이번 리뷰 논문은 상용 깊이 센서로부터 바로 취득한 깊이 정보를 noise & hole이 없는 clean depth로 보완하기 위해 제안된 논문이며, 이를 위한 대규모 데이터 셋이 없다는 문제점을 지적하며 데이터 셋 제작 방법과 제안한 데이터셋을 활용하여 보완된 깊이 정보하는 모델을 제안합니다.
추후 진행할 연구에서도 해당 논문에서 사용한 데이터셋 제작 방법을 활용할 예정이며, 더 나아가 저자가 공개한 코드에 대해 활용 가능 여부를 분석하여 응용 혹은 적용할 예정입니다.

Intro

상용 깊이 센서(e.g. RealSense, ASUS Xtion, MS Kinect …)는 3차원 인지를 활용하는 많은 태스크에서 활용하는 센서로 3차원 인지가 필요한 어플리케이션에서는 높은 정확도를 요구하기 때문에 3차원 정보의 정확도를 높이기 위해 필수적으로 요구되는 센서에 해당합니다. 그럼에도 불구하고 사용 깊이 센서의 깊이 정보 품질은 여전히 한계를 가지고 있습니다. 이러한 이유는 해당 센서들의 설계 목적이 높은 3D geometry를 얻는 것보다는 빠른 추론 속도를 요하기 때문이죠. 위와 같은 특징으로 인하여 상용 깊이 센서들은 센서의 물리적 한계와 낮은 처리 능력으로 인한 노이즈와 누락된 값으로 인해 문제를 일으킵니다.
물론, 깊이 영상의 낮은 품질을 해결하기 위해 많은 방법론이 등장했습니다. 특히, 깊이 영상 복원 태스크와 깊은 연관성을 가질만한 CNN 기반의 color image enhancement, restoration, super-resolution은 높은 성과를 이뤄냈습니다. 허나, 해당 기법들은 large-scale datasets을 활용하여 각 태스크에 맞는 영상 특징 정보를 알아서 추출하도록 학습하고 이를 결합하여 원하는 결과 값을 추론 할 수 있도록 학습이 가능했습니다. 예시로 super-resolution을 들자면, 고품질 영상을 의도적으로 헤쳐 저품질 영상을 만들어 자기-지도 데이터셋을 생성하여 학습이 가능합니다. 이러한 특징으로 대량의 데이터 셋 생성이 어렵지 않죠.
이에 반해 RGBD는 오직 저품질의 영상만을 취득 할 수 있기 때문에 color image에서 이용한 자기-지도 데이터셋 구성이 불가능합니다. 이러한 사유로, 딥러닝 기반 접근 방식 (~지도 학습)을 활용하기 어려울 뿐더러 이를 위한 대용량 데이터셋을 제공하기 어렵다는 문제가 있습니다.
해당 논문에서는 노이즈가 존재하는 raw(원본) depth와 이에 대응되는 clean depth로 구성된 대규모 깊이 이미지로 구성된 데이터 셋을 제안합니다. RGB-D 스트림을 이용한 dense 3d reconstruction을 활용해 깨끗하고 완전한 장면 현상 (scene geometry)을 생성하는 전략을 이용하비다. 원본 깊이 영상이 입력으로 들어오면, 대응되는 clean depth를 dense 3d reconstruction에서 카메라 포즈를 이용하여 생성합니다. 해당 과정에서 structure-based image similarity (SSIM)을 적용하여 카메라 위치의 잘못된 정렬과 3d geometry의 불일치로 인해 발생하는 낮은 품질의 깊이 쌍을 필터링합니다.
이렇게 생성된 raw-clean depth pair-wise dataset을 활용하여 noise & hole을 제거하기위해 coarse-fine scale 구조의 multi-scale Laplacian pyramid based neural network과 structure preserving loss를 제안합니다.
Method
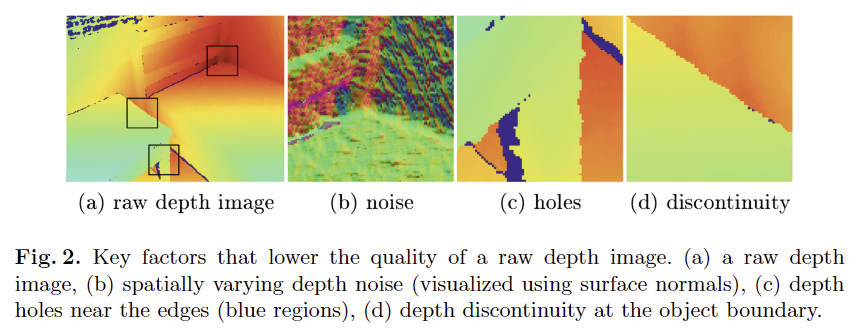
저자는 상용 RGB-D camera로 촬영된 원본 영상을 처리할 때 고려해야할 3가지 주요 문제(이는 Fig 1,2에서 볼 수 있습니다.)를 depth noise, depth hole, depth discontinuity로 정의하고 이에 대해 중점적으로 다룹니다.
Depth noise. 원본 깊이 영상은 일반적으로 강한 불균일한 노이즈 패턴을 가지고 있습니다. RGB-D camera는 투영된 패턴(structured light cameras)를 분석하거나 방출된 빛의 비행 시간을 측정(ToF cameras)하므로, 노이즈 분포는 표면 재질 및 카메라와 물체의 거리에 영향을 크게 받습니다. 그러므로 상용 깊이 센서들은 노이즈를 제거하기 위해 일반적으로 고정된 커널 사이즈의 필터를 통해 보완하나, 다양한 노이즈 형태의 노이즈를 보완하기에는 충분하지 않습니다. 저자는 본인들이 제안한 CNN의 기반의 모델이 multi-scale feature를 추출하여 적응적으로 영상을 보완할 수 있다고 합니다.
Depth hole. Depth noise와 유사하게 RGB-D의 물리적 한계로 인한 depth values의 누락이 발생합니다. 이러한 hole들은 일반적으로 light emitter와 image sensor의 시점 차이로 인해 물체의 경계면에서 발생합니다. 또한, 표면 재질이 반짝이거나 빛을 흡수하는 물체에서도 깊이 값이 누락됩니다. 누락된 값들을 예측하기 위해서는 입력 장면의 로컬 및 전역적인 컨테스트 정보를 이해해야만 합니다. 저자는 제안된 모델이 fine-coarse 구조로 점직적인 예측을 수행하기 때문에 가능하다고 어필합니다.
Depth discontinuity. 깊이 영상의 값은 가장 자리에 따라 강한 불연속성을 가집니다. 컬러 영상에서는 전경과 배경의 부드러운 연결을 위해 가장자리 부분에 안티앨리어싱을 수행하기도 합니다. 깊이 영상에서는 가장자리에 안티앨리어싱이 수행되면 전경과 물체 사이에 떠 있는 조각들이 생성 될 수 있습니다. 저자는 가장자리의 평활화를 방지하기 위해 gradient-based structure preserving loss를 제안하며, 이를 통해 깊이 영상의 부드러운 엣지에 대해 강한 패널티를 부여한다고 합니다.
Dataset quality. 지도 학습을 이용하여 원본 노이즈 깊이 영상을 깨끗한 깊이 영상으로 향상 시키기 위해서는 데이터셋의 퀄리티가 매우 중요합니다. 저자는 특히 hole filling과 discontinuity preserving filtering에 있어 두 깊이 쌍에 대한 가장자리와 geometry features의 정확한 공간 정렬이 필요하다고 합니다. 저자는 데이터셋 생성 시에 SSIM을 이용하여 두 깊이 영상 쌍의 구조적 유사도를 측정하는 필터링을 수행하여 낮은 품질의 깊이 쌍을 제외하여 데이터 셋의 전반적인 퀄리티를 향상시켰다고 합니다.
++ 위 내용은 방법론을 직접적으로 풀어가지 않지만, 굳이 적어둔 이유는 풀어갈 문제에 대해 설명하고 이를 해결하기 위한 방법을 제시하는 구조가 깔끔하다고 판단하여 정리하였고, 나중에 논문 작성에 참고하고자 정리하였습니다.
Pairwise Depth Dataset Generation
이제부터는 위의 기법들을 어떻게 수행했는지에 대해 자세히 언급하도록 하겠습니다. 먼저, 데이터 셋을 어떻게 생성했는지 볼까요?
사실 raw-clean depth를 생성하는 방법이 아예 없는 것은 아닙니다. 높은 정확도를 가진 laser scanner를 활용하는 경우에는 깨끗한 깊이 영상을 생성 할 수 있습니다. 허나 이러한 방식은 추가적인 센서를 요구하는 것이기도 하며, 측정을 위해서는 고정된 위치에서 일정 시간 데이터를 취득해야 하기 떄문에 정적인 물체를 대상으로만 깊이 정보를 취득 할 수 있다는 단점이 존재합니다. 또 다른 방법으로는 모델링 정보(~synthetic scene)를 활용하는 방법이 있습니다. 아마 가장 정확하고 깔끔한 깊이 정보를 취득하는 방법이겠죠. 허나, 복잡한 센서와 물체의 물리적인 상호작용으로 발생한 감소된 real raw depth를 모사하는 것은 굉장히 어렵기 때문에 해당 방법 또한 해결책이 될 수 없습니다.
그렇기에 해당 논문에서는 추가적인 장비나 3d 모델링 없이 RGB-D 원본 깊이 영상으로부터 추론된 dense 3D surface reconstruction으로부터 raw-clean depth image pairs를 획득하는 방법을 활용합니다.
3D Reconstruction Dataset. 실제 세계에서 성공적인 결과물을 만들기 위해서는 가능한 한 많은 실제 세계의 장면이 포함된 정보들이 필요합니다. 이를 위해 저자는 1,500 공간에서 백만장의 RGB-D images가 촬영된 ScanNet을 활용합니다. 해당 데이터 셋은 높은 퀄리티의 triangular mesh data와 BunddleFusion을 통해 추정된 카메라 포즈 정보를 포함하고 있습니다.
+ BunddleFusion은 RGB와 depth 정보를 활용하여 3D Reconstruction을 구성하는 Structure from Motion (SfM) 방법론에 해당합니다. KinectFusion의 후속 연구라고 보면 됩니다.
++ 즉, 3D Reconstruction을 활용한 데이터셋이라고 하는데 3D Reconstruction도 이미 만들어진 데이터셋을 가져다가 쓴거죠
입력 깊이 영상은 reconstructed triangular mesh와 예측된 카메라 포즈를 활용하여 대응되는 clean depth를 렌더링합니다. 인접한 프레임에는 겹치는 정보들이 많이 존재하기 때문에 40프레임에 1프레임만 샘플링을 진행했다고 합니다. 또한, ScanNet의 중복된 장면을 피하기 위해 40개의 장면만 선택하였다고 합니다. 결과적으로 총 4,000개의 깊이 쌍을 얻었다고 합니다. 저자가 주장하길, 깊이 정보는 복잡한 컨테스트를 가진 컬러 영상과 달리 곡선 평면과 같은 단순한 형태를 가진 정보들로 구성되기 때문에 해당 태스크에서는 수천개의 샘플링으로도 충분한 학습이 가능하다고 합니다. 마지막으로 깊이 영상의 학습 샘플들은 128×128 패치로 나눕니다. 이는 효율적인 네트워크 학습과 outlier를 다루기 위해서라고 합니다. 아래에서 자세히 다루도록 할게요.
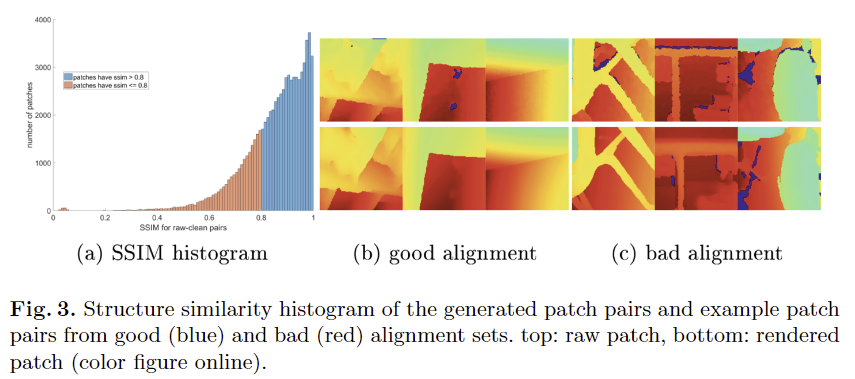
Misaligned Outliers Filtering of Dataset. 앞선 방식을 이용하여 raw-clean depth pairs를 구했지만 여전히 일부 holes을 가지고 있거나, 매끄러운 표면 현상으로 인해 딥러닝 모델을 학습 하기에는 부족하다는 문제가 있습니다. BuddleFusion이 좋은 성능을 가지고 있더라도 일부 error를 가지고 있을 수 있스빈다. 특히, 의자 다리나, 옷장 행거와 같은 얇거나 날카로운 구조를 물체에서는 geometric 통합 과정에 카메라 트래킹을 실패하여 에러가 존재합니다. 이러한 경우에는 raw-clean depth 쌍 간에 오정렬이 발생하게 됩니다. 물체의 경계면에서는 깊이 값이 빠르게 변하고 volumetric reconstruction에서는 정보가 통합되기 대문에 오정렬 문제가 크게 발생하는 문제가 있습니다. 이는 fig 3-(c)를 보면 예시를 볼 수 있습니다. 이러한 사유로 오정렬된 깊이 쌍에 대해 필터링을 수행해야만 합니다.
저자는 아주 직관적이고 단순한 방법을 사용하여 필터링을 수행합니다. SSIM을 이용하여 두 깊이 쌍 값의 구조적 유사도를 측정하여 낮은 품질의 깊이 쌍을 제거합니다. Fig 3-(a)에서는 깊이 패치 쌍에 따른 SSIM에 대한 histogram 분포도를 나타내며 SSIM < 0.8인 데이터 셋의 20%을 필터링 했으며, 원복 혹은 clean 패치에서 패치 크기에 20%가 hole인 케이스에서도 필터링을 수행했습니다. 결과적으로 56,000 depth patch pairs 구성합니다.
Laplacian Pyramid Depth Enhancement Network
이번 섹션에서는 원본 깊이 영상의 품질을 향상시키는 지도 학습 기반 CNN 네트워크와 loss를 소개합니다. 큰 임팩트는 없기 때문에 간략하게 소개하고 넘어가도록 할게요.

저자는 Super-resolution에서 좋은 성과를 낸 LapSRN을 수정한 LapDEN을 제안합니다. fig 4와 같은 U-Net 구조의 네트워크 형태를 가진 모델이며, 3 level의 다른 크기(1/4, 1/2, 1) 결과를 예측하는 coarse-fine 형태의 skip-connection 구조를 가집니다. coarse (1/4)에서는 전역적인 구조를 학습하고 1/4 scale에서는 원본 깊이 영상에서 조차 다운 샘플링으로 인해 hole과 noise 영향이 적은 상태이기 때문에 학습이 용이하다는 장점이 있습니다. 예측된 clean depth는 다음 scale에 참고할 수 있도록 가해지고 fine-scale에서는 깊이 가장자리 불연속성과 미세한 세부 사항을 선명하게 하는 잔차를 예측하는 방법만 학습하도록 진행되는 방식으로 학습을 진행합니다.
+ 저자가 모델을 학습을 진행하는데에 있어 한번에 학습을 해보니 학습에 실패했다고 합니다. 그래서 3 stage로 학습을 진행하는데 coarse-scale 부터 지도 학습을 하고 점차 scale을 느리는 방식으로 학습을 수행했다고 합니다.
Loss Functions for Training
저자는 depth의 구조적인 특성을 보완하면서 향상된 깊이 정보를 생성하기 위한 새로운 방식의 loss를 제안합니다. 전반적인 구조는 아래와 같으며, raw depth는 x, clean depth는 y, predicted clean depth \hat(y) = f(x; \theta) 에 해당합니다.
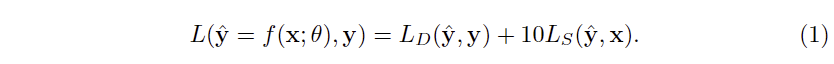
Multi-scale data losses. 먼저 L_D는 L_1으로 clean depth 간의 거리와 gradient를 CNN-based image regreesion으로 정의 할 수 있습니다. 추가로 L1을 이용하여 surface normal n을 이용합니다. surface normal는 깊이 값의 oscillating noise에 예민하기 때문에 깊이 정보의 작은 크기의 노이즈를 없애는데에 큰 도움이 됩니다. 전체적인 L_D는 다음과 같습니다.
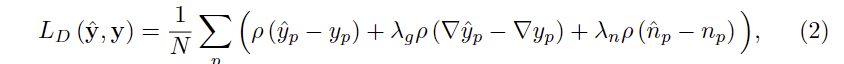
여기서 p는 Charbonnier loss function으로 하이퍼파라미터 값과 입력 값 간의 차이에 따라 L1과 L2를 적응적으로 적용가능한 loss라고 생각하시면 됩니다. (저자는 L1에 가중이 크도록 설정한 것으로 보임) 저자는 여전히 남아 있을 아웃라이어에 강인하게 작동하기 위해서 L1을 썻다고 합니다.
Structure preserving loss. 앞서 언급한 바와 같이 깊이 영상은 컬러 영상과 다르게 전경과 배경의 구분이 명확해야만 합니다. 깊이 영상의 불연속성을 유지하기 위해서는 L1과 L2로는 충분하지 못합니다. 그렇기에 저자는 원본 깊이 영상의 불연속성을 유지하기 위해서 gradient-based structure preserving loss L_S를 제안합니다. 수학적으로 불연속성을 가진 경계면에서는 큰 미분값을 가집니다. 만약 안티앨리어싱이나 블레딩이 발생한다면 이러한 현상들이 주변 픽섹들로 퍼지기 때문에 가장자리 주변의 엣지의 미분 값을 작아지게 됩니다. 이를 이용하여 L_S는 다음과 같이 정의 됩니다.
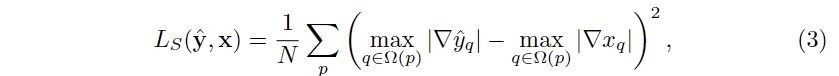
위 \omega 는 local window patch로 저자는 모든 all level of image pyramid에서 5×5로 설정했다고 합니다. 해당 손실 함수의 특징으로 원복 깊이 영상 x를 활용하여 loss를 계산합니다. 이는 렌더링된 clean depth에서 오정렬이 발생된 경우에도 강한 불연속성을 모델에게 학습 시킬 경우에, 모델이 구조적인 모호성을 얻을 수 있게 됩니다. 그렇기에 저자는 보다 확실한 원본 깊이 영상의 불연속성을 학습을 할 수 있도록 모델에게 전달하도록 합니다.
++ 저자가 이런 손실 함수를 설계한 이유가 렌더링된 clean depth에서 long tail 이슈가 보인 것이 아닌가란 의심이 듬… 렌더링 자체가 BuddleFusion에서 생성한 정보를 토대로 만들어지기 때문에 여기다 이슈를 거는 순간 많이 복잡해져 묻은 것 같음…
Experiment
Enhancement Results
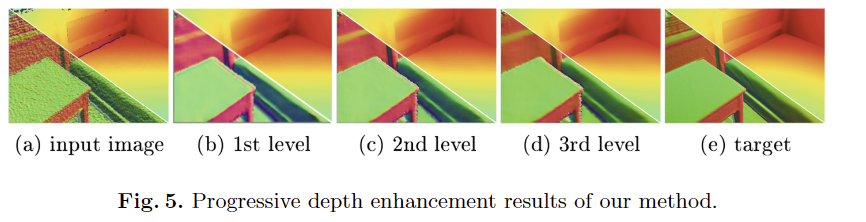

Progressive depth image enhancement. Fig 5에서 각 레벨에 따라 흐릿한 표현이 점점 향상되어져 가는 결과를 볼 수 있음. Fig 6에서는 학습 데이터 셋이 아닌 NYU에서도 평가해보니 좋은 결과를 보
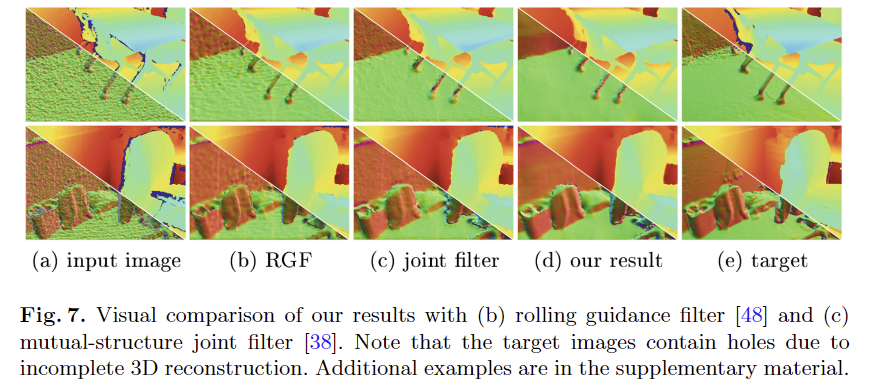
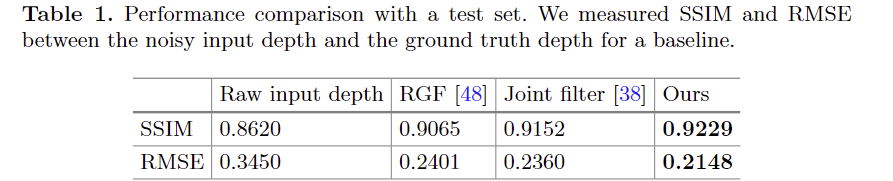
Comparison with previous methods. 해당 기법의 효과를 비교하기 위해 기존 필터링 기법을 가져와서 비교를 했으며, Fig 7과 tab 1에서 정성/정량적인 평가 결과, 가장 좋은 결과를 보임
Ablation study
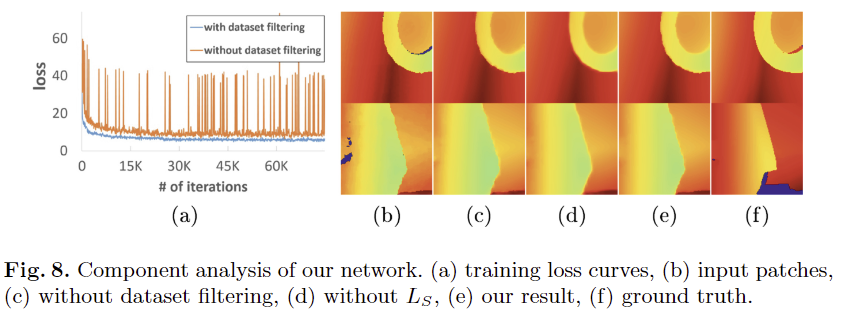
Dataset filtering. Fig 8-(a)에서 보이는 바와 같이 필터링을 수행한 데이터 셋에서 안정된 학습 결과를 보임. 필터링 전 모델 예측 값 Fig 8-(c)와 필터링 후 예측 값 fig 8-(e)을 정성적으로 비교해본 결과, 보다 깔끔하고 경계면이 두드러지는 결과를 보임
Structure preserving loss. Fig 8-(d)에서 L_S를 제거하고 학습한 결과, 경계면이 흐릿해지는 결과를 볼 수 있음
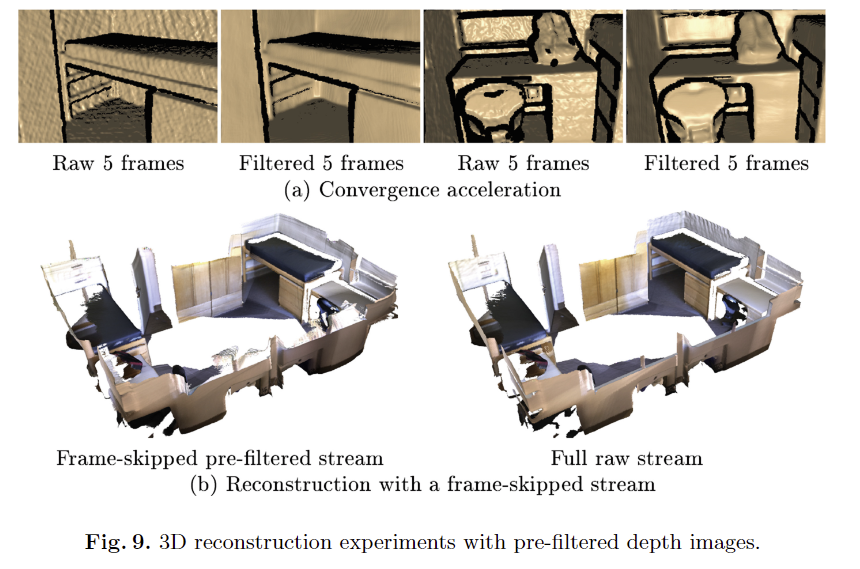
마지막으로 저자는 해당 기법이 필요한 이유를 어플리케이션 관점에서 제시를 했습니다. fig 9에서는 우리 기법을 이용하여 원본 깊이 영상을 향상 시키며 보다 적은 깊이 영상으로도 복원이 가능하다는 것을 보입니다. 이를 통해 더욱 빠른 속도로 움직이는 카메라에서도 복원이 가능하다는 점을 어필합니다.
++ 리뷰어가 이거 왜 필요해라고 물어봐서 생긴 파트 같음. 근데 이렇게 직관적으로 풀어주는 것도 나름 매력적인듯
+ limitations
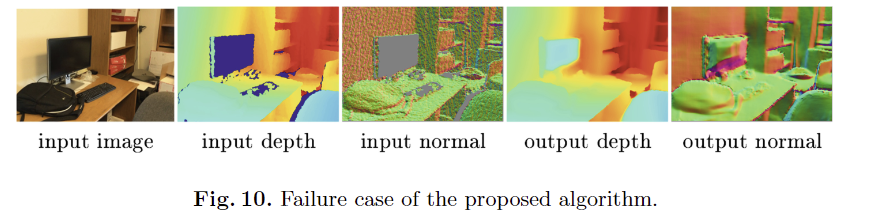
저자가 밝히길, fig 10과 같이 훈련에 적용된 패치보다 큰 hole에서는 정확한 예측이 어렵다는 문제가 발생하며, 실시간성을 얻을 정도의 속도가 나오지 않는다는 점을 언급하며, future work로 나아갈 방향을 제시함.
해당 논문을 보기 전에 저자가 사용한 방법으로 raw-clean depth pair를 얻으려고 했는데… 이게 ECCV 2018 논문으로 제안된 기법인게 진짜 재미있네요 ㅋㅋㅋㅋ 뭔가 너무 당연한건 같아서 아닌 줄 알았는데… 이런 디테일한 삽질이 필요했다니… 해당 논문 덕분에 많은 시간을 줄일 수 있게 된 것 같아서 너무 다행입니다.
안녕하세요 김태주 연구원님 좋은 리뷰 감사합니다.
지난 주 리뷰와 마찬가지로 raw depth에서 noise와 hole등을 보완하는 논문이네용ㅎㅎ
결국 이 논문의 메인 contribution은 대규모 rgbd 데이터셋의 구축으로, 3d reconstruction을 활용하였다는 부분인 것으로 이해하였습니다.
이해한 내용을 정리하자면 아래와 같은데요,
1. raw rgbd로부터 3d reconstruction을 진행하여 dense map 생성하고, 이 과정에서 3d geometry가 일치하지 않는 pair를 필터링하여 데이터셋을 구축하였고, multi-scale Laplacian pyramid based neural network를 통해 이미지를 보정하였다.
2. depth 이미지에 발생하는 noise, hole, discontinuity를 각각 multi-scale feature 추출, fine-coarse architecrture, gradient based stucture preserving loss로 해결하였다.
리뷰를 읽고 간단한 질문이 있는데요, 제가 3d reconstruction 분야를 잘 몰라 pair간의 misalignment가 발생하는 이유에 대해 설명해 주실 수 있나요? 카메라 트래킹을 실패한 어떤 이미지로 3d reconstruction을 진행한다고 할 때 해당 이미지로부터 생성된 3d와 주변 이미지들로 생성된 3d 가 서로 달라지기 때문인 것으로 이해하면 되나요?
그리고 본문의 Loss function 부분이 깨져 보이는데 확인 부탁드립니다!
감사합니다.
잘 정리해주셨네요
Q. 리뷰를 읽고 간단한 질문이 있는데요, 제가 3d reconstruction 분야를 잘 몰라 pair간의 misalignment가 발생하는 이유에 대해 설명해 주실 수 있나요? 카메라 트래킹을 실패한 어떤 이미지로 3d reconstruction을 진행한다고 할 때 해당 이미지로부터 생성된 3d와 주변 이미지들로 생성된 3d 가 서로 달라지기 때문인 것으로 이해하면 되나요?
A. 복잡하게 생각할 필요 없이 모든 센서들은 물리적인 한계로 측정 위치가 같은 곳에 있을 수가 없습니다. 어쩔 수 없이 다른 시점(view point)에서 측정되기 때문에 공간적인 misalignment가 발생합니다.