안녕하세요. 오늘도 지난주 읽은 논문과 동일한 Task인 video frame interpolation을 가져왔습니다. 지난번 논문이 CVPR 2023이고, 이 논문은 CVPR 2022의 SOTA 논문이라서 아마 최근 트랜드를 파악하기 적당할 것 같네요. (Task에 관심있는건 아니고… 실험 세팅에서 건져갈게 있을까 싶어서 보는중입니다 ㅎㅎ)
Introduction
기존의 영상 프레임 보간 Task에서는 대부분 CNN 기반의 구조를 활용하고 있습니다. CNN 기반의 구조들은 대게 2가지 단점이 있는데요. 첫 번째는 같은 커널로 서로 다른 입력과 서로 다른 위치에 연산을 수행하기 때문에, 콘텐츠에 종속적이라는 것입니다. (Transformer도 결국은 정도의 차이가 아닐까 싶은데… 뭐 그렇다고 하네요.) 두 번째는 변화량이 두드러지기 때문에 long-range dependency를 보는 것이 중요한데, CNN 기반의 방법론들은 매우 작은 커널 크기를 가져서 한계가 있다는 단점이 있습니다. 그렇다고 단순하게 이 작은 커널을 다층 구조로 쌓아서 receptive field를 키운다고 해서 이게 해결되는 것도 아니라서 구조적인 단점이 됩니다. 반면에 트랜스포머는 우리가 익히 알듯이… 위의 단점들을 해결할 수 있죠?
따라서 본 논문에서는 Video Frame Interpolation Transformer(VFIT)를 이용하여, 트랜스포머로 연구되고 있지 않았던 해당 분야에서 좋은 성능을 보였습니다. 그렇다고 트랜스포머를 그냥 적용한 것은 아니고요. 시간적으로 연관 있으면서도 사실적인 프레임을 생성할 수 있는 차이점 3가지를 가지도록 적용했는데요.
첫째로 기존 트랜스포머는 기본적으로 입력 요소들을 글로벌하게 상호작용 하는 self-attention에 기반합니다. 이러한 특성 때문에 입력 크기가 커진다면? 그리고 그게 시간 축이 존재하는 “비디오”라면? 상호작용해야 할 요소들이 배로 증가하겠죠? 따라서 본 연구에서는 Swin의 local attention 방식을 차용했습니다.
두번째로 기존 local attention 연산은 이미지에 적합하지 연산 축이 하나 더 존재하는 비디오에 적용하기는 사실 적합하지 않은데요. 따라서 spatial-temporal한 도메인에도 적용할 수 있도록 local attention 컨셉을 일반화했습니다. 논문에서는 Spatial-Temporal Swin attention layer (STS)라고 부릅니다. 근데 이제 더 효율적인 연산 구조를 적용한걸 space-time separable STS(Sep-STS)라고 부르네요. 뒤에 자세히 나옵니다.
마지막으로 Sep-STS의 포텐셜을 끌어내기 위해서, multi-scale kernel-prediction 프레임워크를 제안합니다. 이건 이제 Temporal한 정보도 잘 보면서, fine-grained한 예측도 잘 수행하겠다는 목적에서 제안된 프레임워크라고 보시면 됩니다.
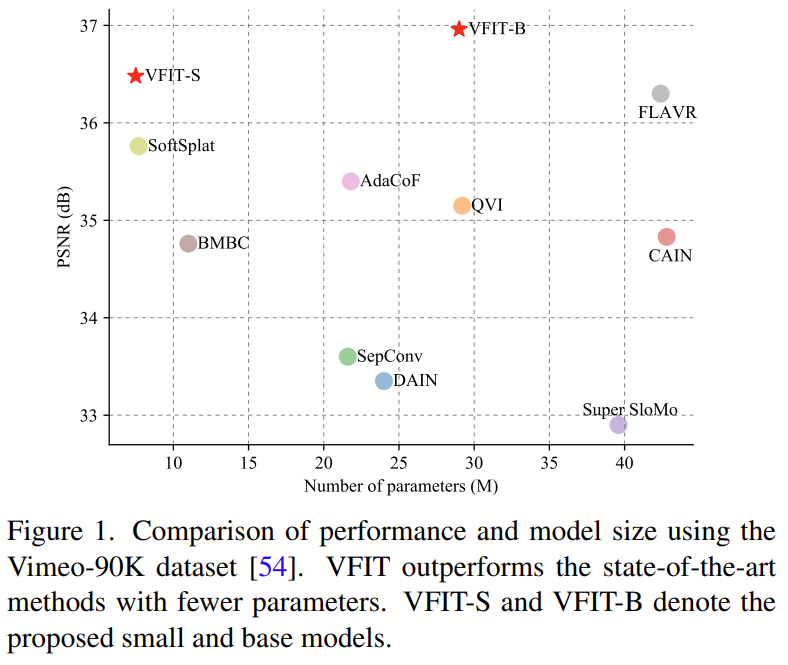
위의 내용들은 아래에서 좀 더 자세하게 설명하도록 하고… 결국은 [그림 1]에서 보는 것과 같이 적은 파라미터에 더 좋은 성능을 보였다고 합니다. 이리저리 수정한 부분들이 꽤 있어서 좋은 게 좋은 거니까 다 먹어봐 느낌은 아닌 것 같네요.
Proposed Method
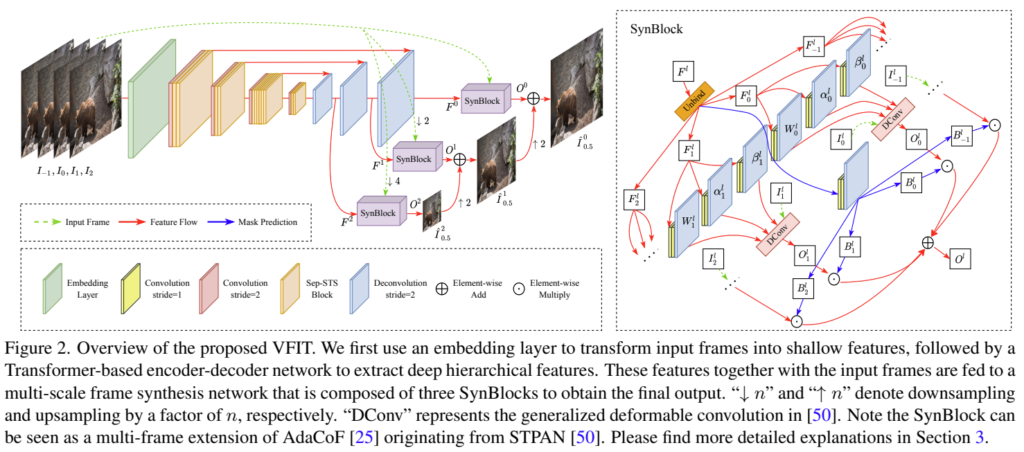
[그림 2]는 제안하는 전반적인 모델의 구조입니다. 기존 방법들과 유사하게 T개의 프레임, 여기서는 4개 프레임(-1,0,1,2)을 입력으로 하여, I_{0.5}에 해당하는 프레임을 생성하는 것이 목표입니다. 제안하는 VFIT 모델에는 3가지의 모듈이 있는데요.
첫번째로 “Shallow feature embedding” 모듈입니다. [그림 2]의 초록색 박스에 해당하는 부분인데요. 이미지를 임베딩 할 때 필요한 부분이고, 기존에는 2D conv를 썻는데 여기서는 temporal한 정보를 활용하기 위해 3D conv로 변경되었습니다. 나머지 두 모듈은 “Deep feature learning”과 ”final frame synthesis“인데 이건 아래에서 자세하게 살펴봅시다.
Learning Deep Features
VFIT에서는 트랜스포머 기반의 인코더-디코더 구조를 학습에 사용합니다. 인코더의 경우에는 4가지 단계로 되어있고, 각 단계는 “3D conv + Sep-STS 블록”으로 구성되어 있습니다. 디코더에서는 단순하게 3D conv 연산만 사용합니다. 이는 디코더에서 Temporal한 크기의 변화 없이 공간 축에 대한 resize만 수행하는 것이 목표였기 때문이라고 하네요.
Local attention
기존 트랜스포머 방법론들을 생각해보면, 입력 정보를 병합해서 global attention을 주는 것에 촛점을 맞추었습니다. 이는 앞서 설명했다시피 동영상에서는 T(시간) 축이 존재하기 때문에 연산량이 많아지고 메모리를 많이 먹게 되는 단점이 있는데요. 이에 대한 해결책으로 영역을 패치 단위로 나누고, global attention의 요소로서 패치를 활용하는 방법이 있습니다. 하지만 Task의 특성상 픽셀 단위 정교한 복원이 필요한데, 패치 단위로 연산을 수행하면 이런 부분에서 퀄리티 저하가 발생하는데요. 따라서 본 논문에서는 Swin 트랜스포머(패치 단위로 나누는 대표적인 방법론이죠?)의 local attention 매커니즘을 차용하여 이 문제를 해결하는 새로운 방법을 제안합니다.
Spatial-temporal local attention
Swin 트랜스포머의 핵심 아이디어는 결국 패치를 이동시키는 방법이라고 보면 되는데요. 해당 방법론은 이미지 단위에서 수행되기 때문에 이 논문에서는 이를 영상 단위로 확장하여 STS attention으로 부릅니다.
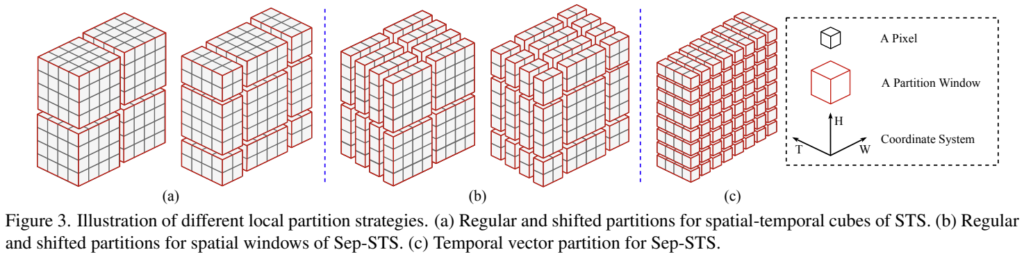
[그림 3-a]와 기본적인 작동 구조는 Swin 트랜스포머랑 똑같은데요. 다른 점은 temporal한 축으로 묶어서 작동한다는 차이점이 있습니다. 자세한 구현 디테일도 적혀있는데… 굳이 볼 필요는 없을 것 같아서 넘어가겠습니다. 축이 하나 늘었다는 것만 알고 넘어가면 됩니다.
Separation of space and time
앞서 설명한 STS attention은 naive하게 temporal한 축을 추가한 케이스인데요. 이러면 Introduction에서 설명한 것과 같이 메모리를 매우 크게 사용하게 됩니다. 패치 크기가 커진다면? 더 큰 문제가 되겠죠? 따라서 본 논문에서는 spatio-temporal한 연산을 분리한 Sep-STS를 통하여 시간 복잡도와 공간 복잡도를 모두 해결하고자 하였습니다.
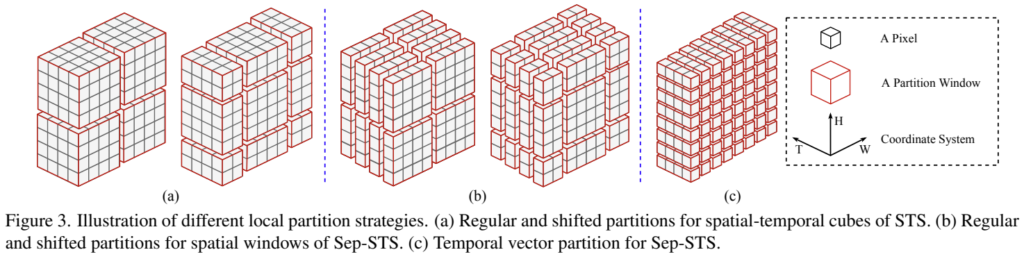
단순하게 생각하면 공간 축에 따른 연산과 시간 축에 따른 연산을 분리했다고 보면 됩니다. [그림 3-b]는 공간 축에 따른 연산만 수행하는 것인데요. 기존 Swin 트랜스포머와 동일하다고 보면 될 것 같습니다. [그림 3-c]는 이제 시간 축에 따른 연산만 수행하는 예시인데요. 이 경우에는 그림 보면 알겠지만 픽셀 단위로 시간 축만 고려한 연산을 수행합니다. 시간 축에 따른 연산이 너무 단순한 것 같기도 한데, 공간 복잡도를 줄여야해서 이런 선택을 한 것 같네요.
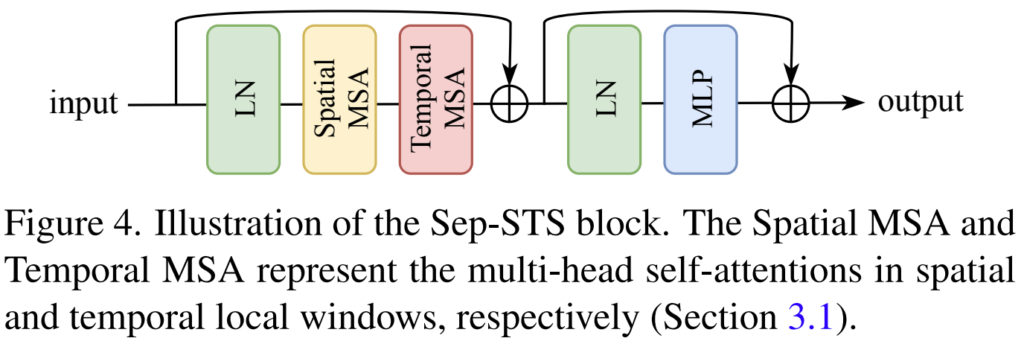
그래서 이 블록을 좀 더 자세하게 보면 [그림 4]와 같습니다. 위에서 분리한 attention 연산이 각각 Spatial MSA와 Temporal MSA로 들어가 있는 것을 볼 수 있습니다. MLP에서 GELU 함수를 activation 함수로 쓰는 것과 유사하게, 학습 안정성을 위하여 Layer Normalization 함수와 residual connection을 함께 사용했습니다. 이러한 구조를 통해서 long-range spatial-temporal dependency를 적은 연산량으로 확보했습니다. 실제로 계산을 해보면 STS가 공간 복잡도로 O((TMM) \cdot THW)로 계산되는 반면에, Sep-STS는 O((T+MM) \cdot THW)가 됩니다. 즉, T-1배 만큼 줄었다고 보면 됩니다. (실제로는 26% 정도의 GPU 메모리 감소 효과가 있었다고 합니다.)
Frame Synthesis
앞서 제안한 모듈을 이용해서 실제 프레임 합성은 어떻게 이루어지는지 알아보겠습니다. 여기서는 추가적으로 multi-scale kernel-prediction 프레임워크를 이용합니다. (보통은 Encoder-Decoder 구조에서 Decoder output을 바로 쓰는 것 같은데, 저희 Depth 연구하시는 분들 리뷰에서 봤던 것처럼 여러 scale의 이미지를 만들어서 쓴다고 생각하면 될 것 같네요.)
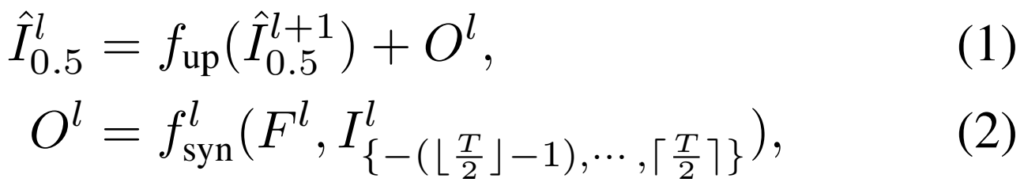
\hat{I}{0.5}^l에서 L은 이제 scale을 의미합니다. (1/4배, 1/2배, 원본 크기의 이미지를 만듭니다.) 0.5는 이 Task가 4개의 프레임(-1,0,1,2)를 입력으로 하여, 중간 프레임을 생성하는 Task라서 타겟 프레임을 의미합니다. [수식 1]을 보면 타겟 프레임을 생성하기 위해서 여러 scale의 이미지를 생성하고, up 함수를 태우는데요. 이건 그냥 bilinear upsampling 함수입니다. 이 Upsample 결과와 O^l(SynBlock)을 더해서 예측 프레임을 생성합니다. 이 SynBlock을 생성하는 방식은 [수식 2]를 통해 확인할 수 있는데요. [그림 2]와 함께 보면 이해가 쉬운데, 그냥 디코더의 특정 output(F^l)과 원본 프레임을 다운샘플링한 프레임(I^l{*})을 입력으로 하는 것을 볼 수 있습니다.
SynBlock

Synblock의 역할은 원본 프레임으로부터 정보를 취합해서, 일반화된 deformable kernel을 통해서 L크기의 예측을 생성하는 것이 목표입니다. [그림 2]의 오른쪽에 그림을 통해서 볼 수 있는데요. (Unbind는 특정 축에 따라 slice 하는 연산입니다) 그림이 조금 복잡하긴 한데요… 이미지마다 픽셀 단위의 deformable kernels을 얻기 위해서 네트워크에 입력을 해줍니다. 그림에서 W,\alpha, \beta라고 표기된 부분인데, 앞에서부터 kernel weight, horizontal offset, vertical offset 값이 됩니다. 이 값을 이용해서 DCconv 연산의 입력으로 해주면 이미지 1개의 SynBlock 예측값이 나옵니다.
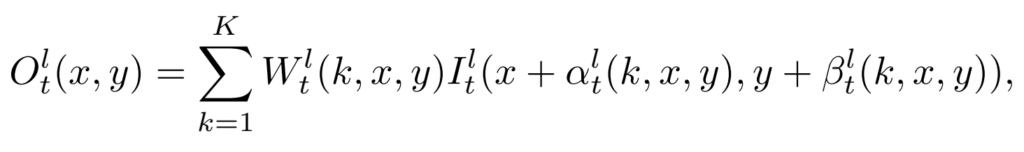
이미지 t에서 특정 픽셀에 대한 예측값은 위와 같이 표현할 수 있습니다. 그림을 보면 이거 말고 파란색으로 표시되어 있는 연산이 또 존재하는데요. 논문에서는 blending mask라고 표현하는 일종의 adaptive fusion weight입니다.
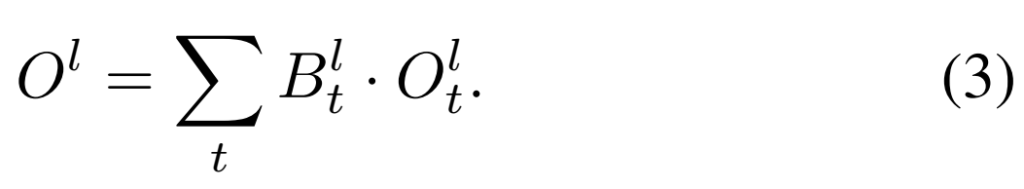
여러 프레임을 입력으로 해서 1개의 프레임을 생성하기 때문에, 모델의 예측 출력값도 여러개가 되는데요. 이때 이 blending mask를 통해서, 어떤 프레임의 예측 결과를 좀 더 많이 가져갈지를 결정해서 [수식 3]과 같이 최종 결과물을 생성합니다.
Experiments
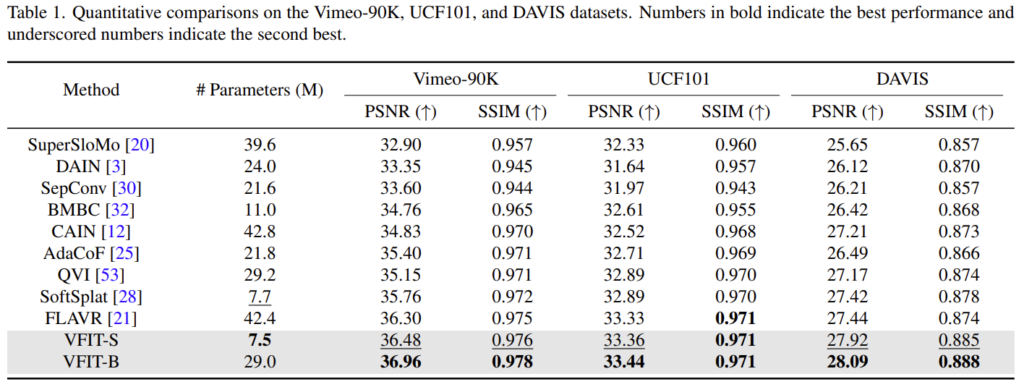
본문에 디테일한 설명들이 많기는 한데, 간단하게 정리했고 실험으로 넘어가봅시다. 여기나오는 성능은 [표 1]에 표기되어 있는 것과 같이 높을 수록 좋은 Metric입니다. 보면 제안하는 방법론이 기존 방법론보다 다 좋습니다. 물론 파라미터 크기 차이가 있긴 해서 VFIT-S와 VFIT-B의 파라미터 크기를 위의 비교군들이랑 체크하면서 봐야하는데요. (S와 B는 베이스 모델의 크기 차이) 적당히 비슷한 크기의 모델과 대조하면서 봐도 성능이 좋습니다.
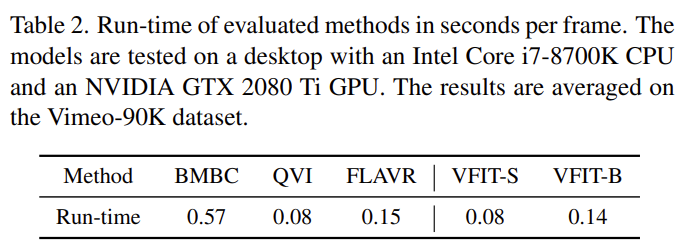
실제 처리 속도를 측정한 결과는 [표 2]인데요. 아무래도 이미 상용화된 기술이라 엄청 빠를 줄 알았는데 그렇지는 않네요…? 기존 방법론들은 CNN 기반의 방법론들인데 이러한 방법론들과 대조해서 동일하거나 더 빠른 속도를 보인다고 합니다.
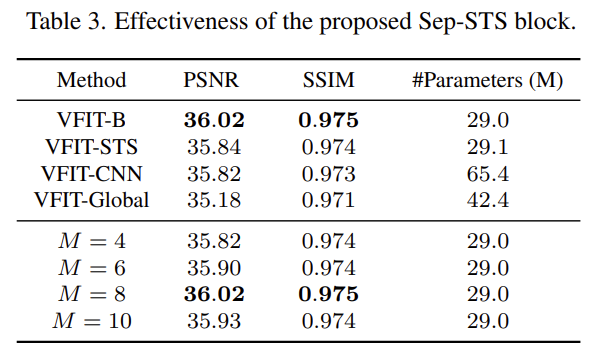
제안하는 Sep-STS Attention 블록이 효율적인가에 대한 증명으로는 [표 3]을 보면 됩니다. Sep-STS를 각각 STS와 CNN, 기존 global attention으로 대체한 실험 결과를 위쪽에서 볼 수 있는데요. 더 적은 파라미터에서도 더 좋은 성능을 보입니다. 결론적으로 비디오에서는 Spatial한거 따로, Temporal한거 따로 보고 돌리는 것이 좋다는 것을 이 실험을 통해서 보이는거죠. 또 밑에 붙어있는 M은 윈도우 크기(패치 크기)인데 이건 실험적인거니까… 설명은 넘어가겠습니다.
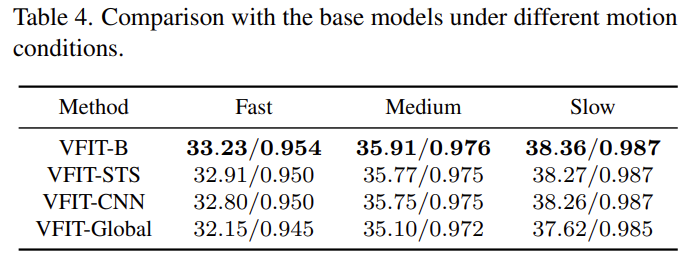
또 Vimeo-90K 데이터 셋에는 움직임의 정도에 따라 3단계로 구분할 수 있는데요. 이 실험은 Long-range dependency 문제가 개선되었음을 입증하기 위한 실험이라고 보시면 됩니다. 예를 들어, Fast의 경우에는 움직임이 휙휙 빠르게 변하기 때문에 더 많은 프레임을 한번에 봐야 프레임 보간이 원할하게 수행되겠죠? 이러한 맥락에서 제안하는 모듈의 성능이 좋다는 뜻은 트랜스포머가 이런 부분에서 장점을 가진다고 볼 수 있습니다.

[그림 7]은 예시니까… 참고해서 보시면 좋을 것 같네요. 바로 위에서 설명한 실험 결과의 정성적인 결과인데요. 제안하는 모듈이 더 선명하게 만든다 정도로 보면 될 것 같네요.
Conclusion
Temporal한 축에 대한 정보가 중요한 Task라서 관련 논문을 읽고 일부 아이디어를 따서 실험을 돌리고 있는데 잘 안되네요 ㅎㅎ;; 이 논문에서 말하는 Attention 방식도 가져가서 실험을 해봐야겠습니다.