안녕하세요, 열 세 번째 X-Review입니다. 이번 논문은 TPAMI 2021에 게재된 PAN++으로 지난주 리뷰한 PAN의 후속작입니다. PAN은 text detection 방법론이었다면 오늘 리뷰할 PAN++은 text detection과 text recognition을 한 번에 수행하는 text spotting 방법론입니다. 그럼 리뷰 시작하겠습니다 !
1. Introduction
지난 수 년 동안 scene text detection과 scene text recognition은 DNN으로 인해 많은 발전을 해왔습니다. Mask TextSpotter 혹은 FOTS 등이 이에 해당하겠습니다. 하지만, 아직 현존하는 방법들이 현실 세계에 바로 적용되기에는 세 가지 한계점이 있습니다.
첫 번째로, 많은 text detection 그리고 text recognition task가 각각으로 분리되어 별도의 task로 다뤄져왔다는 점입니다. Detection과 Recognition 두 task간의 상호 보완적인 특성을 이용하는 방법론은 거의 없을 뿐더러, 이미지에 있는 text를 검출하고 인식하기 위해 각각 독립적으로 수행되었던 두 방법론을 하나로 합쳐 사용하게 된다면 computation cost가 크게 들겠죠.
두 번째로, 대부분의 end-to-end text spotters (text detection과 text recognition을 합쳐 text spotter라고 일컫습니다)방법론들은 오직 수직으로 되어있거나, 수평으로 되어있는 text만 읽을 수 있도록 설계되었다는 점입니다. 즉, 이런 방법론들은 scene에 존재하는 text들이 직선으로 되어있을 것이라는 가정이 있었다는 것입니다. 하지만 natural scene에는 직선으로 예쁘게 펴져 있는 text들만 존재하는 것이 아니라, 여러 보양을 가진 irregular한 text들이 빈번하게 등장합니다.
마지막으로 현존하는 end-to-end text spotter들은 아직 real-world에 적용하기에는 불충분합니다. 예를 들어 Mask TextSpotter같은 경우에는 arbitrary한 모양의 text(휘어져있거나, 곡선 형태 등 임의의 모양의 text) spottting 정확도를 개선시켰지만 모델이 크고 무겁고 복잡한 파이프라인을 가지고 있기에 inference 속도가 낮다는 문제점이 있습니다. 즉, 어떻게 효율적이고, 정확게 arbitrary 모양의 text를 위한 end-to-end spotter를 디자인 해야하는가가 해결되지 않았다고 볼 수 있겠습니다.
이런 3가지 이슈를 해결하기 위해 저자들은 본 논문을 내기 전, PSENet과 PAN을 소개하였는데, 이 두 논문에서는 kernel 이라는 개념을 도입하여 text line을 표현하고자 하였습니다.
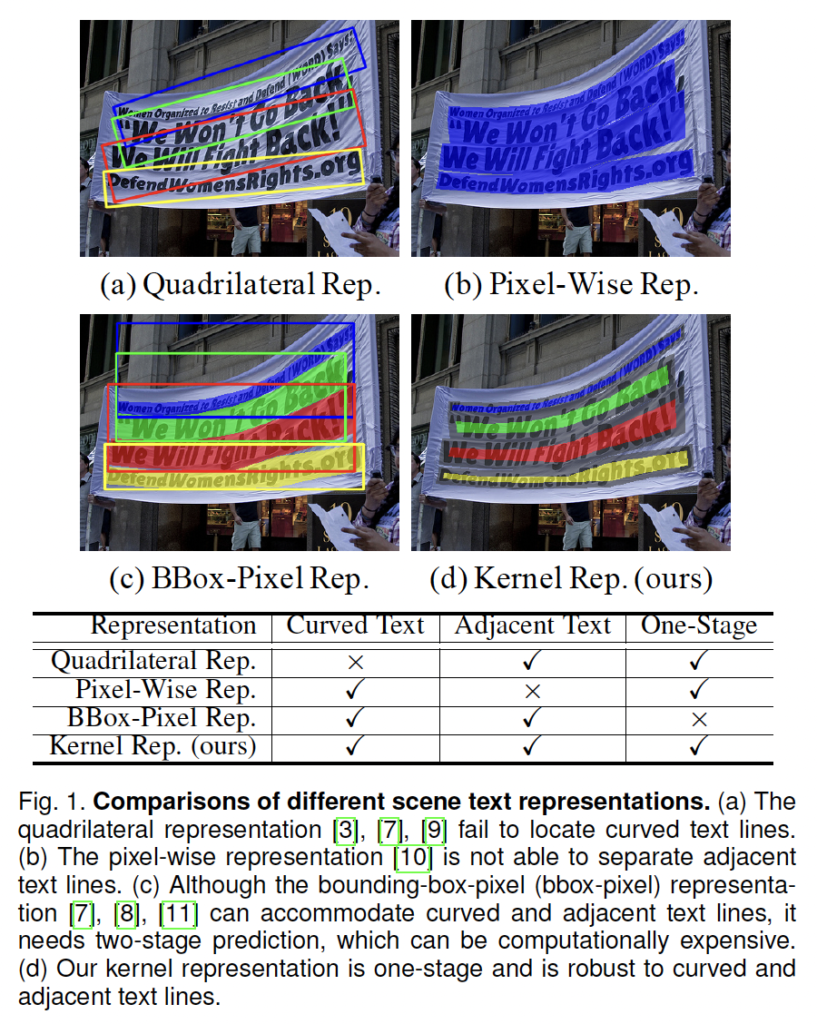
여기서 kernel이라 함은 [Fig. 1]의 (d)를 보면 알 수 있는데, 먼저 (b)같은 경우는 text가 존재하는 영역 전체를 표현하고 있다면 (d)는 text가 존재하는 영역을 다 둘러싸기 보다 그 중심 영역을 표현하고 있고 저 색칠된 부분이 kernel 영역이라고 보면 됩니다. 이런 kernel의 개념을 도입한 건 단순히 [Fig. 1]에 보이는 것과 같이 타 방법론이 어떻게 text line을 표현하고 있는지 살펴본 후 이들의 장단점을 연구하면서 영감을 받은 것입니다.
하나씩 살펴보자면 [Fig 1 – (a)]의 Quadrilateral representation은 흔히들 사용하는 방식입니다. 그림을 보시면 아시겠지만 직선으로 된 text line만 검출하도록 디자인되었으며, 사진에 존재하는 곡선으로 된 text line에 대해 딱 맞는 바운더리를 나타내지 못하고 있습니다.
반대로, Fully Convolution Network(FCN)의 pixel-wise representation은 곡선으로 된 text line을 찾을 수 있을 정도로 flexible합니다. 이에 해당하는 것이 [Fig1-(b)]인데 보시면 인접한 text line이 합쳐진 것을 볼 수 있습니다.
이를 해결하고자 등장한 것이 [Fig-1] (c)의 BBox-Pixel Representation인데 이는 time cost가 크다는 단점이 있습니다. 결국 저자는 (d)의 kernel 표현을 제안하면서 이 kernel 표현은 text line이 곡선으로 되어있고, 가까이 붙어 있는 경우에도 효과적으로 구별할 수 있다고 합니다. 또 이 kernel은 단 하나의 convolution network로 예측이 가능하며 real-time application에 적합하다고 말하면서 이 kernel을 이용하여 정확도와 inference 속도사이의 적절한 균형을 이룰 수 있는 end-to-end text spotter PAN++을 제시하였습니다.
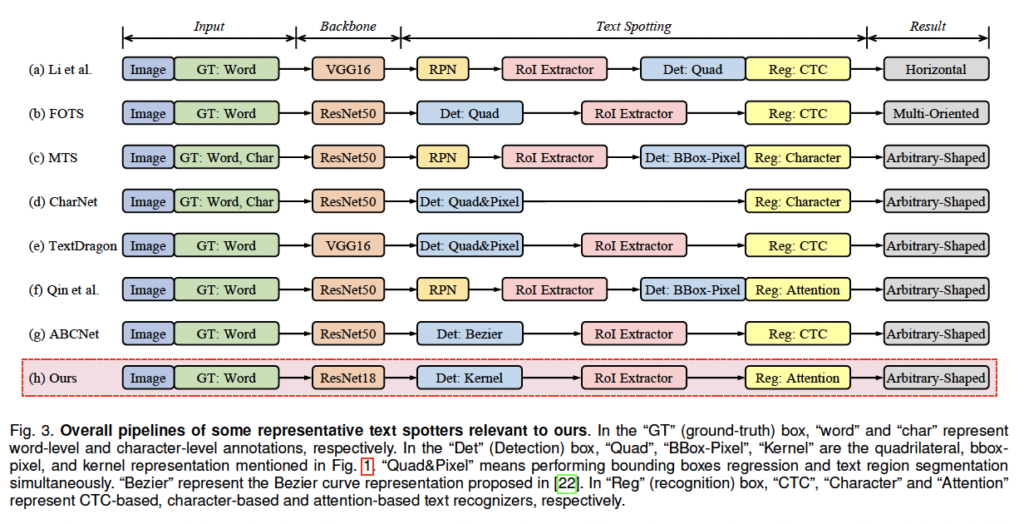
그래서 PAN++은 [Fig 3 – (h)]의 파이프라인을 따르는데, 보시면 크게 Det: Kernel이라고 쓰여져 있는 파란색 박스 부분과 Reg: Attention이라고 쓰여져 있는 노란색 박스 이렇게 두 스텝으로 구성된다고 보면 됩니다. 한마디로 kernel 기반의 detection을 수행한 후 이 detection 결과에서 attention 기반의 recognition을 수행하는 것입니다. 저자들은 real time으로 동작하는 모델을 설계하고자 하였으며, 파이프라인의 각 step에서 드는 time cost를 줄이고자 하였습니다.
본 논문의 contribution은 다음과 같습니다.
- kernel representation의 definition을 제공하고, 이를 기존 text representation과 비교하여 kernel 표현이 얼마나 간단하고 flexible하며, real-time에 적합한지 보여준다.
- kernel 표현을 기반으로 PAN++이라는 arbitrary한 text spotting 프레임워크를 제안하며 이는 정확성과 inference 속도 사이의 좋은 balance를 가져감
- PAN++에 맞게 효율적인 모듈을 제안하고, 설계함 (Featrue Pyramid Enhancement Modules, Pixel Aggregation, Masked RoI, lightweight attention기반 recognition head)
- PAN++은 곡선으로 된 text benchmark에서 SOTA달성 및 빠른 추론 속도
2. Proposed Method
2.1 Kernel Representation

위 그림처럼 text line은 text kernel과 그 주위를 둘러싸고 있는 주변 pixel들로 표현할 수 있습니다. 다시 말하자면 각각의 text line이 주어졌을 때 먼저 text line의 중심 영역을 나타내는 text kernel을 통해 위치를 파악한 후 그 text kernel의 주위 pixel들을 포함하여 완전한 모양의 text line으로 복구하겠다는 것입니다.
저자들은 일반적으로 저자들의 kernel 표현에는 4가지의 이점이 있다고 합니다.
- pixel 기반의 representation이라 arbitrary한 모양의 text line을 표현하기 용이하다
- 기하학적인 margin을 사용하기 때문에 [Fig 1-(b)]와 달리 인접한 text instance들을 잘 구별해낼 수 있다.
- kernel representation은 완전히 pixel 기반인데, 이 말인즉슨 하나의 FCN으로 쉽게 예측가능하며, 이는 곧 real time으로 동작할 수 있게 한다.
- kernel representation의 label은 추가적인 어노테이션 없이 쉽게 생성 가능하다.
이 기하학적인 margin과, kernel label 생성 부분에 관하여는 추가적으로 후술하도록 하겠습니다.
2.2 Overall Architecture
이제 이 kernel representation에 기반한 PAN++의 전반적인 구조를 살펴보도록 하겠습니다.
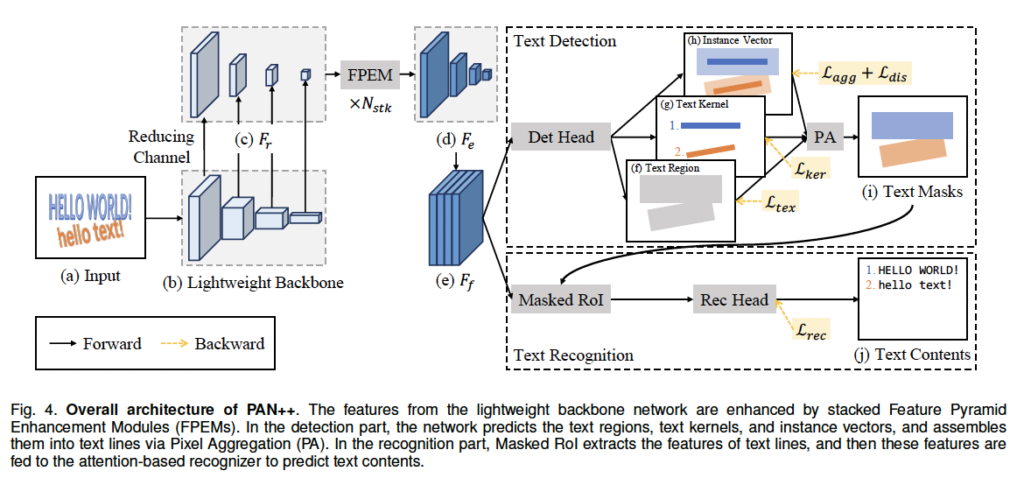
intro에서도 언급한바 있는데 저자들은 높은 효율성을 위하여 가벼운 백본 네트워크를 사용하였다고 하였습니다. 그래서 위 [Fig4]의 backbone 부분이 ligntweight backbone인 것을 볼 수 있으며 ResNet18을 사용하였습니다. 하지만, lightweight backbone을 사용하게 되면 receptive field가 작을 수 있다는 점과, 표현력이 약하다는 단점이 있습니다.
저자들은 이 문제를 해결하기 위해 feature pyramid enhancement network(FPEM)를 제안하였고, 이 부분이 위 그림에서 백본으로 추출한 feature pyraimd를 입력으로 사용하고 있음을 볼 수 있습니다. FPEM 부분을 보면 아래에 xN_{stk}라고 쓰여진 부분이 있는데 이는 FPEM이 stack이 가능하다는 것입니다. 이렇게 FPEM을 통과하게 되면 이전보다 더 깊고 표현력이 풍푸한 feature가 나오게 됩니다.
이후 text detection을 하기 위해 저자들은 Pixel Aggregation(PA)를 포함한 detection head를 제안하였는데, detection head에서 text region, text kernel, instance vector 이 세가지를 예측해내고, 이 결과들이 합쳐져 PA의 입력으로 들어가게 됩니다. 여기서 text region은 text line의 완전한 모양을 설명하기 위해 사용되며, text kernel은 서로 다른 text line을 구별하기 위해 사용되고, instance vector는 text kernel에서 완전한 text line을 복구해내는데 사용됩니다.
이렇게 PA를 거쳐 text들이 검출되면 text recognition을 해야겠죠. Text recognition 단계에서는 Masked RoI가 검출된 text line의 feature patch를 추출하는데 사용되며, attention 기반의 recognition head가 text를 최종적으로 인식하기 위해 사용되었습니다.
2.3 Feature Pyramid Enhancement Module
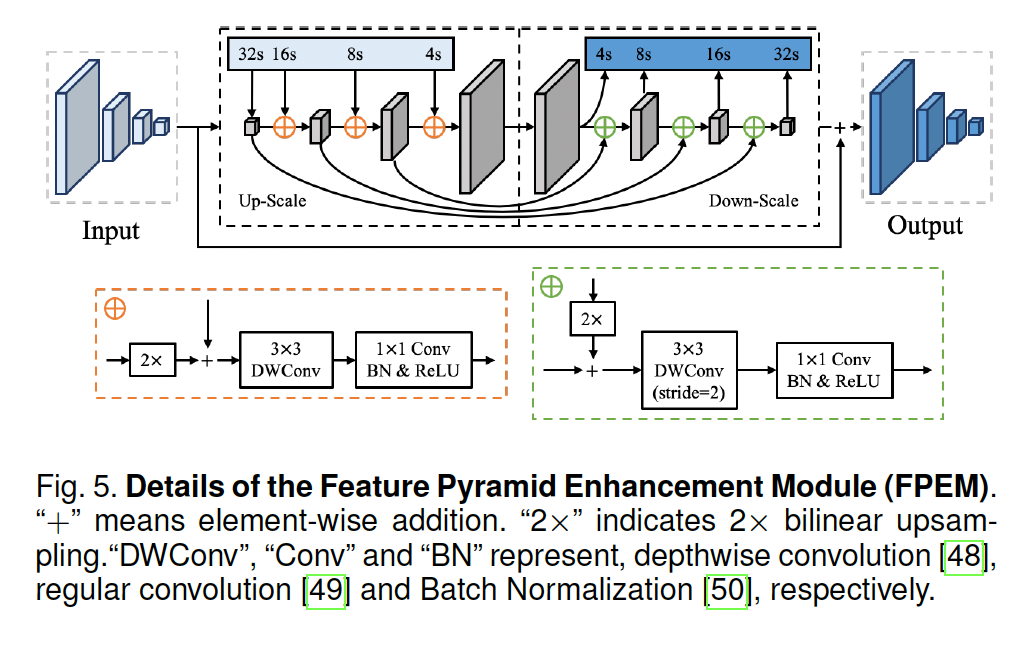
lightweight backbone의 output으로 나오는 feature의 표현력을 키우기 위해 사용되는 Feature Pyramid Enhancement Module(FPEM)에 대해 알아보도록 하겠습니다. 이 FPEM은 이 논문에서 처음 제시한 것이 아닌, 이전 논문 PAN에서 이미 제안했던 모듈입니다. FPEM은 [Fig-5]에 보이는 것처럼 U 모양이며, up-scale enhancement와 down-scale enhancement 두 단계로 구성됩니다. up-scale enhancement에는 앞선 lightweight backbone에서 최종적으로 생성된 feature pyramid에 적용되게 되며, Down-scale enhancement에서는 up-scale enhancement에 의해 생성된 feature pyramid가 input으로 사용됩니다.
PAN의 FPEM과의 차이점이라고 하면, down-scale enhancement의 output feature pyramid가 input feature pyramid와 element-wise addition되어 최종 output feature pyramid가 생성된다는 점입니다.
저자는 결합 부분인 ⊕을 구성할 때 일반적인 convolution 대신에 separable convolution을 사용하였습니다. [Figure -4]의 그림 하단에 점선 부분을 보면 자세히 나와있는데, 이 3×3 depthwise conv + 1×1 projection을 사용함으로써 적은 computation cost로 receptive field를 확장하고(3×3 depthwise conv) network를 더 깊게 쌓을 수 있게 된 것(1×1 projections)입니다.
FPEM은 FPN(Feature Pyramid Network)와 비슷하게 low-level과 high level 정보를 융합하여 다양한 scale의 feature를 향상시킬 수 있죠. 하지만 FPN과 다른 점이라고 하면, 1) FPEM은 stackable 모듈이다라는 점과, 2) FPEM은 computation cost가 적게 든다 라는 두 이점이 있다고 할 수 있겠습니다. 정리해보자면, FPEM은 많이 stack할수록 서로 다른 scale의 feature map이 더 효과적으로 fusion되고, receptive field가 커지며, seperable conv를 사용했기 때문에 최소한의 계산만 필요하게 되겠습니다.
2.4 Text Detection
2.4.1 Detection Head
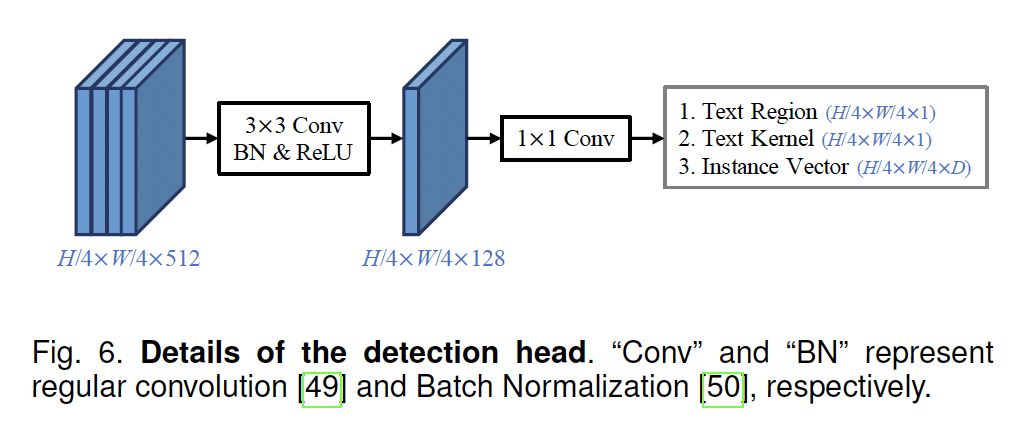
위 그림과 같이 PAN++의 detection head는 오직 2개의 convolution으로 구성됩니다. 이 detection head의 output으로는 text region, text kernel, instance vector가 나오게 됩니다.
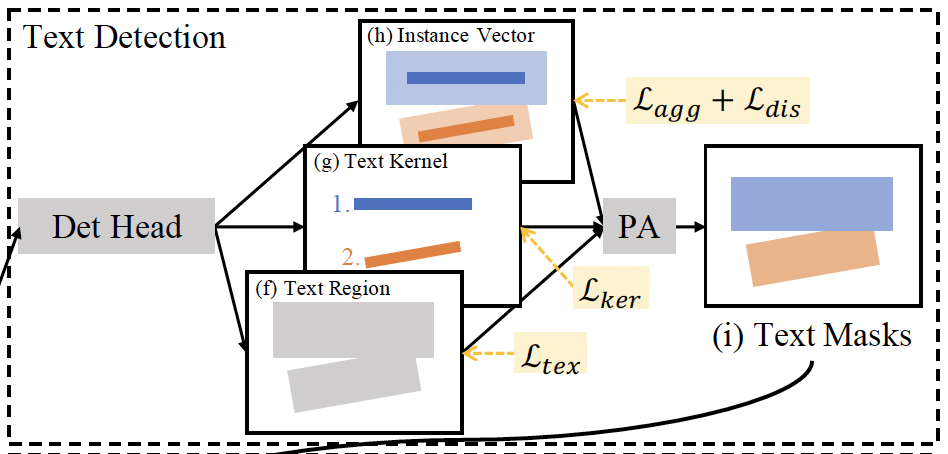
Figure 4에서 text detection 부분만 잘라서 가져온 사진입니다. (f)가 text region인데, text region은 text line의 전체적인 모양을 가지고 나타내고 있지만 text instance가 가깝게 붙어있는 경우에는 여러 text instance를 하나의 text instance로 검출할 가능성이 있겠죠. 그렇기에 (g) kernel 개념을 도입하여 인접한 text instance를 잘 구별해내도록 하였습니다. 이 text kernel은 text line의 완전한 모양을 나타내지 못하고 있지만, 여기에 (h) instance vector를 이용하여 text region의 pixel들이 어떤 커널과 대응되는 알아낼 수 있습니다. 여기 이 instance vector는 이미지 내의 각 pixel에 대한 고차원 벡터로서, 해당 pixel이 어떤 text 영역에 속하는지에 대한 정보를 포함하는 벡터입니다. 이렇게 text region, text kernel, instance vector 세 가지를 가지고 arbitrary한 모양을 가지는 text를 잘 묘사하도록 하는 것입니다.
2.4.2 Pixel Aggregation
Pixel aggregation(PA)는 instance vector를 최적화하고, detection head에서 나온 3가지의 output을 조합하는 역할을 수행합니다.
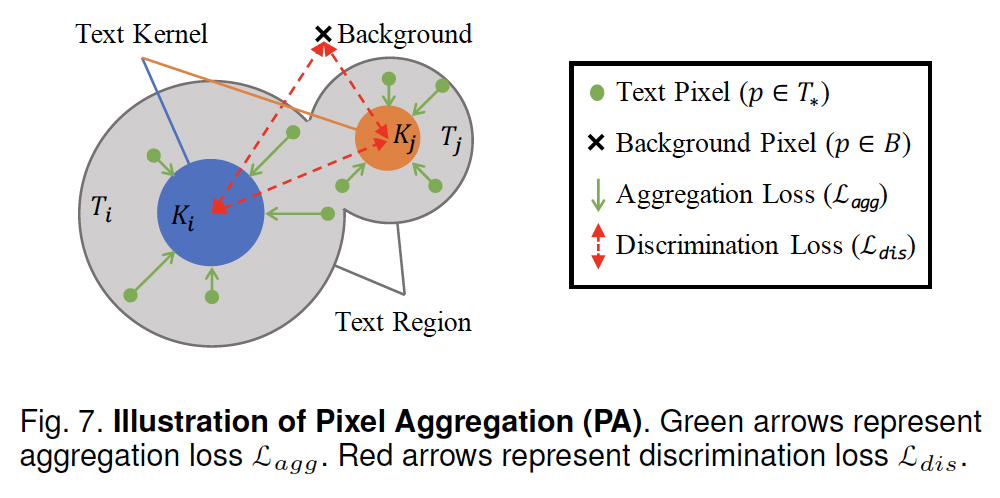
저자들은 PA를 설계할 때 clustering에서 아이디어를 얻었는데요, 위 그림과 같이 서로 다른 text line들을 다른 cluster로 보았고, 그림에서 파란색, 주황색 원에 해당하는 kernel을 cluster의 center로 보았으며, 회색 영역인 text region안에 존재하는 pixel들을 clustering 해야 할 샘플들로 보았습니다.
당연히 text region의 pixel들을 text kernel에 clustering하기 위해서는 위 그림의 녹색 화살표와 같이 text region과 동일한 text line 내부의 text kernel과의 거리를 최소화해야겠습니다. 저자는 이를 구현하기 위해 아래 L_{agg}를 사용하였습니다.
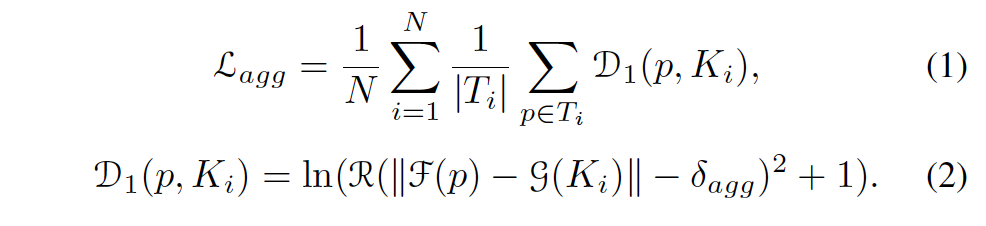
- N : text line 수
- T_i : i번째 text line의 text region
- K_i : T_i의 text kerel
- D_1(p, K_i): text pixel p와 text kernel K_i간의 거리
- R(•) : ReLU function (output이 음수가 나오지 않도록 하기 위한)
- F(p) : pixel p의 instance vector
- G(K_i) : text kernel K_i의 instance vector
- \delta_{agg} : 상수 (0.5로 설정)
여기서 text kernel의 instance vector인 G(K_i)는 해당 kernel의 모든 pixel들의 instance vector의 평균으로 구해집니다.
또, [Fig 7]의 빨간색 화살표와 같이 cluster는 다른 cluster들과 배경과의 구별을 위해 일정한 거리를 유지해야 하는데요, 이는 아래 L_{dis}를 설계하여 구현하였습니다.
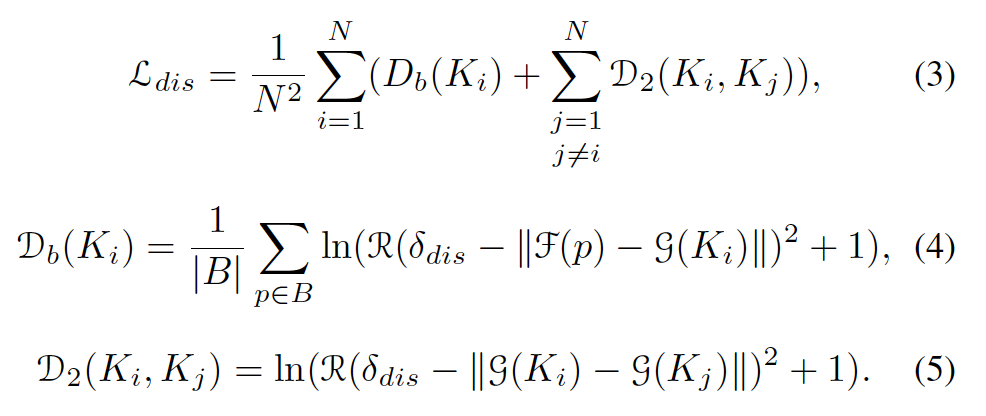
이 L_{dis}는 text kernel과 배경이 서로를 멀리 밀어내는 것이 목표입니다.
- B : 배경
- D_b(K_i) : kernel K_i와 background간의 거리
- D_2(K_i, K_j) : kernel K_i와 kernel K_j간의 거리
- \delta_{dis} : 상수 (3으로 설정)
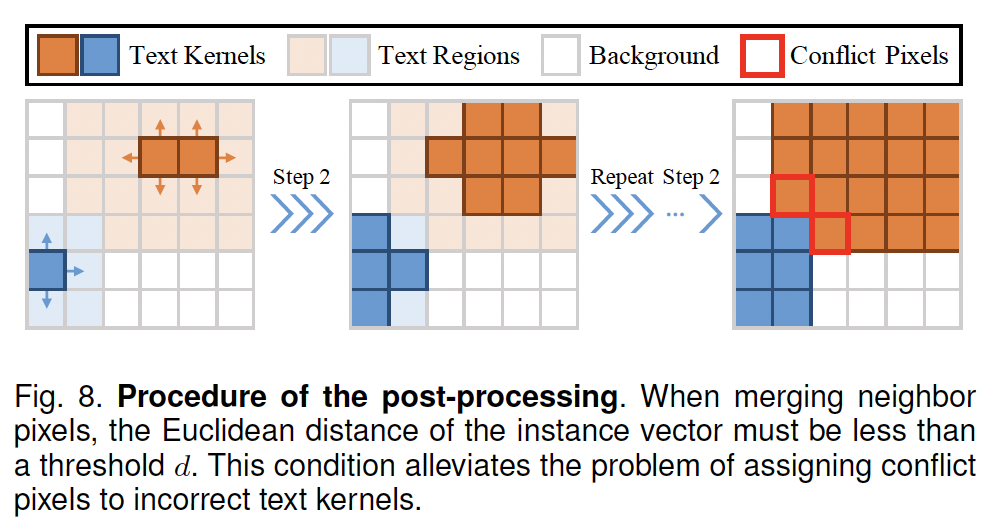
test할 때에는 text region내의 pixel에 대해 예측한 instance vector를 가지고 이에 해당하는 kernel로 cluster하게 되며, 위 그림과 같은 후처리 과정을 거칩니다.
진한 주황, 파란색이 text kernel이고, 흐린색이 region, 흰색이 배경입니다. 먼저 text kernel의 pixel들에 대해 연결되어 있는 pixel을 찾고, text kenel과 4방향의 이웃한 pixel들의 instance vector 유클리드 거리가 d보다 작게 되면 다음 이웃 pixel을 계산할 kernel로 간주하게 됩니다. text region에서 더이상 계산할 pixel이 존재하지 않을때까지 2번째 단계를 반복하게 되죠.
2.5 Text Recognition
방금까지 text detection 과정을 살펴봤으며, 이제 검출한 text line에 대해 recognition을 수행하는 과정을 알아봅시다.
2.5.1 Masked RoI
우선 masked RoI를 사용하여 detection한 text line에 대해 고정된 크기의 feature patch를 추출합니다.
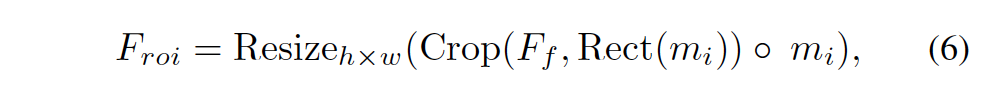
즉, 위와 같은 과정인데 하나씩 보자면 먼저 Rect()를 통해 text line을 포함하는 최소 bbox영역을 계산한 후, Crop으로 patch를 추출하고, Resize를 통해 feature patch의 크기를 고정시키는 것입니다.
이 masked RoI에는 두 가지 이점이 있는데, 1) target text line의 바이너리 마스크가 background나 다른 text line에서 발생하는 noise feature를 제거할 수 있어 arbitrary한 text line의 feature를 정확하게 추출할 수 있다는 것과 2) spatial rectification 단계를 거치지 않기 때문에 시간 소요를 대폭 줄일 수 있다는 점입니다.
2.5.2 Recognition Head
본 방법론의 text recognition model은 seq2seq 모델로 구성되어 있으며, multi-head attention을 사용합니다. 아래 그림에 보이는 것처럼 좌측에 starter와 가운데 decoder로 모델이 구성되게 됩니다.
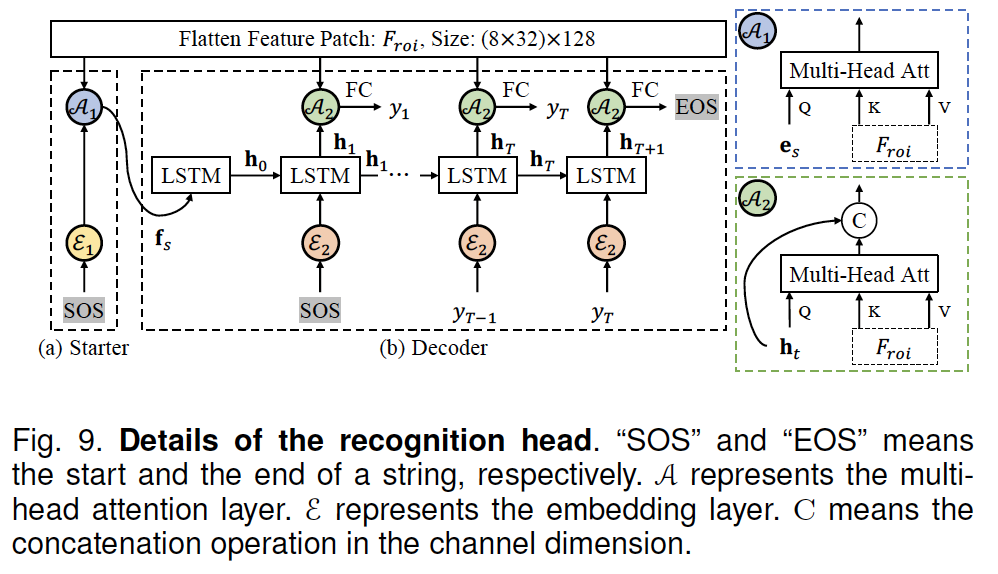
starter는 문자열의 시작 부분을 찾는 데 사용됩니다. starter의 맨 아래 부분에 SOS라고 적혀있는데 이는 Start of String을 의미합니다. starter는 선형 변환(임베딩 레이어)\mathcal{E}_1과, multi-head attention layer \mathcal{A}_1만으로 구성됩니다.
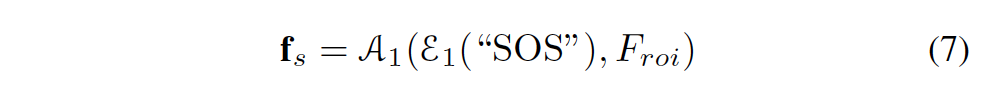
위 식과 같이 임베딩 레이어 \mathcal{E}_1는 SOS를 128차원 벡터로 변환하게 되고, 이 벡터는 앞선 maskted roi를 거쳐 추출하게 된 flatten feature patch인 mathcal{F}_{roi}와 함께 multi-head attention layer \mathcal{A}_1에 입력으로 들어가 SOS의 feature vector f_s를 생성하게 됩니다. 이렇게 생성된 f_s는 이제 Decoder의 입력으로 들어가게 되죠.
다음으로 decoder는 두 개의 LSTM layer와 하나의 multi head attention layer \mathcal{A}_2로 구성되어 있습니다. time step이 0일 떄 decoder는 SOS의 feature vector f_s와 zero LSTM의 initial state를 입력으로 받습니다. 이후 time step이 1일때는 time step 0에서의 hidden state h_0와 SOS가 LSTM의 입력으로 들어가고 y_1를 예측해냅니다. 이후 이전 단계의 output이 EOS(End of String) 토큰을 예측할 때까지 LSTM에 입력되게 됩니다. 방금 서술한 과정은 아래의 식으로 나타낼 수 있겠습니다.
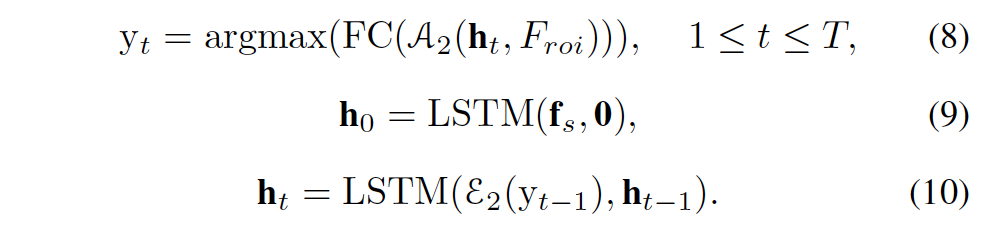
이렇게 설계한 recognition head는 좋은 성능을 냄과 동시에 가볍다고 합니다. 이 recognition head에는 encoder가 존재하지 않으며 decoder도 오직 두 개의 LSTM layer와 attention layer만을 포함하니 말이죠. 게다가 attention layer도 multi-head attention에 기반한 것이라 효율적으로 temporal features(LSTM)과 visual feature (CNN)을 fusion할 수 있습니다.
3. Experiment
저자는 text detection과 end-to-end 두 task에 대한 실험을 진행했습니다. 데이터셋으로는 곡선으로 되어있는 text의 성능을 평가하기 위해 total-text과, CTW1500을 사용하였으며, 직선으로 되어있는 데이터셋인 ICDAR 2015, MSRA-TD500, RCTW-17을 사용하였습니다. 또, PAN++을 사전학습시킬 때는 합성 데이터셋인 SynthText과 COCO-Text, ICDAR 2017 MLT를 사용하였습니다.
3.1 Experiments on Curved Text Datasets
먼저 curved된 text dataset에 대한 실험결과부터 보도록 하겠습니다.
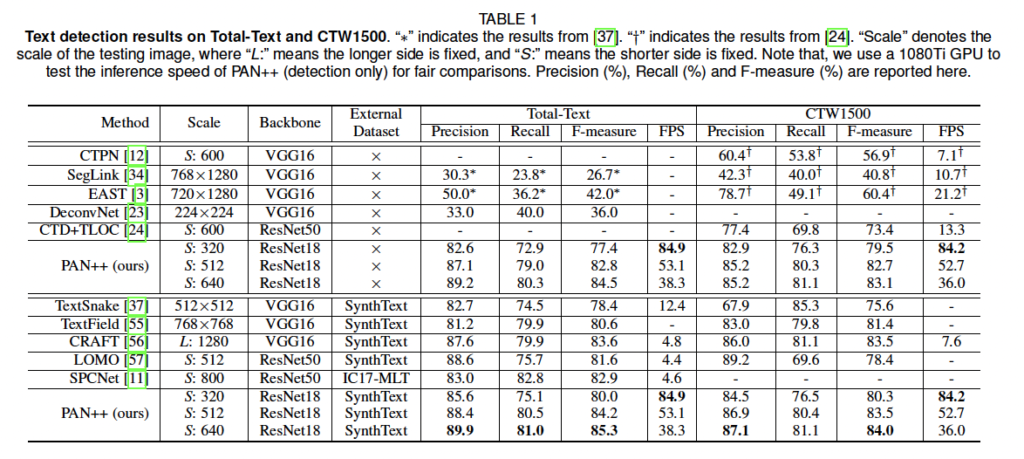
위 표는 text detection 결과인데, 상단과 하단 차이는 추가적인 데이터셋을 사용했는가 사용하지 않았는가 (사전학습 했는가 여부) 차이입니다. 결과를 보면 externel dataset을 이용하여 사전학습을 하기 않았음에도 CTW 1500 데이터셋에서 79.5%의 f-measure을 달성하여 대부분의 타 방법론과 비교했을 때 성능이 뛰어난 것을 확인할 수 있습니다. 이는 합성 데이텃셋을 사용하여 학습한 몇 타 방법론의 성능보다도 높은 것으로 보이네요 . . 또, PAN++의 FPS를 보시면 TextSnake보다 8배정도 빠르고 이전까지 가장 빠른 방법론이었던 EAST보다 4배정도 빠릅니다. 즉, PAN++은 curved된 text도 잘 검출해냄과 동시에 속도도 빠른 것을 알 수 있었습니다.
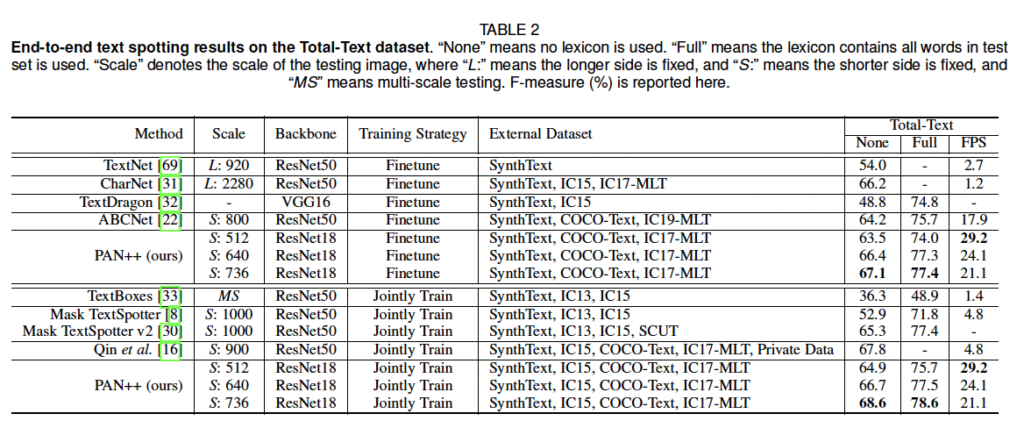
이 표는 end-to-end text spotting 결과입니다. 즉, text detection과 text recognition을 합친 결과이죠. 여기서는 total-text dataset에 대해서만 실험을 진행했는데, 본 방법론 이전에 가장 빠른 방법론인 ABCNet과 비교해보았을 때, 본 방법론이 1.3배 빠른 동시에 F-measure이 더 높은 것을 볼 수 있습니다. 여기서 total-text아래 적혀져 있는 None과 Full은 lexicon(단어 사전) 사용 여부라고 보시면 됩니다. 단어 사전을 사용했다라는 것은 (Full의 경우) 모델이 단어를 recognition 한 후 단어사전에서 가장 유사한 것 혹은 일치하는 것을 선택하는 것으로 단순히 classification이라고 이해해도 괜찮을 것 같습니다. 물론 이 lexicon을 사용한 경우가 사용하지 않았을 때보다 성능이 조금 더 좋은 것을 볼 수 있습니다.
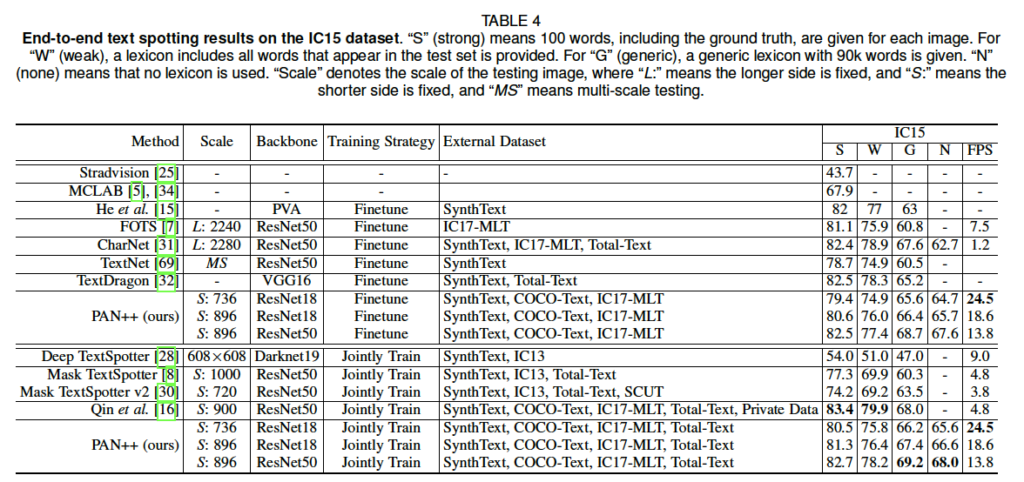
이건 직선으로 되어있는 dataset으로 평가를 진행한 것인데, 타 방법론 대시 성능이 가장 좋다고는 할 수 없겠습니다만 추론 속도는 굉장히 빠른 것으로 보입니다. 아무래도 곡선으로 되어있는 데이터셋에 비해 상대적으로 쉽다보니 타 방법론들도 80언저리로 성능이 높은 것을 볼 수 있네요. 또, IC15아래 적혀있는 S, W, G, N은 각각 Strong, Weak, Generic, None으로 앞에서 언급한 lexicon(단어사전)의 단어 개수 정도를 다르게 한 것이라고 이해하면 됩니다. 사실, PAN++은 타 방법론들과 다르게 사전학습 데이터셋을 많이 사용한 것에 비하여 성능이 그렇게 높지 않은 것으로 보아,, SynthText 데이터셋만 사용하여 pre-training한다면 성능 드랍이 더 있을 수도 있을 것 같습니다.

이건 정성적 결과인데, (a)의 total-text 데이터셋 결과처럼 곡선으로 되어있는 text들도 검출을 잘 해내는 편이며, (b)와 같이 좀 윗줄과 아랫줄 text가 인접해 있는 경우에도 하나로 검출하는 것이 아닌 각각의 text instance를 잘 검출해내고 있습니다.
Ablation Study
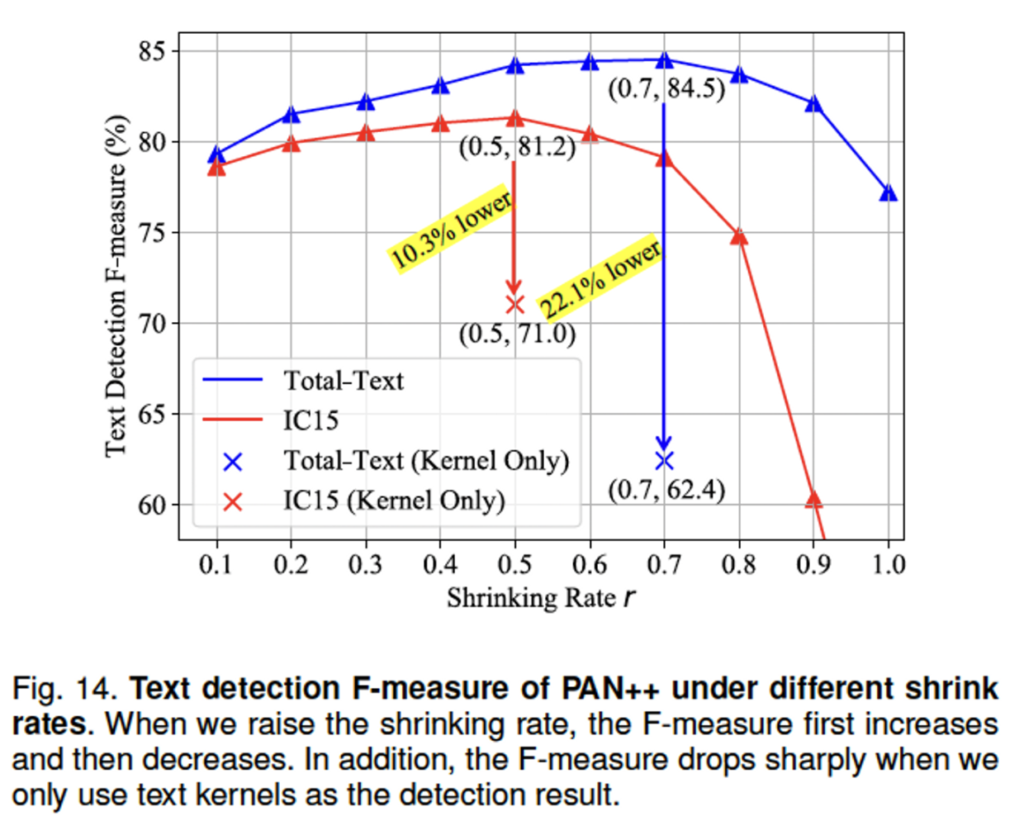
마지막으로 ablation study입니다. 위 그림은 kernel만 사용했을 경우와 kernel과 함께 text region, instance vector도 함께 사용했을 경우의 성능을 비교하고 있습니다. 우선 X쳐려 있는 것들이 text kernel만 오직 사용한 것인데, 이렇게 kernel만 사용했을 경우에 text line의 완전한 형태를 커버하지 못하고, 그렇기에 이를 직접적인 검출 결과로 사용할 수 없기 때문에 성능이 많이 하락한 것을 볼 수 있습니다. 이 결과를 봤을 때 text kernel의 detection 결과를 단독으로 사용하기는 어렵고, kernel representation의 다른 부분(region, instance vector)와 결합해야 한다는 결론을 내릴 수 있겠네요.
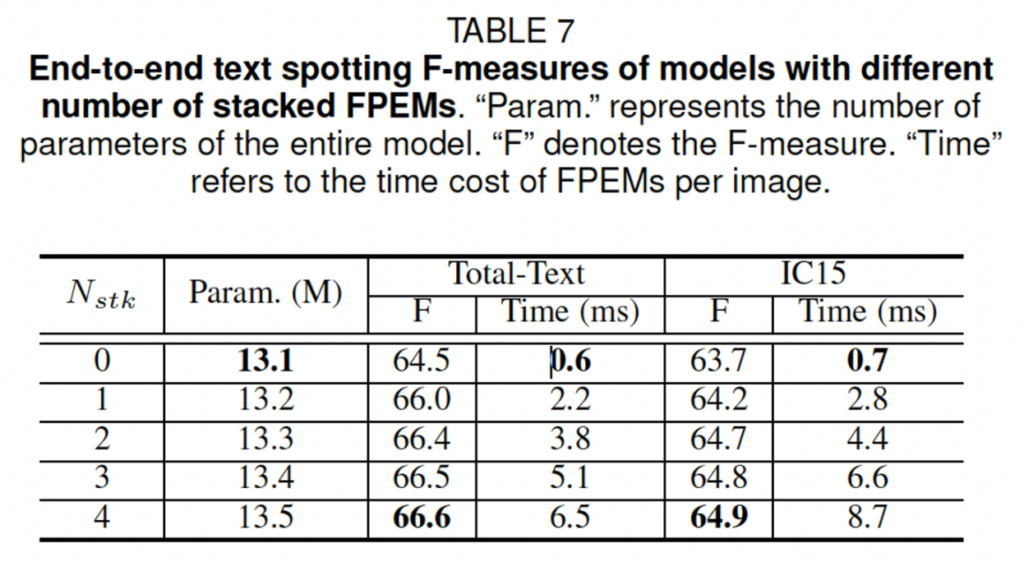
또, 저자는 FPEM을 몇개 쌓는지에 따라 달라지는 성능을 확인해 보기 위해 스택 수 N_{stk}를 0에서 4까지 바꿔가며 실험을 수행했습니다. 여기서 stack 수가 0인 경우에는 FPEM이 없고, 최종 feature map F_f는 feature pyramid F_r을 upsampling하고 concat하여 생성한 것입니다. 위 표에서 볼 수 있듯, stack 수가 증가할수록 f-measure가 높아지는 것을 볼 수 있지만, 2 이상부터는 그렇게 눈에 띄게 높아지지 않습니다 그렇기에 저자는 stack수를 마냥 많이 설정하기 보다는 parameter수를 고려하여 성능과 속도 사이의 균형을 맞추기 위해 기본적으로 2로 설정하였습니다.
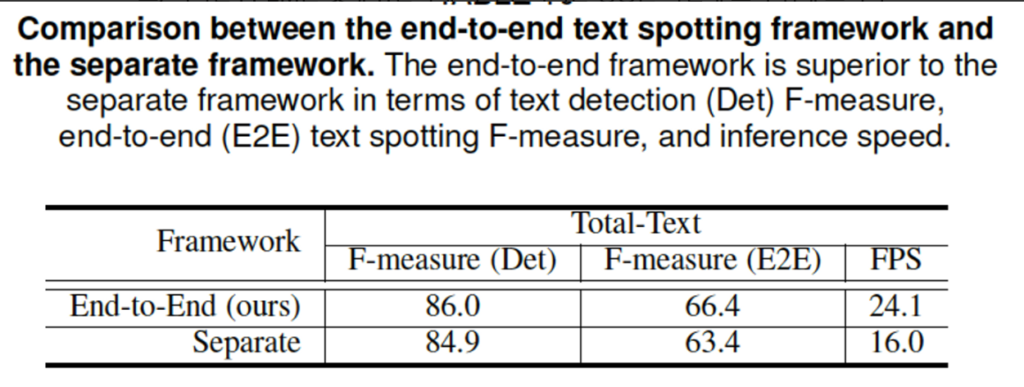
마지막으로 PAN++을 동일한 설정 하에서 end-to-end일 때와 detection과 recognition을 각각 수행했을 때의 성능과 FPS 차이를 확인하고 마무리하도록 하겠습니다. 우선 end-to-end 모델은 86.0%의 text detection f-measure와 66.4%의 text spotting f-measure을 달성하였습니다. 이건 각 모듈을 따로 수행했을 때보다 더 높은 성능인 동시에 더 빠른 결과를 보입니다. 이로써 end-to-end text spotting 프레임워크가 정확도와 inference 속도 측면에서 separate 프레임워크보다 더 우수하다는 결론을 내릴 수 있겠습니다. 이 이유로는 end-to-end 프레임워크에는 detection 모듈과 recognition 모듈이 같이 학습되기 때문에 backbone feature를 동시에 detection과 recognition loss로 최적화할 수 있기 때문이라고 볼 수 있겠네요. 또, 속도가 빠른 이유는 당연하게도 backbone을 공유하기 때문에 end-to-end 프레임워크는 text recognition에서 image feature를 인코딩하는 시간이 생략되기 때문입니다.
안녕하세요. 정윤서 연구원님.
좋은 리뷰 감사합니다.
lexicon에 대하여 처음 들어봐서, 이 개념을 알게되니 조금 헷갈리는 부분이 있어 질문드립니다.
모델이 lexicon을 이용할 경우, apple이라는 텍스트를 (a, p, p, l, e)와 같이 한 글자씩 인식하는 것이 아니라 (apple, appear …)와 같은 단어 사전에서 classification으로 푼다는 것으로 이해하였는데 맞나요?
또한, lexicon을 사용할 경우 일반적인 출력의 형태와 사용하지 않을 경우 출력의 형태가 궁굼합니다.
감사합니다.
댓글 감사합니다.
1. 네 지오님이 이해하신바가 맞습니다.
2. 출력 형태라 함이 recognition module을 통과했을 때의 출력 형태를 말씀하시는 것이면 둘 다 동일하게 word형태의 text로 나오게 됩니다.
안녕하세요 정윤서 연구원님.
좋은 리뷰 감사합니다.
FPEM의 동작 과정에서 질문이 있는데요, upscale enhancement 단계에서 2배씩 upscaling을 진행할 때 각 scale 마다 백본에서 추출된 multi scale feature를 더해주는 것으로 이해하였습니다. 이때 마지막에 input feature를 그대로 다시 더해주는 이유가 있나요? 해당 부분이 이전 논문인 PAN과의 차이점이라고 언급해 주셨는데 논문에는 저자들이 해당 구조를 사용한 이유가 설명되었는지 궁금합니다.
댓글 감사합니다.
PAN++이전 논문인 PAN에서는 FPEM 모듈 외에 Feature Fusion Module(FFM)이 존재했었습니다. FFM은 FPEM의 feature pyramid를 fusion하는 모듈이었고, 이는 low-level과 high level의 semantic한 정보 모두 semantic segmentation에 중요하다고 여겨지기 때문이죠.
저자는 이번 PAN++에서 이전 PAN에서의 FPEM과 FFM을 합쳐 하나의 FPEM 모듈로 가져감으로써 좀 더 효율적으로 동작하도록 한 것입니다.
안녕하세요. 리뷰 잘 읽었습니다.
kernel representation을 말씀해주신 부분에서 kernel의 이점 중 하나로 추가적인 어노테이션 없이 생성 가능하다고 하셨는데, 그 이후에 kernel의 label 생성 과정에 대한 설명이 빠져있는 것 같아, 보충 설명 부탁드립니다.
감사합니다.
댓글 감사합니다.
기존 gt bbox를 vatti clipping 알고리즘을 사용하여 일정 마진으로 축소시킨 것을 kernel의 label로 사용합니다.