안녕하세요, 열 네 번째 X-Review입니다. 이번 논문은 AAAI 2021에 게재된 MANGO:A Mask Attention Guided ONe-Stage Scene Text Spotter입니다. 바로 리뷰 시작하겠습니다 ?

1. Introduction
전통적인 scene text spotting 방법론들은 보통 1) 먼저 이미지에서 text가 존재하는 영역을 검출한 다음, 2) 원본 이미지에서 검출한 text 영역을 crop한 후, 3) 마지막으로 crop한 영역 내의 단어가 어떤 단어인지 인식하는 순으로 동작합니다.
이렇게 동작하는 text spotting 방법론들은 아래와 같은 몇 문제점이 있습니다.
- 에러가 축적될 수 있다는 점
- text detection , text recognition을 각각 분리하여 다루는 것은 cost가 크게 든다는 점
- 다양한 application에 적용하기 어렵다는 점
여기서 첫번째 문제점인 에러가 축적될 수 있다는 것이 무엇이냐면, 가장 먼저 수행되는 text 영역을 검출하는 단계에서 detection 모델이 text 영역을 제대로 검출하지 못하게 되면 이 error가 뒷 단 recognition 부분에도 영향을 미친다는 것입니다.
그렇기에 이후에 많은 방법론들이 이전처럼 text detection을 수행하고 그 다음 recognition을 수행했던 2 stage 방법론에서 벗어나 이 둘을 한 번에 수행하는 end-to-end 방법론들을 제안하기 시작했습니다. 보통 이렇게 end-to-end로 동작하는 방법론들은 RoI operation을 사용하여 detection과 recognition을 연결하고자 하였죠. 초기 end-to-end text spotting 방법론들은 기울어지지 않은 직사각형 모양의 RoI(x축과 평행한 직사각형 RoI)를 사용했었습니다. 그때문에 곡선이 있거나, 원근감이 있는 text같이 irregular한 text instance들을 처리하지는 못했습니다.
이런 문제를 해결하고자, 후에 나온 방법론들은 irregular한 text instance를 잘 추출하고, 이를 regular한 모양으로 수정하는, shape-adaptive RoI 방식이 등장하기도 했습니다.
text detection이후 text recognition을 수행하는 2 stage방법에서는 recognition 부분이 detection한 text 위치 결과에 크게 의존하게 된다고 했었죠, 이건 다시 말하면 detection 파트에서 정확한 text boundary를 검출하여 background에 영향을 받는 부분을 제거할 수 있어야 함을 의미합니다. 따라서 robust한 text detection 모델을 학습하기 위해서는 irregular한 text spotting에 사용되는 polygon 혹은 mask 어노테이션과 같은 text의 영역을 정확하게 나타내는 detection 어노테이션이 필요하겠습니다. 하지만, 이런 어노테이션을 라벨링하는 것은 비용이 많이 들 뿐더러, text region에 딱 맞게 bounding box를 치는 형태가 recognition task를 수행할 때 최적이라는 것도 보장하기 어렵습니다.
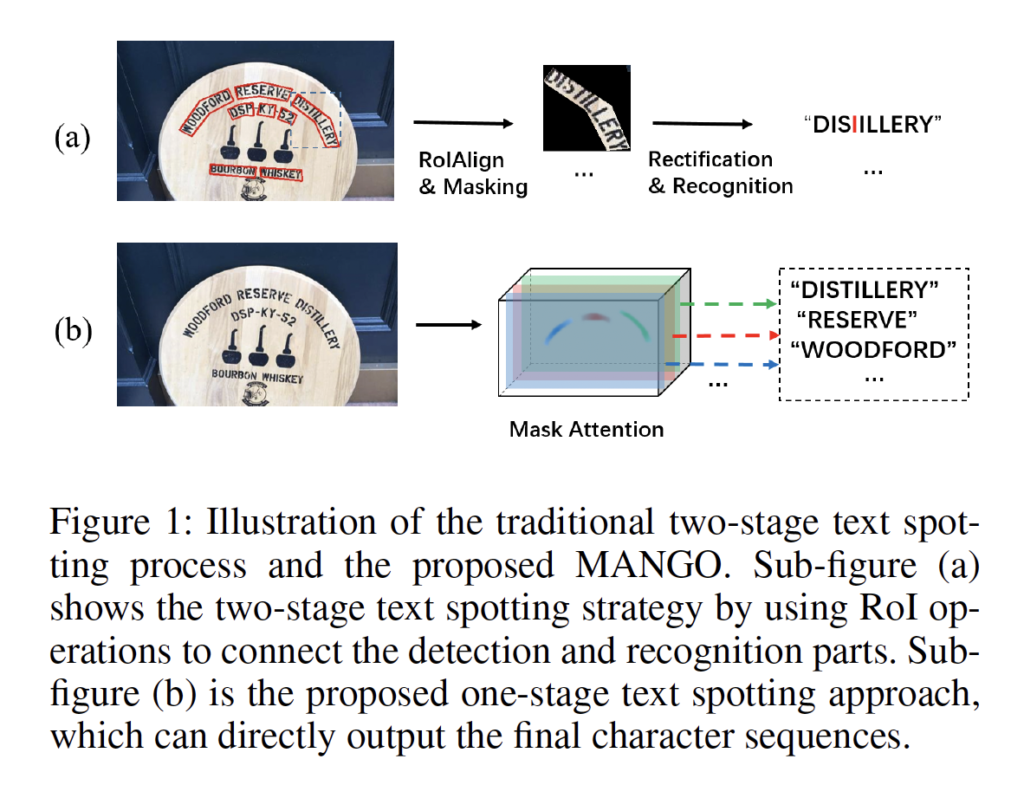
위 그림의 (a)는 RoI operation을 사용하여 2 stage로 text spotting을 수행하는 방법론인데, 보시면 text 영역에 타이트하게 text 경계를 찾아내었습니다. 이 경우 text 바운더리는 문자의 edge texture를 지울 수 있고 이는 곧 잘못된 recognition 결과로 이어지게 되었죠. 이런 경우 수동으로 tight하게 검출한 text 바운더리를 늘려주어야 하는 후처리 과정이 필요하기도 하였으며, 또 NMS를 사용하여 후처리 하는 것도 시간 소모가 꽤 큽니다.
제가 전에 리뷰했던 [Convolutional Character Network]는 ont-stage로 character level의 text spotting 방법론을 제안했었는데, 본 MANGO 논문의 저자는 이 CharNet 논문의 경우 한자같이 class개수가 엄청 많아지는 경우는 다루지 못하며, 이렇게 character level로 text spotting을 수행할 경우 문자 간의 중요한 context 정보를 잃어버린다고 하였습니다. .
저자가 말하기를, 사실 사람들이 글자를 읽을 때는 정확한 text instance의 모양을 볼 필요가 없다고 말하며, 눈으로 보았을 때 대략적인 text의 위치만으로 text를 충분히 식별할 수 있다고 합니다. 여기서 저자는 scene text spotting task를 집중하는 것(attending)과 읽는 것(reading) 문제로 다시 생각해보았습니다. 즉 대략적으로 text의 위치를 attend한 후 한번에 text를 읽어낸다는 것입니다.
본 논문에서는 어떠한 RoI operation없이 이미지에서 모든 text를 한번에 바로 예측하는 1 stage 프레임워크 MANGO(Mask Attention Guided One-sage text spotter)를 제안합니다. 구체적으로 말해, Position-aware mask attention(이하 PMA) 모듈을 도입하여 text region에 spatial한 attention을 생성하도록 하였으며, 이 모듈안에는 instance level의 mask attention인 IMA와 character level의 mask attention인 CMA가 포함되어 있습니다. 이 IMA와 CMA는 각각 이미지 내의 text와 그 text를 구성하는 각각의 character의 위치를 인식하게 되죠.
즉, 이전에 text spotting 방법론 중 text의 영역을 cropping하는 단계가 있었는데 이 단계 대신에 position attention map을 통해 feature를 바로 추출하도록 하였습니다. 이렇게 하면, global한 spatial 정보를 최대한으로 가져갈 수 있게 되겠죠. 여기서 서로 다른 text instance의 feature는 dynamic convolution을 사용하여 서로 다른 feature map channel로 매핑되게 됩니다. [Figure 1]-(b)를 보면 각각의 text instance는 서로 다른 channel에 존재하는 것을 확인할 수 있습니다. 최종적으로 가벼운 sequence decoder를 통해 character sequence를 생성해 냅니다.
본 논문의 contribution은 다음과 같습니다.
- 간단하고 robust한 1-stage text spotting 프레임워크인 MANGO 제안
- position-aware mask attention module(PMA)를 개발하여 text instance feature를 batch로 생성(즉, 한 이미지 내 존재하는 여러 text instance에 대한 feature를 한 번에 생성)
- SOTA
2. Methodology
2.1 Overview
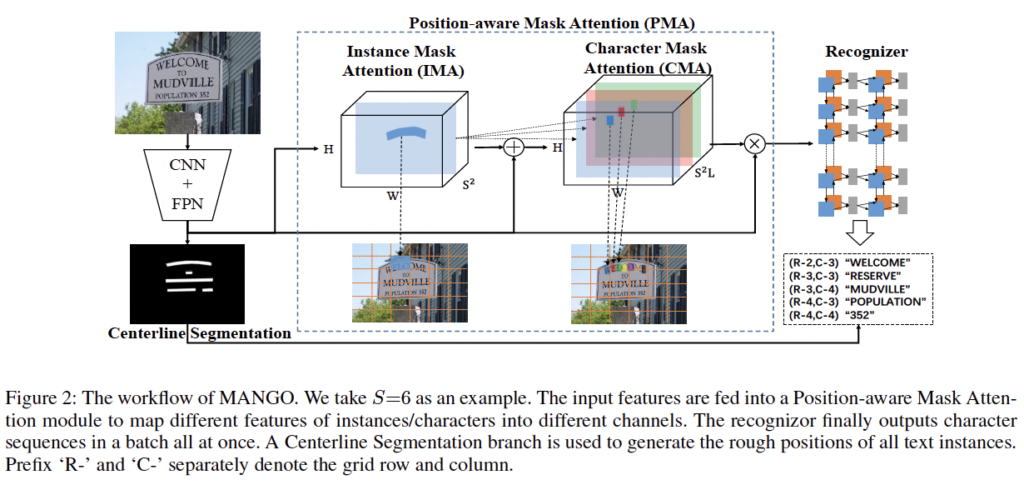
MANGO의 전체적인 구조는 위 그림과 같습니다. backbone으로는 ResNet50와 FPN(Feature Pyramid Network)를 사용하였습니다. 여기서 생성된 feature는 3개의 learnable한 모듈로 들어가게 되는데, 먼저 1) 개별적인 text instance의 spatial attention을 학습하기 위한 Position-aware mask attention(PMA) 모듈(instance-level mask attention(IMA) + character level mask attention (CMA))과, 2) attenting instance feature들을 character sequence로 디코딩하기 위한 sequence decoding 모듈, 마지막으로 3) inference 단계에서 text의 position 정보를 제공하기 위한 gloal text centerline segmentation 모듈입니다. 위 [Figure 2]를 보면, 이미지 아래에 있는 사다리꼴 CNN+FPN을 타고 나온 feature가 방금 언급한 3개의 모듈의 입력으로 들어가는 것을 확인할 수 있습니다.
2.2 Position-aware Mask Attention Module
1-stage text spotting은 단순하게 보자면 원본 이미지에서 text recognition task를 하는 것으로 볼 수 있겠죠. 여기서 중요한 단계라고 하면, detection 모듈이 검출한 text instance와 최종 text recognition 모듈이 인식한 charactr sequence사이에 1:1 매핑을 하는 작업입니다. 여기서 저자는 detection 이후 seqeunce decoding 모듈에서 활용할 수 있는, 모든 text feature을 represenation할 수 있는 position-aware attention(PMA) 모듈을 개발하였습니다. 이 PMA모듈은 [Segmenting objects by locations](이하 SOLO) 논문에서 아이디어를 얻어왔습니다.
SOLO 논문에서 착안해온 아이디어는, 개별적인 instance들이 각각의 서로 다른 특정한 channel로 매핑될 수 있으며, instance- to – feature 매핑이 가능하다는 점입니다. 자세히 말하자면, PMA 모듈을 통해 SxS 그리드로 나눈 입력 이미지가 있을 때, 그 grid 주위에 있는 정보들이 feature map의 특정 채널로 매핑될 수 있다는 것입니다.
정리하자면, backbone network를 통과하여 추출된 x∈\mathbb{R}^{C x H x W}가 PMA의 입력으로 들어가 text intance의 feature representation을 생성하게 되는 것입니다.
Instance-level Mask Attention
이제 PMA 모듈을 구성하는 sub-module인 IMA 모듈에 대해 알아보도록 하겠습니다. 이 IMA 모듈은 instance-level의 attention mask를 생성하고, 서로 다른 instace들의 feature를 서로 다른 feature map 내의 channel로 할당하는 역할을 합니다.
이 모듈은 [Segmenting objects by locations v2](SOLO v2)라는 논문에서 소개된 dynamic convolution kernel을 사용하였습니다. 아까 입력 이미지를 sxs grid로 나눠 어떤 연산을 수행하였다고 언급한 바 있는데, 이 grid 상에서 dynamic convolutional kernel을 이용해 연산을 수행하는 식으로 IMA 모듈이 동작하게 됨니다. 여기서 그리드 shape은 (SxSxC) 입니다.
그럼, 아래 식 (1)과 같이 instance-level의 attention mask는 original feature map에서 이 dynamic convolutional kernel을 적용함으로써 생성되겠습니다.
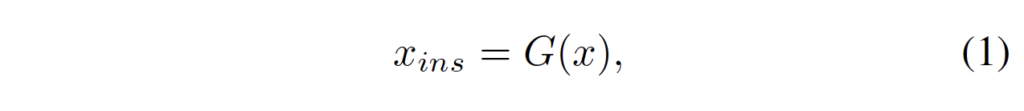
- G : dynamic convolutional kernels
이렇게 나온 x_{ins}는 (S^2 x H x W)의 크기를 가지게 됩니다. channel 수가 SxS가 됐는데, 아까 이미지를 SxS개의 그리드로 나눴고 여기서 각 그리드 하나가 channel 하나와 매핑된다고 이해하면 됩니다.
이 dynamic convolutional kernels G를 학습하기 위해서는 text instance들과 grid간의 매칭이 필요합니다. 일반적인 object detection이나 instance segmentation과는 다르게, text instance들은 보통 엄청 극단적인 aspect ratio를 가지거나 심하게 구부려져 있는 것들이 많기 때문에 text bbox의 center를 바로 grid를 매칭하는데 사용하는 것은 합리적이지 않다고 합니다. 아마 SOLOv1, v2에서는 bbox의 center점을 instance와 grid를 매칭하는데 사용했던 것 같습니다.
하지만 text spotting task에서는 이를 적용하기엔 앞서 언급한 점이 걸리기 때문에 저자는 text instance인 t_i와 grid인 g_i이 얼마나 가까운지 나타내기 위해 occupation ratio o_{i,j}라는 용어를 정의하였습니다.
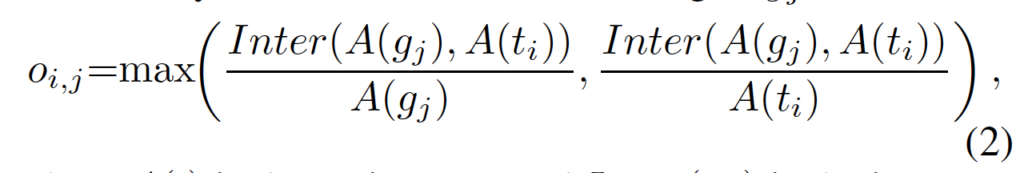
- A(.) : 영역
- Inter(.,.) : 두 영역 간의 교집합 영역
- t_i : i번째 text instance
- g_j : j번째 grid
식은 단순하게 그리드와 text instance 영역간의 겹치는 영역을 나타내고 있습니다. 이 occupation ratio o_{i, j}가 미리 지정해둔 threshold µ보다 클 경우에 text instance t_i가 그리드 g_i를 차지한다고 볼 수 있겠죠. µ는 실험적으로 0.3으로 설정하였습니다.
학습할 때는 occupation ratio를 계산할 때 text instance의 gt region이 아니라 이를 축소한 버전의 region을 사용하였다고 합니다. 이건 아마도 이전 SOLO에서 는 grid와 instance를 매칭할 때 instance의 centerline의 영역을 사용하였기 때문에 이를 따라가려는 부분이라고 생각되네요.
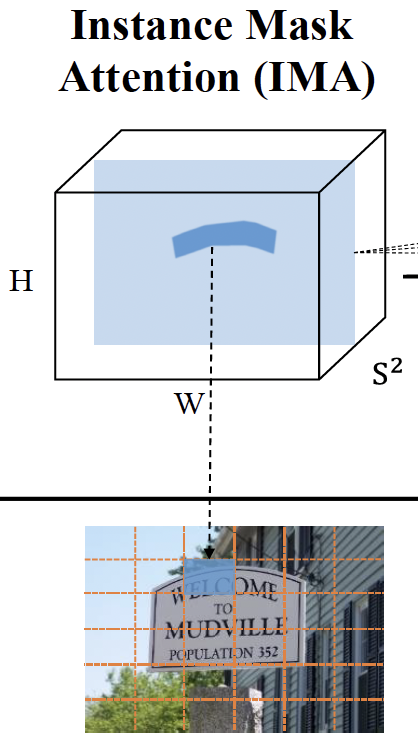
Figure 2를 보며 예를 들어 정리를 해보고 넘어가도록 하겠습니다. 여기서 S=6으로 두어 이미지내 그리드가 6×6개가 나온 것을 볼 수 있습니다. 지금 이미지 내의 text 인 ‘WELCOM’이 위치하고 있는 그리드는 (2행 3열)과 (2행 4열) 그리드이죠. 즉, 9번째 ((2-1) x 6 + 3)와 10번째 ((2-1)x6+4)그리드가 같은 attention mask를 예측할 것입니다. 만약 서로 다른 2개의 instance가 같은 grid를 차기자고 있게 된다면, 간단하게 더 큰 occupation ratio를 가진 것을 선택한다고 하네요.
Character-level Mask Attention
이제 PMA를 구성하는 다른 sub-module인 CMA를 알아보도록 하겠습니다. [Convolutional Character Network]를 포함한 이전 많은 논문들에서 증명됐듯이, character level의 위치 정보는 recognition의 성능을 향상키시는데 도움이 되었습니다. 이런 점은 recognition을 할 때 추가로 세밀한 feature를 제공하기 위한 global character-level attention 모듈을 디자인하는 계기가 되었습니다.
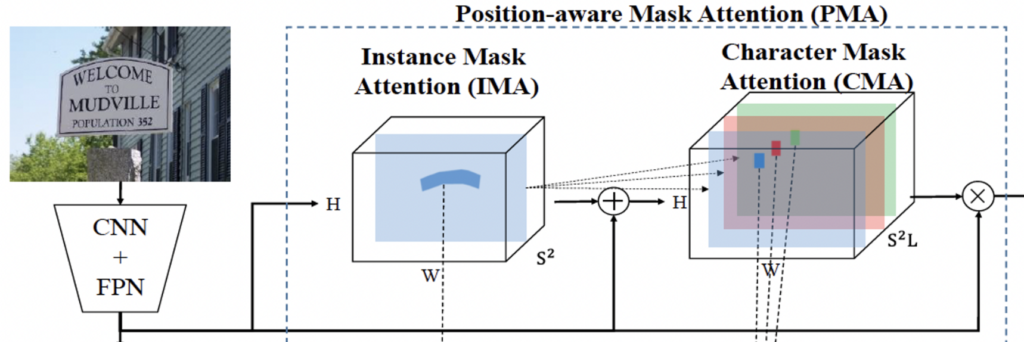
Figure 2에서 CMA 부분만 잘라서 다시 가져와 봤는데, 보시면 이 CMA는 먼저 original feature map x와 IMA 모듈을 통과하여 나온 x_{ins}를 concat합니다. 이후에, 2개의 convolution layer를 통과시켜 character – level의 attention mask를 예측해내게 됩니다. 수식으로는 아래와 같겠죠.
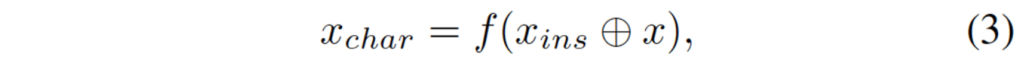
- \oplus : channel-wise concat
이렇게 나온 x_{char}는 ((S^2xL)xHxW)의 shape을 가지게 됩니다. 여기서 L은 사전에 설정된 character string의 최대 길이입니다. 즉, 각 그리드에 대해 문자열 길이 만큼의 channel이 있는 것이죠.
IMA에서의 grid 매칭 과정과 동일하게, 만약 text instance t_i가 (h행, w열)에 위치한 그리드 g_i를 차지하고 있다면, x_{char}의 ((h-1)xSxL+(w-1)xL+k)채널은 text의 k번째 character mask를 예측하고 있는 feature map이 되겠습니다.
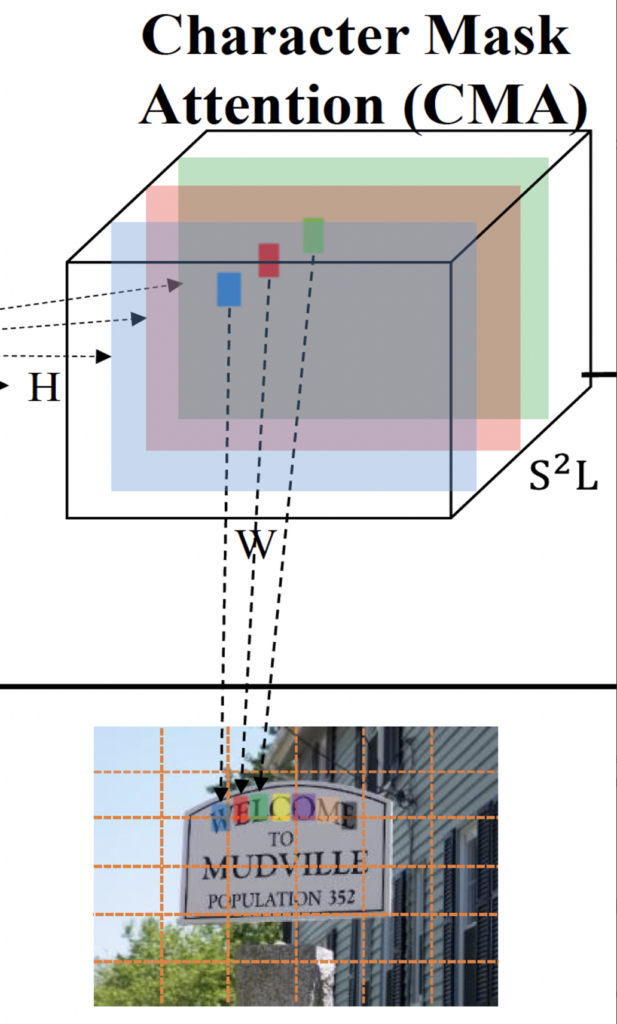
그림을 통해 다시 보면, ‘WELCOME’이라는 단어가 이미지 상에 존재하고 L(사전에 설정한 최대 단어 길이)이 25라고 했을 때, 151번째 channel ((2-1)x6x25 + (3-1)x25+1)이 글자 ‘W’에 대해 예측한 attention mask이고, 152번째 channel이 ‘E’에 대해 예측한 attention mask에 해당합니다.
2.3 Sequence Decoding Module
이제 PMA 모듈을 통해 각 text instance의 attention mask가 서로 다른 feature map channel에 할당되게 되었네요. 이렇게 서로 다른 feature map channel에 할당된 text instance feature를 batch로 묶을 수 있겟습니다.
여기서는 [Decoupled Attention Network for Text Recognition]논문에서 제안한 attention fusion을 수행하면 batch된 sequential한 feature x_{seq}를 생성할 수 있다고 합니다.
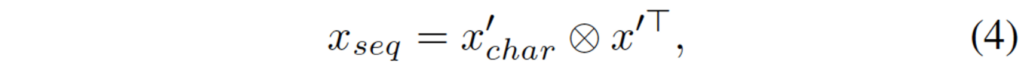
- \otimes : 행렬 곱셈 연산
- x_{seq} ∈\mathbb{R}^{S^2 x L x C}
- x'_{char} : x_{char}의 reshape 행렬
- x’ : x reshape한 행렬
바로 위의 식이 sequential한 feature를 생성하는 식인데요, 간단하게 reshape한 x_{char}과 reshape한 x’ 사이에 multiplication을 취하는 식입니다.
우리는 text spotting을 하는 것이 최종 목표이죠. 이 text spotting 문제는 간단하게 보자면 sequence classification 문제로 볼 수 있습니다. 즉, 다시 말하자면 방금 위의 식으로 sequence decoding을 통하여 character sequence를 생성할 수 있고, 이것이 어떤 단어인지 분류하는 task로 생각할 수 있다는 것입니다.
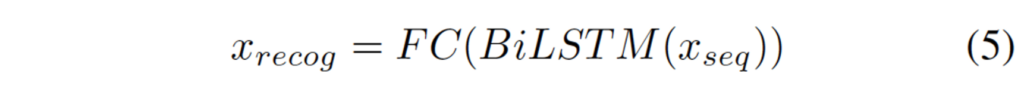
sequence decoding network는 위와 같은데, 단순하게 BiLSTM을 통과한 후 FC layer를 통과시켜 예측한 character sequence를 출력하는 것입니다.
여기서 x_{recog} ∈\mathbb{R}^{S^2 x L x M}이며, M은 character 사전의 크기입니다. 여기서는 26개의 알파벳, 10개 숫자, 32개의 ASCII 부호, EOS(end of string) 심볼로 총 69로 설정되었습니다. 예측한 character string의 길이가 L보다 작게 되면, 나머지 예측들은 EOS 심볼들로 채워져 있게 되는 형식입니다.
x_{ins}의 feature map channel 중 실제 text instance의 attention map이 존재하는 경우는 드물겠죠. 생각해보면, channel 수가 SxS개이고, 여기서는 S를 6으로 뒀기에 36의 grid가 생성되며 각 grid가 한개의 channel에 해당하니 36개의 channel이 생성됩니다. 이 모든 grid를 text instance가 차지하고 있지는 않게 되겠죠, 저자는 x_{ins}의 occupational rate가 일정 threshold가 넘는 경우 즉 positive인 경우에만 학습에 사용하도록 하였습니다. 계산 비용을 줄이기 위해서겠죠.
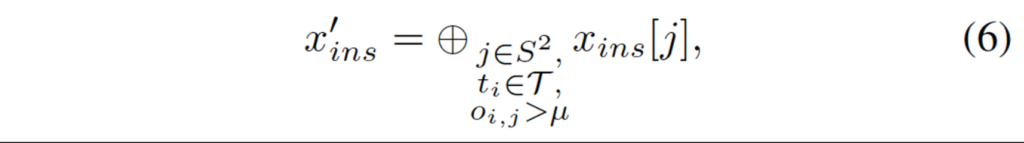
그 식이 위 (6)에 해당하는데, 학습 및 추론 단계 모두에서 위 계산을 한 후 feature map의 potivie channel을 dynamic하게 선택한 후 이후 연산을 진행하였습니다.
2.4 Text Centerline Segmentation
모델은 이제 S^2 개의 grid 각각에 대한 sequence 예측을 할 수 있습니다. 하지만, 만약 한 이미지 내의 2개 이상의 text instance가 존재하게 된다면 어떤 grid가 그 recognition한 결과와 일치하는지 알아내야겠죠. 그렇기에 text detection branch가 필요하게 됩니다.
MANGO 방법론이 정확한 bbox 정보에 의존하지 않기 때문에 RPN이라던지 YOLO같은 타 방법론으로 text instance에 대해 rough한 geometry 정보를 얻어낼 수 있습니다. 여기서 저자는 scene text가 곡선이나 휘어진 것과 같은 arbitrary한 모양을 가질 수 있다는 점을 고려하여 segmentation 기반 text detection 방법론인 [A Flexible Representation for Detecting Text of Arbi- trary Shapes], [Shape Robust Text Detection With Progressive Scale Ex- pansion Network]를 참고하였습니다. 이 text detection branch를 통해 global text centerline 영역 segmentation을 학습하였습니다.
3. Experiments
실험에는 사전학습할 때 합성 데이터셋인 SynthText을 사용하였습니다. 이 데이터셋은 instance-level 어노테이션과 character level의 어노테이션이 둘 다 있기 때문에 PMA 모듈을 학습하는데 사용할 수 있었습니다. 사전학습 이후 finetuning할 때에는 regular한 text 데이터셋과 irregular한 text dataset 둘 다에 대해 학습을 진행했습니다. 학습할 때는 Curved SynthText, COCO-Text, ICDAR-MLT, ICDAR2014, ICDAR2017, total-text 데이터셋을 사용하였으며, test할 때에는 ICDAR2013, 2015, totaltext를 사용하였습니다.
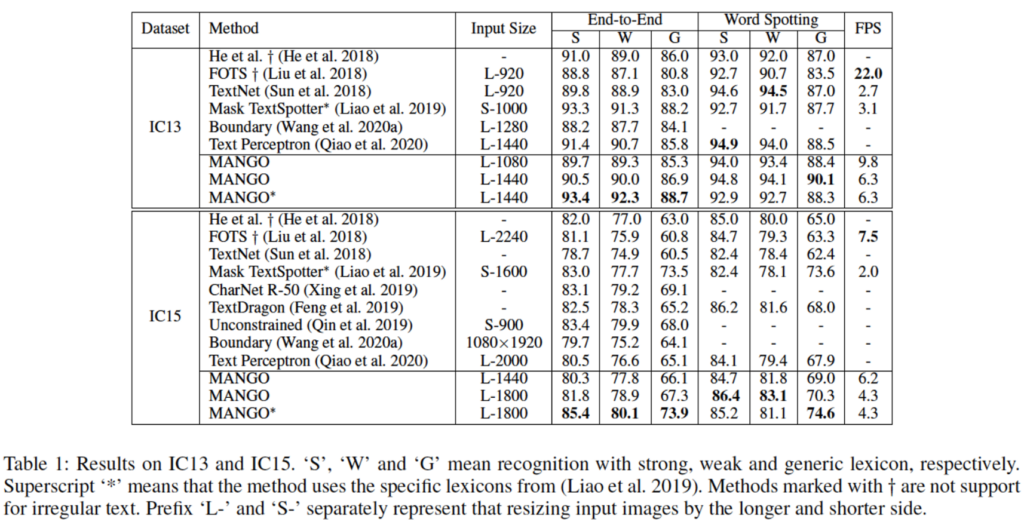
먼저 regular한 text만을 포함한 데이터셋인 IC13, 15에서의 결과를 봅시다. 표에 있는 S, W, G는 각각 Strong, Weak, Generic으로 lexicon(단어 사전)의 단어 개수 차이입니다. 표를 보면 Generic일 경우에 타 방법론과 비교했을 때 SOTA를 달성하였으며, 나머지 S, W에서도 그렇게 나쁘지 않은 성능을 보입니다. 속도 측면에서는 FOTS가 22.0으로 가장 빠르며, 본 방법론 같은 경우에는 inference 속도가 그렇게 빠르지는 않은 것으로 보입니다.
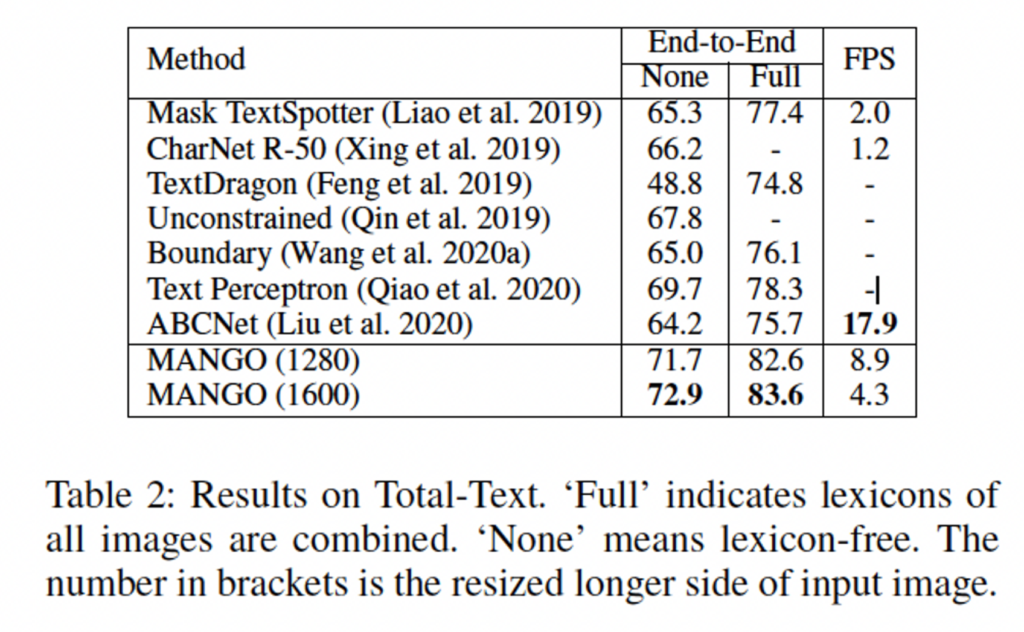
다음으로는 curved되어 있는 irregular한 text만을 포함한 데이터셋인 total-text dataset에 대한 실험 결과입니다. 표의 None , Full은 각각 lexicon을 사용하지 않은 것과, 사용한 것을 구분한 것입니다. 마찬가지로 여기서도 SOTA를 달성했으며, ABCNet과 비교했을 때 속도가 절반 가까이 떨어지지만, 저자는 계속 속도는 좀 느리지만 성능이 잘 나왔다는 것을 어필하고 있습니다.
Ablation Study
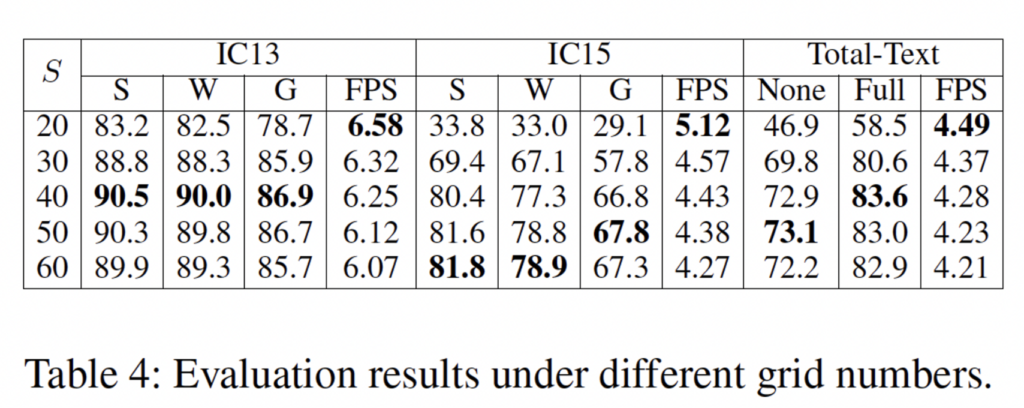
마지막으로 grid 수(S^2)에 대한 ablation study 결과인데요, 만약 S의 개수가 너무 작게 되면, 많은 text가 같은 grid를 차지하게 됩니다. 반면에 S가 너무크다면(gird를 많이 가져간다면) computation cost가 크게 들겠죠.
저자는 위의 세 데이터셋에 대한 실험을 진행한 결과 IC13과 total-text에서는 40이 최적의 결과였으며, IC15는 60이었다고 합니다. IC15만 두 데이터셋과 최적의 gird 개수가 다른 이유라고 하면, IC15는 타 데이터셋보다 더 dense하고 작은 instance를 포함하고 있기 때문이겠죠. 결과적으로 S가 40이상일 때 성능이 잘 나오며, 물론 grid수가 많아질수록 FPS가 감소합니다. 다만,, 40일 때 성능이 더 잘 나오는데 왜 본문에서는 36개의 grid를 사용한것인지는 의문이네요.
안녕하세요, 좋은 리뷰 감사합니다.
dynamic convolutional kernel 이라는 것을 처음 본 것 같아서 간단한 질문을 드립니다.
해당 convolution 연산은 이전 layer의 output에 영향을 받아 adaptive하게 kernel size가 바뀌는 식으로 작동하는 건가요? 만약 맞다면 이미지 내에 존재하는 텍스트들의 크기가 다르기 때문에 해당 OCR task에는 dynamic convolution을 쓰는 게 용이하다고 이해를 해도 되는지 궁금합니다.
감사합니다.
댓글 감사합니다.
우선 리뷰에서 언급한 dynamic convolutional kernel은 SOLOv2논문에서 제안한 것으로 희진님이 말씀해주신 것과 같이 kernel size가 adaptive하게 바뀌는 것은 아닙니다.
원래는 SxS 그리드 크기에 맞게 S^2개의 mask를 생성했었고 결과적으로 SxS 크기의 output channel이 나오게 되는데, instance 중심이 (i, j) 그리드 위치상에 있고, 1x1xC크기의 conv kernel을 G_i,j, 단하나의 instance mask를 포함한 최종 maks를 M_i, j라고 했을 때 M_i, j = G_i, j * F가 되겠죠. 이 전체 mask인 M을 직접 학습하고 추론하는 것은 computation cost가 크게 들게 됩니다. 하지만 대부분의 경우 text instance는 드문드문 위치해 있는데, 실제 한 instance를 추론하기 위해 SxS 중의 한개의 kernel인 M을 따로 학습하는 것은 낭비이기에 valid한 instance만 선택하여 dynamic하게 convolution을 진행하도록 하였고, 이것이 dynamic convolutional kernel입니다. (M을 F와 G로 나눠 학습, 여기 G가 dynamic convolutional kernel에 해당)
안녕하세요 ! 좋은 리뷰 감사합니다.
리뷰를 읽다가 loss에 대한 설명이 없어 궁금함에 질문드립니다. 본문에서 어떤 단어인지 분류하는 task라고 생각해볼 수 있다고 말씀해주셔서 Cross Entropy Loss를 사용할 것이라고 생각이 드는데 정확히 Sequence decoding 부분은 어떤 loss를 사용하는 것일까요?
그리구 charnet을 언급하면서 이 논문이 한자와 같이 class가 굉장히 많아지는 경우에는 잘 동작하지 못한다 하셨는데, 본 논문도 class 개수가 많아짐에 따라 CMA모듈 부분에서 channel수가 증가하게 될 거라고 하셔서 혹시 이 부분은 성능에 영향을 미치지 않는 것인지 궁금하네용
감사합니다.
댓글 감사합니다.
건화님이 말씀하신 것처럼 recognition task에는 단순하게 cross-entropy loss를 사용한 것이 맞습니다.
또, class가 많아지는 경우에 CMA 모듈도 마찬가지로 channel 수가 그에 비례하게 증가하겠지만, 본문에서 저자가 CharNet이 한자와 같이 class가 많은 상황에서는 잘 동작하지 못할 것이라고 말한 주요 이유는 CharNet이 글자 하나 하나에 대해 segmenting하는 방법론이라 sequence의 context 정보를 잃을 수 있다는 점 때문인 것 같습니다.