안녕하세요. 스무 번째 리뷰입니다. 관심 영역의 새로운 태스크 논문을 읽는 것이 아직 쉽지 않네요. 이해력이 아직 부족하지만 Few-shot, Meta-learning을 Detection에 활용한 분야에 더욱 관심과 지식을 얻고자 읽고 있습니다. 이번 논문은, Faster R-CNN에 대한 지식이 요구되나 우리는 RPN, RoI에 대해서는 워낙 잘 알고 있죠. 만약 헷갈린다면 이전 리뷰에서 언급하였으니 한번 읽고 오면 좋을 것 같습니다. 그럼, 시작하겠습니다.
Introduction
저자는 도입부에서 현존하는 CNN 방법들이 Never-seen-before, 즉 이전에 한번도 보지 않은 물체의 샘플이 소수일 때, 이를 인지하는 성능이 낮음을 언급합니다. 이는 물론 CNN 방법이 Numerous한 데이터에 의존함에 기인한 것이겠죠. Few-label로부터 (N-way K-shot에 대해 다시 언급하자면 우리가 특정 객체에 대해 학습할 수 있는 데이터의 양이 5개의 클래스에 대해 각각 10개의 샘플, 50장의 이미지가 존재할 때 5-Way 10-Shot으로 불립니다. Few에 대해 몇 장에서 몇 장까지를 인정하는 지에 대해서는 보지 못하였으나, 한 객체를 인지하는데 10장이면 많이 부족한 수준이니 Few-shot으로 볼 수 있겠네요) 객체를 인지하는 방법은 주로 Few-shot, Low-shot learning에 대한 접근법이였으며, Few-shot learning의 한 방법으로 Meta learning이 효과적이고 자주 쓰임을 언급합니다.
그렇다면 이 Meta learning이 무엇인지가 굉장히 중요한데, 쉽게는 Model-Agnostic, 모델에 상관없이 특정 Task를 수행할 수 있는 학습 방법론이라고 생각하면 됩니다. 아주 조금 더 자세히는 여러 Task의 일반화된 Parameter \theta (Meta-level Knowledge)를 구하고, 이를 새로운 Task 모델의 Parameter의 초기화로 설정한다면 해당 Task의 최적의 Parameter를 빨리 찾아갈 수 있다는 방법입니다. 물론 이는 Optimization-based 접근법에 속하며 이외에도 Model-based, Metric-based에 따른 Meta learning 방법도 존재합니다.
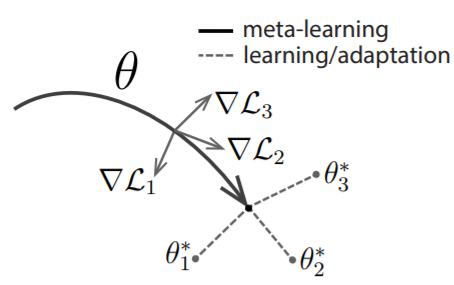
하지만 저자는 이때까지의 Few-shot에 대한 접근은 주로 분류에만 국한되어 있었다고 말합니다. Detection에서는 분류 뿐만 아니라 객체의 위치 (Localization)를 찾는 것에 대해서도 다뤄야하는데, Few-shot localization이라기 보단 Few-shot classification + Detector만의 localization에 한정적이므로, 성능 개선의 여지에 대해 주장합니다. 따라서 본 논문에서는 Few-shot classfication과 Few-shot localization을 통합적으로 다루는 Meta-learning 프레임워크를 제안합니다. 위의 Optimization-based 접근법과 같이, 해당 프레임워크는 Meta-level Knowledge (Parameter)를 Base class(Large dataset)에서 Few-shot에 대한 학습 시 어떻게 잘 다룰 것인가에 대해 다루고, 이는 네트워크의 category(class)-agnostic과 category-specific적인 요소를 명시적으로 분리하여 해결할 수 있습니다. category-agnostic과 category-specific이 주된 내용이니, 이것이 무엇인지 고민하며 읽어보도록 하겠습니다.
Meta-Learning based Object Detection
category-agnostic과 category-specific의 요소를 분리했다는 말이 어떤 것일까요? 직관적으로 CNN을 살펴보면, 초반부의 Layer들은 특정 클래스를 명시적으로 보이기 보다는 객체의 특징을 찾기 위한 파라미터를 찾는 것이 주 목적입니다. 이를 category-agnostic한 요소라고 부릅니다. 반대로, 후반부의 Layer들은 특정 클래스를 분류할 수 있는 Semantic한 요소들을 갖는 파라미터를 찾는 것이 주 목적입니다. 이를 category-specific한 요소라고 합니다. 후반부의 Layer 중 category-specific한 요소라고 하면, FC Layer가 굉장히 대표적이겠네요. 다른 말로는 Generic에서 Specific한 시각적 인지과정에서, 둘을 분리하여 Few-shot의 상황을 해결하고자 했다는 점입니다. 그렇다면 저자는 우선적으로 category-specific한 요소가 부족한 Few-shot에서 해당 부분의 파라미터를 어떻게 생성할 것인가에 대해 관심을 갖겠네요. 바로 해당 방법을 먼저 살펴보겠습니다.
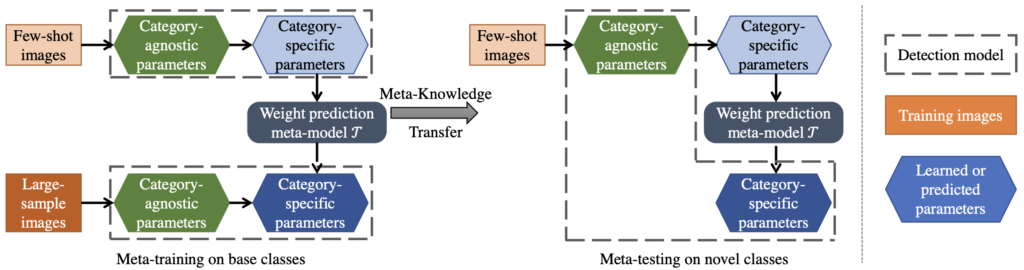
우선 저자는 Large data에 대해 학습하는 (해당 data에서는 당연히도 Few-shot의 클래스를 갖고 있지 않습니다) 상황에서, class-agnostic한 파라미터들이 class-specific한 파라미터로 변하는 과정이 공유하는 속성을 갖고 있음에 주목했습니다. 그런 공유하는 특성을 잘 활용한다면, Few-shot learning 시 문제될 수 있는 Overfitting에 대응할 수 있을 것을 기대했죠.
Faster R-CNN에서, 네트워크의 상단부(후반부)는 category-specific한 파라미터를 갖고 있을 것이고, 해당 파라미터들은 클래스마다 Bounding box classfication과 regression에 사용됩니다. 위에서 한번 언급했듯 category-agnostic한 요소들이 specific한 요소들로 변화하는 과정을 Few-shot에 들고오면, Base class (Large dataset)에서 학습한 파라미터들의 변화 패턴이 Novel class (Few-shot dataset)의 파라미터에 적용할 수 있을 것을 기대했고, 이를 파라미터의 가중치를 예측하는 Meta-model인 \mathcal{T} 를 설계하였습니다. 해당 Meta-model은 Support set으로 학습한 Parameter의 Weight을 Large-scale set으로 학습한 것과 유사한 Weight을 생성할 수 있도록 합니다.
자세히, 해당 Weight Prediction Meta-Model은 category c에 대해 Large-scale의 Base dataset S_{base}에서 학습한 네트워크의 마지막 Layer의 weight인 w^{c,\ast}_{det} 가 있습니다. w^c_{det} 은 S_{base} 에서 샘플링한 k-shot의 Episode dataset으로부터 학습한, 동일하게 네트워크의 마지막 Layer의 weight입니다. 아하, 또 Episode의 정의를 알아야겠네요. 사실 찾아는 봤어도 여전히 이해하기 어렵지만 Episode learning의 과정을 살펴보면, 태스크 T에서 데이터 L만큼 샘플링합니다. T는 적은 양의 Uique한 (N-way) 클래스와 이미지 (K-shot)을 가지는 데이터이며, L은 T가 가진 클래스 중 랜덤으로 정해진 새로운 (N’-way, K’-shot)만큼 뽑습니다. 이제 샘플링 된 L로부터 Support set과 Batch set을 다시 샘플링하고, Matching strategy에 따라 Batch의 이미지를 예측하고 학습합니다. 해당 과정을 반복하며 Meta-knowledge로부터 Support set을 학습했을 때의 Batch set에 대한 모델의 예측도를 향상시키는 것을 목적으로 합니다.
다시 돌아와 Weight Prediction Meta-Model은, w^c_{det} 를 Regression하여 w^{c,\ast}_{det} 와 유사한 형태로 만드는 것 (Parameter space 내, Base class로 학습한 Weight은 일반성을 갖고 있다고 볼 수 있으므로)을 목표로 하므로, 해당 모델을 통해 Few-shot learning의 예측 향상도를 올릴 수 있습니다. 사실 이 부분이 핵심인 것으로 보이며 이를 이해하고자 충분히 많은 글을 보았지만, 여전히 추상적인 느낌이 드네요. 직관적으로 와닿을 수 있을 때까지, 다시 반복해서 보아야할 것 같습니다. 이제는 해당 Model의 Loss function을 살펴보겠습니다.
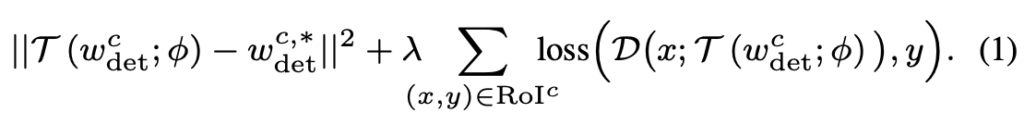
Loss를 보자마자 사실 아이패드를 덮고 논문을 바꿀까도 생각했습니다. +를 기준으로 앞절은 위의 Weight Prediction Meta-Model의 방식 (Support set으로 학습한 Parameter weigth가 Large-sample set으로 학습한 Parameter의 weight을 따라가도록)을 그대로 수식으로 표현하며 L2Norm을 붙여 설계하였지만, +를 기준으로 뒷절의 Loss는 해석하기에 힘들었습니다. 만, 저자가 하나하나 Notation을 너무 친절히 적어주어 얼추 이해할 순 있었네요. Weight Prediction Meta-Model은 결국 Detection network인 \mathcal{D} 에 붙는 상황이니, 뒷절의 Loss는 결국 일반적인 Classification과 Localization을 더한 Detection Network (Faster R-CNN의)의 Loss로 해석하면 됩니다. Faster R-CNN을 차용해왔으니 역시 2-Stage로 RPN과 RoI (뒤에서 다시 category-agnostic에 대한 설명에서 보겠습니다)를 갖고 있으며 RoI^{c} 는 RoI에서 대응하는 클래스 라벨 c를 의미합니다. Detection Network 앞의 Lambda는 규제화 텀으로, 음.. Loss에 대한 수식이 굉장히 어렵게 적혀져 있지만 결국 “Weight Prediction Meta-Model Loss + Detection Network (Classification + Localization) Loss”로 해석하면 끝입니다.
그럼 다시 돌아와 category-agnostic은 어떻게 명시적으로 이용했는지 살펴보죠. 앞에서 agnostic한 요소는 CNN의 Bottom-Layer, 즉 전반부의 Layer에 해당한다 하였는데, Faster-RCNN에서는 RPN도 이에 해당할 수 있습니다. 물론 RPN은 네트워크를 어느정도 통과한 이후이지만, Faster-RCNN에서는 RPN에서 객체의 존재 여부만을 판단 (이진법)하고, 객체가 어떤 클래스에 속하는지까지는 판단하고 있지 않으므로, category-agnostic하다고 말할 수 있죠. classification 뿐만 아니라, localization도 마찬가지입니다. RPN의 box-regression을 위한 Layer는, Sliding window기법으로 사전에 정의한 Anchor box가 ground-truth box와 유사하도록 하지만, 이 과정에서는 class label에 따라 regression을 진행하진 않죠. 앞서 말했듯이 저자는 해당 Layer들의 Parameter weight들이, 이후의 RoI를 거치면서 어떻게 변화하는지의 패턴 (dynamic pattern이라고 말합니다)에 집중한다고 하였으니 (그 집중하는 역할은 위의 Weight Prediction Meta-Model이 하겠죠), category-agnostic, category-specific한 요소를 분리하여 학습했다고 충분히 납득할 수 있습니다.
이제 저자의 핵심은 끝났습니다. 마지막으로 학습 과정을 살펴보며 실험으로 넘어가겠습니다. 먼저, class-agnostic한 요소를 학습하고자 그리고, Large-scale dataset에서의 Parameter weight을 얻고자 Base set에 대해 학습합니다. 뭐, 일반적으로 데이터에 대해 학습한다는 의미입니다. 그 다음으로는, Few-shot의 Episode learning 방법에 따라 하나의 클래스 당 K개의 bounding box를 샘플링하여 Support set으로 사용하고, class-agnostic한 요소는 Freeze한 다음 (class-specific한 요소를 학습하고자) class-specific한 요소 (RoI, FC Layer 등)는 스크래치 레벨부터 다시 학습합니다. 위의 어려웠던 말들을 이렇게만 보니, 결국 저자는 “class-agnostic과 class-specific을 분리하여 학습하고자 함”이 끝인 것 같습니다. Meta-test 시에는, category-agnostic 요소는 Meta-training과 같은 Parameter weight을 사용하고, category-specific한 요소는 랜덤으로 초기화하여 Fine-tuning 함과 동시에 Weight Prediction Meta-Model을 사용하여 class-specific한 요소의 Weight 생성을 학습시킵니다. 아, 이 부분은 참 코드를 보지 않고는 어려운 것 같습니다. 최종적으로 Query set에 대해 예측 시에는, 위의 Weight-Prediction 모델을 제거한 이후 예측합니다. (해당 모델은 단순히 specific한 요소들이 Overfitting되지 않고 적절히 일반적인 모습의 Weight를 갖도록 학습하기 때문입니다)
Experiments
Pascal VOC 2007/2012를 결합하여 클래스만 구분하여 학습 및 평가에 사용하였습니다. 다른 방법론과의 비교를 위하여, Few-shot의 관점이 아닌 일반적인 Detection 모델 (Faster R-CNN, YOLOv2, SSD)를 비교하였으며, (1) 스크래치부터 학습하는 과정 (Few-shot에 대해 학습한 이후, 바로 Query에 대해 예측), (2) Large-scale의 base set과 Few-shot set을 결합하여 학습, (3) 15개 클래스의 모델로 학습한 이후, 5개의 Novel 클래스로 Fine-tuning한 방법을 사용하여 성능 비교를 진행하였습니다.
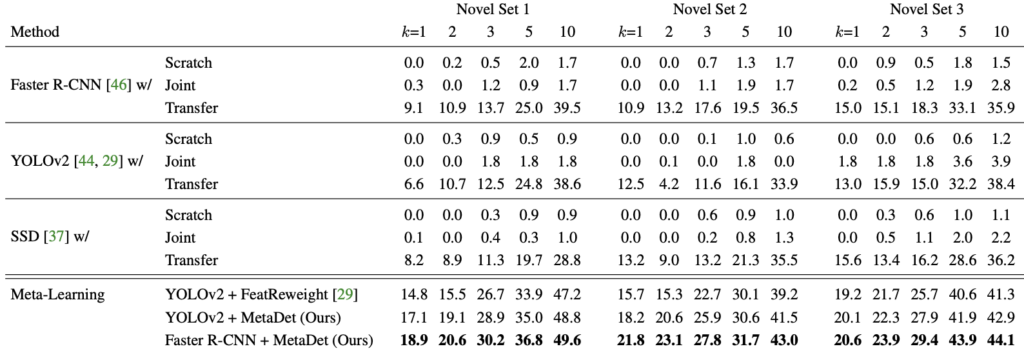
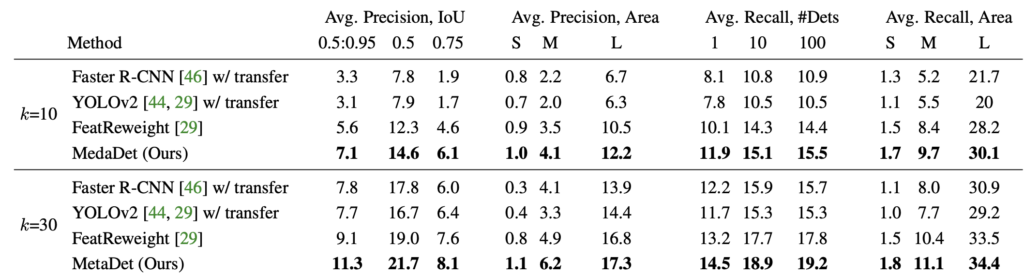
잘보면, 위의 (1)이 Scratch, (2)는 Joint, (3)은 Transfer이며 Transfer-learning도 Few-shot learning을 위한 하나의 방법론으로 대두되다보니 그런지, 얼추 동작하는 모습을 보입니다. 반면 Scratch는, 0.0mAP수준의 처참한, 특히 One-shot에 비해 10-Shot까지 갔음에도 고작 1%에 머물러 있는 모습이 인상적입니다. FeatReweight는 바로 직전 리뷰 논문 다음에 나온 weight를 Reinit하는 방법인데… 아직 안읽어보아 잘 모르겠습니다. 또한 의문점은, SSD에서는 MetaDet의 방법이 안되나? 잘 보면 한 VGG16까지는 class-agnostic하고, 이후의 Auxilary convolution은 class-specific하다고 보고 진행해도 될 것 같은데, 이에 대해 잘 찾아봤는데도 저자의 말이 없었습니다.
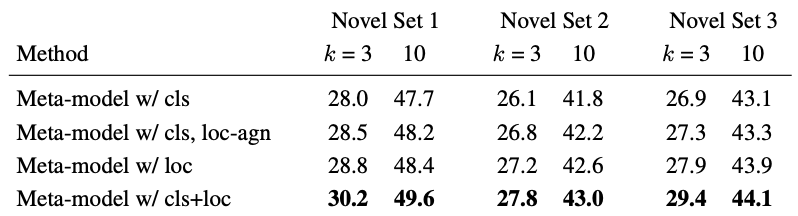
다음의 Ablation study는 category-specific한 요소에 대해 classification, localization 측면을 붙이고 떼었을 때의 성능 비교로, cls는 classification, Faster-RCNN에서는 RoI classification weight을 Weight Prediction Meta-Model을 활용하여 학습시켰을 때를, 동일하게 loc은 bounding box regression weight를 의미하며, loc-agn은 category-agnostic한 bounding box weight을 학습시켰을 때 (음.. Weight Prediction Meta-Model을 어디에나 떼었다 붙였다할 수 있긴 합니다)의 성능 비교로, 저자는 본 실험을 통해 진정히 “우리는 Few-shot object detection이라 해놓고선 classfication만 다루었지만, localization 측면도 고려했다”는 점을 언급하고 싶어 보입니다.
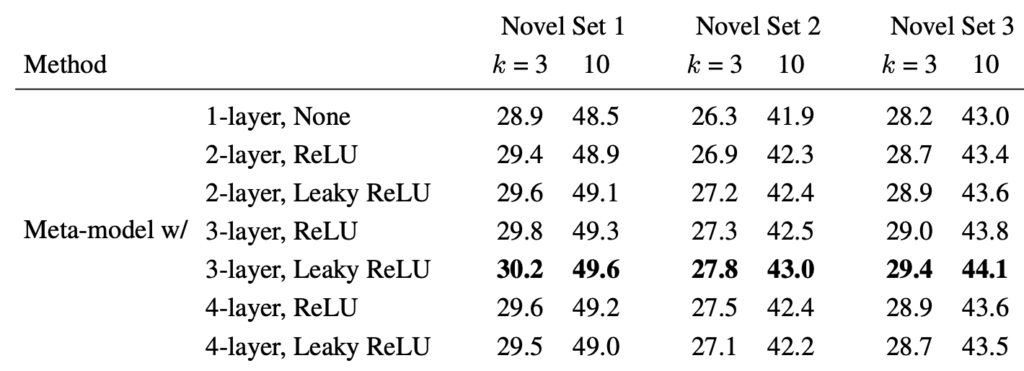
다음으로는, Weight-Prediction Meta-Model의 구조에 따른 성능 비교입니다. 뭐, 간단한 구조로 이루어져있구나하고 보고 넘어가겠습니다. 뒤의 실험에 대해 미리 언급하자면, K-shot에서 K의 수에 따른 성능 및 Transfer-learning과 이전 논문이라고 언급한 FeatWeight와의 성능 비교 (본인 방법론이 SoTA임을 말하고 싶어하는)입니다.

아.. 논문 리뷰는 이로 끝났습니다. 참, 어려웠습니다. Meta-learning도 처음, Episode-learning도 처음인지라 논문 리뷰도 2주만에 쓸수야 있었네요. 새로운 태스크의 논문을 읽는 것은 어렵지만 적응될때까지 해당 분야의 다양한 논문의 우물을 파봐야하지 않겠습니까.. 이상으로 리뷰 마치겠습니다.