이번에 리뷰할 논문은 지난 리뷰와 마찬가지로 knowledge distillation에 관한 분석 논문입니다. Knowledge distillation이란 teacher의 예측값을 student의 정답 값으로 사용하여 크기가 작은 모델인 student의 capacity를 증진시키는 방법이라고 할 수 있습니다. 즉, teacher가 예측하는 대로 student 또한 예측할 수 있도록 하는 것이지요. 기존 연구에서는 student를 단독으로 학습시킬 때보다 teacher의 지식을 distill한 것이 더 좋은 성능을 내는 것을 확인하였고, 실제로 model compression 분야에서는 distillation을 통해 large teacher를 small student로 압축하는 방법을 사용하고 있습니다.
그러나 저자들은 distillation을 사용하여 student의 성능이 향상된 것이 정말 distillation에 의한 것인지 의문을 제기합니다. 논문의 제목과 같이 knowledge distillation이 정말 동작하냐는 것입니다.
Introduction
우리가 일반적으로 알고 있고, 많은 backbone논문에서도 언급했다시피 네트워크의 깊이가 증가하면 일반적인 representation을 더 잘 배울 수 있어 좋은 성능을 보여줍니다. 반면에 흔히 small, efficient하다고 하는 경량 네트워크들은 큰 모델 만큼의 성능을 보여주지는 못하죠. 따라서 이러한 작은 모델들의 일반화 성능을 증가시키려는 목적으로 큰 모델(teacher)의 예측값을 작은 모델(student)의 학습에 사용하는 knowledge distillation기법을 사용합니다.
Knowledge distillation은 student가 teacher의 knowledge를 학습에 사용합니다. 즉, student가 teacher의 soft label을 이용해 one-hot으로는 배울 수 없었던 고정밀의 표현을 학습할 수 있게 되어 student의 일반화 성능이 향상된다는 것입니다. 그러나 저자들은 ‘student의 일반화 성능이 향상되는 것’과 ‘teacher의 지식을 잘 배우는 것’을 구분하며 “knowledge distillation에서 student는 과연 teacher의 지식을 습득하고 있는가?”라는 의문을 제기하였습니다. 이에 위의 두 가지의 관점에 따른 평가 지표를 각각 generalization, fidelity라고 설정하여 해당 질문을 실험적으로 검증하였습니다.
기존에는 KD의 성능을 평가하는 지표로 student의 topk accuracy만을 평가하였는데요, 논문에서는 이를 KD의 generalization성능이라 표현하였습니다. 이 논문에서는 추가적으로 fidelity라는 개념을 도입하였는데요, 단순히 가장 높은 확률의 예측값을 고려하지 않고 teacher와 student의 예측이 얼마나 매칭되는지를 고려하고자 teacher와 student의 예측 분포 간의 KL거리를 사용하였습니다.
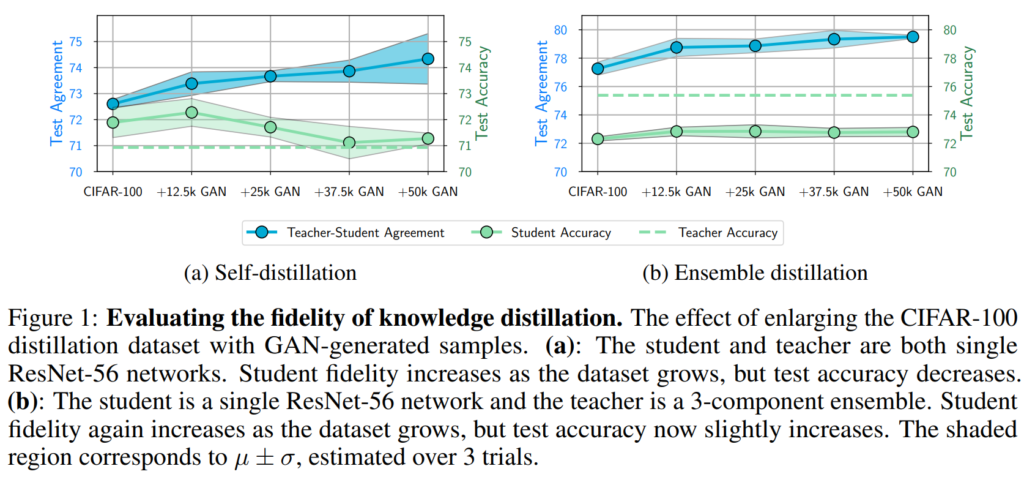
앞서 fidelity란 student의 예측이 teacher와 일치하는 정도라고 설명했었는데요, [그림1]은 fidelity와 generalization을 비교한 실험 결과입니다. 좀 더 자세히 설명드리자면 [그림1(a)]는 student와 teacher가 둘 다 ResNet-56인 상황, 즉, student와 teacher의 capacity가 동일한 상황에서 진행된 실험을 의미합니다. 이때 결과를 보면 data가 증가할수록 test agreement, 즉, fideltiy가 증가하는데 test acc인 generalization이 감소하는 것을 볼 수 있습니다. knowledge distillation이 teacher의 성능을 따라가면 일반화 성능이 좋아짐을 전제로 학습하는 기법인데 실험 결과는 이와 다른 것을 확인할 수 있습니다.
[그림 1(b)]는 teacher가 더 큰 상황으로 resnet56모델 세 개를 앙상블하여 단일 resnet-56에 distill하는 실험입니다. 이 경우에는 (a)와 달리 데이터가 증가할수록 fidelity가 증가하고, generalization또한 소폭 증가하였습니다.
이러한 실험 결과에 대해 저자들은 아무리 학습을 진행해도 fidelity가 80%를 넘지 못했다는 것을 지적하였으며, 그렇다면 이것을 과연 teacher의 지식을 습득했다고 할 수 있는지에 대한 의문을 제기하였습니다.
결과적으로 제목의 “Does Knowledge Distillation Really Work?”라는 질문에 저자들은 student의 일반화 성능이 좋아진다는 관점에서는 distillation이 영향을 주었으니 yes라는 답변을, 그러나 막상 student의 예측을 확인해 보니 teacher의 지식을 제대로 이해하지 못했다는 점에서 ‘distillation’이 잘 동작한 것은 아니다, 즉, no라는 결론을 지었습니다.
본 논문은 일반화 성능에 관심을 많이 갖는 이전 논문들과 달리, ‘student’ 모델의 ‘fidelity’를 향상시키는 것에 초점을 맞추고 있습니다. 또한, 이전 리뷰에서 소개한 학습 기법(mixup, long training time, consistency)들을 적용했음에도 불구하고, ‘fidelity’의 개선이 보이지 않았다고 지적하였습니다.
Metrics and Evaluation
앞서 ‘generalization’과 ‘fidelity’에 대해 언급했었는데요, 각각을 평가하기 위한 metric을 간단히 소개하고 넘어가겠습니다. Generalization 성능은 top1 accuracy, negative log likelihood, 그리고 expected calibration error를 사용하였다고 합니다. ‘Fidelity’의 성능을 평가하기 위해 사용하는 것은 top1 agreement로,teacher와 student가 가장 높은 확률로 예측한 class를 비교하였으며, ‘top 1’ 클래스 외에도 모든 class에 대한 분포를 비교하기 위해 KL divergence도 함께 사용하였다고 합니다. 두 metric을 수식으로 나타내면 아래와 같습니다.
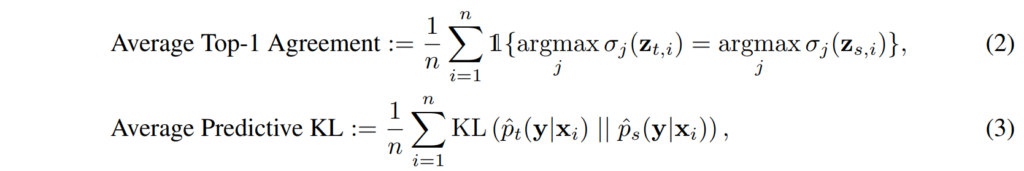
Knowledge Distillation Transfers Knowledge Poorly
이 부분에서는 knowledge distillation이 fidelity를 잘 향상시키지 못한다는 것을 보여주는 실험을 진행하였습니다. 모든 실험에서는 기존에 knowledge distillation을 할 때 사용되는 loss중 아래와 같은 distillation loss만을 사용하였습니다. 즉, student를 학습시킬 때 gt에 의한 supervised를 진행하지 않은 것이죠.
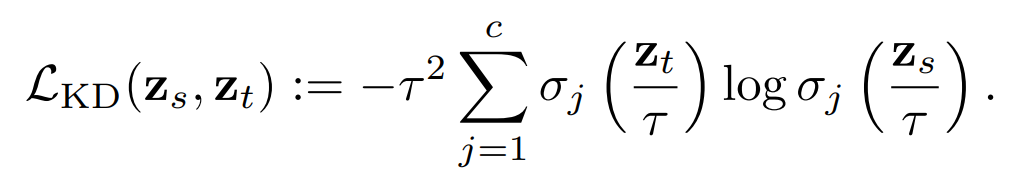
When is knowledge transfer successful?
먼저, 상대적으로 가벼운 모델인 LeNet-5에 대해서 실험을 진행하였습니다. Self distillation,즉, teacher와 student 모두 LeNet-5 구조를 사용했습니다. 이때 teacher의 학습에는 MNIST 데이터를 사용하였는데, 단 200개의 샘플만 사용하였습니다. 데이터가 쉽기 때문에 모든 데이터를 사용하면test accuracy가 99% 이상이 나오기 때문이라고 합니다. 반대로 student에 distillation을 진행할 때는 MNIST의 전체 데이터셋과 EMNIST를 추가로 사용하였다고 합니다.

[그림2]가 해당 실험의 결과는 나타내고 있는데요, 데이터가 많아질수록 ‘fidelity’가 증가하는 경향을 보이고 있습니다. 그러나, 이것이 일반화 성능을 향상시키는 것은 아닙니다.
다음으로는 조금 더 어려운 모델과 데이터에 대해 실험을 진행했는데요, CIFAR-100데이터셋으로 ResNet-56모델에서 실험을 진행하였으며, [그림1]의 (a)에 해당합니다.
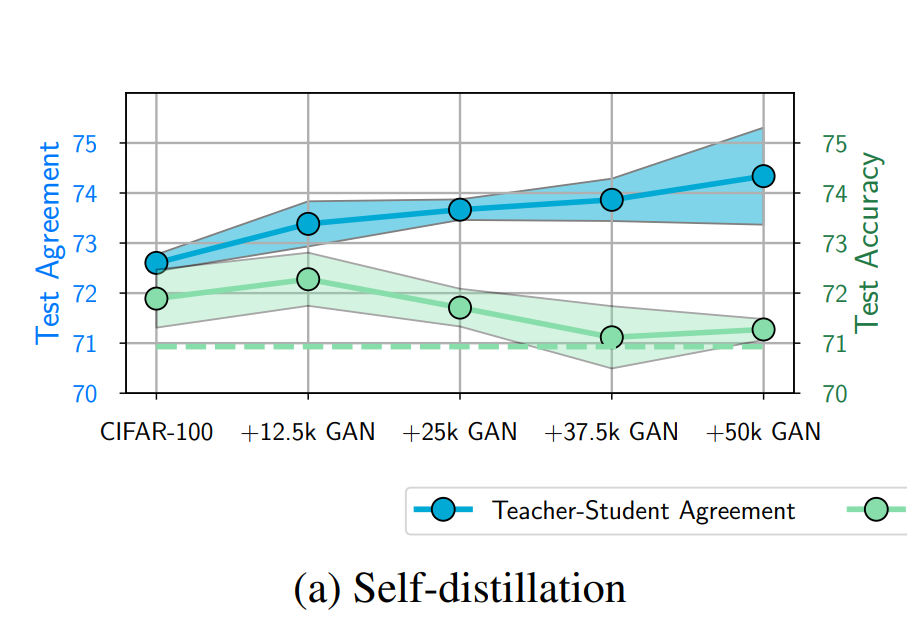
결과를 보면 데이터가 증가할수록 fidelity가 증가하는 것을 볼 수 있으나, student의 일반화 성능이 낮은 것을 확인할 수 있습니다. 이때 주목할 점은 앞 부분에서는 오히려 teacher보다 student의 성능이 좋다는 것입니다.
What can self-distillation tells us about knowledge distillation in general?
논문에서는 위 실험의 결과를 다음과 같이 분석하였는데요, student가 teacher보다 일반화 성능이 높은 것은 distillation이 실패했기 때문에 발생하는 것이라고 합니다. Distilation loss만으로 학습했기 때문에 student가 teacher와 완벽히 matching되었다면, student는 teacher의 성능을 넘을 수 없었을 것이라는 의미입니다.
그러나 위의 결과들은 teacher와 student가 동일한 구조라는 특수한 상황이었고, 일반적인 경우, 즉, teacher가 student를 독립적으로 학습시킨 것 보다 명백히 좋은 성능을 가지고 있으면 fidelity로부터의 이점이 있다고 합니다. 사실상 이것이 KD의 original motivation이죠. 이러한 경향성은 [그림1(b)]에서도 확인할 수 있습니다.
If distillation improves generalization, why care about fidelity?
Knowledge distillation’이 일반화 성능을 향상시킨다면, 왜 우리가 fidelity에 관심을 가져야 하는지에 대해, 저자는 몇 가지 이유를 들어 설명합니다.
첫 번째로, 일반적으로 큰 teacher와 작은 teacher 사이에는 일반화 성능의 차이가 있다는 것입니다. [그림1(b)]와 같이 fidelity의 증가가 teacher와 student간의 일반화 성능을 줄이는 방향이라는 것입니다.
두 번째로, interpretability와 reliability 때문이라고 합니다. Distillation은 large black-box 모델의 representation을 상대적으로 더 해석 가능한 small 모델에 전달하는 것이기 때문입니다. 즉, teacher는 데이터의 구조를 보다 정밀하게 파악할 수 있을 것이라 기대되는데 KD를 통해 student가 well-calibratied uncertainty와 robustness를 얻을 수 있을 것이라 기대되기 때문이라는 것입니다.
세 번째로, ‘distillation’의 원리에 대한 근본적인 접근 방향이 필요하다고 주장합니다.
Possible causes of low distillation fidelity
그러나 지금까지의 실험은 대부분 fidelity가 좋지 않았습니다. [그림1]과 [그림2]를 보면 75~80 정도로, 저자들은 distillation fidelity가 낮게 나오는 원인에 대한 가설을 세우고 이를 검증하고자 하였습니다.
먼저 Identifiability와 Optimization에 관한 가설이 제시되었습니다. Identifiability에 대한 가설은, Student를 학습시킬 때 학습 데이터에 대한 Teacher의 예측 값을 매칭하도록 학습을 진행하였으나, 이것이 Test 데이터에서도 Teacher의 예측을 정확히 맞출 수 있을 것이라는 보장이 없다는 것입니다.
Optimization에 대한 가설은, Test 데이터에서 낮은 성능을 보이는 것을 확인하였는데, 이것이 학습 과정에서부터 Fidelity 매칭이 잘 이루어지지 않았다면, 당연히 Test 데이터에서도 낮은 성능을 보일 수 있다는 주장입니다.
따라서 3번과 4번 가설에 대해서는 다음과 같이 질문을 제기할 수 있습니다. 첫째, Identifiability에 대해서는 우리가 사용하는 학습 데이터가 정말 적합한 것인지에 대한 질문이며, 둘째, Optimization에 대해서는 Student가 Test 데이터가 아닌 학습 데이터에 대해서도 Teacher와 얼마나 잘 매칭하는지에 대한 질문입니다.
Are we using the right distillation dataset?
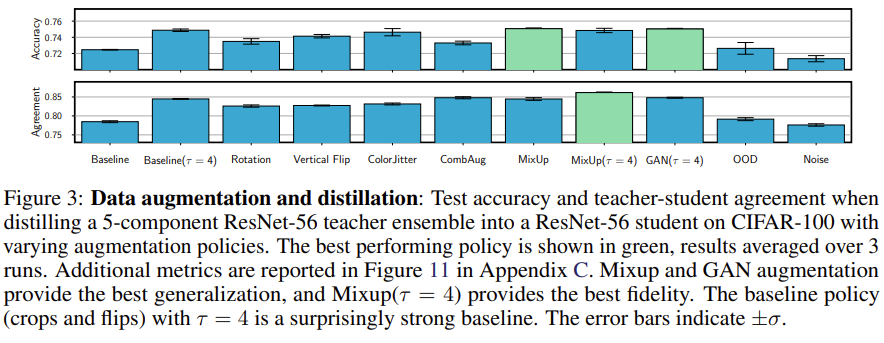
먼저 Identifiability 가설에 대한 검증을 알아보도록 하겠습니다. 적합한 데이터셋을 사용하는 게 맞는지에 대한 질문에 대해서 먼저 충분히 많은 데이터를 사용했는지를 검증을 하였습니다. 이는 Augmentation을 통해서 많은 데이터를 확보하고 이걸 사용해서 실험했을 때 Fidelity가 향상되는지를 결과로 보았는데 Augmentation 방법으로는 기본적인 Flip이나 Crop 외에도 MixUp, CutMix 같은 방법을 사용했습니다. 결과적으로 MixUp이 가장 높은 Fidelity를 보이기는 했지만 이것 역시 Fidelity가 86%밖에 되지 않았습니다.
두 번째로는 데이터 학습에 대한 조합과 관련된 실험이었는데요. CIFAR-10 데이터를 랜덤하게 두 개로 Split을 한 다음에 각각을 A와 B로 칭하겠습니다. 그러면 A 데이터로 Teacher를 학습한 다음에 Student를 A 그리고 Teacher가 보지 못한 데이터인 B 그리고 이 두 개를 다 사용한 A+B 데이터로 학습했을 때의 결과를 살펴보았는데 일반화 성능 그리고 Fidelity 측면에서 모두 이 두 개를 모두 사용한 모델이 좋은 성능을 보였습니다. 그러나 이 역시 Fidelity가 85% 정도밖에 되지 않았다라고 실험적으로 확인을 하였습니다.
결론적으로는 fidelity의 향상을 확인할 수 없었기 때문에 저자들은 identifiability에 대한 가설을 기각하였습니다.
Does the student match the teacher on the distillation data?
마지막으로 Optimization에 대한 가설입니다. 여기서 던지는 질문은 Student Model이 테스트 데이터가 아닌 학습 데이터에도 잘 매치를 하느냐, Teacher와 매치를 하느냐에 대한 질문입니다. 일단 많은 데이터, 다양한 수의 데이터로 수행한 실험 결과는 아래와 같습니다.
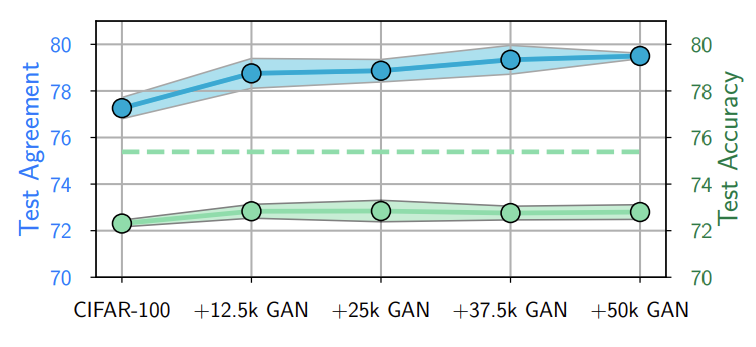
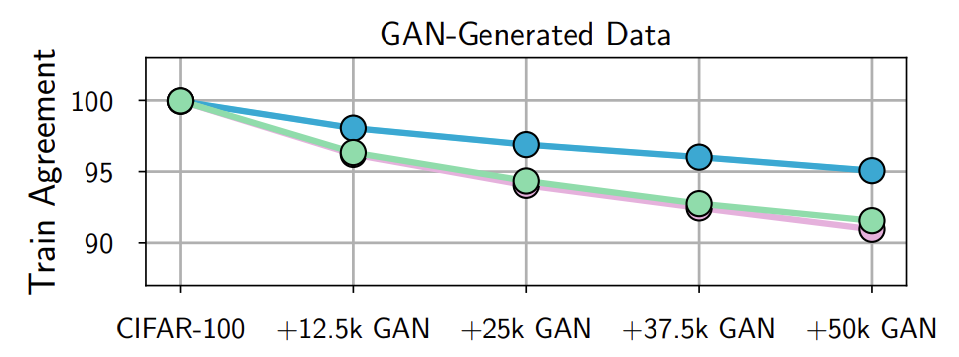
위쪽의 그림은 [그림1(a)]로, test augment를 측정한 결과입니다. Test 데이터에 대해서는 데이터가 많을수록 fidelity가 증가합니다. 그러나 수치가 80%밖에 되지 않는 것을 볼 수 있습니다. 학습 데이터에 대한 Fidelity를 계산 했을 때 아래쪽의 그림과 같이 dataset이 많아질수록 fidelity가 떨어지는 것을 확인할 수 있습니다. 이것이 의미하는 것은 애초에 학습할 때부터 Student가 Teacher의 예측을 잘 매칭하지 못하는, 즉, 최적화가 잘 되지 않는 상황을 시사합니다.