안녕하세요. 스물한 번째 리뷰입니다. 지난 두 번의 리뷰에 이어 Few-shot object detection 논문을 리뷰합니다. 해당 논문은 엄밀히는 처음 리뷰한 LSTD 이후의 논문이지만, 지난 주에는 이번 논문 뒤에 나온 논문을 먼저 소개해드렸었습니다. 그럼에도 이번 논문은 여전히 어려웠지만, 꽤나 많이 자료를 찾아보고 글을 작성하게 되었습니다. 바로 시작하겠습니다.
Introduction
Few-shot의 필요성으로, 여전히 CNN이 수 많은 라벨링된 학습 데이터를 필요로 하고, 그렇기에 라벨링된 데이터가 부족하다면 과적합의 문제와 일반성을 갖기 어려운 문제가 있습니다. 딥러닝에 반하여 사람은, 처음 보는 물체 (Zero-shot) 혹은 한 두번 본 물체 (Few-shot)에 대해서도 해당 객체를 적절히 분류할 수 있는 장점이 있습니다. 앞서 말한 바와 같이 딥러닝도 해당 클래스에 대해 충분한 양의 학습 데이터만 있다면 괜찮겠지만, 멸종 위기 종의 동물, 특정 의학 데이터와 같이 양이 많지 않은, 혹은 라벨링에 비용이 많이 드는 데이터의 경우엔 기존의 딥러닝 모델들이 적절히 대응하지 못합니다.
저자는 이러한 challenging한 Few-shot object detection에 대해 해결하고자 하며, 현존하는 Few-shot classification이 localization을 포함하는 detection에서는 직접적으로 사용할 수 없는 점을 언급하며 새로운 Matching strategy를 소개합니다. 사실 본 논문은 방법론보다는 실험을 자세히 다룰 예정인데, Few-shot의 데이터 설정, 수많은 실험 속 저자가 주장하고자 한 내용이 재밌었습니다. 이전 LSTD 리뷰에서와 다른 점을 눈 여겨 보면, 저자의 말이 충분히 납득될 수 있을 것입니다. Introduction에서 저자의 방법에 대해 흘낏 살펴보자면, 첫 번째는 Base class로부터 Meta feature를 학습하는 모델 (Meta feature learner)로, 다른 클래스의 객체에 대해 일반화된 검출을 위해 설계하였습니다. 다시 해당 모델은 적은 양의 Support set을 활용하여 Meta feature를 추출하고, 해당 feature로부터 Novel class의 중요하고 차별화된 부분을 파악합니다. 이는 Base class의 지식으로부터 Novel class를 이식하는 과정과 유사하다고 생각하면 되겠네요. 다음으로는 Reweighting module로, Support set에 대한 global feature를 얻는 과정을 학습합니다. 그리고선 Meta feature와 Channel attention (Channel-wise multiplication)을 진행하여 Meta feature의 representation을 향상하고, Novel object를 잘 탐지할 수 있도록 돕습니다. 저자가 직접적으로 언급한 Contribution을 살펴본 후, 바로 방법론으로 넘어가도록 하죠.
- We are among the first to study the problem of few-shot boejct detection, which is of great practical values but a less explored task than image classification in the few-shot learning literature.
- Few-shot classification에 비해선 덜 연구되었지만, 실제적인 효용성 측면에서 봤을 때 더욱 연구되어야할 detection에 대한 연구를 진행한 것 자체를 contribution으로 삼았습니다.
- We design a novel few-shot detection model that 1) learns generalizable meta features; and 2) automatically reweights the features for novel class detection by producing class-specific activating coefficients from a few support samples.
- 저자의 방법론으로, Meta feature learner를 설계하여 (lightweight CNN으로 설계했다고 하며, 공간 부족으로 Appendix에 담겠다고 했는데, 없네요? …) Query 이미지의 Meta feature를 학습하고, global feature를 얻도록 학습한 Reweight module과의 channel attention으로 class-specific한 표현력을 얻을 수 있습니다.
- We experimentally show that our model outperforms baseline methods by a large margin, especially when the number of labels is extremly low. Out model adapts to novel classes significantly faster.
- 실험적으로 베이스라인에 비해 월등히 높은 성능을 보이며, Few의 수가 극단적으로 적을 때 (1,3,5)에 특히 성능이 좋았다고 언급합니다. 추가적으로, 뒤의 실험에서 저자가 꼭 말하고자한 부분으로 보이는데, 학습 시 수렴에 빠르다고 말합니다.
Approach
우선 개념 및 용어 정리를 하고 넘어가겠습니다. Few-shot에 대한 관점은 Knowledge라고 불리는 Feature를 어떻게 Generalize한 형태로 만들 것인가에 대해 관심이 있어왔습니다. Generalize Knowledge, 굉장히 추상적인 말입니다. 이는 Knowledge Distilation과 함께 생각하면 좋은데, Teacher 모델의 지식을 Student 모델이 잘 전달받도록 하는 과정이라고 생각하면 됩니다. 다음으로는 Meta-learning입니다. 이전 리뷰 논문은 이런 Meta-learning 관점에서 Few-shot learning을 해결하는데, 이전 리뷰에서 Meta-learning의 세 방식에 대해 다루지 않았으니 본 논문의 Related works에서 다룬 방법론들만 한번 짚고 넘어가겠습니다. 1) Metric Learning based: 분류 대상 이미지와 유사한 클래스의 이미지로 분류되게끔 학습하는 방식 (Matching Networks), 분류 대상 이미지와 몇몇 라벨링된 이미지 간의 거리를 통해 분류하는 방식 (Relation Networks). 2) Optimization for fast adaptaion: classifier가 새로운 few-shot task에 대해 빠르게 수렴할 수 있는 학습 방식 (LSTM), Task-agnostic하게, 몇몇의 gradient를 업데이트하는 방식으로 성능을 올리는 방식 (MAML). 3) Parameter Prediction: One-shot learning을 위해, 각 클래스에 맞는 Parameter를 학습하는 방식 (Learnet).
위의 Meta-learning에 대한 세 관점의 예시를 보았으나, 모두들 “태스크에 상관없이 어떤 태스크가 잘 오든, 특정 태스크에 맞게끔 / Parameter, Gradient 등의 모델 내부적인 요소를 업데이트하는 방식”과 같이, 마치 우리가 SSD를 봤을 때 모델 Architecture만 보고서 “다양한 부분에서 검출을 실행하구나”는 알지만, 막상 conv4_3의 Feature를 Normalize해주고 … 와 같이 모델 내부적으로 들어간다면 직관적이지 않고 추상적으로 느껴지겠죠. 그런 부분에서 Meta-learning을 이해함이 매우 어려운 것 같습니다. 그래도 Meta-learning은 중요한 트렌드이니, 지속적으로 살펴봐야겠죠.
그럼 이제 Base set, Support set, Query set..이라고 용어를 자주쓰게 될 텐데, 짚고 넘어가겠습니다. Few-shot learning이라함은 Unseen 클래스에 대해 잘 분류하고자함이 목적인데, Zero-shot과 같이 해당 클래스의 이미지를 한 장도 안보여주고서 갑자기 이미지를 “사람”으로 분류하라고 한다면, 말이 안됩니다. Zero-shot에서는 클래스와의 관계, 혹은 자연어 등의 추가적인 지식을 통해 해결하며, 우리는 Unseen 클래스에 대해 몇몇의 라벨링된 이미지만 있을 때 (실제에선 이런 경우가 훨씬 많겠죠. 위에서 언급한 멸종 예시종의 동물의 경우, 어쩌면 딥러닝이 실용적으로 사용될 수 있는 태스크로 보임에도 ‘라벨링할 데이터 자체’가 부족하므로, 모델의 성능은 좋지 않을 것입니다) 이것만을 이용해서 새로운 해당 클래스의 새로운 이미지를 잘 분류하는 것 입니다. Unseen 클래스를 분류한다고 해서 혹은 Few-data 클래스를 분류한다고 해서, 아예 모델이 본 적도 없는 것은 아니란 것이죠. (Zero-shot은 아직 저 스스로 받아들이지 못하고 있기에, 추후에 보겠습니다)
그렇다면 학습 과정에서, 우리는 Base set, Support set, Query set이란 용어를 자주 사용합니다. 이는 다른 말로는 Base class, Novel class로도 불리죠. 우선, 전체적인 학습 파이프라인을 아주 큰 관점에서 살펴보자면 Base class, 즉 COCO, Pascal VOC와 같은 대용량 데이터에서 학습을 진행합니다. 이는 모델의 파라미터들이 일반성을 갖고자함이죠. 또한, 이러한 대용량 데이터에서 학습하는 것은 랜덤으로 혹은 Xavier와 같이 초기화된 파라미터들이 어느정도 객체의 특징을 학습할 수 있는 장점이 있습니다. 적어도 classification + localization에서, Edge, Texture와 같은 요소들에 익숙해질 순 있습니다. 이 때 사용하는 데이터를 Base set이라고 부릅니다. (부르는 용어는 논문마다 조금씩 변형하여 부르는 것 같긴 합니다) 이제 Support set, Novel class로 구성된 데이터는 N-way K-shot으로 불리는데, Novel class (Base set에 대해 학습 시 보지 않은 클래스 (Unseen))가 5개의 클래스, 한 클래스 당 10장의 이미지 총 50장으로 구성되어 있다면, 5-way 10-shot learning입니다. Support set의 데이터를 어떻게 잘 학습시킬 것이냐, 혹은 Base set으로부터 학습한 파라미터들이 Support set 이미지를 만났을 때 어떻게 변화하느냐 등의 관점이 Few-shot learning의 주된 해결책들이죠. 이제, Support set과 동일한 클래스의 이미지들이 실제 Inference에 사용되며, 평가를 위해 사용됩니다. 이를 Query set, 또는 Test set이라고 부릅니다. 그렇다면 이제, 정말로 방법론을 살펴보겠습니다.
Feature Reweighting for Detection
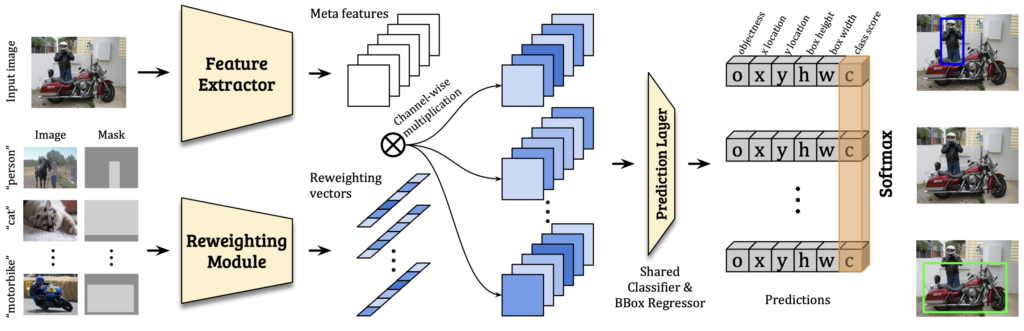
본 논문에서 제안하는 Few-shot detection 모델은 Meta Feature Learner \mathcal{D} 와 Reweighting Module \mathcal{M} 로 구성되어 있습니다. 참고로, Yolo2의 구조를 토대로하는 본 논문은 이후의 방법들과 비교했을 때, One-stage로 구성된 유일한 논문이라고 불립니다. (2022년의 자료라, 그 이후에는 어떤지 잘 모르겠네요) Meta Feature Extractor (learner)는 Darknet-19를 백본으로하는 YOLOv2의 구조를 따랐으며, Reweighting module은 light-weight CNN으로, 몇 개의 레이어만을 설계하였다고 하는데, Supplementary에서 구조를 소개하겠다고 하나 나오진 않아, 단순히 레이어 몇 가지 정도로 구성되어 있다고만 알고 넘어가겠습니다. 그럼 우선, Meta feature learner입니다.
Meta Feature Learner의 역할은 어떻게 입력 Query 영상에 대한 Meta Feature (Meta Feature라 함은, Meta learning에서와 같이 몇 태스크의 Optimal parameter에 빠르게 수렴할 수 있는, Task-agnonstic한 parameter로 이해하면 됩니다)를 뽑고, 그들의 Novel object를 탐지할 수 있을 것인가에 초점이 맞춰져 있습니다. Figure. 1에 나오는 Feature Extractor가 이 Meta Feature Leaner의 역할에 해당하겠죠. Query 영상을 I라고 할 때, Meta Feature Learner를 통해 나오는 Feature, F는 F \in \mathbb{R}^{w \times h \times m}의 형태를 가집니다. 이 때 m은 생성되는 Meta feature map의 개수입니다. (Feature라 칭한 이는 Feature map 개수들을 의미합니다) Support set에서 class 1, ..., N 의 i번째 영상에 대한 bounding box anntation을 각각 I_i, M_i 라 칭할 때, 이제 Reweight Module이 등장합니다. 사실 Meta Feature Learner는단순히 Yolo2의 구조를 따랐을 뿐인데, 왜 본인들이 제안한진 모르겠네요. 아마 해당 모듈으로부터 나온 Feature들을 모아 Reweighting 모듈에 태우고자, 중간단에서 Feature map들을 빼내는, 그 정도를 한 것으로 보입니다.
다음으로 Feature Reweighting Module입니다. 본 논문의 핵심이죠. Reweighting Module (다음부턴 M으로 명하겠습니다). M은 Support image ( I_i, M_i )에 대해 class-specific representation으로 임베딩합니다. 이 class-specfic이라 함은, 이전 리뷰한 MetaDet의 class-agnostic, class-specific과 동일하게, Support image만으로 Query image를 분류해야하니, class-specific한 representation을 잘 임베딩시키는 것이 중요합니다. 정리하자면 해당 임베딩된 Feature의 weight (w)는 다음의 수식으로 부터 나오며 w \in \mathbb{R}^{m}, w_i = \mathcal{M}(I_i, M_i) , 해당 Feature는 Support target object에 대한 global representation을 가지고 있을 것을 기대합니다. 위에서 말했듯이 해당 임베딩된 Feature ( w_i)로부터 M이 시작되는데, w_i 는 class-specific reweighting 계수로써 Reweight Module M의 역할은 class-specific feature F_i 를 F_i = F \otimes w_i 의 수식을 통해 얻습니다.
이제 class-specific feature를 얻었으니, 해당 Feature를 Prediction module \mathcal{P} 에 넣습니다. 해당 module은 prior default box (predefined anchor)에 대해 객체가 존재하는지의 여부 o를 판단하는 값과 bounding box의 offset (x, y, h, w), 그리고 classification score인 c를 모두 추론합니다. 이 때 o와 c의 차이는, 이전 LSTD 논문 리뷰 및 세미나에서 말씀드린 바와 같이 one-vs-one (객체의 존재 이진 여부)와 one-vs-all (클래스에 대한 예측)입니다.
Learning Scheme
Meta Feature Learner와 Reweight Module이 Base set에 대해 학습하기 때문에, 일반화된 좋은 Feature를 뽑을 것을 기대하지만, Few examples에 대해서도 (Support 및 Query) 일반화된 성능을 보장해보고자, 저자는 두 단계로 이루어진 학습 과정을 제안합니다. 이는 우리가 Episode learning으로 알고 있는 여러 태스크로 분리하여 학습하는 과정인데, Base set은 대용량이므로 이로부터 Support set과 Query set으로 분리하는 방식입니다. \theta_D, \theta_M, \theta_P 를 각각 Meta Feature Learner, Reweight Module, Prediction Module의 파라미터라고 할 떄, 각각이 아닌 모든 모듈을 동시에 최적화하는 방향으로 학습하고자, 다음의 Loss를 설계하였습니다.
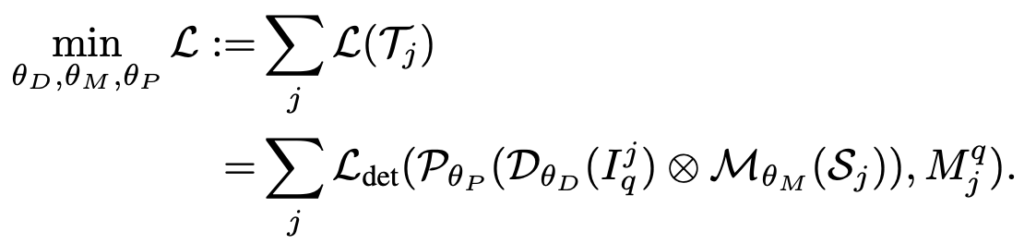
Loss를 살펴보면, 두 단계로 나눠집니다. 우선, Base set으로부터 Few-shot 실험을 만들어 Feature learner 외 두 Module을 함께 학습시키고자 하였습니다. (첫 번째 단계) 두 번째 단게는 Few-shot learning에 대한 디테일로, 해당 단계에서는 Novel class가 K개의 이미지에 대해서만 학습, 즉 K개의 bounding box만을 봤다는 점에 착안하여, Base set과 Novel set의 class balance를 위해 Base set에서도 (Episode 학습 단계에서 적용됩니다) K개의 bounding box만을 사용했습니다. 그렇다면 Base set의 이미지도 적은 양만 사용했다는 것과 같겠네요. 다만, 이렇게 한다면 Base set이 의미가 있을까 싶긴 하지만, 어쨋거나 저자는 위 Feature Learner 이외에도 두 모듈이 함께, 조화롭게 학습해야한다는 점에 중점을 두고 있습니다.
두 학습 단계에서, Reweighting 계수는 랜덤하게 샘플링된 입력 영상에 의존적이게 되는데, 그로 인해 랜덤에 의한 변화성을 낮추고자 한 Episode learning 이후 해당 파라미터를 토대로 다음 Episode learning을 진행하는 것이 아니라, 각각 랜덤하게 샘플링하여 실험한 뒤 Reweight 계수 (Vector)를 평균하는 방식으로 사용했습니다. 그렇다면, 전체 Base set을 학습한 것과 유사한 효과를 볼 수 있고 또한 파라미터를 건드리는 일이기 때문에 (논문 제목이 왜 Feature Reweighting인지 보여주는 것 같습니다), Inference 시에는 해당 모듈을 제거해도 충분하겠죠. 다음은 Detection loss 입니다.
저자는 Few-shot learning의 경우, Meta feature의 역할이 중요하므로 파라미터와 관련된 Detection loss를 신중히 택해야한다고 말합니다. 특히, class prediction의 경우, 샘플의 수가 적기 때문에 그렇다는데, 따라서 단순히 1과 0으로 이진 분류하는 binary cross entropy loss를 사용하면 해당 loss가 detection 결과를 너무 많이 내는 (이 말은 즉슨 해당 객체에 대해 A일 확률을 이진 분류하고, B일 확률을 이진 분류하면 A, B로 둘 다 예측해버린다는 말입니다) 경향이 있기 때문에, N개의 클래스에 대해 하나의 결과만을 내고자 또한, binary loss를 사용하다면 학습 과정에서 positive와 negative 예측을 비슷하게 만드려는 경향이 있었기 때문에 cross-entropy loss를 가져갑니다. 그렇다면 어떤 이는 NMS를 사용하면 되지 않냐?는 질문이 있을 순 있지만, NMS는 클래스 내에서만 이루어지죠. 한 bounding box에 대해 A,B,C 클래스 모두라고 예측해버리면, 소용없습니다.
위의 문제를 해결하고자, 저자는 다른 클래스들에 대한 classification score를 조정하는 softmax layer를 추가하고, detection score가 낮은 class에 대해서는 더욱 더 wrong class로 분류하고자했습니다. 즉, i번째 클래스에 해당하는 실제 classification score는 softmax의 수식으로 나타내어집니다. 이후, 더 나은 학습 과정과 Few-shot detection의 성능을 위해, softmax layer로 조정된 score \hat{c}^{i} 에 대해 다음의 Loss를 따르도록 합니다.
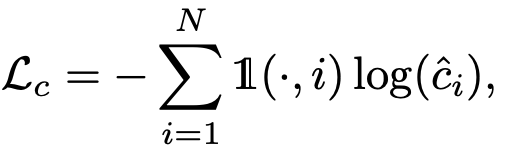
Loss에서 Indicator function은 bounding box가 class i에 속하는지 속하지 않는지를 우선적으로 판단하게 되며, softmax의 도입으로 classification의 score의 합은 1이 되고, 그러므로 위에서 말한 lower classification score에 대해 wrong class임을 학습할 수 있도록 돕습니다. classification loss이외의 bounding box loss와 objectiness score에 대한 loss는 Yolo2를 따랐다고 하니, 해당 Yolo2를 참고하면 될듯합니다. 본 논문에서 따로 언급이 없는 점으로, 중요치 않게 생각하므로 넘어가겠습니다.
Figure. 1을 보면 의아한 부분은 (앞의 부분에서 대부분이 설명되었지만) Reweight module에 Image 외에 Mask를 확인할 수 있는데요, 그럼 이 Mask는 무엇이냐? 생각할 수 있습니다. 방법론의 마지막 부분으로, Reweight module에 어떤 입력이 들어가는지가 핵심인데, 위에서는 Support set에 대해 다루고 있으므로 이미지만을 입력으로 받는다고 말했으나, 실제로는 적은 양에서 Detection을 잘하고자 한다면 LSTD에서 Background Depression (Base set에 대해 bounding box만큼 Feature map 단에서 마스킹을 씌우는) 과 같은 방식으로, 객체에 대해서만 Reweighting을 중요시 가져가고자 bounding box는 interest 영역으로 판단하여 1, 아닌 background는 0으로 마스킹을 씌어 RGB 채널 외에 하나의 채널을 추가하여 입력으로 넣습니다. 뭐, LSTD 세미나에서 잘 설명한 내용이라는 생각이 들어, 넘어가곘지만 이렇듯 Few-shot 관점에서 저자들이 중요시 여기는 점은 “적은 양의 샘플에서, 중요한 영역만 보고 싶은데 자꾸 배경이 가리니 힘들 것 같아 어떤 조치를 취해야겠다”라고 생각했다는 점입니다. 실험을 살펴보죠
Experiments
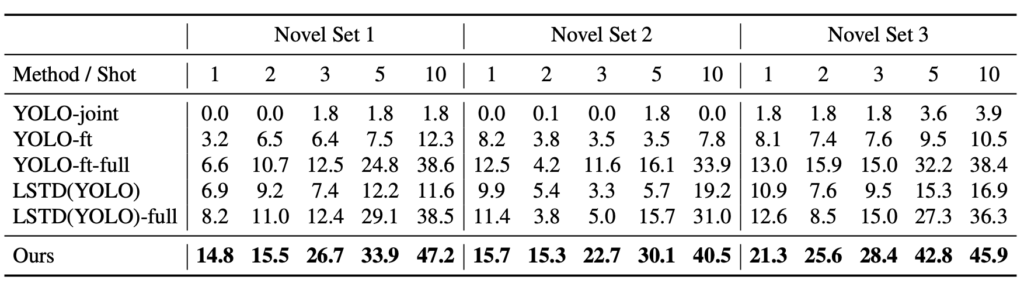
위의 Novel Set은 우선, Few-shot detection 논문이 그러하듯 MS COCO와 Pascal VOC에서 Base set과 Support & Query set의 클래스는 겹치지 않게 하고, 개수를 조정하여 뽑은 Set들입니다. 그러다보니 최근 의구심이 드는게, Support set에서 어떤 이미지가 뽑히고 또한 어떤 클래스가 뽑히고, 더하여 Query Set은 어떤 이미지가 뽑히는지에 따라 mAP가 상이할 것 같은데 (Saturation되지 않았다보니, 사소한 차이도 꽤나 유의미할 것으로 보이는데), 이에 대한 기준 Dataset이나 그런 것이 없다는 점이 참 아쉽습니다. 제 역량만 된다면, 이런 문제점에 대해 짚으며 기존 방법론의 다른 랜덤 샘플링 시의 성능 리포팅 + 샘플링과 상관없이 일반화할 수 있는 Meta-learning 관점에서의 Knowledge transfer 방법론을 내세운다면.. 꽤나 괜찮겠는데 싶습니다. 관심 있으시다면 제가 혼자서 연구할 수 있는 역량이 된 이후 연락바랍니다ㅎㅎ
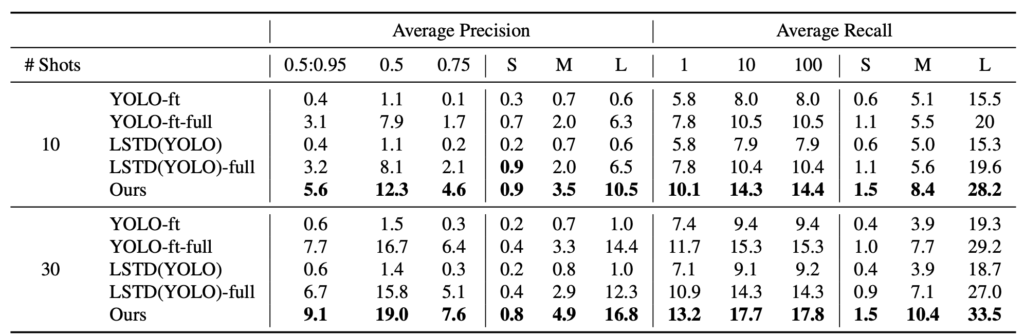
우선, Precision과 Recall에 대한 성능 리포팅입니다. 역시나 이전의 유일한 Few-shot detection인 LSTD의 SSD를 Yolo로 바꾸어 비교하였고, 이 때 YOLO-ft와 YOLO-ft-full은 각각 Baseline으로 삼았는데, Yolo2를 기반으로 하되 Ours와 같은 iteration (Epoch)을 돌았는지, 수렴될 떄 까지 돌았는지로 나누었습니다. 이 점도 중요한데, 뒤에 수렴 속도와 관련한 실험을 살펴보면 저자가 왜 Meta-learning과 같은 기법의 Episode learning을 사용하여 Parameter를 평균한 값으로 사용하였는지, 그런 Meta-Feature를 왜 사용하였는지와 관련합니다. 미리 언급하자면, Meta learning은 Optimal한 파라미터로 수렴하는 속도를 중요시여겼습니다. 성능이 우수한 것은 당연히 좋지만, 아래의 성능에 대한 분석이 조금 더 재미있습니다.
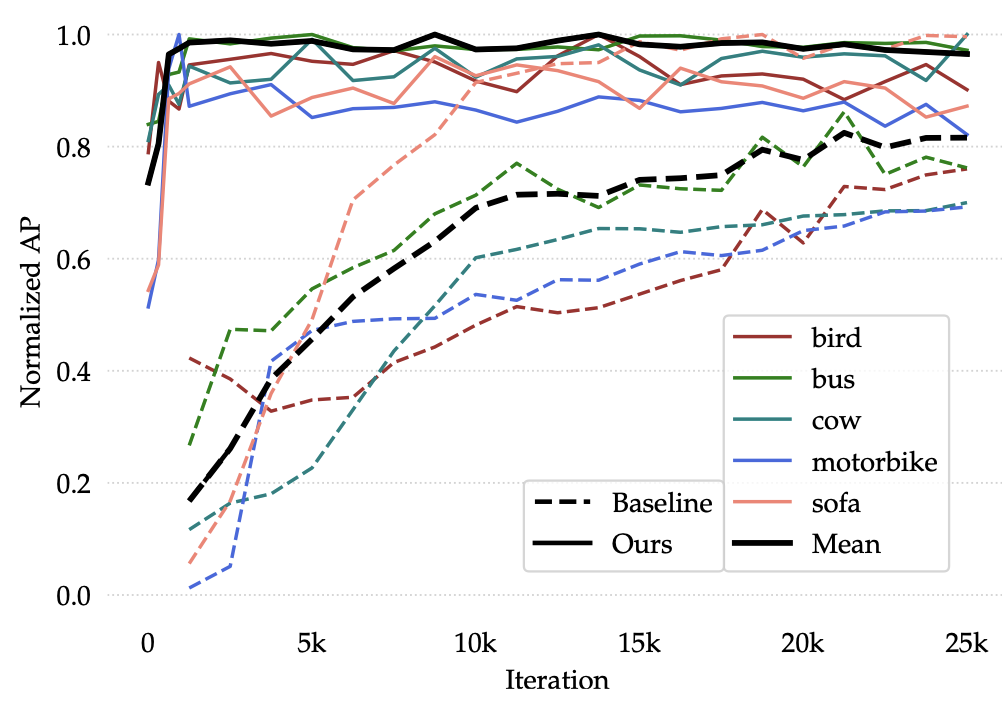
그래프를 잘 살펴보면, 클래스 별 AP가 얼마나 빠른 속도로 수렴하는지가 중요시 여깁니다. 모든 클래스에 대해 AP가 높은 것은 아니지만 (sofa의 경우), 굉장히 중요한 점은 모든 클래스에 대해 Baseline (Yolo2-ft-full)에 비해 수렴 속도가 굉장히 빠르다는 점이죠. 저자는 이 점을 짚으며, 수렴까지 가는 학습 속도도 중요하다고 봅니다. 왜냐하면, 다른 여타 학습 방법과는 달리 Few-shot detection은 적은 샘플 몇가지를 가지고 바로 학습 시켜서 실제 사용하는 것이 Application 측면에서 주 목적인데, 수렴이 오래 걸린다면 Online-deep learning이 힘들겠죠.
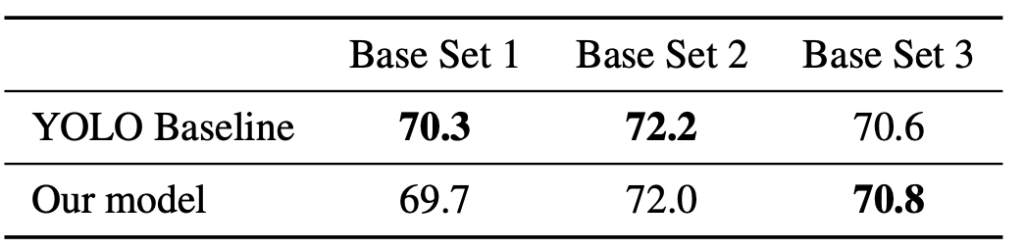
위는 Base set에 대해 Train/Test를 거친 실험입니다. 저는 중요하게까진 보고 있지 않지만, 저자의 말을 빌리자면 Baseline 대비 일반적인 detection 성능도 좋다는 것을 말합니다. 만, 사실 Yolo의 백본 및 구조를 그대로 들고 왔는데, 이 성능이 괜찮다는 것을 언급한 것은 어떤 고찰을 얻을 수 있는지는 모르겠습니다. 다양한 Ablation study를 더 살펴보죠.
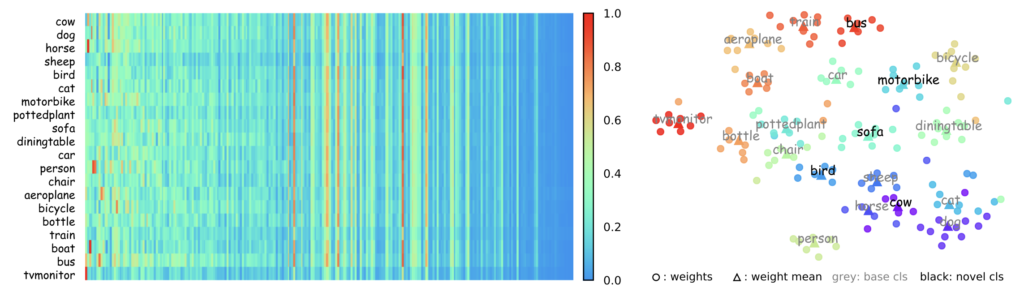
해석하기 굉장히 어려운 그래프입니다. 왼쪽 그래프는 Reweight coefficients를 시각화한 모습으로, 계수는 meta-feature를 어떻게 사용할 것인지를 판단하고 그러므로 detection 성능에 중요합니다. 시각화된 자료를 살펴보면, column들은 Feature를 매핑하여 수로 표기한 것인데 저자는 중간을 기준으로 클래스들이 중간의 왼쪽 부분은 각자 다른 모습을, 오른쪽 부분은 비슷한 모습을 보이는 것을 보아 (왼쪽이 조금 더 클래스를 가로짓는데에 중요히 여겨진 부분), Meta-feature가 적절히 학습되었다는 것을 보여줍니다. (오른쪽이 유사하므로) 이는 왼쪽에 보이는 것과 같이 class-specific한 Feature를 갖도록 수렴하는데 시간이 적게 걸리는 것과도 연관성은 있겠네요 (물론 추론 시간은 현 그래프가 아닌 위의 수렴 속도 그래프를 참고해야하지만)
오른쪽 t-SNE를 살펴보면, Base set과 Novel set을 함께 그린 것인데, 유사한 클래스들끼리 (Aeroplace, train, bus, car, …) 비슷한 클러스터링을 이루는 것으로 보아 Base set으로부터 학습한 Meta-feature parameter들이 본인의 학습 방식으로 인해 잘 학습되었으므로, 이렇게 좋은 성능을 보이지 않았나 설명합니다.
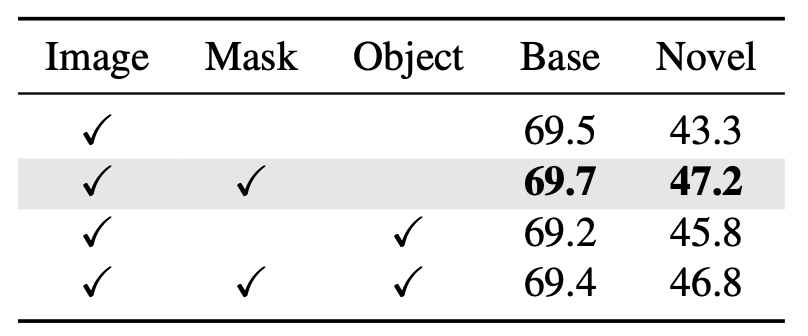
이 실험은 위의 Mask를 씌워 입력으로 하는 Feature Reweight Module과 관련된 실험인데, 재밌는 점은 Object column은 마스킹 씌우지 않고 배경을 아예 없애기 위해 object만 crop하여 입력으로 넣은 것이나, 세 번째 행과 같이 오히려 성능이 하락한 모습을 볼 수 있습니다. 이는 저자의 고찰 그리고 저의 옛 실험에 빗대어 설명하자면, Object 주변의 부분과 연관성을 학습하기 힘들고 또한 Localization이 어려워지는 문제가 있을 것입니다.
이로써 논문 리뷰가 마쳤습니다. 앞으로도 계속 Few-shot detection 논문을 읽고 리뷰하며 이 쪽으로 나아가고 싶습니다. 가장 흥미로워하는 detection과 최근 관심이 깊은 few-shot의 조합에 앞으로의 발전 가능성이 더욱 보여 재밌네요. 그리고 본 논문에서 위의 t-SNE와 같이, 다양한 시각화를 통해 설득력 있는 실험을 보여주는 것이 중요함을 깨닫게 되었습니다. 리뷰 읽어주셔서 감사합니다.
리뷰 잘 읽었습니다.
마지막 실험 table에서 Object Column에 대한 고찰과 관련해서 질문 사항이 있습니다.
뭔가 직관적으로 생각했을때 Object만 crop해서 넣으면 주변 배경과 관련없이, background agnostic 하면서 object만을 보고 학습을 하기 때문에 object specific한 지식을 잘 학습할 수 있을 거 같고, 이는 few shot 적 관점, 그리고 계속해서 배경이 바뀌는 새로운 scene을 보는 관점에서는 도움이 될 거 같은데 이에 대해서는 어떻게 생각하시는지 개인적인 견해가 궁금합니다.
그리고 object crop했을때 성능 하락이 일어난 이유에 대한 저자의 고찰도 궁금합니다. 상인님의 실험적 견해와 동일한가요?
안녕하세요.
해당 Object crop 상황에 대해 질문해주셨는데, 우선 저자의 고찰을 살펴보겠습니다.
“The necessity of the mask may lie in that it provides the precise information about the object location and its context.” 이를 다른 말로 해석하자면 “Crop한 이미지만 넣었을 때는 이미지의 Location, Context Information에 취약해진다”라고 볼 수 있겠는데요, 저의 견해도 일치합니다.
다만 조금 더 고찰해서 어떤 의미인지 생각해본다면, 우리가 Detection이라고 할 때, 실질적으로 Classification도 중요하지만, 그보다도 Detection이라고 하면 역시 Localization입니다. 즉, Object만 Crop해서 넣은 이미지는 어찌 생각해보면 Background의 영향을 덜 받아 Classification에는 도움이 될 수도 있겠죠. 적은 양의 이미지로 특징을 잡아내야 하는 힘든 상황에서, 하지만, Localization 측면에서는 Visual location cue들을 없애는 꼴과 매한가지입니다. 즉, 저의 실험과 빗대어 다시 설명하자면 만약 Pedestrian만 Crop하는데 이 때 모델이 너무 쉬운 상황만 학습하지 않고자 Crop한 영역과 비슷한 크기를 이미지 내에서 잘라 붙이는 Augmentation을 준다 한들, 그때의 Location cue들은 사라진다고 봐야하죠 (실제로 성능 하락이 일어났었고, 해당 고찰은 교수님께서 도움을 주셨습니다). 이런 관점에서, 이미지에 Mask를 씌워 해당 영역에 집중하도록 돕는 것은 Localization 정보를 보존할 수 있으므로 도와 효과적일 수 있다고 생각합니다.
이상인 연구원님, 좋은 리뷰 감사합니다.
이번 주 세미나에서 다뤄주신 내용과 이어지는 내용이라 재밌게 읽을 수 있었습니다. 질문이 있습니다, meta learning이 학습하는 방법을 학습하는 것이고, few-shot이 support set의 적은 데이터만 가지고 학습해서 좋은 성능을 기대하는 것으로 이해되는데, few-shot learning에서 meta learning이 계속 등장하는 것과(구체적으로 어떤 관계가 있는지), meta learning이 정확히 무엇인지 알려주시면 감사하겠습니다. 재밌어 보이는데 낯선 분야라 잘 와닿지가 않네요.
감사합니다.
Few-shot learning에서 Meta-learning이 자주 보이는 이유?에 대해 말씀해주셨는데요,
우선 Meta-learning은 이전 저의 리뷰 http://server.rcv.sejong.ac.kr:8080/2023/09/10/iccv-2019-meta-learning-to-detect-rare-objects/ 를 읽어주시면 좋습니다.
그래도 댓글로 간단히 말씀드리자면, 그리고 재연님의 공부 스타일에 맞추어 설명드린다면, “학습하는 방법을 학습한다”라는 것은 맞는 말이지만 너무 추상적입니다. 저한테도 그렇게 와닿았구요. 실제로도 우리가 Meta-learning을 이해하고자한다면, 많은 블로그와 유튜브를 통해 이해되는 정보들을 합쳐 본인만의 이해를 갖춰야하지 않을까 싶습니다. 우선, Meta-learning은 Model-based, Metric-based, 와 같은 방법이 존재하지만, 최종적인 목표는 “A 태스크에서 학습한 파라미터를, 다른 태스크에 사용할 때 일반적으로 사용할 수 있는 파라미터로 만드는 방법”으로 이해하는 것이 좋을듯합니다.
언뜻 생각해보면 Classification 태스크에서 학습한 파라미터를 사용해 Detection의 Backbone에 붙이는 일과 비슷하다고 볼 수 있지만, 틀린 말이라고 볼 수는 없지만 그보다도 더 Task-specific한 부분까지 붙이는 것을 의미합니다. 단순 Pretrained parameter를 불러오기보다, 전혀 다른 Task에 사용하더라도 수렴까지 빠르게 갈 수 있는, 마치 이차원 그래프에서 Global minima 근처부터 시작하는 파라미터를 만드는 방법이라고 이해할 수도 있곘습니다.
그렇기에 흔히들 “학습하는 방법을 학습한다”라고도 표현하죠. 다른 태스크를 학습할 때 이롭게 작동할 수 있도록 Meta-parameter를 만든다.. 그래도 추상적이네요. 어느정도 이해되셨으면 좋겠습니다.
지나가다가 궁금한 점이 생겨서 질문 드립니다.
그럼 meta-learning 은 결국 저희가 흔히 알고있는 task-specific 과, 완벽하게 generalization이 된 task-agnostic, 이 두 녀석의 중간 포지션을 담당(?), 의미(?) 하는 것인가요?
Meta-learning은 Task-agnostic을 담당하는 것이 더 맞습니다. Task-specific은, 해당 Task에서 해야할 일이죠. 이상적으로 봤을 때 다양한 Task에 일반적인 Parameter가 존재한다면, 각 Task에 적용될 때는 수렴이 빨라질 것이므로 Task-agnostic parameter를 구하는 일입니다.
Meta-learning만 본다면 그렇죠. 하지만 Task-specfic에서, 그러니까 각 Task에 대해 수렴 속도가 느리다면, 요놈또한 Meta-learning의 잘못이니 다시 Task-agnostic한 파라미터를 구하러 숑숑해야겠죠??
안녕하세요 이상인 연구원님. 좋은 리뷰 감사합니다.
지난 세미나에서 한 번 들었던 들었던 내용임에도 생소한 분야인지라 역시 이해하기 쉽지 않네요
질문이 하나 있는데요, 실험 부분에서 3번째 표는 어떤 것을 의미하는지 궁금합니다. base set에 대해 train/test를 거친 것이라고 언급되어 있는데 서로 다르게 분할된 3개의 base set으로 각각 학습한 뒤의 test 성능인가요? 그렇다면 두 모델간의 성능 차가 일관적이지 않은 것 같은데 이는 어떤 것을 보여주고자 하는 지 모르겠습니다.
감사합니다.
세 번째 테이블은 중요하게 보고 있진 않지만, Base set에 대해 train/test 샘플로 나누어 학습 및 평가한 것 입니다. 당연히 성능은 상이할 수 있으나, 해당 표를 잘 살펴보면 저자가 하고자 하는 말은 “현 모델이 일반적인 Detection 파이프라인에서도 잘 작동한다.”는 것을 보여주고 있습니다. 아마 이전 LSTD 논문에서 비슷한 류의 실험을 한적이 있어서, 그것을 따라한듯 하네요.