
안녕하세요, 오늘 리뷰할 논문도 마찬가지로 UDA (Unsupervised Domain Adaptation) 을 수행하는 논문입니다.
Prototype의 개념을 활용하였고, noise가 포함되어 있는 pseudo label 을 denoising하는 기법도 소개하고 있습니다.
논문을 쓴 기관(?)이 Microsoft Research Asia 인 것으로 보아 꽤나 신뢰도 있는 논문일것이라 생각이 드네요. 그럼 바로 리뷰 시작하도록 하겠습니다.
1. Introduction
보통의 UDA 논문들과 Introduction 초반부 내용은 유사합니다.
Real World 에서의 annotation cost가 비싸기 때문에 gt가 존재하는 큰 규모의 Synthetic Dataset으로 부터 정보를 가져 오고자 하는 것이죠.
이때 특정 처리(constraint) 없이 Synthetic Dataset(source) 로 부터 학습된 모델을 Real Dataset(target) 에 단순 적용하게 되면 둘 사이의 domain gap 때문에 모델의 일반화 성능이 떨어지게 되고 성능에서도 상당 수준의 drop이 일어납니다.
본 논문에서는 gt가 존재하지 않는 target domain에서의 segmentation performance를 끌어올리고자 large scale source dataset 으로 부터 domain gap을 해결하면서 풍부한 정보를 가지고 오는 UDA 를 수행하게 됩니다.
기존 UDA 방식에서는 제가 앞선 리뷰들에서도 많이 소개 드렸다시피 adversarial 방식과 self-training 방식이 존재합니다. Adversarial 방식은 source와 target에서 추출된 feature의 분포를 정렬시키는 방식입니다.
하지만 본 논문에서는 self-training 기법으로 UDA를 해결하고자 합니다.
self-training 방식의 UDA 에서는 source에서 학습된 모델에다가 target image를 입력으로 넣어서 pseudo label을 만들게 됩니다. 이때 모든 pixel level 예측을 pseudo label로 사용하는 것은 아니고 특정 threshold 값 이상인 pixel 만을 pseudo label로 채택하게 되는데, 이 때문에 self-training 학습 초기의 pseudo label은 아무래도 예측이 부정확 하기 때문에 매우 sparse하게 되고, 점차적으로 dense 한 pseudo label이 만들어지게 됩니다.
(아래 그림처럼 초기에는 매우 sparse한 pseudo label이 생성됩니다. 학습 초기이기 때문에 대부분의 pixel들이 threshold 값을 넘지 못했기 때문이죠)

하지만 아무리 threshold 값을 기준으로 confidence 가 높은 pseudo label을 만들었다고 한들 target gt가 없는 UDA에서는 아무래도 성능의 upper 한계가 존재하게 됩니다. 설상가상으로 예측한 pseudo label이 100% 정답이라는 보장도 없죠. ,target gt가 없기 때문에 noise가 어느정도 포함되어 있을 수 밖에 없습니다.
저자는 위 내용들을 바탕으로 기존 연구들의 문제점과 함께 self-training 기반 UDA에서 핵심적으로 고려해야 할 점을 2가지 언급합니다.
- self-training based UDA 연구에서 confidence 가 높다고 해서 반드시 올바른 pseudo label은 아니다. 따라서 해당 pseudo label을 곧이곧대로 믿고 학습하게 되면 reliable knowledge를 학습하는 데에 실패할 수 있다.
- source와 target의 domain gap 때문에 모델은 target domain에서 분산된(dispersed) 특징을 생성하게 된다. 그리고 분산된 target feature에서 thresholding 과정을 거치게 되면 아무래도 source domain과 가까운 데이터만 살아남고, 멀리 떨어져 있는 데이터(confidence가 낮은) 는 학습 시에 고려되지 않는다는 문제가 발생한다.
저자는 위의 2가지 핵심 문제점을 언급하며 아래와 같은 방향성을 제시합니다.
우선 각 class 별로 하나씩의 prototype을 계산하게 됩니다. 이는 class-wise feature centroid라고 생각하시면 됩니다. 그리고 pseudo label 예측 시 prototype과의 상대적인 distance를 기반으로 pseudo label을 rectify(수정) 하게 됩니다.
단순하게 threshold 값만 넘었다고 해서 pseudo label로 사용하는 것이 아니라 prototype과의 추가적인 계산을 통해 pseudo label을 수정(or 정제) 하면서 noise를 제거하게 됩니다.
학습이 진행되면서 prototype은 계속해서 EMA 방식으로 update 가 수행되기 때문에, pseudo label또한 계속해서 update가 된다는 것을 알 수 있습니다.
그리고 좀 더 정확한 target feature space를 모델링 하기 위해 soft한 방식의 prototypical assignment 방식을 설계하였는데 이는 method 부분에서 자세하게 설명 드리겠습니다.
2. Method
2.1. Prototypical Pseudo Label Denoising
보통의 self-training 방식에서 pseudo label은 매 iteration마다 update 되는 것이 아닌, computation cost 때문에 특정 iteration(ex. 10000) 마다 한번씩 update 됩니다. 하지만 해당 방식을 그대로 사용하게 될 경우 이미 초기 10000 iteration이 진행되는 동안 noisy한 pseudo label 에 의해 잘못된 방향으로 학습이 진행된다고 합니다.
반면 pseudo label과, 이를 생성하는 model의 weight를 동시에 학습해 나가는 방식은 trivial solution이라고 하네요.
본 논문에서는 noisy pseudo label로의 초기 수렴을 방지하면서, trivial solution도 피하기 위해 pseudo label을 online 방식으로 update 하는 간단하면서도 효과적인 방식을 제시합니다.
보통의 방식들은 pseudo label을 생성할 때 아래 식을 통해 soft prediction을 hard label로 만들게 됩니다. 단순한 argmax 과정이라고 생각하시면 됩니다.
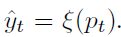
위 방식과 다르게, 본 논문은 클래스별 확률에 따라 점진적으로 가중치(weight)를 부여하여 새롭게 학습된 지식이 점차적으로 반영되도록 합니다.
‘점진적’ 이라는 키워드, 그리고 soft prediction에 weight를 부여한 뒤 argmax를 취하는 과정이 중요하겠네요. 식은 아래와 같습니다.
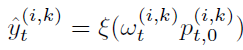
위 식에서 w는 학습이 진행됨에 따라 점진적으로 변경되는 값이며, soft prediction 확률 값에 가중치를 부여하는 역할을 합니다. 그리고 p는 초기 source domain으로 학습 된 모델의 예측으로 초기화 되며, 학습 과정 내내 고정됩니다. p는 고정값이고, w가 학습과정 동안 점진적으로 변경되면서 denoising pseudo label이 생성되는 원리입니다.
(여기서 p를 초기 값으로 고정한 이유에 대해선 저도 좀 헷갈리네요. w도 점진적으로 update 시키고, p 또한 점진적으로 update 시키면 좀 더 빨리 수렴되지 않을까 라는 의문점이 들긴 한데 음,.,, 그래도 뭔가 중요한 이유가 있겠죠,,!!) – (저자는 이후 refinement 과정을 위한 boiler-plate역할을 한다고 말하네요,,)
그러면 위 식에서 weight w 가 어떻게 계산되는 지를 좀 더 자세하게 알아봅시다.
pseudo label을 점진적으로 refinement 하기 위해 prototype과의 distance를 활용하게 되고, 해당 distance를 반영한 것이 가중치 w 라고 보시면 됩니다. 우선 식은 아래와 같습니다.
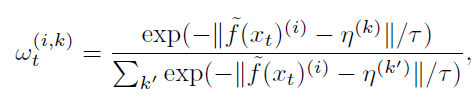
식을 한글로 표현하자면 ‘prototype과 각 pixel level feature 사이의 distance에 softmax’ 값입니다. f(x_t)^i 는 특정 위치 i(x,y) 에서 target image t로 부터 추출된 feature 이고, η^{(k)}는 특정 class k에 대한 prototype 이며 이는 feature x_t 중 class 가 k인 feature들의 중심 이라고 생각하시면 됩니다. 계산 식은 아래에서 다시 나오니, prototype은 특정 class k를 대표하는 하나의 cluster 중심이다~ 라고 이해하시면 될 듯 합니다.
위 식을 통해 feature와 prpototype 사이의 거리값을 활용해서 pseudo label을 점진적으로 수정하게 됩니다. 자세히 보시면 softmax 식 내부의 exp 지수 부분에 – 표기가 된 것을 볼 수 있는데, 위 식에서 만약 feature 와 prototype η(k) 사이의 거리가 멀다면 해당 feature는 noise일 확률이 높게 되고, 이때 weight w 값은 작아지게 됩니다. denoising을 weight w 를 통해서 진행하는 것이죠.
그리고 위 식에서 f(x_t)^i 를 잘 보시면 f 위에 ~ 표기가 있는 것을 볼 수 있는데 이는 Moco 논문의 momentum encoder 라고 합니다.
Prototyep Computation
위의 weight w를 점진적으로 update하기 위해선 prototype 을 점진적으로 update 해 줘야 합니다. 이를 논문에서는 on-the-fly 방식이라고 언급하고 있고, Moving average 방식을 사용합니다.
우선 이를 위해 초기 initialization 과정을 수행해 줘야 하는데 이는 아래의 수식을 통해 진행됩니다.
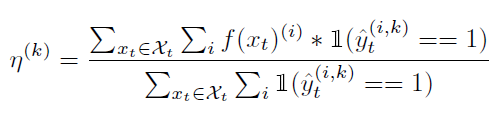
\hat{y_t}^{(i,k)} 는 초기 예측된 pseudo label 을 의미하며, \mathbb{1} 은 0 or 1을 return 하는 indicator function 입니다. class 가 k인 pixel 위치에서의 feature vector의 평균이라고 생각하시면 됩니다.
하지만 이러한 prototype의 계산은 학습과정 중에 computational intensive 하다는 문제가 존재합니다. 모든 학습 이미지에 대해 feature를 추출하고, class 별로 prototype을 계산하면 그것이 진정한 학습 데이터를 대표하는 prototype은 맞지만, 이는 computation cost 적인 관점에서 말이 안됩니다.
그래서 이를 해결하고자 mibi batch 내에서 cluster의 중심을 moving average 방식으로 점차적으로 update 하며 천천히 prototype을 아래 수식을 통해 update 하게 됩니다.
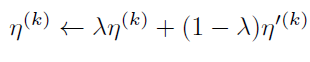
η^{'(k)} 는 현재 mini-batch에서 계산된 class k에 대한 prototype이고, \lambda 는 0.9999 를 사용합니다.
Pseudo Label Training Loss
점차적으로 update 되는 pseudo label을 사용해서 cross entropy loss를 계산하게 될텐데, 본 논문에서는 이 대신 symmetric cross-entropy (SCE) 이라고 하는 loss를 사용한다고 하네요. 학습 초기의 noise로 부터 좀 더 강건한 학습이 가능하다고 하며, 식은 아래와 같습니다.
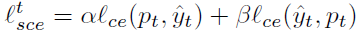
alpha와 beta는 각각 0.1, 1 을 사용하게 됩니다.
Why are prototypes useful for label denoising?
우선 prototype을 사용하게 되면 class-unbalance 문제에 강건합니다. 왜냐면 class가 자주 등장하던, 드물게 등장하던 관계 없이 class 별로 하나의 prototype만 생성하기 때문입니다. 그리고 prototype을 통해 pseudo label을 refinement 하는 본 논문의 장점을 잘 나타내 주는 그림을 첨부하겠습니다.

결국 정확한 pseudo label이라 함은 class A(파랑) 와 class B(주황) 를 정확하게 나누는 결정 경계(회색 점선) 을 그어야 합니다. 하지만 (a) 의 좌측을 보시면 결정경계가 target domain의 class A 의 거의 정중앙을 가로지르는 것을 볼 수 있습니다. 잘못된 결정 경계이죠.
반면 (a)의 우측은 완벽하지는 않지만 조금 더 성공적으로 결정 경계가 생성된 것을 볼 수 있습니다. 이는 pseudo label을 생성할 때 weight를 prototype과의 distance 계산을 통해 부여한 본 논문의 방식을 통해 이루어 진 결과입니다. 결정경계 주변에 있는 녀석들은 prototype과의 거리가 상대적으로 멀리 떨어져 있으므로, weight w의 값이 낮게 책정됩니다. 이 덕분에 pseudo label refinement가 이루어 진 것이죠.
그리고 이러한 방식을 통해 점차적으로 prototype 또한 실제 real cluster 중심에 가까워 지게 됩니다.
2.2. Structure learning by enforcing consistency
추출한 target domain의 feature가 매우 compact 하고 각 class별로 오밀조밀한 cluster를 형성한다면 성공적으로 pseudo label의 noise 가 제거될 수 있을 것입니다. 하지만 domain gap에 의해 실제 추출되는 target domain feature는 위 그림의 우측 (b)와 같이 분산된 형태로 예측되게 됩니다. 이러한 경우에는 성공적인 denoising이 이루어 질 수 없기 때문에 본 논문에서는 target domain 의 structure 를 학습하도록 모델을 설계합니다. 음,,, structure를 학습한다는 것이 완벽하게 와닿지는 않네요.
어쨋든 이를 위해 최근 unsupervised learning에서 영감을 받아 clustering과 representation learning 을 동시에 수행하도록 설계 했다고 합니다. 이를 위해 입력 이미지 x_t에 각각 weak augmentation \tau(x_t) 와 strong augmentation \tau'(x_t)를 적용한 뒤 각각에 대해서 아래 식을 수행하게 됩니다. 아래 식은 2.1 절에서 weight w를 구하는 식과 동일한데, f의 입력으로 들어가는 값이 x_t => \tau(x_t) 로 변경 된 것입니다.
아무튼 weak augmentation \tau(x_t) 와 strong augmentation \tau'(x_t) 에 대해 각각 z_{\tau} 와 z_{\tau'}을 구하게 되고 이에 KL Divergence loss를 계산하게 됩니다.
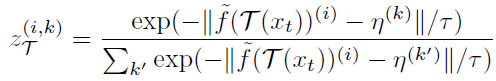
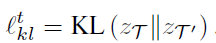
사실 제가 위 과정에 대해 정확하게 이해한 것은 아니라 조금은 설명이 부족할 수도 있습니다.
위 식을 통해 동일 이미지에 대해 weak aug와 strong aug를 부여하고 이로부터 계산된 prototype assignment weight z_{\tau},z_{\tau'} 를 구하게 됩니다. 이 둘은 결국 동일 이미지로 부터 비롯되었기 때문에 aug의 강도가 세던 약하던 관계없이 동일한 결과를 도출하도록 KL loss를 부여한 것입니다.
그리고 결국 모델이 인접한 특징점에 대해 일관된 prototype label을 부여하도록 하여 target domain에서의 feature space를 compact 하게 만드는 역할을 하게 됩니다.
위 kl loss만 사용하게 될 경우 특정 class에서의 prototype이 퇴화(degeneration) 될 수도 있으므로 이를 방지하는 loss term을 추가하여야 합니다.
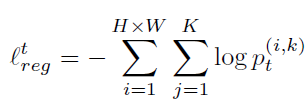
그리고 이를 적용한 최종 loss는 아래와 같습니다.
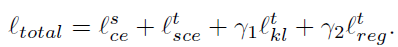
3. Experiment
본 논문은 ResNet-101 을 백본으로 하는 DeepLabv2 모델을 사용합니다.
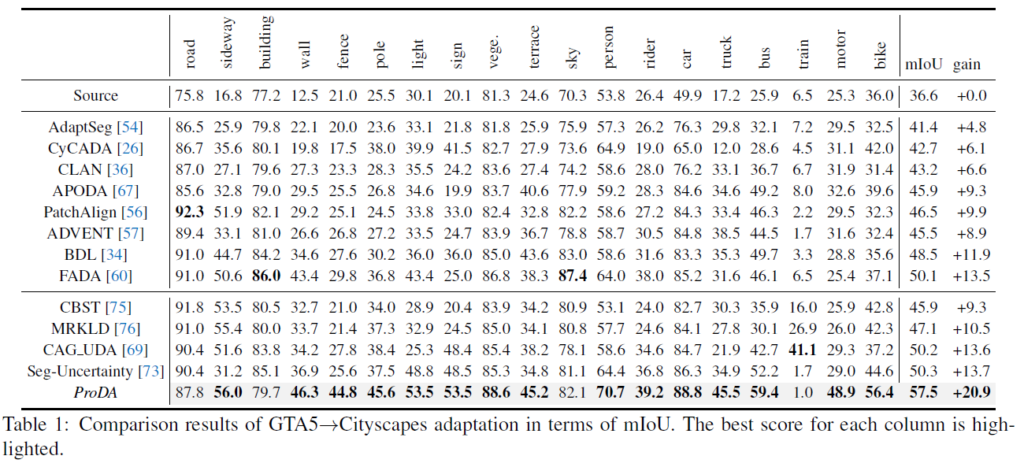
위 실험은 Synthetic Dataset인 GTA5를 source로, Real Dataset인 Cityscapes Dataset을 target으로 했을 때의 성능을 리포팅 한 결과입니다.
우선 제일 위 row인 Source는 Source domain에서 학습한 모델에 추가적인 UDA 과정 없이 단순 target image를 입력으로 넣었을 때의 결과입니다. lower bound 이자, UDA 적용 전의 성능이라고 보면 되겠죠.
본 논문에서 설계한 ProDA가 전체 19개 class 중 15개 class에 대해 최고 성능을 달성한 것을 볼 수 있습니다.
특히 hard class인 fence, terrace, motor 등의 class에서의 성능 향상폭이 인상적인데 이는 prototype이 제 역할을 톡톡히 했다고 볼 수 있습니다. 위 3개 class들은 등장 빈도가 매우 낮은 class인데, prototype은 class의 빈도와 관계없이 class별로 하나의 prototype을 생성하기 때문에 class unbalance 문제를 해결하는 데에 효과적이라고 합니다.
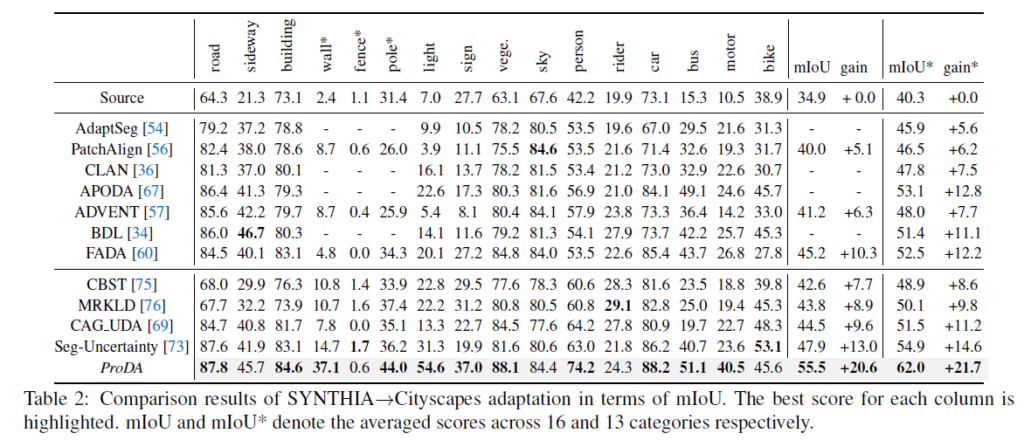
또한 SYNTHIA -> Cityscapes dataset으로의 UDA 에서도 기존 대비 매우 큰 폭의 성능 향상을 보여주고 있습니다. 해당 실험에서도 위와 유사하게 hard class에 대한 성능 향상 폭이 꽤나 높네요.
아무래도 gt가 없는 상황에서 pseudo label을 생성할 때 car, road 등 쉬운 class 보다는 hard class에서 더 confidence 가 낮고, noisy한 예측을 수행하기 마련인데, prototype 기반의 pseudo label refinement 전략이 잘 통한것을 알 수 있네요.
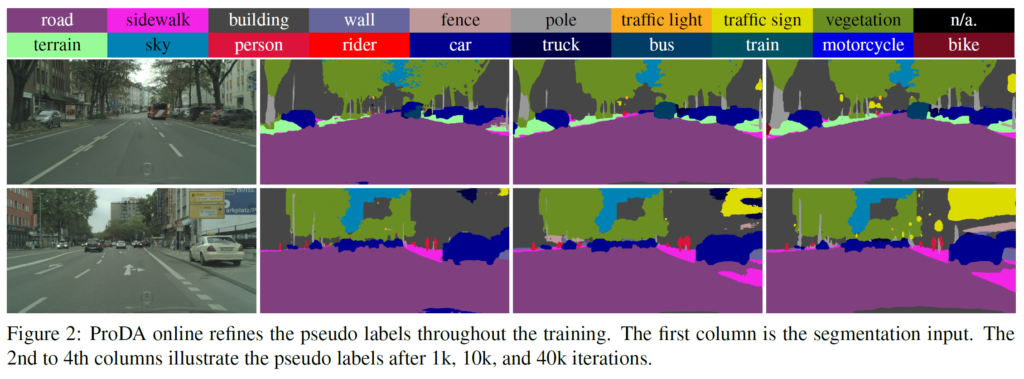
그리고 위는 정성적인 실험 결과입니다.
첫번째 column은 입력 이미지이고, 2~4번째 column은 학습이 진행됨에 따라 각각 1k, 10k, 40k iterations 에서의 pseudo label을 시각화 한 결과입니다. 점차적으로 pseudo label refinement가 수행된 것을 볼 수 있는데 특히 전봇대, 표지판 등 작은 class 에서의 noise가 제거되는 것을 볼 수 있습니다.
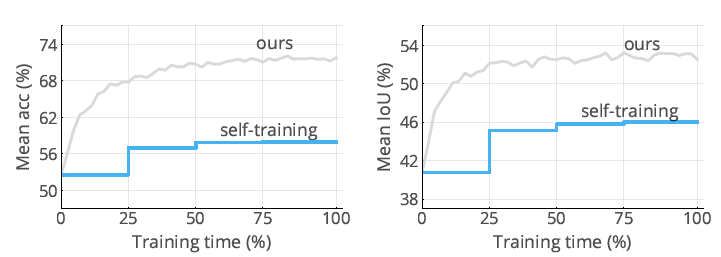
그리고 위는 pseudo label의 성능을 보여주는 성능 결과 그래프입니다.
좌측은 mACC, 우측은 mIOU 인데, 기존 self-training 기법 대비 훨씬 더 정확한 pseudo label 이 생성되네요.
사실 pseudo label refinement, 그리고 prototype이라는 키워드만 보고 호기롭게 덤볐다가 생각보다 너무 어려워서 호되게 당한 논문이였습니다..
그래도 얻은 점이라고 하면, prototype 을 기반으로 pseudo label을 정제할 수 있다는 점, 그리고 정제 과정에서 distance 기반으로 weight를 부여해서 noise를 완화해 주는 기법 또한 적용할 만한 가치가 있다는 점이였습니다.
제대로 된 이해를 위해서 몇번은 더 정독이 필요할 거 같네요..ㅠ
아직 완벽히 이해하기엔 제 수련이 부족한 거 같습니다.
그럼 리뷰 마치도록 하겠습니다. 감사합니다.
안녕하세요. 좋은 리뷰 감사합니다.
prototype이라는 단어가 굉장히 많이 나와서 집중해서 읽었는데 저의 한계로 인해서 헷갈리는 부분이 있습니다. prototype이란 것을 사용하는 방법론이 원래부터 존재하던 건가요? 아님 이 방법론에서 처음 사용한 것인가요? 그리고 prototype이란 게 어떻게 계산되는 것인지 잘 와닿지 않아서 헷갈리는 것 같습니다. prototype은 이미지마다 구할 수 있는건가요? 구할 수 있다면 어떻게 해서 구할 수 있는 걸까요? 제가 놓치는 부분이 있나 싶어 계속 읽어봤지만 그래도 헷갈려 질문 드립니다.
감사합니다.
prototype은 초기 n-shot learning을 수행하는 task들에서 처음 등장한 후, 본 Domain Adaptation 분야에도 등장하기 시작했습니다. 해당 논문이 처음은 아닙니다.
segmentation gt에 대해 생각해보시면 자동차, 사람, 자전거 등의 class가 pixel 별로 annotation 되어 있는 것을 알 수 있습니다. 본 논문에서 말하는 prototype은 ‘각 class의 대표 역할을 하는 embedding vector’ 라고 생각 하시면 되며, 각 class 별로 하나씩의 prototype이 만들어지게 됩니다.
예를들어, 480×640의 해상도를 가지는 이미지에서 자동차를 나타내는 pixel들의 정보를 가지고 있다가 이를 feature map에 적용해서 자동차에 대한 prototype을 생성해내게 됩니다.
이러한 prototype은 각 이미지별로 구할 수 있긴 하지만, 최대한 dataset 전체 정보를 포함하는 global한 prototype을 구하고자 이미지별로 prototype을 생성하지는 않고, batch 단위로 계산한다거나 혹은 본 논문처럼 EMA 방식을 사용해서 점차적으로 update 해 나가는 방식을 사용할 수 있습니다.
안녕하세요 권석준 연구원님.
리뷰 잘 읽었습니다.
궁금한 점으로 pseudo label을 곧이 곧대로 믿어선 안된다고 말하는데, 그렇다면 prototype이 이를 해결할 수 있단 식으로 말씀해주셨는데, prototype이 pseudo label에 비해 신뢰성이 높은 이유가 단순히 psuedo label에 대한 noise를 제거할 수 있기 때문인가요? 그렇다면 EMA는 어떤 것인지 간단한 설명 부탁드립니다
엄밀히 말하면 prototype 의 도입만으로 pseudo label의 noise를 해결해주는건 아닙니다. pseudo label이 부정확하다면, 해당 pseudo label을 사용해서 생성되는 prototype 또한 noise 가 존재하게 되죠.
본 논문에서는 pseudo label, 그리고 prototype의 noise를 제거하기 위해 가중치 w를 점진적으로 update 하는 방식을 모델링합니다.
그리고 EMA 그 자체의 정의는 ‘지수이동평균’ 으로 이전 time에서의 평균을 함께 고려해서 현재 time의 평균을 구하는 방식으로 알고 있습니다.
이렇게 점진적으로, 그리고 이전 time의 값을 반영해서 현재 time의 값을 update 해 나가는 방식은 prototype 을 계산할 때에 적용되며, self-training 분야에서 꽤나 많이 등장하고 있습니다.
예전 세미나에서도 질문을 드렸던 것 같은데
1. Prototype이 Cluster랑 굉장히 비슷한 개념인 것 같은데 둘의 차이가 궁금하네요.
2. 위의 설명을 읽어보면 동일 category 내에서 prototype도 결국에는 category에 대한 평균을 나타내는 것 같은데 이것이 맞는지 확인 부탁드립니다.
1. cluster의 중심을 prototype 이라고 생각하시면 될 거 같습니다.
다만 기존 저희가 알고 있는 cluster 라는 개념은 데이터가 어떤 class이든 상관없이 distance 기반으로 군집을 형성했다면, 본 논문과 UDA 방식에서 사용하고 있는 prototype이란 동일 class k 를 나타내는 데이터끼리 군집을 형성했을 때 해당 군집의 중심을 나타내는 것입니다.
각 class의 대표라고 생각하시면 편합니다.
2. 음.. category가 class와 동일하다는 가정 하에 설명을 드리자면,,,
맞습니다. 결국 pixel-level로 자동차, 사람 등등 class 정보가 할당되어 있을텐데 각 class별로 feature vector들의 평균으로 계산하면 됩니다.
예를들어 200x200x512(H,W,C) 라는 feature map에서 자동차를 나타내는 pixel이 40000개 중 10000개라면 자동차 class의 prototype 은 10000×512 의 평균(dim=0)으로 계산해서 1x1x512 차원의 vector 인 것입니다.
좋은 리뷰 감사합니다.
prototype과의 거리를 고려하는 w를 통해, 업데이트되는 prototype이 매번 가중치의 형태로 반영이 되는 것으로 이해하였습니다.
혹시 pseudo label을 학습할 때, symmetric cross-entropy (SCE)를 이용하는 이유에 대해 초기 noise로부터 강건한 학습이 가능하다고 하셨는데 symmetric cross-entropy의 어떤 점이 초기 noise에 강인하게 해주는 지 알고계시면 설명해주실 수 있나요?
또한, p는 초기값으로 고정하고 업데이트 하지 않는다고 하셨고, refinement 과정을 위한 boiler-plate역할을 한다고 하셨는데 이게 어떤 의미인지 설명해주실 수 있을까요?
symmetric cross-entropy (SCE) 는 [ICCV 2019] Symmetric cross entropy for robust learning with noisy labels 논문에 소개된 방식인데, 사실 제가 처음 들어보는 loss인지라 정확히 설명드리기는 어려울 거 같습니다.ㅜ
그리고 boiler-plate 음,,, 이건 저도 정확히 내포된 의미를 파악하지 못하여 논문의 내용을 그대로 직역해 놓긴 했습니다. 아마 boiler-plate는 뭔가의 기초가 되는 ‘골격’, ‘틀’ 이라는 의미를 가진 것으로 보아 초기 값으로 고정하게 되는 p가 boiler plate, 즉 기초 틀이 되고 해당 틀에 점차적으로 weight w를 반영해서 점진적 update가 수행된다는 의미인 거 같습니다.
안녕하세요 권석준 연구원님 좋은 리뷰 감사합니다.
UDA라는 분야 자체가 잘 모르는 분야이기도 해서… 나름 정리하며 읽어 보았습니다.
1. gt가 없는 target 도메인에서 semantic segmentation을 수행할 때 gt가 있는 source도메인에서 학습된 모델에 target 데이터를 입력하는 방식으로 진행되는데, 이때 source와 target간의 domain gap에 의해 성능 드랍이 발생하며, 이를 방지하기 위해 UDA를 수행합니다.
2. self-training방식의 UAD는 target 중 높은 confidence score로 예측된 pixel의 예측값을 psudo label로 지정하여 source의 gt + target의 psudo label로 모델을 재학습시킵니다.
3. 그러나 이러한 방식에는 두 가지 문제점이 존재하는데, 하나는 psudo label의 신뢰도 문제이고, target데이터 중 source에 가까운 쪽으로 편향된다는 것이다.
4. 본 논문에서는 이러한 문제점을 해결하기 위해 각 class 별로 prototype을 생성하고, psudo label을 예측할 때 prototype과의 거리를 고려하는 방식을 제안하였다.
5. psudo label을 구할 때 초기 모델에서의 예측값인 p를 고정하고 weight를 곱하여 구하는데, weight는 각 feature에서 protptype까지의 거리에 softmax를 취해준 값이다.
6. prototype은 각 클래스 별로 하나씩 생성되기 때문에 클래스의 빈도 수에 따른 noise를 절감하는 효과가 있다.
리뷰를 읽다보니 간단한 궁금증이 있는데요, 일반적인 self-training 방식에서는 일정 iter마다 psudo label의 업데이트가 일어난다고 하셨는데, 논문의 방법의 경우 매 iter마다 업데이트가 발생하는 것인가요?