안녕하세요, 열네번째 x-review 입니다. 이번 논문은 CVPR 2021에 게재된 Pointformer로 indoor와 outdoor 환경에서 모두 사용할 수 있도록 설계된 3D Object detection을 위한 백본 네트워크 입니다. 그럼 바로 리뷰 시작하겠습니다 !

카메라 이미지와 다르게 3D 포인트 클라우드는 물체의 기하학적인 정보를 제공해줄 수 있지만 분포가 불규칙하다는 단점 때문에 CNN에 직접적으로 사용할 수 없다는 단점이 존재합니다. 그래서 보통 3D detection에서는 포인트 클라우드를 복셀 그리드로 변환하였었는데, 복셀 형태는 sparese 3D convolution을 사용하여 비교적 정확하게 계산할 순 있었지만 효율성과의 딜레마에 빠지게 됩니다. 복셀 그리드를 작게 사용할수록 더 정확할 순 있으나 계산 비용이 더 높아지고 반대로 더 큰 폭셀을 사용하면 복셀 사이에서 raw level에서의 가지고 있던 local 정보를 잃기 쉽습니다. 그래서 2017년 PointNet의 등장으로 raw level의 포인트 클라우드를 직접적으로 모델의 입력으로 사용할 수 있게 되었는데요, 그럼에도 불구하고 여전히 포인트의 sparse함 때문에 permutation invariant와 입력 사이즈에 따라 adaptive함을 가져야 한다는 어려움이 존재하였습니다. 그래서 복셀 기반과 포인트 기반의 representation을 합쳐서 사용하겠다는 Hybrid approach는 복셀 level과 복셀의 각 열 level에서 PointNet 구조를 사용하거나 scene level에서 복셀과 포인트넷 feature을 합치는 방식이었다고 합니다. 그러나 본질적인 두 representation의 차이 때문에 오히려 두 방식을 합치는 것은 서로의 장점을 제한시키는 방향이었다고 합니다. 이러한 한계점을 해결하기 위해서 저자는 tnrasformer을 사용하고자 한 것 입니다. 트랜스포머와 self attention은 permutation invariance를 충족시키고 당시에 이미 2D detection과 classification에서 널리 사용되고 있었습니다. 그러나 3D 포인트 클라우드에 트랜스포머를 적용시키려고 하니 계산 비용이 입력 데이터 사잊에 따라 quadratic하게 늘어난다는 문제점이 존재하였고 이를 해결하기 위해 제안하는 것이 본 논문의 Pointformer로 트랜스포머를 3D 포인트에서 효율적으로 이용할 수 있도록 하는 3D 백본 네트워크 입니다. Pointformer는 3개의 pointformer block과 coordinate refinement module까지 총 4개의 모듈을 제안하고 있는데, 자세한 구조에 대해서는 아래에서 다루도록 하겠습니다.
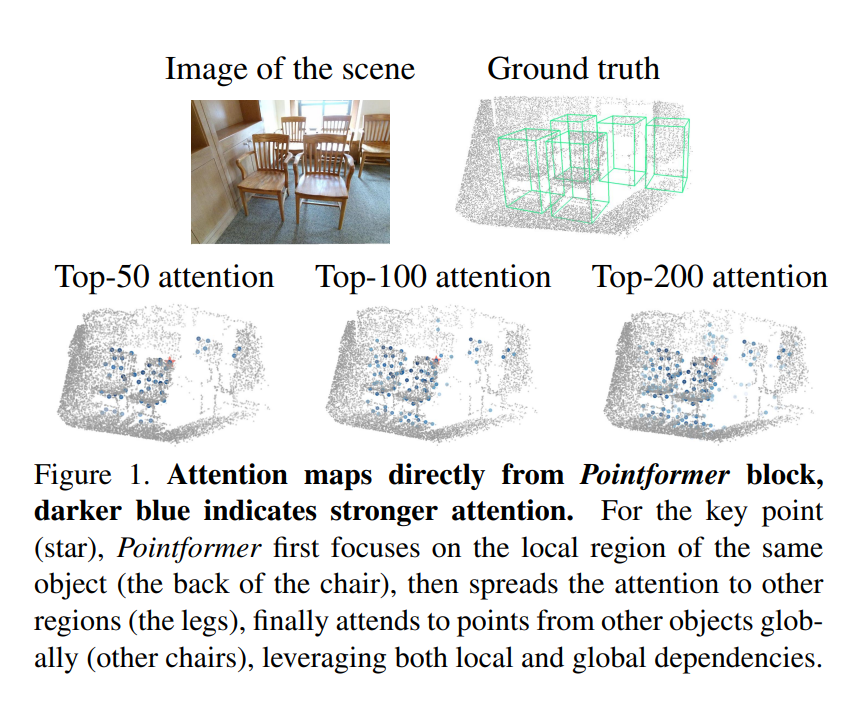
위의 모듈들을 통해 Pointformer는 local, global 정보를 모두 사용할 수 있고 다양한 물체가 배치되어 있는 scene에 대해서도 모든 물체에 대한 특징을 잘 학습할 수 있다고 합니다. Figure 1에서처럼 처음에는 하나의 의자에서 인접한 포인트들에 집중하다가 서서히 주변의 서로 다른 의자끼리의 attention까지 진행하는 것을 시각화하여 확인할 수 있습니다. 또한 본 논문은 backbone 네트워크를 제안하는 만큼 indoor, outdoor 둘 중 하나에 치중한 실험이 아니라 모든 detection dataset에서 범용적으로 사용할 수 있는지를 보여주기 위해 여러 데이터셋에서 실험을 진행하였으며 기존 방법론에서 backbone을 Pointformer로 변경했을 때 유의미한 성능 향상이 존재하였다고 합니다. 여기서 본 논문의 contirbution을 정리하면 아래와 같습니다.
- 3D 포인트 클라우드의 feature을 효율적으로 학습할 수 있는 새로운 transrformer 기반 backbone인 Pointformer을 제안
- 기존 포인트 클라우드에서의 SOTA detector backbone에 교체하여 적용 가능
- 3개의 SOTA detector에 대해 indoor, outdoor 데이터셋에서 높은 성능 향상을 보이며 일반성을 띄는 backbone임을 증명
2. Pointformer
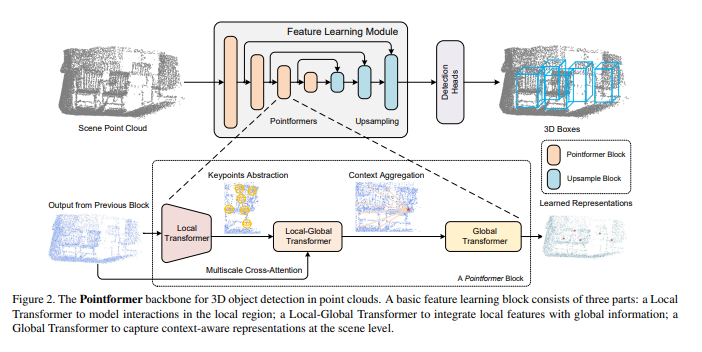
기존에 포인트 클라우드의 feature을 학습하기 위해서는 간단한 symmetric function을 활용하거나 인접한 이웃 포인트들로부터의 정보를 합쳐 GNN의 기술을 사용해왔습니다. 그러나 전자의 경우 context dependent한 feature을 완전히 활용하지 못하여 후자는 인접한 포인트들간의 정보는 사용하지 않고 오로지 중심 포인트와 이웃 포인트 사이의 관계에만 집중한다는 한계가 존재하였습니다. 또한 당시 3D Object detection에서는 global한 representation이 정보로 거의 사용되지 않았다고 합니다. 그래서 Figure2와 같이 local 영역의 모든 포인트 간의 관계를 파악할 수 있으면서 global한 정보까지 함께 사용할 수 있는 Pointformer을 제안하게 된 것 입니다. Pointformer는 U Net 구조로 multi scale의 Pointformer block으로 구성되어 있습니다. Pointformer block이라고 함은 트랜스포버 기반의 모듈로 Local Transformer(LT), Local-Global Transformer (LGT), Global Trnasformer (GT) 모듈 세 가지로 나눌 수 있습니다. LT가 먼저 이전 block의 high resolution 포인트 집합을 출력을 입력으로 받아 local한 영역을 low resolution의 새로운 포인트 집합을 만들고 LGT는 두 resolution의 feature을 합치기 위한 cross attention 모듈 입니다. GT는 context-aware한 global representation을 위한 모듈이며 추가적으로 LT에서 FPS로 샘플링한 포인트들의 중심점의 위치와 feature을 개선하기 위한 coordinate refinement module까지가 Pointformer의 전반적인 구조이며 아래에서 하나씩 살펴보도록 하겠습니다.
2.1. Background
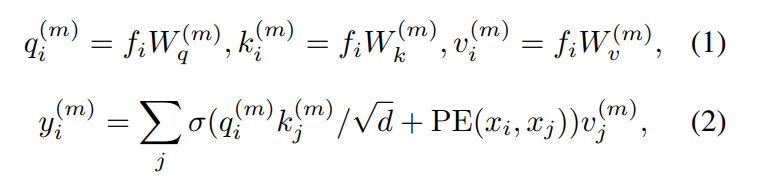
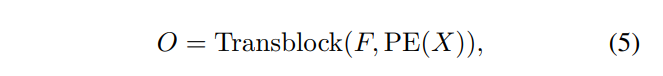
일반적인 트랜스포머 구조를 먼저 살펴보면 F = \{f_i\}, X - \{x_i\}로 정의할 수 있는데 각각 입력의 feature와 위치를 의미합니다. 트랜스포머 block은 multi head self attention 모듈과 FFN으로 이루어져 있습니다. 여기서 기억해야 할 점은 앞으로의 방법론에서 이러한 트랜스포머 block을 식(5)와 같이 정의겠다는 점 입니다.
2.2. Local Transformer
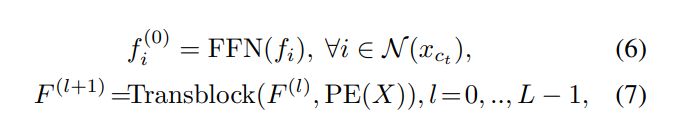
이제 Local Transformer부터 하나씩 살펴볼텐데요, 먼저 입력으로 포인트 클라우드 P = {x_1, x_2, . . ., x_N}이 주어지면 center가 되는 포인트들을 고르기 위해서 FPS로 샘플링을 합니다. 그러면 {x_{c1}, x_{c2}, …, x_{cN’}}이라는 중심 포인트 집합이 새롭게 생성할 수 있고, 해당 집합으로 원래 PointNet++에서의 ball query를 적용하여 사전에 주어지는 반경을 기준으로 반경에 들어가는 K개의 포인트들을 모아 하나의 그룹으로 만듭니다. t개의 중심 포인트를 샘플링했다고 가정하면 t번째 집합의 local region을 {x_i, f_i}로 정의할 수 있습니다. x_i는 local region 안에 속한 포인트들의 좌표이고 f_i는 각 포인트의 feature가 되어 L개의 transformer block layer local region에 모두 적용되며 이를 식으로 표현하면 (6), (7)과 같습니다.
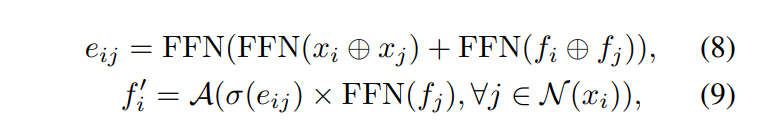
여기서 저자는 그래프 학습 기반의 파라미터가 LT 모듈에 근사화될 수 있다고 이야기하는데요, 식(8)과 (9)는 LT의 local region 내의 두 포인트 간의 관계를 계산하는 과정을 일반적인 그래프 feature learning 식으로 나타낸 것으로 여기서 \oplus는 concat, plus, 내적 중 선택하여 사용되며 edge function인 e_{ij}는 {x_i, x_j, f_i, f_j}에 대한 최대 quadratic function으로 정의할 수 있습니다.
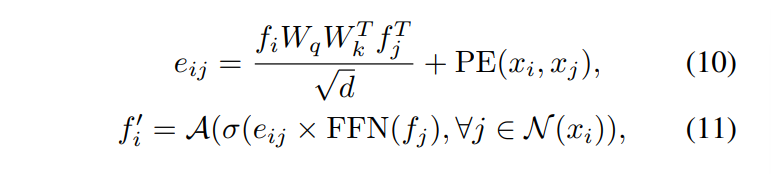
이러한 그래프 학습 모듈을 Transformer block의 하나의 layer에 대한 self attention 메커니즘으로 식(10), (11)과 같이 표현할 수 있는데, 여기서 d는 f_i와 f_j의 feature 차원을 뜻합니다. self attention 식으로 변환하였으나 e_{ij}는 여전히 동일하게 \{x_i, x_j, f_i, f_j\}에 대해서 quadratic function으로 정의할 수 있다고 합니다. FFN에서 충분히 많은 수의 layer가 쌓이게 되면 그래프 기반의 feature learning 모듈은 하나의 transformer encoder layer와 동일한 feature 표현력을 가질 수 있게 되는데 Pointformer의 경우 L개의 transformer layer을 쌓게 되어 보다 나은 representation과 feature을 추출할 수 있게 됩니다.
Local Transformer에서 특히 강조하는 점은 흔히 다른 모델에서는 중심 포인트만 중요하게 여겨지며 소위 말하는 edge들의 feature들은 무시되기 마련이지만 detection에서 그러한 이웃 포인트들이 informative한 경우가 존재하기에 저자는 local region 내에 존재하는 모든 포인트들가의 관계를 계산하기 위해 설계한 모듈이라고 합니다. 따라서 인접한 포인트들 간의 dense한 self attention 계산이 가능해지면 local feature 추출이 더 효과적으로 발생할 수 있게 되는 것 입니다.
2.3. Coordinate Refinement
2.2.에서 포인트를 샘플링할 때 FPS를 사용한다고 했는데요, FPS라는 것은 널리 사용되고 있는 포인트 클라우드 샘플링 방식 입니다. 하나의 포인트를 기준으로 가장 거리가 먼 포인트를 샘플링 대상으로 삼기 때문에 비교적 물체의 본래 모양을 유지하면서 균일한 샘플링이 가능하다는 장점이 존재합니다. 그러나 FPS는 outlier에 민감하여 real world 포인트 클라우드를 다룰 경우에 샘플링이 불안정해질 수 있습니다. 또한 물체가 occlusion 되어 있거나 물체에 대한 포인트가 충분히 확보되지 않았을 경우 물체의 기하하적인 정보를 추론하기가 어려워진다는 단점이 존재합니다. 포인트 클라우드가 대부분 물체의 표면에 대해서 표현된다는 것을 고려해보면 기하학적인 정보를 추론할 수 없다는 단점은 샘플링한 포인트와 GT 사이의 차이가 커지는 요인이 되며 detection에 치명적일 수 있습니다. 따라서 FPS로 샘플링한 중심 포인트들의 정확도를 개선하기 위해서 제안한 것이 self attention map을 이용한 point coordinate refinement 모듈 입니다. refinement 모듈은 모든 attention head에서 트랜스포머 block 마지막 레이어의 self attention map에서 중심 포인트에 대한 특정 행들의 평균을 구하여 가중치 벡터로 사용합니다.
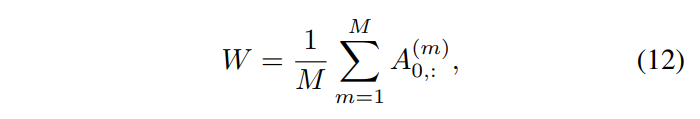
M은 attention head의 개수, A^{(m)}은 m번째 헤드에 대한 attention map을 의미합니다.
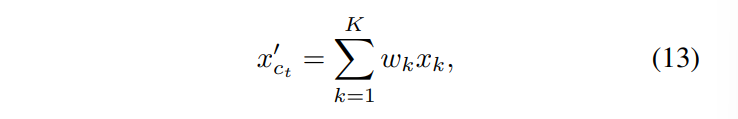
즉 아까 ball query로 K개의 인접한 포인트를 그룹화 한다고 하였으니 그룹화하여 만든 local region의 모든 포인트에 대해 가중치를 곱하여 새로운 refine 된 중심 포인트가 정해집니다. 식(13)에서 w_k는 k번째 가중치이고 이러한 가중치를 각 포인트들에 곱해줌으로써 실제 물체의 중심과 더 비슷하게 가까워진 중심 포인트를 이동시킬 수 있습니다.
3.4. Global Transformer
여기서 Global이라고 함은 서로 다른 물체 사이의 correlation을 의미하며 이전에 PointNet++이나 복셀에서의 sparse 3D convolution은 global 정보를 표현하기 위해 receptive field를 넓히곤 했지만 그러한 모델은 long-range interaction에 한계가 존재하였습니다. 따라서 long-range interaction이 가능하면 global한 포인트들, 쉽게 이야기하면 전체 포인트 간의 관계를 계산하기 위해 제안된 것이 Global Transformer(GT)입니다. GT ahebfdpsms 모든 포인트가 하나로 모아진 P라는 그룹이 입력으로 들어가고 모듈을 식으로 나타내면 아래와 같습니다.
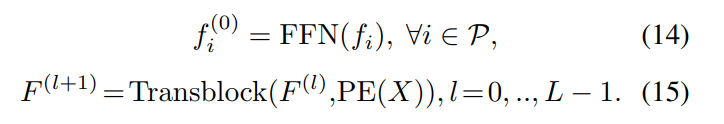
같은 scene에 존재하는 모든 포인트들 간의 관계를 파악하는 것이기 때문에 scene level에서 transformer을 이용했다고 말할 수 있으며 이러한 global 정보를 representation이 필요한 궁극적인 이유는 매우 적은 포인트만으로 물체를 검출해야 하는 상황에 효과적으로 사용할 수 있기 때문이라고 합니다.
3.5. Local-Global Transformer
Local-Global Transformer (LGT) 모듈은 Figure2에서 명시한 것처럼 multi scale cross attention을 계산하는데, LT의 출력인 중심 포인트(low resolution)와 LT 모듈을 들어가기 이전의 포인트(high resolution) 사이의 계산이 이루어집니다.
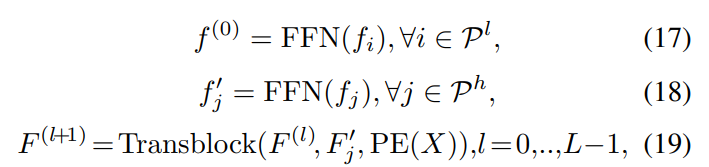
P^l은 LT를 거친 중심 포인트를 포함한 keypoint 집합이며 P^h는 Pointformer block를 들어오는 입력 포인트의 집합을 의미합니다. LT의 출력이 query이고 high resolution의 포인트들을 key와 value로 사용하게 됩니다. 위의 식처럼 cross attention을 통해서 LT에서의 중심점을 scene 영역에 적용하여 global 정보와 합쳐져 GT의 입력으로 들어갈 수 있는 형태로 변형하고자 LGT 모듈을 설계한 것 입니다.
2.6. Positional Encoding
본 논문에서는 포인트의 좌표 자체가 local한 구조를 나타낼 수 있는 중요한 특징을 간주하는만큼 position encoding의 역할이 중요하다고 표현하며 변형된 position encoding을 제안합니다. 모든 transformer 모듈에서 query 포인트와 key 포인트의 좌표를 빼줌으로써 encoding에 둘 포인트 간의 상대적인 좌표를 사용한다는 것 입니다.
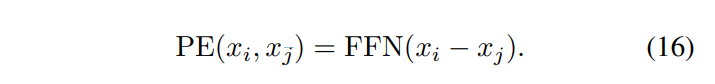
논문에서는 positional enocoding에 대한 위의 설명 이외의 추가적인 이야기는 없었기에 .. LT 뿐만 아니라 GT에서도 동일한 positional encoding을 사용하는 상황에서 local한 구조를 나타내기 위한 상대적인 좌표라고 표현하는 것이 옳은 것인지 잘 모르겠습니다만 아마도 LT에서처럼 동일한 object 간의 local한 관계라기보단 attention 하는 대상인 두 포인트에 대한 상대적인 위치를 활용하기 위해 변형한 것이라고 이해하였습니다.
3. Experimental Results
Pointformer는 백본 네트워크로 기존 SOTA detection 모델의 백본을 Pointformer로 대체함으로써 성능이 어떻게 변화하는지 확인하는 방식으로 진행하였습니다. outdoor와 indoor 환경에서 모두 범용적으로 사용할 수 있는 백본인지 증명하기 위해 oudoor 데이터셋인 KITTI와 nuScenes, 그리고 indoor 데이터셋인 SUN RGB-D와 ScanNet V2을 사용하였습니다.
3.1. Outdoor Datasets
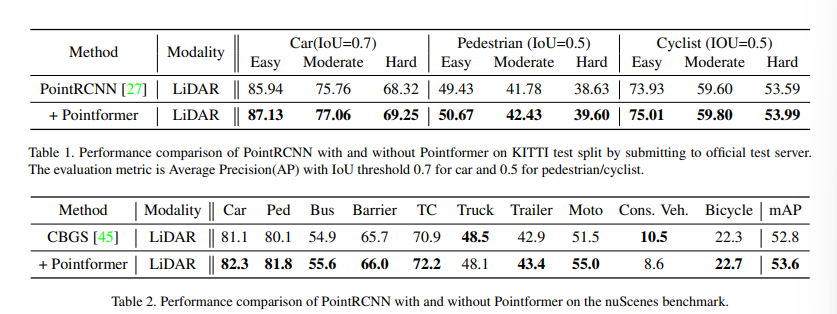
먼저 KITTI에서 PointRCNN 모델을 사용하였는데, PointRCNN은 백본으로 원래 PointNet++을 사용하였는데 이를 Pointformer로 변경한 결과가 Table1 입니다. Pointformer을 적용하기 이전과 비교했을 때 모든 카테고리와 level에서 성능 개선이 되었음을 확인할 수 있습니다. 두 번째로 nuScenes에서 실험을 진행하였는데 nuScenes는 KITTI에 비해 데이터셋의 크기도 크고 물체의 수와 카테고리 종류 역시 더 다양한 데이터셋 입니다. 또한 물체의 클래스 사이에 imbalance 문제가 존재하는 데이터셋이기 때문에 KITTI보다 더 challenge한 데이터셋이라고 할 수 있습니다. Table2를 보면 기존 SOTA 모델인 CBGS를 베이스라인으로 사용하였고 Pointformer로 교체했을 때 베이스라인 대비 0.8mAP 향상한 것을 확인할 수 있습니다. 이를 통해 large scale의 challenge한 데이터셋에서도 성능을 개선하는 효과를 기대할 수 있음을 보였습니다.
3.2. Indoor Datasets
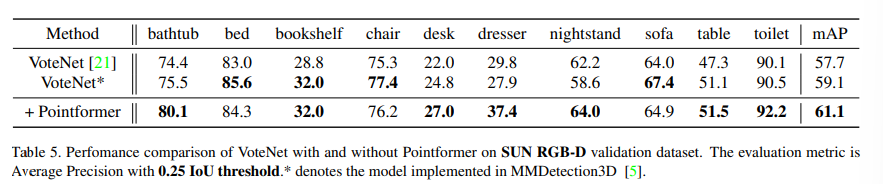
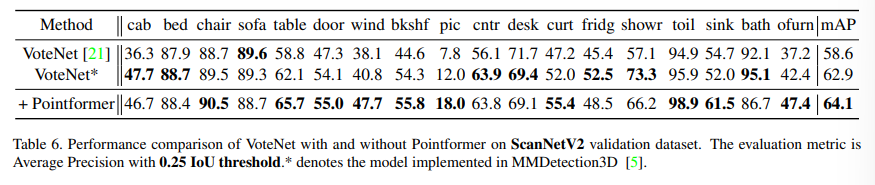
다음은 Indoor 데이터셋에 대한 실험으로 먼저 SUN RGBD(Table 5)에서는 VoteNet을 베이스라인으로 설정하였습니다. 베이스라인 대비 2%의 mAP 향상을 달성하였고 SUN RGBD에서 크고 어려운 물체에 속하는 dresser나 bathub에서도 5% 이상의 성능 향상을 보이며 local하지 않은 feature을 추출하는 GT가 긍정적인 영향을 주었음을 알 수 있다고 합니다. ScanNet V2도 마찬가지로 기존 VoteNet 대비 1.2% 개선되었음을 보여주고 있습니다.
3.3. Ablation Study
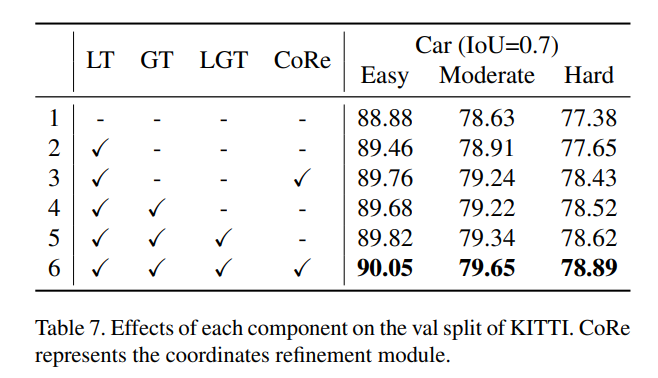
제안한 LT, GT, LGT, CoRe 모듈이 어떤 영향을 주는지에 대한 Ablation Study 입니다. 2번째와 4번째 행을 통해 어려운 물체를 검출하는데에는 GT가 더 적절하게 사용되고 있음을 알 수 있고 첫번째와 두번째 행에서 데이터셋이 Easy level에 해당하면 LT가 약 0.6%의 성능 향상에 기여하고 있습니다.
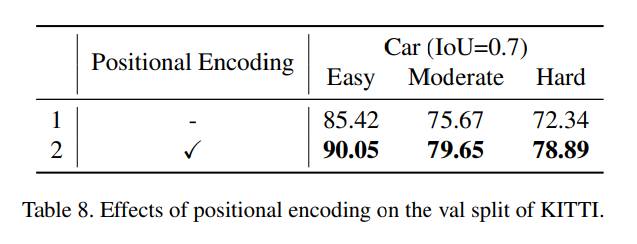
마지막으로 두 포인트의 좌표 차이를 통해 상대적인 position encoding을 제안하였는데, 제안한 encoding의 효과를 보여주는 Ablation Study 입니다. Pointformer에서 제안한 Positional Encoding을 사용하지 않을 경우에 모든 난이도의 데이터셋에서 5-6%의 성능 하락이 발생하면서 포인트 간의 local한 기하학적 정보를 유지하다는 것이 중요하다는 것을 확인하면서 리뷰 마치도록 하겠습니다.
안녕하세요, 좋은 리뷰 감사합니다.
간단한 질문이 있는데, 식(8)에서 ⊕ 기호는 concat. element-wise, inner product 중 하나를 사용한다고 하셨는데, 상황에 따라 연산이 달라지도록 설계를 한 것인지 아니면 실험을 통해 성능이 향상된 연산 방법을 찾아서 수행하는 것인지 궁금합니다.
감사합니다.
안녕하세요 ! 리뷰 읽어주셔서 감사합니다.
질문해주신 부분에 대해서는 말씀하신 것처럼 상황에 따라 연산이 달라지도록 설계를 한 것이라고 말씀드릴 수 있을 것 같습니다 !
좋은 리뷰 감사합니다.
몇 가지 질문 드리고 가도록 하겠습니다.
1. 2.2. Local Transformer에서 notation이 헷갈려서 질문 드릴게요.
1-1. FPS로 추출한 t 개의 중심 포인트를 선정하면 중심 포인트들의 집합은 {x_{c_1}… x_{c_t}} 가 되어야 할 것 같은데 맞나요? 기존 포인트 수 N이랑 같아서 헷갈리네요…
1-2. 중심 포인트에만 관심을 가지던 기존 방법론과 다르게 주변 포인트과 중심 포인트 간의 연관성을 고려하는 점은 좋은 방식인 것 같습니다. 그런데 초기 주변 포인트의 feature f_i는 어떻게 구하는 건가요?
1-3. 수식 11의 A()는 뭘 의미하는 건가요?
2. Coordinate Refinement
w_i는 W에 속하는 건가요? 차원이 궁금하네요. 그리고 multi-head attention은 뭐에 대한 multi-head인지 헷갈려요.
3. local level에서 attention을 수행하는건 비용이 꽤 비쌀 것 같네요. 사용한 GPU랑 모델 크기, 추론 속도가 궁금해요
논문의 notation이 굉장히 불친절하네요. 같은 걸 반복해서 쓰니깐 어질…
1-1. 샘플링한 포인트의 수를 처음에는 N’이라고 표현하는데, N’ == t개와 동일하게 생각해주시면 될 것 같습니다.
1-2. 논문에서는 이전 block에서의 출력이라고 해서 이미 feature가 뽑혀져 있는 상태인데, 코드를 확인해보니 mmdet에서 ConvModule이라는 모듈을 통과한 feature을 사용하는것으로 보아 간단하게 conv layer을 태운것으로 생각됩니다.
1-3. A는 feature aggregation을 위한 aggregation function 입니다.
2. 네, w_i는 W의 k번째 weight vector 입니다. coordinate refinement에서 말하는 multi-head attention은 Local Transformer에서 PE와 feature가 입력으로 들어가는 attention의 head를 의미합니다.
3. GPU 같은 경우엔 nvidia gpu로 깃허브에 표기만 해놓고 정확히 어떤 gpu를 썼는지는 명시가 안 되어 있고, 나머지 모델 크기나 추론 속도에 대해서도 적어놓은 부분이 없네요 .. 추가적으로 찾게 되면 공유하도록 하겠습니다 !
안녕하세요. 좋은 리뷰 감사합니다!
FPS를 통해서 하나의 포인트에서 가장 거리가 먼 포인트가 샘플링의 대상이 된다고 말씀해주셨는데 여기서 샘플링이 되는 포인트는 모두 중심포인트로 사용되는 것인가요 ? 아니면 따로 중심점을 뽑는 과정이 있는것인가요 ?
또 하나 궁금한 점은, 그룹화를 위해 ball query라는 방식을 사용하는 것 같은데 정확히 어떤 동작하는 것인지 궁금하여 질문 드립니다.
그리고 FPS로 샘플링한 포인트가 불안정해질 수 있다는 것은 어떤 의미인가요 ? 정확히 와닿지 않아 추가적인 설명부탁드리겠습니다.
감사합니다.
안녕하세요 ! 리뷰 읽어주셔서 감사합니다.
샘플링되는 포인트는 모두 중심 포인트로 사용되는 것으로, 뽑은 중심 포인트에서 ball query를 통해 기존 포인트에서 K개의 주변 포인트를 모아서 그룹화하는 것 입니다.
ball query를 PointNet++에서 제안한 방식인데, 단순히 반지름 r을 정해서 중심점 기준 반지름 반경 내에 존재하는 K개의 점을 하나의 그룹으로 여기는 것을 의미합니다.
그리고 샘플링 포인트가 불안정하다는 것은 occlusion처럼 본래 물체의 형태를 파악하기 어려운 상태에서 FPS로 샘플링을 해도 샘플링한 포인트는 본래 포인트 클라우드로 얻은 포인트 이상으로 물체의 형태를 표현할 수 없기에 불안정하다고 표현한 것 같습니다.
안녕하세요 손건화 연구원님 좋은 리뷰 감사합니다.
pointformer의 idea는 3D 포인트 클라우드를 처리하는 두 가지 방식인 voxel과 point 기반 representation을 fusion할 때 오히려 성능이 저하되는 문제점을 transformer를 사용하여 해결한 것이라고 생각하였는데요, 리뷰를 읽다보니 LT, LGT, GT모두 point representation을 이용한 것 같습니다. 그렇다면 이 방법론은 fusion이 아니라 단순히 point 기반의 방법론인가요?
또한 transformer의 과도한 연산량이라는 단점을 해결하기 위해 저자들이 새롭게 제안한 것이 Pointformer라고 이해하였는요, 구체적으로 어떤 부분에서 quadratic한 연산량 증가라는 단점이 해결되었는지 잘 모르겠습니다… Local Transformer에서 downsampling이 일어나는 것 때문 같기는 한데 해당 부분에 대해 추가적인 설명 부탁드립니다.
안녕하세요 ! 리뷰 읽어주셔서 감사합니다.
음 본 논문이 해결하고자 하였던 것은 복셀과 포인트 representation을 fusion 할 때의 성능이 저하되는 문제를 해결하는 것이 아니라 포인트만으로 PoitNet++을 통해서 detection 할 수 있게 되었지만 여전히 포인트의 sparse함이 문제가 되었고 이를 해결하기 위해 복셀과 fusion을 하려니 두 방식의 차이 때문에 오히려 성능이 저하 되었기 때문에 복셀을 사용하지 않고 transformer을 사용하여 포인트만을 효과적으로 사용할 수 있는 백본을 제안하고자 한 것이 메인 idea 입니다.
그리고 연산량 측면에서 GT와 LGT transformer block의 layer들을 기존 transformer layer가 아니라 포인트를 처리하는데 O(n^2)에서 O(n)으로 연산량을 줄였던 Lineformer의 layer들로 대체하여 사용함으로써 연산량을 줄였다고 합니다.