안녕하세요. 이번에도 ERC 논문을 들고 와봤습니다. 확실히 ER보다는 ERC가 훨씬 더 많이 연구되고 있다보니 이쪽 논문을 더 읽게 되는건 어쩔 수 없는 것 같습니다. 이번에는 text modality만 사용한 논문인데요. 이전에 논문들에서는 context나 knowledge를 사용하는 것을 매우 중요하게 여기는 것에 비해서 이 논문은 제목에서 알 수 있듯이 필요할 때만 사용해야 한다!라는 주장이 흥미로워 읽게 되었습니다. 그럼 리뷰 시작하겠습니다.
<introduction>

Emotion recognition in conversation (ERC)의 기존 연구는 전통적으로 context-sensitive 종속성과 knowledge-sensitive 종속성을 모델링해야 했는데요.
특히, knowlege-sensitive ERC 모델에서는 주로 두 가지 종류의 external knowledge가 있습니다. 하나는 external knowledge 기반 ConceptNet 또는 SenticNet에서 가져온 concept입니다. 다른 하나는 pre-training commonsense transformers (COMET)에 의해서 생성된 concept입니다. 또한, context-sensitive ERC 모델에서는 최근 연구에서 memory network 및 graph-based 모델 등 다양한 방법을 제안했습니다. 하지만, 이러한 연구는 모델에 현재 발화에 대한 context와 external knowledge가 필요한지 여부를 따르는 것이 아니라 모델링하는 방법을 개선하는데 중점을 둡니다. 조금 더 예시를 들어보겠습니다. Fig 1을 보시면, Example1의 감정은 context와 external knowledge를 활용하지 않고도 직관적으로 감정을 인식할 수 있습니다. Example 2(context-independent)는 대화의 첫 번째 발화로 context가 없는 발화입니다. 이 문장에서 감정을 인식할 때 patio furniture와 ‘joy’ 사이의 관계를 미리 알고 있지 않다면 감정을 인식하기가 어려울 것입니다. Example 3 (knowledge-independent)의 경우, 발화의 문자 그대로의 의미가 전달된 감정과 반대를 띕니다. 따라서 context가 없으면 발화의 감정을 정확하게 인지하기 어렵습니다. 이렇게 위의 예시들이 존재하지만 context나 external knowledge가 제거하는 경우, 발화 represnetation 간의 semantic gap이 발생합니다. 따라서 context-, knowledge-independent 발화를 다른 발화와 구별하는 방법은 매우 어려운 과제라고 말할 수 있습니다.
위의 내용을 바탕으로, 논문의 저자는 context-, knolwdge-independent 발화를 구분하기 위해 contrastive learning (CL) 기반 framework인 CKCL을 제안하였습니다. 구체적으로 context-independent, knowledge-indepednet 발화를 ‘1’로 label을 지정합니다. (context-dependent, knowledge-dependent 발화의 경우 ‘0’으로 label을 지정합니다) 그런 다음, CKCL은 label이 같은 발화는 함께 있을 수 있도록, label이 다른 발화는 멀리 있을 수 있도록 밀어버립니다. ERC 모델의 경우, 이렇게 함으로써 학습 동안에 context-, knowledge-independent 발화 representation의 성능 저하를 완화시킬 수 있습니다. 또한, CKCL은 관련없는 context와 knowledge의 noise를 제거하여 모델의 robustness를 향상시킬 수 있습니다. 그리고, 논문의 저자는 Li et al. (2022a)에 영감을 받아, 비슷한 감정을 더 잘 구분하기위해 Emotion SCL이라는 이름의 weighted upervised CL (SCL)을 CKCL에 도입하여 ERC의 고르지 않은 클래스 분포를 고려합니다. 최종적으로 논문의 contribution은 아래와 같습니다.
- 논문의 저자는 ERC task에서 최초로 self-supervised CL을 사용하였습니다
- context-, knowledge-independent 발화를 구별하기 위해 CKCL framework를 제안하였고, 이를 통해 학습 중에 관련 없는 context와 knowledge에 대한 ERC 모델의 robustness를 키웠습니다.
- SOTA 달성
<Proposed CKCL Framework>
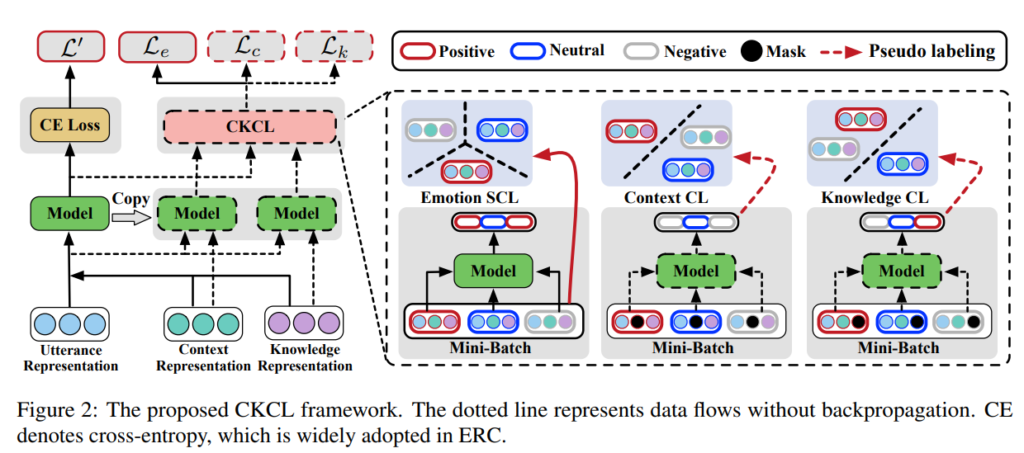
<Task Definition>
conversation C는 발화 $u_1, u_2, …, u_n$으로 구성되며, 여기서 n은 발화의 개수를 의미합니다. 각 발화 $u_i = {w_1, w_2, …, w_m}$은 $m$개의 token으로 구성됩니다. 그리고 C에는 참가자 $S = {s_1, s_2, …., s_g} (g ≥ 2)$가 있습니다. 각 발화 $u_i$는 S 중 하나가 발화합니다. 그런 다음 ERC task는 $C$의 각 발화에 대해 미리 정의된 감정 label set $Y = {y_1, y_2, …, y_e}$를 예측하는 것을 목표로 합니다. 그러나 vanilla emotion recognition과 달리 ERC 모델은 참여자 간의 상호 작용으로 인해 context-, knowledge-sensitive dependency를 모델링하는데 중점을 두어야 하는데요, 따라서 이러한 부분을 다음과 같이 표현할 수 있습니다. $y_i = f((u_i, k_i), (u_{i-1}, k_{i-1}), …., (u_{i-w}, k_{i-w}))$ 여기서 $w$는 context의 size를 의미하고, $K = {k_1, k_2, …., k_n}$는 발화에 대한 external knowledge를 나타냅니다.
<Overview>
CL은 visual representation을 개선하기 위해 data를 augment하기 위해 처음 제안되었습니다. 이후 semantic text similarity task에서 BERT의 성능이 좋지 않은 것에서 영감을 받아 연구자들은 발화 간의 상관관계와 차이를 포착하기 위해 self-supervised CL을 도입하기 시작했습니다. 그 후 NLP 분야에서 점점 더 많은 CL 기반 방법이 등장하기 시작했는데요. 안타깝게도 ERC 분아에셔 unsupervised CL을 기반으로 한 관련 연구는 아직 없다고 합니다. 이 세션에서는 context와 external knowledge를 모델링할 때 ERC 모델의 성능이 저하되는 점을 감안한하여 학습 중에 발화 representation을 개선하기 위해 CL 기반 framework인 CKCL을 소개합니다. 또한 Li et al. (2022a)에서 영감을 받아 weighted supervised CL을 CKCL에 통합하여 고르지 않은 분포 샘플을 구별하는 것 또한 진행합니다.
<Context CL>
context는 NLP와 관련된 task에서 core에 해당하며 NLP systems의 성능을 크게 향상시킵니다. ERC에서는 현재 발화(t 시점)의 주변 발화(t 미만 시점)가 context로 처리되는데요(Poria et al., 2017). 그러나 (1) emotion al dynamics : self-, inter-personal dependency modeling (Poria et al., 2019), (2) 근거리 발화와 원거리 발화 간의 차이로 인해 context를 모델링하는 것은 어려운 일입니다. 기존 ERC 모델은 context를 모델링하여 classification performance를 향상시키지만, 낮은 품질의 context로 인해 퇴보하는 경우도 있습니다. 특히 특정 발화에서 모델의 성능은 context 정보를 고려하지 않은 모델보다 훨씬 더 나빴으며, 이는 ERC에서 관련 없는 context noisze 제거의 중요성을 강조합니다. 또한 저품질의 context noise 제거의 효과는 다른 NLP task에서도 입증되었다고 합니다. (Zhang et al., 2021)

논문의 저자는 이를 기반으로 context-independent, context-dependent 발화 간의 상관관계와 차이를 포착하기 위해 context CL을 설계하였습니다. 먼저 모델 M을 복사하여 각 mini-batch $B$에 대한 복제 모델 $M†$에 $u_i$의 context reprsentation $\hat{x_i}$를 0으로 masking한 input data ${x_i, [MASK], k_i}_{i=1}^{N_b}$를 feed 합니다. 그런 다음 Algorithm 1의 $Line 6 – Line 12$로 표시되는 self-supervised pseudo labling을 수행합니다. 마지막으로, Algorithm의 $LIne 14 – Line 24$에 설명된 pseudo labels $z^c = {z_i^c}^{N_b}_{i=1}$에 따라 constrastive loss item $L_c$를 계산할 수 있습니다.
<Knowledge CL>
대화에서, 사람은 일반적으로 감정을 전달하기 위해 commensence knowledge에 의존한다고 합니다(Zhong et al., 2019). 그러나 knowledge-sensitive ERC 모델에서는 발화를 이해하는 데 관련이 없는 knowledge가 noise로 받아들여질 수 있습니다(Tu et al., 2022b). knowledge selection을 위해서 노력한 몇 연구자들의 연구가 있지만, knowledge-dependet 발화에서는 발화의 감정을 식별하는데 external knowledge를 필요로하지 않기 때문에 여전히 한계가 있습니다. 이를 위해서 논문의 저자는 knowledge-independent 발화와 knowledge-dependent 발화를 구분하고 관련없는 knowledge noize 제거를 위해서, CL 기반 방법론 Knowledge CL을 설계하였습니다. Knowledge CL의 process는 Context CL의 과정과 유사하지만 차이점이 있다면 Knowledge CL은 context representation이 아닌 knowledge representation을 마스킹한다는 점입니다. 결과적으로 Algorithm 1에서 설명한 loss L_k를 얻을 수 있습니다.
<Emotion SCL>
클래스 분포가 매우 고르지 않고 emotion label의 유사성이 높은 ERC task 특성을 고려하여, 논문의 저자는 유사한 감정을 가진 발화를 보다 명확하게 표현하기 위해 class-weighted SCL인 Emotion SCL을 제안하였습니다. Emotion SCL은 emotion label이 다른 sample을 더 멀리 떨어뜨려 클래스 불균형 문제를 어느정도 완화할 수 있다고 합니다. 각 mini-batch B에 대한 Emotion SCL의 process는 다음과 같습니다.
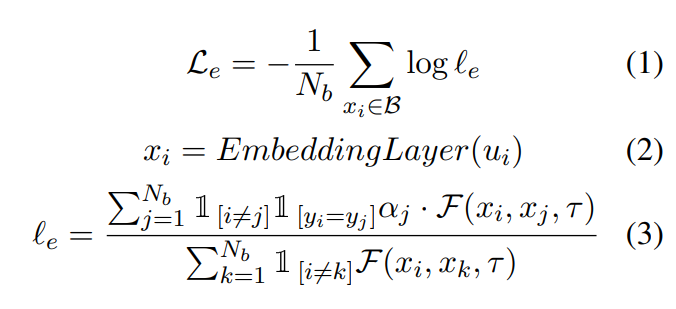
여기서 $B$는 mini-batch sample을 나타내고, $N_b$는 B의 size 입니다. $\mathbb{1}_{[.]} \in {0, 1}$은 indicator function을 나타냅니다. $α_j$는 $j$번째 발화의 class weight를 나타냅니다. $EmbeddingLayer(.)$는 word embedding method를 나타냅니다. ERC 모델은 일반적으로 발화 representation을 encoding하기 위해서 BERT, Glove 또는 Roberta를 활용합니다. $\mathcal{F}(x_i, x_k, \tau) = e^{simi(x_i, x_j)/\tau}$, 여기서 $\tau$는 temperature parameter를 의미하고, $simi(x_i, x_j) = \frac{x_i \cdot{x_j}}{||x_i|| ||x_j||}$은 cosine similarity function을 의미합니다. 그리고 ${y_i}^{N_b}_{i=1}$은 B의 발화의 emotional label set을 의미합니다.
<Model Training>
모델의 학습은 다음 세 가지 loss의 합을 최소화하여 제안한 framework를 공동으로 학습합니다.
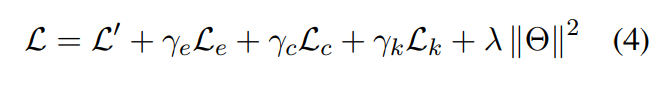
$γ_e, γ_c$와 $γ_k$는 튜닝된 하이퍼파라미터 입니다. $L’$은 classification loss를 의미합니다. $Θ$는 CKCL framework의 학습가능한 파라미터 set 입니다. $λ$는 $L_2-regularization$의 계수를 나타냅니다.
<Experiments>
<Dataset>
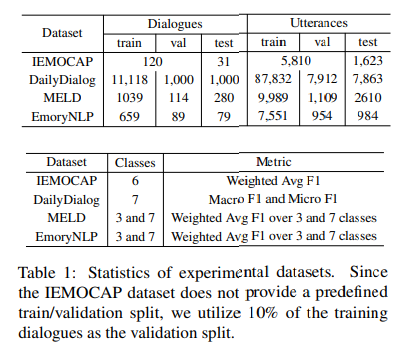
본 논문에서는 총 4가지의 데이터셋을 이용하여 성능을 측정하였는데요. 각 데이터셋에 대해서 간략히 설명드리고자 합니다.
- IEMOCAP : 제 리뷰를 몇번 보신 적 있다면 이 데이터셋을 자주 마주쳤을 것 같은데요. 감정인식에서 아주 유명한 데이터셋이죠. 이 데이터셋은 배우들이 즉흥 연기를 하거나 대본에 따라 시나리오를 여기하는 dyadic session으로 구성됩니다. 그리고 각 발화에는 happy, angry, neutral, sad, excited, frustrated가 labeling 되어 있습니다.
- Dailydilog : 사람이 직접 작성한 일상 대화 데이터셋인데요. 각 발화에는 happioness, surprise, sadness, anger,disgust, neutral 중 하나의 감정과 neutral, negative, positive 중 하나의 sentiment로 labeling 되어 있습니다.
- MELD : TV show인 Friends에서 수지한 다자간 대화 데이터셋으로, EmotionLines 데이터셋의 확장판이라고 합니다. 각 발화에는 surprise, fear, disgust, anger, sadness, neutral, joy 중 하나로 labeling 되어 있습니다.
- EmoryNLP : MELD와 마찬가지로 TV show인 Firend의 multi-party session으로 구성되어 있으며, 각 발화에는 surprise, fear, disgust, anger, sadness, neutral, joy 중 하나로 labeling 되어 있습니다.
<Comparision Models>
논문의 저자는 다양한 모델과 비교를 수행하고자 하였는데요. 비교한 모델을 간략히 분류하자면 이렇습니다.
- RNN-based models : COSMIC, DialogueRNN
- Memory network : AGHMN
- Graph-based models : DialogueGCN, DAG-ERC
- Transformer-based model : KET
- SOTA : TODKAT, CoG-BART, MIC+HCL, CauAIN
정말 다양한 방법론과 비교하는 것을 확인할 수 있습니다.
<Experimental Results and Analysis>
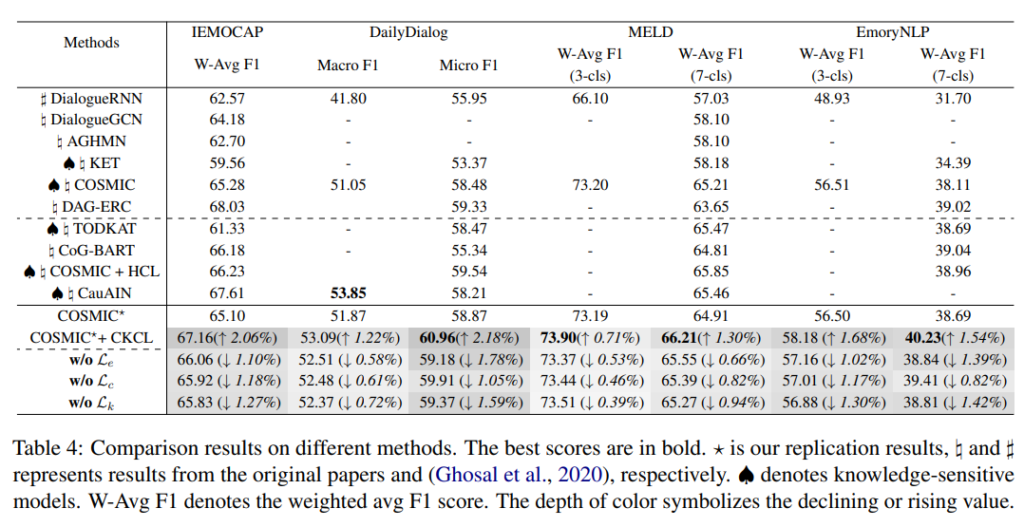
Table 4를 통해서 데이터셋에서의 모델의 성능을 확인할 수 있습니다. CKCL framework에 기반한 COSMIC의 성능이 크게 향상된 것을 확인할 수 있습니다. DailyDialog 데이터셋에서 COSMIC⋆은 2.18%라는 최고의 개선 결과를 보였습니다. 또한 COSMIC⋆+CKCL은 IEMOCAP 제외한 다른 데이터셋에서 SOTA를 달성한 것을 확인할 수 있습니다.
<Ablation Study>
제안한 CKCL framework의 각 구성 요소가 미치는 영향을 조사하기 위해서 COSMIC⋆에 대해서 abliation study를 진행했으며, 그 결과는 Table 4를 통해 확인할 수 있습니다. ‘w/o $L_{con}$’, ‘w/o $L_{kno}$’, ‘w/o $L_{emo}$’는 각각 Context CL, Knowledge CL, Emotion SCL이 없는 경우를 나타냅니다. 결과적으로 성능을 통해서 확인해보면 Context Cl, Knowledge CL, Emotion CL이 유의미한 역할을 하는 것을 알 수 있습니다.
<Analysis of CKCL>
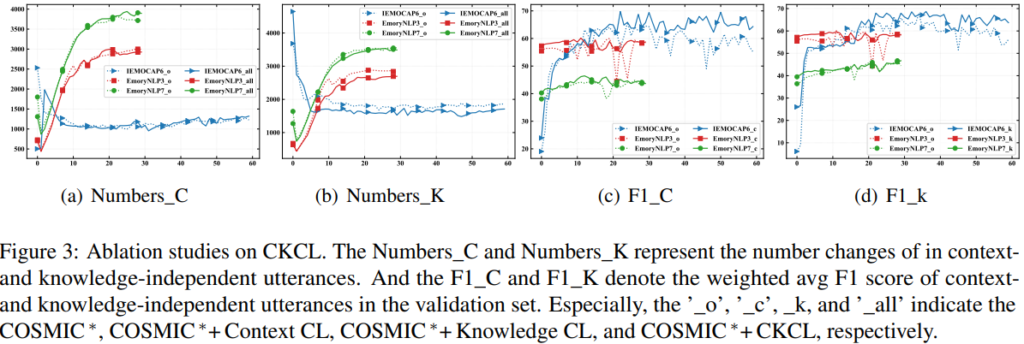
모델 학습에서, context-, knowledge independent 발화를 적절히 구분하면 latent feature를 포착할 수 있는데, 이는 채context 또는 knowledge가 예측 결과에 미치는 영향 정도를 반영합니다. 이는 ERC에서 모델의 representation과 denosing 능력을 향상시킵니다. Table 4를 통해서 이를 확인할 수 있으며, Knowledge CL의 effectiveness가 Context CL의 비해 우수하다는 것을 확인할 수 있습니다. 이는 모델 고유의 능력으로 관련 없는 context의 노이즈 제거는 어느 정도 가능하지만, 관련 없는 knowledge를 효과적으로 처리하는데 어려움을 겪기 때문일 수 있다고 본 논문의 저자는 말합니다. 또한, IEMOCAP과 Dailylog 데이터셋 간의 데이터 크기 차이를 고려하여, 더 나은 시각화를 위해 IEMOCAP과 EmoryNLP 데이터셋에 대한 CKCL을 분석하였습니다. context-, knowledge-independent 발화의 수는 Figure3에 표시되어 있습니다. 특히 Figure 3의 (c-d)는 context- 또는 knowledge-independent 발화의 성능을 효과적으로 향상시키는 CKCL의 기능을 보여줍니다. 이는 관련 없는 context나 knowledge noize 제거에 있어서 CKCL framework가 효과적이라는 것을 입증합니다.
이렇게 리뷰를 마쳐봅니다. 이전에 읽었던 논문이 context와 knowledge를 어떻게 주입하고 이거를 어떻게 모델링할지에 대해서밖에 다루지 않았다면 정말 context와 knowledge가 항상 필요한 것인가? 라는 질문에 답을 해주는 논문이 아니었나 싶습니다. 읽어주셔서 감사합니다.
Shimin Li, Hang Yan, and Xipeng Qiu. 2022a. Contrast and generation make bart a good dialogue emotion recognizer. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 36, pages 11002– 11010.
Soujanya Poria, Erik Cambria, Devamanyu Hazarika, Navonil Majumder, Amir Zadeh, and Louis-Philippe Morency. 2017. Context-dependent sentiment analysis in user-generated videos. In Proceedings of the 55th annual meeting of the association for computational linguistics, pages 873–883
Soujanya Poria, Devamanyu Hazarika, Navonil Majumder, Gautam Naik, Erik Cambria, and Rada Mihalcea. 2019. Meld: A multimodal multi-party dataset for emotion recognition in conversations. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 527–536.
Chenwei Zhang, Yaliang Li, Nan Du, Wei Fan, and Philip S Yu. 2021. Entity synonym discovery via multipiece bilateral context matching. In Proceedings of the Twenty-Ninth International Conference on International Joint Conferences on Artificial Intelligence, pages 1431–1437.
Peixiang Zhong, Di Wang, and Chunyan Miao. 2019. Knowledge-enriched transformer for emotion detection in textual conversations. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing, pages 165–176.
Geng Tu, Bin Liang, Dazhi Jiang, and Ruifeng Xu. 2022b. Sentiment-emotion-and context-guided knowledge selection framework for emotion recognition in conversations. IEEE Transactions on Affective Computing, (01):1–14.
안녕하세요
중간의 Emotion SCL 연산 시 클래스 별 alpha는 어떻게 계산되는 것인가요? 저자가 제안하였다고 하니 다른 논문에서 가져온 것 같지는 않은데, 해당 설명을 제가 놓친 것인지 궁금합니다. 그리고 라벨이 다른 instance를 더 멀리멀리 떨어뜨리는 것이 클래스 불균형 문제 해결과 어떤 연관이 있는지도 궁금합니다.
Emotion SCL 연산 시 발화 representation을 얻기 위해 BERT, GloVe 등을 사용한다고 해주셨는데 일반적으로 같은 프레임워크인 경우 어떤 representation이 가장 높은 성능을 보여주나요??
안녕하세요. 댓글 감사합니다.
1) α의 경우 논문에서 구체적으로 어떻게 계산하는지에 대해서 나오지는 않았지만 저는 sklearn.utils.class_weight.compute_class_weight 함수를 생각하며 읽었는데요. sklearn에서 제공하는 class weight는 n_samples / (n_classes * np.bincount(y)) 식을 통해서 구할 수 있습니다.
2) 라벨이 다른 instance를 멀리 떨어뜨리는 경우, 클래스 불균형 문제를 해결한다는 것에 대해서 구체적으로 어떻게 해결한다는 것인지 나와있지는 않았지만 제 생각에는 클래스 불균형일 경우 embedding space가 좁은 embedding space로 인해서 감정 예측이 어렵지만 멀리 멀리 떨어뜨리게 되면 space가 넓어지면서 감정들의 구분이 수월하게 되지 않나 생각이 듭니다.
3) 논문의 시기상 GloVe > BERT > RoBERTa이기 때문에 마지막의 것이 제일 높은 성능의 representation을 가지는 것이 아닐까 생각합니다
감사합니다.
안녕하세요 김주연 연구원님 좋은 리뷰 감사합니다.
결국 이 논문은 직관적으로 감정을 알 수 있는 발화와 맥락 정보를 필요로 하는 발화를 contrastive learning기반의 방법으로 분류하는 과정을 추가한 것으로 이해하였습니다.
Context CL부분에서 psudo labeling을 Algorithm 1의 Line6 –Line12에 따라 진행하였다고 하셨는데요, 해당 과정이 잘 와닿지 않습니다. 알고리즘을 보면 입력으로 utterence x, context x^, external knowledge k가 들어가고 x^와 k를 각각 masking하여 감정을 예측하는 것으로 보이는데요, 이때 z^c와 z^k는 각각 무엇을 의미하는지, 해당 알고리즘이 어떻게 진행되는지 설명 부탁드립니다.
감사합니다.
안녕하세요. 댓글 감사합니다.
z의 경우 pseudo labels을 의미합니다. 저는 zc의 경우 context에 대해서, zk의 경우 knowledge에 대해서 pseudo label을 가진다는 것으로 이해하였습니다. 이를 바탕으로 line6-12를 보면 context인 경우 zc에 1을, knowledge에 해당하는 경우 zk에 1을 할당하는 것을 확인할 수 있습니다.
감사합니다.