안녕하세요, 이번에도 6D pose estimation 관련 논문입니다. NOCS를 이전에 리뷰를 했었는데, NOCS를 이용한 +something을 한다고 하길래 읽어보았습니다. 해당 논문은 KAIST RCV Lab.에서 작성된 논문이라 어려워보여도 읽어보려고 한 것 같습니다.
이번 논문은 기존의 3D detection + 6D pose만 추정하는 것이 아닌 3D shape을 만드는 것까지 하는 task를 수행합니다. (해당 task는 6D pose estimation task 중 instance-level이 아닌 category-level task입니다. NOCS 리뷰를 참고해서 읽으시면 조금이나마 도움이 되실 것 같습니다.)
리뷰 시작하겠습니다.
I. INTRODUCTION

3D 물체 인식은 로봇 조작 및 증강 현실(AR)과 같은 다양한 로봇 공학 및 컴퓨터 비전 애플리케이션에서 중요한 작업 중 하나입니다. 이러한 애플리케이션이 3D 공간에서 사물을 인식하고 상호 작용하려면 사물의 유형, 모양, 크기, 위치 및 방향을 파악해야 합니다. 예를 들어 로봇이 머그잔을 잡으려면 머그잔이 어떤 종류인지(유형), 어떤 모양인지(모양), 얼마나 크고 작은지(크기), 머그잔이 정확히 어디에 놓여 있는지(위치), 머그잔의 손잡이가 어느 방향을 가리키고 있는지(방향)를 파악해야 합니다. 기존의 많은 6D pose estimation task의 방법은 각 오브젝트의 3D CAD 모델과 크기 정보를 알고 있다고 가정하여 instance-level에서의 pose estimation을 하려고 시도했습니다. 최근까지도 주로 카메라 파라미터를 이용하는 방법을 적용하여 좋은 성능을 보여준 사례들이 많습니다. 하지만 저자는 모든 물체에 대한 정확한 3D 스캔을 확보하거나 얻는 것은 쉽지 않기 때문에 이전에 물체를 본 적이 없거나 3D CAD 모델이 없는 일반적인 환경에서는 이러한 알고리즘을 적용하기가 어렵고, 새로운 물체가 관찰될 때마다 별도의 네트워크를 학습시키는 것도 비효율적이라는 문제를 제기합니다.
이러한 category-level의 문제를 해결하기 위해 unseen object에 대한 물체를 다루는 방법론들이 제안되었는데요. 대표적으로는 NOCS가 있습니다. 해당 NOCS에서는 서로 다른 객체 인스턴스를 shared orientation으로 정렬하기 위해 Normalized Object Coordinate Space(NOCS)이라는 새로운 representation을 도입하였습니다. 카테고리별로 유사한 NOCS map을 예측하면 3D model 없이도 unseen object에 대한 6D pose estimation을 수행하는 것이 핵심입니다. 기존의 category-level 6D pose 추정 방법에서는 물체의 pose와 scale 정보를 추정하기 위해 3D 모델 정보 대신 depth 정보가 필요했습니다. 깊이 정보를 사용하지 않고 물체의 모양과 포즈를 예측하는 알고리즘을 제안한 연구도 있었지만, RGB 기반 물체 shape 추정 결과에는 물체 scale 정보가 부족한 문제가 있었다고 합니다.
이번 논문에서는 depth 정보가 없거나 단일 RGB 이미지만을 활용하여 CNN 기반의 category-level의 metric scale 물체의 3D shape 및 6D pose estimation 방법을 제안합니다.
II. RELATED WORK
A. Instance-level object pose estimation
3D 객체 인식에 대한 관심이 높아지면서 다양한 instacne-level의 객체 pose estimation 접근 방식이 도입되고 있습니다. instance-level pose estimation 접근법은 크게 correspondence-based 방법과 regression-based 방법의 두 가지 범주로 나눌 수 있습니다.
regression-based 방법은 입력 이미지에서 rotation과 translation을 direct inference 합니다. 이러한 접근 방식에서 생기는 challenge한 부분은 pose 공간의 비선형성으로 인해 학습을 일반화하기 어렵다는 점입니다. 정확한 pose를 얻으려면 해당 방법에는 3D CAD 모델을 기반으로 하는 ICP(iterative closest point)와 같은 특정 유형의 refinement 과정이 필요합니다.
correspondence-based 방법은 2D 이미지와 3D 모델 간의 포인트 매칭에 의존합니다. mask 영역의 각 이미지 픽셀에 대해 해당 3D 객체 좌표를 regression시키는 방법론과 이미지에 투영된 3D 포인트에서 keypoint를 detection한 다음, PnP(Perspective-n-Point) 알고리즘을 사용하는 방법론이 있습니다. 앞서 언급한 모든 instance-level의 연구들은 높은 결과들을 보여주고 있지만, 대부분의 방법론들은 학습과 추론 시점에 3D CAD 모델 정보가 필수적으로 필요합니다.
B. Category-level object pose estimation
일부 방법은 inference할 때 instance 별로 3D 모델이 제공되지 않을 때, 학습 중에 known category를 사용하여 unseen 오브젝트의 pose를 추정하는 데 중점을 두었습니다. 대표적으로 category-level의 물체의 6D pose 추정을 위한 Normalized Object Coordinate Space(NOCS)을 도입했습니다. 해당 논문에서는 RGB 이미지로부터 카테고리 내 객체 instance의 shared canonical representation인 NOCS를 추정했습니다. non-linear solution을 사용하여 예측된 NOCS map과 observed depth map을 일치시켜 물체의 pose와 size를 indirect 추정합니다. 이후, NOCS map을 추정하기 전에 shape으로부터 변형을 명시적으로 학습하는 보다 발전된 네트워크를 제안하는 연구도 나왔습니다. 또 다른 연구는 이미지와 depth로부터 direct로 pose와 size를 regression했습니다. 하지만 이러한 방법은 물체의 scale를 안정적으로 예측하기 위해 필수적으로 depth 정보가 필요하게 됩니다. 마지막으로 다양한 관점에서 물체의 외관을 생성하는 생성 모델을 제안하는 연구도 있었습니다. 합성은 추론 시 iterative한 alignment을 사용하여 입력과 생성된 외관을 일치시켜 RGB 이미지에서 객체 pose를 추정하지만, 해당 방법 또한 3D 오브젝트 모양과 크기에 대해서 강건하게 대처하지 못 하는 문제가 있었다고 합니다.
III. CATEGORY-LEVEL METRIC SCALE OBJECT SHAPE AND POSE ESTIMATION
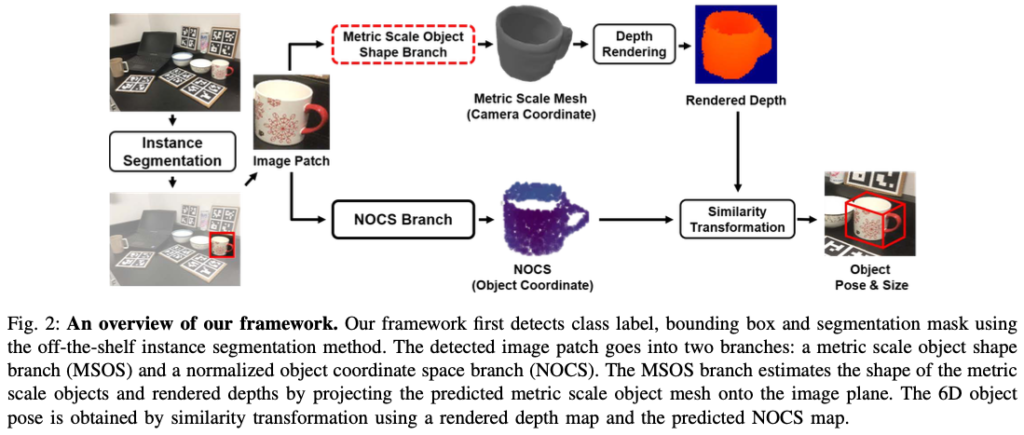
RGB 이미지가 주어졌을 때, 해당 방법론의 목표는 오브젝트 instance의 오브젝트 shape, pose, scale를 추정하는 것입니다. 위 그림(2)는 전체적인 파이프라인을 보여주는데요. 기성 instance segmentation network를 사용하여 class label, bounding box, segmentation을 detection합니다. 그런 다음, detect된 이미지 패치는 두 가지 branch로 나뉘게 되는데요. 즉, Metric Scale Object Shape(MSOS) branch와 Normalized Object Coordinate Space(NOCS) branch 입니다. 이후 rendered depth map과 NOCS branch에서 예측된 NOCS map은 similarity transformation을 사용하여 오브젝트의 pose와 scale을 추정하는 데 사용됩니다.
A. Metric Scale Object Shape Branch(MSOS)
Voxel, Point cloud, Mesh 등은 다양한 3D shape representation을 위한 방법인데요. 저자는 로보틱스 분야나 AR 어플리케이션에서는 dense하고 정확한 3D shape representation을 필요로 한다고 합니다. 이후 각 representation에 대한 문제점과 사용할 representation을 설명합니다.
- Voxel representation은 디테일한 구조의 정확도는 3D 공간의 voxel resolution에 따라 달라짐
- Point cloud representation은 비교적 적은 3D 포인트로 더 많은 디테일을 처리할 수 있지만, 아래 그림(4)에서 볼 수 있듯이 물체의 surface 정보를 포함하지 않으므로 모양이 너무 sparse 함.
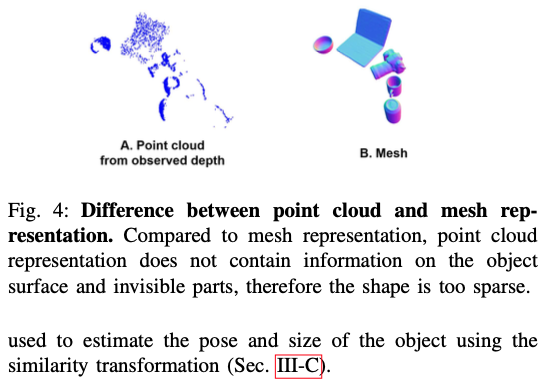
위의 이유로 비교적 dense하고 정확한 3D shape를 모두 보여줄 수 있는 mesh representation을 선택했습니다.
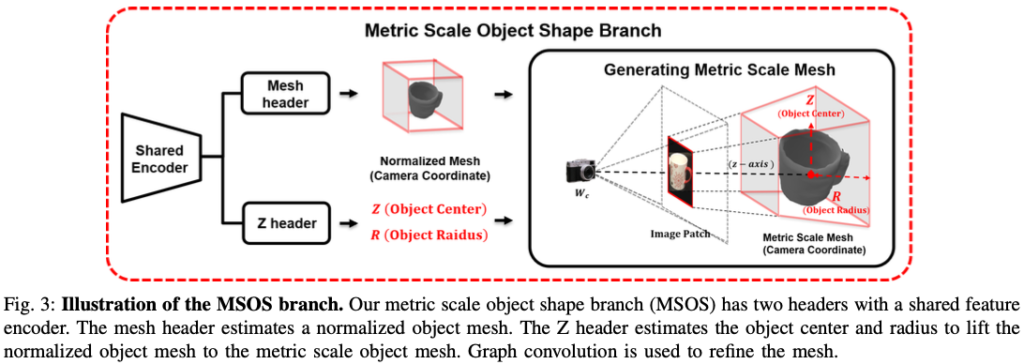
Metric Scale Object Shape(MSOS) branch는 단일 이미지를 사용하여 카메라 좌표로부터 metric scale object mesh를 추정합니다. 그림(3)은 MSOS branch에 대한 세부적인 정보를 보여주는 그림입니다. 해당 branch에서 shared encoder를 사용하여 공동으로 학습된 두 개의 header로 구성됩니다.
- Mesh header : Normalized Object Mesh 추정
- Z-Header : 카메라 중심에서 z축을 따라 오브젝트의 거리인 Z 정보를 예측하여 Normalized Object shape을 Metric scale object shape으로 lift합니다.
1) Normalized Object Mesh Estimaiton(Mesh header)
해당 header의 목표는 각 category에 대해 단일 네트워크를 학습하는 방법 대신에 단일 네트워크로 모든 객체 카테고리를 커버할 수 있도록 하는 것입니다. 이러한 이유로 특정 네트워크 baseline에 민감하지 않으면서도 Mesh R-CNN과 유사한 방식을 따라 Normalized Object Mesh M_{norm}을 추정합니다. instance segmentation 단계에서 detect된 객체는 bounding box를 사용하여 crop되며, 동일한 패치 크기를 갖도록 크기가 resize됩니다. 이렇게 크기가 조정된 이미지 패치를 입력으로 받아 mesh header는 관련 정보만을 활용하여 객체 모양을 효율적으로 학습할 수 있습니다.
2) Normlized Object Center Estimation(NOCE)
예측된 normalized mesh를 카메라 좌표, 즉 metric scale로 변환하기 위해서는 객체의 location과 scale 정보가 필요합니다. 그림(3)과 같이 카메라에서 객체 중심까지의 거리를 z-axis, 오브젝트 중심을 Z로 표현하고, metric scale object mesh의 반경을 object radius R로 정의합니다. 오브젝트 중심은 metric mesh의 location을 처리하고 오브젝트 반경은 scale/size를 결정합니다. 오브젝트 중심과 오브젝트 반경에 대한 추정 branch를 Z header라고 부르는 이유는 두 값 모두 카메라에서 Z을 따라 예측되기 때문이라고 합니다.
RGB 이미지만을 사용하여 물체의 중심까지의 거리를 추정하는 것은 어려운 일이라고 합니다. 주된 이유는 RGB 이미지에 3D 볼륨에 관한 정보가 포함되어 있지 않기 때문인데요. 이러한 문제를 해결하기 위해 mesh header와 Z header에 shared feature encoder를 사용하여 학습 과정에 mesh를 예측하도록 하는 기능을 내부적으로 포함시켰습니다. 물체의 shape과 물체의 중심을 공동으로 추정함으로써 각 header는 다른 header의 목표 또한 사용하여 유도할 수 있다고 생각한다고 합니다.
앞서 설명 과정 중에, 오브젝트 영역에서 crop되고 크기가 resize된 이미지 패치가 있었습니다. 이를 mesh header의 입력으로 사용하면 mesh의 퀄리티나 효율적인 추론에 유리하다고 합니다. 하지만, crop된 이미지 패치의 크기를 resize 하면 아무래도 bounding box의 정보가 손실되게 되는데요. 여기서 bounding box의 크기는 카메라에서 오브젝트까지의 거리를 의미하므로 이미지 크기를 resize하면 Z 및 R의 예측이 모호해질 수 있으므로 이는 매우 중요하다고 합니다.
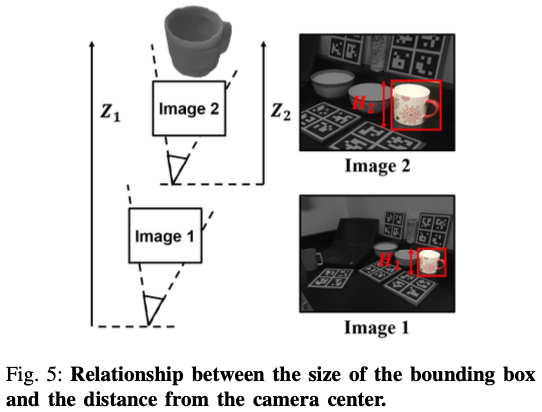
예를 들어, 그림(5)에서 볼 수 있듯이 원본 이미지 패치를 up-sampling하는 것은 카메라를 장면에 더 가까이 가져가는 것과 유사하며, 이로 인해 원본 Z 정보가 변경됩니다. 따라서 detection된 두 개의 머그잔은 입력 이미지 패치에서 같은 크기로 보이지만 물체 중심은 완전히 다른 것처럼 보입니다. 따라서 crop + resize된 이미지 패치를 사용하여 오브젝트 중심을 예측하는 것은 문제가 될 수 있습니다. 이 문제를 해결하기 위해 Normlized Object Center Estimation(NOCE)을 제안합니다. NOCE는 detect된 bounding box의 크기 정보를 사용하여 GT 오브젝트 중심 Z를 선형적으로 스케일링합니다.
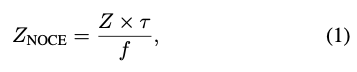
식(1)과 같이 resize ratio \tau를 오브젝트 중심 Z에 곱해줍니다. 여기서 \tau = H_{o}/H_{patch} 입니다. 여기서 H_o는 원래 bounding box의 크기를 나타내고, H_{patch}는 입력 이미지 패치의 크기이며, f는 focal length를 나타냅니다. 학습 중에는 원본 Z 대신 normalize 오브젝트 중심 Z_{NOCE}가 기준점으로 사용됩니다. 이렇게 하면 유사한 장면에서 유사한 오브젝트는 유사한 Z_{NOCE} 값을 가지게 되어 metric scale object shape과 translation 추정을 개선하는 데 큰 도움이 됩니다. 추론 시에는 예측된 Z를 \tau로 나누어 원래 오브젝트 중심 정보를 복원합니다.
오브젝트 반경 R도 Z header에 의해 공동으로 학습됩니다. NOCE와 같은 맥락에서 오브젝트 반경 R은 정규화된 scale로 학습됩니다. 그런 다음 최종 예측 R에 Z를 곱하여 원래 객체 크기를 복원합니다.
3) Generating the Metric Scale Mesh
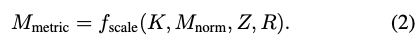
MSOS branch의 마지막 단계는 식(2)와 같이 mesh header의 오브젝트 중심 Z 및 오브젝트 반경 R 추정값을 사용하여 mesh header에서 예측된 정규화된 mesh를 metric scale mesh로 변환하는 것입니다. 여기서 f_{scale}은 Normalized mesh를 카메라 좌표계로 변환하여 카메라 intrinsic parameter K로 metric scale object를 만듭니다.
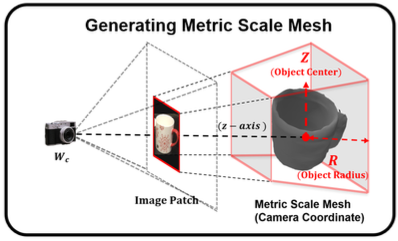
위 그림에서 f_{scale}의 직관적인 프로세스와 detect된 이미지 패치에서 normalized object shape을 metric scale object shape으로 변환하는 방법을 보여줍니다. 원본 2D bounding box, 예측된 Z과 R을 사용하여 f_{scale}은 카메라 좌표에서 3D bounding box를 얻습니다. 그런 다음 normalized 3D bounding box와 예측된 3D bounding box 사이의 keypoint 대응을 사용하여 normalized mesh를 metric scale로 최적화합니다.
B. Depth Rendering
렌더링된 depth map을 얻기 위해 metric scale object mesh를 이미지 평면에 투영하는 방법을 선택합니다. 저자는 metric scale object shape이 depth를 direct regression하는 것보다 pose 추정을 위해 더 적합한 depth를 생성할 것으로 추측한다고 합니다. Depth renderding에는 DIB-R 렌더러, 카메라 고유 파라미터 K, 예측된 metric mesh M_{metric}, 렌더링된 depth map D_{r}을 사용합니다. 저자는 3D 구조를 고려하기 위해 metric scale object surface를 통해 렌더링 되는 저자가 제안한 depth map은 면(face)를 사용하여 각 픽셀 관계로 dense한 깊이를 추정할 수 있었다고 합니다.
C. Pose Estimation
저자는 기존의 NOCS의 접근 방식과 비교를 합니다. 저자가 제안한 방법은 MSOS branch에서 예측된 metric scale mesh에서 렌더링된 depth map D_{r}을 사용했습니다. 렌더링된 깊이 D_{r}과 NOCS N_{c}가 주어지면 Umeyama/RANSAC을 통해 오브젝트의 rotation, translation, size를 추정합니다.
D. Loss
마지막으로 Loss 파트입니다.
저자는 전체적인 프레임워크를 학습시키기 위해 MSOS branch에서 loss function을 도입했다고 합니다. 앞서 봤듯이, MSOS branch에는 Mesh header, Z header 이렇게 두 개의 header가 있었는데요. 먼저 Mesh header를 학습시키기 위해서 Mesh R-CNN의 Voxel loss \zeta_{\mathrm{voxel}}과 normalized mesh loss \zeta_{{M_\mathrm{norm}}}을 적용했다고 합니다.
- Voxel loss : Quantization된 Voxel grid에서 측정된 BCE(binary cross entropy)
- Normalized Mesh loss : 예측된 point cloud와 GT point cloud 사이의 Chamfer distance
- mesh의 예측 및 GT surface의 법선 벡터 사이의 inner product, shape-regularizing edge loss
Z header의 경우, 반경 loss \zeta_R과 저자가 제안한 Normalized Object Center Estimation(NOCE) loss \zeta_{Z_\mathrm{NOCE}}를 적용했는데, 해당 loss는 간단하게 smooth l_{1} loss입니다.
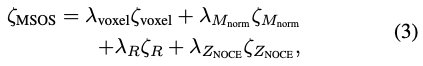
최종적인 MSOS loss는 식(3)과 같습니다. 앞의 \lambda는 가중치 파라미터라고 합니다.
IV. EXPERIMENTS
Datasets.
- train : CAMERA300
학습을 위한 300만 개의 합성 이미지로 구성, 25만 개는 평가 이미지입니다. train set에는 병, 그릇, 카메라, 캔, 노트북, 머그잔 등 6가지 카테고리에서 선택한 1085개의 객체 instance가 포함되어 있고 eval set에는 184개의 서로 다른 instance가 포함되어 있습니다.
- eval : CAMERA25, REAL275
해당 데이터셋 구성은 train set에는 7개의 scene, real 이미지 43000개, eval set에는 6개의 scene, real 이미지 2750개가 포함되어 있습니다. 여기에는 6개 카테고리의 42개 고유 객체가 포함되어 있습니다.
Metrics.
3D detection과 6D pose을 평가하는 NOCS의 평가 지표를 따랐다고 합니다.
- 3D Detection
IoU를 다양한 threshold에 따른 AP(Average Precision)를 계산하여 리포팅
- 6D Pose
rotation과 translation error에서 AP를 계산하여 리포팅
- Metric Scale Object Shape
Chamfer distance와 Normal consistency를 계산하여 리포팅
- Depth
RMSE를 계산하여 리포팅
A. Ablation study

표(1)은 다양한 설계에 대한 평가를 위해 수행한 표라고 합니다. 학습과 평가는 모두 CAMERA 데이터셋에서 진행됐다고 합니다.
Depth rendering
저자는 UNet-based depth estimation과 비교하여 성능을 리포팅했는데요. 표(1)에서 첫 두행을 비교하면, 예측된 metric scale mesh와 함께 depth rendering을 사용하여 얻는 것이 성능이 더 높은 것을 볼 수 있습니다.
‘-’ 라고 표시된 것은 UNet은 3D 오브젝트의 metric scale shape을 예측하지 않으므로 이렇게 표시를 해놨다고 합니다.
Object Center Estimation
저자는 오브젝트의 중심을 추정하기 위해 NOCE를 제안했었습니다.
표(1)의 두 번째 행을 보면 NOCE를 사용하지 않고 바로 입력 이미지 패치로부터 객체 중심 Z를 direct regression한 결과 입니다. 표(1)의 전반적인 내용은 NOCE와 shared encoder를 사용하면 성능이 향상되는 것을 보여주는 표였습니다. 저자의 초점은 3D shape의 chamfer distance와 6D pose 및 크기, 10cm 10^\circ, 3D IoU에 맞추고자 하였고 이러한 지표들은 물체 중심 Z와 물체 반경 R 예측과 직접적으로 관련이 있었기 때문이라고 합니다. 즉 NOCE는 성능을 향상시키는데 크게 기여한 것으로 보인다고 합니다.
B. Comparison with state-of-the-art
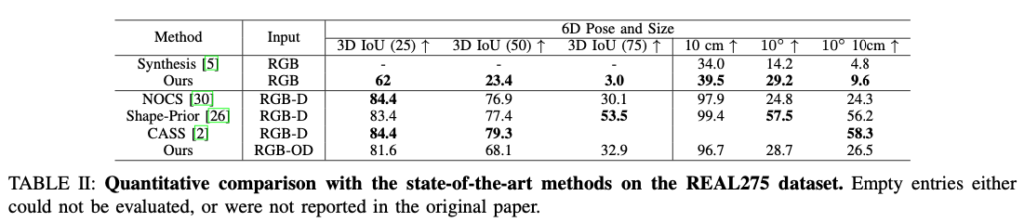


V. CONCLUSION
이번에는 단일 RGB만을 사용하여 Category-level 오브젝트의 Metric scale shape과 6D pose를 추정하는 방법을 살펴보았습니다. 2개의 branch로 나뉘게 되며 MSOS branch는 Metric Scale Object Mesh를 예측하고, NOCS branch는 NOCS map을 예측합니다. MSOS branch에서는 3D 볼륨 정보를 사용하여 기하학적으로 정렬된 오브젝트 중심 예측을 유도하기 위해 shared feature encoder를 사용하는 NOCE를 제안합니다. 예측된 metric scale mesh와 NOCS map 간의 유사도를 측정하여 최종 metric scale mesh, 6D pose, size를 inference합니다. 당시 RGB 기반으로는 SOTA의 성능을 보여주었고, RGB-D 기반으로는 동등하거나 더 나은 성능을 보여주었습니다.
카메라 기하학적인 요소는 요긴하게 사용하는 방법들이 많은 것 같습니다. 특히 6D 분야는 매번 볼 때마다 발상하는 방법이 새롭고 어렵네요. 해당 방향으로도 논문을 많이 읽어야 할 것 같다고 생각이 드는 논문이었습니다.
감사합니다.
안녕하세요 양희진 연구원님 좋은 리뷰 감사합니다.
Metric Scale Object Shape Branch에서 궁금한 점이 있습니다. MSOS가 instance semgenation에 의해 crop된 이미지를 바탕으로 3d mesh를 생성하는데, mesh header는 mesh의 형태를, z header는 mesh의 scale을 결정하는 것이라고 이해하였습니다. 이때 mesh header에 의해 normalized mesh를 추정한다고 하셨는데, 이 과정이 어떻게 진행되는지 잘 이해가 되지 않습니다. Mesh R-CNN과 유사한 방식으로 추정된다는 언급이 있었는데 해당 부분은 학습이 어떻게 진행되는 것인지 궁금합니다. 아니면 다른 3d mesh 데이터로 사전 학습된 모델인가요?
안녕하세요, 천혜원 연구원님.
normalized 과정은 Mesh R-CNN을 사용하여 한 것으로 보입니다. 저도 [Mesh R-CNN](https://openaccess.thecvf.com/content_ICCV_2019/papers/Gkioxari_Mesh_R-CNN_ICCV_2019_paper.pdf)이라는 것을 처음봐서 잘 모르겠지만 해당 논문의 task가 3D shape을 만드는 것을 목표로 하기 때문에 해당 모델을 사용하여 3D mesh를 만드는 방법을 사용한 것이라고 이해를 했습니다. 2D bounding box로부터 3D Voxel을 만들고 마지막으로 3D Mesh를 만들어 최종적인 3D shape을 만들어 normalize를 했다고 봅니다. 해당 논문에서 사용하는 Mesh R-CNN의 학습 방법은 Voxel loss와 Normalized mesh loss를 사용하여 구성을 했다고 합니다.
감사합니다.
좋은 리뷰 감사합니다.
여기서 MSOS는 어떤 모델을 이용하는 건가요? 사전 학습 모델일까요?
전반적으로 구성된 모듈들이 사전 학습된 모델들을 활용하지 않으면 초기 학습 조차 어려울 것 같은 느낌이 드네요.
왠지 사전 학습된 NerF 모델을 활용하는 느낌인데… 단일 영상으로 가능한 것도 신기하네요…
안녕하세요, 김태주 연구원님.
NOCS branch는 사전학습된 모델을 가지고 사용하였고, MSOS branch는 처음부터 학습을 진행했다고 합니다.
감사합니다.
좋은 리뷰 감사합니다.
본 논문은 scale 정보가 부족한 상황에서 MSOS branch에 scale을 고려할 수 있도록 네트워크를 디자인하여 기존 연구인 NOCS branch와 합친 것으로 이해하였습니다.
리뷰와 관련하여 몇가지 질문이 있습니다.
우선, metric scale object shape이 depth를 direct regression하는 것보다 pose 추정을 위해 더 적합한 depth를 생성할 것으로 추측한다고 하셨는데, 이를 추가적으로 설명해주실 수 있나요? intrinsic 파라미터 등을 고려하기 때문인가요?
또한, similarity transformation가 무엇인지 설명해주실 수 있나요? NOCS에 얼마나 Similarity Transformation을 적용해야 Rendered Depth 형태가 나오는지를 구하여 pose와 scale을 추정하는 것인가요? 이 과정은 어떤 네트워크로 구성되는지도 궁금합니다.
마지막으로, Table 2와 3을 보면, ours 방식에 depth를 활용하는 논문들이 있는데, 이때 depth가 추가되면 어떻게 네트워크가 변형되는지에 대한 설명과 RGB-OD의 O는 어떤것을 의미하는 지 알려주시면 감사하겠습니다.
감사합니다.
안녕하세요, 이승현 연구원님.
Q. metric scale object shape이 depth를 direct regression하는 것보다 pose 추정을 위해 더 적합한 depth를 생성할 것으로 추측한다고 하셨는데, 이를 추가적으로 설명해주실 수 있나요? intrinsic 파라미터 등을 고려하기 때문인가요?
A. 아무래도 rendering을 하면 학습하는 데에는 계산하는 cost는 좀 더 클 수 있겠지만, 3D geometry 정보를 좀 더 고려하므로 좀 더 적합하지 않나라고 생각하고 있습니다.
Q. similarity transformation가 무엇인지 설명해주실 수 있나요? NOCS에 얼마나 Similarity Transformation을 적용해야 Rendered Depth 형태가 나오는지를 구하여 pose와 scale을 추정하는 것인가요? 이 과정은 어떤 네트워크로 구성되는지도 궁금합니다.
A. Similarity Transformation은 Umeyama algorithm을 의미합니다. 렌더링된 depth로부터 NOCS branch의 결과와 비교하기 위해 Umeyama 알고리즘을 사용하여 회전, 크기 조절 및 평행 이동과 같은 기하학적 변환을 정확하게 추정하기 위해 사용하는 것으로 보입니다. 네트워크라기 보다는 PnP와 같이 그런 기하학적 변환이라고 보시면 될 것 같습니다.
Q. Table 2와 3을 보면, ours 방식에 depth를 활용하는 논문들이 있는데, 이때 depth가 추가되면 어떻게 네트워크가 변형되는지에 대한 설명과 RGB-OD의 O는 어떤것을 의미하는 지 알려주시면 감사하겠습니다.
A. 먼저 OD는 Ours Depth입니다. depth가 추가되면 네트워크의 구체적인 변화에 대해 구체적인 언급은 없고, 물체 하나 당 하나의 depth를 사용하는 setup을 사용했다까지의 언급만 있네요.
감사합니다.