Before Review
이번 리뷰는 Object Detection(Faster R CNN , FPN)과 ResNet에 대해서 다루게 되었습니다.
지금 해야 되는 실험이 Faster R CNN + ResNet50 + FPN 구조를 바탕으로 Detection을 돌려봐야 하는 상황입니다. 코드 뜯어보기 전에 제가 해당 연구들을 들어본 적은 있지만 논문을 읽어본 적은 없어서 이번 기회에 한번 간단하게 정리 해보았습니다. 아래의 모든 리뷰는 방법론에 집중하며 실험 결과에 대해서는 부분적으로 리뷰 하였습니다.
인상 깊은 것은 세 연구 모두 Kaiming He 선생님의 작품이라는 것이죠…
리뷰 시작하겠습니다.
[2015 NIPS] Faster R-CNN Towards Real Time Object Detection with Region Proposal Networks
기본적으로 R-CNN, Fast R-CNN, Faster R-CNN은 모두 two-stage 계열의 detector들 입니다. 즉, Region Proposal 과정이 필요하다는 것이죠. Region Proposal을 위해 가장 많이 활용되었던 당시 알고리즘은 Selective Search라는 방법론 입니다.

Selective Search라는 알고리즘에 대해서는 자세히 다루지 않겠습니다. 다만, 문제점은 해당 알고리즘이 Region Proposal을 위해 너무 오래 걸린다는 것이죠. 논문에서는 하나의 이미지 당 2초의 처리 시간이 필요하다고 합니다. 이러한 이유는 해당 알고리즘이 CPU에서만 작동할 수 있도록 설계 되었다고 합니다.

간단하게 정리하면, R-CNN은 Selective Search를 먼저 돌리고 CNN network를 각각 태우는 방식으로 진행이 되었고 SVM과 Regressor 부분에 대한 학습이 CNN으로 전달 되지 않아 End-to-End 방식으로 학습할 수 없습니다.
Fast R-CNN은 CNN network를 태우고 Selective Search 하는 방식의 차이가 있다고 보시면 됩니다. Selective Search는 Rwa 이미지 단에서 진행하고 이를 feature map에 적용할 수 있도록 다시 rescaling 해주는 것이죠.
Faster R CNN에서는 기존 연구들이 사용하는 Region Proposal 방식이 bottleneck이라고 판단하여 Real-Time으로 동작할 수 있는 방향을 고민하게 됩니다. 가장 쉬운 것은 CPU에 비해 연산이 굉장히 빠른 GPU로 올리면 되겠죠? 따라서 Faster R CNN은 Region Proposal을 더 이상 알고리즘 방식이 아니라 GPU기반의 학습 가능한 신경망으로 대체 합니다.
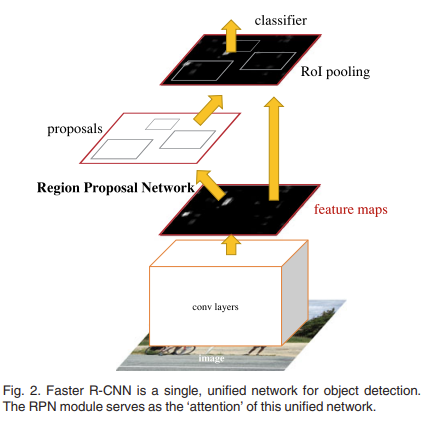
위의 그림이 전반적인 Faster R CNN의 구조를 나타내고 있습니다. Faster R CNN은 결국 Conv Layer + Region Proposal Network + Fast R CNN의 detector라 볼 수 있습니다.
Conv Layer라는 것은 ImageNet으로 사전학습된 백본 네트워크를 의미하고 논문에서는 VGG16으로 가정하고 설명하고 있습니다.
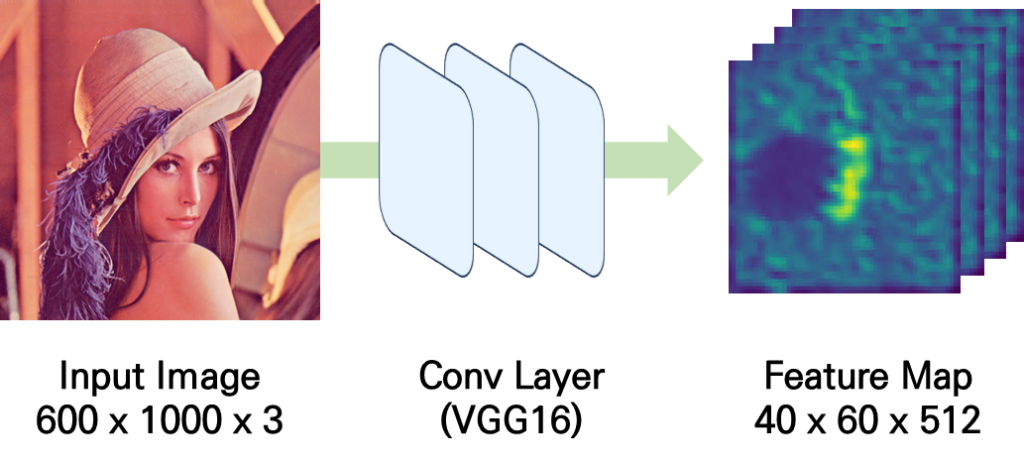
우선 입력 이미지가 들어오면 우리가 흔히 아는 방식으로 Conv Layer를 이용하여 forward를 진행하면 입력 이미지에 대한 feature map을 얻을 수 있습니다. (40과 60은 입력 이미지의 height, width에 대한 차원이고, 512는 채널에 대한 차원입니다.)
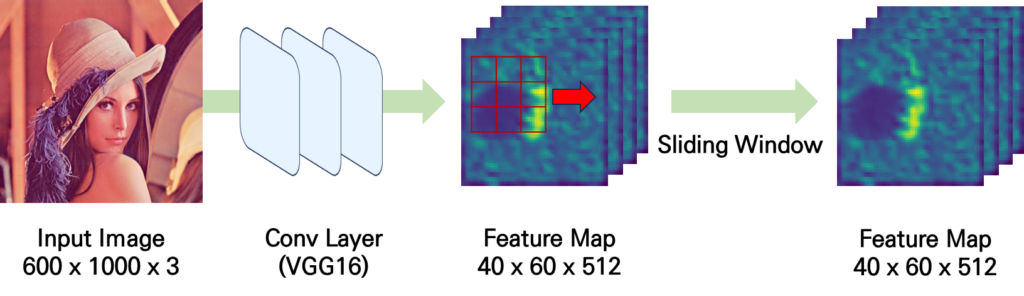
이렇게 얻어진 feature map에 대해서 3 \times 3 에 해당하는 sliding window를 적용시켜 같은 크기의 feature map을 생성합니다. Zero Padding을 1만큼 주면 feature map의 사이즈를 그대로 유지할 수 있습니다.
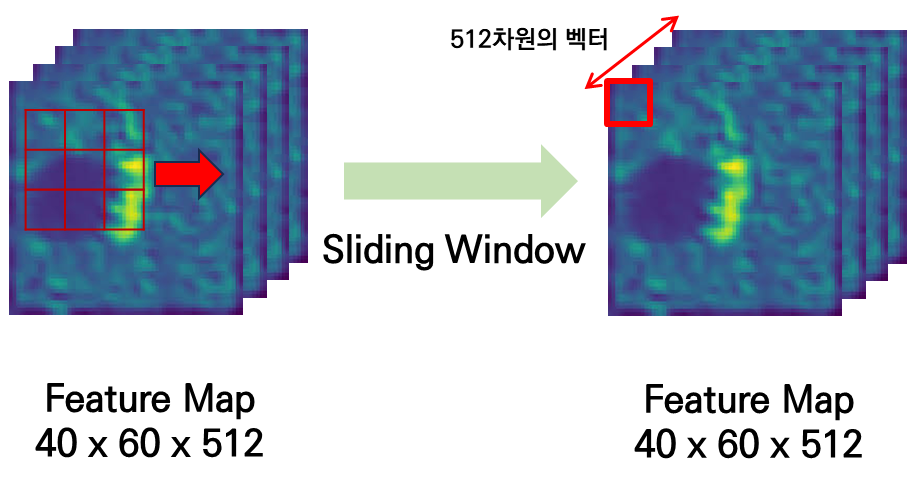
이러한 sliding window를 하는 이유는 feautre map의 spatial 차원(H' \times W')에 대해서 3 \times 3 의 영역 만큼 국소적 특징을 축약 시키는 것이죠. 즉, sliding window를 거치고 나온 feature map에서 (x,y) 위치는 해당 위치의 지역적 특성을 나타내는 512 차원의 벡터라고 보시면 됩니다.
위의 단계가 Region Proposal Network의 기본적인 구조이며 그 후 Anchor를 생성하는 부분과 prediciton network를 학습하는 부분으로 나뉘어집니다.
Anchor를 생성하는 부분은 어렵게 생각하지 말고 그냥 prediction network를 학습 시키기 위한 정답 라벨을 만드는 과정이라 보시면 됩니다.
위에서 3 \times 3 크기의 sliding window를 적용하는 동시에 각 window의 중앙에 anchor의 중앙을 동시에 위치 시킵니다. 임의로 feature map에서의 anchor의 center 위치를 잡아주고 이를 rescale하여 실제 input raw image의 좌표로 투영 시키는 것이죠.
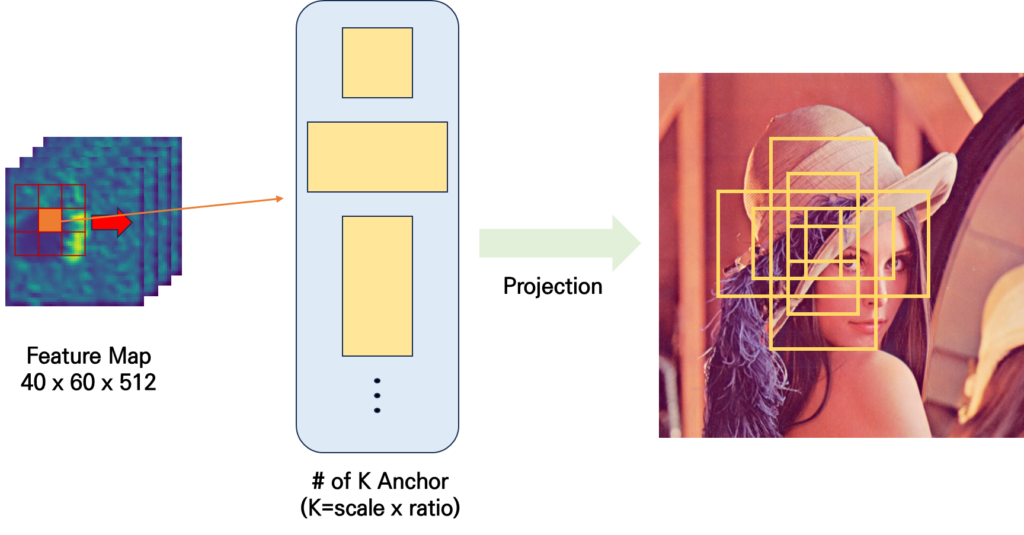
무슨 말이냐면 줄어든 spatial size 만큼 ( H \times W \rightarrow H' \times W') 다시 linear 하게 rescale 해주면 H' \times W' \rightarrow H \times W실제 input 이미지에서 anchor의 위치를 임의로 정의해줄 수 있는 것이죠.
scale(논문에서는 3가지) 이란 1,2,3.. 등등 anchor 박스의 전체적인 스케일을 의미하며 ration(논문에서는 3가지)란 1:1, 1:2, 2:1 등의 종횡비를 나타내는 비율 입니다.
Window 과정에서 우리는 몇 개의 anchor box를 생성하게 될까요? 40 \times 60 \times 3 \times 3 = 21,600개의 anchor 박스를 생성하게 됩니다.
자 그리고 이 모든 anchor 박스를 학습에 사용할 수는 없습니다. 대다수의 anchor 박스는 background에 해당되기 때문이죠. 여기서 Ground Truth와의 IoU(Intersection of Union)을 비교하여 box 마다 positive, negative, invalid로 라벨을 부여합니다. 여기서 invalid에 해당하는 box는 아예 학습에 사용하지 않는다고 합니다.
- Positive : 각 Ground Truth와 가장 높은 IoU 혹은 Ground Truth와 IoU가 0.7 이상
- Negative : Ground Truth와 IoU 0.3 이하
- Invalid : Ground Truth와 IoU 0.3 ~ 0.7 사이거나, 이미지 경계를 벗어난 경우 (가장 자리에서 anchor box가 정의되는 경우 scale과 ration의 상황에 따라 원본 이미지의 경계를 벗어나는 경우가 생김)

즉, Ground Truth와의 IoU를 비교하여 Object가 있는지 없는 지를 나타내는 Objectness에 해당하는 1D vector를 생성합니다.
또한 위에서 정의된 Positive Anchor Box에 한해, 해당하는 Ground Truth의 bonding box offset을 라벨링 해줍니다.
이렇게 anchor box를 window 과정에서 정의하고 이를 실제 이미지 상의 좌표로 projection 후 GT와의 IoU를 계산할 수 있으며 positive anchor box의 경우에는 GT의 bounding box의 좌표까지 라벨을 할당 해주게 됩니다.
이 다음으로는 anchor box 마다 512차원의 벡터가 있으니 이를 활용해서 objectness score와 box coordinates를 예측해줄 수 있는 layer를 각각 추가해줍니다.
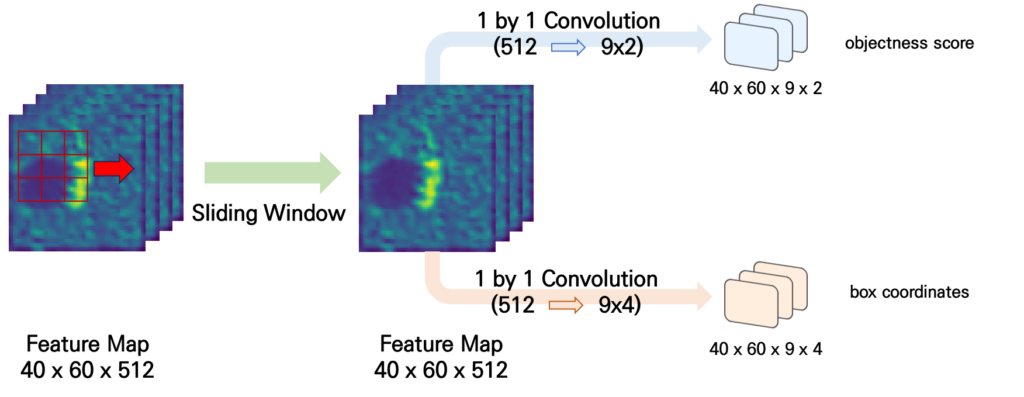
위의 그림과 같이 Windowing이 끝나고 나면 3 \times 3 만큼의 지역적 특성이 모여진 512차원의 벡터가 40 \times 60개 만큼 존재하니 각각 prjection을 시켜주는 것이죠.
우리가 anchor를 정의할 때 objectness score와 box 좌표에 대한 label을 이미 정의했기 때문에 이제 남은 것은 적절한 loss를 선택하여 Region Proposal의 학습 구조를 마무리하는 것 입니다.
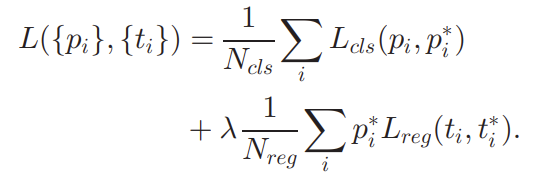
결국 anchor 마다 positive인지 negative인지 맞추는 head는 BCE Loss로 최적화 시키고 anchor의 box offset을 예측하는 head는 Smooth L1 Loss를 토대로 최적화를 시켜준다고 합니다. 어려운 부분은 아니니 Loss는 이 정도로만 설명을 마치도록 하겠습니다.
여기서 학습 디테일을 조금 더 부연 설명 하면 하나의 이미지에서 256개의 anchor box를 sampling 하여 배치 단위의 학습을 하는데 이 떄 positive와 negative의 비율이 최대한 1:1이 되도록 하여 Negative에 bias되는 학습을 방지한다고 합니다.
이렇게 Region Proposal Network가 잘 학습이 되면 확률적으로 GT와 IoU가 높은 Region Proposal을 만들어내고 이를 바탕으로 Fast R CNN이 학습이 되는 것이죠.
Faster R CNN의 정리는 이 정도로 마무리 하도록 하겠습니다.
[2016 CVPR] Deep Residual Learning for Image Recognition
다음은 ResNet 입니다. 사실 Residual Learning에 대한 깊은 의미는 이전에 알고 있었고 이번 논문 리뷰를 할 때는 network 구조에 대해서 좀 더 자세히 보긴 했습니다.
개인적으로 딥러닝에서 가장 중요한 논문 몇 가지를 뽑아보라고 얘기하면
저는 ResNet, Adam, GAN, Transformer… 이 정도로 뽑을 것 같습니다. (좋은 연구들은 정말 많지만 진짜 굵직한 것들만 적었습니다.)
그래도 그중 단연 으뜸은 ResNet으로 생각할 만큼 정말 파급력 있는 연구라고 생각합니다. 실제로 citation이 17만을 넘을 정도로 중요한 연구이긴 합니다.
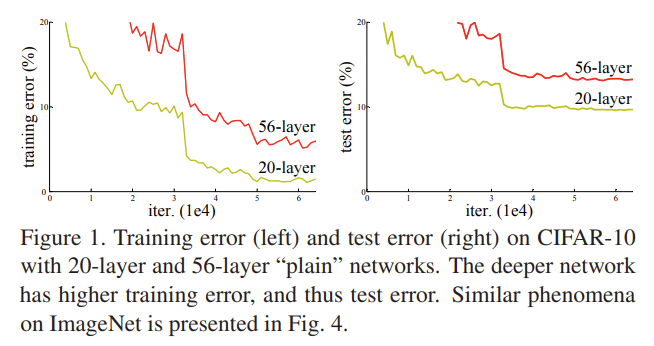
ResNet의 Motivation은 위의 실험 결과로 간단하게 설명할 수 있습니다. 풍부한 visual representation을 얻기 위해서는 인공 신경망을 깊게 쌓는 것이 중요한데 신경망을 깊게 쌓으면 최적화가 어렵다는 것이 핵심이죠.
위의 실험 그래프는 깊은 신경망을 학습할 때 성능이 떨어지는 것은 overfitting의 문제가 아니라 training error 조차 높게 나오는 degradation 문제라는 것 입니다.
결국 “모델을 수렴 시키는 것이 쉽지가 않다.”라는 얘기 입니다.
Kaiming He 선생님은 이를 해결 하기 위해 Residual Learning을 제안합니다.
여담으로 Related Work에 잠깐 소개 되고 있지만 VLAD나 Fisher Vector는 코드북을 만들고 centorid와의 잔차(residual)를 모델링하여 좋은 visual representation을 보여주는 방법론 입니다. 여기서 영감을 얻으셨는지는 모르겠네요.
무튼 ResNet에서 제안하는 Residual Learning에 대해서는 아래의 그림으로 완벽하게 정리가 가능합니다.
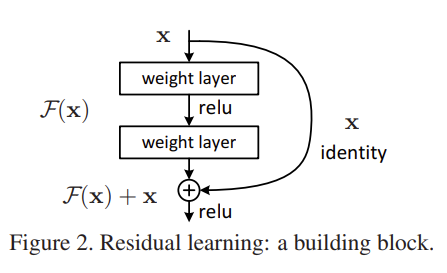
네트워크를 구성하는 임의의 중간 레이어 상황을 한번 가정해보도록 하겠습니다.
이때, 레이어로 들어오는 입력을 x라고 하고 우리가 원하는, 이상적인 mapping 함수를 H(x)라고 가정하겠습니다.
- x \rightarrow H(x) : x를 원하는 H(x)로 바로 사상 시키는 구조
그런데 Kaiming He 선생님은 이러한 mapping 구조가 모델 입장에서는 조금 어려울 수 있다고 생각하는 것죠. 무슨 말이냐면
3이라는 입력을 받아서 3.1을 만들고 싶다 가정해보겠습니다.
3 을 바로 3.1로 만드는 것이 쉬울까요 아니면 3.1을 3 + 0.1 이렇게 만드는 것이 쉬울까요?
Residual Learning의 아이디어는 “3.1을 3 + 0.1 이렇게 만드는 게 더 쉽지 않을까?” 라고 가정하는 것이죠.
무슨 얘기냐면 3을 3.1로 만드는 방법은 무한히 많습니다. 3을 100으로 만들었다가 다시 3.1로 만들 수가 있을 것이고 정말 복잡하게 돌아가는 방식으로 3.1을 만들 수도 있습니다.
하지만 3 + x = 3.1는 단 하나의 solution만 존재 합니다. x = 0.1 밖에 없죠. 즉, 우리는 모델에게 난이도가 비교적 쉬운 task를 부여해서 좀 더 쉬운 최적화 난이도를 제공하는 것 입니다.
x \rightarrow H(x)가 아니라 x + F(x) = H(x)라는 것이죠. 기존의 입력 대비 달라지는(차이가 발생하는) 부분만 학습 해보라는 것 입니다.
이는 깊은 신경망 내에서 데이터들이 레이어를 통과하면서 그 값이 급격하게 변화할 수 있는 함수를 모델링 하는 것이 아니라 데이터들이 천천히 변화할 수 있도록 학습을 강제하는 것이라 볼 수 있죠.
최적화 난이도가 낮아지며 이는 실제로 깊은 인공 신경망의 안정적인 학습을 이끌어내는데 큰 역할을 합니다. 제안하는 Residual Learning에 대한 수학적 분석이 담긴 논문은 [ECCV 2016] Identity Mappings in Deep Residual Networks 가 있으니 참고하실 분들은 참고해도 좋을 것 같습니다.
아이디어 자체는 굉장히 직관적이라 볼 수 있습니다. 구현은 두 가지 방식으로 하게 되는데
- \textup{Identity Shortcut} : \mathbf{y}=\mathcal{F}(x,{W_{i}})+\mathbf{x}
위의 수식은 Identity shortcut으로 논문에서 정의 하고 있네요. \mathcal{F}(x,{W_{i}})은 Fully Connected Layer나 Convolution Layer를 거쳐서 나온 ouput 입니다. Identity shotcut은 \mathcal{F}(x,{W_{i}})와 \mathbf{x} 끼리의 차원이 동일한 상황에서 가능하겠네요.
Identity shortcut은 이 과정에서 추가적인 parameter를 사용하지 않는다는 점에서 network의 복잡도를 높이지 않습니다.
- \textup{Projection Shortcut} : \mathbf{y}=\mathcal{F}(x,{W_{i}})+W_{s}\mathbf{x}
위의 수식은 Projection shortcut으로 논문에서 정의 하고 있네요. \mathcal{F}(x,{W_{i}})의 차원이 \mathbf{x} 차원과 달라질 때 사용해줍니다. Fully Connected Layer 혹은 1 by 1 Convolution 둘 다 가능합니다.
이렇게 ResNet은 기존 Network에서 크게 변경하는 부분 없이 Residual Learning이란 개념을 도입하여 이미지 넷 분류에서 사람의 오차율인 5% 미만인 3.57%를 달성하면서 세상을 놀라게 합니다.
Experiments
간단하게 몇 가지 실험만 살펴 보도록 하겠습니다.
ImageNet Classification
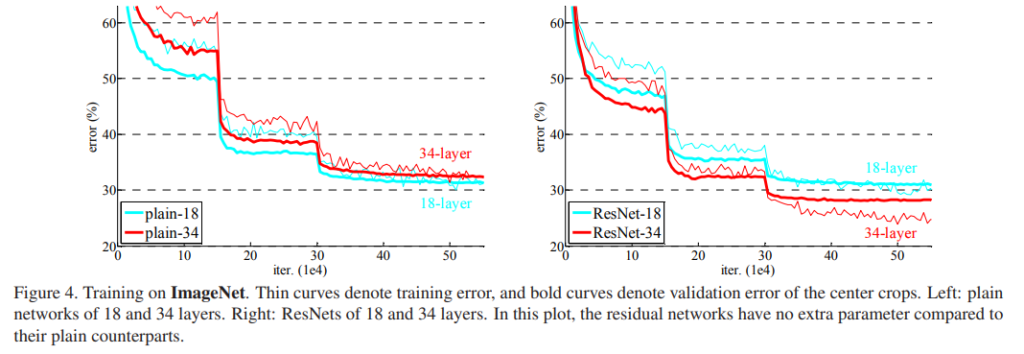
위의 그래프는 이미지 넷에서 training data에 대한 오차율을 나타내는 그래프 입니다.
왼쪽 그래프는 Plain network로 Residual Learning을 적용하지 않은 상황에서 학습 결과 입니다. 18-layer 보다 34-layer의 오차율이 더 높게 나오고 있습니다.
이는 degradation 상황을 나타내는 실험 결과라 볼 수 있습니다. 깊은 신경망이 training data 상황에서 조차 오차율이 더 높게 나오고 있는 상황이죠. 저자는 이러한 문제가 gradient vanishing에 있는 것 같지는 않다고 설명 합니다. Batch Norm을 사용하기 때문에 forward나 backward 과정에서의 gradient signal이 사라지지 않는다고 하네요. 이는 gradient vanishing 문제가 아닌 최적화 자체의 어려움으로 plain network에서는 느린 수렴 속도가 원인이라 서술 합니다.
오른쪽 그래프는 Residual Network로 Layer 중간 중간 제안하는 skip connection이 적용된 상황(추가적인 parameter를 사용하지는 않은)에서 학습 결과 입니다. 이제는 상황이 반대가 되었습니다.
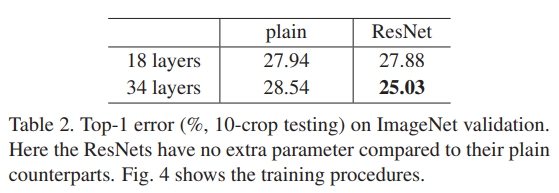
우선 Validation Set에서 34-layer가 18-layer 보다 성능이 더 좋습니다. 이는 좋은 일반화를 보여준다고 볼 수 있겠네요.
또한 Training Set에서도 34-layer가 18-layer 보다 성능이 더 좋습니다. Degradation 문제가 어느 정도 해소 되었다고 볼 수 있겠네요.
그리고 테이블을 보면 18-layer 기준 성능이 비슷하게 나오고 있는 것을 볼 수 있습니다. 아마도 그렇게 깊지 않은 network 상황에서는 SGD solver가 나름 적당히 수렴을 하고 있는 것을 확인할 수 있네요. 그래프를 보면 18-layer 기준 resnet이 plain network 보다 더 빠른 수렴 속도를 보여주고 있습니다. 성능은 비슷하게 나와도 수렴 속도 측면에서 residual learning이 긍정적인 효과를 가져다준다고 합니다.
Analysis
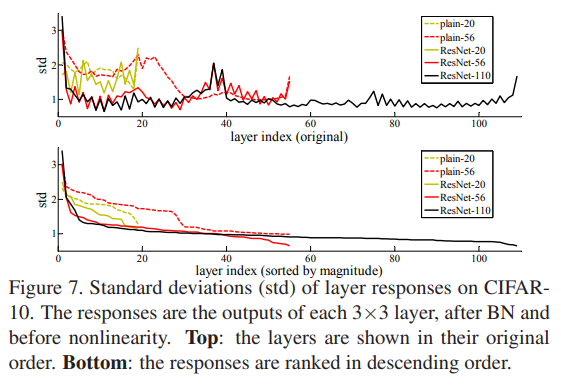
CIFAR-10 상황에서 layer response에 대한 실험 입니다.
Residual Learning의 motivation은 모델이 입력과 출력 사이의 관계를 찾아낼 때 천천히 값을 변화 시키면서 그 구조를 파악하는 것이었습니다.
값이 천천히 변화한다는 것은 layer를 통과할 때의 편차가 크지 않다라는 것이겠죠.
위의 분석 실험은 정확히 그 motivation과 일맥상통 합니다.
Plain network의 경우 x \rightarrow H(x)로 학습을 시키다 보니 값이 어디로 튈지 모르는 상황이라 편차가 크게 발생하고 있지만 Residual network의 경우에는 x \rightarrow H(x)가 아니라 x + F(x) = H(x) 즉, 기존의 입력 대비 달라지는(차이가 발생하는) 부분만 학습 하기 때문에 편차가 크게 발생하지 않습니다.
ResNet은 아직까지 이미지의 레벨의 feature를 기술하는데 있어 베이스라인으로 많이 사용될 만큼 중요한 백본 입니다. 저도 이번 기회에 다시 한번 공부 하게 되었고 논문을 직접 읽으니 저자의 깊은 고찰을 엿볼 수 있어 너무 좋았네요.
ResNet 정리는 이마 마치도록 하겠습니다.
FPN이 남았는데 리뷰가 길어질 것 같기도 하고 코드 리뷰도 다루고 싶어서 Part.2에서 FPN과 코드 리뷰에 대한 내용을 같이 다루도록 하겠습니다.
감사합니다.
임근택 연구원님 좋은 리뷰 감사합니다.
URP과정 동안 깊은 신경망 모델을 훈련할때, epoch가 늘어면서 오히려 모델의 성능이 떨어지는 문제가 있었는데 이것이 degradation때문이라는 것과 이를 residual learning을 통해 해결한 것이 ResNet이라는 사실이 굉장히 흥미로웠습니다. 예시도 들어주며 리뷰해주셔서 쉽게 이해할 수 있었습니다.
리뷰를 읽으며 두가지 궁금한점이 생겼는데 첫번째는 깊은 신경망이 파라미터 수가 많아져 연산량이 많을 것으로 예상되는데 residual learning이 gradient vanishing문제 외에 모델의 학습이 오래걸리는 문제는 어떻게 해결했는지 궁금하고
두번째로 궁금한 점은 F(x,Wi)의 차원이 x와 달라질때
1 by 1 convolution이 가능하다고 해주셨는데 3 by 3이 아닌 1 by 1을 적용하는 이유가 있는지, 만약 있다면 그 이유가 궁금합니다.
residual learning이 gradient vanishing문제 외에 모델의 학습이 오래걸리는 문제는 어떻게 해결했는지 궁금하고
=> 결국에는 reisdual learning이 최적화 난이도를 낮추기 때문에 수렴 속도가 빨라진다고 설명할 수 있습니다. 문제가 쉬워지는 것이죠.
1 by 1 convolution이 가능하다고 해주셨는데 3 by 3이 아닌 1 by 1을 적용하는 이유가 있는지, 만약 있다면 그 이유가 궁금합니다.
=> 1 by 1 convolution은 결국 FC Layer와 같습니다. 왜 그런지는 한번 깊게 고민해보시죠..ㅎ