안녕하세요.
이번에도 6D pose estimation 방법론에 대한 논문을 리뷰해보았습니다. CNN-based 논문이기 때문에 전체적인 네트워크 구조 자체는 어렵지 않으나 디테일한 방법들은 여전히 어려운 것 같습니다.
리뷰 시작하겠습니다.
Abstract
자율 로봇 조작에는 조작할 물체의 이동과 방향을 6-DoF(Degree of freedom) pose로 추정하는 작업이 포함됩니다. RGB-D를 사용하는 방법은 이 문제를 해결하는 데 큰 성공을 거두었습니다. 그러나 비용 제약이나 작업 환경으로 인해 RGB-D 센서 사용이 제한될 수 있는 상황이 있습니다. monocular 카메라로만 제한할 경우 물체 pose 추정 문제는 매우 어렵습니다. 이 연구에서는 단안 영상에서 6D 물체의 pose를 예측하는 새로운 방법인 SilhoNet을 제안합니다. 저자는 관심 영역(ROI) 제안을 받아들이는 CNN 파이프라인을 사용하여 occlusion mask와 3D translation 벡터가 연결된 오브젝트에 대한 intermediate silhouette representation을 동시에 예측합니다. 그런 다음 3D rotation은 예측된 silhouette에서 regression합니다. 이 방법은 monocular 이미지 입력으로부터 6D pose를 추정하는 YCB-V 데이터셋 에서 전반적으로 더 나은 성능을 달성한다는 것을 보여줍니다.
I. INTRODUCTION
로봇은 우리의 삶에 많은 도움을 줄 수 있도록 기술력이 발전하고 있습니다. 예를 들어 몸이 불편한 사람이 집안에서 다양한 작업을 수행할 수 있도록 돕는 것는 로봇이 있고, 사람이 접근하기 어려운 환경에서 자율적으로 데이터를 수집하는 것도 있습니다. 이처럼 로봇은 흥미롭고 영향력 있는 다양한 영역에 적용되고 있습니다. 이러한 애플리케이션의 대부분은 로봇이 어떤 방식으로든 물체를 잡거나 조작하는 것에 대해 여전히 챌린지한 상황을 겪고 있습니다. 특히 로봇은 물체의 위치를 파악하기 위해 장면의 sensory 정보를 해석해야 합니다. 로봇 조작 외에도 증강 현실과 같이 이미지에서 물체의 정확한 위치 파악이 필요한 애플리케이션도 있습니다.
기존의 오브젝트 pose 추정 방법은 주로 3D 작업 환경에 대한 RGB-D 데이터에 의존합니다. 그러나 이러한 depth 정보를 쉽게 구할 수 없는 경우가 있습니다. 몇 가지 예로는 Kinect 같은 일반적인 depth 센서가 잘 작동하지 않는 outdoor에서 작동하는 시스템, 공간과 비용으로 인해 센서의 크기와 수가 제한될 수 있는 임베디드 시스템이 있습니다. 이러한 시나리오에서는 monocular 카메라에서 작동하는 방법이 필요합니다. 센서 모달리티가 monocular 이미지로 제한되어 있는 경우, scene illumination의 가변성, 다양한 물체 모양과 텍스처, scene clutter로 인한 occlusion이 있는 상황에서는 물체의 pose를 추정하는 것은 어려운 문제입니다.
이번 논문에서는 기존의 있던 방법론의 성능을 개선하여 단안 이미지에서 6D pose estimation을 하는 새로운 방법론을 제안합니다. 3D 오브젝트 외관에 대한 사전 정보를 네트워크 아키텍처에 명시적으로 통합하고, intermediate silhouette 기반 object viewpoint representation을 사용하여 방향(회전)에 대한 예측 정확도를 개선합니다. 또한 제안한 방법론은 오브젝트에 대한 occlusion 정보를 제공하여 오브젝트 모델의 어느 부분이 scene에 표시되는지 결정하는 데 사용할 수 있습니다. monocular 이미지에서 대상 물체가 어떻게, 얼마나 occlusion 되는지를 아는 것은 물체의 보이는 부분만 projection 하는 것이 중요한 증강 현실과 같은 특정 애플리케이션에서 중요한 역할이 됩니다.
해당 논문의 contribution은 다음과 같습니다.
- 복잡한 장면에서 pose와 occlusion을 추정하는 새로운 RGB 기반 딥러닝 방법인 SilhoNet을 제안함
- intermediate silhouette representation을 사용하여 합성 데이터에서 모델을 학습하고 실제 데이터에서 6D object pose를 예측함으로써 sim-to-real domain shift를 효과적으로 연결하는 역할을 함
- 새로운 scene에서 예측된 silhouette의 projection을 사용하여 오브젝트 모델의 어느 부분이 시각적으로 제외되지 않았는지 결정하는 방법을 제안함
- YCB-Video 데이터셋에서 실험을 진행하였고, 제안된 접근 방식이 다른 방법론들 보다 우수한 성능을 보임
II. RELATED WORK
RGB-D 데이터를 사용한 6D 오브젝트 pose 추정에 대한 광범위한 연구가 진행되었습니다.
- 여러 연구에서 특징 및 모양 기반 템플릿 매칭에 의존하여 이미지에서 물체의 위치를 찾고 pose를 대략적으로 추정합니다.
- 3D 오브젝트 모델과 scene의 depth map을 사용하여 Iterative Closest Point(ICP) 알고리즘을 사용하는 refinement 단계가 이어집니다. 이러한 방법은 계산 효율이 높지만 복잡한 환경에서는 성능이 저하되는 경우가 많습니다. 다른 방법으로는 point cloud 데이터를 활용하여 3D feature를 일치시키고 오브젝트 모델을 scene에 맞추는 방법이 있습니다. point cloud 기반 방법론은 SOTA를 달성하지만 계산 비용이 매우 높을 수 있습니다.
- Conditional Random Field(CRF)를 학습하여 RandomForest에 의해 계산된 dense pixel-wise 객체 좌표 prediction map에서 여러 가지 pose-hypothesis를 출력했습니다. 최종 pose 추정치를 도출하기 위해 ICP의 변형을 사용했습니다. 이러한 학습 기반 방법은 robust하고 효율적이며 좋은 성능을 제공하지만, 오브젝트 pose를 추정하기 위해 RGB-D 데이터에 의존합니다.
- 에서는 최근 딥러닝 방법을 RGB 데이터만을 사용하여 6D 물체 pose 추정 문제로 확장한 몇 가지 연구가 있습니다. CNN을 사용하여 이미지에서 3D bounding box 모서리의 2D projection을 예측한 다음 PnP 알고리즘을 사용하여 2D-3D 좌표 간의 대응을 찾아 객체 pose를 계산했습니다.
- PoseCNN에서는 Hugh Voting 방식을 사용하여 6D 객체 pose를 3D translation 및 단위 quarternion 방향으로 direct regression 하는 네트워크를 제안했습니다.
- DeepIM에서는 RGB 기반 pose 정합을 위한 딥러닝 기반 iterative 정합 알고리즘을 제안했는데, 이 알고리즘은 깊이 정보를 ICP로 사용하는 방법에 근접한 성능을 달성하며 모든 RGB 기반 방법에 사후 정합으로 적용할 수 있습니다. 이러한 RGB 기반 pose 추정 방법은 깊이 데이터에 의존하는 최신 접근 방식에 비해 경쟁력 있는 성능을 보여줍니다.
저자의 이번 논문에서는 딥러닝의 성능과 오브젝트 모델에 대한 사전 정보를 결합하여 silhouette 예측에서 pose를 추정합니다. 또한 이 방법은 예측된 rotation 에 따라 오브젝트가 시각적으로 어떻게 가려지는지에 대한 정보를 occlusion mask 형태로 제공하며, 이 mask는 오브젝트 모델에 투영될 수 있습니다.
III. METHOD
monocular RGB 이미지에서 작동하여 6D Object pose estimation 방법을 설명하는 섹션입니다.
3D orientation은 unocclusion인 intermediate silhouette representation으로부터 예측됩니다. 또한 이 방법은 이미지에서 오브젝트 모델의 어느 부분이 보이는지 결정하는 데 사용할 수 있는 occlusion mask도 예측합니다. 이 방법은 translation을 나타내는 벡터와 함께 오브젝트의 intermediate silhouette representation과 occlusion mask를 예측한 다음 예측된 silhouette에서 rotation quaternion을 regression하는 방
A. Overview of the Network Pipeline
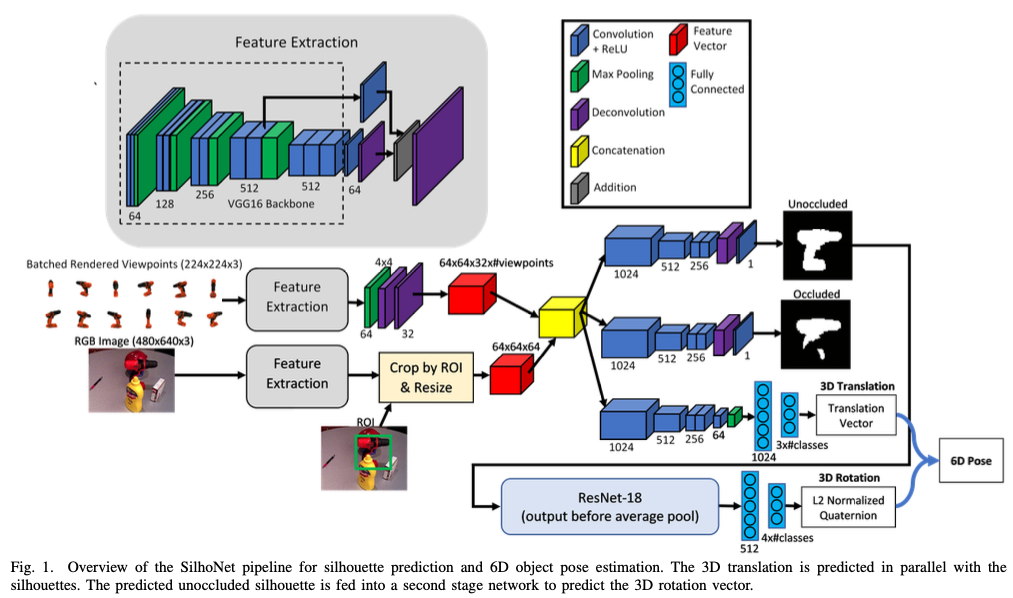
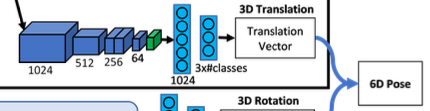
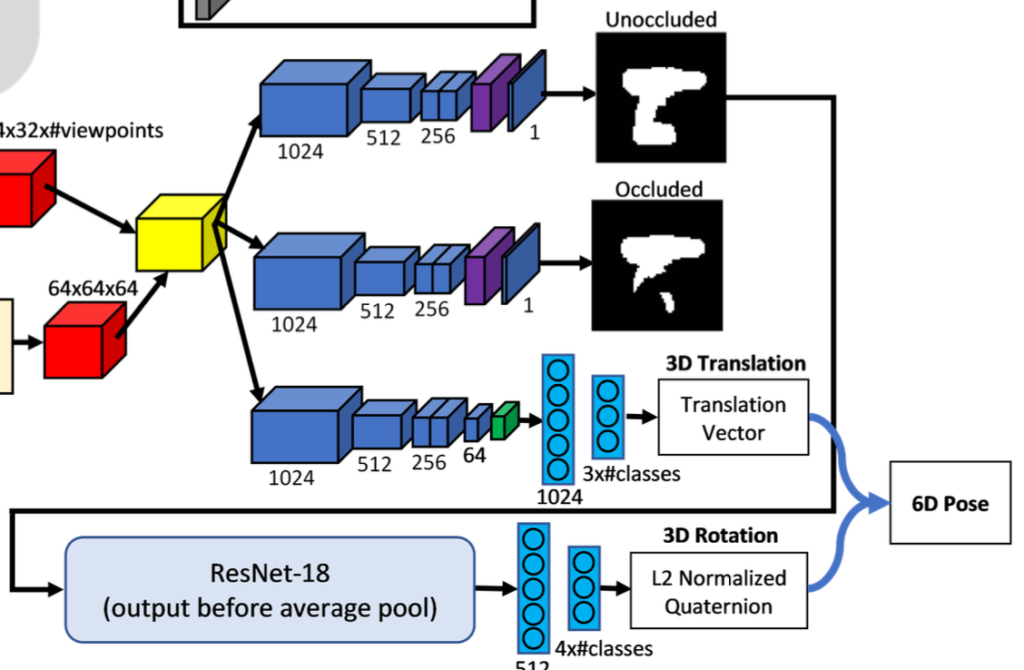
그림(1)은 전체적인 SilhoNet 파이프라인을 설명하는 그림인데요. 네트워크에 대한 입력은 detection된 오브젝트와 관련있는 클래스에 대한 ROI 영역이 포함된 RGB 이미지입니다.
첫 번째 스텝에서는 마지막에 deconvolution layer가 있는 VGG16을 backbone으로 사용하여 입력으로 받는RGB 이미지로부터 Feature map을 생성합니다. 이후 입력 이미지에서 추출한 feature는 렌더링된 오브젝트 viewpoint 세트의 feature와 concat된 다음 세 개의 브랜치를 통과하게 됩니다. 이 중 두 개(1, 2번째)는 동일한 구조로 full unoccluded silhouette과 occlusion mask를 예측합니다. 여기서 세 번째 branch는 객체 중심을 픽셀 좌표로 인코딩하는 3D vector와 카메라로부터의 객체 중심 거리를 예측합니다. 즉, translation vector를 예측하는 branch가 됩니다.
두 번째 스텝에서는 예측된 silhouette을 마지막에 FC layer 2개로 구성된 ResNet18를 통과하여 3D rotation을 나타내는 L2 정규화된 quarternion을 출력합니다.
1) Predicted ROIs
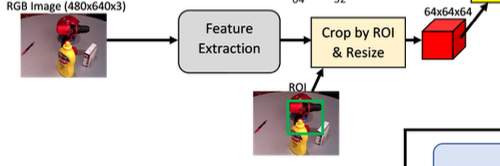
해당 방법론은 ROI proposal을 수행해야 하는데요. YCB-V 데이터셋에 대해 Faster- RCNN을 학습했다고 합니다. 이러한 ROI proposal은 특징 추출을 거치고 다시 네트워크의 입력으로 들어가게 됩니다. 이때 입력 이미지 feature map에서 ROI 영역을 crop에 사용됩니다. crop을 거친 feature map은 resize를 거치게 되는데, 크기를 축소하거나 bilinear interpolation을 이용한 확대를 통해 64×64의 크기로 맞춰줍니다.
2) Rendered Model Viewpoints

저자는 네트워크의 첫 번째 스탭에 추가적인 입력을 주었는데요. detection된 오브젝트의 클래스와 관련된 사전에 렌더링 된 합성 뷰포인트 세트를 생성하여 silhouette 예측 성능을 향상시킬 수 있었다고 합니다.
각 클래스에 대한 오브젝트 모델을 12개 사용하였습니다. 이때, 크기는 224 \times 224인 viewpoint 세트를 렌더링하여 사용했다고 합니다. 해당 viewpoint의 기준은 0^\circ ~ 300^\circ과 -30^\circ~ 30^\circ 각도에 대해 생성되었습니다. intermediate에서의 목표는 silhouette 예측이므로 이러한 합성 렌더링은 시뮬레이션된 오브젝트의 시각적 외관에 대해서 domain shift가 존재함에도 불구하고 다양한 방향에서 실제 오브젝트의 모양과 silhouette을 캡처해서 사용할 수 있습니다.
detection된 오브젝트 클래스의 모든 viewpoint는 특징 추출 과정을 거친 다음 max pooling 통과하고 deconvolution layer 2개를 통과합니다. 실제 구현에서는 각 오브젝트 detection에 대해 렌더링된 viewpoint의 특징 맵을 즉석에서 추출했습니다.
그러나 계산 시간을 줄이기 위해 이러한 추출된 feature map을 미리 계산하여 저장할 수 있습니다. 렌더링된 viewpoint feature map과 크기가 조정된 입력 이미지 feature map과 concat하여 사용하였다고 합니다.
3) Silhouette Prediction
네트워크의 첫 번째 단계에서는 오브젝트의 중간 실루엣 표현 intermediate silhouette representation을 64\times64\times1를 가지는 binary mask를 예측하게 합니다. 이 silhouette은 마치 동일한 방향으로 렌더링되지만, 프레임 중앙에 있는 것처럼 오브젝트의 full unoccluded visual hull를 나타냅니다. 프레임 내 silhouette의 크기는 이미지 내 오브젝트의 scale에 변하지 않으며, 실루엣이 렌더링 되는 카메라에서 오브젝트의 고정된 거리에 따라 결정됩니다. 이 거리는 각 오브젝트에 대해 선택되므로 실루엣이 모든 방향에 대해 프레임 내에 맞게 됩니다.
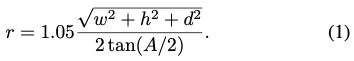
이미지 센서의 너비와 높이의 최소값, 오브젝트의 3D 영역를 너비, 높이, 깊이 (w, h, d) 로 결정되는 카메라 A의 최소 FOV(Field of View)가 주어지면 렌더링 거리 r 을 식(1)과 같이 계산합니다.
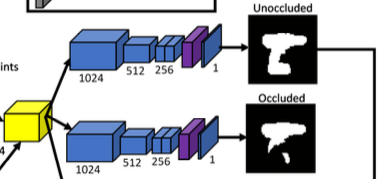
네트워크의 해당 과정에서는 오브젝트의 occlusion 되지 않은 부분만 보이도록 즉, 보이는 silhouette만을 출력하는 parallel branch도 있습니다. 해당 출력을 occlusion mask라고 합니다.
입력 이미지가 Feature Extractor(VGG16을 살짝 수정)를 통과한 후 detection된 객체에 대한 입력으로 사용하게 되는데, ROI proposal을 사용하여 결과 특징 맵의 해당 영역을 잘라내고 64\times64로 크기를 resize합니다. 해당 feature map은 사전에 렌더링된 viewpoint feature과 concat하면 64\times64\times448 크기의 단일 Feature vector matrix(노란색)이 생성됩니다. Feature vector matrix는 두 개의 동일한 branch로 들어가게 되며, 그 중 하나는 silhouette(unocclusion mask) 예측, 다른 하나는 occlusion mask 를 출력합니다. 각 branch는 convolution layer + deconvolution layer로 구성되어 있습니다. 마지막 출력에 대해 activation function으로 sigmoid를 적용하여 probability map을 생성합니다.
4) 3D Translation Regression
translation은 객체 중심 위치를 영상 좌표계로 인코딩하고 카메라 중심으로부터의 거리를 미터 단위로 인코딩하여 3차원 벡터로 예측합니다. 다른 RoI proposal 기반의 pose 추정 방법론들은 RoI에서 직접 Z좌표를 regression 해서 사용한다고 합니다. 하지만 이러한 방법론은 ambiguity를 발생시키게 되는데요. 카메라 중심을 기준으로 지정된 범위 내에서 물체를 이동하면 Z좌표는 바뀌지만 translation된 RoI의 물체 모양은 바뀌지 않습니다. 카메라는 고정되어 있고, 물체만 움직이는 경우를 생각하시면 이해하실 거라 생각합니다. ambiguity는 특히, 광시야각(wide field of view) 카메라에서 많이 발생한다고 합니다. 저자는 Z좌표를 direct regression하는 방법을 사용하지 않고, 물체의 범위를 예측하도록 합니다. 이렇게 하면 ambiguity 문제를 해결할 수 있고 높은 정확도로 Z좌표를 구할 수 있다고 합니다.
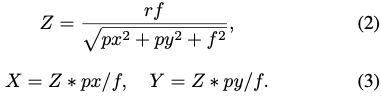
카메라 초점 거리 f, 이미지 중심에 대한 객체 중심의 픽셀 좌표 (px,py), 카메라 중심과 객체 중심의 범위 r이 주어지면 삼각형 닮음비를 사용하여 3D 객체의 translation, (X, Y, Z)를 식(2), (3)와 같이 얻는 것은 다들 아실 것이라 생각합니다.
객체 중심의 픽셀 좌표는 ROI 영역에 대해 box로 정규화하고 sigmoid 함수를 통과한 하단 box의 edge boundary로부터 offset을 예측하도록 합니다.
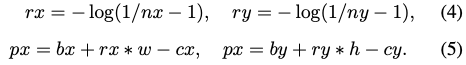
즉, 너비 w, 높이 h, 하단 좌표 (x, y)라고 할 때 boundary는 (bx,by)로 나타내고, 이미지 principal point의 좌표 (cx,cy)로 나타낼 때, 네트워크에서 예측된 정규화된 출력 (nx,ny)이 있는 ROI가 주어지면 객체 중심 픽셀 좌표 (px, py)는 식(4), (5)를 얻을 수 있습니다. 위 식에서는 오브젝트 중심의 픽셀 좌표만 principal point에 의해 offset된다는 점에 유의를 해야 합니다. 물체가 이미지 프레임에 완전히 들어가지 않으면 중심이 ROI 내에 위치하지 않을 수 있으며, ROI 예측이 불안정하기 때문에 물체 중심이 ROI 중심에 위치하는 경우는 거의 없습니다. 오브젝트 중심을 예측하는 이러한 방법은 ROI 내에 있는 지점을 제한하지 않으며, 불안정한 ROI 제안에도 강건하다고 합니다.
5) 3D Orientation Regression
rotation은 quarternion을 사용하게 되는데, quarternion에 대해 간략히 설명하면 임의의 3D rotation에 대해 길이가 4인 단위 벡터로 나타낼 수 있는 representation이라고 합니다. (이전에 PoseCNN 리뷰에 해당 내용을 작성하였으니, 참고해주시면 감사하겠습니다.)
ROI에서 방향을 예측하면 실제 물체의 방향이 이미지 내에서 추출된 위치에 따라 달라지기 때문에 visual ambiquity가 발생합니다. 이러한 문제를 해결하기 위해 이미지의 중앙에서 ROI를 추출한 것처럼 겉으로 보이는 방향을 예측하도록 네트워크를 설계합니다. 즉, 예측된 물체의 translation이 주어지면 예측된 방향에 대해 pitch (\delta \theta)와 roll (\delta \phi)을 조정해서 실제 방향을 복구하도록 설계합니다.
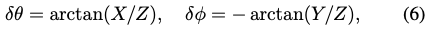
조정하는 방법은 식(6)과 같고 즉, X축에 대한 회전, Y축에 대한 회전을 통해 복구한다는 뜻이 됩니다.
두 번째 스탭에서 예측된 silhouette probability map은 특정 threshold에 따라 binary mask로 변환되고, 오브젝트 방향에 대한 quarternion 예측 결과를 출력합니다. 해당 과정에서 사용되는 backbone은 ResNet18을 사용하고 맨 마지막에 FC layer 2개로 구성되어있습니다. 마지막 FC layer같은 경우, 출력의 크기가 4\times n이고 이때 n은 클래스를 의미합니다. 해당 클래스는 별도의 출력 벡터를 갖습니다(detection된 클래스에 대한 예측 벡터를 의미). 해당 예측된 벡터는 l2-norm이 적용 됩니다.
해당 SilhoNet에서 제안하는 방법론은 오브젝트의 silhouette representation에는 특징이 적으므로, 오브젝트에 대칭과 비대칭에 대해 고려하지 못하고 모두 동등한 대칭으로 취급합니다. 모든 비대칭까지 모두 고려하여 rotation을 추정도록 확장하는 것이 해당 방법론의 향후 목표라고 합니다.
intermediate silhouette representation에서 rotation을 regression시킴으로써 합성으로 렌더링된 silhouette 데이터만을 사용하여 이 단계의 네트워크를 학습할 수 있었습니다. 실험 결과, 네트워크가 실제 데이터의 pose를 예측하는 데 일반화가 잘 되어 이 intermediate representation이 실제 데이터와 합성 데이터 사이의 domain shift를 효과적으로 연결할 수 있음을 보여주었습니다.
6) Occlusion Prediction
오브젝트의 예측된 외형의 방향이 주어지면 occlusion mask를 예측하여 오브젝트 모델에 투영하여 scene에서 모델의 어느 부분이 표시되는지 결정할 수 있습니다. 수학적으로는 오브젝트 모델의 모든 vertex v를 occlusion mask에 투영하면 이 작업을 수행할 수 있습니다. 해당 오브젝트 클래스의 렌더링 거리 r과 동일한 z 변환 컴포넌트와 0으로 설정된 x, y translation 컴포넌트를 사용하여 변환 행렬 T를 구성합니다. 회전 하위 행렬은 예측된 외형 방향에서 형성됩니다.

식(7)을 사용하여 오브젝트 모델의 각 vertex를 입력 이미지의 최소 차원에 맞게 scale up된 occlusion mask에 투영할 수 있습니다. 여기서 K는 카메라 고유 행렬, v는 오브젝트 좌표계에서 vertex의 3D 좌표, \gamma는 scale up된 occlusion mask에 투영된 vertex의 픽셀 좌표입니다. 오브젝트 self-occlusion을 고려하지 않고 occlsuion mask의 보이는 부분에 있는 vetex는 이미지에 표시되도록 예측합니다.
B. Network Training
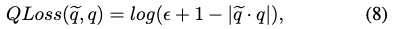
Translation branch에서는 L2 loss를 사용하였고, rotation regression 네트워크는 예측된 quarternion과 GT quarternion 사이의 식(8)과 같은 로그 거리 함수를 사용하여 학습되었습니다. 여기서 q는 GT quarternion, \tilde q는 예측된 쿼터니언, \epsilon는 stability를 조절하기 위한 파라미터 값(해당 경우 e^{-4})입니다.
IV. RESULTS
A. Silhouette Prediction
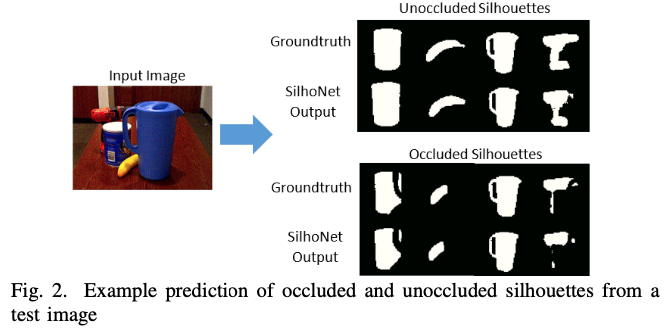
SilhoNet의 silhouette 예측 과정의 성능을 YCB의 두 가지 GT ROI 입력으로 테스트했습니다. 그림(2)는 테스트셋의 이미지 중 하나의 대한 silhouette 예측의 예를 보여줍니다.
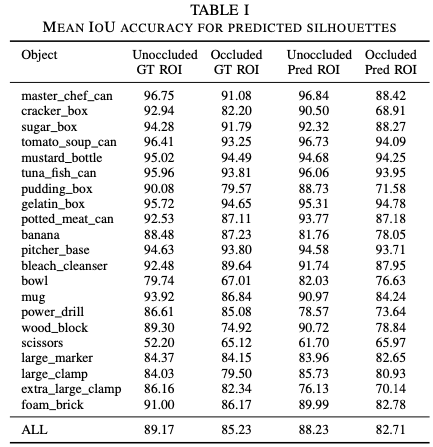
표(I)은 silhouette 예측과 occluded silhouette과 unoccluded silhouette 예측의 정확도를 예측된 silhouette과 GT silhouette의 mean IoU로 측정한 값으로 표시합니다. 전반적으로 GT값(GT ROI)이 아닌 예측 ROI(Pred ROI)를 입력으로 제공하면 성능이 몇 퍼센트 저하되지만, 일반적으로 예측은 ROI 입력에 대해 robust합니다.
B. 6D Pose Regression
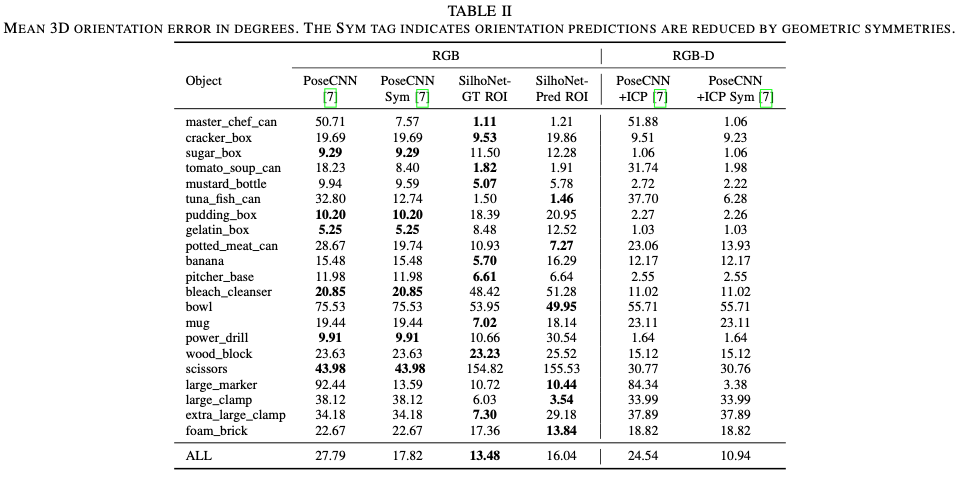
표(II)는 각 클래스의 rotation error에 대한 평균을 PoseCNN과 SilhoNet 방법론 모두에 걸쳐 보여줍니다. SilhoNet의 예측 정확도가 PoseCNN에 비해 가장 낮은 클래스는 “bleach cleanser”와 “scissors”입니다. SilhoNet은 이 두 물체를 silhouette 공간에서 대칭이 아닌 것으로 취급하지만, 두 물체의 모양은 거의 평면 대칭이며 특히 부분적으로 가려진 경우 silhouette의 pose 예측에 혼동이 될 수 있습니다. SilhoNet은 대칭을 통해 방향 공간을 가장 많이 줄이는 ‘master chef can’이나 ‘tomato soup can’과 같은 원통형 물체에서 좋은 성능을 보이고 있습니다. SilhoNet의 방향 예측 정확도는 예측된 ROI가 입력으로 제공될 때 감소하지만, 전반적으로 PoseCNN에 비해 여전히 상당한 개선이 있어 SilhoNet이 영역 제안에 효과가 있음을 입증하였습니다.
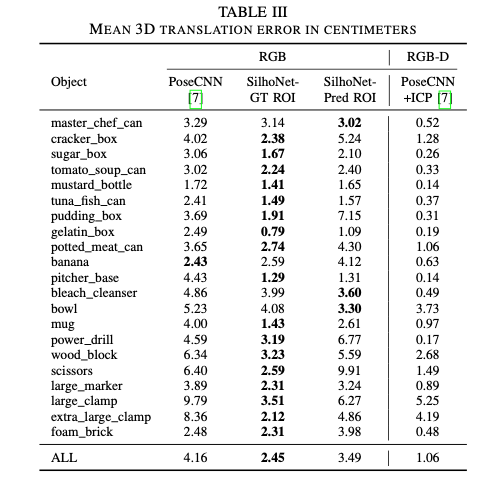
표(III)은 각 객체 클래스에 대한 translation error의 평균 보여줍니다. SilhoNet은 ICP refinement 전 대부분의 클래스에서 PoseCNN보다 성능이 뛰어납니다. 예측된 ROI가 입력으로 제공되면 SilhoNet의 translation 예측 정확도도 감소하지만 여전히 PoseCNN에 비해 상당한 개선이 이루어집니다.
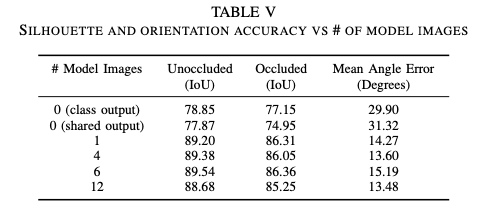
표(5)를 마지막으로 ablation study 입니다. 렌더링 모델 이미지를 입력으로 12개를 주었을 때 가장 성능이 좋았음을 보입니다.
V. CONCLUSION
SilhoNet은 외관으로 보이는 viewpoint에 대한 ambiguity에 영향을 받지 않는 새로운 3D translation 예측을 위한 방법을 제안하여 기존 방법론들보다 번역 정확도를 향상시켰습니다. SilhoNet은 silhouette 공간에서 대칭에 대해 고유한 rotation을 예측합니다. 저자는 이번 논문에 제안한 방법론을 객체의 모양에 대한 대칭성에도 불구하고 특징 공간에서 고유한 방향 예측으로 확장하는 데 중점을 둔다고 합니다.
좋은 리뷰 감사합니다.
우선 첫번째 스템에서 렌더링된 viewpoints 세트를 이미지에서 추출한 feature와 concat한다고 하셨는데, 랜더링된 viewpoints는 랜덤하게 12개가 선별되는 것인가요?
또한, Silhouette Prediction과 관련된 부분을 보면, unoccluded와 occluded mask가 동일한 feature로부터 생성이 되는데, 두 브랜치가 모두 필요할지에 대한 의문이 듭니다. 혹시 이와 관련하여 ablation study나 언급이 있었나요? 그리고 이에 대해 양희진 연구원님은 어떻게 생각하시나요? 두 마스크 예측이 모두 필요하다고 생각하시나요?
안녕하세요, 이승현 연구원님.
1. 한 개의 클래스에 대한 12개의 다른 렌더링 viewpoint set을 가지게 됩니다
2. 사실 저희는 unoccluded mask만 필요하긴 합니다. 해당 논문에서도 occluded mask는 다른 task(AR)에서 사용할 때 중요한 역할을 할 것이다. 라고 언급을 합니다. 이와 관련된 ablation study는 없었고 이승현 연구원님 말씀대로 해당 논문에서 수행하는 과정에서는 딱히 필요 없는 것 같습니다.
감사합니다.
안녕하세요 ! 좋은 리뷰 감사합니다.
제가 6D Pose Estimation에 대해 잘 몰라서 드는 궁금증일 수도 있는데 .. 해당 task에서는 물체의 silhouette을 예측하는 것이 일반적인 방법인가요 ? ? 첫번째 스텝에서 detection된 오브젝트의 클래스와 관련된 사전에 랜더링 된 합성 뷰포인트 세트를 생성한다고 설명해주셨는데 그러면 검출된 오브젝트와 클래스만 같은 모든 물체를 사용할 수 있는 것인가요? 같은 클래스이더라도 어떤 물체이냐에 따라 silhouette은 다르기 마련이라고 생각이 드는데 그런 점들이 silhouette을을 예측하는데에 영향이 없는 것인지 궁금합니다.
감사합니다 !
안녕하세요, 손건화 연구원님.
1. 주로 silhouette이라는 표현은 저도 처음봐서 흥미로웠습니다. 저희가 잘 아는 mask라는 표현으로 많이 사용을 합니다. 해당 논문에서 제안하는 방법은 단일 오브젝트에 대해 예측을 수행하는 것이기 때문에 단일 오브젝트에 대한 마스크를 수행하는 것이고, 이러한 마스크를 통한 방법론들은 CNN-based 방법론에서는 일반적으로 많이 사용하는 방법론입니다.
2. 데이터셋에서 제공하는 1~21번까지의 클래스만을 사용하기 때문에 나와있는 드릴로 예를 들자면, 제안한 RoI가 드릴인 경우, 드릴 클래스에 대해 사전에 렌더링 된 viewpoint set을 사용하여 학습을 하는 것입니다.
감사합니다.