이번 리뷰는 Depth completion 방법론입니다. 기존 딥러닝 기법들이 상용 깊이 센서들이 예측하지 못한 공간들을 주변 예측된 깊이 정보를 활용하여 예측 및 보간하지만 경계면이 무너지는 문제가 있다는 점을 지적하고 해결한 방법론에 해당합니다. 매우 단순한 로직이지만, 경계면은 컬러 영상과 열화상 영상에서 동작이 가능하다는 점을 고려하여 추후 연구에 활용 가능하다고 판단하여 해당 논문을 리뷰합니다.

Intro
깊이 추정은 3차원 인지에 있어서 많은 도움을 줄 수 있는 기법으로 3차원 인지를 활용하기 위해서는 매우 중요한 기법 중 하나입니다. 보다 정밀하고 강인한 깊이 추정을 위해 기 개발된 상용 깊이 카메라 (e.g. Realsense, Microsoft Kinect…)를 활용한 깊이 정보를 활용하기도 합니다. 허나, 실내에서의 상용 깊이 센서는 빛이 반사되거나, 투명하거나, 너무 가깝거나, 너무 먼 거리에 물체가 위치한 경우에는 측정되지 못하는 한계를 가지고 있습니다.
이러한 한계를 극복하기 위해서 활용되는 기법이 Depth completion 입니다. 기존 전통적인 기법으로는 SLAM이 있습니다. 연속적으로 취득된 정보들로부터 대상을 재구성하여 원하는 위치에서의 깊이 정보를 취득하는 방식을 활용합니다. 강력하고 정확한 방법이나 해당 기법은 연속적인 정보를 사전에 취득된 상황을 전제로 합니다. 이번 리뷰 논문은 연속적인 정보 없이 한장의 영상에서도 깊이 정보를 보완하는 것을 목적으로 합니다. 싱글 뷰를 활용하는 기존 딥러닝 기반의 방법론들은 딥러닝이 예측되지 못한 곳의 정보를 주변 정보로부터 예측 및 보간을 수행한다는 점을 이용하여 연구가 진행되어 왔습니다. 허나, 이러한 기능은 fig 1의 FCN과 같이 경계가 흐릿해지는 한계를 가집니다. 저자는 기존 방법론들의 한계를 지적하며 나아가야할 2가지 방향: 정확한 깊이 정보를 추론하고 경계가 명확하도록 구성해야한다고 합니다.
저자는 위에서 언급한 문제를 해결하기 위해서 2가지 방법을 제안합니다. 먼전, 이전 연구에서는 CNN을 이용하여 주변 정보를 전체를 활용하여 깊이 정보를 보완했습니다. 허나, 소실된 깊이 정보를 보완에 있어 어느 구역은 의미론적/기하학적으로 중요도가 상이할 수 있습니다. 그렇기에 저자는 self-attention을 이용하여 모델이 장면에서 관련이 높은 곳에 집중하도록 합니다. 이러한 기능은 위에서 언급한 방향 중 하나인 향상된 깊이 추론 정확도를 충족합니다. 마지막 방향을 충족하기 위해서 저자는 일관된 경계면을 유지하는 것으로 해결하고자 합니다. 저자는 예측된 깊이 정보로부터 추정되지 못한 영역에서의 경계면을 예측하는 네트워크를 추가로 활용하여 경계면의 일관성을 보완하도록 합니다.
++ 해당 논문은 2019년도 논문이고 거기다가 workshop 논문이라, 기여도가 좀 떨어져 보이기는 하네요.
++ Depth completion에서는 Attention을 최초로 사용했다고 합니다.
Method
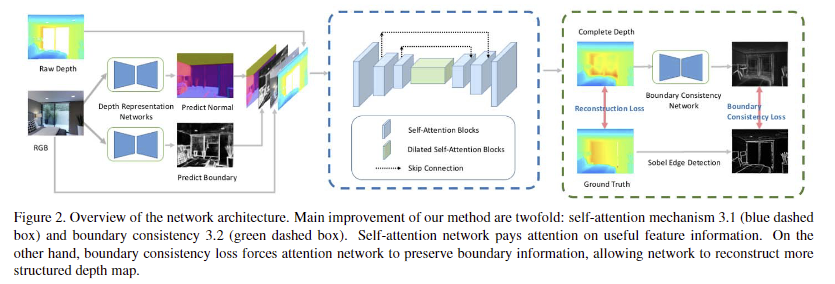
+ 방법론을 설명드리기 앞서 이해를 돕기 위해 입력 정보와 GT에 대해서 설명을 드리도록 하겠습니다. 해당 기법은 지도 학습 방법론에 해당하며, 입력 영상은 상용 깊이 센서로부터 취득 된 RGB 영상과 재구성(e.g. SLAM)을 수행하지 않은 Raw Depth 영상에 해당합니다. Ground Truth는 재구성을 수행하여 보완된 깊이 정보를 활용합니다. 이에 대한 예시는 Fig 2에서도 확인 가능합니다.
저자는 위에서 언급한 2가지 문제점(‘모델이 보간된 깊이 정보를 배우는 문제점을 어떻게 극복할 것인가?’, ‘깊이 이미지의 명확한 구조를 형성하는 방법은 무엇인가?’)에 집중하여 문제 해결을 제안합니다.
Self-Attention Mechanism
기존 딥러닝 기법들이 활용하는 CNN을 이용하는 기법들이 관측되지 않은 깊이 정보를 주변 정보를 복사하거나 보간하면서 추정하는 경향이 있다는 문제가 있습니다. 대체로 관측되지 않은 영역의 평균 깊이 값을 예측하면 loss가 급격히 감소하여 정확한 깊이 값을 예측하는 대신 쉽게 복사 및 보간을 수행하는 local minima에 빠지기 쉽습니다.
+ 기존 딥러닝 기법들은 hour-glass 구조를 가진 모델들이 주를 이루었기에 컨볼루션의 필터가 영역 정보를 취합하면서 들어가고 이를 평균으로 취하여 임베딩한 다음에 복원하는 형태를 가집니다. 그렇기에 평균 값을 예측했을 때, loss가 급격히 감소하는 현상을 보입니다.
저자는 이러한 문제점을 해결하기 위해서 각 컨볼루션 레이어에 self-attention을 활용하는 것을 제안합니다. self-attention을 활용하여 정확한 깊이 값을 예측할 수 있으며, 복사-보간으로 인한 local-minima에 쉽게 갇히지 않는 결과를 보여줍니다. 해당 기법은 인페인팅 태스크에서도 좋은 결과를 보여준 기법으로 인페인팅과 유사하게 depth completion에서도 누락된 깊이 정보를 보완하는 것을 목표로 하기 때문에 해당 기법을 활용합니다. 해당 방법론에서 활용되는 self-attention에 대한 수식은 다음과 같습니다.
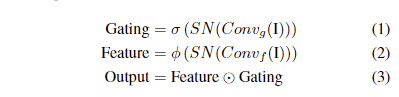
I는 영상, SN은 Spectral Normalization, \sigma 는 soft-max, \phi 는 any activation function에 해당합니다. Spectral Norm을 제외하고는 단순한 어텐션 기법으로 이해하시면 됩니다. 어찌되었든 어텐션 기법을 통해 모델은 효과적으로 각 채널 맵과 각 공간 위치에 대한 정보를 강조할 수 있게 됩니다. 따라서 어텐션 기법을 통해 추출된 로컬 정보와 주변 정보에 더 많은 주의를 기울임으로써 보다 정확한 깊이 값을 예측할 수 있습니다.
+ Spectral Norm은 ICLR 2018의 SN-GAN에서 제안된 기법으로 GAN 중 discriminator 불안정한 학습을 해소하기 위한 가중치 정규화 기법으로 discriminator가 generator의 분포를 너무 따라가지도 혹은 너무 못따라가지도 않도록 하기 위해 두 상황에서의 분포를 일정 비율 유지하는 기법으로 이해하시면 됩니다.
++ GAN이 아닌데도 불구하고 Spectral Norm을 사용한 이유는 베이스라인이 위에서 언급한 Inpainting 기법 [1] 중 discriminator에서 영감을 얻어 제작한 것이 원인으로 추측하고 있습니다.
[1] Yu, Jiahui, et al. “Free-form image inpainting with gated convolution.” Proceedings of the IEEE/CVF international conference on computer vision. 2019.
Boundary consistency.
일반적인 FCN 방법론들은 위에서 언급한 바와 같이 주변 정보에 대해 복사 및 보간을 통해 깊이 이미지를 생성할 가능성이 높습니다. 이로 인해 예측된 깊이 정보의 경계과 구조가 흐린한 결과물이 나오게 됩니다. 대부분의 깊이 보완들은 회귀 문제들로 구성되기 때문에 인접한 픽셀 값이 크게 다른 날카로운 경계를 가진 깊이 맵을 생성하기 어려운 문제점이 있습니다. 저자는 해당 문제를 해소하기 위해서 명확한 경계와 구조를 학습 있는 Boundary consistency를 사용한 것을 요청합니다.
Boundary consistency는 또다른 네트워느인 Boundary consistency network를 통해 예측된 깊이 맵이 경계 정보를 갖도록 제약을 걸어주는 역할을 합니다. U-Net 기반의 모델을 설계하여 예측된 깊이 맵을 입력으로 하여 경계면을 예측하도록 합니다. 해당 네트워크는 depth completion network와 결합되어 학습을 진행하며, 해당 네트워크의 예측값은 Ground truth depth로부터 sobel을 수행한 경계면을 활용하여 loss를 계산합니다.
+ 저자가 다양한 엣지 검출기 중 sobel을 선택한 이유로 sobel은 다른 기법에 비해 선명한 예측이 가능하며 변동이 적다는 점과 노이즈에 덜 민감하게 엣지를 검출할 수 있기 때문이라고 합니다. 다른 엣지 검출기에 대한 실험이나 분석 내용이 없어서 주장에 대한 신빙서이 떨어지긴 합니다…
Depth Representation.
이전 방법론에서 언급되길 깊이 정보를 표현하는데에 있어서 surface normal과 occlusion boundaries가 중요한 작용을 한다고 합니다. Surface normal은 조명 변화에 밀접한 관련이 있으며 표면 속성에 대한 추가 정보를 제공하는 역할을 합니다. Occlusion boundaries는 RGB에서 관찰된 texture에 대한 표현으로 국소적인 정보로 활용할 수 있습니다. 저자는 이를 수용하여 RGB로부터 두 정보를 추론하기 위해 U-Net 구조의 depth representation networks을 설계하며, 추론된 정보를 depth completion network의 입력인 RGB와 raw depth에 추가하여 입력하는 것을 제안합니다.
Loss Functions.
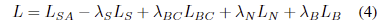
먼저, RGB를 입력으로 받는 depth representation network는 normal N 과 boudaries를 예측하는 것을 목적으로 합니다. 해당 네트워크의 loss는 L_N = 1/p \sum_p \lVert N(p) - N_0(p) \rVert^2 와 L_B = 1/p \sum_p \lVert B(p) - B_0(p) \rVert^2 이며, N_0, B_0 는 GT, p는 픽셀에 해당합니다.
그럼, RGB, depth representations과 raw depth는 결합되어 self-attention network로 입력되어져 complete depth D를 예측합니다. 해당 네트워크는 L_SA = 1/p \in obs \sum_p \lVert D(p) - D_0(p) \rVert를 통해 손실을 계산합니다. D_0는 GT에 해당합니다. 주의해야 할 점이 D_0에서도 누락된 깊이 정보는 손실 계산에서 무시한 채로 학습을 진행합니다. 구조적인 정보를 강화하기 위한 boundary loss L_S는 SSIM을 이용하여 계산되어집니다.
마지막으로 보완된 깊이 정보 D는 boundary consistency network에 입력되어져 경계면 B를 예측합니다. sobel을 이용하여 GT Depth D_0로부터 생성된 경계면 B_0를 활영하여 boundary consistency loss L_{BC} = 1/p \sum_p \lVert B(p) - B_0(p) \rVert^2 를 이용하여 예측을 수행합니다.
Experiment
실험에 활용된 데이터 셋은 Matterport3D를 활용합니다.
+ 실내 기반 Depth completion에서 범용적으로 활용되는 NYUv2에서 실험을 진행하지 못한 이유에 대해서 저자가 밝힐 길, 해당 데이터 셋에서는 단일 뷰에서 추정된 GT depth map이 부재하다는 것을 이유로 말합니다…
++ Matterport3D는 라이다 기반의 깊이 센서인 Matterport를 이용하기 때문에 단일 뷰에서 밀집한 깊이 영상 가지고 있습니다. 해당 장비는 깊이 정보를 생성하기 위해 고정된 위치에서 일정 시간 정보를 누적해야하기 때문에 실시간으로 활용하기에는 어렵다는 단점을 가지고 있습니다.
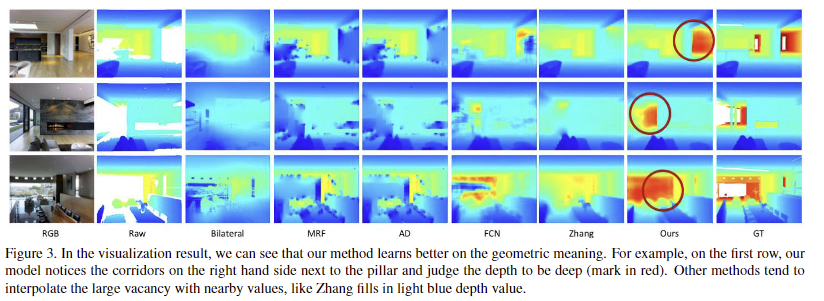
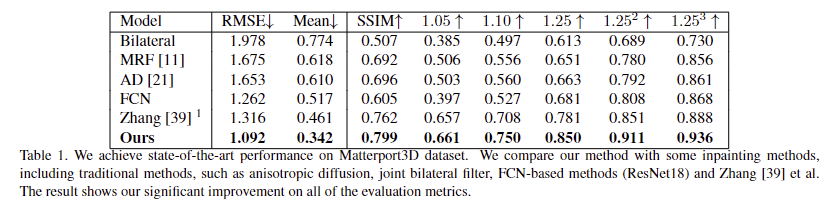
Fig 3과 Tab 1을 통해 SOTA에 해당하는 정성/정량적 결과를 보여주고 있습니다.

특히, Fig 4를 보면 복도와 같은 건축물의 구조에 대한 특성을 잘 반영하여 다른 방법론 대비 경계면이 뚜렷한 결과를 볼 수 있습니다.
Ablation studies


fig 5와 tab 2에서 Self-attnetion이 미치는 긍정적인 영향을 확인 할 수 있습니다. W/O SA는 단순한 FCN 구조의 모델로 Conv만 활용한 결과보다 좋은 결과를 나타냄을 볼 수 있습니다. 저자가 주장하길 Self-attnetion이 중요 영역의 특징 정보에 대해 집중 할 수 있도록 기능함으로써, 기하학적인 의미를 학습하는 데에 도움이 되었다고 주장합니다.
SSIM Loss를 활용할 경우, 더 좋은 성능을 보여주고 있습니다. Fig 5의 SA+SSIM에서는 배경 표면이 부드럽고 정확한 결과를 보여주며 sobel를 이용한 엣지에서도 깊이 영상 품질의 향상과 노이즈 감소를 보여주고 있씁니다.
Boundary Consistency을 활용한 경우에 가장 좋은 결과를 보여주고 있으며, 경계면도 매끈한 모습을 확인 할 수 있습니다.
해당 방법론이 획기적인 방향을 제시한 것은 아니지만 열화상 영상에서도 어느 정도 강인한 엣지 검출이 가능하다는 점에서 활용 가능성이 있다고 보고 있습니다. 더 나아가 Surface Normal에 대해서는 열화상 영상이 컬러 영상에 비해 조명 영향을 덜 받기 때문에 보다 강인하게 작동할 수 있다는 점에 있어서 해당 기법을 베이스라인으로 선정해도 좋을 것 같다는 생각이 듭니다.
단, GT Depth를 요하기 때문에 이 부분에 대해서 어떻게 풀어나갈지에 대해서 고민해봐야겠습니다.
안녕하세요 김태주 연구원님 좋은 리뷰 감사합니다.
제목의 ‘depth completion’이라는 tasks는 무엇일지, 또 depth estimation과는 어떤 차이점이 있을 지 궁금하여 들어왔습니다.
결국 depth completion이라는 것은 depth estimation에서 depth가 측정되지 못한 부분을 보충하는 것, 즉, depth map을 dense하게 만드는 것이며, 논문에서는 깊이 정보를 보완할 때 self-attention을 사용하여 이미지 전체가 아닌 특정 부분과 관련 있는 구역에 집중하도록 하여 기존 방법론들보다 정확한 깊이 추정을 수행하였으며, 경계면을 예측하는 네트워크를 추가하여 dense map의 경계를 명확히 하였다고 이해하였습니다.
리뷰를 읽고 궁금한 점이 있는데요, Depth Representation Network는 어떻게 학습을 진행하는 건가요? 해당 네트워크는 rgb이미지를 통해 surface normal과 occlusion boundaries를 예측하는 네트워크라고 이해하였으나 해당 정보를 gt로 가지고 있는건지, 아니면 사전 학습된 네트워크를 통해 추출한 것인지 궁금합니다.
감사합니다.
좋은 질문 감사합니다.
Q. Depth Representation Network는 어떻게 학습을 진행하는 건가요? 해당 네트워크는 rgb이미지를 통해 surface normal과 occlusion boundaries를 예측하는 네트워크라고 이해하였으나 해당 정보를 gt로 가지고 있는건지, 아니면 사전 학습된 네트워크를 통해 추출한 것인지 궁금합니다.
A. 사전 학습된 모델을 이용하여 추출합니다.