안녕하세요, 열다섯번째 x-review 입니다. 이번 논문은 ECCV 2022에 게재된 Point-MAE로 포인트 클라우드에 masked autoencoding을 적용한 backbone 네트워크를 처음으로 제안한 논문 입니다. 그럼 바로 리뷰 시작하겠습니다 !

1. Introduction
self-supervised learning(SSL)이란 사람이 데이터에 대한 어노테이션을 거치는 대신 라벨이 없는 데이터에 대해 latent feature을 학습하는 것을 의미합니다. SSL은 현재 NLP와 비전 분야에서 활발히 사용되고 있는데 그 중에 masked auto encoding은 language와 이미지 모두에서 좋은 성능을 보이고 있다고 합니다. 입력 데이터의 일정 부분에 랜덤하게 마스킹을 적용하여 마스킹 된 부분에 대해 원래의 형태로 복원하기 위해 auto encoder을 사용하는 것을 masked auto encoding이라고 정의하고 있습니다. 마스킹된 부분에 대한 데이터 정보는 제공하지 않기 때문에 reconstruction을 위해서 auto encoder는 latent feautre을 학습하게 되는 것이죠. 이러한 masked autoencoding은 비단 언어와 이미지 뿐만 아니라 3D에서의 포인트 클라우드에서도 적용할 수 있는데요, 두 task와 유사하게 포인트 클라우드 또한 각각의 포인트가 아주 독립적인 데이터가 아니라 이웃한 포인트들과의 관계를 통해서 local한 특징들을 제공하고, local한 정보가 모여 하나의 global한 정보까지 제공할 수 있기 때문 입니다. 그래서 여러 포인트의 집합들을 토큰으로 임베딩하여 타 task처럼 masked autoencoding이 가능하게 됩니다. 당시에 3D에서는 masked autoencoding과 유사하게 동작하는 네트워크나 autoencoding을 적용하는 연구들이 존재하긴 했지만 그러한 방법론들은 pretrain할 때 트랜스포머의 입력으로 마스킹된 토큰들이 들어가게 되면서 높은 계산 resource와 위치 정보를 초기에 사용하게 된다는 한계점이 존재하였습니다. 이러한 한계점을 해결하기 위해, 그리고 masked autoencoding을 포인트 클라우드에 적용하기 위해서 저자는 새로운 네트워크를 제안하고자 한 것 입니다. 현재 포인트 클라우드에 masked autoencoding을 적용하기에 몇가지 어려운 측면들을 소개하며 해결할 수 있는 방안에 대해 소개하고 있습니다. 먼저 3D 범용적인 transformer 구조가 부족하다는 것 인데요, transformer나 ViT 등이 존재하긴 하지만 포인트 클라우드를 처리하기 위한 트랜스포머 구조는 아직도 완전히 자리잡은 구조가 없다고 합니다. 제가 논문들을 읽어보아도 아직까지도 transformer 기반의 논문들은 2D Detr에서 변형된 구조들을 가지기 때문에 저자도 이러한 점을 지적한 것이 아닐까 생각이 듭니다. 그래서 본 논문에서는 범용적으로 사용할 수 있는 standard transformer을 기반으로 한 autoencoder backbone 네트워크를 제안하고 있습니다. 다음으로는 마스킹 토큰의 position embedding을 할 때 위치 정보가 노출된다는 점 입니다. 모든 마스킹 토큰은 position embedding을 통해서 입력 데이터로 위치 정보가 제공되는데, 위치 정보를 제공한다는 것이 2D 이미지에서는 중요한 문제가 아니라고 합니다. 왜냐하면 위치 정보를 포함하지 않고 있기 때문인데요, (classification 기준으로 이야기하는 것 같습니다. ) 포인트 클라우드는 데이터 자체에 좌표 정보가 포함되어 있다는 점에서 마스킹 토큰에 대한 recunstruction이 어렵지 않은 문제로 정의될 수 있다는 것 입니다. 이러한 부분을 해결하기 위해서 인코더에 입력으로는 마스킹 토큰을 사용하지 않고 디코더의 입력으로만 사용하고자 하였습니다. encoder가 마스킹되지 않은 부분에 초점을 맞추어 작동되도록 하여 최대한 위치 정보의 사용을 미루고자 하였습니다. 마지막으로는 여타 포인트 클라우드를 다루는 모든 논문에서 동일하게 언급하는 포인트 클라우드의 irregular한 특성을 이야기 하고 있습니다. 데이터 분포가 매우 불규칙하지만 그 중에서도 중요한 local 특징인 코너나 엣지를 나타내는 포인트는 다른 영역에 비해 dense하게 분포되어 있습니다. 즉 코너, 에지를 나타내는 영역이 마스킹된다면 물체를 reconstruction하는 것이 더 어려워진다는 뜻이 되겠죠. 그런데 포인트 클라우드에서 이러한 불규칙성이 존재하지만 높은 비율로 마스킹을 적용였을 때 recunstruction 더 잘 이루어지는 것을 확인하였고 저자는 이러한 점에서는 포인트가 이미지와 유사하다고 분석하였다고 합니다.
이러한 문제점들에 대한 분석을 바탕으로 본 논문에서는 포인트 클라우드를 masked autoencoding으로 처리하는 Point-MAE를 제안합니다. 크게 포인트를 마스킹하고 임베딩하는 모듈, 그리고 autoencoder로 이루어진 구조로 간략하게 설명해보면 포인트를 패치 형태로 나누어 랜덤하게 마스킹을 적용한 이후 마스킹되지 않은 패치들에 대해 autoencoder가 latent feature을 학습하도록 합니다. 이후 decoder와 prediction head를 거쳐 마스킹된 패치들에 대한 reconstruction이 진행됩니다. 제안한 Point-MAE은 pretrained model로 다양한 downstream task에 사용될 수 있고 classification 데이터셋인 ScanObjectNN과 ModelNet40에서 다른 self-supervised learning과 비교하였을 때 SOTA를 달성하였습니다. 또한 supervised learning에서의 트랜스포머 모델들의 성능까지도 넘어서며 의미있는 결과를 도출하였다고 합니다.
2. Related Work
SSL for Point Cloud
self supervised learning은 포인트 클라우드 representation learning에서 널리 연구되고 있는데 그 중에 DepthContrast는 입력으로 들어오는 포인트 클라우드에 대해 두 개의 augmentation 결과에 대해 contrastive learning을 진행하며 OcCo는 카메라 뷰에서 occlusion된 포인트 클라우드로부터 원래의 포인트 클라우드를 복원하는 방법론 입니다. introduction에서도 그렇고 실험에서도 계속해서 Poin-MAE와 비교될 최근 방법론인 Point-BERT는 입력 토큰을 마스킹하여 BERT 형식으로 pretrain model을 제안하고 마스킹 된 부분에 대한 discrete 토큰을 예측하고자 하는 네트워크 입니다. 본 논문에서는 introduction에서 언급한 이러한 포인트 클라우드에 대한 self supervised learning의 한계점들을 해결하기 위해 제안된 것이죠.
Autoencoders
autoencoder는 인코더가 입력에서 high leveld의 latent feature을 얻고 디코더에서는 그러한 인코더의 결과로 원래 입력의 형태를 reconstruct 합니다. 따라서 궁극적인 목적은 원래 입력과 최대한 유사하게 복원하고자 하는 것 입니다. 본 논문의 방법론은 denoising autoencoder의 분류될 수 있으며 denoising autoencoder는 입력 데이터에 노이즈를 주는 것으로 masked autoencoding은 그 노이즈를 masking으로 주게 되는 것이죠. NLP에서 model에게 랜덤하게 단어를 마스킹하여 가려진 부분에 대한 단어를 예측하거나, 이미지에서 패치 단위로 픽셀 영역을 가려 원래와 유사한 이미지를 예측하는 것처럼 본 논문 역시 포인트 클라우드를 대상으로 masked autoencoding을 적용하고 있습니다.
3. Point-MAE
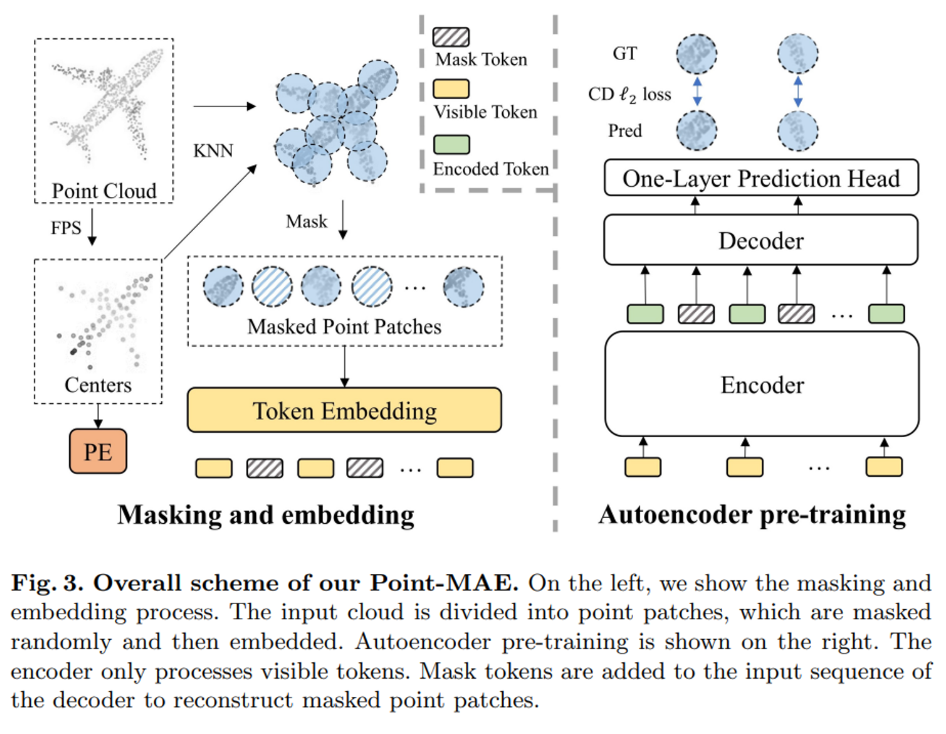
3.1. Point Cloud Masking and Embedding
이미지의 특정 사이즈를 가진 채로 균일한 패치로 편하게 나눌 수 있는 반면에 3D 공간에서 불규칙한 형태로 존재하는 포인트 클라우드를 처리하기 위해서 본 논문에서는 3가지 단계를 제안합니다.
Point Patches Generation
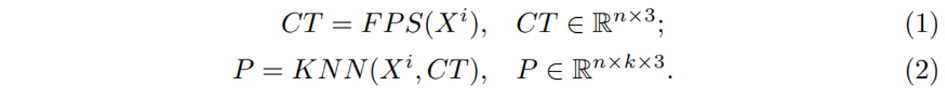
먼저 Farthest Point Sampline (FPS)와 KNN 알고리즘을 사용하여 포인트를 패치 형태로 나누게 됩니다. 입력으로 p개의 포인트가 들어오면 FPS로 패치의 중심이 될 포인트 n개를 샘플링 합니다. 그러면 n개의 중심에 대해서 샘플링 하기 전 포인트 기준으로 k nearest 포인트를 선택하여 하나의 포인트 패치 P을 형성할 수 있습니다. 식(1), (2)가 앞선 과정을 나타낸 식으로 X^i가 입력으로 들어오는 포인트, CT가 샘플링 된 중심 포인트를 의미하고 식(2)가 KNN으로 형성한 포인트 패치를 의미합니다. 각 패치가 만들어지고 나면 한 패치 내의 포인트들은 중심 포인트를 기준으로 normalization된 local 좌표로 표현할 수 있습니다.
Masking
Fig3에서의 만들어진 패치 예시를 보게 되면 각 패치마다 겹치는 영역이 생길 수 있는데 저자는 패치마다의 정보를 완전히 유지하기 위해서 분리하여 마스킹한다고 표현하고 있습니다. 정보를 완전히 유지한다는 것은 겹치는 영역이라고 마스킹을 하지 않는 것이 아니라 마치 겹치지 않는 것처럼 온전한 패치 영역 내의 포인트를 모두 마스킹하는 것을 의미하는 것 같네요. 마스킹 비율을 m이라고 표현하는데, 비율을 높게 설정하였을 때 (대략 60% – 80%) 좋은 성능을 보이는 것을 확인하였다고 합니다. 참고로 마스킹 패치를 모두 모아놓은 집합 P_{gt} \in \mathbb{R}^{mn \times k \times 3}은 reconstruction loss를 계산할 때 gt로 사용된다고 하는데, recunstruction에 대해서는 뒤에서 더 자세히 살펴보도록 하겠습니다.
Embedding
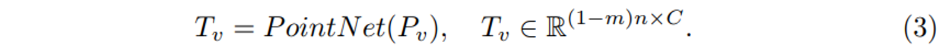
이제 포인트를 패치화 시켜 일정 비율로 마스킹까지 진행하였으니 패치를 토큰으로 임베딩 시켜야 하는데, 우선 마스킹 포인트 패치는 T_m \in \mathbb{R}^{mn \times C}로 m개의 마스킹 토큰을 표현하며 C가 임베딩 차원이 됩니다. 마스킹 패치에 대한 토큰 임베딩은 가중치를 공유하는 learnable 마스크 토큰을 이용하였습니다. 또한 마스킹 되지 않은 포인트 패치에 대해서는 flatten하고 linear projection 하는 것이 가장 단순한 방법일 순 있으나, 이러한 linear한 임베딩 방식은 permutation invariance를 보장하지 못할 수 있습니다. 그렇기 때문에 저자는 lightweight PointNet을 사용하는데, 이는 PointNet이 MLP에서 maxpool layer을 통해 permutation invariance를 유지할 수 있는 네트워크 구조를 가졌기 때문 입니다. 따라서 식(3)의 P_v가 visible token으로 정의 됩니다. 추가저으로 포인트 패치를 만들 때 normalization한 로컬 좌표를 사용하였기 때문에 임베딩한 토큰에 각 패치의 중심 포인트 좌표 정보를 제공해야 했는데요, 이러한 중심 포인트에 대한 임베딩은 learnable한 MLP로 임베딩 차원인 C에 중심 좌표를 매핑시키면서 해결하였습니다.
3.2. Autoencoder’s Backbone
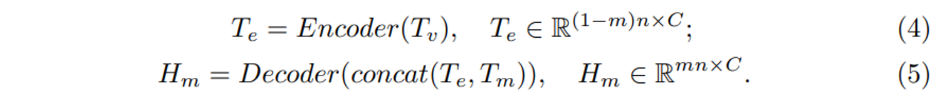
이제 autoencoder의 구조를 살펴볼텐데요, 전체적으로 standard 트랜스포머를 기반으로 구성되어 있습니다. 먼저 인코더는 마스크 토큰을 제외한 visible token T_v만을 인코딩 하여 T_e라는 인코딩 토큰을 만들어냅니다. 반면 디코더는 인코더의 출력인 T_e와 더불어 마스킹 토큰인 T_m까지 입력으로 들어가서 최종 마스크 토큰인 H_m을 디코딩 결과로 출력하게 됩니다. 해당 구조에서는 마스크 토큰을 인코더에서 처리하지 않는데에는 두 가지 이유가 있습니다. 첫번째는 60-80%에 해당하는 높은 비율의 마스킹 처리를 하기 때문에 인코더에 들어가는 입력 토큰의 수를 줄일 수 있어 기존 트랜스포머에서 발생하는 computational resource를 아낄 수 있다는 점 입니다. 하지만 더 중요한 점은 마스킹 토큰을 디코더에서 처음으로 사용하면서 인코더에서는 마스크 토큰의 위치 정보를 숨김(?)으로써 latent feature을 더 잘 학습할 수 있었다는 것 입니다. 마스킹 토큰의 위치 정보가 인코더에서부터 활용된다면 introduction에서도 이야기 하였듯이 인코더가 한층 쉬운 문제를 풀고 있는 것과 다름없기 때문이죠 ..
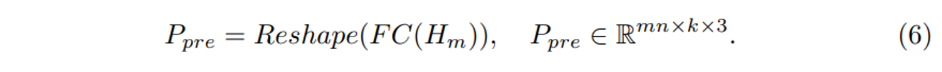
위의 인코더-디코더 구조의 백본 마지막 레이어는 마스킹 포인트 패치(H_m)를 reconstruct하기 위해 FC 레이어를 사용한 prediction head가 존재합니다. 디코더로부터 출력값을 받으면 prediction head가 이를 벡터로 projection하는데 projection된 벡터는 원래 포인트 패치의 동일한 shape을 가지고 투영됩니다. 따라서 식(6)의P_{pre}가 최종 예측한 포인트 패치가 되겠네요.
3.3 Reconstruction Target
이제 개별적으로 예측한 포인트 패치를 가지고 원래 포인트의 위치로 reconstruction 해야 합니다. 예측 포인트 패치인 P_{pre}와 P_{gt} 사이에 L2 chamfer distance를 사용하는 reconstruction loss를 계산하게 되는데, 여기서 P_{gt}가 앞선 masking 파트에서 이야기하였던 임베딩 하기 이전에 모아놓았던 마스킹 패치 집합을 가리킵니다.
4. Experiments
실험은 ShapeNet에서의 pretrained model로 여러 task에서의 실험을 진행하였습니다.
4.1 Pre-training setup
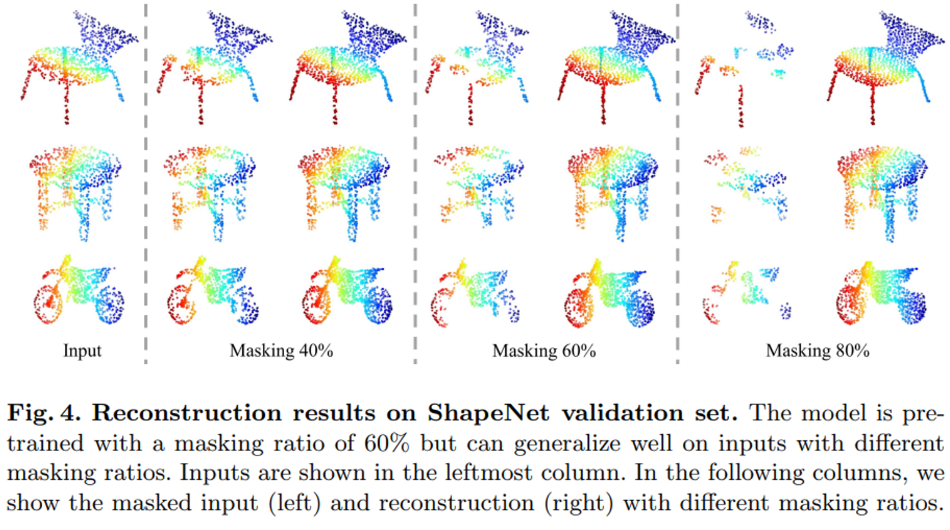
먼저 ShapeNet에서 pretrain을 하였고 Figure4가 reconstruction 결과 입니다. 60%로 비율로 마스킹하였지만 저자는 다른 마스킹 비율로 들어온 입력에 대해서 reconstruction이 가능하기 때문에 높은 일반성을 가지고 있다고 이야기합니다.
4.2. Downstream Tasks
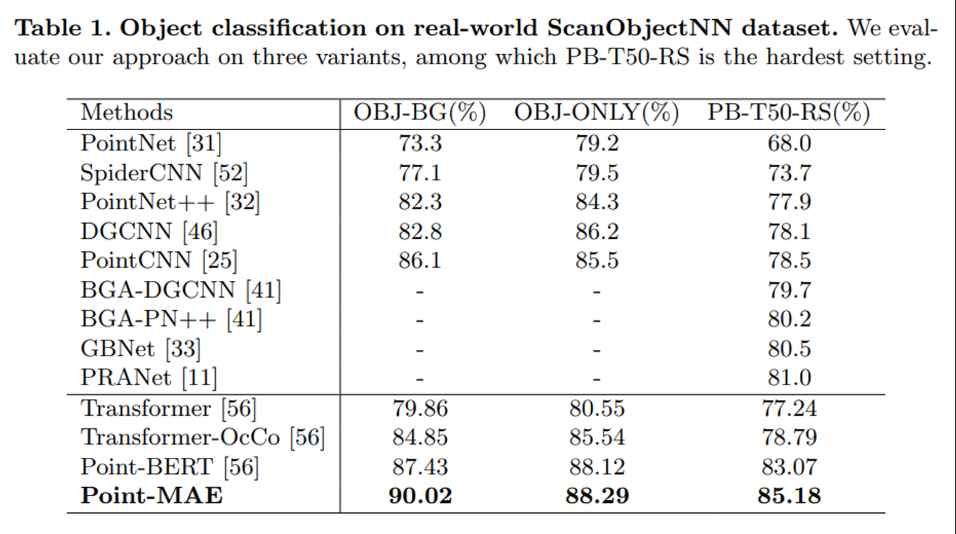
포인트 클라우드에 대한 SSL에서 메인 관심사는 흔히 pretrain에 사용하는 데이터셋인 ShapeNet은 배경 정보나 scene의 다른 영역에 대한 정보가 아예 없는 clean 모델로 challenge한 경우가 거의 없다는 것 입니다. 그래서 저자는 pretrained 모델을 challenge한 real world 데이터셋인 ScanObjectNN에서 실험을 진행하였습니다. ScanObjectNN은 ShapeNet과 다르게 실제 indoor scene에서 배경과 주변 환경과 함께 스캔된 데이터셋으로 Table1이 그에 대한 실험 결과 입니다. standard Transformer와 비교했을 때 큰 폭을 가지고 성능이 향상되었으며 가장 어려운 경우인 PB-T50-RS에서도 기존 SOTA인 Point-BERT와 2.11%의 차이를 보여주고 있습니다. 비록 clean 데이터셋으로 사전학습 되었어도 Point-MAE는 real world 데이터셋에서도 잘 작동한다는 것을 보여주는 실험 입니다.
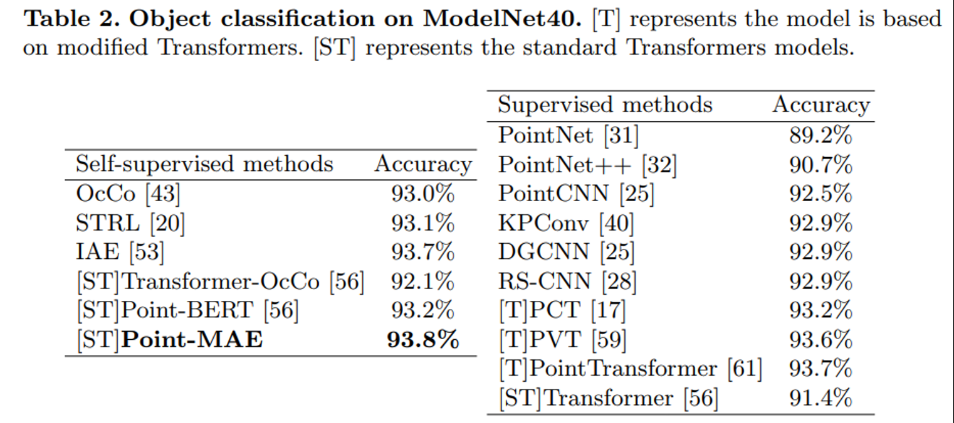
Table2는 또 하나의 classification 데이터셋인 ModelNet40에서의 성능을 보여주며 다른 Self supervised learning 방법론과 비교하여 sota를 달성하였습니다. 특히 supervised learning인 transformer 방법론들과 비교해도 가장 높은 성능을 보여주고 있습니다.
4.3. Ablation Study
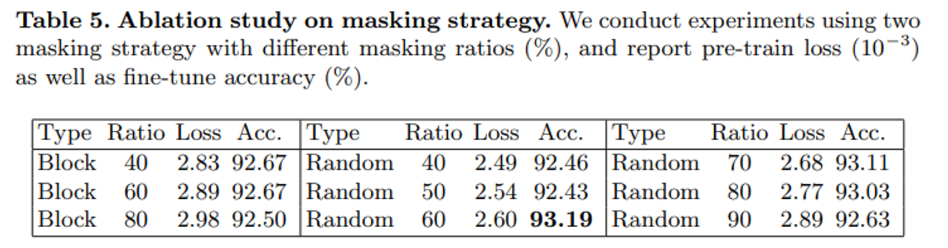
다음은 마스킹 유형과 비율에 따른 ablation study로 block masking이란 인접한 포인트 패치 여러개를 마스킹하여 마스킹된 하나의 블록을 생성하는 마스킹 방식 입니다. 더 넓은 영역을 한번에 마스킹하여 reconstruction을 어렵게 하지만 결과적으로 낮은 마스킹 비율에서도 준수한 성능을 보일 수 있습니다. 블록 마스킹과 랜덤 마스킹을 비교하였을 때 60%-80% 마스킹 비율을 적용한 구간이 가장 높은 성능을 나타내며 그보다 마스킹 비율을 더 낮추면 블록 마스킹보다 더 낮은 성능을 보이며 또 80% 보다 비율을 더 높이게 되면 오히려 성능이 떨어지는 것을 확인할 수 있습니다. 해당 ablation study를 통해 본 논문에서 마스킹 비율을 60%-80%로 설정한 근거를 실험적으로 증명하였습니다.
Effect of shifting mask tokens
논문에서 마스킹 토큰을 encoder가 아니라 decoder의 입력에서만 사용하였는데, 그에 대한 효과를 증명하기 위해서 encoder에도 동일하게 마스킹 토큰까지 처리하였을 때의 실험을 진행하였다고 합니다. 이상하게 이에 대한 실험 테이블은 포함되어 있지 않지만 .. 논문에서 서술하기로는 ModelNet에서 실험을 진행하였을 때 92.14%의 정확도를 달성하면서 기존 Point-MAE의 93.19%에 미치지 못하는 결과를 보여주었다고 합니다. 그러한 결과를 바탕으로 마스킹 토큰까지 포함된 모든 토큰을 인코더의 입력으로 사용하였을 때 각 토큰에 대한 position embedding으로 인해 위치 정보가 제공되어 초기에 위치 정보를 사용하는 것이 high level의 latent feature을 학습하지 못하도록 방해하여 성능 저하에 영향을 준다는 것을 보여주고는 있습니다만 실험 테이블이 없는 것이 조금 아쉬운 것 같습니다.
안녕하세요. 좋은 리뷰 감사합니다.
position embedding과 관련하여서 질문이 있는데, position embedding을 통해서 위치 정보가 노출된다는 것이 왜 2D 이미지에서는 중요한 문제가 아닌가요? 3D와 마찬가지로 autoencoding을 할 때 position 이라는 정보가 추가로 제공되기 때문에 3D에서 그런 것처럼 high level의 latent feature을 학습하지 못하도록 방해하여 성능 저하에 영향을 줄 것 같은데 이러한 부분에 대해서는 논문에서 어떻게 말하고 있나요? 그리고 2D 이미지에서 위치 정보를 제공하는데 위치 정보를 포함하지 않는 다는 말이 잘 이해가 가지 않습니다.
감사합니다
안녕하세요 ! 리뷰 읽어주셔서 감사합니다.
논문에서는 단순히 이미지에서는 위치 정보를 포함하지 않는다라고 이야기하는데 좀 더 저자의 의도를 생각을 해보면 .. 사실 이미지에서 mae는 이미 인코더에서 visible token만을 입력으로 사용하고 있기 때문에 마스킹 토큰의 position 정보가 인코더에서 일찍이 노출된다는 가정 자체가 성립이 되지 않습니다. 그렇지만 포인트 클라우드에서는 당시에 나온 마스킹 포인트를 사용했던 논문들은 인코더에서부터 마스킹 토큰을 입력으로 넣어 포인트의 위치 정보를 사용해왔기 때문에 그러한 두 분야에서의 연구 동향을 비교하여 이야기한 것이 아닐까 생각합니다. 위치 정보가 포함되어 있지 않다, 중요한 문제가 아니다라고 이야기하면서도 부가적인 설명이 들어갔어야 했는데 그 부분이 부족했네요 하하
좋은 리뷰 감사합니다.
Masking과정의 경우, 패치로 나누었을 때 특정 point들일 겹치더라도 각 패치별로 분리된 정보로 고려하는 것으로 이해하였습니다. 제가 이해한 바가 맞다면, 해당 논문에서 표현하는 마스킹 비율은 실제 object의 포인트를 고려할 경우 다른 비율이 되는 건 아닌지 궁금합니다. 그리고 이러한 점에서 FPS로 뽑은 중심에 대하여 N개의 nearest point를 고를 때, N은 어떻게 결정되는 지도 궁금합니다.
추가로 Figure4의 reconstruction은 Input을 GT로 보면 되는 것인가요?? reconstruction 결과가 굉장히 좋아보여서 신기합니다.
안녕하세요 ! 리뷰 읽어주셔서 감사합니다.
본 논문에서의 마스킹 비율은 물체의 포인트들을 패치로 나눈 후에 패치를 기준으로 이야기하고 있습니다. 그리고 KNN에서의 이웃한 포인트 개수는 하이퍼 파라미터 입니다.
마지막으로 Figure 4의 input이 GT가 되는 것이 맞습니다 !
안녕하세요. 좋은 리뷰 감사합니다.
읽으면서 궁금했는데, 포인트 클라우드에 인코더에 마스킹 토큰을 입력으로 사용하지 않는 것이 이 논문이 처음인가요 ? 그리고 각 패치의 정보를 온전히 유지하기 위해서 패치끼리 겹치는 부분을 신경쓰지 않고 하나의 패치에 포함되는 전체 부분을 마스킹한다고 하셨는데, 그럼 만약 겹치는 부분이 존재하는 두 패치 중 하나의 패치만 마스킹 되고 나머지 하나는 마스킹 되지 않는 경우에는 어떻게 처리되는 것인지 궁금하네요 .. 하나가 visible 토큰으로 들어가게 되면 마스킹 토큰의 일부 영역에 대한 정답 정보를 제공주게 된다고 생각하는데 . . . 이 부분에 대한 고려사항은 없었는지 궁금합니다.
감사합니다.
안녕하세요 ! 리뷰 읽어주셔서 감사합니다.
본 논문이 포인트 클라우드에 masking autoencoder를 적용한 첫 논문인데요, 비슷하게 마스킹된 포인트를 입력으로 사용했던 방법론들을에서는 모두 encoder에도 마스킹 포인트를 사용했다고 합니다. 그런데 이미지에서의 mae에서는 visible token만 encoder에서 사용했으니 기존 mae를 포인트 클라우드에 그대로 끌고 온 것이라고 생각해주시면 될 것 같습니다. 그 다음 마스킹이 겹치는 영역에 대해서 윤서님이 말씀해주신 부분이 저도 의문이 들었던 점인데, 논문 내용만으로는 패치 내에 존재하는 영역 중에 다른 패치에서 마스킹 된 부분이라고 하더라도 패치 자체가 마스킹 패치가 아닌 이상 그대로 visible token으로 임베딩 되는 것 같습니다 ..