Introduction
Speaker Recognition은 음성 데이터의 발화자를 인식하는 것으로 어떤 음성 샘플이 지정된 speaker 중 어떤 사람의 음성인지 분류하는 task입니다. 주로 두 음성 샘플을 비교하여 해당 음성들이 동일한 화자로부터 나왔는지를 판별하는 방식으로 동작하게 됩니다. 대부분의 speaker recognition system은 ideal한 audio condition을 가정하고 이루어지는데요, optimal performance를 위해 background noise를 최소화하고 neutral speaking style, normal vocal effort를 사용한다고 합니다. 그러나, 저자들은 이러한 가정이 practical scenario에 비해 지나치게 단순화되어있다고 지적하였습니다.
최근 일부 연구들이 잡음을 포함한 SR에 중점을 두고 있지만, 이러한 연구들조차 speaking style은 제한되어있다고 합니다. Neutral하게 spoken된 음성들은 발화자의 vocal dynamics중 일부만을 표현 가능하게 되므로 기존 방식의 SR은 speaking style이 달라지는 경우 성능이 하락하게 되겠죠.
이에 저자들은 spoken이 아닌 다른 speaker style이 SR에 어떤 영향을 끼치는지 알아보기 위해 ‘singing voice’를 사용하였습니다. Singing은 전통적인 spoken 데이터에 비해 다양한 physiological dynamics를 가지고 있어 전통적인 SR에 새로운 challenge가 될 수 있다는 맥락에서 사용하게 된 것이죠. 여기서 physiological dynamics란 생리학적 변화로써 성대의 진동, 호흡 패턴 등을 의미하는데요, 일반적인 어조의 말하기보다 노래를 부를 경우 이러한 변화가 더 다양한 양상으로 나타나게 된다는 것으로 이해하시면 됩니다. Singing의 또 다른 특징으로는 화자에 따른 다양성에 더해 음악의 스타일/장르에 영향을 받는다는 것입니다. 따라서 저자들은 이러한 다양성을 가진 singing voice를 하나의 speaker style로 사용하여 기존의 SR시스템에 challenge를 제시하였습니다.
저자들은 이전 연구에서 JukeBox라는 singing voice dataset을 구축하고, 이를 사용하여 ‘singing’이라는 style에서의 SR을 수행하였습니다. 이때 기존 SR모델을 singing데이터로 fine tuning하는 방식을 사용하였다고 합니다. 그러나 fine-tuned 모델은 하나의 style에 대해서만 평가되어 다른 style간의 일반화 성능을 평가하지 않았다고 합니다. 또한 JukeBox 데이터셋은 사람의 노래하는 목소리에 해당하는 말하는 목소리 샘플을 포함하고 있지 않아, 즉, 사람의 노래하는 목소리를 그들의 말하는 목소리와 매칭시키거나 그 반대의 경우에 대한 cross-domain speaker verification의 utility를 제한한다고 합니다.
저자들이 밝힌 이 논문의 contribution은 다음과 같습니다. 먼저 원래의 JukeBox 데이터셋을 확장하여 JukeBox 데이터셋의 test set에 동일한 화자들의 spoken 샘플을 포함시켰습니다. 즉, 기존 데이터셋을 JukeBox-V1이라 할 때, 확장된 데이터셋인 JukeBoxV2는 다양한 speaking style 간의 SR 방법론의 평가를 가능하게 되었다고 합니다. 다음으로, 저자들은 Domain Adaptation을 적용하여 singing과 spoken이라는 서로 다른 style의 특징을 공정하게 학습하는 방법론을 제시하였습니다. 마지막으로, style 변화가 학습된 feature space에 어떤 영향을 미치는지 분석하였습니다.
Domain Adaptation-Based Speaker Recognition Framework
음성에서 speaker 모델링에 중요한 phoneme duration, mean fundamental frequency (F0), formant center frequency 등의 audio feature를 추출할 때, spoken voice와 sing voice, 즉, 서로 다른 speaker style에 따른 도메인 격차가 발생합니다. 따라서 저자들은 [Anurag Chowdhury and Arun Ross]의 fine-tuned 모델을 Domain-adaptation 관점으로 확장하여 기존 모델이 spoken과 singing이라는 두 도메인에의 일반성을 확보하고자 하였습니다.
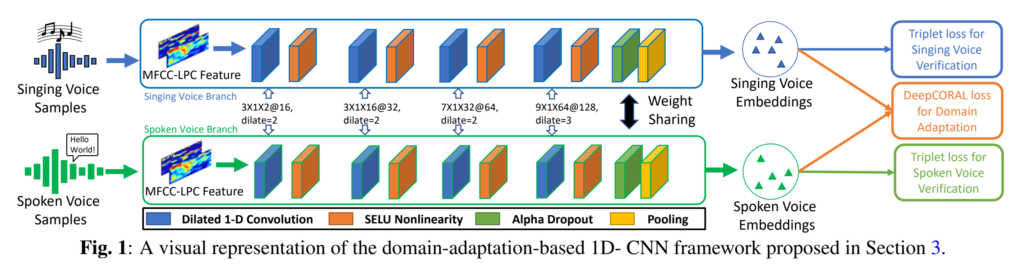
[그림1]은 논문에서 주장하는 SR모델인 domain-adaptation-based 1D-CNN의 pipeline입니다. 전체 구조를 살펴보자면 가중치가 공유되는 두 개의 동일한 1D-CNN branch로 구성되어 있습니다. 각 branch는 MFCC-LPC (audio signal의 hand crafted feature)를 CNN에 입력하여 feature vector를 추출한 다음 adaptive triplet mining에 사용됩니다.
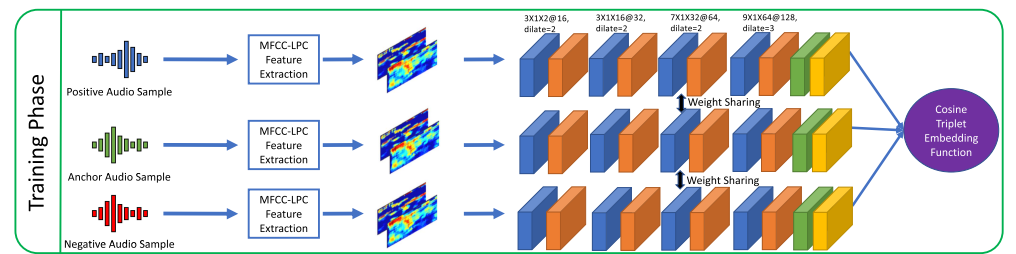
아래의 그림이 한 branch에서의 1D-CNN 구조입니다. 특정 화자의 audio sample이 anchor audio sample일 때, anchor와 동일한 화자의 음성은 positive, anchor와 다른 화자의 음성은 negative로 설정하여 {a, p, n}형태로 동일한 네트워크에 입력 후 anchor/positive는 가깝게, anchor/negative는 멀어지도록 학습합니다.
각 branch의 triplet loss는 [수식1]과 같이 정의되는데요, N개의 쌍에 대해 anchor sample과 positive sample, anchor sample과 negative sample간의 cosine similarity와 margin을 합한 형태로 구성되어 있습니다.
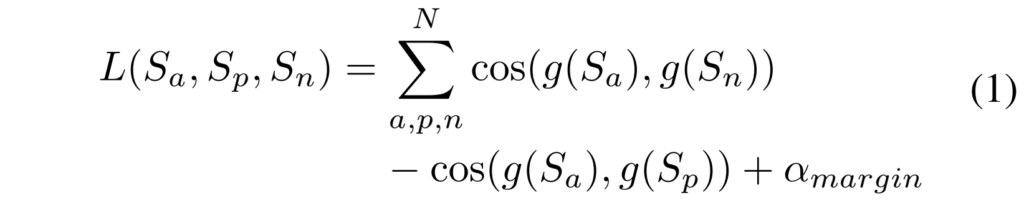
Singing과 Spoken branch에서 각각 triplet loss L_{si}, L_{sp}를 구했다면 두 branch간의 domain adaptation을 수행하기 위해 [수식2]와 같은 Domain Adaptation Loss를 사용합니다.
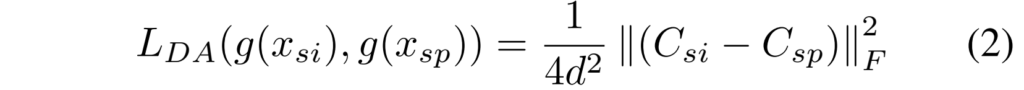
[수식2]는 DeepCORAL loss로 voice 임베딩 g(x_{si}) 및 g(x_{sp})의 공분산 C_{si}와 C_{sp} 사이의 거리를 최소화하는 방향으로 학습이 진행됩니다. 여기서 \left\| \cdot \right\|^2_F F는 squared matrix Frobenius norm이고 d는 음성 임베딩의 차원 수를 의미합니다.
각 branch의 triplet loss와 DA loss를 포함하는 전체 프레임워크의 Loss L은 아래의 [수식3]과 같습니다.
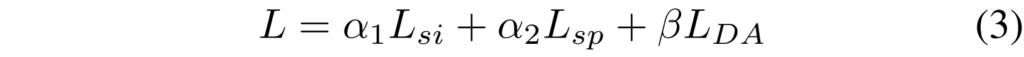
여기서 \alpha 1, \alpha 2, \beta는 각 loss에 대한 가중치로 사용자가 조정할 수 있는 하이퍼 파라미터값에 해당합니다. (실험에서는 각각 1, 10, 10로 설정하였다고 하네요)
Experiments
DA의 효과를 검증하기 위해 저자들은 세 가지 모델의 실험 결과를 비교하였는데요, 1) spoken voice 데이터인 VoxCeleb2로만 사전 학습된 baseline모델, 2) baseline 모델을 JukeBox-V1의 singing voice로 fine-tuning한 fine-tuned모델, 3) baseline 모델을 DA 방식으로 singing과 spoken voice를 모두 사용하여 fine-tuning한 Domain Adapted모델입니다.
위의 정의된 모델들은 세 가지 다른 test dataset인 1) VoxCeleb2 , 2) JukeBox-V1, 그리고 3) JukeBox-V2에서 평가되었습니다. VoxCeleb2 large scale의 spoken dataset으로 spoken-spoken에서의 평가를 수행하며, JukeBox-V1은 sining-singing 평가를, JukeBox-V2는 JukeBox-V1의 singing voice와 동일한 화자에 대해 spoken-spoken평가를 수행합니다.
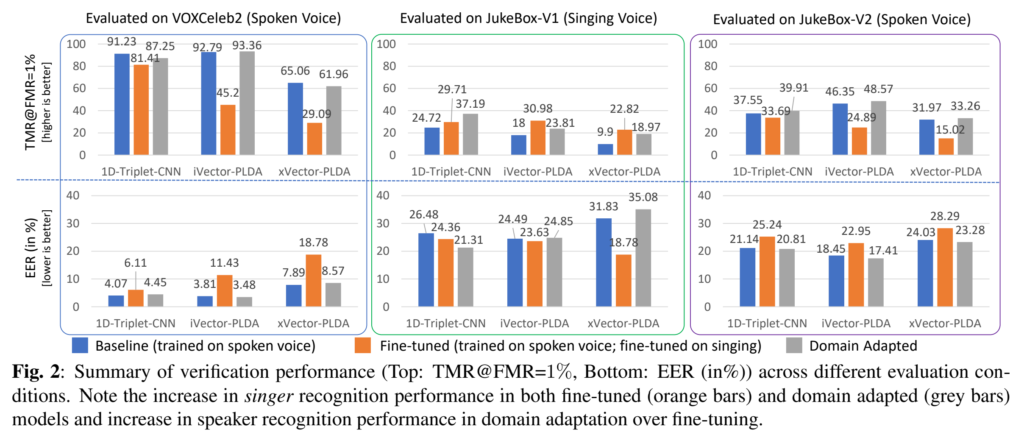
[그림2]를 보면 1D-Triple-CNN외에 iVector-PLDA와 xVector-PLDA가 있는 것을 볼 수 있는데요, 이때 i vector와 x vector는 각각 고차원의 audio 정보를 압축하는 전통적인 통계 기반 방법론이며, PLDA 또한 통계 기반 방법론이라고 이해하시면 될 것 같습니다.
[그림2]의 결과를 보자면 모든 baseline 모델은 JukeBox 데이터셋에서 spoken에 비해 singing의 낮은 성능을 보입니다. Baseline은 spoken만으로 학습된 모델인 만큼 singing이라는 도메인으로 평가 환경이 바뀌었을 때 성능 드랍이 발생한 것입니다. Baseline 모델과 비교하여 Fine-tuned 모델은 singing에서 성능이 증가한 것을 볼 수 있지만, JukeBox-V2 와 VoxCeleb2 데이터셋의 spoken의 성능은 평균적으로 약 14%와 약 31%정도 떨어진 것을 확인할 수 있습니다. fine tuning으로 인해 원래 도메인에서의 성능 하락이 발생한 것이죠. 즉, singing으로 fine-tuning된 모델이 spoken에서의 일반화 능력이 없다는 것을 보여줍니다.
저자들이 제안한 DA모델의 결가를 보자면 JukeBox-V2 데이터셋의 singing과, spoken에서 각각 평균 약 9%와 약 2%로 해당 baseline 모델보다 좋은 성능을 달성한 것을 볼 수 있습니다. 또한 DA와 fine-tuned 모델을 보면 VoxCeleb2 데이터셋에서 spoken의 성능 드랍을 평균적으로 약 31%에서 약 2%로 줄인 것을 확인할 수 있습니다. 이러한 결과는 DA을 통해 speaking style의 변화에도 충분한 일반화 성능을 확보하였음을 보여주고 있습니다.
또한 저자들은 singing과 spoken voice간의 domain gap을 실험적으로 입증하고자 하였습니다.
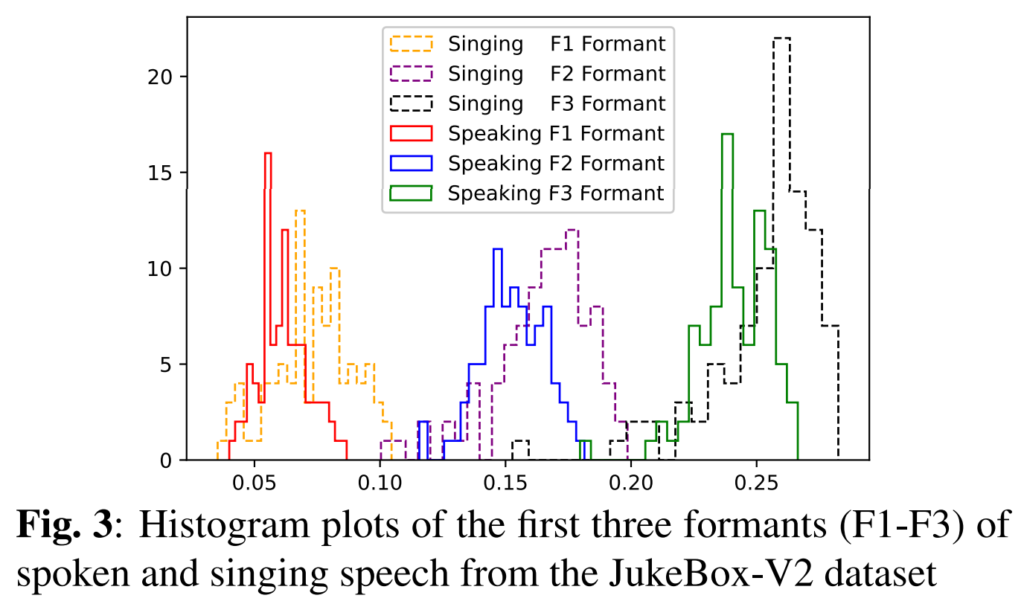
JukeBox-V2 데이터셋의 노래하는 목소리와 말하는 목소리의 처음 세 개의 포먼트(formants)의 히스토그램은 그림 3에서 도메인 갭의 존재를 질적으로 검증합니다. 이 섹션에서는, 이 도메인 갭이 말하는 목소리만으로 훈련된 1D-Triplet-CNN-, iVector-PLDA-, 그리고 xVector-PLDA 기반 기본 화자 인식 모델에 의해 학습된 피처 공간에 미치는 영향을 조사합니다. 비교를 위해, 우리는 DA와 결합된 다른 접근법에 의해 학습된 피처 공간을 분석하여 두 말하기 스타일 간에 DA의 영향을 이해합니다. 이를 위해, 우리는 JukeBox-V2의 테스트 세트에서 1D-Triplet-CNN, iVector-PLDA, 그리고 xVector-PLDA 기반 모델에 의해 추출된 노래하는 목소리와 말하는 목소리 데이터의 음성 임베딩의 t-SNE를 비교합니다,
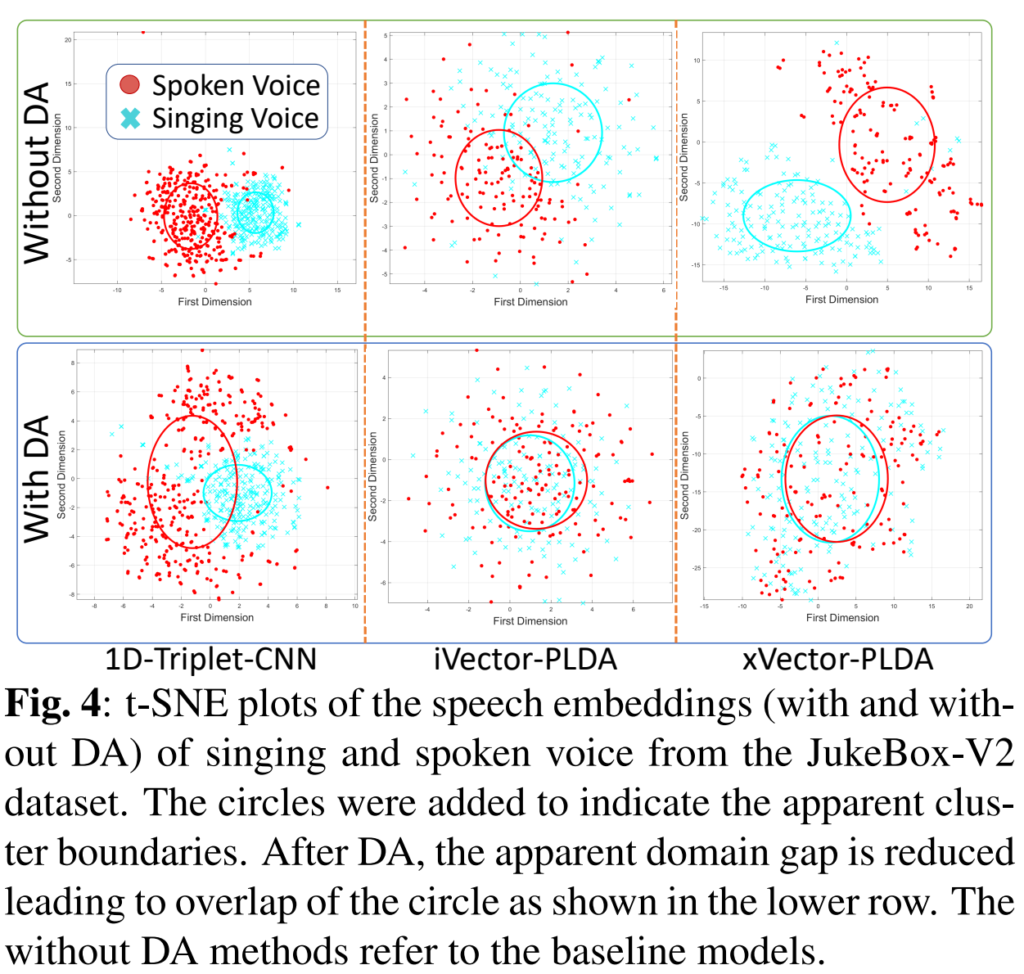
DA 없이 그리고 DA와 함께 (그림 4). 그림 4에서, DA 없이 모델에 의해 추출된 노래하는 목소리와 말하는 목소리의 임베딩은 도메인 갭의 존재를 보여주는 별도의 인지된 클러스터를 형성합니다. 그러나, DA가 있는 모델에서는 인지된 클러스터의 중첩이 눈에 띄게 증가하고 도메인 갭이 줄어들었음을 나타냅니다. DA와 non-DA 모델 간의 음성 임베딩 클러스터의 이 차이는 DA를 수행하기 위해 사용된 CORAL+ 및 DeepCORAL 손실의 직접적인 영향이라고 우리는 가설을 세웁니다. DA는 두 말하기 스타일의 음성 임베딩 간의 공분산을 최소화하여 클러스터를 병합하고 도메인 갭을 부분적으로 연결합니다.
안녕하세요. 좋은 리뷰 감사합니다.
domain adaptation 논문이라니 매우 구미가 당기는 논문이군요. 최근에는 singing과 관련하여 그냥 목소리와 노래하는 목소리의 구분 없애고자 하는 논문이 많이 나오는 것 같습니다. 이 논문의 메인이라고 생각되는 부분이 domain adaptation loss 부분이라고 생각이 드는데 공분산을 최소화하는 방향으로 이 두개의 공분산은 어떻게 계산되는 건가요? 이 부분이 메인이라고 생각이 드는데 feature의 공분산인건지 아니면 parameter의 공분산인건지 조금더 디테일하게 말씀해주시면 감사하겠습니다.
감사합니다.
임베딩 g(x_si)와 g(x_sp), 즉 feature의 공분산을 최소화하도록 학습됩니다.
감사합니다.