최근 quantization, low-bit 연산에 관해 공부중이었는데요, quantization에 대해 잘 정리된 논문을 발견하여 소개드리고자 리뷰하게 되었습니다.
Introduction
일반적으로 DL application에서 사용되는 numerical format은 32-bit single-precision floating point입니다. 이는 32개의 비트를 가지고 소수의 부호, 지수, 가수를 표현하는 방식인데요, 최근에는 DL application의 computation performance를 향상시키기 위해 FP32대신 다양한 format을 사용한다고 합니다. DL accelerator에서 16비트 형식(FP16혹은 bfloat16)을 사용하여 학습하거나, 이미 FP32로 학습된 모델을 inference시 32보다 낮은 정밀도를 가진 다른 format을 사용하는 방법 등이 있습니다. 이러한 낮은 정밀도의 표현을 사용하는 것에는 성능적으로 세 가지의 이점이 있다고 하는데요, 먼저 많은 processor들이 low-precision에 대해 더 높은 처리량의 pipeline을 제공하여 행렬곱을 가속화할 수 있다고 합니다. 다음으로는 데이터를 표현하는 데 드는 비트 수가 감소하여 memory bandwidth pressure를 줄일 수 있습니다. 마지막으로는 memory requirements가 감소하여 메모리 시스템 운영을 최적화할 수 있다는 이점이 있습니다.
Quantization
논문에서는 ‘uniform integer quantization’에 집중하였는데요, 논문에서의 quantization은 Floating Point로 표현된 activation(feature map)과 weight를 integer domain으로 변환하여 연산하는 것을 의미합니다. 즉, 실수 범위에 존재하는 수를 정수로 mapping하는 것이라고 할 수 있습니다.
quantization은 두 단계를 거쳐 진행됩니다. 첫 단계에서는 실수 영역에서 quantization할 값의 범위를 지정합니다. 다음으로는 그 범위의 실수 값을 quantized representation의 정수에 매핑합니다.
즉, quantization이란 [\beta, \alpha ]범위의 실수 값 x 를 [−2^{b−1},2^{b−1}−1] 범위의 정수로 매핑하는 것으로, 여기서 b는 signed integer의 비트 수를 의미합니다. 이때 quantization을 수행하는 변환 함수 f(x)는 두 가지 형태로 나타낼 수 있는데요, 하나는 scaling factor s와 offset z를 사용하는 affine quantization, 다른 하나는 scaling factor s만 사용하는 scale quantization입니다.
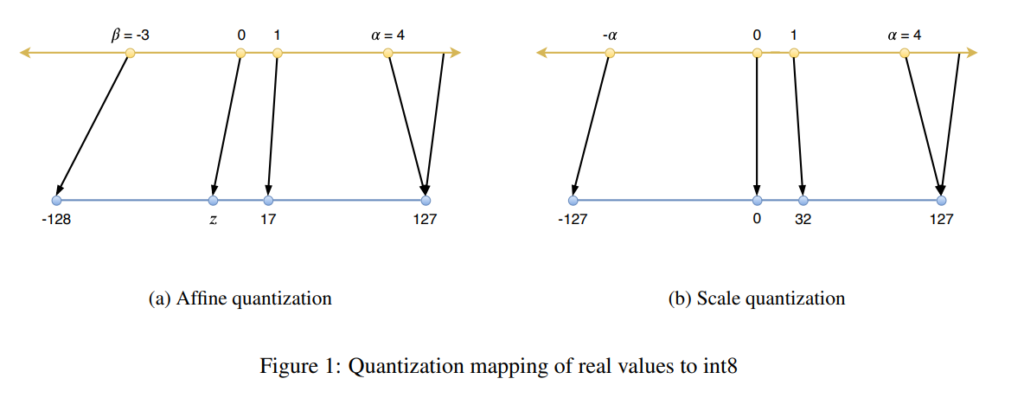
Affine Quantization
Affine quantization이란 [그림1(a)]와 같이 Affine Transform을 통해 mapping하는 것을 의미하는데요, affine transform function f(x)는 아래와 같이 정의됩니다.
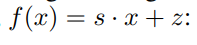
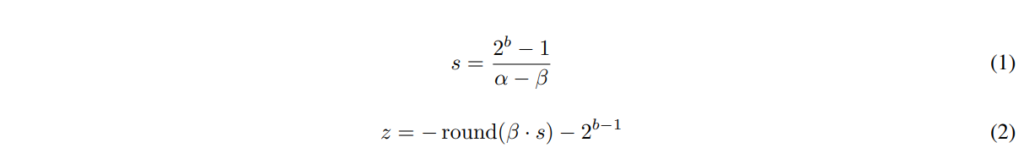
여기서 \beta, \alpha는 위에서 설명한 바와 같이 quantization할 실수값의 range를 나타내는 값으로, 입력값의 Min, Max를 의미합니다. 예를들어 Int8로 quantization하는 경우, Max값에 해당하는 α가 127로, Min값에 해당하는 β는 -128로 scaling되는 것이죠. z는 zero-point를 의미하며, 변환되기 전 0의 위치가 양자화 후 어떤점으로 대응되는지 표현하기 위해 사용합니다. 즉, scaling된 값을 z 만큼shift하는 것이라고 생각하시면 될 것 같습니다.
전체적인 quantization 수식은 아래의 [식4]로 나타낼 수 있습니다. 입력값 x를 , b의 비트 수를 가지는 정수 범위로 quantization하는 과정은 x를 s만큼 scaling, z만큼 shift한 후 정수로 반올림하는 것이라고 정리할 수 있겠습니다.
이때 clip 함수를 통해 설정된 범위를 벗어나는 값은 quantized된 값의 경계값으로 mapping하였습니다.
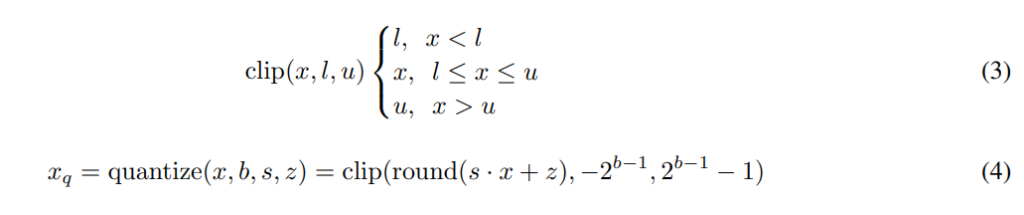
Scale Quantization
scale quantization은 [그림1(b)]와 같으며, affine과 동일하게 scaling을 진행하지만 z를 이용한 shift가 없는 경우입니다. 즉, 입력값의 0이 변환 후에도 0으로 대응되게 하는 방법이며 이 때문에 처음 실수 영역에서 입력 범위를 대칭으로 설정합니다. 만일 Int8로 quantization한다고 하면, -128 ~ 127까지 표현가능하지만 input, output값의 범위가 대칭을 이루어야 하기 때문에 [-\alpha, \alpha]를 [-127, 127]로 mapping하게 되는 것이죠.
수식으로 나타내면 아래와 같이 나타낼 수 있습니다.
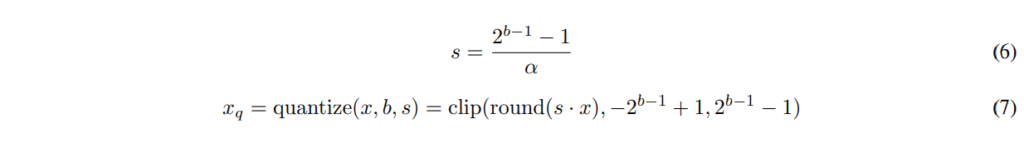
Tensor Quantization Granularity
Quantization granuarity란 quantization을 진행할 때, 어떤 단위로 quantization parameter를 고려할지를 결정하는 것을 의미합니다. 예를 들어 어떤 Tensor를 quantization할 때 Tensor단위로 진행할 것인지, channel 단위로 진행할 것인지에 따라 scaling parameter s와 quantization범위 \alpha를 공유하는 범위가 달라지게 되겠죠. 즉, channel단위로 진행하게 되면 보다 세분화된 분포를 고려할 수 있게 될 것입니다.
Calibration
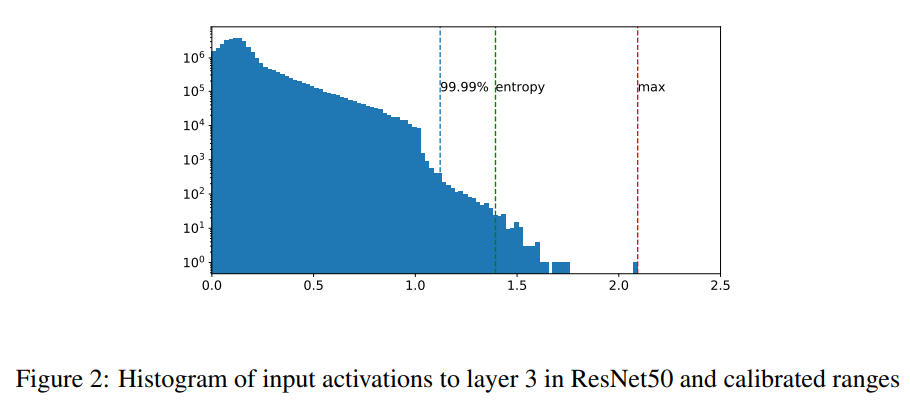
calibration이란 모델의 activation과 model에 대한 \alpha, \beta값을 구하는 것을 의미합니다. 논문에서는 단순히 scale quantization을 고려하기 위해 symmetric한 범위를 설정하여 \alpha값을 구하는 세 가지 방법을 고려하였습니다.
- Max: 가장 절대값이 큰 값을 \alpha로 설정
- Entropy: 양자화된 값과 기존 floating-point값 간의 KL divergence가 최소인 값을 찾고 해당 지점을 \alpha로 설정
- Percentile: 전체 분포 중 사용자가 설정한 비율에 해당하는 값을 \alpha로 설정
Percentile의 경우 사용자가 0.999를 입력하였다면 전체 분포에서 상위 0.001값을 \alpha로 설정한다는 의미입니다.
Post Training Quantization
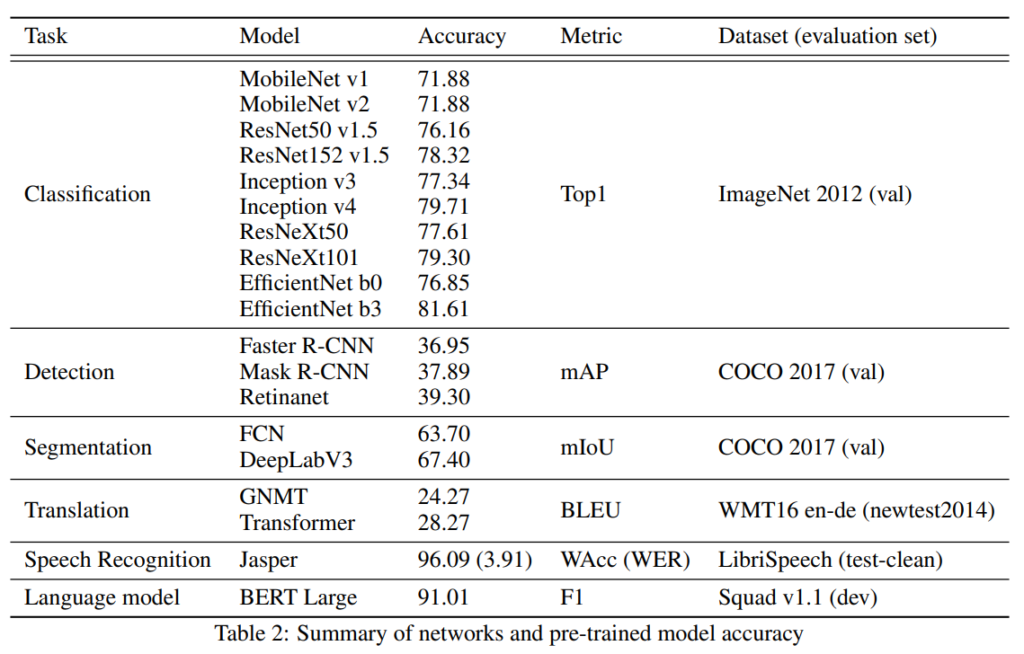
논문에서는 여러 task의 pre-trained모델에 대해 위의 quantization기법을 적용하여 성능을 평가하였습니다.
[표2]는 실험에 사용한 모델과 각 모델의 성능을 나타낸 것입니다.
위의 모델은 사전 학습 모델이기 때문에, inference시 가중치와 파라미터들이 고정되어 있는데요, 이로 인해 batch norm이 단순히 각 점에서의 덧셈과 곱셈 연산으로 취급되어 이전 Conv Layer의 가중치로 미리 계산될 수 있다고 합니다. 이를 Folding이라고 하며 BN의 fold를 통해 전체 Layer의 수를 줄일 수 있다고 합니다.
Weight Quantization
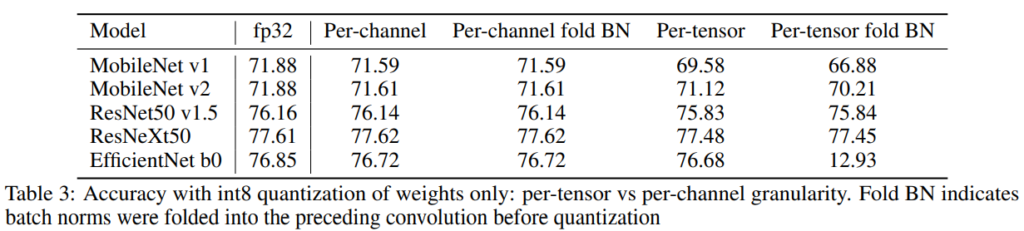
[표3]은 weight만을 int8로 quantization하여 image classification을 수행한 결과입니다. 이때 granularity에 따른 성능 차이를 확인할 수 있는데요, 채널 단위로 수행한 경우, 모델의 메모리 자체는 4배 줄어들었으나 성능 하락은 1%이하로 발생하였음을 확인할 수 있습니다.
위의 결과에서 EfficientNet의 Per-Tensor fold BN 성능이 급격하게 떨어진 것을 확인할 수 있는데요, EfficientNet의 경우 depth-wise conv, 즉, 채널 단위로 행렬곱 연산이 발생하기 때문에 BN을 folding하여 가중치를 변화시키는 것은 모델의 weight분포를 해치게 되어 이러한 결과가 발생하였다고 합니다.
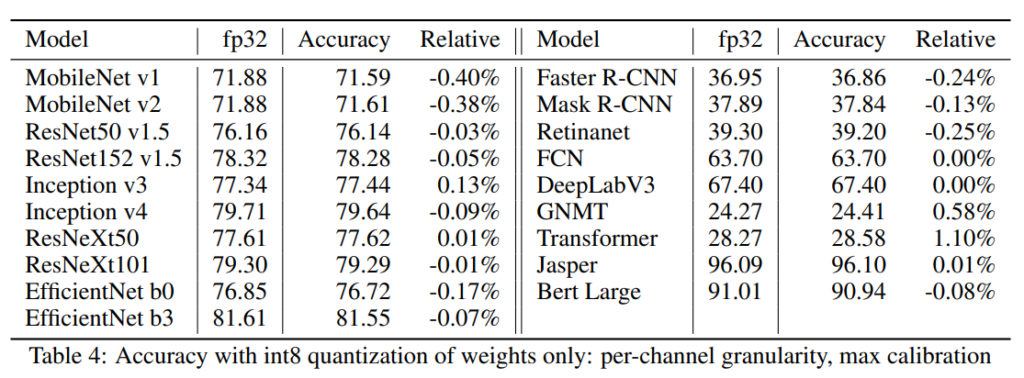
위의 [표4]는 channel단위로 quantization을 진행한 결과이며, Image classification뿐 아니라 [표2]에 나타난 다양한 task에서의 성능을 리포팅한 것입니다. [표4]에는 Accuracy로 표기되어 있으나 적혀있는 결과값은 [표2]의 Metric으로 평가한 결과입니다.
전체적으로quantization결과 1%내외의 성능 변화가 발생한 것을 확인할 수 있습니다.
Activation Quantization
[표5]는 weight와 activation을 모두 quantization한 결과입니다.
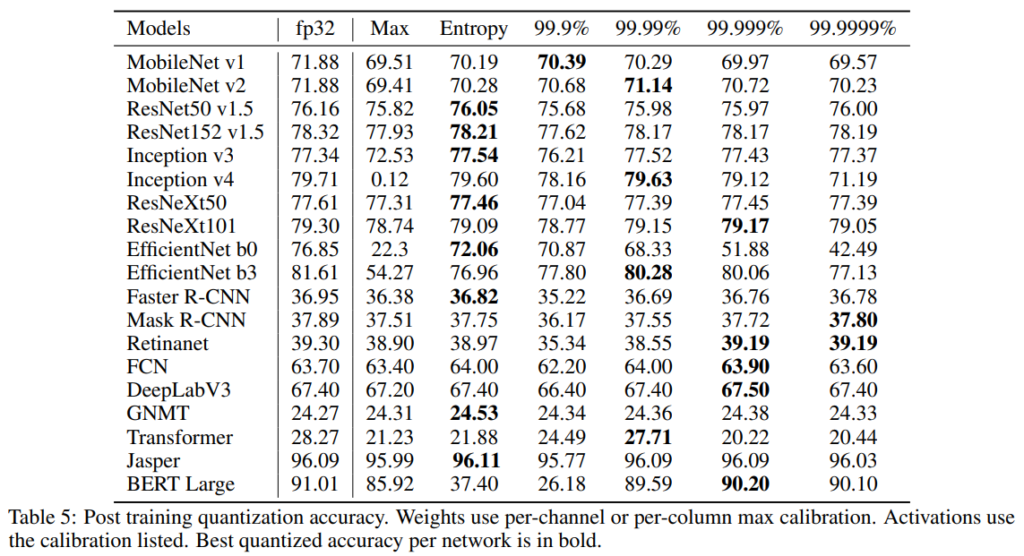
[표 5]는 activation을 99.9%에서 99.999%까지의 percentile, max, entropy calibration으로 quantization한 결과입니다. 이때 weight는 max calibration과 per-channel을 사용하였다고 합니다.
대부분 적절한 calibration을 사용하면 성능 하락이 1%이하로 발생한 것을 확인할 수 있습니다. 그러나 max calibration은 다양한 네트워크에 대해 일관되지 않은 quantization 품질을 보여주고 있는데요, 특히 MobileNet, EfficientNet, Transformer, BERT와 같이 복잡한 네트워크에서 성능 하락이 크게 발생하였습니다.
Partial Quantization
위의 결과들을 보면, quantization을 진행하였을 때 성능이 크게 저하되는 모델이 있다는 것을 알 수 있었는데요, 저자들은 이러한 정확도 손실을 Partial quantization을 통해 회복할 수 있음을 보였습니다.
Partial Quantization이란, 모든 Node를 양자화 진행하는것이 아니라, 마치 DropOut과 같이 몇개의 Node에서는 quantization을 진행하지 않는 것입니다.
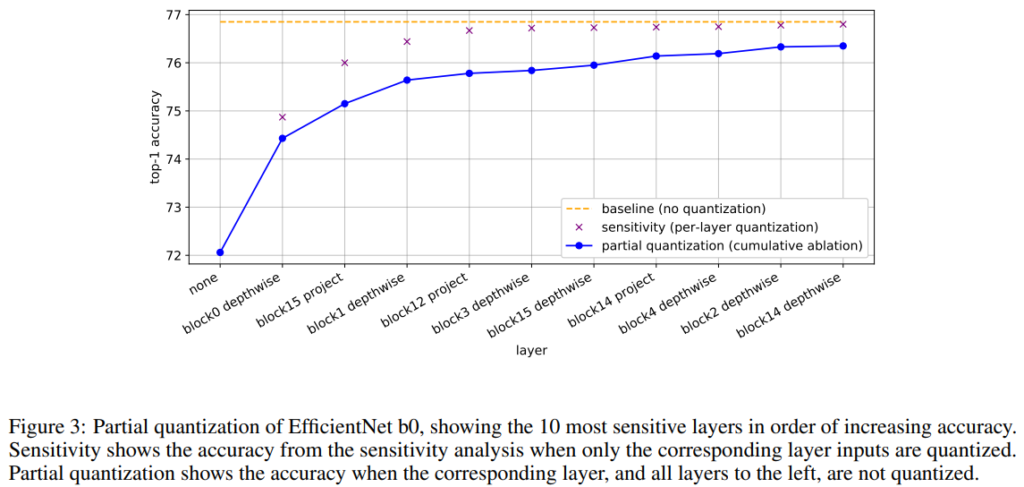
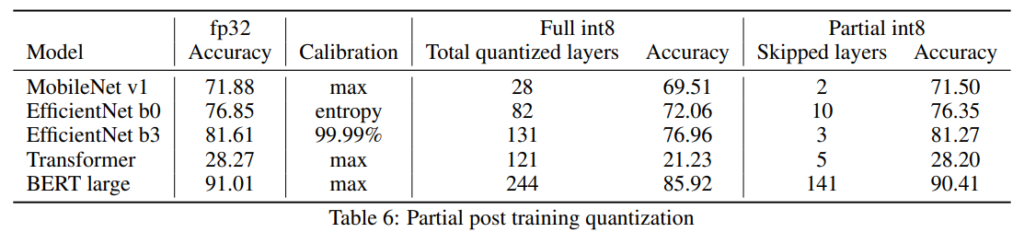
이때 partial quantization이 수행되는 방식은 모델의 각 Layer를 Sensitive기준으로 sort하여 하나씩 dequantize하는 것인데요, [표6]의 결과를 통해 partial quantization이 정확도를 보존할 수 있음을 보였습니다.
Recommended Workflow
위의 결과들을 종합하여, 저자들은 weight와 activation에 int8 quantization을 적용할 때 아래와 같은 방법을 사용할 것을 제안하였습니다.
- weight
- column, channel 단위로 세분화하여 scale quantization을 적용
- max calibration을 사용하며, [-127, 127]의 scale quantization을 사용
- Activation
- tensor 단위의 Scale Quatization 사용
또한 pre-trained 모델을 quantization할 때는 아래와 같은 pipeline을 따를 것을 제안하였습니다.
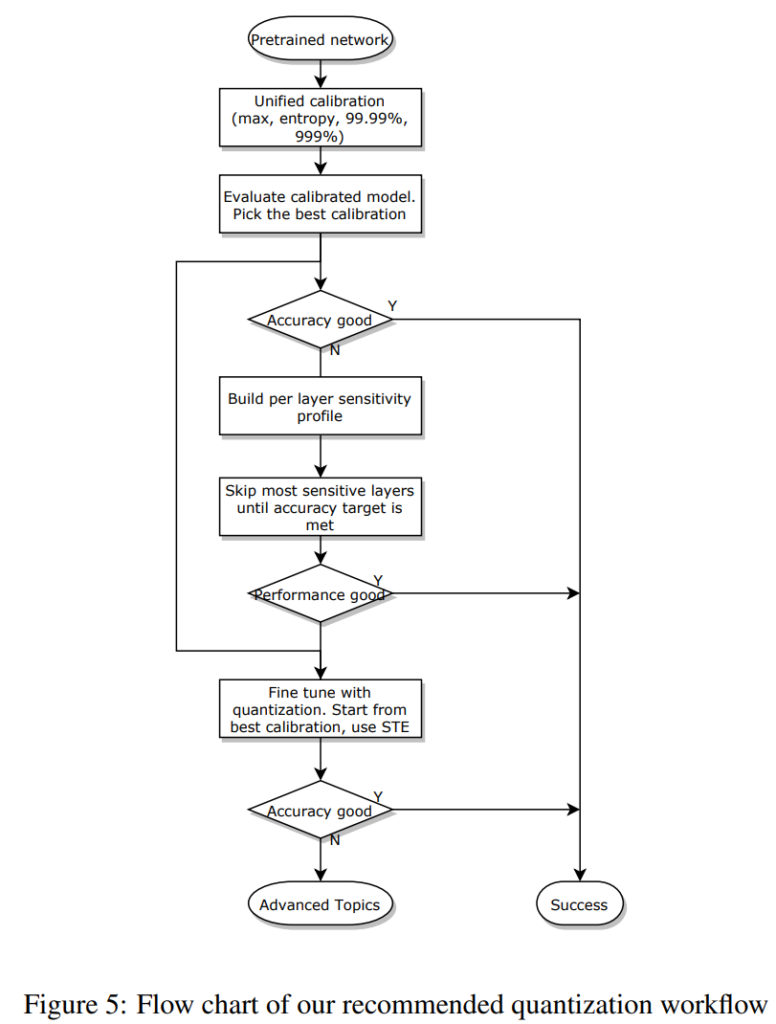
[그림5]를 정리하자면 다음과 같습니다.
- PTQ 방법을 우선적으로 고려한다. 즉, 모든 레이어에 대해 quantization을 적용한 뒤, activation에는 앞서 소개했던 Max, Entropy, Percentile Calibration을 다양하게 적용하며 성능을 확인하여 적절한 것을 선택한다.
- PTQ에서 목표한 성능에 도달하지 못한 경우, 부분적으로만 quantization을 진행하는 Partial Quantization을 적용한다. (1)에서 quantization한 모델의 레이어를 Sensitive 기준으로 내림차순하여 하나씩 dequantize하며 성능을 확인 후 적절한 것을 선택한다.
안녕하세요 천혜원연구원님.
리뷰와 관련하여 간단한 질문이 있습니다.
우선, Percentile와 같이 max에 여유를 두어 알파 값을 설정할 경우 어떤 이점이 있는지 혹시 설명해주실 수 있나요?
또한, EfficientNet의 경우 네트워크의 특성상 folding을 할 경우 큰 성능 드랍이 발생한다고 하셨는데, 한가지 궁금한 것은 네트워크에는 한가지 quantization만이 적용 가능한 것인지 궁금합니다.
** 추가로 어디 논문인지도 제목에 넣어주시면 좋을 것 같습니다.
댓글 감사합니다.
Max에 여유를 두고 수행하는 경우 기존 값의 분포를 고려한다는 장점이 있습니다. max의 경우 단순 최대값을 경계값으로 설정하게 되는데요, 이 때 [그림2]와 같이 max값이 동떨어진 경우 그대로 mapping을 진행하게 되면 해당 그림의 [0.75, 2.0] 구간과 같이 값이 거의 존재하지 않는 부분을 mapping 범위에 포함시키게 되겠죠. 반면 percentile은 평균에 가까운 부분, 기존 값이 다수 분포한 부분만을 mapping범위에 포함시켜 해당 구간에 대한 세부적인 표현이 가능해집니다.
이 논문에서는 전체 네트워크에 한 가지 방식으로 quantization을 진행하였는데요, 결론적으로 말씀드리면 여러 가지 quantization도 적용 가능합니다. [Hwang and Sung 2014]의 연구에서 레이어 마다 서로 다른 비트 수로 quantization을 진행하는 경우도 있습니다.
감사합니다.
안녕하세요, 천혜원 연구원님, 좋은 리뷰 감사합니다. 재밌어 보이는 제목을 보고 들어왔습니다. 읽어보니 전혀 모르던 분야라서 흥미롭네요. 질문이 2개 있는데,
1. 정확도를 희생 시키면서 quantization을 적용하려는 이유가 무엇인까요? 메모리 부족 해결이나 학습 시간 단축을 위한 것인가요? 성능을 희생하면서까지 양자화를 하는 것이 어디에 사용되는지 궁금합니다. 직관적으로 떠오르는것은 edge device에서의 real-time inference정도가 있긴 한데, 또 다른 곳에서 사용될 수 있는지 궁금하네요.
2. Table 4를 보면 다른 모델들과 다르게 GNMT와 Transformer는 성능이 소폭 상승한 것이 보이는데, 이에 대한 저자의 분석이나 코멘트가 있는지 궁금합니다. 또 GNMT가 어떤 모델인지도 궁금하네요
답변 남겨주시면 감사하겠습니다!
댓글 감사합니다.
1. 말씀하신 대로 quantization의 적용 이유는 모델 압축을 통한 메모리 부족 해결과 추론 속도 향상이 맞습니다. 또한 추론 속도룰 높여 real-time inference를 수행하기 위해서이기도 한데요, 기본적으로 edge환경은 전력 소모량이라던지 가용 메모리와 같은 연산 자원의 한계가 있기 때문에 기존 모델을 보다 소형화된 환경에서 원활이 동작하도록 하는 것에 초점을 두고 있다고 생각하시면 될 것 같습니다. 이 과정에서 [실험3]과 같은 정확도 손실이 발생하나, 현재 quantization연구들은 이러한 accuracy gap을 줄이는 방향으로 진행되고 있다고 합니다.
2. 논문에서 [표4]의 실험 결과에 대해 언급한 부분은 기존의 정확도를 크게 벗어나지 않았다는 부분 외에는 없었습니다. 그러나 [표5]에서도 machine translation 모델들과 semantic segmentation모델들의 성능이 소폭 상승한 것으로 보아 task자체의 특성같기도 한데… 현재로써 해당 부분은 잘 모르겠네요. GNMT는 lstm기반의 machine translation모델입니다.
안녕하세요. 좋은 리뷰 감사합니다.
저도 NPU를 다뤄야하는 입장에서 quntization에 대해서 알아야할 필요성을 느껴 읽게 되었습니다. 궁금한 점이 있는데요. 보통 Calibration의 경우 어떤 데이터를 이용하나요? train 데이터의 일부를 이용하는 것인지, test 데이터의 일부를 이용하는 것인지, 그리고 그 일부에 따라 성능 변화가 큰지 궁금합니다.
감사합니다.
댓글 감사합니다.
calibration 데이터는 train/val 혹은 실제 inference할 데이터에서 선정하게 됩니다. 당연히 많을 수록 좋겠지만 optimal한 연산을 위해 100장 정도 선택한다고 하네요. 입력 데이터가 layer를 통과했을 때 어떤 범위를 가지는 지 파악하는 것이기 때문에 calibration과 차이가 큰 데이터가 들어오게 된다면 quantization시 데이터가 손실되어 큰 성능 하락이 발생합니다.
좋은 리뷰 감사합니다.
전부터 관심이 있던 분야인데 요새 관련 논문 리뷰를 작성해주셔서 좋네요.
해당 논문의 주요 주장 중 가장 흥미롭게 보인 부분은 quantization을 tensor 측면보다는 channel 측면 혹은 column 측면으로 진행하면 좋다라는 결과였어요.
음 근데 각 측면이 어떻게 적용하는지에 대해 와닿지가 않아서 설명 한번 부탁합니다.
그리고 fold BN 은 어떻게 수행하는 건지 궁금합니다. 그래야 tab 3의 내용이 와닿을 것 같아요.
마지막으로 캘리브레이션은 왜 수행해야하는지 궁금합니다.