Before Review
오늘은 Generic Event Boundary Detection이라고 해서 제가 요즘 관심 있어 하는 Video Scene Segmentation 이라는 연구 분야와 굉장히 비슷한 것으로 가져왔습니다. Segmentation을 하는 과정에서 Segmentation Unit을 Scene으로 할 지 Event로 할 지의 차이와 사전 학습으로 사용하는 비디오의 길이에 차이가 있긴 합니다.
본 논문에서 제안하는 알고리즘이 생각보다 괜찮은 거 같아서 저의 연구에도 적용해볼 수 있을 것 같아 리뷰 하게 되었습니다.
리뷰 시작하겠습니다.
Introduction
비디오 플랫폼 (Youtube, TiK Tok, Netflix..)의 확산과 함께 컴퓨터 비전 연구자들은 Video Understanding에 많은 관심을 가지게 되었습니다. Video Understanding 분야에서 가장 많이 사용되는 방식은 비디오를 단순히 겹치지 않는 고정된 길이의 snippet으로 분할하는 것 이었습니다.
하지만 이런 방식의 접근은 비디오 데이터의 semantic continuity를 고려하지 못하기 때문에 효과적인 접근은 아니라 볼 수 있습니다.
이러한 와중에 인지 과학(Cognitive Science)에서 말하길, 사람들은 visual stream을 event의 집합으로 받아들인다고 합니다. 즉, 비디오라는 데이터도 “단순히 고정된 길이의 snippet으로 분할하는 것이 아니라 event 단위로 분할하는 것이 진정한 Video Understanding의 방향이다.” 라는 것 입니다.

그래서 우리가 찾고자 하는 Event의 Boundary는 위와 같이 정의 됩니다.
- Shot이 변화하는 부분
- 사람의 Action이 달라지는 부분
- 조도 변화가 심하게 발생하는 경우
- 새로운 subject가 등장하는 경우
등등.. 이러한 semantic change가 발생하는 경우를 찾고 비디오를 좀 더 유의미한 단위로 쪼개는 것이 Generic Event Boundary Detection(이하 GEBD) 입니다.
사실 이러한 작업을 하는 비슷한 task가 이미 있긴 했습니다. Temporal Action Localization(이하 TAL)이라고 해서 Action이 발생하는 구간을 temporal 차원에서 찾는 것이죠.
하지만 기존 TAL에서 사용하는 방식을 GEBD에 적용하는 것은 한 가지 문제가 있습니다. TAL에서는 Temporal Localization을 목표로 하지만 정작 Video Classification으로 사전 학습된 신경망을 사용하여 task discrepency 문제가 있습니다.
Video Classification으로 사전 학습을 하는 TAL 방식을 활용하기에는 무리가 있습니다. 결국 Event Boundary를 찾기 위해서는 인접한 frame 사이의 관계를 좀 더 정밀하게 모델링 해야 하기 때문에 새로운 방법이 필요한 상황입니다.
이러한 boundary를 찾기 위해서 비디오 분야에서는 자주 사용되는 테크닉이 있습니다. 바로 Temporal Self-Similarity Matrix(이하 TSM)이죠.
T개의 feature가 있다고 하면 feature들끼리 일대일 대응을 시켜 코사인 유사도를 계산하고 T \times T의 Similarity Map을 생성하는 것 입니다.
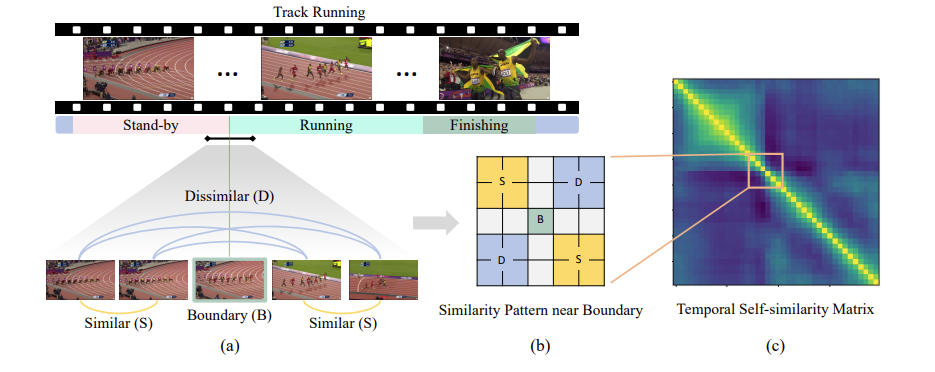
이 때 본 논문의 중요한 observation은 boundary 경계에 있는 TSM의 pattern은 위의 그림 (b)와 같다는 것 입니다. T개의 프레임을 1초에 하나씩 샘플링 했다고 가정하면 TSM에서 하나의 값은 1초의 temporal length를 책임지게 됩니다. 0초에서 2초가 evnet A, 2초~3초가 boundary, 3초~5초가 event B라 가정하면 Boundary를 경계로 전후의 Similarity Map의 양상이 아래와 같이 나옵니다.
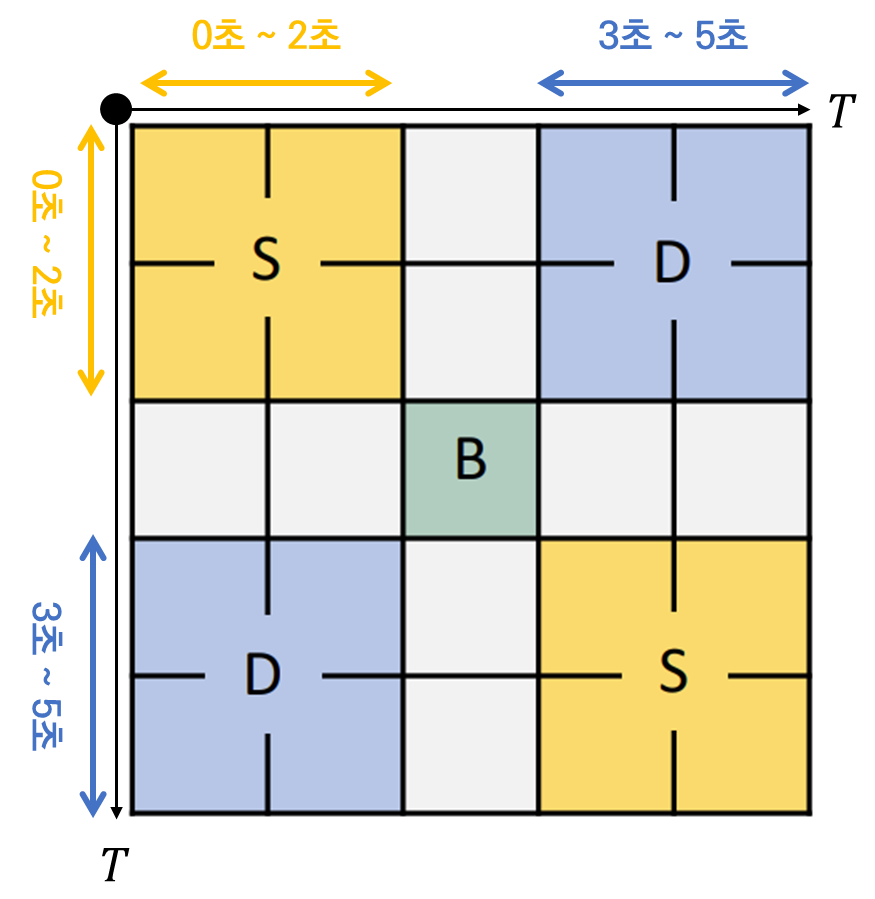
같은 event에 속한 feature들의 similarity가 높고 다른 event간 similarity가 낮게 나오는 것이 boundary를 찾는데 이상적이기 때문 입니다. 이러한 local diagonal pattern이 boundary를 찾는데 굉장히 중요한 learning signal로 작용할 수 있습니다.
이는 TSM에서 대각 방향으로 edge를 찾는 것과 비슷하기 때문입니다. 저러한 pattern을 찾을 수 있다면 우리는 그 지점을 pseudo boundary로 사용할 수 있겠네요.
본 연구는 이러한 TSM의 local pattern에 집중하여 event boundary를 찾는데 더욱 적합한 feature representation을 얻을 수 있는 방법을 제안합니다.
본 연구는 분할 정복 방식으로 TSM을 분할하여 임의의 종료 조건까지 계속해서 pseudo boundary를 찾습니다. 이렇게 찾은 pseudo boundary를 가지고 다시 feature representation을 정교하게 만들고 정교해진 representation을 바탕으로 다시 분할 정복 방식의 알고리즘을 활용합니다.

그래서 저자가 제안하는 방식으로 학습을 진행하면 왼쪽 그림과 같이 boundary를 찾는데 더욱 distinctive한 feature representation을 얻을 수 있습니다.
저자는 이렇게 TSM을 learning signal로 활용하여 GEBD에 굉장히 효과적인 학습 framework를 제안하여 비지도학습 방법론과의 비교뿐만 아니라 지도학습 방법론들과의 비교에서도 굉장히 좋은 성능을 보여줍니다.
그렇다면 이제 제안하는 방법론에 대해서 살펴보도록 하겠습니다.
Proposed Method
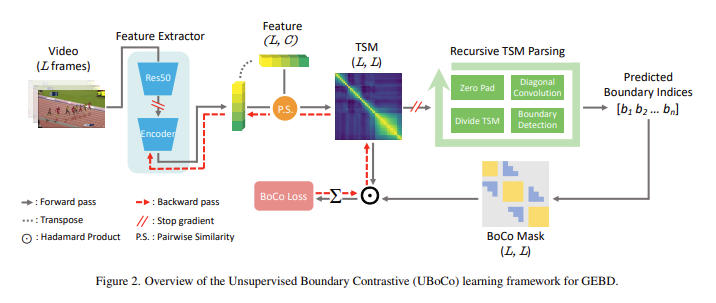
위의 그림은 제안하는 방법론의 전체적인 구조를 나타내고 있습니다.
입력 비디오가 L개의 프레임으로 구성되어 있으면 이미지 넷으로 사전 학습된 ResNet50을 이용하여 frame feature를 기술합니다. 그리고 이 feature를 추가적인 Encoder를 활용하여 다시 embedding을 시키게 됩니다. ResNet50까지 업데이트를 하는 것은 아니고 추가적인 Encoder만을 학습하여서 GEBD에 적합한 feature representation을 얻는 것이 목적 입니다.
이렇게 L개의 프레임으로 구성된 비디오들의 frame feature들을 활용하여 TSM을 만들면 (L, L)사이즈의 TSM을 얻게 됩니다.
이렇게 얻어지는 TSM을 바탕으로 이제 두 가지의 과정을 거치게 됩니다. 1) Recursive TSM Parsing을 통해 TSM내의 local pattern을 바탕으로 pseudo boundary를 분할 정복 방식으로 찾습니다. 2) 앞에서 찾은 pseudo boundary를 바탕으로 boundary senstive 할 수 있는 contrastive loss를 제안합니다.
Recursive TSM Parsing (RTP)
제가 논문에서 가장 인상 깊게 읽었던 Recursive TSM Pasring(이하 RTP) 입니다.
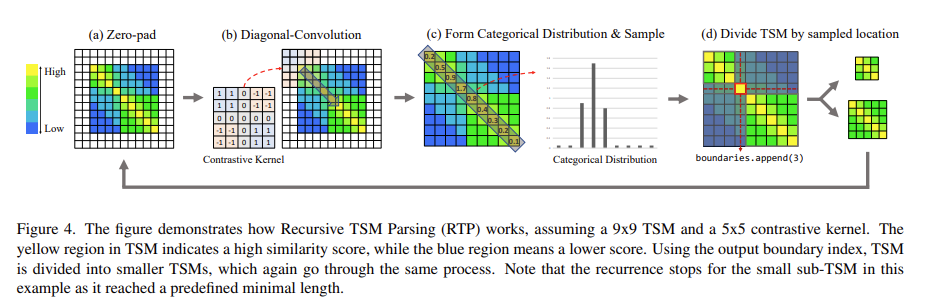
4가지 단계로 구성되어 있는데 하나씩 살펴보도록 하겠습니다.
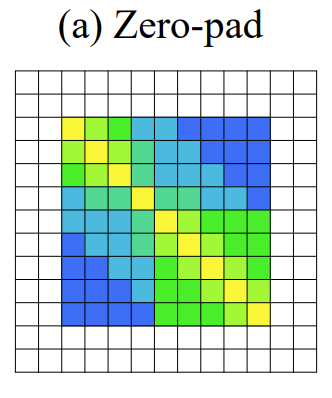
가장 처음으로 Zero-pad 입니다. Padding은 보통 사이즈를 맞춰주기 위해 사용하지만 corner 정보를 살려주기 위해 사용하기도 합니다. 여기서는 corner 정보를 살려주기 위해 사용해주고 있습니다. Corner 정보를 살려줘야 하는 이유는 바로 corner에 boundary가 있는 경우도 고려해주기 위함입니다. 사소할 수 있지만 이러한 디테일이 중요하게 작용한다고 합니다.
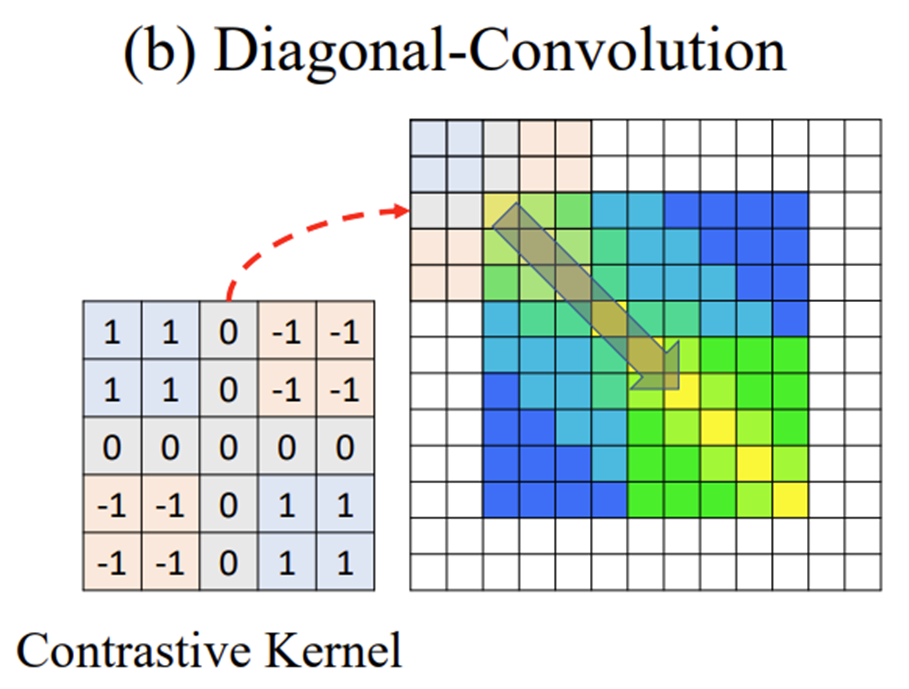
다음으로 Diagonal Convolution 입니다. Convolution이라고 해서 학습이 되는 filtering을 해주는 것은 아니고 위의 그림과 같이 사전에 정의된 Contrastive Kernel을 바탕으로 대각 방향 Sliding을 합니다. 그럼 저 Contrastive Kernel이 찾고자 하는 패턴은 무엇이냐면 바로 우리가 찾고자 했던 Boundary Local Pattern 입니다. 좀 더 자세히 설명해보도록 하겠습니다.
우리가 Cosine Similarity를 바탕으로 TSM을 정의하면 -1 ~ 1 사이의 값을 가지게 됩니다.
만약에 이상적인 Boundary Pattern이라 한다면 Similar한 부분에서는 1에 근접한 값이 나타날 것이고 Disimilar한 부분에서는 -1에 근접한 값이 나타나게 되겠죠.
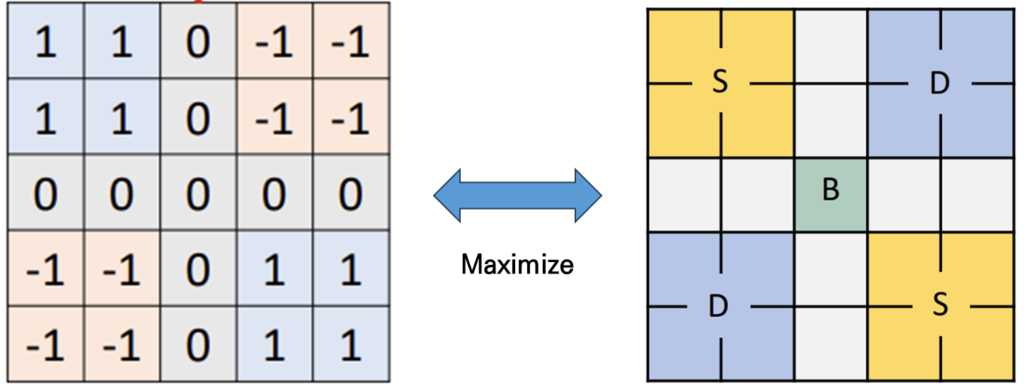
이때 Kernel을 5 by 5로 정의하고 4개의 구역으로 나누어 Similar한 부분에는 1을 채워주고 Disimilar한 부분에는 -1을 채워 줍니다. 그리고 나서 이상적인 Boundary Pattern에 filtering을 해주면 가장 최대 값이 발생하게 됩니다.
자 그럼 이러한 kernel을 가지고 대각 방향으로 필터링을 해주다 보면 우리가 찾고자 하는 boundary 인지 아닌지 나타낼 수 있는 스칼라 값을 얻을 수 있습니다.
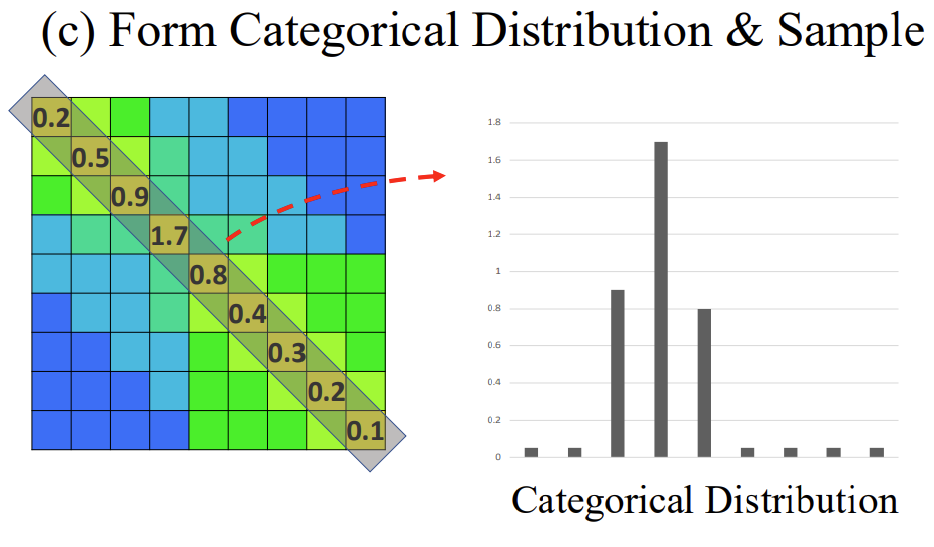
위의 그림 처럼 [0.2, 0.5, 0.9, 1.7, 0.8, 0.4, 0.3, 0.2, 0.1] 의 리스트를 얻을 수 있죠.
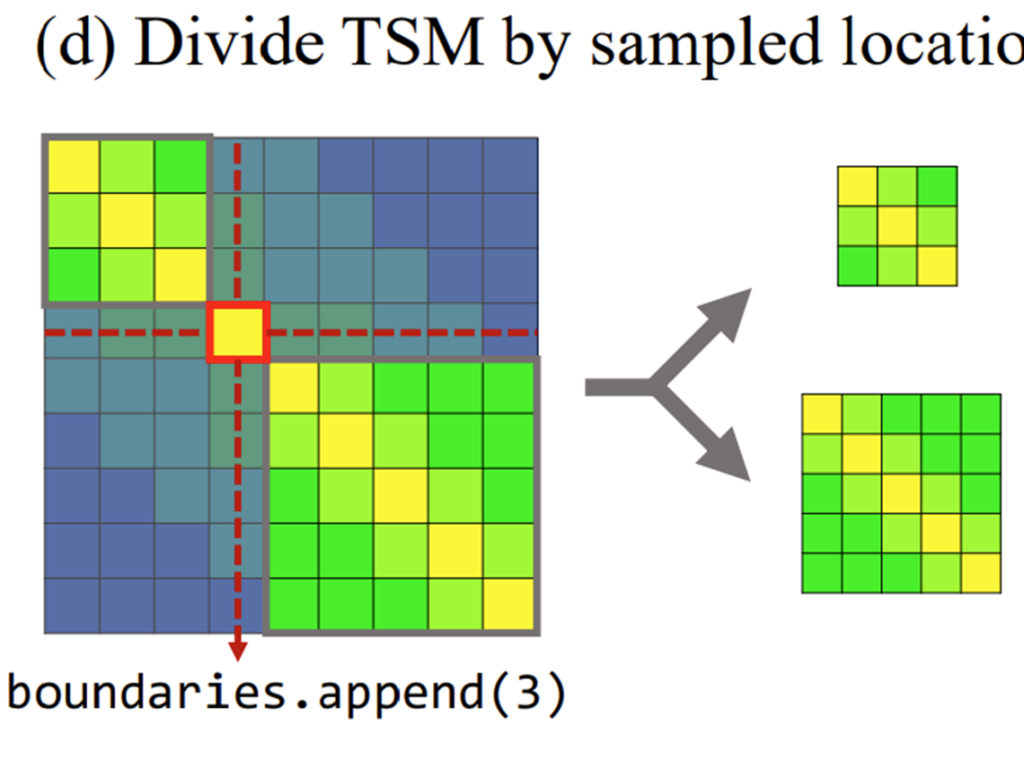
그리고 위에 리스트에서 [0.2, 0.5, 0.9, 1.7, 0.8, 0.4, 0.3, 0.2, 0.1] 최대 값에 해당하는 index를 바탕으로 다시 TSM을 분할 합니다. 여기서는 1.7이 가장 max 값이기 때문에 1.7에 해당하는 index=3을 pseudo boundary라 정의하고 이를 바탕으로 다시 TSM을 위의 그림과 같이 분할 합니다.
이렇게 쪼개진 TSM은 다시 위의 과정을 종료 조건까지 반복합니다. 그리고 우리는 그 과정에서 얻어지는 boundary를 pseudo boundary로 사용하는 것이죠.
종료 조건은 두 가지가 존재합니다.
- 분할되는 TSM의 temporal length가 사전에 정의한 threshold 보다 작을 경우, 이는 event가 정의될 수 있는 최소 길이에 대한 가정을 나타냅니다.
- 분할되는 TSM에서 max boundary score와 mean boundary score의 차이가 사전에 정의한 threshold보다 작을 경우, 이는 해당 TSM이 나타내는 구간에서는 boundary라 정의할 수 있는 distinctive한 point가 없는 경우 입니다.
이렇게 비디오에 대해서 N개의 pseudo boundary point를 얻었다면 이제 이를 활용해서 Contrastive Loss를 정의할 차례 입니다.
Boundary Contrastive Loss (BoCo Loss)
사실 위에서 정의한 RTP는 알고리즘 방식이라 학습이 되는 부분이 없습니다. 즉, 정교한 boundary를 찾기 위해서는 정교한 TSM이 필요하고 정교한 TSM을 만들기 위해서는 boundary에 senstive한 feature representation이 필요합니다.
즉, 위의 그림을 보면 알겠지만 pseudo boundary는 TSM에서 정의되며, TSM은 Encoder를 통해 나오는 feature representation으로부터 정의 됩니다.
즉, Encoder를 학습 시켜줄 적당한 Loss 함수가 필요한데 이것이 Boundary Contrastive Loss(이하 BoCo Loss) 인 것이죠.
본 연구는 BoCo Loss와 RTP와의 선순환 구조를 기대합니다. 무슨 말이냐면
RTP를 통해서 pseudo boundary가 나오고 이를 활용해서 BoCo Loss가 정의되어 Encoder가 업데이트 됩니다. 다시 업데이트된 feature representaion을 바탕으로 TSM이 나오고 RTP를 통해서 boundary가 나오고 BoCo Loss가 정의 됩니다.
즉, BoCo Loss를 줄이기 위해서는 정교한 boundary를 찾아야 하고 정교한 boundary를 찾기 위해서는 Encoder가 Boundary Senstive 할 수 있도록 feature를 embedding 시켜야 합니다.
이 과정을 반복하다 보면 BoCo Loss와 RTP가 서로 상호 보완적으로 작동할 수 있다는 것이죠.
BoCo Loss는 결국 Contrastive Learning을 목적으로 하다 보니 제일 중요한 건 Contrastive Pair를 어떻게 정의하는 것 입니다.
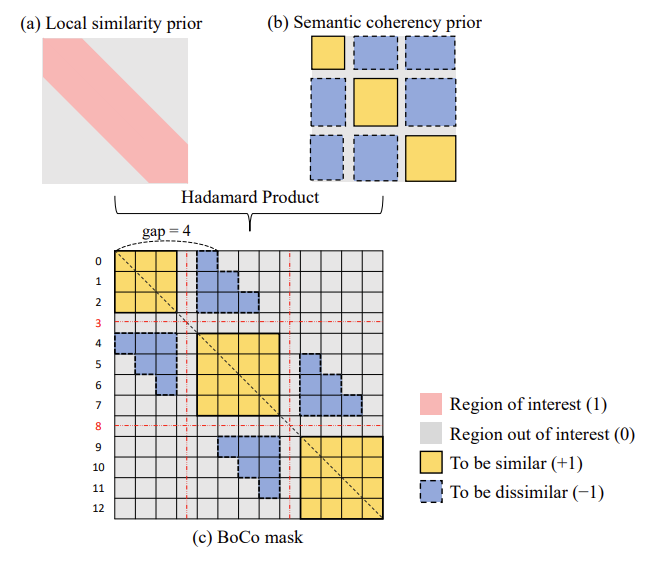
Contrastive Kernel과 동일한 사이즈 만큼의 Local 영역을 보기 위해 Local similarity prior를 위의 그림 처럼 만들고 RTP를 통해 얻어진 pseudo boundary를 활용하여 Semantic coherence prior를 만들어 element-wise product을 진행하여 BoCo mask를 만들어냅니다.
BoCo mask를 통해서 이제 유효한 positive/negative pair를 생성할 수 있습니다. 빨간색으로 칠해진 영역 내에서 yello region과 blue region 각각에 대해서 mean value를 계산하고 이를 활용하여 metric learning을 진행합니다.
Frame level로 진행할 줄 알았는데 이렇게 region 별로 진행하는 것은 연산의 효율성을 위함이라 하네요.
Supervised Boundary Contrastive Learning with Decoder
위에서 정의한 pseudo boundary를 ground truth boundary로 바꾸면 지도학습이 됩니다.
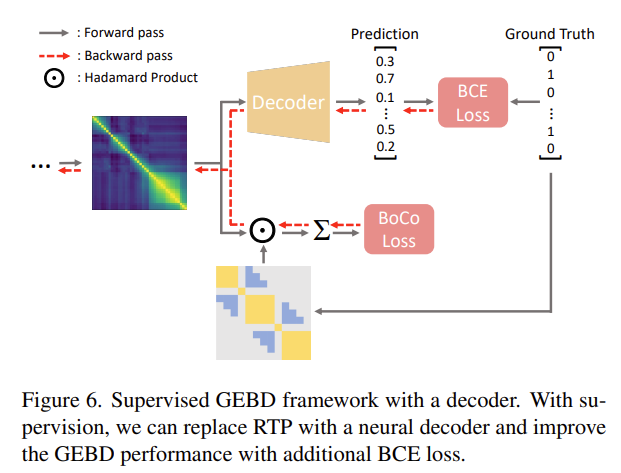
여기서 BoCo Loss야 그대로 사용하면 되는데 ground truth boundary가 있으니 boundary detection을 수행 합니다. 여기서 boundary detection은 사실 frame 마다 이 frame이 boundary 인지 아닌지 예측하는 binary classification 문제로 정의 됩니다.
이 때 decoder는 몇 가지 convolution layer와 transformer로 구성되어 있는데 구조에 대한 detail은 supple에 있다고 합니다. 궁금하신 분들은 직접 찾아보시고 저는 이제 실험 섹션으로 넘어가도록 하겠습니다.
Experiments
Results on Kinetics-GEBD
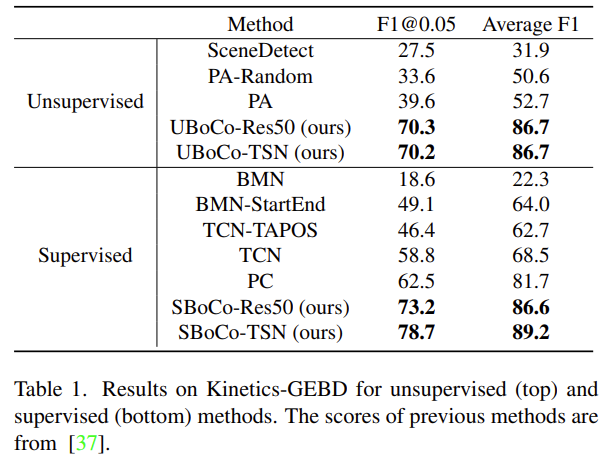
GEBD task에 대한 Benchmarking 입니다. GEBD task 자체가 21년도에 제안되고 바로 그 다음 해에 연구되었다 보니 Unsupervised 상황에서는 비교 방법론이 많이 없으면서 성능이 낮은 상황입니다. 신기한 건 Unsupervised setting에서의 UBoCo 성능이 Supervised setting에서의 다른 방법론들보다 성능이 높다는 것 입니다.
여기서 feature 추출을 frame 기반의 ResNet이 아닌 비디오 기반의 TSN을 사용하니 이전 SOTA 보다 16.2%나 더 높은 성능을 보여주고 있습니다.
Ablation Studies
Self-Supervision with Pseudo-label
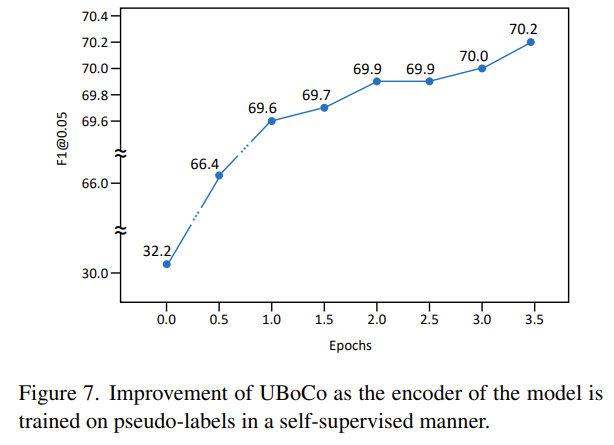
RTP를 통해서 만들어지는 Pseudo Boundary를 가지고 UBoCo 모델을 학습 시킬 때 성능을 epoch 별로 보여주고 있습니다. 이를 통해 Pseudo Boundary가 학습을 통해 좀 더 개선되고 있다는 것을 보여주고 있습니다.
Recursive TSM Parsing
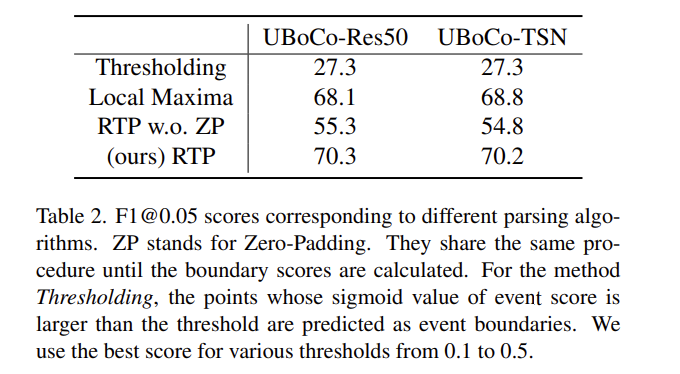
다음으로는 RTP에 대한 ablation 입니다. 여기서 Thresholding은 위의 설명 처럼 sigmoid 함수를 통과해서 나온 값에 대해 thresholding을 해 임시로 boundary를 정의하는 방식 입니다. 너무 나이브한 방식인 만큼 boundary 제대로 생성이 되지 않고 있고 Local Maxima라는 방법에 대해서는 자세한 설명이 없네요.
대신 RTP를 zero padding과 함께 적용해주는 것이 가장 좋은 성능을 보여주고 있습니다. Zero Padding을 하는 것과 하지 않는 것의 차이가 굉장히 많이 발생하고 있습니다.
아까 설명한 것 처럼 코너의 정보를 살려주는 것이 중요하게 작용했나 봅니다.
Extension to Supervised Model
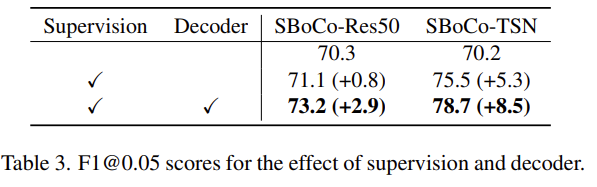
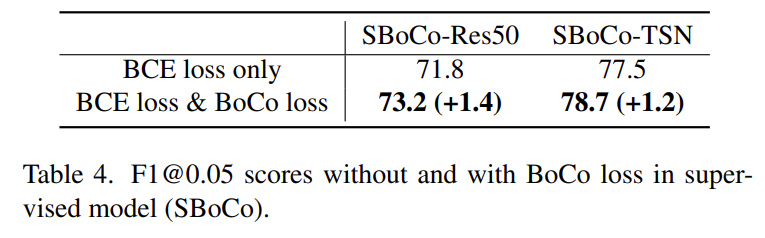
위 두 개의 실험은 Supervised 상황에서 Decoder의 유무와 BCE Loss의 유무에 따른 실험 결과를 나타내고 있습니다. BCE Loss의 경우 성능 향상이 조금 marginal 한 것 같지만 그래도 있으면 더욱 성능을 높일 수 있다고 하네요.
Conclusion
저자가 밝히는 본 논문의 한계점으로 고정된 contrastive kernel을 사용한 점과 비디오의 길이가 비슷한 Kinetics GEBD에서 밖에 실험이 이루어진 점을 지적하고 있습니다.
그럼에도 TSM의 local pattern을 활용한 pseudo boundary를 찾는 RTP 알고리즘은 굉장히 인상적이었고 실제로 굉장히 효과적 이었네요.
리뷰 읽어주셔서 감사합니다.
안녕하세요. 임근택 연구원님.
좋은 리뷰 감사합니다.
학습 기반이 아닌 저자들이 설계한 합성곱을 이용한 Recursive TSM parising이 아주 인상깊네요.
몇가지 질문드리겠습니다.
1. 먼저 Figure 3. 아래 왼쪽 그림이 아니라 오른쪽 그림이 제안하는 방식을 적용한 distinctive feature인 것 같은데, 오타인 것 같습니다.
2. TAL의 경우 classification으로 학습되어 event boundary detection에 적합하지 않다고 하는데, W-TAL이 아닌 Supervised TAL 방법론들을 통해서는 이러한 GEBD를 수행할 수 없는건가요?
3. BoCo Loss를 위한 BoCo mask 생성 시, 모델이 예측한 pseudo boundary에 알맞게 TSM을 생성하도록 학습을 시키는 것으로 이해하였는데 이렇게 학습을 할 경우 pseudo boundary가 어느 정도 정확하다면 괜찮지만, 초기에 아주 불안정할 경우 실제 boundary가 아닌 영역을 기준으로 metric learning이 되어 학습이 어려울 것 같은데, 이와 관련한 저자들의 언급이 있었을까요?
감사합니다!
안녕하세요 임근택 연구원님 좋은 리뷰 감사합니다.
TSM의 edge를 찾는 방식으로 event boundary를 찾을 때 저자들이 설계한 Recursive TSM parising을 사용하며, 이는 사전에 정의한 특정 패턴(boundary local pattern)을 contrastive kernel을 이용하여 찾아내는 것이라고 이해하였습니다.
리뷰의 내용 중 BoCo Loss부분에서 질문이 있는데요, contrastive pair를 어떻게 구성하는 지 잘 모르겠습니다. BoCo mask에서 대각선 방향의 값 중 0으로 된 부분이 앞서 RTP에서 구한 psudo boundary라고 이해하였는데요, 이 이후에 positive/negative가 어떻게 정의되는 것인가요?