서 처음 영상에 적용해주었던 호모그래피의 역행렬을 적용시켜 원본 영상과 동일한 좌표계로 고정을 시키는 과정이 필요로 합니다… 라는 식으로 명확하게 그 목적과 과정을 차근차근 설명을 할 것 같아요.
근데 지금 리뷰 또는 답글에 작성해주신 내용들을 살펴보면 >> (“이때 라벨링을 적용하기 위해 pseudo-GT 만들어주기 위해 Base detector로부터 interest point를 찾고 homography → warpping을 적용하고 등등을 하는 과정이 식(7), 식(8), 식(9)이고 마지막으로 식(10)을 통해 aggregation 합니다.”, 또는 “해당 방법론의 핵심은 입력 이미지의 warpping을 copy한 것에 대한 Random Homography를 적용하고 해당 결과를 결합하는 것을 Homographic Adaptation이라고 정의합니다. 즉, Homography Adaption을 통해 두 이미지 사이의 camera motion을 알 수 있도록 하는 것이며 각 첫 번째 이미지 위의 keypoint 위치들이 두 번째 이미지 위에 그대로 옮길 수 가 있게 됩니다.” )라는 식에 내용들은 무언가 모호하고 애매하게 설명하는 바람에 명확한 이해를 하는데 더 어려움이 생기는 것 같아요.
예를 들어 입력이미지의 warpping을 copy한 것에 대한 random homography가 무슨 뜻인가요?
그리고 “pseudo GT를 만들어주기 위해” 라는 문장 바로 뒤에 “Base Detector로 interest point를 찾고… “라는 문장이 오는게 아니라 먼저 “이미지에 random한 homography를 적용하여 영상을 변환(warping)시키고” 라는 문장을 넣어서 영상이 먼저 warpping이 되었다를 설명해주어야 뒤에 “homogrpahy –> warping”이라는 내용이 나올 수 있는거죠. 게다가 엄밀히 말하면 base detector를 통과한 이후에 warping을 적용하는 것은 homography가 아니라 inverse homography이기 때문에 이 부분도 명확히 기존 변환에 대한 역변환이다라는 것을 설명해야만 읽는 사람들이 오해가 없을 것 같아요.
댓글을 쓰다보니 질문이 아니라 검토 및 피드백..? 이 되어버렸는데 앞전에 NeRF 리뷰에서도 주어와 목적어에 대한 누락 등 어떤 과정을 설명하는데 있어서 중간중간 누락된 표현들이 있어 리뷰를 이해하는데 어려움이 있었고 이를 지적했었는데 이번에도 비슷한 상황인 것 같아서 이렇게 댓글로 남기게 되었습니다. 이런 습관만 고치면 앞으로 좋은 리뷰 및 논문을 쓸 수 있을 것 같아서 그러니 넓은 마음으로 이해 부탁드려요ㅎㅎ..
감사합니다.
좋은 논문 좋은 리뷰 감사합니다.
엄청 좋지만 어려운 논문 읽고 리뷰하느라 고생하셨습니다.
나중에 도움 많이 될겁니다.
질문 하나 던지고 갈게요!
학습에 활용되는 GT인
(a) Pseudo-GT interest point 위치
(b) 두 이미지를 연관시키는 무작위로 생성된 homography H의 GT correspondence
는 구체적으로 어떻게 만드고, 어떤 구성인가요?