안녕하세요. 오랜만에 ERC(Emotion Recognition in Conversation) 논문을 들고와봤습니다. COLING은 익숙하지 않은 학회일텐데 NLP 학회 중 하나입니다. 이번 논문은 제목이 재미있어 가져와봤는데요. emotion의 shape이라니,, 뭔가 구미가 당기지 않습니까..? 그럼 리뷰 시작하도록 하겠습니다.
<1. Introduction>
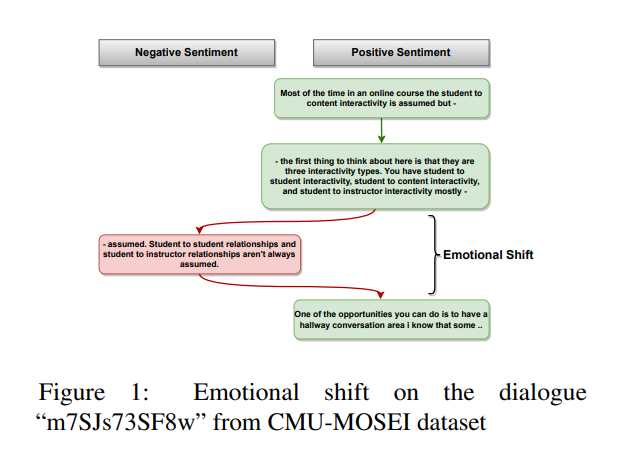
사람은 대화하는 동안 다양한 감정을 표현하고 여러 감정 상태를 오갑니다. 대화에 참여하는 사람들은 어떠한 자극으로 인해서 변화를 일으키지 않는 한 특정한 감정 상태를 유지하는 경향이 있다고 합니다. 이러한 관찰은 유명한 작가인 Kurt Vonnegut (Vonnegut, 1995)가 제안한 Shapes of Stories와 밀접한 관련이 있는데, Vonnegut는 모든 이야기에는 이야기의 등장인물이 경험하는 기복에 의해 그려진 형태가 있으며, 이것이 이야기의 감정적 아크(Emotional Arc)를 정의한다고 가정합니다. 이러한 현상은 약 13000개의 스토리를 분석하여 다양한 스토리에서 공통적인 감정적 아크 패턴을 도출한 Reagan(2016)에 의해서 경험적으로 검증되었습니다. 그런데 이러한 흐름과는 별개로 긍정적인 감정에서 부정적인 감정으로 감정의 급격한 전환이 존재하는 경우가 있는데요. Figure 1을 보시면 세 번째 발화의 감정이 긍정에서 부정으로 바뀌었다가 네 번째 발화에서 다시 긍정으로 바뀌는 것을 볼 수 있습니다. 본 논문에서는 현재의 SOTA 방법들은 이러한 감정 변화의 존재를 인식하지 못하는 경우가 많고, 감정의 상태가 갑작스럽게 변하는 경우 감정 인식에 실패하는 경향을 보인다고 말합니다. (Poria et al., 2019) 이러한 문제를 해결하기 위해서 본 논문에서는 대화에서 이러한 감정 변화를 명시적으로 추적하는 새로운 모듈을 제안합니다. 사람은 언어, 목소리의 변화, 얼굴 표정, 몸짓 등의 다양한 방식으로 감정을 표현하는데요. 본 논문에서는 인간의 감정을 정확하게 인식하기 위해서, language, audio, video modality를 사용하여 감정 인식을 수행합니다. 이에 서로 다른 모달리티의 정보를 융합하는 GRU 기반의 멀티모달 ERC(Emotion Recognition in Conversation) 모델을 제안합니다. 독립적인 emotional shift의 component는 연속된 발화 사이의 emotional shift signal을 포착하여 모델이 감정 변화 시 past information을 잊어버릴 수 있도록 합니다.
본 논문의 contribution을 정리하면 아래와 같습니다.
- We propose a new deep learning based multimodal emotion recognition model that captures information from text, audio, and video modalities.
- We propose a novel emotion shift network (modeled via a Siamese network) that guides the main emotion recognition system by providing information about possible emotion shifts or transitions. The proposed component is modular, it can be pretrained and added to any existing multi-modal ERC (with a few modifications) to improve emotion prediction.
- The proposed model is experimented on the two widely known multimodal emotion recognition datasets (MOSEI and IEMOCAP), and results show that emotional shift component helps to outperform some of the existing models
<2. Related Work>
여러 모달리티를 사용한 감정인식은 활발한 연구 분야인데요. 최근 연구에서는 대화의 emotional dynamics에서 자아의 중요한 측면과 대인관계의 의존성을 강조하였습니다. (Poria et al., 2019). 또한 감정 인식 system에서 local, global context의 역할을 강조하였는데요. 그 중의 예로 Dialogue RNN은각 화자를 party state로 각 발화의 감정을 emotional state로 모델링하여 local context를 사용하고자 하였고, global conversation context를 모델링하기 위해 context state를 추가로 사용하였습니다. 또 다른 연구인 MUltilogue-Net은 Dialogue RNN에서 사용된 fusion machanism의 한계를 강조하고 각 모달리티에 대한 party, context, emotion GRU를 사용하여 이를 해결하고자 하였습니다. 계속해서 party라는 단어가 등장하는데요. 잠시 설명을 드리자면 여러 사람이 함께 대화하는 상황을 multi-party라고 하고 여기서 party는 대화에 참여하고 있는 사람을 의미합니다. 이렇게 이해하고 위의 문장을 다시 보시면 Multilogue-Net은 대화에 참여하고 있는 사람의 정보, context, emotion GRU를 사용하여 fusion machanism의 한계를 극복하고자 하였다고 볼 수 있습니다. 계속 이어서 설명하겠습니다. 이 모델은 모든 모달리티에 대한 emotion state를 효과적으로 사용하기 위해서 pairwise attention machanism을 사용하였는데요. 그러나 DialogueRNN에서는 감정이 긍정적 감정에서 부정적 감정으로 전환되는 발화에서 감정에 대한 예측 성능이 좋지 않다는 점을 강조합니다. 본 논문에서는 대화에 존대하는 감정 변화(emotion shift)를 고려하고 이를 활용하여 감정 인식을 수행하는데요. 또 다른 연구로는 여러 모달리티를 결합하기 위해 multimodal transformer기반 모델을 사용하여 MOSEI 데이터셋의 sentiment task에서 SOTA를 달설한 Transformer-based Joint-Encoding (TBJE)이 있습니다. 그런데 TBJE의 경우 emotion task에서 Multilogue-Net 모델 보다 성능이 떨어지는데요. 논문에서 강조한 이유로는 TBJE가 현재 발화에 대한 감정을 예측하기 위해 이전 발화나 다음 발화를 사용하지 않기 때문에 architecture에 context-awareness가 부족해 성능이 좋지 않다고 합니다. 멀티모달 감정인식 분야에서 다른 연구로는 multi-view gated memory를 사용하여 multimodal sequence를 align하는 Memory Fusion network(MFN)이 있고, Dynamic Fusion Graph (DFG)를 사용하고 n-modal interaction을 동적으로 모델링하는 법을 학습하는 Graph-MFN, contextual information을 capture하기 위해 LSTM 기반의 모델을 사용하는 bc-LSTM이 있습니다. emotion classification의 성능을 높이기 위해 CRF 모델을 사용하여 발화에서 emotional consistency를 포착하는 CESTa는 emotional shift를 활용하려는 본 논문의 아이디어와 근접한 부분이 있습니다.
<3. Task and Corpus>
<Problem Definition>
발화($u_1, …, u_N$)가 있는 대화를 예를 들어보면, Emotion Recognition in Conversation (ERC)의 목표는 각 발화 $u_t$의 감정을 예측하는 것입니다. 본 논문에서는 발화를 주어진 시간에 한 명의 참가자가 전달한 일관성 있는 정보(coherent piece of information)(single 또는 multiple sentece일 수 있습니다)라고 정의합니다. 본 논문에서는 발화를 다양한 모달리티 관점에서 모델링하는데요: $u_t = {l_t, a_t, v_t}$. time-step $t$에서 발화$(u_t)$는 화자의 텍스트 transcript$(l_t)$, audio$(a_t)$, visuals$(v_t)$로부터의 feature로 표현됩니다. 또한 발화 $u_t$의 화자를 $q_t$로 표현하도록 하겠습니다.
<3.1 Corpus Details>
<3.1.1 CMU-MOSEI>
CMU Multimodal Opinion Sentiment and Emotion Intensity (CMU-MOSEI)는 1000명 이상의 화자와 250개 topic에 대해 65시간 이상 annotated된 비디오가 표함된 영어 데이터셋인데요. 각 문장은 [-3, 3] Likert scale로 sentiment에 대해 annotation되어 있습니다. 그러나 본 논문에서는 이러한 label을 0보다 큰 값은 positive sentiment를, 0보다 작은 값은 negative sentiment를 나타내는 twocalss classification으로 project하였습니다. 또한 데이터셋에는 각 발화에 대해 angry, happy, sad, surprise, fear, disgust에 대한 label이 포함되어 있습니다. 주의해야할 점은 multi-label이라는 점입니다.
<3.1.2 IEMOCAP>
IEMOCAP 벤치마크는 10명의 서로 다른 화자 간의 대화로 구성되는데요. 이 데이터셋은 모든 video clip이 하나의 dyadic english dialogue(쌍방향 영어 대화)를 포함하는 video의 양방향 대화가 포함되어 있습니다. 또한 각 대화는 happy, sad, neutral, angry, excited, and frustrated 등 6가지 emotion label을 가진 발화들로 세분화되었습니다.
<4. The Proposed Model>
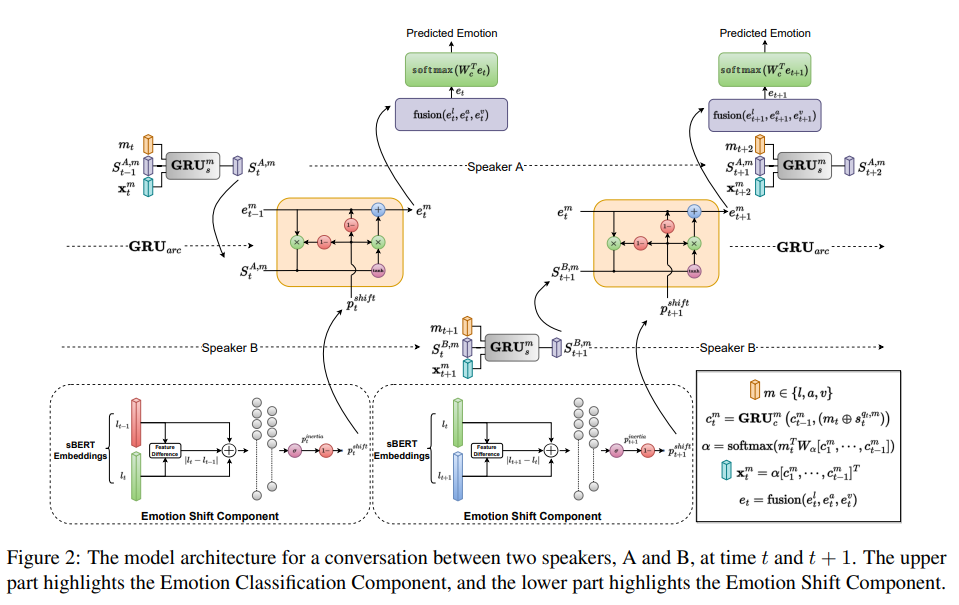
앞에서 언급했듯이 대화하는 동안, 감정 state의 감정 flow를 유지하려는 경향이 있습니다. 이러한 상태는 주로 전체 대회의 맥락에 따라 달라지는데, 예를 들어, 화자의 주제에 대한 전반적인 요지가 긍정적이라면, angry, sad와 같은 부정적인 감정보다 happyiness, joy, surprise와 같은 감정이 더 자주 나타날 수 있습니다. 또한, 화자의 감정은 대화에 존재하는 과거의 감정에 영향을 받는 경우가 많은데요. 따라서 emotion prediction model은 문맥을 고려해야할 뿐만 아니라 과거 발화에 나타난 감정과 함께 speaker-level수준의 정보도 유지할 수 있어야 합니다. 이러한 가정을 고려하여, 본 논문에서는 emotion recognition model의 주요 구성 요소인 Emotion Classification Component를 제안합니다. emotion classification component는 현재 화자, 이전 발화의 감정, 전체 대화 context에서 얻은 정보를 사용하여 발화의 emotion label을 예측합니다. 또한 대화에서 감정에 대한 또 다른 중요한 insight는 emotion state의 갑작스러운 변화(shift)인데요. 기존의 많은 SOTA의 접근 방식은 error analysis에서 모델이 감정 상태의 갑작스러운 변화를 포착하지 못해서 prediction이 잘못 분류되는 경우를 강조합니다. 갑작스러운 감정 변화 효과를 통합하기 위해서 본 논문에서는 별도로 학습된 component인 Emotion Shift Compoent를 도입하였습니다. emotion shift component는 발화 $u_{t-1}$과 $u_t$ 사이에서 감정이 바뀔 확률 $(p_t^{shift})$를 명시적으로 모델링합니다. 이러한 감정의 변화는 연속된 발화 사이에 긍정적인 감정(예: happy)에서 부정적인 감정(예: sad)로 또는 그 반대로 이동하는 것으로 표현될 수 있습니다. emotion shift component는 기본 architecture와 독집적으로 pretrained되며, 갑작스러운 감정 변화가 발생할 시, 과거에서 미래로의 information flow를 컨트롤하는데 도움이 됩니다. pretrained된 emotional shift component의 sigal은 emotion classification component에 추가되어 과거에서 미래로의 emotional flow를 컨트롤 합니다. Figure 2를 통해 디테일한 모델의 세부 architecture를 확인할 수 있습니다.
<Emotion Classification Component>
대화에서 감정을 모델링하기 위해 party state, emotion state, context state를 유지합니다. spaker state는 각 화자에 대해 유지되며 대화에서 참가자의 특정 측면을 추적하는데 도움이 되는 state입니다. context state는 global (각 참여자에게 공통)하며, 전체 대화 context를 encoding하여 발화간 dependency를 파악하는데 도움이 됩니다. context state와 마찬가지로 emotion state도 global하며 발화 간 감정의 흐름을 활용하는데 도움이 됩니다. 또한 현재 발화와 이전 발화 사이의 emoption shift signal은 global emotion state를 업데이트하는데 사용됩니다. 그런 다음 emotion satae를 decoding하여 각 발화의 emotion label을 예측합니다. 본 논문의 모델에서는 각 party, context, emotion state는 모달리티에 따라 다르며, 각 모달리티 $m \in {l, a, v}$에 대해 모달리티별 GRU network를 사용하여 업데이트합니다. 본 논문에서는 late fusion을 사용하여 다양한 모달리티의 emotion state를 합칩니다. 다음으로 모델에 사용된 GRU network에 대해 설명드리도록 하겠습니다.
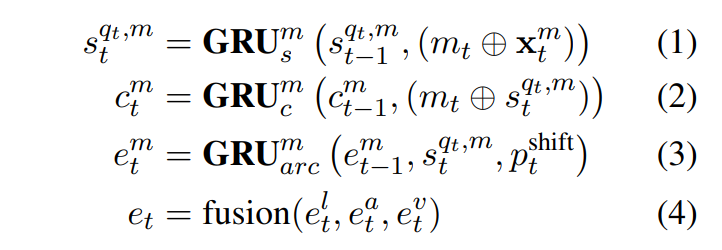
- Party State Update $(GRU_s)$: 각 참가자의 state는 party state update $GRU_s$로 모델링 됩니다. 각 모달리티 $m \in {l,a,v}$에 대해, attention vector $x_t^m$과 modality specific feature $m_t$를 이용하여 $q_t$의 party state $s_{t-1}^{q_t, m}$이 $s_t^{q_t, m}$로 업데이트 되며, $⊕$는 concatenation operation을 나타냅니다. 여기서 $x^m_t$는 context state ($c^m_t$)에 대한 간단한 dot product attention machanism을 사용하여 계산됩니다. $q_t$를 제외한 모든 화자의 경우 t-1과 t의 party state는 동일하게 유지됩니다.
- Context Sate Update ($GRU_c$): global conversation context는 context state update $GRU_c$를 사용하여 모델링 됩니다. 각 모달리티 $m \in {l,a,v}$에 대해, global context state $c^m_{t-1}$은 $q_t$의 party state $s_t^{q_t, m}$과 대응하는 모달리티 feature m_t를 이용하여$c_t^m$로 업데이트 됩니다. context states$ (c_1^m, …, c_1^{t-1})$은 다음과 같이 각 모달리티 $m \in {l,a,v}$에 대한 attention vector $x_m^t$를 계산하는데 사용됩니다.
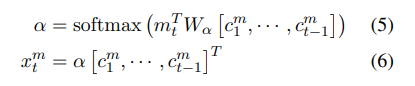
- Emotion State Update ($GRU_{arc}$): 각 모달리티 $m \in {l,a,v}$에 대해, global emotion state $e^m_{t-1}$은 현재의 aprty state $s_t^{q_t, m}$를 사용하여 $e_t^m$로 업데이트 되고, emotion shift component ($p_t^{shift}$)에 의해 모듈화 됩니다. 세 가지 모달리티 모두에 대한 emotion state를 fuse하여 pairwise attention mechanism을 사용하여 $e_t$를 생성합니다. $e_t$는 나중에 발화에 대한 emotion class를 decoding하는데 사용됩니다.
emotion classification component는 Multilogue-Net과 같은 이전연구와 유사한 context-aware 모델이지만 몇가지 주요 차이점이 있습니다. 첫 번째, 각 참여자의 대한 emotion state를 모델리하는 대신 각 대화에 대한 global emotion sate를 사용합니다. 이는 발화 사이의 감정의 흐름을 활용하기 위해서 입니다. 두 번째, 현재 발화와 이전 발화 사이의 emotion shift signal ($p_t^{shift}$)는 대화에서 emotion arc를 모델리하은 것을 목표로 하는 $GRU_{arc}$를 이용하여 global emotion state를 업데이트하는데 사용됩니다.
<Emotion Shift Component>

대화 전반에 걸친 emotional erc를 포착하기 위해, 연속된 발화 ($u_{t-1}$과 $u_t$) 사이의 emotion shift probability($p_t^{shift}$)를 명시적으로 모델링합니다. 본 논문에서는 발화 전반에 존재하는 emotion shift를 모델링하기 위해 Siamese network(Bromley et al., 1993)를 사용하였습니다. Siamese network는 일반적으로 parameter와 weight를 공유하는 동일한 구성을 가진 두 개 이상의 동일한 subnetwork로 구성됩니다. 제안된 emotion shift architecutre는 현재 ($l_t$) 그리고 이전의 ($l_{t-1}$) 발화의 textual feature를 취하여 emotional ineria(감정적 관성) ($p_t^{inertia}$)를 유지할 확률을 output으로 가집니다. emotion shift prediction entwork는 Figure 2의 하단에 나와있는데요. 위의 그림을 참고하시면 됩니다. 본 논문에서는 Sentence-BERT (SBERT) (Reimers and Gurevych, 2019)의 embedding을 textual feature로 사용합니다. SBERT는 pretrained된 BERT network를 수정한 것으로, Siamese network를 사용하여 transfer learning task를 위해 semantically 의미있는 sentence embedding을 도출합니다. emotion shift prediction은 두 가지 이유로 text 모달리티만 사용하는데요. 첫 번째, text, audio, video 모달리티 중에서 text 모달리티가 ERC task에 더 많은 정보를 전달한다는 사실이 경험적으로 밝혀졌다고 합니다. (Poria et al., 2018) 두 번째, 세 가지 모달리티를 합치는 ealry fusion techniques는 유사한 vector가 가까운 vector 공간에 fused modality vector를 mapping하기 때문에 Siamese type architcture에서 어려울 수 있다고 합니다.
($u_t$와 $u_{t-1}$ 사이에) emotion shift prediction network는 발화 ($l_t$와 $l_{t-1}$)에 해당하는 text feature와 해당 element의 difference를 받아 [식 7]과 같이 shift의 probability를 output합니다. 여기서 $p_t^{inertia}$는 Siamese network [식 8,9]를 이용하여 계산됩니다. 여기서 $H_t$는 Siames hidden sate이고 $W \in \mathbb{R^{3d_l}}$은 모델 parameter입니다. Siamese network의 경우, 분포 $p_t^{shift}$에 대한 Binary Cross Entropy loss($L_s$)을 사용합니다. emotion shift component는 $p^{shift}_t$를 통해 emotion state $GRU_{arc}$를 모듈화하여 대화 중 정보의 흐름을 컨트롤합니다. emotion shigt component는 발화에서 감정적 일관성(emotional consistency)를 포착하며, 대화에서 emotion recognition을 개선하기 위해 몇 가지 수정을 통해 pretraing하고 기존의 multi-modal ERC framework에 추가할 수 있는 독립적인 모듈식 구성요소로 작동할 수 있습니다.
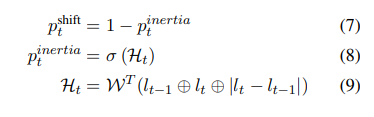
<Overall Architecture>
자, 이제 방법론 설명을 마무리 하겠습니다. 본 논문에서 제안된 architecture의 motivation은 감정이 바뀔 경우(shift될 경우) 이전 emotion state의 contribution을 고려해야 한다는 직관에 따른 것입니다. 즉, 높은 $p_t^{shift}$가 있을 때, $e_t^m$의 계산에서 $e^m_{t-1}$의 영향을 줄어야 한다는 것입니다. 이렇게 하기 위해서, 대화의 emotional arc를 모델링하는 GRU에서 reset 그리고 update gate, 즉, $GRU_{arc}$를 수정합니다. GRU에는 unit 내부의 정보 흐름을 modulate하는 gating unit (reset and update gate)가 있습니다. Ravanelli et al. (2017)은 sequence에 상당한 불연속점이 존재하는 시나리오에서 reset gate의 유용성을 언급하며 정보를 forget하는데 reset gate가 중요한 역할을 가진다는 것을 말하였습니다. 또한 Ravanelli et al. (2017) 연구에서 speech sequence를 처리할 때 reset gate와 update gate의 activation에서 중복성이 있음을 발견하였다고 합니다. 이에 착안하여, 감정이 바뀔 확률이 높을 때 더 많은 정보를 forget 해야 한다는 직관에 따라 reset gate와 update gate 모두에 ($1 – p_t^{shift}$) 값을 직접 사용합니다. $GRU_{arc}$의 update는 [식 10, 11]에 의해서 계산됩니다. [식 10]은 이전 emotion state의 ($e^m_{t-1}$)이 emotion shift signal에 의해 제어되는 후보 emotion state $e_t^{~m}$를 계산합니다. output $e_t^m$은 $e_t^{~m}$와 $e^m_{t-1}$ 사이의 linear interpolation 입니다. 위에서도 말했지만 $p_t^{shift}$는 $e^m_{t-1}$의 영향을 컨트롤하는데요[식 11]. 따라서 $p_t^{shift}$의 값이 높을수록 이전 emotion state의 contribution이 제한됩니다. emotion shift compunent가 없는 경우, GRU gate는 모델의 나머지 parameter와 마찬가지로 classification data만 사용하여 학습됩니다. 본 논문에서는 대부분의 딥러닝 모델처러 모델의 총 parameter의 수가 많으면 gate가 제대로 학습되지 않을 수 있음을 언급하며, 본 논문의 방법론은 emotion의 shift를 모델링함으로써 이러한 gate의 학습을 개선하였음을 확인하였다고 합니다.
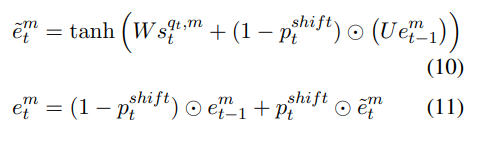
time t에서의 prediction을 위해, ([식 4]에서 설명한대로 $e_t^m$의 fusion으로 형성된) emotion vector $e_t$는 최종 classification layer $W_c ( \in \mathbb{R^{d_e \times {K}}}$를 통과하며, 여기서 K는 emotion class 수 입니다. 이는 softmax activation을 통해 emotion lable에 대한 probability distribution을 구하는데 사용됩니다: o = $softmax(W_c^T e_t)$. 본 논문에서는 Cross-Entorpy를 사용하여 모델을 학습시킵니다.
<5. Experiments and Reulsts >
<Multimodal Emotion Corpora>
앞에서 설명드린 것처럼 본 논문에서는 두개의 벤츠마크인 CMU-MOSEI와 IEMOCAP을 사용합니다. 간단히 다시 설명드리자면, 두 벤츠마크 모두 세 가지 모달리티로 구성되고 있으며 MOSEI과 IEMOCAP 모두 6개의 emotion labeling이 되어있습니다.
<Emotion shift in Dataset>
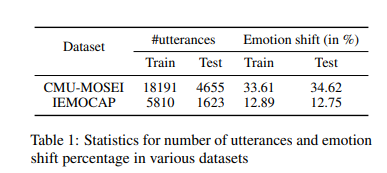
본 논문에서는 긍정적인 감정에서 부정적인 감정 또는 그 반대의 경우 연속된 발화 사이에 emotion shift가 있는 것으로 정의하였습니다. CMU-MOSEI 데이터셋의 경우, 각 발화에 대해 annotated (positive/negative) sentiment label을 제공하는데요. IEMOCAP 데이터셋의 경우 그렇지 않기 때문에 emotion class를 positive와 negative로 나누었습니다. happy와 surprise는 positive category에 속하고 disgust나 angry, sad는 negative category에 속합니다. IEMOCAP에는 중립적인 감정도 있지만, 긍정적인 감정에서 부정적인 감정 혹은 그 반대의 경우만 계산하였다고 합니다. Table 1은 데이터셋에서 관찰된 emotion shift의 비율을 보여줍니다.
<5.1 Reulsts>
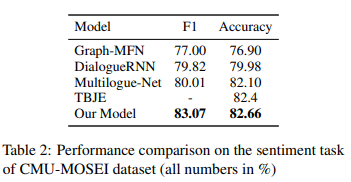
Table 2는 sentiment label에서 본 논문의 방법론이 SOTA를 달성했음을 보여줍니다. 결과에서 알 수 있듯이 본 논문의 방법론의 F1 score가 3%로 이전 SOTA를 크게 능가했음을 알 수 있습니다.
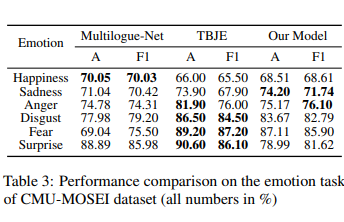
Table 3는 emotion task에서 CMU-MOSEI 성능을 확인한 것인데요. 일부 감정 class에서는 본 논문의 방법론보다 다른 모델의 성능이 높게 나온 것을 확인할 수 있습니다. 성능이 좋지 않은 이유는 본 논문에서는 CMU-MOSEI 데이터셋의 multilabel setting 때문이라고 하는데요. emotion label이 multilabel이기 때문에 emotion shift component가 emotion classification compoent의 성능을 향상시키는데 의미 있는 역할을 할 수 없다고 합니다.
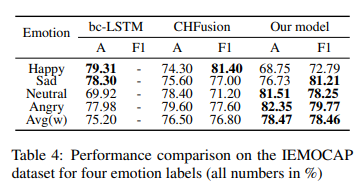
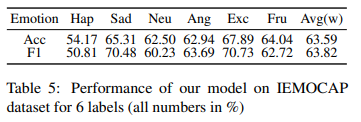
IEMOCAP에서 이전의 SOTA 모델들이 4개 감정(angry, happy, sad, neutral)에 대해서만 성능을 보였기 때문에 이 4가지 감정에 대해서 비교하였다고 합니다. Table 4에서 성능을 확인할 수 있습니다. 본 논문의 방법론이 average weighted F1과 Accuracy 모두 크게 성능 향상을 이룬 것을 확인할 수 있는데요. 또한 6가지 emotion label에 대해서도 성능을 Table 5에서 확인할 수 있습니다.
<Performance of emotion shift component>
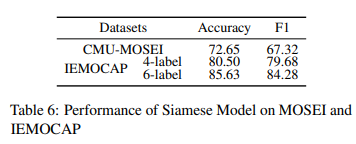
emotion shift compoent의 CMU-MOSEI, IEMOCAP 데이터셋에 대한 성능은 Table 6을 통해 확인할 수 있는데요. emotion shift를 정확하게 예측하는 것이 주요 목표는 아니라는 것을 유의하고 봐주시면 되겠습니다. 본 논문의 objective는 emotion shift component에서 받은 signal ($p_t^{shift}$)를 사용하여 emotion prediction을 개선하는 것입니다.
<6. Analysis and Ablation Studies>
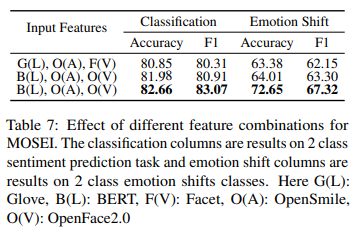
<Feature and Design choices>
서도 다른 모달리티에 사용되는 feature의 중요성을 이해하기 위해 text와 visual 모달리티에 대해 서로 다른 두가지 feature set을 선택하였다고 합니다. 한 설정에서는 text의 경우 averaged Glove embeddings을 오디오의 경우, OpenSmile feature을, 비디오의 경우 Facet feature를 선택하였습니다. 다른 설정에서는 text 모달리티의 경우, 사전학습된 BERT 모델의 output layer를 사용하는데 이 layer의 평균을 계산하여 고정된 크기의 vector를 얻습니다. visual modality의경우, OpenFace2.0에서 제공하는 feature를 사용했다고 합니다. Table 7에서 그 결과를 확인할 수 있습니다.
<Importance of Pretraining the Emotion Shift Component>
pretraining emotion shift component의 중요성을 review하기 위해서, 위에서 설명한 두가지 설정과 비교하는데요. 논문의 저자는 emotion classification와 emotion shift component를 처음부터 공동으로 최적화하면 모델의 분류 선능이 저하될 수 있음을 확인하였다고 하는데요. 학습이 시작될 때 Siamese compoent는 weight가 무작위로 초기화되어 classification component에 유용한 signal을 제공하지 못하기 때문에 classification component의 학습을 방해합니다. 이를 방지하기 위해 공동으로 학습하기 전에, emotion shift label에 대해 emotion shift compoent를 사전학습시켜 학습 시작 시 emotion classification component에 대해 더 나은 emotion shift signal을 주어 더 쉽게 접근할 수 있도록 합니다. Table 7의 세 번째 줄 결과는 사전학습을 하지 않은 동일한 feature setting(두 번째 줄)과 비교했을 때 F1 score가 2% 증가한 것을 확인할 수 있습니다.
<Effect of Modeling Emotion Shift>
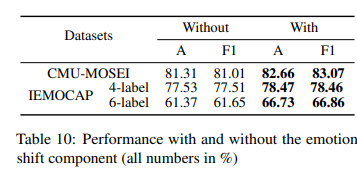
emotion shift를 별도의 component로 모델링하는 것의 중요성을 더 확인하기 위해서, emotion shift component가 있는 모델과 없는 모델의 두 가지 변형을 비교해봤는데요. Table 10을 통해 그 성능을 확인할 수 있습니다. 두 데이터셋 모두에서 emotion shift compoent를 사용하는 동안 성능이 크게 향상되는 것을 확인할 수 있었습니다.
<Contributions of the Modalities>
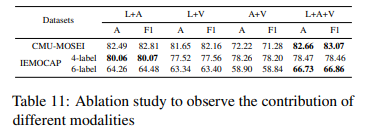
데이터셋 존재하는 다양한 모달리티의 중요성을 이해하기 위해 세 가지 모달리티 중 두 가지 모달리티의 조합을 선택하여 실험을 추가로 진행하였는데요. Table 11을 통해 그 성능을 확인할 수 있습니다. 예상대로 대부분의 데이터셋에서 세 가지 모달리티를 모두 사용하는 모델이 두 가지 모달리티만 사용하는 모델보다 성능이 뛰어남을 확인할 수 있습니다. 4개의 class가 있는 IEMOCAP 데이터셋에서는 text+audio 모델이 6개 class 보다 더 나은 성능을 보였는데요. 이에 본 논문에서는 text 모달리티가 context의 중요성을 강조하는 다른 모달리티에 비해 가장 핵심적인 것으로 보인다고 하였습니다.
<Using other modalities in the Emotion Shift Component>
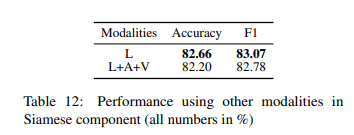
emotion shift compoent에 대한 text 이외의 모달리티의 효과를 관찰하기 위해 이 component를 학습할 때 세 가지 모달리티를 모두 사용할 때의 효과를 분석하였는데요. 이를 위해 ealry fusion technique를 사용하여 $l_t, a_t, v_t$ 모달리티를 concat($l_t ⊕ a_t ⊕ v_t $)한 다음 Siamese network에 이를 전달합니다. Table 12를 통해 그 성능을 확인할 수 있는데 text 모달리티만 사용했을 때 성능이 더 좋은 것을 확인 할 수 있습니다. 그 이유는 emotion shift를 예측하는데 있어 (text 모달리티에서 captured한) context이 중요하기 때문일 수 있다고 본 논문의 저자는 말합니다.
이렇게 리뷰를 마쳐봤습니다. emotion shift를 직접 계산한다는 생각은 전혀 해보지 못했는데 이렇게도 감정 인식을 할 수 있구나를 배워가는 논문이었습니다. 읽어주셔서 감사합니다.
Kurt Vonnegut. 1995. Shapes of stories. Vonnegut’s Shapes of Stories
Andrew J Reagan, Lewis Mitchell, Dilan Kiley, Christopher M Danforth, and Peter Sheridan Dodds. 2016. The emotional arcs of stories are dominated by six basic shapes. EPJ Data Science, 5(1):1–12.
Soujanya Poria, Navonil Majumder, Rada Mihalcea, and Eduard H. Hovy. 2019. Emotion recognition in conversation: Research challenges, datasets, and recent advances. CoRR, abs/1905.02947.
Jane Bromley, J.W. Bentz, Leon Bottou, I. Guyon, Yann Lecun, C. Moore, Eduard Sackinger, and R. Shah. Signature verification using a siamese time delay neural network. International Journal of Pattern Recognition and Artificial Intelligence, 7(4).
Nils Reimers and Iryna Gurevych. 2019. Sentence-bert: Sentence embeddings using siamese bert-networks.
Soujanya Poria, Navonil Majumder, Devamanyu Hazarika, Erik Cambria, Amir Hussain, and Alexander F. Gelbukh. 2018. Multimodal sentiment analysis: Addressing key issues and setting up baselines. CoRR, abs/1803.07427.
Mirco Ravanelli, Philemon Brakel, Maurizio Omologo, and Yoshua Bengio. 2017. Improving speechrecognition by revising gated recurrent units. CoRR, abs/1710.00641.
좋은 리뷰 감사합니다.
감정이 유지되는 경우와 급격하게 shift되는 경우를 명시적으로 고려하여, 여러 모달리티의 정보를 융합하는 감정인식 모듈을 제안한 것으로 이해하였습니다.
그런데 본 논문에서는 발화자가 일관성 있는 정보를 준다는 것으로 발화를 정의하였다고 하셨는데, 이러한 정의는 감정이 급변하는 상황을 고려하지 않는다는 전제가 아닌지 궁금합니다. 여기서 일관성있는 정보라는 것은 발화 내용(context)의 일관성을 의미하는 것인가요?
그리고 emotion classification component는 현재 화자, 이전 발화의 감정, 전체 대화의 context로 발화의 label을 예측한다고 하셨는데, 현재 발화를 예측하기 위해서 참고하는 전체 대화는, 데이터셋 전체의 context일까요? 그리고 전체대화의 context를 고려한다면, 감정인식은 real-time으로는 작동하기 어려운 것일지도 궁금합니다.
마지막으로, emotion Classification Component는 angry, happy 등의 감정을 예측하고,
emotion shift component는 positive와 negative 두가지 감정으로 별도로 사전학습된 것으로 이해하였는데 제가 제대로 이해한 것인지 궁금합니다.
안녕하세요. 댓글 감사합니다.
1) 네 맞습니다. 저는 context의 일관성으로 이해하였습니다.
2) 데이터셋 전체의 context라고 간주해도 될 듯하고, 한 대화의 context라고 생각하시면 더 좋을 것 같습니다. real-time으로 작동하기 어려운 task라고 생각이 듭니다. 저도 항상 erc 논문을 읽으며 real-tiem으로는 한계를 가지는 분야라고 생각하고 있습니다.
3) 네 맞습니다.
감사합니다,
안녕하세요 김주연 연구원님. 좋은 리뷰 감사합니다.
제가 이해한 바에 따르면 ERC에 사전 학습 모델인 emotion shift component를 추가하여 갑작스러운 감정 변화를 명시적으로 감지하고자 한 것 같습니다.
리뷰를 읽고 몇 가지 질문이 있는데요,
Table 3의 결과 부분에서 Multi Label로 인해 emotion shift가 성능 향상에 기여하지 못했다고 하셨는데요, 그 이유가 궁금합니다. multi label 인 경우 둘 중의 하나만 달라져도 emotion shift가 발생하였다고 할 수 있기 때문에 probability가 애초에 높게 측정되기 때문인가요?
그리고 해당 논문의 방법론이 큰 성능 향상을 이룬 것을 Table 4에서 확인할 수 있다고 하셨는데 Happy의 경우 다른 두 방법론보다 매우.. 큰 성능 하락이 발생하였습니다… 이에 관해 논문에서 언급한 것은 없는지도 궁금합니다.
안녕하세요. 댓글 감사합니다.
1) 네 맞습니다. 저도 동일하게 이해하였는데요. multi label인 경우 multi label에서 emotion shift를 표현할 수 있기 때문에 probability가 애초에 높게 측정되기 때문이라 생각합니다.
2) 흠.. 다시 보니 정말 그렇네요. 다시보니 happy 왜에 surprise와 같은 긍정 감정의 성능이 대체로 하락한 것을 확인할 수 있는데 논문에서는 이에 대한 언급이 없습니다. 제 생각에 emotion shift를 통해서 순간적으로 변하는 부정적인 감정을 잘 캐치 할 수 있는 반면에 그로 인해서 부정적인 감정에 민감해져서 긍정적인 감정에는 성능이 낮아진 것은 아닌가… 생각이 듭니다.
감사합니다.