안녕하세요.
항상 Domain Adaptation 관련 논문만 리뷰하다가 오랜만에 Knowledge Distillation 논문을 리뷰하게 되었습니다.
평소에, 그리고 최근에 실험을 하면서도 종종 느꼈던 점인데 segmentation task에서 대부분의 방법론들이 Adaptation 혹은 KD 를 수행할 때 pixel level의 spatial 한 정보에 초점을 맞춘다는 것입니다.
spatial 축 뿐만 아니라 channel 축도 각각 담고 있는 정보들이 모두 상이할텐데,
channel 축을 기준으로 KD 혹은 Adatpation 을 수행한 논문이 없을까~ 하면서 찾다가 우연히 읽게 된 논문입니다.
사실 제 기준으로 방법론적인 부분이 너무 빈약하다는 생각이 들긴 했는데 ICCV 네요.,
아무튼 리뷰 시작하도록 하겠습니다.
1. Introduction
Object Detection, Semantic Segmantation 등의 dense prediction task에서의 기존 KD 방식은 pixel level로의 spatial 정보에 초점으로 맞춰서 teacher와 student의 activation map을 정렬(align) 하는 데에 초점을 둡니다.
pixel level로 예측을 수행해야 하니, KD를 통해서 spatial 정보를 줘야한다~ 라는 직관적인 생각을 할 수 있죠.
하지만 본 논문에서는 channel 에 집중합니다.
각 channel 별로 가장 두드러지게 집중하는 spatial 영역을 찾아서 channel-wise soft probability map을 얻고자 하는 것이죠. 그리고 channel별로 어떤 spatial 영역에 집중하는지는 dense prediction task에서 매우 중요한 사항입니다.
가령 이미지에 자동차와 사람이 존재하고,
1번째 channel이 자동차를, 그리고 2번째 channel이 사람을 집중해서 볼 때(activation) 각 channel이 어떤 영역을 더 집중해서 보는지를 알아야 하는 것이죠.
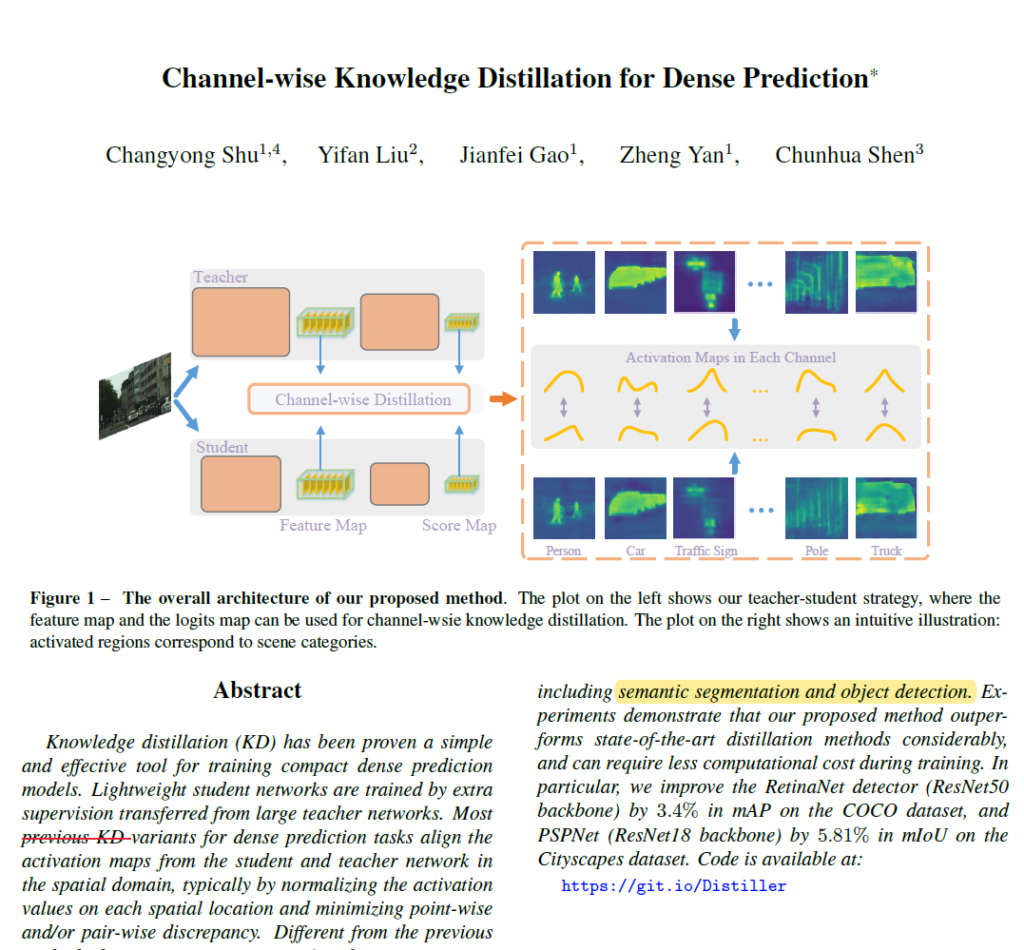
사실 접근이 정말 직관적이고,
위 그림이 본 논문에서 하고자 하는 모든 것을 보여주고 있습니다.
Teacher 와 Student에서 예측하는 각각의 feature map 혹은 score map 이 있고, 해당 map의 각 channel들은 우측에서 보는 것과 같이 activation 되는 영역이 상이합니다.
그리고 해당 사항에 집중해서 본 논문은 chennel-wise KD 방식을 제안하는데 이는 아래 그림과 함께 설명드리겠습니다.
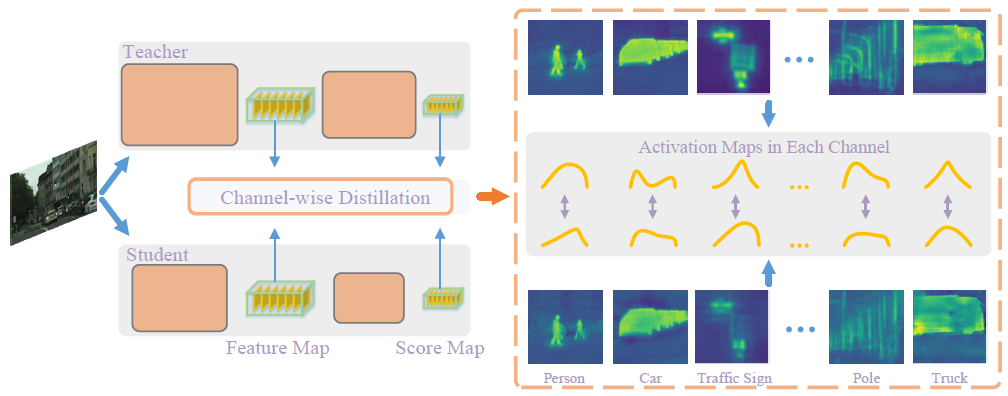
기존에 진행된, spatial level로의 KD 방식을 시각화 한 것이 위 그림의 (a)에 해당합니다.
그림에서 보시는 것과 같이 W, H 축을 기준으로 spatial location 사이에서의 상관 관계에 주목하고 이에 대한 가중치를 서로 다르게 주는 것이죠.
각 위치 별 막대 색상이 다른 것을 볼 수 있는데 이는 각 spatial location을 기준으로 활성화의 정도를 나타내는 가중치의 값이 정규화 된 것입니다. 앞선 문장과 같은 의미인데, 그냥 pixel-level 로 가중치를 다르게 주는 것입니다.
하지만 이러한 방식은 activation map의 모든 영역에 대해 동일한 가중치를 가지기 때문에,
teacher network에서 중복되는 정보를 가지고 올 수 있다고 합니다.
(직역했을 때 정확하게 의미가 와 닿지 않아서 원문으로 대체하도록 하겠습니다.)
However, every spatial location in the activation map contributes equally to the knowledge transferring,
which may bring redundant information from the teacher network.
반면 본 논문에서는 위 그림의 (b) 처럼 spatial이 아닌, 각 channel의 activation map을 정규화해서 KD를 수행하는 새로운 channel-wise knowledge distillation 을 제안하게 됩니다.
위 그림 (c)를 보시면 channel 별로 어떤 영역이 활성화 되어 있는지에 대한 정보가 시각화 되어 있습니다.
이러한 channel 정보에 간단한 정규화 과정을 더해서 teacher와 student 사이의 KL Divergence를 최소화 하는 방향으로 진행됩니다.
사실 뭐 컨셉이 되게 간단하긴 합니다.
어떤 식으로 정규화가 진행되는지는 method 에서 보도록 하겠습니다.
2. Method
저자들은 각 channel 들이 담고 있는 정보들을 더 효율적으로 활용하기 위해 teacher와 student 사이에서 각 channel의 activation map을 부드럽게 정렬하게 됩니다. activation map이라 함은 위 그림 (c) 에서 어떤 영역에 더 가중을 둬서 활성화가 되었는지를 나타낸다고 보시면 됩니다.
teacher와 student의 activation map은 각각 y^T, y^S 로 표기되며,
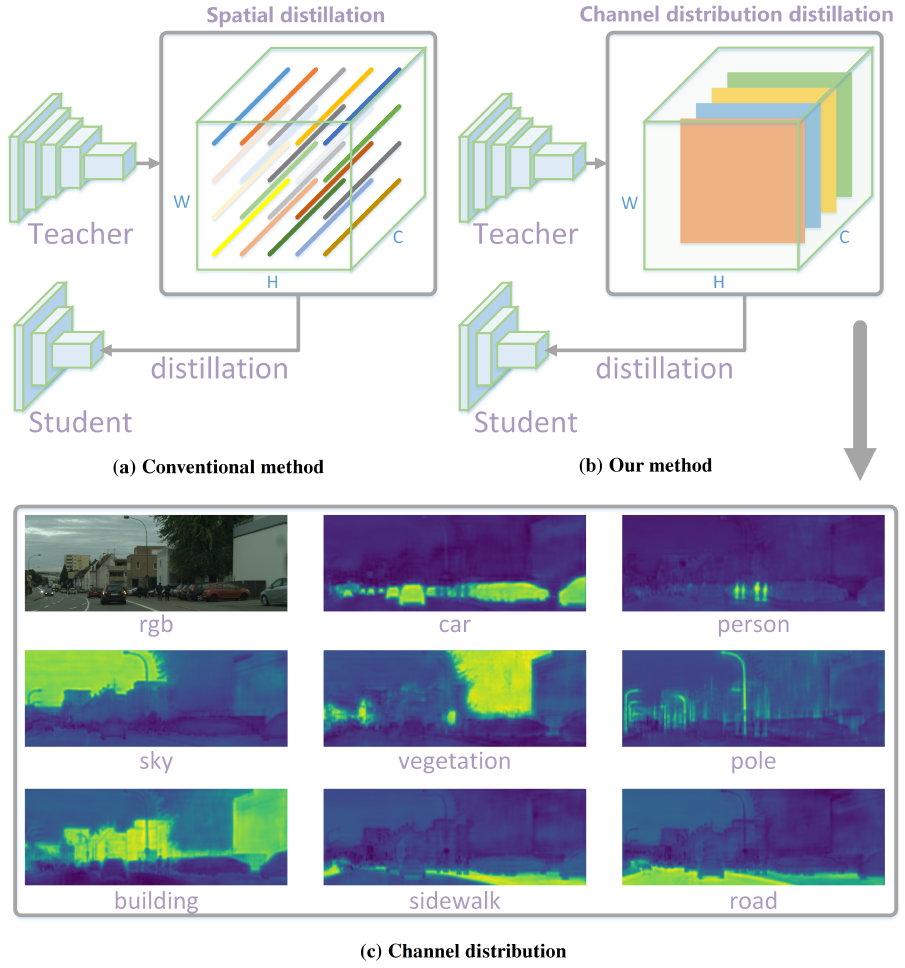
channel-wise로 계산되는 distillation loss는 아래 식을 통해 계산됩니다.
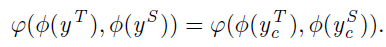
또한 추후에 KL Divergence를 통해 teacher와 student activation map 사이의 확률 분포를 최소화하게 될텐데 이를 위해 \phi 를 사용해서 activation 값을 pixel 별 확률 분포로 변경시킵니다.
식은 아래와 같습니다.
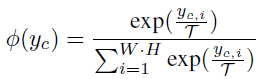
c는 1~C 까지 각 channel 을 의미합니다.
또한 T는 softmax 연산 시 적용되는 temperature parameter를 의미하며,
높은 T를 사용하게 되면 더 smooth한 확률 분포를 가지게 됩니다. 즉 각 channel에 대해 특정 좁은 영역이 아닌 더 global한, 넓은 공간 영역에 집중하게 되는 것입니다. 본 논문에서는 4 로 세팅했네요.
결국 위 식이 의미하는 바는 channel-wise로 각각 영역(spatial) 에 대한 softmax 연산을 수행하는 것입니다.
각 채널별로 자신들이 집중하는 영역은 높은 확률 값을 가지게 되겠죠.
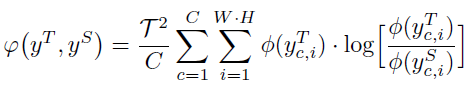
그리고 위 KL Divergence 식을 통해 teacher와 student의 확률 분포를 정렬하게 됩니다.
KL Divergence는 특성 상 비대칭(asymmetric)한 성격을 지니고, student의 분포를 teacher로 맞춰 나가게 됩니다.
****
사실 이게 끝입니다.
결국 기존 방식과는 다르게 channel 별의 정보를 각기 고려해서 normalization 을 수행 후 distillation을 했다,, 라는 것입니다.
3. Experiment
본 논문의 실험 파트가 전체 분량의 절반 가까이를 차지하고 있습니다.
기존 spatial level의 KD와의 차별성을 여러 실험을 통해 증명한 것이지요.
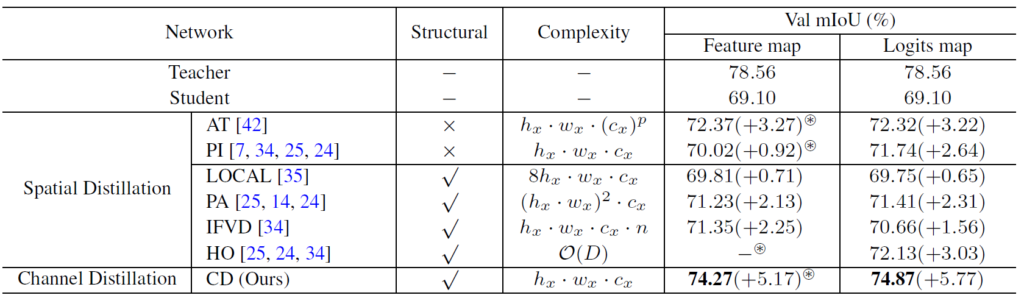
기존 방식들과의 성능적 비교 뿐만 아니라 연산의 complexity 정도까지 함께 비교한 표 입니다.
CityScapes dataset에 대해 validation을 진행하였고
Teacher network로는 PSPNet-R101 을, Student network로는 PSPNet-R18을 사용하였습니다.
성능 표에서 Feature map 성능과 Logit map 성능이 보이실텐데 이는 각각 KD 기법을 encoder를 통과한 Feature map에 적용할지, 아니면 Decoder까지 통과한 Logit map에 적용할지 입니다.
- AT 방식은 Attention Transfer의 줄임말입니다.
해당 경우 각 spatial 위치에서 모든 channel을 단순히 더해서 1 channel의 attention map을 만들게 됩니다.
channel별로 특별한 고려 없이 단순히 더하는 방식이죠.
teacher와 student 각각 H,W,1 의 attention map을 만들게 될텐데 이 둘 사이를 L2 loss를 통해 최소화 시키게 됩니다. - PI 방식은 Pixel-wise Distillation의 줄임말입니다.
teacher와 student에서 결과로 뱉는 H,W,C 형태의 feature map(혹은 logitmap) 이 있을텐데 이를 KL Divergence를 사용해서 pixel-wise로 정렬하는 방식입니다.
attention을 사용하는 위 AT 방식에 비해 student의 성능 향상이 낮네요. - 다음은 LOCAL 방식입니다.
이름에서 알 수 있다시피 local 한 유사성을 고려하겠다는 기법인데요, 각 pixel에 대해 자신과 이웃한 8개의 pixel들 끼리의 상관 관계를 고려해서 local similarity map을 구하게 됩니다.
마찬가지로 teacher 와 student 모두 local similarity map 을 구할 수 있는데, L2 loss를 통해 최소화 시키게 됩니다.
물론 pixel level만을 고려 한다는 점에서 위 2가지 방식과 동일하지만, 단순 pixel level이 아닌 주변 이웃 pixel을 바라보면서 조금 더 구조적인(structural) 정보를 반영하게 됩니다. 그런데 향상폭은 생각보다 낮네요. - PA 방식은 Pair-wise distillation 방식으로 H,W 에 대해 모든 픽셀 쌍 사이의 상관관계를 모두 고려하게 됩니다.
그렇기 때문에 성능 향상 폭이 크긴 합니다만, Complexity가 매우 큰 것을 알 수 있죠. - IFVD 방식은 Intra-class feature variation distillation 입니다.
각 pixel의 특징과 이에 대응하는 class별 prototype 간의 similarity 관계를 intra-class feature variation으로 보고 이를 teacher->student로 distillation 하는 것입니다.
앞선 이러한 Spatial Distillation 기법들에 비해 본 논문이 제안하는 Channel-level로의 Distillation 의 성능 향상 폭을 보면 매우 이상적입니다. 여러 종류의 Spatial Distillation 방법론들과의 실험적인 비교를 통해 강건함을 보여주고 있네요.

그리고 정성적인 결과입니다.
(c)의 CD가 본 논문의 결과이며, (d) AT는 기존 spatial distillation 기반 방법론 중 최고 성능인 녀석에 대한 결과를,
그리고 (e)는 distillation과정 없이 student 혼자 단독으로 예측한 결과입니다.
각 channel 별로 집중해서 보는 structural 정보를 잘 모델링 했기에 신호등, 자동차 등 특정 영역에 대한 결과가 성공적으로 진행되었음을 확인할 수 있습니다.
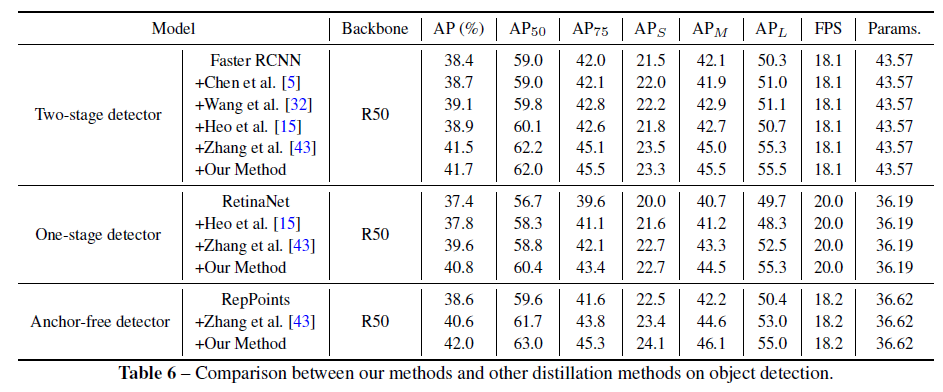
또한 detection 방법론에서도 본 논문의 효과를 톡톡히 보여주고 있습니다.
2-stage, 1-stage 모두에서 꽤나 의미있는 mAP 향상을 보였고, 특히 Anchor-free 기반 방법론에서 큰 개선을 보인것을 볼 수 있습니다.
사실 본 논문이 제안하는 방식은 매우 간단하지만, 분석과 결과는 매우 의미있다고 봅니다.
segmentation 실험을 수행하면서 항상 channel level 보다는 spatial level에 집중해서 무엇인가를 설계하려고 했던 거 같습니다. 아무래도 더 직관적이기 때문에 constraint를 걸기에 용이하기 때문이죠.
하지만 spatial 뿐만 아니라 channel 에도 다채롭고, 서로 다른 정보들이 들어있는데 이때까지의 저와 기존 연구들은 해당 포인트를 꽤나 간과한 거 같습니다. 본 논문은 기존 연구들의 이러한 문제를 콕 집은거구요.
아무튼, 간단하지만 심금을 울리는 그런 논문이였습니다. 감사합니다.