
안녕하세요, 허재연입니다. 이번 리뷰에는 Vision 분야 Active Learning의 근본 논문을 들고 왔습니다. 이제 연구실의 많은 분들이 Active Learning에 대해서는 익숙할 것이라고 생각합니다. Active Learning은 deep learning의 실제 적용에 있어 bottleneck이 되는 데이터 확보에 대한 문제를 해소하고자 합니다. 딥러닝 기술이 상당히 발달되어 이제 충분한 양의 데이터만 확보되면 높은 수준의 모델을 만들 수 있지만, 적절한 데이터셋 취득 및 라벨링에는 현실적으로 많은 시간 및 비용이 소모됩니다. 특히 데이터를 확보하는 것보다 학습에 필요한 label을 annotation하는 단계에서 더욱 그렇습니다. Active Learning은 모델 학습 효율이 좋은 고가치 데이터를 선별하는 방법을 연구합니다. labeling 예산이 제한되어 있을 때, 한정된 예산 안에서 더욱 informative한 데이터들을 확보하고자 합니다. 학습 초기에는 소량의 labeled set으로 모델을 학습 시키고, 이후에는 모델이 데이터를 선별하고, 선별된 데이터를 (human annotator가) 라벨링하고, 라벨링 한 데이터를 labeled data pool에 추가시켜 이것으로 다시 모델을 학습 하는 것을 반복합니다.
데이터의 가치를 판단하는 기준은 많이 있지만, 크게 1. uncertainty 기반 방법론 계열과 2. diversity 기반 방법론 계열로 나눌 수 있습니다. 1. uncertainty 기반 방법론은 모델이 어려워하는 데이터가 학습 효율이 높은 데이터일 것이라는 관점으로 문제를 해결하고자 하며, 2. diversity 기반 방법론에서는 전체 데이터셋의 분포를 잘 반영하는 subset을 추출하고자 합니다. 이 둘을 함께 결합한 hybrid 기반 방법론들도 있습니다. 몇가지 대표적인 방법론들을 소개해 드리자면 다음과 같습니다 :
- Least Confidence, Margin Sampling, Entropy Sampling : 가장 기본적인 uncertainty 기반 방법입니다. classification task에서 모델의 예측 confidence(이미지 분류 CNN 모델을 예로 들면 softmax output의 분포) 및 Shannon의 entropy를 기준으로 불확실성이 높은 데이터를 선별합니다. 방법론이 간단하면서도 성능이 좋아서 AL에서 baseline으로 자주 등장합니다. 하지만 classification 이외의 task에는 적용하기 힘들다는 단점이 있습니다.
- Bayesian 방법 : 베이지안 네트워크를 active learning에 응용한 uncertainty 기반 방법론입니다. 학습 시킬 때 모든 convolution layer 뒤에 dropout을 붙여서 학습 시킨 다음, inference 할 때도 dropout을 끄지 않고 N번 feedforward를 진행합니다. 그리고 이 N개 prediction의 variance를 이용해 uncertainty를 측정합니다. 이 또한 강력한 방법이지만, 모든 convolution 계층 뒤에 dropout을 붙이다 보니 학습 수렴이 매우 느리다는 단점이 있습니다. practical하지는 않은 편입니다.
- Learning Loss : LL4AL은 CVPR 2019에서 제안된 간단하면서도 강력한 uncertainty 방법으로, 딥러닝 학습이 결국 하나의 Loss값에서 시작된다는 점과 Loss가 큰 데이터는 uncertainty가 높을 것이라는 아이디어에서 착안해 제안된 방법론입니다. 본래 목적의 모델 아래 작은 loss prediction module을 붙여서 데이터의 loss값을 예측하도록 학습한 뒤, 데이터의 예상 loss를 기반으로 데이터의 불확신도를 판별합니다. 위 두 방법과 달리 (딥러닝은 어떤 task를 수행하더라도 loss값에서 경사하강법으로 역전파가 진행되니) 특정 task에 구애 받지 않으며, 학습에 필요한 computational cost도 낮다는 장점이 있습니다. 성능도 준수해서 이 또한 baseline으로 자주 등장합니다.
- Expected Model change : 모델을 가장 많이 변화시키는 데이터가 학습 효율이 높을 것이라는 관점의 접근법입니다. gradient의 크기나, 모델의 파라미터를 많이 업데이트 할 것으로 예상되는 데이터를 선별합니다.
- Core-set : diversity 기반 방법론인 core-set은 주변 데이터를 대표할 수 있는 중심점(core)들을 선별해서 전체 데이터의 분포를 반영할 수 있는 subset을 추출하고자 합니다. 신경망의 feature space에만 의존하므로 classification이든 regression이든 (Learning Loss처럼) task-agnostic하다는 장점이 있지만, 모델이 어려워하는 샘플을 전혀 고려하지 않고, unlabeled dataset의 크기가 너무 거지면 optimization이 굉장히 무거워진다는 단점이 있습니다.
이번에 다룰 논문은 CNN에 uncertainty 기반 AL을 접목 시킨 방법론을 제안합니다. Active Learning을 본격적으로 공부하기 시작 한지 얼마 되지 않아 해당 분야 감을 잡는 중인데, 해당 논문이 Deep Active Learning의 대표적인 초기 논문 중 하나라고 해서 읽어보게 되었습니다. 2017년 IEEE transaction에 게재된 상당히 예전 논문이니(CNN이 막 다양한 분야에서 접목되기 시작하던 시절입니다) 이 점 감안해주시기 바랍니다. 프레임워크가 간단하면서도 강력해서 AL에 입문하시는 분들이 읽기 좋은 논문이라는 생각이 드네요. 리뷰 시작하겠습니다.
Introduction
당시 deep learning에 적극적으로 Active Learning을 통합 시킨 사례는 많지 않았지만, Active Learning은 기존 통계 기반 기계학습 방법론이 주류일 때 계속 연구되고 있었습니다. 이에 따라 자연스럽게 다양한 vision task(이미지/비디오 categorization, text/web 분류, 이미지/비디오 검색 등)에 Active Learning을 접목하려는 시도 또한 있었다고 합니다. 기존의 AL 접근법들이 나쁘지 않은 성과를 보이고 있진 했지만 classifier/model이 작은 크기의 visual dataset으로 handcrafted feature(Hog, SIFT) 기반으로 훈련되고 있었고, 더 challenging한 상황 에서의 효과적인 AL은 당시에는 제대로 연구되지 않고 있던 상황이었습니다. 동시에 당시에는 충분한 labeled data와 deep Convolutional Neural Network를 이용한 접근이 vision에서 상당한 성과를 이루어내고 있었는데, ‘실제 적용’을 위한 labeled data는 부족했기 때문에 CNN을 AL에 통합 시키는 것이 필요한 상황이었습니다. 엥 그럼 이 논문 전에는 AL과 CNN을 제대로 통합 시킨 연구가 없었느냐? 라는 의문이 생길텐데, (저자들 말에 따르면)그렇습니다. CNN이 워낙 핫하게 떠오르고 있던 시기이기에 이런 시도가 없었던 것은 아니지만, 2가지 이슈가 있어서 쉽게 CNN을 AL에 붙이기에는 한계가 있었다고 합니다.
- 기존 active learning에서는 대부분의 unlabeled sample들이 무시되었기 때문에 AL을 사용한 labeled training sample이 CNN에 사용하기에는 부족했다고 합니다. 일단 기본적으로 딥러닝 방법이 데이터가 많이 필요하기도 하고, AL에서는 가장 informative한 소수의 샘플들만 추출하도록 발전되고 있었기 때문에 이런 일이 발생했다고 합니다(이전까지는 기계학습 기반 방법론들을 염두하고 소량의 고가치 데이터를 선별하는 연구가 진행되었기에 딥러닝에 사용할 만큼의 데이터를 확보하기에는 당시 AL이 충분히 발전하지 않았다는 맥락으로 보시면 될 것 같습니다). 이런 minority informative sample들 만으로는 CNN 모델을 fine-tuning해서 적절한 feature representation을 확보하기에는 한계가 있었습니다.
- 마찬가지로 기존 AL이 CNN에 최적화되지 않았었기 때문에, AL과 CNN 간 process pipeline이 일치하지 않아서 둘을 곧바로 접목할 수는 없었다고 합니다. 기존 AL 방법론은 모델과 분류기 학습에 집중했는데, 이들이 informative sample을 선별하는 전략들은 feature representation이 고정되어 있다는 가정을 기반으로 한다고 합니다. 하지만 CNN에서는 이와 달리 feature learning과 classifier training이 통합되어서 최적화됩니다(특징 추출을 사람이 직접 하지 않아도 되는 게 딥러닝의 큰 장점이죠). 기존 AL와 CNN의 이런 괴리 때문에, 전통적인 AL framework에 그저 단순히 CNN을 붙여 fine-tuning하는 것은 divergence problem을 일으킨다고 합니다.
저자들은 이런 문제점들에 주목해서 위의 이슈들을 상호 보완적 데이터 샘플 선택으로 CNN과 AL을 비용 효율적으로 통합했다고 합니다. AL과 CNN 간 inconsistency를 극복하고 충분한 양의 unlabeled 훈련 데이터를 이용해 CNN을 fine-tuning 할 수 있게 한 이 방법을 ‘Cost-Effective Active Learning (CEAL)’ 이라고 이름 붙였습니다.
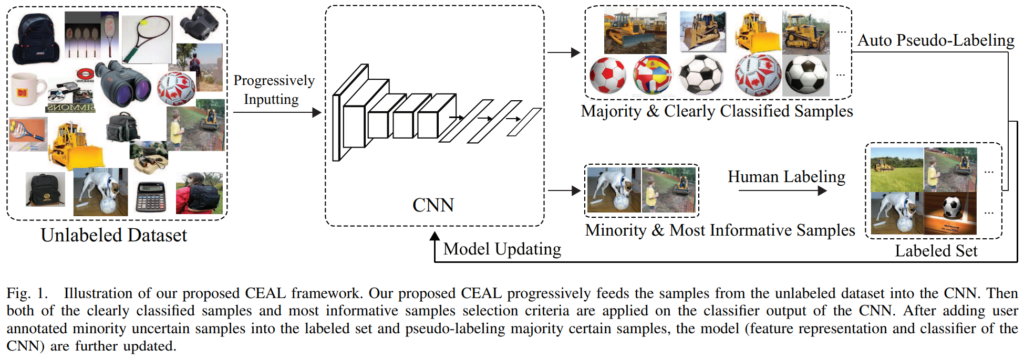
기존 AL 연구의 접근법들이 informative하고 표현력이 풍부한 샘플들을 선별하는 것에만 집중했다면, CEAL는 이와 달리 unlabeled sample을 자동으로 선택하고 pseudo annotation하는 방법을 제안합니다. uncertainty 기반 방법론에서는 모델이 어려워하는(classification 에서는 decision boundary 근처에 있는) 데이터를 모델 학습 효율이 좋은 고가치 데이터로 간주하는데, decision boundary 근처의 소량의 데이터만 사용하는 것은 효율이 좋지도 않고 모델 학습이 안정적이지도 않으니, 대량의 confidence가 높은 데이터들을 뽑아서 수도 라벨을 붙여 모델 학습에 함께 이용합니다. Fig1에서 확인할 수 있듯 해당 프레임워크에서는 2가지 종류의 데이터를 선별합니다. 1.Minority & Most Informative Samples와 2.Majority & Clearly Classified samples를 따로 선별합니다. minority sample들은 기존 uncertainty 기반 AL에서 선별하고자 하던 데이터들입니다. 모델이 헷갈려 하면서 모델에 많은 정보를 줄 것으로 기대되는 데이터입니다. Majority sample들은 반대로 confidence가 매우 높은, 모델이 확실하게 예측하는 sample들입니다. 이 샘플들에게는 수도 라벨을 부여해 labeled pool에 추가한 다음 모델 학습에 이용합니다. 이 방법으로 CEAL은 인간 라벨러의 도움 없이 수도 라벨을 부여할 수 있습니다. CNN모델을 fine-tuning할 때는 이 두 종류의 데이터를 모두 학습에 활용하는데, CEAL은 이 상호보완적 데이터들을 모두 활용해 다양한 confidence 데이터에 대한 표현력을 확보할 수 있었습니다. 저자의 해석으로는 minority informative 데이터를 이용해 더 classifier를 더 잘 학습 시킬 수 있게 되었고, high confidence의 majority 데이터를 이용해 더욱 discriminative한 특징 표현력을 확보할 수 있었다고 합니다. minority 데이터는 decision boundary 근처에 분포하니 분류기를 더욱 잘 조정할 수 있었을 것이고, high confidence의 majority 데이터들은 feature space에서 labeled data에 매우 근접해 있을 것이니 수도 라벨을 부여해서 학습에 이용해도 무리가 없을 것이라는 설명입니다. 특히 이 high confidence sample의 수를 uncertainty 데이터보다 월등히 많이 확보할 수 있는데, 이 덕분에 AL과 CNN의 inconsistency를 극복할 수 있을만한 강건한 특징 표현력을 확보할 수 있었다고 합니다. (저자에 따르면 기존 uncertainty 방법들은 대부분의 unlabeled sample들을 무시하므로 outlier에 민감했다고 합니다. 소수의 low-confidence 데이터에만 의존해서 오히려 대부분의 high confidence data에 대한 충분한 정보를 얻을 수 없었다고 합니다.)
약간 더 자세히 살펴보면, 모델을 안정적으로 학습하기 위해서 어려운 샘플보다 쉬운 샘플들을 먼저 사용하여 점진적으로 학습을 진행한다고 합니다. 학습 초기에는 모델이 불안정하니 쉬운 데이터를 활용해서 안정적으로 학습을 진행하고자 합니다(이후 학습시킬 데이터들은 기존 학습되었던 데이터를 기반으로 모델이 점진적으로 결정합니다). 결국 confidence가 매우 높은 것들을 우선적으로 학습한다는 것인데, 이런 easy-to-hard manner 학습이 pseudo-labeling 과정을 좀 더 안정적으로 만들어줍니다. 초기에는 높은 confidence threshold를 부여해서 확실한 샘플들에게만 수도라벨을 부여하고, 학습을 진행한 다음 분류기의 성능이 어느 정도 확보되면 이에 따라 threshold를 낮추게 됩니다(threshold는 학습이 진행됨에 따라 점차 업데이트됩니다)
저자들이 주장하는 3가지 contribution은 다음과 같습니다:
- 본 연구를 통해 최초로 Active Learning framework와 CNN을 통합 시켜 deep image classification 문제를 해결하는데 성공했다. 이 프레임워크는 비슷한 다른 visual recognition task로 쉽게 확장 가능하다.
- 자동으로 high confidence sample들을 선택하고 annotation하는 cost-effective한 방법을 도입해서 Active Learning을 발전시키는데 성공했다.
- 실험적으로 기존 방법들보다 높은 정확도를 달성했고, 성능 대비 라벨링 횟수도 줄일 수 있었다. (CACD와 Caltech256 데이터셋을 활용했습니다)
Method

전반적인 큰 그림은 introduction에서 충분히 설명 드렸으니, 여기서는 세부적인 부분들을 짚고 넘어가겠습니다.
A. Initialization
각각 class에 대해 몇 학습 샘플들을 unlabeled pool에서 무작위로 뽑아서 사람이 라벨링 한 다음 모델을 학습시킵니다.
B. Complementary sample selection
informative minority sample과 high confidence majority sample을 어떻게 선택할지 설명하는 부분입니다.
Informative Sample Annotating
unlabeled dataset DU에 있던 unlabeled sample들을 Active Learning의 판단 기준에 따라 정렬한 다음에 가장 불확실한 데이터들을 DL(라벨링 데이터셋)에 추가해 라벨링합니다. Active Learning에서 uncertainty 판단 기준으로는 크게 1.Least confidence, 2.Margin sampling, 3.Entropy 기반 방법이 있습니다.

- Least Confidence는 예측 한 확률 중 가장 큰 확률(top1)이 가장 낮은 데이터가 불확실하다고 판단하는 기준입니다. 가장 높은 확률값이 작을수록 모델이 헷갈려한다고 판단합니다.
- Margin sampling은 (top1예측 확률 – top2예측 확률)값인 Margin을 기준으로 불확실성을 판단합니다. (top1-top2) 확률값이 작을수록 모델이 헷갈려하는 데이터라고 판단합니다
- Entropy기반 방법은 말 그대로 엔트로피를 기반으로 불확실성을 판단합니다. 엔트로피가 높은 데이터일수록 모델이 헷갈려한다고 판단합니다.
High Confidence Sample Pseudo-labeling
low confidence의 informative data는 인간에게 라벨링을 부탁하고, 반대로 confidence가 높은 데이터는 모델이 임의로 수도라벨을 부여합니다. 이들은 수도라벨이 붙은 그대로 모델 학습에 활용됩니다. unlabeled dataset pool인 DU에서 entropy threshold δ보다 entropy값이 작은 high confidence sample을 선별해서 수도라벨을 붙입니다. δ값은 수도라벨의 신뢰를 충분히 보장할 수 있는 높은 값으로 설정되어 학습을 시작합니다.

C. CNN fine-tuning
여기서는 CNN의 학습 과정을 설명합니다. 저희가 익히 알고 있는 내용들인데, 라벨링한 데이터로 CNN모델을 학습하는 것을 수식으로 풀어서 설명합니다. ‘아 그냥 CNN 학습을 시켰구나..’ 정도로 생각하시면 됩니다. 수식으로 설명하고 있긴 해서, 간단하게 훑고 넘어가겠습니다.
저자들은 CEAL의 이미지 분류를 다음과 같은 수식으로 표현합니다.

수식이 복잡해보이기는 하는데, 그냥 익숙한 딥러닝 분류를 표현했다 정도로 생각하시면 됩니다. 여기서 네트워크 파라미터에 대해 편미분을 수행하면 :

이렇게 표현할 수 있고, softmax classifier는 다음과 같이 표기합니다:

end-to-end 학습을 통해 fine-tuning이 종료되면 high confidence sample들은 수도라벨을 지우고 다시 unlabeled pool인 DU에 넣습니다.
D. Threshold updating
앞서 threshold는 충분히 큰 값에서 시작해서 모델이 어느정도 안정적으로 학습되면 점차 업데이트되며 낮아진다고 했습니다. 업데이트는 다음 수식에 따라 진행됩니다.

δ0는 초기 threshold값이고, dr은 threshold 업데이트를 조정하는 decay rate입니다.
Experiment
Dataset

실험에는 Cross-Age Celebrity face recognition Dataset (CACD)라는 데이터셋과, 우리에게 익숙한 Caltech-256 object categorization 데이터셋이 사용되었습니다. CACD는 안면 인식 및 검색을 위한 데이터셋입니다. 2000명의 유명인에 대한 160,000장의 이미지가 포함되어 있다고 하네요. age, pose, illumination, and occlusion이 다양하게 포함되어 있다고 합니다. (데이터셋 구성 및 크기가 달라 약간 다른 CNN구조를 이용했다고 합니다)
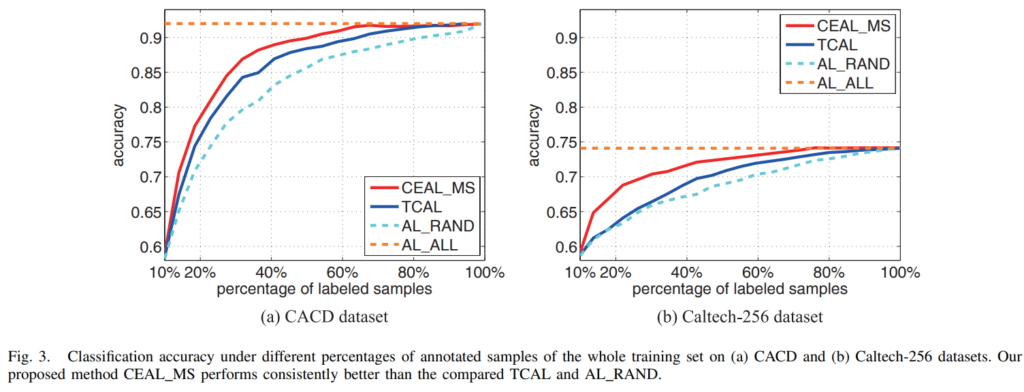
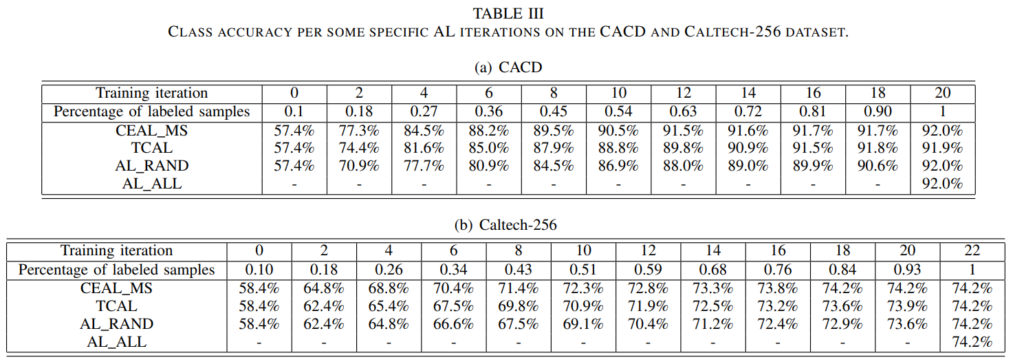
그래프를 보실 때는 labeled sample을 추가하면서 얼마나 초기에 높은 정확도를 달성했나? 에 집중해서 보시면 됩니다. Fig3와 Table3에서 모두 CEAL_MS가 높은 성능을 달성한 것을 확인할 수 있습니다. 저자의 설명으로는 TCAL은 풍부한 high confidence 데이터를 활용한 CEAL과 달리 소수의 데이터만을 이용해서 성능이 떨어진다고 설명합니다. 비교군에 대한 설명을 간략해 드리자면,
- AL_ALL : 모든 학습 샘플을 사람이 라벨링해서 학습시킨 것입니다. 위에 주황색으로 직선에 가까운것을 확인할 수 있습니다. 저희가 빠르게 달성하기 원하는 성능으로 생각하시면 됩니다
- AL_RAND : 학습 과정 중 annotation할 샘플을 random sampling한 것입니다. 별다른 AL 방법이 적용되지 않은, lower bound로 생각하시면 됩니다.
- Triple Criteria Active Learning(TCAL) : 기존에 제안된 uncertainty, diversity, density를 모두 고려한 AL 방법론이라고 합니다. 기존 SOTA로 생각하시면 되겠습니다.
이후에는 수도라벨링 데이터(high confidence majority data)를 사용한 학습 효과를 입증하기 위한 실험입니다.
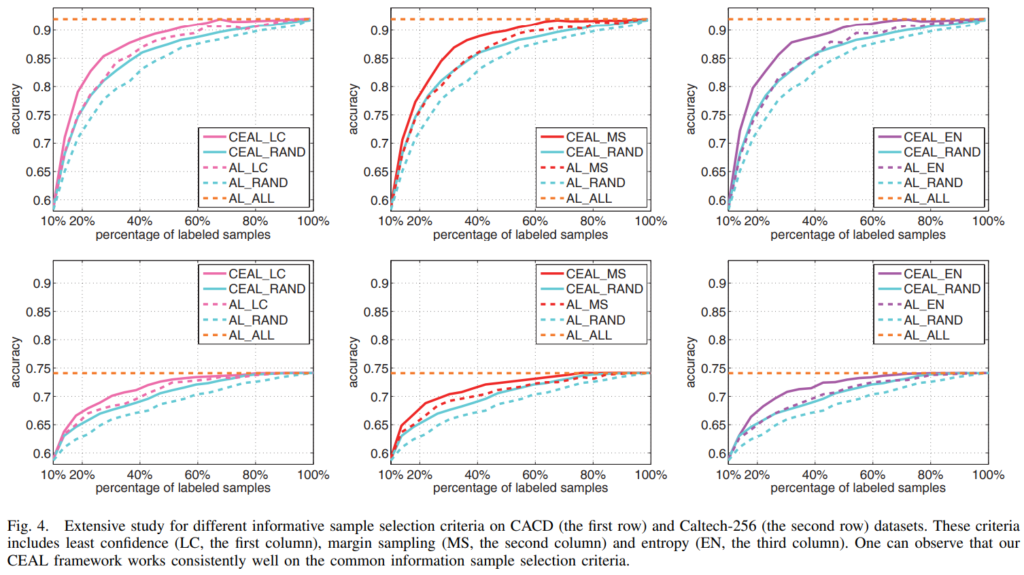
LC는 least confidenc, MS는 margin sampling, EN는 entropy를 의미합니다. CEAL_LC, CEAL_MS, CEAL_EN는 저자가 제안한 방법론을, AL_LS, AL_MS, AL_EN은 high confidence majority 데이터를 이용하지 않은 결과입니다. 한 눈에 봐도 수도 라벨을 이용한 방법의 성능이 월등한 것을 확인할 수 있습니다.
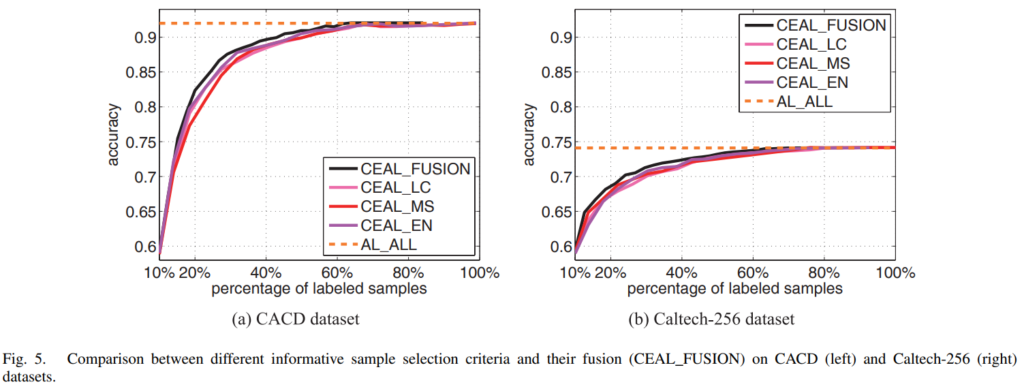
이것은 informative minority sample을 어떤 기준으로 고를 것인지에 따른 실험입니다. CEAL_FUSION은 3가지 기준(LC, MS, EN) 모두를 사용해서 샘플링 한 이후 중복되는 데이터는 버리고 학습한 것인데, fusion의 성능이 가장 높습니다. 이는 uncertainty로 샘플링한 데이터가 비록 그 수는 적지만 classifier의 학습에 매우 중요하며, AL에서 여전히 informative 데이터가 중요한 비중을 차지하고 있다는 것을 보여주는 것이라고 설명합니다.
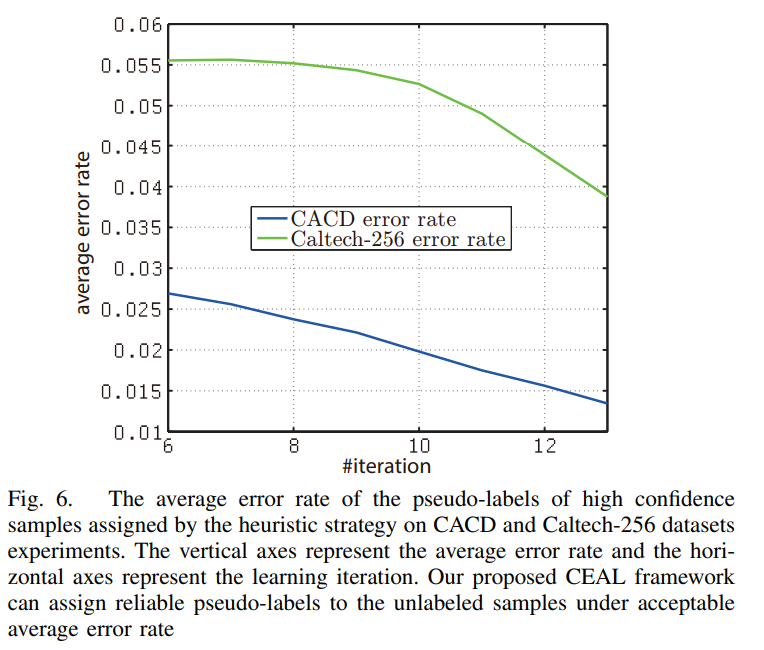
이는 CEAL의 수도라벨링이 과연 믿을만하냐? 라는 부분에 대한 실험입니다. Active Learning에서는 항상 실제 정확도보다 모델이 예측값을 과신하는 overconfidence 문제가 있는데요(얼마 전 황유진, 조원, 홍주영 연구원님이 이를 다룬 논문을 작성하셨죠), 저자들은 이 부분을 확인하기 위해 수도라벨의 에러율을 나타내었습니다. 해당 실험을 통해 수도라벨의 에러율이 낮음을 확인할 수 있었습니다.
Conclusion
CNN에 AL을 처음 접목 시킨 근본 방법론 CEAL에 알아보았습니다. AL 분야 자체가 아직 저에겐 낯설고 어려운데 그래도 지난번에 리뷰한 Core-set보다는 수월하게 읽을 수 있었습니다. 개인적으로 수도라벨링을 활용하는 논문을 읽어본 것 자체가 처음인데, semi-supervised learning쪽도 계속 관심을 가져야겠다는 생각이 들었습니다.
감사합니다.
안녕하세요. 좋은 리뷰 감사합니다.
논문의 방법론이 굉장히 깔끔하여서 덕분에 읽으며 이해하기 쉬웠습니다. 한가지 간단한 질문이 있는데 초반에 모델이 높은 threshold를 사용하는 것에 대해서는 이해가 되는데 왜 학습하면서 점점 threshold를 낮춰가는 걸까요? 이렇게 하면 어떤 점에서 장점이 있길래 threshold를 이렇게 가져가는 것인지 잘 이해가 가지 않습니다. 오히려 threshold를 계속 높은 것으로 유지하는 것이 더 확실하게 라벨링하기 때문에 에러율이 작지 않을까 생각이 들어 질문 드립니다.
감사합니다.
간단합니다. threshold를 낮추면 그만큼 많은 데이터를 활용할 수 있기 때문입니다. threshold를 높게 제한하는 초기 모델과 충분히 학습이 진행된 상태의 모델은 완전히 다른 수준의 예측 수준을 갖기 때문에, 아직 충분한 분류 능력을 갖추지 못한 초기에는 수도라벨이 잘못 붙여지는것을 방지하기 위해 threshold를 높이 가져가게 됩니다. 하지만 모델이 반복적인 학습을 통해서 충분한 분류 능력을 확보했으면 threshold를 낮추어도 정확한 예측이 가능해지고, high confidence 데이터를 많이 확보할 수 있습니다. 데이터는 많을수록 좋으니 threshold를 조금씩 낮춰가는게 좋은 성능을 달성하는 데에 있어 이점이 있습니다.
안녕하세요.
기존 AL 프레임워크에 CNN을 붙이는 것은 divergence problem을 일으킨다고 해주셨는데, divergence problem이 대략 어떤 것인지 설명해주실 수 있나요?
그리고 방법론에서 backpropagation 설명이 꽤 많은 부분을 차지하는 것 같은데, 이것은 진짜 당시 딥러닝의 초반 시기라 이해를 돕기 위해 들어가 있는 내용인것인가요?
divergence problem에 대해서는 어떤 추가적인 언급이나 citation 없이 그냥 문제가 있다고 설명하고 넘어가서 정확히 어떤 것인지는 모르겠지만.. 저는 ‘딥러닝 프레임워크에 알맞지 않은 방식을 적용해서 모델이 수렴하지 않고 발산한다. 즉 제대로 학습되지 않는다’ 라고 이해하고 넘어갔습니다. 저도 궁금해서 구글에 검색해봤는데 관련된 내용이 나오지는 않네요. 그냥 파이프라인의 차이 때문에 의미 있는 학습이 진행되지 않는다고 받아들이면 될 것 같습니다.
리뷰를 다시 보니 CNN finetuning backpropagation 부분이 마치 설명이 잘린 것 같이 보일 수 있을 것 같은데, 내용을 자르지 않고 해당 단락 전체를 나눠 캡쳐해서 리뷰에 실었습니다. 리뷰에서 누락된 내용은 없습니다. 다시 읽어봐도 그냥 딥러닝 내용을 설명한 것이 끝이네요. 논문이 게제된 때가 2017년임을 생각해보면 CNN에 익숙하지 않은 독자를 고려해 설명을 실은 것으로 보입니다. 사실 저도 이 부분을 읽으면서 ‘다들 아는 CNN 학습 과정을 굳이 이렇게 현학적인 수식으로 표현해서 넣었어야 하나..’ 라는 생각을 하긴 했습니다.
좋은 질문 감사합니다!
안녕하세요. 좋은 리뷰 감사합니다.
리뷰에서 높은 confidence를 가지는 sample을 선별하여 수도 라벨을 붙이는데, 이 high confidence sample을 선별하는 기준이 threshold라고 하셨습니다. 근데 이 threshold같은 경우 학습 초기에 큰 값으로 설정한 후 학습이 진행되면서 점차 작아진다고 하셨는데 굳이 threshold를 낮춰가며 학습하는 이유가 궁금합니다. 학습을 진행할수록 더 많은 sample을 선택하기 위해서인가요 ? 또, 초기 threshold값과 decay rate값은 얼마로 설정된 것인지 궁금합니다.
감사합니다.
threshold를 낮추면 그만큼 많은 데이터를 활용할 수 있기 때문입니다. threshold를 높게 제한하는 초기 모델과 충분히 학습이 진행된 상태의 모델은 완전히 다른 수준의 예측 수준을 갖기 때문에, 아직 충분한 분류 능력을 갖추지 못한 초기에는 수도라벨이 잘못 붙여지는것을 방지하기 위해 threshold를 높이 가져가게 됩니다. 하지만 모델이 반복적인 학습을 통해서 충분한 분류 능력을 확보했으면 threshold를 낮추어도 정확한 예측이 가능해지고, high confidence 데이터를 많이 확보할 수 있습니다. 데이터는 많을수록 좋으니 threshold를 조금씩 낮춰가는게 좋은 성능을 달성하는 데에 있어 이점이 있습니다.
초기 threshold값의 경우 CADC는 0.05, Caltech의 경우 0.005로 설정되었으며 dr의 경우 CADC는 0.0033, Caltech의 경우 0.00033으로 설정했다고 논문에 써져 있습니다.
안녕하세요. 허재연 연구원님.
좋은 리뷰 감사합니다.
혹시 모델에서 학습 초기에 confident하게 a 클래스로 분류하여 pseudo label이 a로 생성된 샘플이, 추가 학습 후 confidence가 threshold 밑으로 떨어지거나, 예측 결과가 b로 바뀌면 어떻게 되나요? 이전에 추가한 pseudo label을 업데이트 하는지 그냥 두는지 궁굼합니다.
감사합니다.
한 번 학습에 사용한 high confidence dataset DH는 수도라벨을 떼어버리고 다시 unlabeled data pool DU로 들어갑니다. 수도라벨이 끝까지 라벨링된 데이터셋에 사용되지 않습니다. 학습을 통해 동일 데이터에 대해 다른 예측을 할 수도 있지만 그럼 달라진 라벨로 학습을 하게 될 것입니다.
안녕하세요 허재연 연구원님 좋은 리뷰 감사합니다.
결국 이 논문은 우리가 알고 있는 uncertainty기반의 AL pipeline을 제안한 논문이라고 이해하였습니다. 제가 이해한 것을 정리하자면, 대량의 unlabeled 데이터를 소량의 데이터로 학습된 모델에 입력하여 uncertainty가 높은, 즉, 결정 경계에 가까운 데이터를 선별하여 labeling하는 방식입니다. 이에 더해 uncertainty가 일정 threshold이상 낮은, 즉, 매우 높은 확신도를 가진 데이터는 psudo label을 부여하여 labeling pool에 추가하여 모델을 업데이트합니다.
리뷰를 읽고 질문이 있는데요, psudo labeling을 진행한 high confidence sample의 경우, 해당 라벨을 매 iteration마다 업데이트를 진행하는 것인지, 초기 라벨을 고정적으로 사용하는지, 아니면 일정 주기로 업데이트가 진행되는 지 궁금합니다.
추가로 threshold 값을 어떻게 선정하는지, 그리고 어떤 주기로 얼만큼 줄여나가는지에 따른 실험 결과는 없는지 궁금합니다. threshold의 값에 따라 psudo label의 정확도에 차이가 있을 듯 한데 저자들은 어느 정도의 값을 적정한 값이라고 생각하였는지 궁금하네요.
감사합니다.
1. high confidence sample의 경우 매 iteration마다 뽑아서 수도라벨을 붙여 학습에 이용하고, 학습이 완료되면 수도라벨을 떼어버리고서 다시 unlabeled pool에 넣게 됩니다.
2. Method 부분의 Algorithm 1과 D. Threshold updating을 참고하시면 이해가 쉬울 것입니다. high confidence samples selection threshold δ값은 매 iteration마다 δ – dr*t 값으로 업데이트됩니다. 이 이외에 iteration 주기에 대한 추가적인 설명이나 실험은 딱히 나와있지 않습니다. 논문에서 threshold와 dr값은 값을 조정하며 여러 번 실험을 진행해서 적절한 값을 찾았다고 합니다.
좋은 질문 감사합니다. 이해해 도움이 되었길 바랍니다.
좋은 리뷰 감사합니다.
해당 논문 내용을 보니 다크데이터 팀에서 설명하던 uncertainty 기반 방법론의 기초가 되는 방법론으로 보이네요.
다른 분들이 디테일한 질문을 하셔서 가지고 있던 궁금증은 풀렸습이다만 실험 파트 중 fig 6의 error rate는 어떻게 계산되어지는지 궁금합니다.
추가로 될 수 있으면 논문이 출판된 년도를 타이틀에 적어주시면 좋을 것 같아요.
김태주 연구원님, 질문 주셔서 감사합니다. 논문을 다시 살펴봤지만 해당 부분을 정확히 어떻게 계산하는지 명시적으로 나와있지는 않습니다. 하지만 수도 라벨의 에러율을 측정하는 맥락으로 추측해보면, 각 iteration마다 전체 수도 라벨 중 GT라벨과 다른 수도 라벨을 갖는 데이터 개수를 비율로 나타낸 것으로 보입니다.
감사합니다.