안녕하세요, 열 다섯 번째 X-Review입니다. 이번 논문은 CVPR 200에 게재된ABCNet: Real-time Scene Text Spotting with Adaptive Bezier-Curve Network입니다. 바로 리뷰 시작하겠습니다.
1. Introduction
Scene text detection과 recgnition은 지금까지 많이 발전해왔지만 아직까지 해결 못한 점이라고 하면 text의 크기, 종횡비, 스타일, 왜곡, 모양의 다양성으로 인한 것입니다. 꾸준히 scene text spotting 분야에서 성능을 개선시켜왔지만 real-world에 바로 적용하기에는 무리가 있었죠. 최근에는 많은 end-to-end 방법론들이 여러 방향을 가지고 곡선으로 되어 있는 text에 대한 spotting에서도 성능이 잘 나오게 되었는데, 이런 방법론들은 파이프라인도 복잡할 뿐더러 cost가 큰 character level의 어노테이션을 필수로 요구하였습니다. 또, inference 속도가 느려서 real-time에 적용하기 힘들었죠. 그래서 본 논문의 저자는 간단하고 효율적인 end-to-end 프레임워크를 디자인하고자 하였고, inference 속도가 빠르고 다른 SOTA 방법론들의 성능과 성능이 동등하거나 더 나은 ABCNet을 제안하였습니다.
ABCNet은 Adaptive Bezier Curve Network인데,, 이름만 봐도 알 수 있듯이 Bezier Curve를 이용하여 oriented, curved text를 detection합니다. 이 Bezier curve adaptation을 사용하여 detection하는 경우에는 일반적으로 사각형의 bbox를 검출해내는 것과 비교했을 때 computation cost가 무시할 수 있을 정도로 적게 든다고 합니다.
추가로 저자는 새로운 feature alignment layer인 BezierAlign을 제안하였습니다. 이는 roi align과 같은 개념으로 생각해도 될 것 같은데, 곡선으로 휘어져있는 text에 대한 convolution feature들을 정확하게 추출해낼 수 있는 역할을 하게 되고, 이는 computation cost가 거의 들지 않으면서 이후 뒷단에 수행되는 recognition을 더 잘 할 수 있게 된다는 장점이 있습니다.

그래서 위 [Figure 1]의 (a)는 segmentation 기반 방법론, (b)는 본 논문 저자가 제안한 ABCNet의 text detection 및 spotting 결과입니다. 보시면 segmentation 기반 방법론은 서로 근접하게 이웃해있는 text에 쉽게 영향을 받는 것을 확인할 수 있습니다. 이렇게 뭔가 정형화되어 있지 않은 segmentation 결과(nonparametric) 는 이 다음에 recognition branch로 들어가기 위해서는 feature를 align할 필요가 있는데 그 과정이 굉장히 어렵겠죠. 대신에 저자가 제안한 Bezier curve를 사용한 결과(parametric)는 BezierAlign을 통해 보다 쉽고, 자연스럽게 recognition branch와 이어지게 됩니다.
물론 이전에 TextAlign이나, FOTS같은 타 논문에서도 그들이 제안한 Align기법을 사용하였었는데 이들은 ABCNet과는 달리 오직 사각형의 bbox만을 가지고 text를 detect하였기에 회전되어 있고, 구부러진 text를 잘 표현하지 못했었죠. 추가적으로 ABCNet의 장점이라고 하면 2D attention과 같은 복잡한 transformation 과정이 없기 때문에 보다 recognition branch를 단순하게 설계할 수 있었습니다.
본 논문의 주 contribution은 다음과 같습니다.
- Bezier curve를 사용하여 curve된 text에 대해 parametric하게 표현함으로써 더 정확하게 localization할 수 있었음
- 정교한 feature alignment를 하기 위한 BezierAlign을 제안함
- oriented, curve된 text로 구성된 Total-Text, CTW1500 두 데이터셋에 대해 SOTA 달성
2. Adaptive Bezier Curve Network (ABCNet)
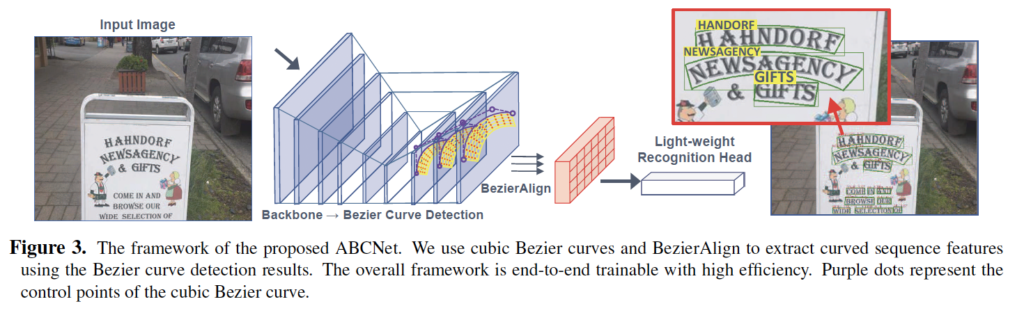
ABCNet의 전체적인 파이프라인은 위와 같으며, end-to-end로 학습가능한 text spotting 모델입니다. detection head는 4개의 convolution layer로 구성되어 있고 output feature map에서 detection이 수행됩니다. 이는 위 그림의 backbone이후 4개의 layer에 해당하겠습니다. 이후 본 논문의 핵심 부분인 Beizer curve detection과 BezierAlign을 통과한 뒤 마지막으로 recognition branch를 통과하여 최종적으로 검출한 text가 어떤 단어인지 recognition하게 됩니다.
2.1. Bezier Curve Detection
본격적으로 Bezier Curve Detection에 대해 설명드리기 전에 간단하게 Bezier Curve에 대해 알아보도록 하겠습니다.
Bezier Curves (베지에 곡선)
베지에 곡선이라는 것은 매끄러운 곡선을 그리기 위한 것입니다.
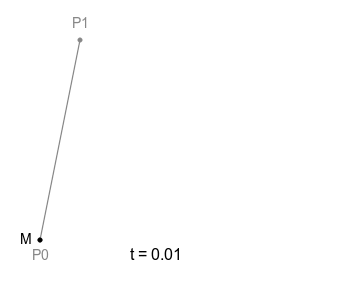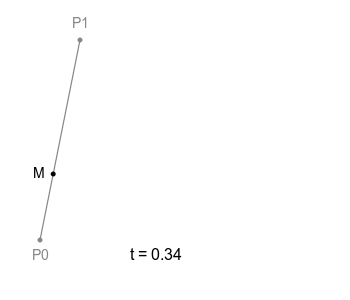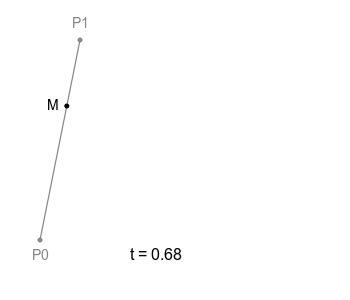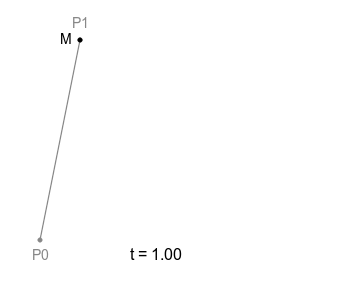
위 그림처럼 직선에서의 점의 움직임이 모든 Bezier Curve의 기본이 되는데, 하나의 직선이 있고 그 위를 점 M이 일정 속도로 이동하고 있다고 한다면 이 점 M의 궤적은 당연하게도 단순한 직선으로 그려집니다.
여기에 선을 하나 더 추가하고 그 위에 M처럼 이동하는 점을 놓아보도록 하고 이때, 기존 점은 M0으로 새로운 점은 M1로 부르도록 하겠습니다.
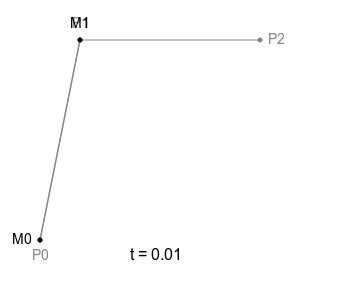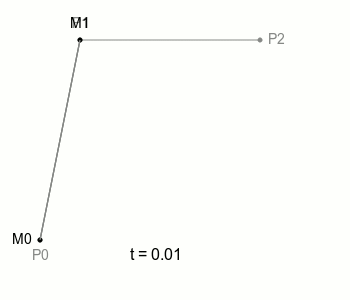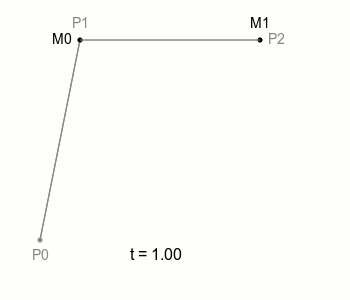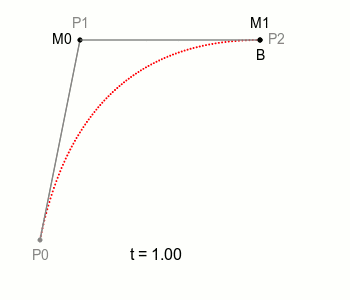
여기서 M0과 M1을 잇는 선을 하나 더 그을 수 있는데, 이 선은 M0과 M1이 이동하면 자연스럽게 함께 움직이게 되겠죠. 이 선 위에 M0, M1처럼 일정 속도로 이동하는 점을 놓을 수 있고, 이 점이 위 그림에 보이는 B에 해당합니다. 여기 이 점 B가 그리는 궤적이 ‘2차 베지에 곡선’ 입니다.
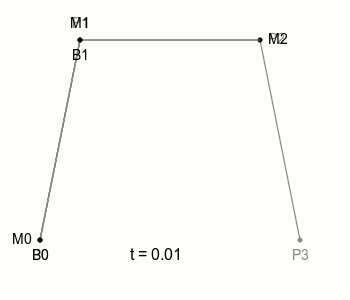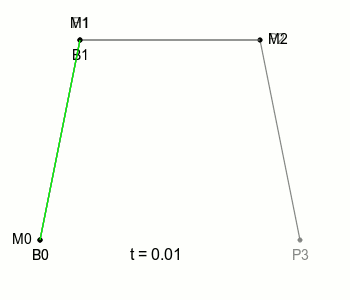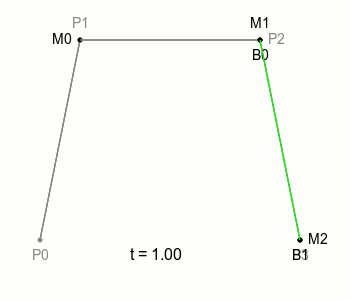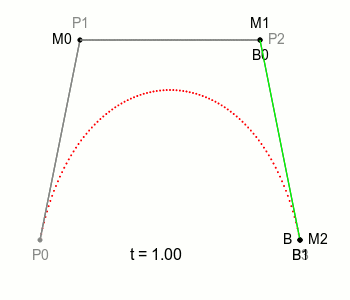
그림에서 P0, P1 등을 Control Point(조절점)라고 하는데, 이제 위 그림과 같이 Control point(조절점)을 하나 더 늘린 베지에 곡선을 봐보겠습니다.
새로운 Control point P3가 추가되었고, P2와 P3을 선으로 잇고 있습니다. 그리고 M0, M1과 같이 그 선 위를 이동하는 점 M2를 생각해볼 수 있겠죠.
이전 2차 베이제 곡선에서는 P0, P1, P2의 조합으로 점 B의 위치를 정할 수 있었는데, 이와 마찬가지로 P1, P2, P3의 조합으로 비슷하게 점의 위치를 정할 수 있을 것입니다.
이전에 부르던 점 B를 B0으로 부르기로 하고, P1, P2, P3의 조합으로 정해지는 새로운 점을 B1이라고 부른다면 이전과 마찬가지로 점 B0과 점 B1을 잇는 선과 그 선을 일정한 속도로 움직이는 점을 다시 생각해볼 수 있는데 그때 이 점이 그리는 궤적을 ‘3차 베지에 곡선’이라고 합니다.
여기서 Control point를 하나 더 들린다면 4차 베지에 곡선이 됩니다.
마지막으로 정리해보자면, ‘베지에 곡선’이란 선분 위를 일정 속도로 움직이는 점과, 그런 점과 점을 잇는 또 다른 선분 위를 일정 속도로 이동하는 점 등을 조합하여 최종적으로 특징점이 그리는 궤적을 이용하여 곡선을 그려내는 방법입니다.
수식으로 알아보자면, Control point P0, P1 , …, P_{N-1}에 대한 베지에 곡선은 아래와 같이 쓸 수 있습니다.
P(t) = \sum_{i=0}^{N-1}P_iJ_{ni}(t)
여기서 J_{ni}(t)는 아래와 같습니다.
J_{ni}(t) = \begin{pmatrix} n\\i \end{pmatrix}t^i(1-t)^{n-i}
- \begin{pmatrix} n\\i \end{pmatrix}→ binomial coefficient
t가 0부터 1까지 변할 때, P_0에서 시작하여 P_{N-1}에서 끝나는 베지에 곡선을 그리게 됩니다.
다시 본론으로 돌아와서 기존 segmentation 기반 방법론들과 regression 기반 방법론들은 oriented, curved text를 검출하는데 더 직접적인 방식이 되겠지만 text 경계에 딱 맞는 복잡한 prediction을 요구하기 때문에 매우 비효율적입니다. 저자는 이 점을 단순화하고자 앞에서 설명한 Bezier curve를 사용하기로 한 것입니다. 이 곡선을 표현하는 데 가장 기본적인 방식인 Bezier curve가 curve된 text를 parameterization하기 적합하다고 합니다.
다시 한번 식을 보겠습니다.
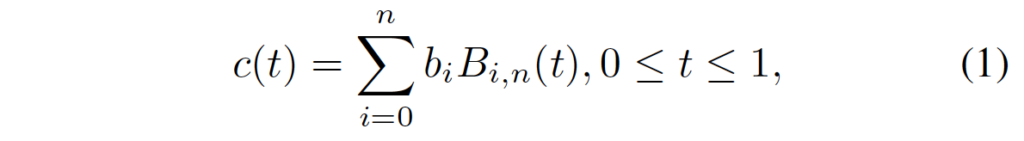
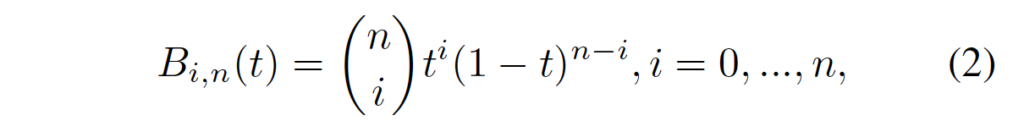
- b_i : i번째 control point
앞서 본 수식과 알파벳만 다를 뿐 동일한 식입니다. 이 Bezier curve를 이용하여 arbitrary한 모양을 가지는 text에 딱 fit하게 하기 위해 저자들은 현존하는 dataset과 real world에 존재하는 oriented, curved text를 관찰한 끝에 n은 3으로 설정하는 것이 적합하다고 판단하였습니다. n을 3으로 설정한다는 것은 3차 베지에 곡선을 사용한다는 것과 동일한 의미입니다.
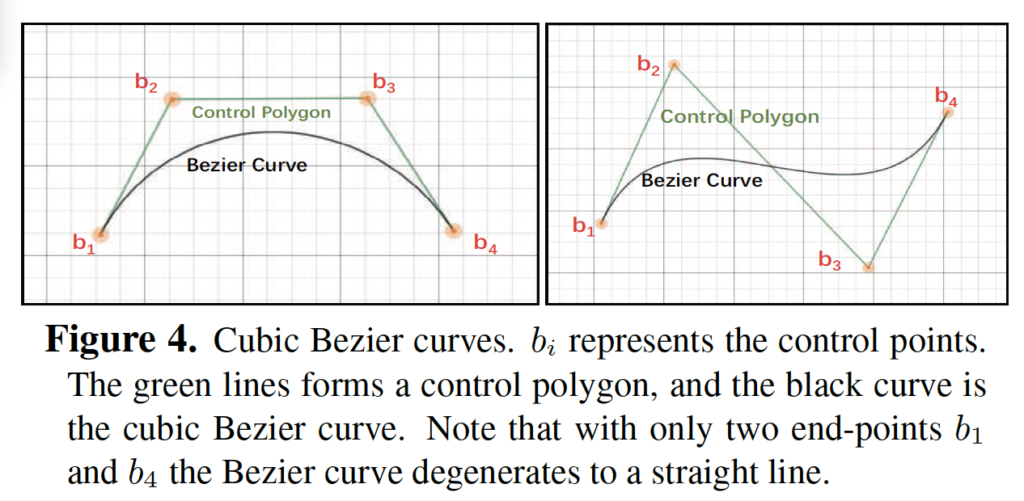
3차 Bezier curve는 위와 같이 생겼습니다. cubic(3차) Bezier curve에 기반하면 곡선으로 되어 있는 text는 단 8개의 control point을 사용하여 bbox로 표현할 수 있겠죠. text가 존재할 때 윗 부분 curve를 표현할 때 control point가 4개 필요하며 아랫 부분 curve를 표현할 때 마찬가지로 4개가 필요하기 때문입니다. 위 그림에서 control point는 b_n에 해당합니다.
저자들은 일관성을 위해 가장 긴 변의 3분점에 추가로 2개의 control point를 이용하여 보간을 했다고 합니다. 추가로 2개의 control point를 사용하였다는 것이 아니라 control point를 생성할 때 가장 긴 변의 1/3, 2/3 지점에 생성하도록 하였다는 것으로 이해하면 될 것 같습니다.
이 control point들의 좌표를 학습하기 위해서는 먼저 Bezier curve gt를 생성해야 겠죠. 이 부분에 관해서는 뒤에 후술하도록 하겠습니다.
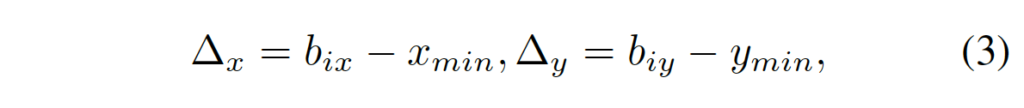
- b_{ix} : 현재 고려중인 control point의 x좌표
- b_{iy} : 현재 고려중인 control point의 y좌표
- x_{min} : gt Bezier curve control point중 minimum x 좌표
- y_{min} : gt Bezier curve control point중 minimum y 좌표
우선 Beizer curve gt를 생성했다고 가정하고 위 식을 보겠습니다. 식은 현재 고려 중인 컨트롤 포인트의 좌표 (b_{ix}, b_{iy})를 해당 text instance의 gt Bezier curve에서 사용된 컨트롤 포인트들의 x 좌표 중 최소값 x_{min} 및 y 좌표 중 최소값 y_{min}을 기준으로 상대적인 좌표로 변환하는 것을 의미합니다.
이렇게 상대적인 거리를 예측하는 것의 이점은 Bezier curve control point가 이미지 경계를 벗어나는지 여부와 상관없이 잘 동작한다는 점입니다. Detection head에는 16개의 output channel을 뱉는 오직 한개의 convolution layer만 존재하며 이 conv는 \vartriangle_{x}와 \vartriangle_{y}를 학습합니다. 단 한개의 conv layer만 사용하니 드는 cost도 굉장히 작겠죠.
2.1.1 Bezier Ground Truth Generation
이제, 기존 어노테이션을 이용하여 Bezier curve gt를 생성하는 과정에 대해 알아봅시다. Oriented, curved된 text가 존재하는 데이터셋인 Total-Text와 CTW1500은 다각형 형태로 어노테이션이 되어 있습니다. 여기서 Bezier curve gt를 생성하기 위해서는
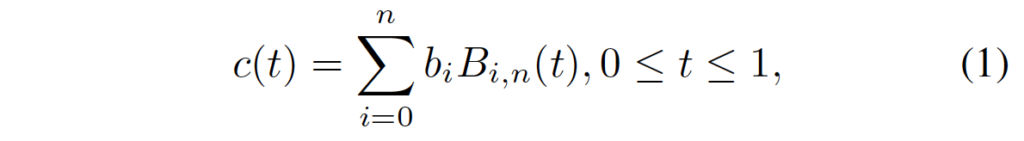
위 3차 Bezier 곡선 식으로 계산되는 c(t)의 최적의 파라미터 t를 얻어내는 것입니다. 이 t는 0부터 1 사이의 값을 가지는데, 이 t값에 따라 곡선이 어떻게 그려지는지 조절할 수 있는 것입니다. 이 최적의 t값을 구하기 위해서 단순하게 아래 식과 같이 standard least square method(최소자승법)을 적용하였습니다.
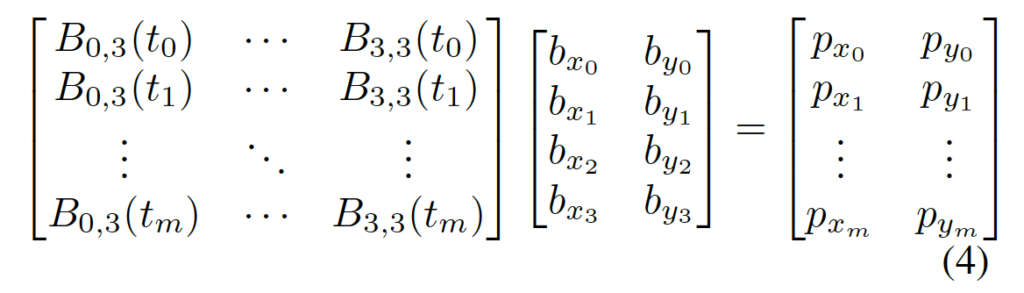
위 식에서 m은 곡선 경계의 어노테이션 포인트 수입니다. 구체적으로 말하자면 Total-Text같은 경우 5개의 점을 사용하여 곡선 text에 대해 어노테이션이 되어 있고, CTW1500은 7개의 점을 사용했는데 그럼 m이 각각 5, 7이 되겠습니다.
t는 0에서 1로 증가하면서 곡선의 길이를 누적해가며 더한 다음 이를 gt polyline의 둘레로 나눈 값으로 계산됩니다. 이후 t를 계산하였으면, 식(1)과 (4)를 이용하여 원본 gt polygon을 Bezier curve형태로 변환합니다. 식(4)에서 있는 첫번째 control point b_{0}는 첫번째 어노테이션 point를 사용하고, 마지막 어노테이션 point는 b_4로 사용하도록 하여 Bezier curve를 주어진 polygon 어노테이션의 시작점과 끝점에 정확하게 연결하도록 하였습니다.

위 그림은 (a)원본 gt와 (b) 생성한 gt결과를 시각화한 것입니다. box쳐진 위 그림 말고 그림 하단 부분에 단어만 crop하여 보여주는 결과는 각각 (a)에 경우 TPS, STN을 사용하여 warpping한 것과 (b)의 경우 저자가 제안한 BezierAlign을 사용하여 warp한 경우입니다. 한눈에 보기에도 (b)의 경우가 더 잘 warpping되었다고 볼 수 있겠네요.

위 그림은 Bezier curve의 예시들을 더 보여주는 것인데 잘 안보이시겠지만 여러 다양한 곡선들에 대해서도 곡선이 잘 생성되었다는 것을 보여주고 있습니다.
2.1.2 Bezier Curve Synthetic Dataset
end-to-end text spotting 방법론을 학습하기 위해서는 방대한 양의 합성 데이터가 항상 필수적으로 사용됩니다. 주로 SynthText 데이터셋을 사용하는데, 이 SynthText 데이터셋 같은 경우 주로 직선으로 예쁘게 펴진 text만 존재하여 오직 사각형 형태의 bbox만 제공합니다. 하지만 저자는 실생활에서 존재하는 challenge한 형태인 oriented, curved된 text에 대해 강인하게 동작하는 모델을 설계하고자 하였는데 이 합성 데이터셋 같은 경우 큰 도움이 되지 못하고 있죠. 그래서 저자는 이 curve된 text가 존재하는 합성 데이터셋(150k개)을 추가로 만들었습니다. 합성 데이터셋을 생성할 때는 VGG 합성 방식을 사용하였다고 하는데, 이에 대해서 자세히는 잘 모르겠습니다 . . 저자는 우선 COCO Text에서 4만개의 text가 없는 배경 사진을 선별하였으며, 이 배경 이미지에 대해 segmentation mask와 scene depth를 사용하여 text를 rendering하였습니다. 합성 text 모양의 다양성을 늘리기 위해 VGG synthetic 방법론을 사용하여 text의 글꼴과 스타일을 다양하게 하였으며, 이 합성한 text에 대해 polygon형태의 어노테이션도 생성했습니다. 이 어노테이션은 당연하게도 앞서 설명한 Bezier curve gt를 생성하는 방식과 동일하게 gt를 생성하여 학습에 사용하였습니다. 합성된 예시는 아래 그림과 같습니다.

2.2. Bezier Align
end-to-end로 학습하기 위해서, 이전에 많은 방법론들은 detection 결과와 recognition branch를 연결하기 위해 feature alignment(sampling) 방법을 많이 사용해왔습니다. 전형적인 sampling 방식은 detection한 region을 crop하는 과정인데, 다시 말하면 feature map이 있고 RoI가 있을 때 RoI에 해당하는 feature를 선택하고 이를 고정된 크기로 뽑아내는 것이겠죠. 하지만, 이전에 사용되오던 sampling 방식은 RoI Pooling, RoI Rotate(FOTS에서 제안된) 등과 같은 segmentation 기반 방식인데 이들은 oriented, curved text에 대해 적절하게 feature를 align할 수 없습니다. 그래서 저자들은 detection 결과로 나오는 Bezier curve bbox에 잘 맞는 BezierAlign이라는 새로운 feature sampling방식을 제안하게 되었습니다.
BezierAlign이란 RoIAlign을 확장한 버전인데,, RoIAlign과는 다르게 BezierAlign의 sampling grid는 직사각형이 아닙니다. [Figure 7]의 (c)가 BezierAlign에 해당하는데, 보시면 RoIAlign과는 다르게 Bezier curve boundary에 수직으로 grid가 생성되는 것을 알 수 있습니다. 이 sampling point는 다른 sampling point들과 가로 세로로 같은 거리를 가지도록 하였는데 이 때 bilinear 보간을 사용하였습니다.

먼저 input feature map과 Bezier curve control point가 주어졌을 때 이들을 고정된 크기(h_{out}, w_{out})의 feature map으로 변환시켜 recognition branch의 입력으로 잘 들어갈 수 있도록 해야하겠죠. (g_{iw}, g_{ih}) 위치에 대항하는 pixel g_i가 어떤 위치로 이동하는지 수식으로 살펴보도록 하겠습니다.
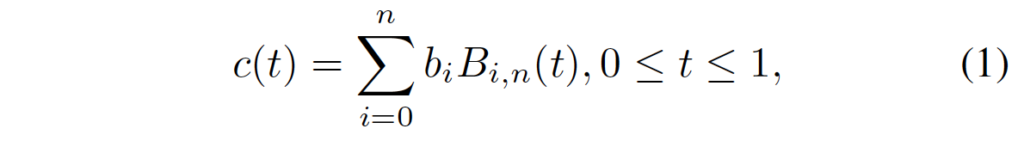
위에식은 bezier curve 수식을 들고 온 것인데, 이 식의 파라미터인 t를 계산하는 식은 아래와 같습니다.
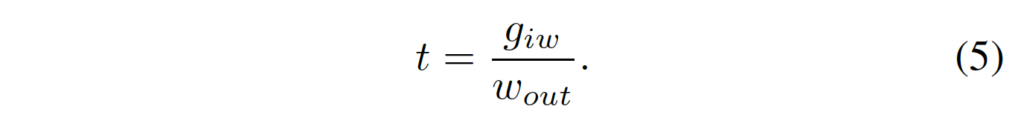
그 다음 t를 계산하였으면 이를 식(1)에 대힙하여 계산해서 upper Bezier curve 경계의 point와 lower Bezier curve 경계 point tp, bp를 각각 얻어낼 수 있습니다. 이를 가지고 단순하게 아래 식(6)으로 계산을 하면 sampling point op를 얻어낼 수 있는 것입니다.
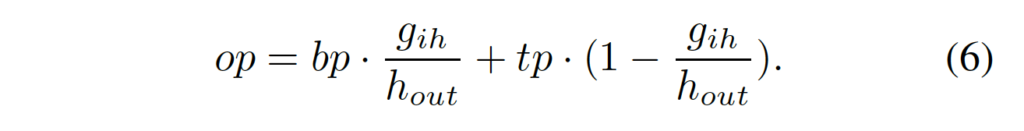
식(6)은 단순한 선형 계산으로 보여집니다. 이렇게 계산된 op의 위치가 있으면 최종적으로 bilinear 보간을 통해 결과를 도출할 수 있겠습니다.
Recognition branch.
마지막으로 Bezier curve 방식을 사용하여 text를 검출한 후 Bezier align을 거쳐 feature를 align시킨 후 이를 입력으로 사용하여 최종적으로 어떤 단어인지 인식하는 recognition branch에 구조에 대해 알아보도록 하겠습니다. text detection branch와 backbone feature를 공유하기도 하고 최대한 가벼운 모델을 설계하기 위해 recognition branch도 아래 table1과 같이 lightweight로 설계하였습니다.

보시면 오직 6개의 convolution layer, 1개의 bi LSTM, 1개의 fc layer만으로 구성되어 있습니다.
최종적으로 fc layer를 통과하면 각 class에 대한 score가 나오게 되고 이를 기반으로 타 recognition branch에서도 많이 사용해왔던 CTC Loss를 사용하여 실제 gt와 모델이 예측한 class간의 일치되는 정도를 측정하도록 하는 식으로 학습이 이루어집니다.
학습할 때는 생성해놓았던 Bezier curve GT를 사용하여 바로 RoI feature를 추출하도록 하여 detection branch가 recognition branch에 영향을 미치지 못하도록 하였고, 당연하게도 Inference할 때에는 RoI region이 detect한 Bezier curve로 대체가 되겠습니다.
3. Experiments
저자들이 scene text spotting에서 해결하고자 하였던 부분이 oriented, curved text와 관련된 것이었기에 다른 regular한 text dataset에서는 실험을 진행하지 않았고, 오직 irregular한 dataset인 Total-Text와 CTW1500에서만 실험을 진행하였습니다. 물론 이 데이터셋에서도 많은 양의 straight text가 포함되어 있긴 합니다.
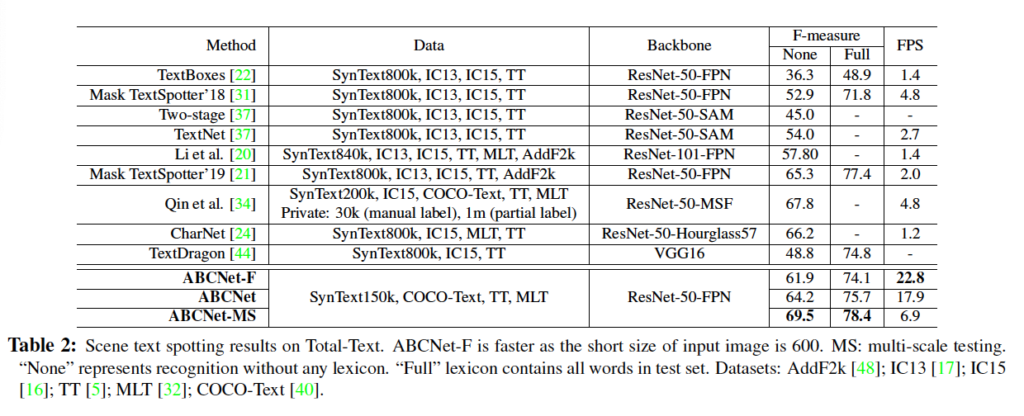
Total Text에 대한 실험 결과를 보면 ABCNet-F는 input으로 들어가는 이미지 크기를 600으로 설정한 것에 해당하는데 저자들의 말에 의하면 다른 방법론들과 비교할만한 성능인데 FPS는 가장 빠르다고 합니다. 또, ABCNet-MS는 Multi-scale로 수행한 것인데 SOTA를 달성하였네요. 하지만 타 방법론 중에서도 MS로 학습을 한다면 더 높은 성능이 존재할 것 같긴 합니다. 일단 저자는 SOTA 방법론과 비교했을 때 본 방법론이 11배 정도 빠른 속도를 가진다는 점을 내세우며, 속도 측면을 굉장히 강조하였지만 그와 비슷한 성능을 가지는 ABCNet-MS와 비교를 했어야 하지 않나 싶네요.
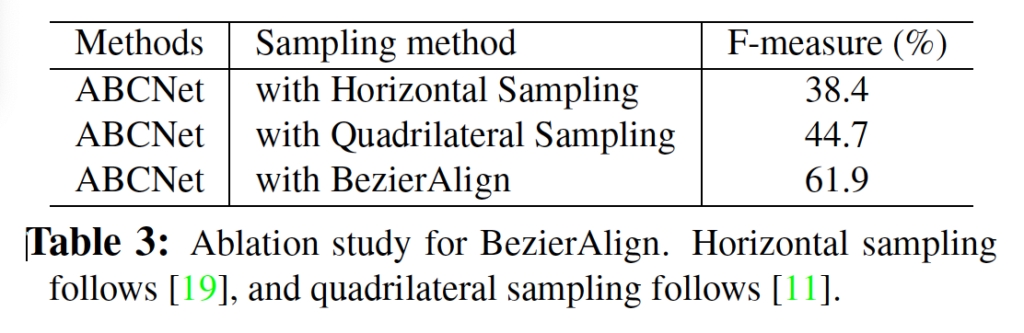
위 표는 BezierAlign에 대한 ablation study 결과인데 보시다시피 저자들이 제안한 BezierAlign을 사용했을 때가 타 sampling 방식을 사용했을 때보다 확연하게 성능이 높은 것을 볼 수 있습니다.

이에 대한 정성적 결과인데, 오른쪽 그림들에서 위에 해당하는 것이 quadrilateral sampling에 해당하고, 아래에 해당하는 것이 본 논문에서 제안된 BezierAlign입니다. 아무래도 BezierAlign은 휘어진 글자에 대해 똑바로 펴 주기 때문에 recognition을 보다 잘 할 수밖에 없겠네요. ..
안녕하세요! 좋은 리뷰 감사합니다.
ABCNet의 장점이라고 하면 2D attention과 같은 복잡한 transformation 과정이 없다고 하셨고, 이로서 recognition branch를 light하게 설계할 수 있어 보다 빠르게 동작할 수 있던 것으로 이해했습니다. 그런데 타 방법론과 비교하였을 때 왜 본 방법론은 transformation 과정이 필요 없는 것인지 의문이 듭니다. BezierAlign이 일종의 transformation 역할을 하는 것으로 이해하면 되는 것일까요 ?
또, Bezier GT를 만드는 부분에서 t를 계산할 때 왜 곡선의 길이를 누적한 값을 기존 gt polyline으로 나누는 것인지 이해가 잘 가지 않는데 굳이 이렇게 계산해야 하는이유가 있는 것인가요?
감사합니다.
안녕하세요. 댓글 감사합니다.
건화님이 말하신 것처럼 BezierAlign warping이 일종의 transformation 과정이라고 볼 수 있으며, 이로 인해 2D attention과 같은 복잡한 transformation 과정이 없겠습니다.
또, BezierGT를 생성하는 부분에서는 gt polygon을 가지고 bezier curve를 만들게 되는데 이 gt polygon의 각 좌표 사이의 거리가 서로 다른 text끼리는 상이한 값을 가지게 될 것입니다. 이런 상황에서 t를 하나로 통일시키게 된다면 bezier curve가 그에 맞지 않는 모양을 가지게 될 것이기 때문에 이를 방지하기 위해 gt polygon 좌표 사이 거리에 따라 적절하게 조절을 해야 합니다. 이때 t를 사용하게 되는데 여기서 t는 Bezier curve를 어디에 위치시킬지 결정하는 parameter입니다. 곡선 길이를 누적한 값으로 t를 계산하게 된다면 그 gt polygon 좌표 사이의 거리에 따라 곡선을 부드럽게 만들어낼 수 있게 됩니다. .