안녕하세요. 백지오입니다.
열 여덟 번째 X-REVIEW는 논문 리뷰가 아닌 코드에 관련된 내용을 준비했습니다.
연구실에서 공부와 여러 task를 진행하며, 자연스럽게 논문과 관련된 코드를 많이 읽고, 실행해볼 기회가 많았습니다.
특히 올해 여름방학 즈음에 제가 맡은 task에서, 다른 논문의 구현 코드 4,5개를 정리하고 저희 서버에서 돌릴 수 있도록 수정하고 이를 다른 사람도 할 수 있도록 도커와 메뉴얼로 만드는 작업을 진행했었는데요. 복잡한 코드들을 며칠간 들여다보고, 숱한 에러에 부딪혀가며 “언젠가 내가 코드를 짤 날이 오면 어떻게 짜야할까”하는 고민을 했었습니다.
그리고 마침 최근에 제가 이전에 리뷰한 Distilling Vision-Language Pre-training to Collaborate with Weakly-Supervised Temporal Action Localization 논문을 구현해보는 작업을 하게 되면서 이러한 고민들을 구체화하고, 발전시킬 기회를 얻을 수 있었는데요.
이번 주에는 제가 논문 구현 작업을 하며 스스로 괜찮다고 생각한 부분들이나 아쉬운 부분, 생각해보면 좋을 법한 부분들을 공유해보고자 합니다.
사실 제가 뭐 엄청난 클린 코더도 아니고 저만의 대단한 비법이 있지도 않지만, 읽으시면서 하나라도 도움이 되시거나 혹은 더 좋은 방법이나 아이디어를 공유할 수 있는 기회가 되었으면 좋겠습니다.
그럼 시작해보겠습니다.
클래스, 함수 별 주석 작성하기
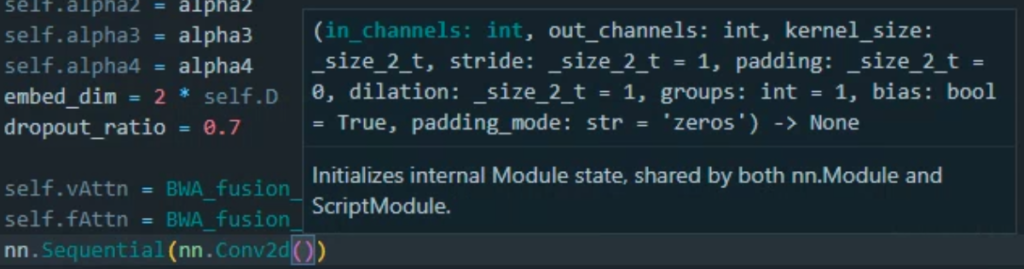
몇 천 줄의 코드를 작성하다보면, 내가 짠 코드여도 이 함수가 뭐였는지, 어떤 순서로 인자를 받았는지 헷갈리는 일이 많은데요. 하물며 남이 짠 코드를 보면 도대체 이 함수에 $X, alpha$라고 하는 입력은 뭔지, 어떤 shape인지 헷갈릴 때가 많습니다.
따라서 제가 이번에 논문을 구현하면서도, 클래스와 함수들의 형태와 기능이 명확하게 짜고자 노력했는데요. 크게 두 가지 원칙을 적용하였습니다.
- 우선, 함수와 변수의 이름과 같은 맥락으로 최대한 역할을 한번에 알아볼 수 있도록 짜도록 하자.
- 만약 불가능하다면, 적절한 위치, 적절한 양의 주석을 통해 설명하자.
이때, 주석을 달 경우 위 이미지와 같이 vs code 툴팁에 표시되는 클래스별, 함수별 주석을 최대할 깔끔하게 작성하고자 하였습니다. vs code에 python extension을 설치하면, 각 함수와 클래스 최상단에 작성되어 있는 주석을 아래와 같이 툴팁으로 보여주게 됩니다.


이러한 기능은 특히 함수별 주석에서 유용하게 동작하는데요. 함수 별 주석을 작성할 때, 아래와 같이 매개변수들의 역할을 설명해주면…
1 2 3 4 5 6 7 8 9 10 11 12 | def get_pseudo_label(self, visual_feature, actionlist, label, branch): “”“ get pseudo-label from designated branch visual_feature: visual feature input for prediction, (B, T, D) actionlist: list of the actions label: video-level one-hot label (B, C) branch: branch to make pseudo_label pseudo_label: one hot vector (B, T, C), 1 indicates confident foreground \ and 0 indicates confident background -1 otherwise. ““” | cs |
해당 함수를 사용할 때, 각 매개변수를 입력할 때마다 해당 변수의 역할을 알려줍니다!
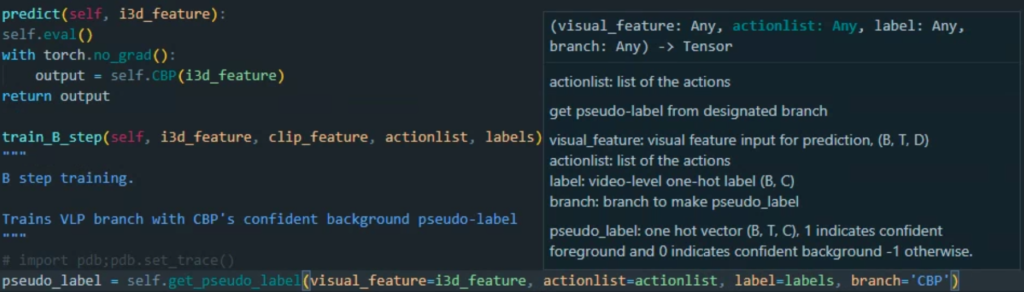
코드가 길어지다 보면, 어떤 함수가 정확히 어떤 값을 입력받는지, 자료형이나 shape가 헷갈리는데 조금 번거롭더라도 이런 주석을 꼼꼼히 달아주면 나중에 다른 사람이 제 코드를 볼 때도 편하겠지만, 당장 제가 코드를 디버깅하는 과정에서도, 과거에 작성한 함수의 입출력 구조를 다시 찾느라 시간 낭비를 할 필요가 없어 디버깅을 훨씬 효율적으로 진행할 수 있었습니다.
이러한 클래스별, 함수별 주석과 같이, 정형화된 형태의 주석을 docstring이라 하는데요, docstring을 작성하기 위한 convention 몇 가지를 소개해드리겠습니다. (이 부분은 다음 글을 참고하였습니다.)
Sphinx Style
1 2 3 4 5 6 7 8 9 10 11 12 | def multiply(x, y): “”“Multiply two given values. :param x: input value number one :type x: int :param y: input value number two :type y: int :returns: multiplied value of x and y :rtypes: int ““” return x * y | cs |
파이썬 공식 문서에 사용하기 위해 제작된 형식입니다. 파라미터에 대한 설명과 자료형을 별도의 line에 작성한 게 특이하네요. 다른 방식들에 비해 간결한 형태입니다.
NumPy / SciPy docstrings
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | def multiply(x, y): “”“Multiply two given values. Parameters ———- x: int input value number one y: int input value number two Returns ——- result multiplied value of x and y ““” return x * y | cs |
이름 그대로 넘파이에서 사용하는 형식입니다. 이 링크에서 자세히 보실 수 있습니다.
앞선 방식에 비해 가독성이 좋지만, 줄 수가 좀 많은 느낌이 듭니다.
Google Style
1 2 3 4 5 6 7 8 9 10 11 | def multiply(x, y): “”“Multiply two given values. Args: x (int): input value number one y (int): input value number two Returns: result: multiplied value of x and y ““” return x * y | cs |
역시 이름처럼 구글에서 사용하는 방식입니다. 이 링크에서 더 많은 예시를 보실 수 있습니다.
Gio Style
1 2 3 4 5 6 7 8 9 10 | def multiply(x, y): “”“ Multiply two given values. x: input value number one y: input value number two return: multiplied value of x and y ““” return x * y | cs |
제가 사용하는 방식입니다. 위 방식들에 비해 아주 짧고 간결합니다.
사실 표준화된 방식을 사용하는 것이 가장 좋겠지만, 중요한 것은 vs code python extension과 같은 doc parser가 잘 파싱해서 툴팁을 보여줄 수 있는가 여부이기 때문에, 작성의 편의와 필요성을 적절히 타협한 형태..라고 합리화하고 있습니다. 죄송합니다. 다음부터는 google style로 해보겠습니다.
아무튼, 코딩할 때는 조금 귀찮지만 이러한 docstring이 상당히 작업 효율을 개선해준다는 것을 프로젝트를 진행하며, 디버깅을 하고 있는 지금도 절절히 느끼고 있습니다.
함수 매개변수 타입 지정하기
파이썬에서는 기본적으로 함수의 매개변수 자료형을 제한하지 않지만, 함수 선언 시 명시적으로 매개변수의 자료형을 적어둘 수 있습니다.
1 2 | def train(model: DisCo, dataset: THUMOS_FEATURES, batch_size=64, shuffle=True, num_workers=16, epochs=20, lr=1e–4, device=‘cuda’, step=None): pass | cs |
매개변수의 자료형 지정은 위와 같이, 매개변수 옆에 콜론(:)을 붙여 할 수 있는데요, 이때 매개변수의 자료형이 지정되어 있다고 하더라도 다른 매개변수를 입력할 수도 있기는 합니다. 그럼 위와 같이 매개변수의 자료형을 지정하였을 때의 장점이 뭔가 싶으실텐데요.
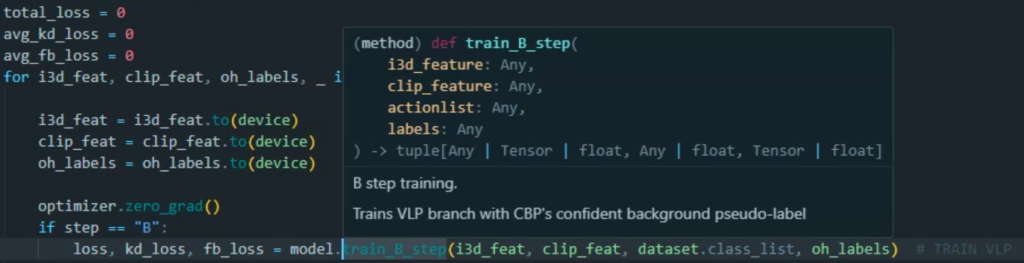
바로 해당 매개변수에 대한 자동완성 기능이 동작한다는 것입니다. ?
매개변수가 정확히 어떤 자료형인지 알려줬기 때문에, IDE가 해당 변수의 내장 함수를 참조할 수 있게 됩니다.
이외에도, 해당 함수를 사용할 때 주석과 함께 사용자로 하여금 어떤 값을 입력해야 하는지 알려줄 수 있는 기능도 있으니, 적절히 활용하면 정말 유용한 기능입니다.
그런데, 만약 함수의 매개변수를 정확히 어떤 자료형으로 제한하고자 한다면 어떻게 하는 것이 좋을지 궁굼하실 수 있는데요. 이는 아래 방어적 프로그래밍에서 이어집니다.
방어적 프로그래밍
방어적 프로그래밍이란 예상치 못한 입력이 주어졌을 때에도 프로그램이 계속적으로 동장하도록 하는 프로그래밍 방식(출처)입니다. 사전적 정의가 직관적으로 이해되지는 않을 것인데, 예를 들면 이렇습니다.
주어진 숫자 x, y를 더하는 함수 add(x, y)를 작성할 때, 프로그래머는 매개변수 x, y가 숫자형 자료(int 혹은 float)라고 가정하고 아래와 같은 코드를 작성합니다.
1 2 | def add(x, y): return x + y | cs |
그런데, 사용자나 개발자의 실수로 해당 함수에 x=2, y=3과 같은 숫자가 아닌 x=[2], y=[3]과 같은 list가 들어갔다고 생각해봅시다. 개발자의 의도에 따르면 해당 함수는 2+3에 해당하는 5를 출력해야 하지만, 해당 함수는 [2, 3]으로 합쳐진 list를 출력하는 오류를 일으키게 됩니다.
그러나, 이러한 상황에 대한 예외처리(Exception)가 되어있지 않기 때문에 해당 코드는 정상적으로 실행되게 되고, 결과적으로 전체 코드는 완전히 이상한 결과값을 내놓거나, 혹은 위 함수가 아닌 어딘가에서 Exception이 발생하여, 개발자로 하여금 문제의 시작이 어디인지 찾아내 디버깅하기 어렵게 될 것입니다.
방어적 프로그래밍이란 이러한 문제들이 반드시 일어난다고 가정하고, 코드 작성 단계부터 이러한 문제들을 대비해가며 프로그래밍하는 방식입니다. 가장 대표적인 것이 가정 설정문, assertion 입니다.
1 2 3 4 | def add(x, y): assert type(x) in [float, int] assert type(y) in [float, int] return x + y | cs |
가정 설정문을 통한 방어적 프로그래밍을 적용한 add 함수입니다. assert 구문은 이어지는 조건식이 참이 아니라면 AssertionError를 발생시킵니다. 이러한 assertion을 각 함수의 시작점, 끝점, 그리고 코드 내부의 중요한 부분에 적절히 배치해 줌으로서 개발과 디버깅 과정에서 오류를 상당히 빠르게 찾을 수 있었습니다.
저는 이번 프로젝트에서 dataset loader 부분을 작성하며 방어적 프로그래밍의 덕을 크게 봤는데요.
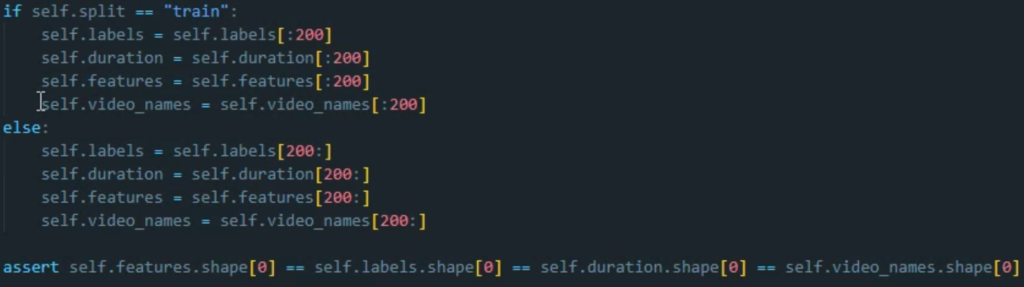
여러 파일로 분산된 dataset을 읽어오는 과정에서, 중간에 데이터셋 파일을 일부 수정한 것을 까먹고 코드를 놀렸는데, feature들의 갯수가 잘 맞는지 확인하기 위해 넣어 놓은 assert 문이 바로 해당 오류를 알려줘 디버깅을 빨리 진행할 수 있었습니다.
만약 이 assert 문이 없었다면, feature와 label, metadata들의 갯수가 다른 상태로 데이터가 로드되어 모델이 완전히 잘못 학습되고 평가되었을 것이고, 저는 도대체 왜 이런 문제가 발생하는지 데이터셋을 직접 까보고 나서야 알 수 있었을 것입니다. (아마 데이터셋을 까보기 전에 모델에 뭔가 문제가 있는 줄 알고 한참을 뒤졌을 수도 있지요.)
try-except 활용하기
try-except 역시 assert와 같은 맥락으로 방어적 프로그래밍에 활용할 수 있습니다. 물론 try문을 사용하는 경우 애초에 Exception이 발생한 것이기 때문에 에러가 발생한 위치를 비교적 빠르게 파악할 수 있겠지만, 미리 에러가 발생할만한 부분에 try문을 적어두고 except 문 아래 pdb를 찍어놓으면, 에러가 발생한 시점에 바로 디버깅을 시작할 수도 있고, 에러에 한층 유연하게 대처할 수 있습니다.

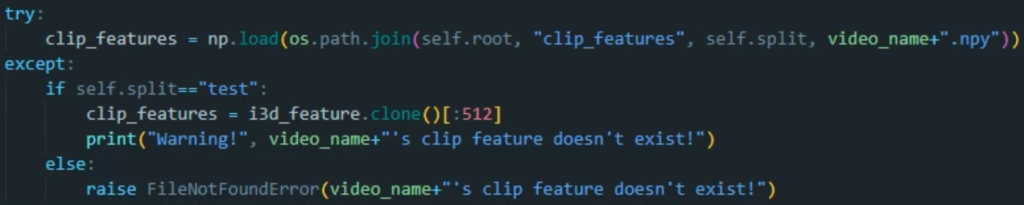
특히 이러한 try-except 문을 활용 시 좋은 점은, 코드의 각 영역에서 어떤 에러가 발생할 수 있는지 외우고 있을 필요가 없다는 점입니다. 위의 두 코드를 자세히 보시면, 제가 except문에 각기 다른 에러를 raise하도록 해놓은 것을 보실 수 있습니다.
위 코드를 작성할 때야 당연히 해당 부분을 작성하고 있으니, 여기서 어떤 에러가 발생할 수 있는지 알고 있지만, 한참 코드를 작성한 후에 테스트 단계에서는 에러가 발생한 위치를 알아도 여기서 어떤 에러가 발생했는지 떠올리기 귀찮고 어렵습니다.
때문에, 해당 위치에서 발생할 수 있는 에러를 미리 위와 같이 적어둔다면, 파이썬 기본 에러 메시지를 보는 것보다 빠르게 디버깅을 시작할 수 있습니다.
log 기록 깔끔하게 하기
실험을 여러 차례 진행하면서 당연히 log를 잘 기록해야겠지만, 제가 귀차니즘이 심한 편이라 기록을 별로 좋아하지도 않고, IOU threshold 값에 따라 실험 한번에 9개씩 나오는 값들을 수기로 기록하기 귀찮아 어떻게 하면 log를 잘 정리할 수 있을까 고민을 해보았습니다.
실험을 진행하며 기록을 남겨야할 것들은 다음과 같습니다.
- 학습 후 얻어진 체크포인트
- 학습 시 사용한 설정 값들
- 학습 시 loss의 변화
- 학습 후 평가 결과
정말 별 것 아니지만, 이 모든 것들을 기록하기 위해 작성한 코드를 공유합니다.
1 2 3 4 5 6 7 8 9 10 11 12 13 | def save_model(state_dict, test_name: str, args=None): “”“ saves model and args ““” save_dir = os.path.join(“./ckpt”, test_name) if not os.path.exists(save_dir): os.makedirs(save_dir) file_name = branch + “.pkl” torch.save(state_dict, os.path.join(save_dir, file_name)) if args is not None: with open(os.path.join(save_dir, “args.json”), “w”) as f: json.dump(args.__dict__, f, indent=2) print(“SAVED MODEL TO”, save_dir) | cs |
모델의 state_dict를 저장하고, 실험 시 사용한 설정 값들이 담긴 args 파일은 json 형태로 dump하는 코드입니다.
JSON은 신입니다. 유사하게 학습 시 loss 기록도 json으로 저장해주었습니다.
1 2 3 4 5 6 | def save_history(hist: dict, test_name: str): savedir = os.path.join(“./ckpt”, test_name, ‘logs’) if not os.path.exists(savedir): os.makedirs(savedir) with open(os.path.join(savedir, ‘train_loss.json’), ‘w’) as f: json.dump(hist, f, indent=2) | cs |
마지막으로 테스트 결과의 경우, pandas를 이용해 csv 형식으로 저장하도록 만들어주었습니다.
테스트 결과를 표 형식으로 바로 볼 수도 있고, 엑셀이나 스프레드시트에 복붙하기도 편해져서 정말 강추합니다.
1 2 3 4 5 6 7 8 | def save_result(dmap, test_name: str, ckpt: str, log_file=“results.csv”): result_csv = pd.read_csv(log_file) # test_name, checkpoint, mAP@IoU [.1-.9], mAP@IoU AVG., mAP@IoU AVG [.1-.5], mAP@IoU AVG [.1-.7], mAP@IoU AVG [.3-.7] log = np.concatenate(([test_name, ckpt], dmap, [np.mean(dmap), np.mean(dmap[:5]), np.mean(dmap[:7]), np.mean(dmap[2:7])])) result_csv.loc[len(result_csv)] = log result_csv.to_csv(log_file, index=None) | cs |
지금까지 제가 이번 코드 구현에서 신경썼던 몇 가지 팁들을 공유드렸는데요. 이어서 프로젝트를 진행하며 제가 고민했고, 아직 결론을 내리지 못한 내용들을 공유드리겠습니다.
양날의 검 argparser
argparser는 의심할 여지없이 편리한 도구입니다. 설정을 다양하게 바꿔가며 실험을 수행할 때, 코드를 수정하지 않고도 이를 수행할 수 있으니까요.
그러나 동시에 TDD를 방해하는 양날의 검이기도 합니다.
argparser를 사용한 코드를 보면, parsing된 arguments 없이는 실행이 불가능한 경우가 많다보니 무조건 argparser가 동작하는 main.py와 같은 파일을 통해 파이프라인 전체를 실행시키며 디버깅을 해야하는 문제가 있습니다.
1 2 3 4 5 | class MyDataset(torch.utils.data.Dataset): def __init__(self, args): self.root = args.root self.split = args.split pass | cs |
위와 같은 코드는 굉장히 간결하고, 초기값 설정을 전부 argparser가 있는 main.py 파일에서 해주면 되는 장점이 있지만, MyDataset 클래스 하나를 디버깅하기 위해 dataset.py 파일이 아닌 main.py 파일에 들어가서, utils와 model과 같은 무관한 파일들까지 모조리 읽어들이고 학습이나 테스트 파이프라인을 실행시켜야 하는 번거로움이 있습니다.
1 2 3 | if __name__ == “__main__”: test_dataset = MyDataset(root=“./dataset”, split=“train”) import pdb;pdb.set_trace() | cs |
한편 argparser를 사용하지 않으면 위와 같이 데이터셋 바로 아래 몇 줄의 테스트 코드만 삽입하여 바로 테스트를 수행할 수 있는 장점이 있지만, 코드 전체의 초기값을 dataset.py, model.py 등 여러 파일에 나누어 설정해야하는 불편함도 있죠.
도대체 어떻게 해야 깔끔하고 효율적인 방법일까 고민하던 저는 결국, argparser를 사용하되, 각 클래스나 함수에 값을 넘길 때는 args 대신에 각 값을 분해해서 넣어주는 약간은 비효율적인 방법을 택하였습니다.
1 2 3 4 | def train(args): datasets = THUMOS_FEATURES(args.dataset_path, annotation_path=args.annotation_path, n_snippet=args.n_snippet) model = DisCo(classlist=datasets.class_list, device=args.device, threshold_high=args.threshold_high, threshold_low=args.threshold_low, loss_weight=args.loss_weight, temperature=args.temperature) model.load_weights(CBP=args.ckpt_CBP, VLP=args.ckpt_VLP) | cs |
뭔가 괜찮은 방법이 있으면 좋겠는데, 이 부분에 대해서는 조금 더 고민을 해봐야 할 것 같습니다.
argparser를 활용한 초기화에 대한 좋은 방법이나 의견이 있으시다면 공유해주시면 감사하겠습니다.
최근 논문 구현 task를 하며 정말 오랜만에 코드를 천 줄 이상 작성해본 것 같습니다.
다른 사람이 짠 코드를 분석하고 수정하는 것과는 또 다른 어려움이 있었고 사실 아직도 완전히 완료하지는 못해서 디버깅을 하고 있지만, 오랜만에 코딩을 하다보니 나름 자랑하고 싶은 부분이나 다른 사람들과 얘기를 나눠보고 싶은 분들이 많이 생겨서 약간 이른 감이 없지 않지만, X-REVIEW에 작성해보았습니다.
지난 7년 간 개발자로서의 코딩만 하다가 이제야 연구자로서의 코딩을 경험해 본 것 같아서 감회가 새롭기도 하고 즐거웠네요. (디버깅도 즐거운 마음으로 하려고 노력 중입니다 ?)
다음 리뷰부터는 다시 논문 리뷰로 찾아뵙겠습니다.
즐거운 연휴 되세요!
감사합니다.
백지오 연구원님, 안녕하세요. 좋은 리뷰 감사합니다. 제목을 보자마자 평소에 보던 리뷰가 아니라 흥미롭게 읽어보았네요. 특히 함수 주석 부분은 전혀 몰랐던 부분입니다. 앞으로 긴 코드를 작성할 일 있으면 염두해 두어야겠습니다. 방어적 프로그래밍이랑 로그 관리도 항상 해야겠다 생각만 하고 어떻게 해야할지 잘 모르기도 하고 귀찮기도 해서 하지 않았는데, 덕분에 어떻게 해야할지 감이 좀 잡힌 것 같습니다. 이런 소소한 팁들이 코드 짜는 효율을 많이 높여주는데, 정리해주셔서 감사합니다.
argparser 설명을 해 주시는 부분에서 헷갈리는게 있는데, 각 class나 함수에 arg 대신 각 값을 분해해서 넣어주는 방식도 결국 main.py의 argment parser를 실행시켜야 하지 않나요? 전체를 실행시키는 것과 어떤 차이가 있는지 조금 더 설명해주시면 감사하겠습니다.
안녕하세요. 허재연 연구원님.
흥미롭게 읽어주셔서 감사합니다. 도움이 되셨다니 기쁘네요.
질문에 대해, dataset.py에 구현된 MyDataset 클래스의 예시를 들어 설명드리겠습니다.
만약, MyDataset의 초기화를 argparser로 parsing된 dict 형태의 args하나만 받도록 했다고 가정해보겠습니다. 이때는 MyDataset(args) 선언을 위해 args가 반드시 필요하기 때문에, main.py에서 argparser로 args를 만들어주거나, dataset.py 파일에도 argparser를 통한 argparsing 코드를 구현해줘야 합니다.
하지만 MyDataset의 초기화를 각 값마다 따로 입력을 받도록 구현한다면, 테스트 시 dataset.py 파일에 테스트 코드를 MyDataset(root=’./’, split=’test’)와 같이 하드코딩하여 간단하게 추가하고, dataset.py를 실행해주면 됩니다.
일반적으로 main.py를 실행시키면 우리가 테스트하고자 하는 데이터셋 파트 이외에 training이나 test를 위한 argment도 파싱하고, 테스트에 필요하지 않은 초기화 로직들을 실행하기도 하기 때문에 제게는 약간 비효율적이라 느껴졌습니다.
또한, class 구현 시 args를 이용해 초기화를 진행하게 되면, 클래스 선언부 코드를 보았을 때 해당 클래스가 요구하는 매개변수가 어떤 것들이며 어떤 자료형인지 등을 유추하기 위해, 해당 클래스 선언부 외에 argparser의 구현부도 살펴봐야하는 번거로움도 존재합니다.
감사합니다.
안녕하세요, 코드 관련후기에 대해 작성해주신 부분 잘 읽어보았습니다.
글을 읽어보니 팁과 같은 부분을 제시해주셨는데, 저도 요즘 코드 분석을 하고 있는데 생각보다 어려워 시간이 오래 걸리고 있는 상황이라 이런 건 어떻게 구현을 한 건지 하는 그런 생각을 많이 하고 있습니다. 질문이라기 보다는 대처방법에 대해 궁금한 점이 있습니다. 백지오 연구원님께서도 구현을 하시면서 분명히 막히는 부분이 있으실 거라고 생각이 듭니다. 이러한 부분에 대해서는 보통 어떻게 해결책을 얻으시고 구현을 하시는지 궁금하네요.
감사합니다. 잘 읽었습니다.
안녕하세요.
좋게 읽어주셔서 감사합니다.
양희진 연구원님이 주신 질문을 읽고 저도 제가 구현을 하다가 어떨 때 막히는지 돌아볼 기회가 되었는데요, 생각해보면 막히는 경우는 보통 둘 중 하나인 것 같습니다. 1. 문제가 너무 복잡해서 어디서부터 풀어야 할지 막막하거나, 2. 문제에 대해 무지해서 어떻게 구현해야 할지 모르겠는 경우입니다.
1.의 경우에는, 저는 최대한 문제를 잘게 쪼개서 분할 정복 하려고 노력하는 편입니다. 코딩을 시작할 때 가장 먼저 구현해야 할 클래스와 함수를 모두 선언 해놓고, 본문에서 설명한 함수별 주석 등을 작성한 후에 본격적으로 함수들을 구현합니다. 만약 함수 하나에서 처리해야 하는 로직이 복잡하다면, 그 함수를 다시 작은 함수들로 쪼개거나, 함수 내부에서 코드를 몇 단계로 나누어 작성합니다. 이런 식으로 문제를 쪼개서 아는 부분들을 다 채우고 나면, 코드에서 어떻게 구현해야 할지 헷갈리거나 아예 모르는 부분만 남게 되기 때문에 그때부터 남은 조금의 영역에만 집중하면 되고, 오류가 발생해도 코드를 잘게 나누어 놨기 때문에 디버깅하기도 편해집니다.
꼭 구현이 아니라 디버깅 코드 분석 과정에서도 코드를 여러 단위로 나누어서, 적어도 어디부터 어디까지는 어떻게 작동하는지 이해하고, 이해한 영역을 넓히는 방식으로 진행하면 웬만큼 복잡한 코드라도 결국 모든 부분을 살펴볼 수 있었습니다.
한편 2.와 같이 무지로 인해 구현이 어려울 때는 결국 공부와 고민밖에 답이 없는 것 같습니다. 이번 task에서 논문에 설명이 매우 rough하게 되어있는 부분에 대해서 구현할 때 이러한 문제를 겪었는데요. 논문을 다시 다 읽어보며 단서가 될 만한 부분들을 찾아도 보고, 유사한 방법을 사용하는 논문이나 코드를 살펴도 보고, 어떻게 한 것일지 고민도 많이 하면서 해결할 수밖에 없었습니다.
정리하면, 결국 2.와 같은 문제들은 노력을 통해 해결하야하기 때문에 뾰족한 수가 없지만, 적어도 2.를 위해 노력을 쏟을 때 코드의 다른 영역들이 방해가 되지 않도록 효율적이고 깔끔한 코드를 짜는 것이 중요할 것 같습니다.
감사합니다.
개추요^^b
개추 감사합니다~ ?