제가 이번에 리뷰할 논문도 6D Pose Estimation 논문입니다. CVPR 2023 논문으로, Self-supervised 방식을 도입한 방법론입니다.
Abstract
본 논문은 합성 데이터와 일부의 unlabeled real 데이터를 이용한 Neural Texture Learning을 소개합니다. 동일 모달리티나 refinement에 의존한다는 문제를 해결하고자 새로운 학습 방식을 제안하였으며, texture learning과 pose learning 두가지로 나누어 각각을 학습합니다. 이때, texture는 실제 데이터를 이용하고, pose 정보는 정확한 GT를 얻을 수 있는 합성 데이터를 이용하게 됩니다. 해당 방법론을 통해 GT pose 정보가 없는 방법론들과 비교했을 때, SOTA를 달성하였고, unseen에 대하여 일반화 성능이 개선됨을 보였다고 합니다.
Introduction
물체와 상호작용을 하기 위해서는 3차원 공간에서 물체의 rotation과 translation 정보를 알아야 합니다. 이러한 6D Pose 정보를 예측하는 연구는 컴퓨터비전에서 중요한 연구이며, AR/VR이나 자율주행, 로봇 조작 등에 활용이 가능한 기술입니다. 딥러닝의 발전으로 정확도는 물론 추론 속도도 크게 발전하였고, 이러한 딥러닝 방법론은 대부분 강한 일반화 성능을 갖추기 위해 학습 과정에 대량의 labeled 데이터를 필요로 합니다. 그러나 pose 정보를 annotation하는 것은 너무 많은 시간과 비용이 요구되며, 3차원 정보에 대한 annotation은 오류가 발생할 수 있다는 어려움이 있습니다. 따라서 대부분의 6D Pose Estimation 밴치마크들은 몇백 장의 이미지에 대한 정보만을 가지고 있으며, 이러한 소량의 데이터로 인해 overfitting 문제와 일반화 실패로 새로운 장면에 대해 잘 작동하지 않는 경향이 있습니다.
이러한 데이터 부족 문제를 해결하기 위해 여러 연구들이 진행되었습니다. 가장 쉬운 방법은 object 인스턴스를 잘라서 다른 sceen에 붙여 도메인에 강인하게 만드는 것으로, 이는 정확한 수동 labeling 정보가 필요하며 여전히 원본 도메인에 overfitting된다는 문제가 있습니다. 다른 방법은 합성 데이터를 생성하는 것으로, 저렴하고 빠르지만 합성데이터는 여전히 실제 이미지와 차이가 있다는 문제가 발생합니다. 또한, GAN을 이용하여 합성 데이터와 real 데이터 간의 domain gap을 줄이기 위한 연구도 진행되었으나, 이러한 접근방식도 여전히 생성된 데이터와 real 데이터의 차이가 있다는 문제가 있습니다. 최근, 합성 데이터로 학습한 뒤 real 데이터로 fine-tuning하는 self-supervised 방법론이 등장하여 좋은 성능을 보여주었으나, depth나 GT 카메라 pose 정보와 같은 학습을 위한 추가적인 정보를 주지 않을 경우 성능 드랍이 발생한다는 문제가 존재합니다. 본 논문은 self-supervised 방식의 새로운 학습 방식을 제안하여 추가적인 정보가 필요하지 않고 SOTA를 달성하였다고 합니다.
사전에 학습된 pose estimator를 real domain으로 적용하려는 기존 연구들의 핵심 아이디어는 render-and-compare 로, CAD 모델과 pose가 주어졌을 때 renderer를 이용하여 object의 pose와 mask, depth 정보 등을 반환하여 반복적인 비교를 통해 pose를 학습하는 것입니다. 그러나 2D 시각적 콘텐츠인 mask나 색상에 의존할 경우, texture 정보가 부족하거나 도메인이 달라지는 경우 등에 문제가 발생할 수 있습니다.
이러한 이유로 본 논문에서는 pose estimator에 대한 학습을 하기 전에 object의 사실적인 texture를 중간 representation으로 이용하는 방식을 제안합니다. texture 정보 학습과 pose 학습 두 가지를 연관된 2가지 최적화 문제로 공식화 하고 먼저 실제 이미지로 사실적인 texture를 학습한 뒤, 합성 데이터를 통하여 pose estimator를 학습합니다. 제안한 방식의 가장 큰 문제는 학습 과정에 초기화된 pose estimator의 노이즈가 있는 상태에서 정확한 texture를 파악해야 하는 것으로, 합성데이터를 이용하여 기하학적인 정보를 제공하고 local 표면의 정보에 색상을 합성하여 적대적 학습 방식을 이용하여 해결하고자 하였습니다. 또한, 합성 texture로부터 정규화 항을 추가하여 texture learning 과정에서의 segmentation 오류를 보완하고자 합니다. 저자들은 GT Pose 정보가 없는 방법론들과의 비교를 통해 SOTA를 달성하였고, 나아가 성능이 떨어지는 pose estimator를 이용하여도 강한 자체 개선 능력을 통해 성능이 개선되었음을 보여줍니다.
본 논문의 contribution을 정리하면
- 새로운 self-supervised 학습 방식인 TexPose(Texture learning과 Pose learning으로 구분된)를 공식화
- texture 학습 과정에 pose estimator의 pose 추정 오류와 segmentation의 불완전함으로 인한 노이즈를 보완하기 위해 surfel-conditioned adversarial training loss와 texture 정규화 항을 제안
- 추가적인 정보(depth나 카메라 pose 등)를 제공하는 방법론과 비교하여 상당한 성능 개선
Method
본 논문은 단일 RGB 이미지로부터 pose 정보 labeling 없이 인스턴스 별 6D Pose 정보를 추정하는 것입니다. CAD 모델이 존재하므로, 기존 연구들이 많이 사용하던 2-stage 학습 방식(CAD모델이 있으므로 렌더링을 통해 합성 데이터를 만들어 pose estimator를 학습한 뒤, unlabeled 데이터로 self-training)을 따랐다고 합니다. 해당 파트는 self-training 과정에 대해 소개합니다.
먼저 사전학습을 통해 real 이미지 \hat{I}로부터 대략적인 pose 정보 T 와 segmentation mask M를 예측할 수 있는 pose estimator f_{\theta} 를 구합니다. M 은 pose T 를 refinement하는 데 pseudo 윤곽 단서를 제공하는 역할을 합니다.
1. Revisiting Self-supervised 6D Pose Learning
먼저 이전의 방법론에 대하여 검토를 수행합니다. Render-and-compare는 6D Pose self-supervision에서 일반적으로 사용하는 방식입니다. 공식화하자면 아래의 식(1)로 표현할 수 있습니다.
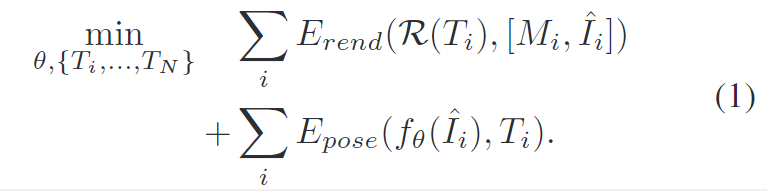
- 예측된 pose를 미분 가능한 renderer \mathcal{R}에 넣어 렌더링된 마스크와 이미지 [M_r,I_r] 를 출력합니다. ( [M_r, I_r] = \mathcal{R}(T) )
- E_{rend}는 렌더링된 output[M_r,I_r] 과 [M,\hat{I}] 사이의 일관성을 강화하는 것으로, pseudo pose label을 개선하는 것을 목표로 합니다.
- 또한, E_{pose}에서 f_{\theta}를 추가로 학습합니다.
기존 연구들은 주로 E_{rend}를 개선하는 것에 집중하여 더 정확한 pseudo pose를 얻고자 하였습니다. 2D 정보인 [M_r,I_r] 에 의존하여 E_{rend} 를 최소화( \{ T_1, ..., T_N \}을 개선)하는 것은 정보가 없는 shape과 appearance, 시뮬레이션과 실제의 불일치로 인해 어려움이 있습니다. 이에, 기존 연구들은 depth나 deep pose refiner 등을 이용하여 추가적인 supervision 정보를 제공합니다. 그러나 이러한 방식은 연구[1]에서 보였듯 upper bound가 존재하며, pose refiner로 인해 pose가 발산할 수 도 있다는 문제가 있습니다.
2. TexPose: Learning Pose from Texture
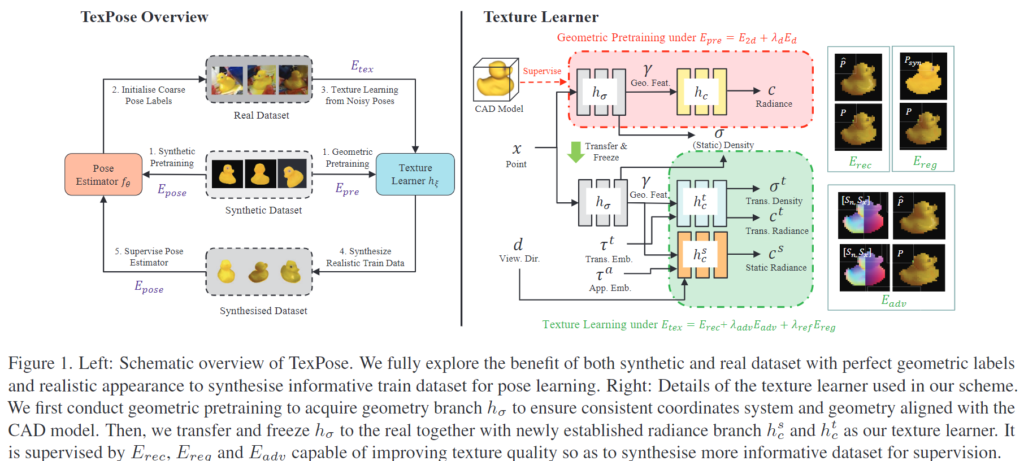
저자들은 앞서 설명한 기존 연구들이 가지고 있는 한계를 극복하기 위해 self-supervised 6D Pose learning을 2개의 최적화 문제(texture learner h_{\xi}와 pose estimator f_{\theta})로 재정의 합니다. 식으로 표현하면 아래의 식(2)로 나타낼 수 있으며 Figure 1(왼쪽)로 도식화 할 수 있습니다.
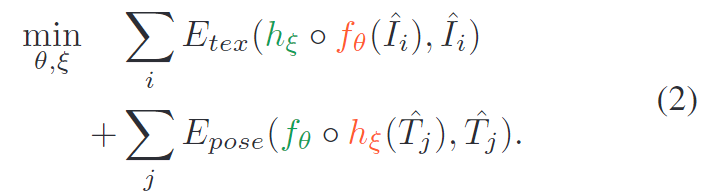
이때, 해당 방법론은 pose를 구할 때 이미지 정보가 아닌 texture representation 정보를 이용한다는 것을 식(2)에서 확인할 수 있습니다. ( h_{\xi}(\hat{T}_j))
과정에 대해 설명하면 다음과 같습니다.
- 먼저 E_{tex}를 최적화 합니다.
- 이미지 \{\hat{I}_1, ...,\hat{I}_N \}으로부터 초기 pose \{T_1, ...,T_{N} \}를 추정하는 데 사용되는 pose estimator 파라미터 f_{\theta}를 고정하여 이미지로부터 사실적인 texture 정보를 임베딩할 수 있도록 h_{\xi}를 학습합니다.
- 그 다음 학습 데이터 \{I_1, ...,I_{N'} \}를 합성하기 위해 h_{\xi}를 freeze하고 label \{\hat{T}_1, ...,\hat{T}_{N'} \}와 함께 학습 샘플을 구성합니다.
- 학습데이터를 이용하여 E_{pose}를 최적화하며 f_{\theta}를 업데이트합니다.
이렇게 학습 방식을 재구성하여 2D 정보로부터 pose 정보를 직접 추정하지 않고, 사실적인 합성 데이터를 만들도록 하여 도메인 격차를 해소하는 방식을 제안하였습니다.
그 다음, pose 노이즈가 존재할 경우 texture mapping 오류를 제한하여 기하학적 label과 최대한 정확한 외관 정보를 제공하기 위해 multi-view supervision을 통해 각 view별 pose noise를 보정하여 보다 정확한 외관 정보를 포착하도록 합니다. 이처럼 해당 방법론은 기존 방법론과 달리 추가정인 정보(depth 나 카메라 pose 정보 등)가 필요하지 않고, texture learning을 통해 자체적으로 pose estimator도 개선이 가능합니다.
NeRF preliminaries
저자들은 NeRF를 이용하여 texture 정보를 임베딩합니다. NeRF는 모든 query point x에 대한 정보를 인코딩하기 위해 2개의 MLP(geometry branch; volume density인 \sigma와 기하학적 feature \gamma를 예측하기 위한![]() 와 radiance branch; 색상 c를 예측하기 위한
와 radiance branch; 색상 c를 예측하기 위한 ![]() )로 object 모델을 표현합니다. 주어진 시점에서 K샘플들 \{ x_k \}^K_1은
)로 object 모델을 표현합니다. 주어진 시점에서 K샘플들 \{ x_k \}^K_1은![]() 를 따라 모이고, 이때 o는 카메라 중심, d는 view의 방향을 나타내고, t는 distance를 나타냅니다. 색상 C(r)는 w_k = exp(-\delta_k \gamma_k) 과 \alpha_k = \Pi^{k-1}_{j=1}의 quadrature 근사 방식을 이용하여 추정됩니다. 이때 \gamma_k는 근접 point의 step size, C(r) = \Sigma ^K_{k=1} \alpha_k(1-w_k)c_k입니다.
를 따라 모이고, 이때 o는 카메라 중심, d는 view의 방향을 나타내고, t는 distance를 나타냅니다. 색상 C(r)는 w_k = exp(-\delta_k \gamma_k) 과 \alpha_k = \Pi^{k-1}_{j=1}의 quadrature 근사 방식을 이용하여 추정됩니다. 이때 \gamma_k는 근접 point의 step size, C(r) = \Sigma ^K_{k=1} \alpha_k(1-w_k)c_k입니다.
Geometric pretraining
geometry와 radiance branch를 함께 학습할 수 있으나, pose 정보는 노이즈가 많고, NeRF의 좌표계는 임의의 좌표계이므로 CAD 모델을 렌더링하여 생성한 합성 데이터를 통해 정확한 pose와 depth, mask를 이용하여 식 4를 통해 NeRF를 학습합니다.
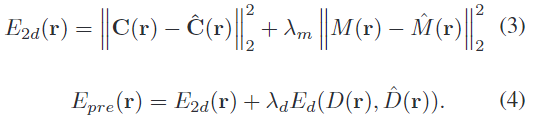
이때 E_d는 scale에 불변한 loss이고, \lambda_m,\lambda_d는 가중치 값을 나타냅니다. 또한, 저자들은 geometry branch를 학습하는 것을 목표로 하지만, CAD 모델과 정렬된 정확한 밀도 정보를 이용하여 radiance branch도 함께 학습을 진행합니다. (pose estimation에는 사용하지 않고 NeRF를 학습할 때 함께 사용한다는 것입니다.)
Texture learning from noisy poses
이제 f_\theta 에 의해 초기화 된 pose와 raw 이미지를 사용하여 texture encoding을 위한 h_\xi 를 학습합니다. 이때 정확한 texture를 포착하고 좌표계와 기하학적 정보가 변하지 않도록 하기 위해 h_\sigma 는 고정하고 h_c 를 최적화합니다.
그러나 여전히 E_{rec} 는 충분히 정확한 texture 정보를 포착하지 못한다는 것을 발견하였고, pose 오류로 인한 texture 변화를 고려하기 위해 샘플링된 패치에 대하여 surfel-conditioned adversarial loss(surfel이란 surface element를 의미합니다)를 설계하였다고 합니다. 객체 표면의 각 위치에서 추정된 pose T를 이용하여 정규화된 obejct 좌표 S_x와 법선 S_n을 계산하여 local한 정보를 나타냅니다. 그리고 예측된 패치의 색상 P를 local한 표면 정보 [ S_x, S_n] 에 따라 조정하여 adversarial 방식을 이용합니다.
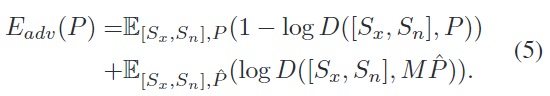
다시 말하면, 패치에 대하여 좌표 정보와 법선 정보를 계산하여 local 정보를 나타내고, 이를 색상과 매핑되도록 한 것으로 생각하시면 될 것 같습니다.
또한, 마스크에 배경 영역이 포함되는 문제가 발생할 수 있다는 것을 관찰하였고, 이를 해결하기 위해 정규화를 도입합니다. 합성 패치 P_{syn}를 생성하고, 현재 pose 추정치 T를 이용하여마스크 M_{syn} 를 만든 뒤, 예측된 마스크 M을 이용하여 불완전한 경계 M_{pad} = M_{syn}(1-M)에 대하여 합성 색상으로 채워줍니다. 이러한 정규화 항 E_{feat}는 사전학습된 VGG10 네트워크의 feature를 이용하여 의미론적 수준에서 예측된 패치와 합성 패치의 align을 맞추도록 MSE loss로 학습됩니다.
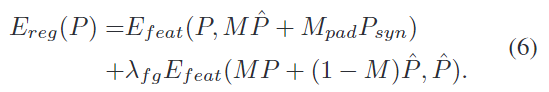
이렇게하여 아래의 loss를 통해 texture를 학습합니다.
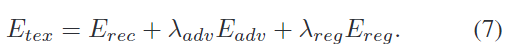
Pose learning
E_{tex}를 최적화 한 뒤, 합성 데이터를 이용하여 E_{pose}를 최적화합니다. 이 부분은 사용하는 pose estimator를 사용한 것으로 보입니다.(수식이 적혀있지 않고, 단순히 texture learning 다음에 수행한다라고표현합니다.)
Expereiments
- 6D Pose estimation에서 일반적으로 사용하는 ADD(-S)를 평가지표로 이용합니다.
- GT와 예측된 transformation matrix를 적용하여 거리를 측정하는 방식
- 이때 물체가 symmetric할 경우 거리가 가까운 vertex에 대한 값을 이용
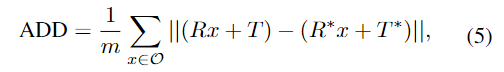
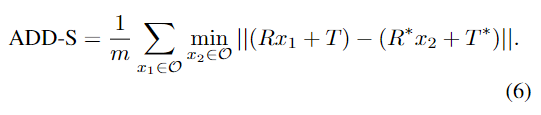
- Dataset은 6D Pose Estimation에서 많이 사용되는 밴치마크를 이용하였습니다.
- LineMOD: CAD모델이 있는 13개의 obejct로 구성. 기존 연구를 따라서 15%의 RGB 이미지를 사용하여 self-supervised로 학습하고 나머지는 GT label을 제거하고 모델 test에 사용
- Occluded LineMOD: occlusion이 심각한 LineMOD의 8개 object로 구성. 공정성을 위해 다른 self-supervised 연구에서 사용한대로 train/test set을 나누어 사용
- HomebrewedDB: 최근에 구축된 데이터셋으로, 일반화 성능을 테스트하기 위해 LineMOD와 공유하는 3가지 object에 대하여 test를 진행
Performance on LineMOD and Occluded LineMOD
아래의 Table 1은 LineMOD에 대한 정량적 성능으로, GDR-LB와 GDR-UB가 각각 합성 데이터와 실제 데이터로 학습하는 pose 추정기의 성능이며, 성능 하한과 상한이 됩니다. Table1의 DPOD와 GDR의 성능 차이를 통해, 합성 데이터와 실제 데이터 사이에 상당한 성능 차이가 있음을 알 수 있습니다. 또한, Self6D[1] 실험 결과를 통해 self-supervised을 위해서는 추가적인 정보가 필요함을 알 수 있습니다. 하지만 저자들이 제안한 방법론은 추가적인 정보를 사용하지 않았음에도 다른 self-supervised 방법론보다 뛰어난 성능을 보이는 것을 확인할 수 있습니다.
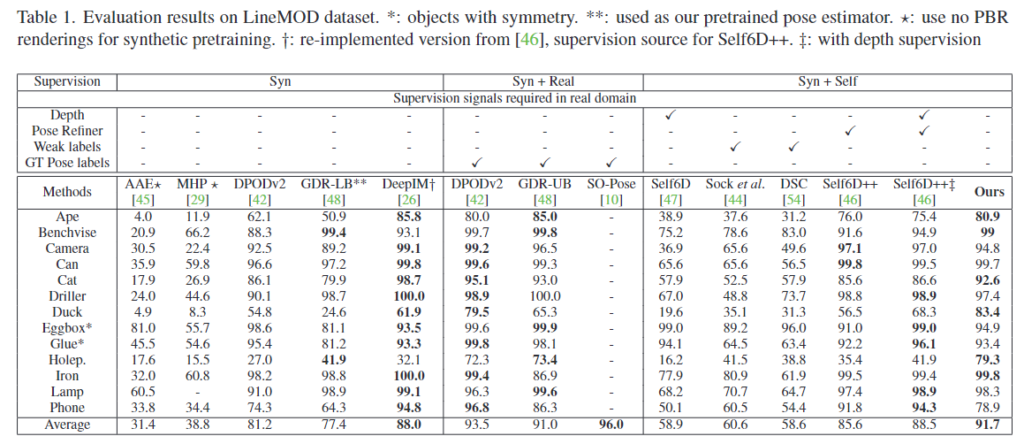
Table2는 Occluded LineMOD에 대한 실험 결과로, 마찬가지의 결과를 얻을 수 있습니다. occlusion을 위한 설계를 하지 않았음에도, occlusion을 해결하기 위한 구조를 설계한 Self6D++보다 개선된 결과를 얻을 수 있었다는 것도 유의미한 점이라고 주장합니다.
Performance on HomebrewedDB and generalisation
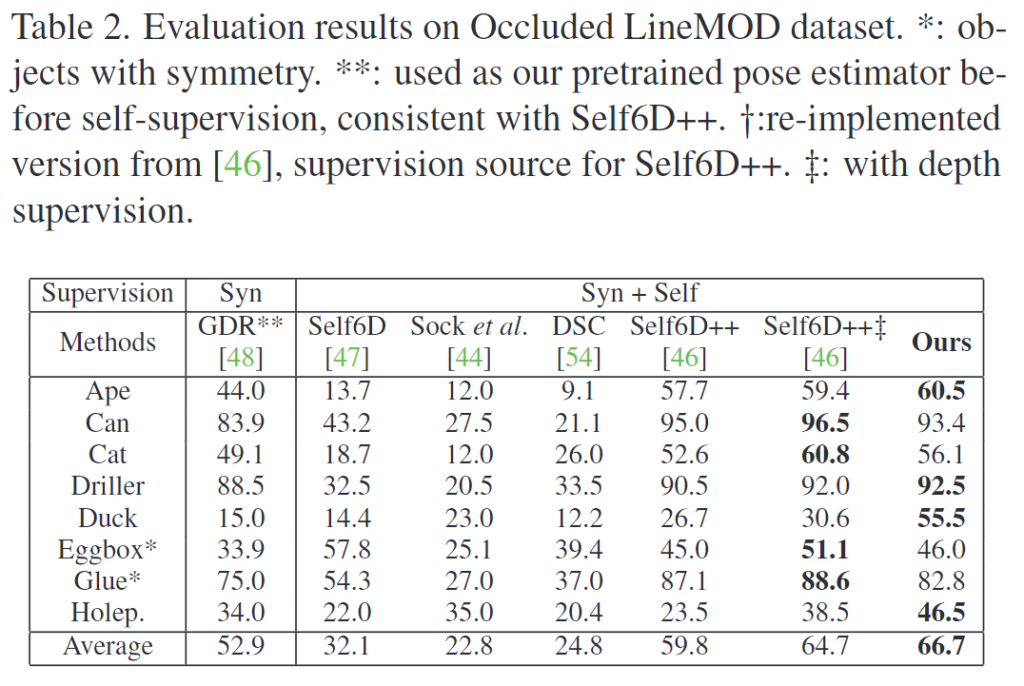
저자들은 HomebrewedDB를 이용하여 일반화 성능 연구를 수행하였습니다. Table3의 결과는 LineMOD로 self-supervised 학습을 수행한 네트워크들이 HomebrewedDB에 있는 동일한 obejct에 대해 얼마나 잘 작동하는지를 측정한 것입니다.(Table 3의 GDR**† 과 비교합니다.) Self6D++는 성능이 뚜렷하게 저하되었다는 것을 확인할 수 있고(table3의 86.8 →80.6), 저자들의 방법론은 오히려 성능이 개선되었습니다(table3의 86.8 -> 89.1).
References
[1]Gu Wang, et al., “Occlusion-aware self-supervised monocular 6D object pose estimation.” TPAMI, 2021.
안녕하세요, 좋은 리뷰 감사합니다.
이미지가 아닌 texture로부터 pose를 추정하는 것이 흥미로운 것 같습니다. 이를 위한 texture learning을 위해 공교롭게도 제가 이번에 리뷰한 NeRF 내용이 나와 친숙한 내용이 있네요.
제가 리뷰했던 논문을 살펴보시면 Loss function에서 Color에 대한 loss를 2개의 term으로 나뉘게 됩니다. 즉, Coarse와 fine에 대한 loss term을 사용하게 됩니다. 하지만, 이번 TexPose의 식(3)에서는 coarse인지 fine인지는 모를 하나의 Color loss를 사용하는 것으로 보이는데, 기존의 NeRF에서 제안했던 color term 2개를 사용하는데 줄여서 하나로 표현을 한 것인지 아니면 이번 논문에서는 coarse 또는 fine만 사용해도 충분한 성능이 나온 건지 궁금합니다.
감사합니다.
질문 감사합니다.
우선 제가 이해한 바로는, NeRF에서는 Coarse와 Fine 전체 continuous한 특성을 고려하고자 전체에 대해 coarse를, 그중 Density가 높은 지점에서 추가적인 샘플링을 진행하여 fine을 학습한 것으로 이해하였습니다. 하지만 해당 논문의 경우 K개의 샘플을 지정해두고 사용하였다고 합니다. 따라서 둘중 어디라고 정확하게 이야기하기는 어렵고, 미리 정의되어있는 샘플을 사용하였으며, 추가로 mask에 대한 정보도 학습하였다는 점이 주된 활용 방식인 것 같습니다.
안녕하세요. 리뷰를 자세히 읽어보려고 했는데 Self-sup 6d Pose Learning이 처음이라 해당 task의 사전지식에서부터 이해가 어렵네요:(
질문을 좀 드리면
1. 사전 학습을 한다는 것은 cad 모델로부터 생성된 합성 데이터로 학습한 모델을 의미하나요?
2. 그리고 예측된 pose라고 함은 real image로부터 추정된 pose를 의미하나요? 그럼 해당 pose를 통해 다시 렌더링과정을 거쳐서 Image와 Mask를 만드는 과정은 어떻게 동작하는 건가요? 미분 가능한 renderer라는 것이 미분 가능한 연산으로 구성된 어떠한 tool인가요? 아니면 이 renderer라는 것도 모델 학습을 통해 학습시켜야만 하는건가요? 랜더링이라는 행위 자체가 제 머릿속에 정확히 정의되지 않아서 이부분에 대해 명확히 알게 되면 과정을 어느정도 이해할 수 있을 것 같습니다.
3. 그리고 real image \hat{I}를 pre-trained pose net f_{\theta}에 입력으로 넣어 T를 추정한 것이 아닌가요? 왜 E_{pose}에 대한 loss 식이 f_{\theta}(\hat{I})와 T 간에 minimize가 되나요?
감사합니다.
질문 감사합니다.
1. 네 맞습니다. 사전학습이란 CAD모델을 이용하여 생성한 합성 데이터를 이용하여 대략적인 pose 정보를 예측할 수 있도록 학습된 모델을 의미합니다.
2. 렌더링은 3D 모델로부터 2D 영상을 만들어내는 과정입니다.
저도 renderer을 학습해야하는지에 대해 의문이 생겨 검색해보았는데, 기존의 3D 렌더링 기술은 너무 많은 연산량이 드는 문제가 있다고 합니다. (예를들어, 3D 렌더링 기술 중하나인 Ray tracing 기술은 물체를 여러 다각형의 집합으로 정의한 뒤, 모든 다각형들이 빛을 반사하는 것을 계산한다고 합니다.)이에 계산량을 줄일 수 있을 것으로 기대하고 딥러닝을 이용하여 3D 정보를 렌더링하는 Neural Rendering이라는 분야[2,3]가 등장했다고 합니다.
따라서 여기서 이야기하는 미분가능한 renderer는 CAD와 Pose 정보를 입력으로 하고, output이 mask나 color image, depth image 등이 되도록 하는 학습한 모델입니다.
** Reference **
[2] H. Kato, Y. Ushiku, and T. Harada. Neural 3d mesh renderer. In CVPR, 2018
[3] N. Ravi, J. Reizenstein, D. Novotny, T. Gordon, W.-Y. Lo, J. Johnson, and G. Gkioxari. Accelerating 3d deep learning with pytorch3d. arXiv:2007.08501, 2020.
3. reference에 있는 다른 Render-and-compare 논문들을 찾아보았으나, 동일한 함수를 찾지 못하였고, 관련 논문들마다 다 다른 loss를 이용한다는 점에미루어볼 때, 식(1)은 저자들이 Render-and-compare 방법론을 표현하기 위해 일반화하여 표현한 것으로 보입니다. E_pose 항에 대해서는 ‘pseudo pose정보를 이용하여 pose estimator를 추가학습한다’ 정도로 이해해야할 것 같습니다.
안녕하세요 이승현 연구원님. 좋은 리뷰 감사합니다.
결국 이 논문은 기존 방법론에서 2d 정보만을 사용하였을 때 texture정보가 부족하였다는 문제를 object의 texture representation을 학습하는 texture learning을 추가한 것으로 해결하였다고 이해하였습니다.
리뷰를 읽고 질문이 있는데요, Method 부분에서 f_theta는 segmentation mask를 추정하는 pose estimator라고 하셨는데요, 수식(1)의 E_pose에서는 real image의 mask와 pose정보인 T사이의 loss를 구하는 것으로 보이는데 이때 real image의 pose정보를 어떻게 구했는지 궁금합니다. 사전 학습된 pose estimator의 예측값을 psudo label로 사용하는 건가요? 또한 segmentation mask정보와 pose정보 간의 loss는 어떻게 계산되는지도 긍금합니다.
감사합니다.
질문 감사합니다. 수식(1)은 저자들이 Render-and-compare 방법론을 표현하기 위해 일반화하여 표현한 것으로 보입니다. E_pose 항에 대해서는 ‘pseudo pose정보를 이용하여 pose estimator를 추가 학습한다’ 정도로 이해해주시기 바랍니다. 식에서 나오는 T는 real image의 pose 정보라는 것은 합성 데이터로 미리 학습한 pose estimator를 이용하여 예측한 결과 값입니다.
오 이번에 엄청 좋은 논문을 찾았네요 ㅋㅋㅋ
NeRF 사용한 방법론이 나올 거라고 생각했는데, 역시나 나왔군요.
여러 방법의 기법들을 이리저리 섞어서 어려웠을텐데 해당 논문을 기반으로 참고된 문헌들을 읽어보고 다시 읽어보면 좋을 것 같아요.
궁금한 점이 생각보다 너무 많아서 오피스에서 구두로 질문 드리도록 하겠습니다.
그래도 질문 남기고 가면,
1. NeRF를 학습을 진행할 때에 사용한 데이터 셋이 무엇인가요? 캐드 모델을 활용한 렌더링 정보일까요?
2. 해당 기법에서도 mask 추정을 위해 Mask-RCNN (혹은 사전 학습된 기성 모델)을 이용하나요?
질문 감사합니다.
1. NeRF를 이용하여 texture Learner를 학습하였고, texture Learner는 실제 이미지를 이용하였으므로 CAD 모델을 렌더링한 정보가 아닌, (적은 양의) real 이미지입니다.
2. 해당 모델에서는 mask를 추정하기 위해 Mask-RCNN을 이용했다는 표현은 없고, 기존 연구를 따라 미분가능한 renederer를 이용하였다고 합니다. 미분 가능한 renderer란, 기존의 rendering이 너무 많은 연산량이 든다는 문제를 해결하기 위해 딥러닝을 이용하여 렌더링 이미지를 생성하는 Neural Rendering 분야에서 제안된 것입니다. 미분 가능한 renderer는 CAD모델과 Pose를 입력으로 넣어 원하는 특성을 output으로 받는데, 여기서 원하는 특성이란 depth이미지나 color 이미지, mask 등이 될 수 있습니다.