제가 diffusion model에 대해 큰 관심을 가지고 있다는 것은 연구실에 계신 분들은 다들 아실거라고 생각합니다. 이번 리뷰 논문이 이에 대해 보여줄 수 있는 논문이라고 생각합니다.
이번에 들고온 논문은 diffusion model을 이용하여 mono-depth와 optical flow에서 좋은 성능을 보여준 논문입니다. 복잡한 모델 구조나 추가적인 loss 없이 좋은 결과를 보여줍니다. (단, 대용량 합성 데이터 포함해서 학습해야만 한다는 점…)

Intro

많은 분들이 아시다시피 최근 Diffusion model은 high fidelity (=실제 같은) 영상을 생성하는 결과를 보여줌으로써, GAN을 뛰어 넘는 생성 모델로 주목 받고 있습니다. 하지만 GAN 또한 그런 것처럼 리얼 월드로부터 cue를 얻어 값을 추론하는 태스크에서는 효과적인 결과를 보여줄지에 대해서는 불분명한 견해가 있었습니다. 대표적인 예시로 두 프레임 사이의 대응되는 픽셀로부터 정보를 추론하는 mono-depth와 optical flow가 있죠. 두 태스크는 일반적으로 회귀 문제로서 두 프레임 간의 유사성을 찾기 위한 목적으로 설계된 모델 구조와 각 태스크 별 특정 손실 함수로 문제를 해결했습니다. 이처럼 특수성을 고려한 회귀 프레임워크가 없으면 일반적인 생성 모델로는 일반화 및 성능 개선에 있어 취약하다는 문제가 있습니다.
저자는 위 두 태스크를 고려한 모델 설계와 손실 함수 없이 일반적인 image-to-image translation을 위한 diffusion model이 두 태스크에서 모두 좋은 결과를 보여주며, 일정 부분에서는 SOTA를 능가하는 성능을 보여줍니다. 무엇보다 일반적인 회귀 모델들은 예측 결과에 대한 uncertainty과 ambiguity 보일 수 있다는 장점을 가집니다. 이에 대한 결과는 fig 1에서도 확인 가능합니다.
또한, 저자는 diffusion model을 제대로 학습하기 위해 많은 양의 데이터를 필요하다는 문제를 해결하기 위해 실제 데이터와 합성 데이터를 사용하여 supervised pre-training 도중에 multi-task self-supervised pre-training으로 구성된 training pipeline을 제안합니다. (해당 기법은 inpainting과 colorization 태스크에서 좋은 결과를 보여준 사례가 있으며, 실제로 성능이 크게 향상된 결과를 보여줍니다.)
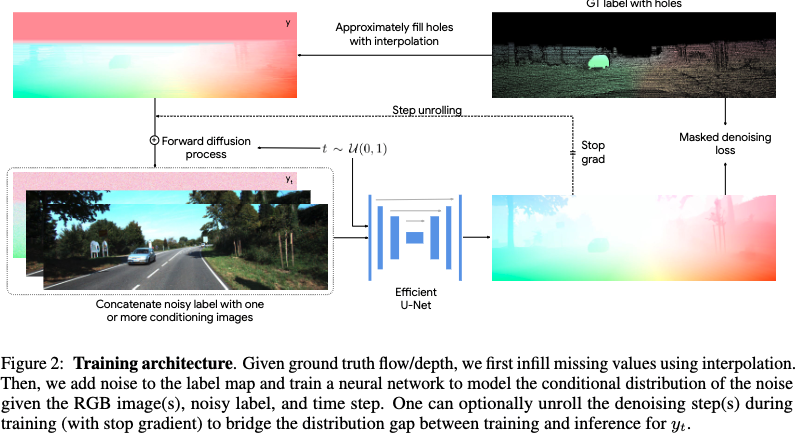
더 나아가서, depth와 optical flow의 기존 리얼 데이터 셋에는 노이즈가 많고 불완전한 ground-truth label이 있다는 점에 문제를 제기합니다. 이점은 diffusion model의 훈련 프레임워크~반복 샘플링에서 문제를 야기시키며, 훈련과 추론 사이의 distribution shift 문제를 발생시킵니다. 이러한 문제를 해결하기 위해 견고성을 위한 L1 loss와 훈련 중 infilling missing depth values를 수행, step-unrolled denoising diffusion을 사용할 것을 제안합니다.
++ infilling missing depth values: 말 그대로 소실된 값 채우기. step-unrolled denoising diffusion: GT 대신 예측 값으로 예측하기
++ fig 2-오른쪽 상단의 GT label with holes와 같이 실제 세계에서 취든된 GT들은 누락된 정보가 많음
+ Diffusion model
Diffusion model은 가우시안 노이즈 샘플을 데이터 분포의 샘플로 변환하도록 훈련된 생성 모델입니다. Diffusion model은 time t가 0에서 1로 증가함에 따라 노이즈를 추가하여 데이터를 점진적으로 소멸시키는 ‘forward process’와 t = 1의 무작위 노이즈 샘플에서 시작하여 t가 0으로 감소함에 따라 점진적으로 감쇠 노이즈를 추가하는 학습된 ‘generative (reverse) process’로 구성됩니다. Conditional Diffusiom model은 reverse process의 단계(e.g. label, text, image)에 조건이 부여됩니다.
해당 프레임워크의 중심에는 conditioning signal x 와 함께 time-step t에서의 noisy sample y_t 를 취해 노이즈가 덜한 sample을 취하도록 학습된 denoising network f_{\theta} 로 구성됩니다. forward process에서의 가우시안 노이즈를 이용하여 시간에 따라 (t가 줄어드는 방향) 점진적인 변화 값에 대해 L2 loss를 이용하여 학습을 진행합니다. 이에 대한 수식은 아래와 같습니다.
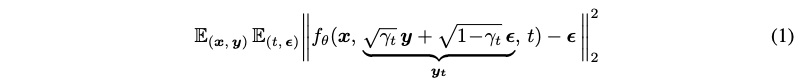
Method
Model Framework
기존 monocular depth와 optical flow methods이 전문화된 도메인 지식을 활용하여 모델 구조를 설계한 것에 반해, 저자는 아주 간단하고 일반적인 모델 구조와 loss functions을 활용합니다. 기존 SOTA 모델 구조와 losses의 inductive bisa를 real and synthetic data를 이용한 combination of self-supervised pre-training와supervised training를 대체합니다.
fig 2에서도 볼 수 있다시피, 해당 모델은 conditioning signal (one RGB image for depth and two RGB images for flow)와 함께 노이즈가 가해진 target map (i.e., a depth or flow)을 입력으로 받습니다. 해당 모델에서의 denoiser는 노이즈가 없는 target map을 추정하며, trinaing loss는 노이즈가 제거된 맵의 residual error를 통해 추론됩니다. 해당 방법은 기존 태스크에서 흔히 사용하는 image reconstruction losses와는 다른 방식입니다.
Synthetic pre-training data and generalization
해당 모델은 task 측면에서의 모델 디자인과 loss로 추론되는 inductive bias 없이 단순한 노이즈 제거를 목표로 모델을 훈련합니다. 그렇기에 저자는 학습 데이터의 퀄리티와 양이 중요하다고 합니다. 특히, dense vision task는 실제 세계에서 측정된 데이터는 데이터 확보가 어렵기 때문에 수가 굉장히 적다고 합니다. 이러한 문제를 해결하기 위해 훈련 중에 합성 데이터를 활용하는 방식들이 많이 사용합니다.
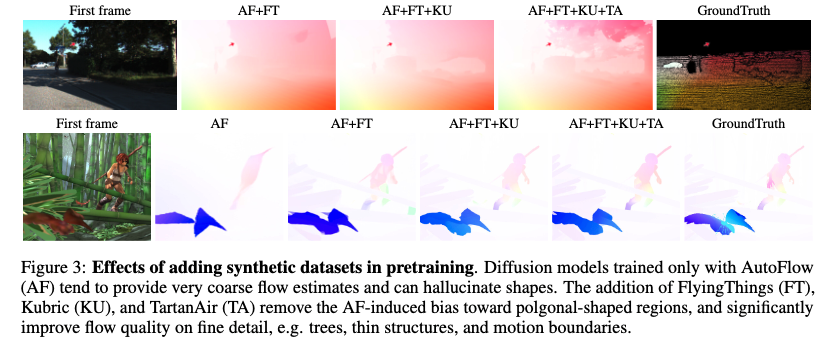
저자는 먼저 flow models 학습에 많이 활용되고 있는 합성 데이터 셋인 AutoFlow (위 그림 A1 참고)를 이용하여 학습을 진행하였습니다. 놀랍게도 AutoFlow만으로는 불충분한 결과를 보였습니다. fig 3과 같이 AutoFlow에서 보이는 다각형 형태의 구조를 유지하려는 편향을 보이며, 심한 경우에는 conditional input의 shape 조차 무시하는 결과를 보여줍니다.
AutoFlow로 인한 편향 문제를 해결하기 위해 추가적인 합성 데이터 FlyingThings3D, Kubric, TartanAir을 활용하여 학습을 진행합니다.
+ 데이터 셋 혼합 비율에 대해 greedy mixing strategy를 구축했다고함. 적절한 mixing strategy에 대해서는 향후 연구에 맡긴다는 글을 토대로 비율에 따른 성능 변화가 있는 것으로 보임. 아쉽게도 이에 대한 분석 내용이 없음.
Sintel and KITTI에서 Zero-shot testing을 통해 추가 합성 데이터를 이용한 성능 향상을 보여줍니다. 추가로 depth estimation에서도 pre-training을 중요하다는 결과를 tab 7에서 보여주며, indoor에서는 ScanNet과 SceneNetRGB-D, outdoor에서는 Waymo Open Dataset을 이용하였다고 합니다.
Real data: Challenges with noisy, incomplete ground truth
Real data은 많은 노이즈를 가질 수밖에 없습니다. 예를 들어, 반사율이 높거나, 흡수율이 높은 물체들로 인해 정확한 측정이 어려우며, 센서 자체의 노이즈가 발생한 경우 혹은 센서 자체의 한계로 인해 노이즈가 발생합니다. 이러한 특성으로 인해 일부 정보가 소실된 경우가 많으며, 따로 valid map을 제공하거나 생성하여 학습을 진행합니다. 기존 모델들은 픽셀 별로 예측 값에 대한 회귀를 진행하기 때문에 확인된 정보만을 이용한 학습이 쉽습니다. 반면에, diffusion model은 픽셀 별 예측이 아니라는 문제도 있으며, 이전 time step의 정보로부터의 distribution shift가 존재하기 때문에 GT로 인한 노이즈로 인한 영향을 크게 받습니다.
저자는 이러한 문제를 해결하기 위해 몇 가지 기법을 적용하여 완화시켰으며 이는 다음과 같습니다.
- Infilling : GT의 빈 공간 채우기. 저자는 nearest neighbor interpolation만으로도 충분한 결과를 얻을 수 있다고 주장합니다. 또한 fig 2와 같이 Masked denoising loss를 통해 기존에 있던 값들에 대해서만 예측을 수행하도록 했기에 문제가 안된다고 주장합니다.
- Step-unrolled denoising diffusion training : filled GT로 구성된 y_t 대신에 model로부터 예측된 y_pred로부터 노이즈 예측하기(alg 1에서 자세히 확인 가능). 초기 학습 단계에서는 예측된 값이 GT보다는 모델이 예측한 값이 보다 나은 결과를 보여준다고 합니다. 이에 대한 직관적인 이유는 fig 2에서 모델이 예측된 값과 filled GT (fig 2-왼쪽 상단)을 보면 알 수 있습니다.

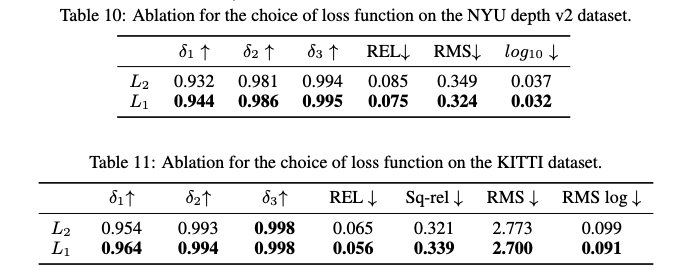
3. L1 denoiser loss. 저자가 주장하길 L2 loss는 노이즈가 존재하지 않는 GT에서 강인하기 때문에 상대적으로 outliner에 강인한 L1 Loss를 이용하여 학습할 것을 제안합니다. 이에 대한 결과는 tab 10-11에서 볼 수 있습니다.
Coarse-to-fine refinement.
고해상도의 영상을 이용할 경우, 해상도의 크기에 따라 diffusion model의 성능이 향상된 결과를 보여줬습니다. 저자는 이러한 특성을 고려하여 특정 타임 t에서 영상을 overlap되도록 패치 단위로 자른 다음 bicubic interpolation을 이용하여 기존 target 해상도로 업샘플링한 다음 fine하게 예측하도록 합니다.
+ 2×5 overlapping patches, Sintel we use t′ = 32/64 and for KITTI t′ = 8/64. ~ {자른 step}/{총 step}
Experiment
저자는 기본적인 Diffusion model인 DDPM의 U-net을 Efficient UNet으로 변경하고 Palette[1] style self-supervised pretraining을 적용했다고 합니다. 각 태스크에 따라 적절한 입력과 출력을 가지도록 약간의 변경을 수행했다고 합니다. Depth task에서는 diffusion의 예측 값이 [-1, 1]을 가짐으로, [10m, 80m]으로 정규화를 진행했습니다. flow task에서는 GT의 높이와 너비로 정규화를 진행했습니다.
[1] Chitwan Saharia, William Chan, Huiwen Chang, Chris A. Lee, Jonathan Ho, Tim Salimans, David J. Fleet, and Mohammad Norouzi. Palette: Image-to-Image Diffusion Models. In SIGGRAPH, 2022.
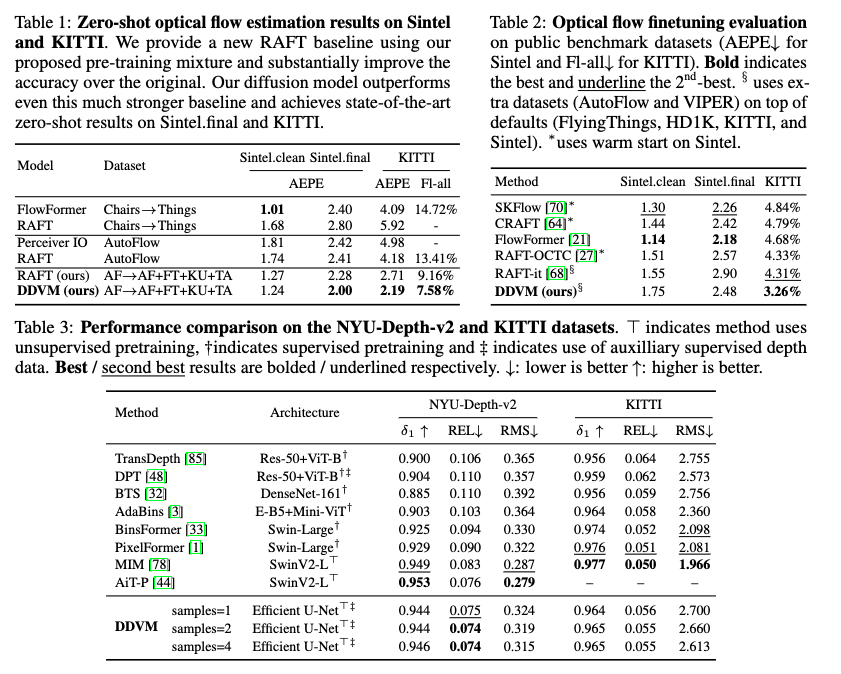
Evaluation on benchmark datasets.
- Depth. Tab 3에서 NYU-v2의 REL에서는 SOTA을 달성했으며, KITTI에서도 SOTA 대비 경쟁력 있는 결과를 보여줍니다.
- Flow. Tab 1 (Zero-shot)에서 sintel과 KITTI 모두 좋은 결과를 보여주고 있습니다. 공평한 비교를 위해 합성 데이터를 이용한 학습 기법을 RAFT에서도 동일하게 수행했으며, 개선된 성능을 보여주고 있으나 제안한 모델에서 더 좋은 성능 (정성적 결과는 Fig 4)을 보여주고 있습니다.
Tab 2 (fine-tunning)에서 KITTI에서는 SOTA 결과를 보여주고, sintel에서는 SOTA 기법에 버금가는 결과를 보여줍니다. 여기서 상기해야하는 부분은 해당 모델은 도메인 측면에서 설계된 모델 구조나 손실 함수 없이 경쟁력 있는 결과를 보여주고 있다는 점이겠죠.(정성적 결과는 Fig 5)

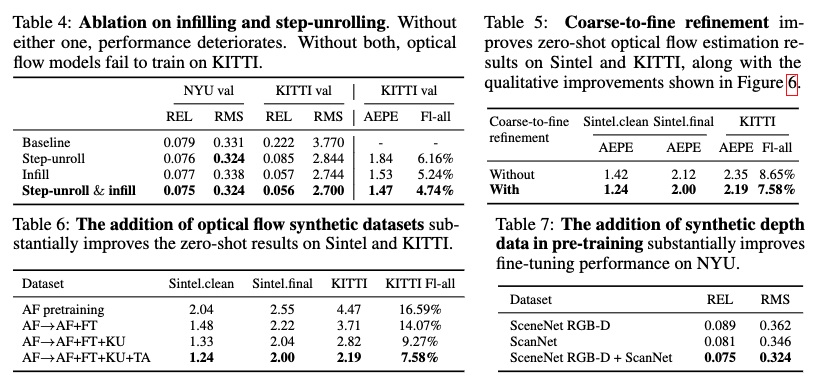
Ablation study
- Infilling and step-unrolling. Tab 4에서 보이는 바와 같이 데이터의 누락이 심한 KITTI에서는 두 기법이 없는 경우에는 추론이 불가한 모습을 보여주고 있으며, 두 기능을 함께 사용했을 때 가장 좋은 성능을 보임
- Coarse-to-fine refinement. Tab 5와 fig 6에서 개선된 결과를 보여줌
- Datasets. Tab 6-7, fig 3에서 보이는 바와 같이 많은 합성 데이터를 사용할 경우에 개선된 성능을 보여줌

Interesting properties of diffusion models
- Multimodality. Diffusion model의 강점 중 하나는 complex multimodal distributions 잘 포착한다는 점입니다. 이런 장점은 불확실성을 예측하는데에 효과적이며 이러한 강점은 모호한 경우, 예를 들어 반사율 혹은 흡수율이 높은 물체나 경계가 모호한 경우에서 그럴싸한 결과를 잘만드는 결과로 이어집니다. 정성적인 결과는 fig 1에서 볼 수 있습니다.
- Imputation of missing labels. fig 7과 같이 누락된 라벨이 발생한 경우에도 그럴싸한 예측을 잘 수행함
- Limitations. 가장 기본 모델을 사용했기에 개발된 Diffusiom model 대비 큰 모델, 느린 속도를 가지고 있음. Tab 15 참조

++ L1 and L2 loss
해당 논문은 Diffusion model을 이용한 mono depth, optical flow 모델 개발 논문이 아닌 분석 논문에 가깝다고 보는 것이 맞는 것 같습니다. 모델도 가장 기본적인 DDPM을 사용하되, 최소한의 변경을 했다고 봅니다. 다른 분들도 해당 논문을 통해 어떠한 통찰이 있었으면 합니다.
제가 생각했을 때, Diffusion model의 장점이자 단점은 모호한 부분을 포착하고 이를 그럴싸하게 만든다는 점이라고 봅니다. 이런 특성은 수 많은 데이터로부터 얻어지는데 수 많은 데이터의 구성에 따라 모델의 성능 혹은 표현력은 천차만별로 달라질 것이라고 예상합니다. GPT도 그렇고 Diffusion model도 그렇고 데이터의 중요성은 나날이 커져 가는 것 같습니다.