제가 이번에 리뷰할 논문은 Uni6D라는 논문입니다. 6D Pose Estimation 논문으로, RGBD를 입력으로 사용할 때, RGB와 D를 동일한 Feature Extractor를 이용한다는 점이 흥미로워 가져왔습니다.
Abstract
RGB-D 이미지의 사용이 확산됨에 따라 정확한 6D pose를 추정하기 위해 RGB-D를 이용하는 것이 더 좋은 선택지가 되었습니다. SOTA 방법론들은 일반적으로 RGB와 depth 이미지의 feature를 추출하기 위해 RGB는 2D CNN, depth는 픽셀별 point cloud 네트워크를 이용하는 등, 서로 다른 백본을 이용하고 이후 fusion 네트워크를 이용하여 feature를 융합하고 있습니다. 그러나 저자들은 서로 다른 두 백본을 이용하는 것이 “projection breakedown”(pooling, crop 등의 spation transform으로 인해 projection 식이 깨지는 경우)의 원인이라는 것을 찾아내었고, 이를 해결하기 위해 RGB-D 이미지와 UV 데이터를 한번에 입력으로 사용하는 Uni6D라는 단순하고 효율적인 네트워크를 제안하였습니다. Uni6D는 통합된 CNN 프레임워크를 이용하며 하나의 백본으로 구성되어있으며, 6D Pose를 바로 예측하는 RT head와 visible point를 3D 좌표에 매핑하도록 네트워크에 정보를 주는 abc head로 구성된 Mask R-CNN을 기반으로 합니다.
Introduction
6D pose Estimation은 물체의 pose 정보를 추정하는 task로, 로봇의 grasping이나 AR 분야 등에 활용이 가능한 중요한 작업입니다. RGB-D 센서는 표면의 texture 정보와 3D 세계의 기하학적 정보를 직접적으로 제공할 수 있으며, 가격이 저렴해짐에 따라 6D 분야에서 RGB-D정보를 많이 활용하고 있습니다.
그러나, SOTA 방법론들은 일반적으로 2개의 개별적인 백본으로 구성되며 서로 다른 네트워크를 이용하여 추출한 두 feature는 추가적인 fusion 과정을 거치게 됩니다. 이러한 기존 방법론들은 서로 다른 두 데이터를 다루기 위해 다른 백본을 쓰지만, 단을 백본을 이용하지 못하는 가장 중요한 이유는 3D 비전의 투영 방식 때문입니다.
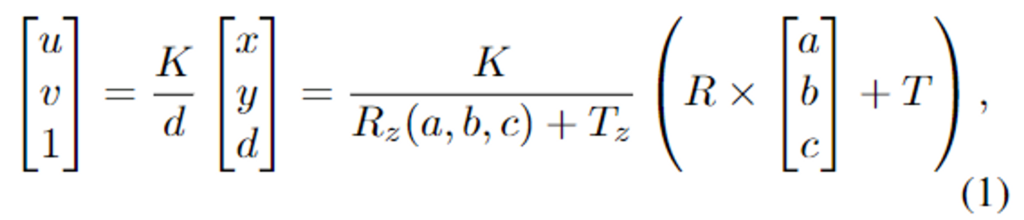
위의 식(1)은 3D vision projection 공식으로, point (a,b,c)는 먼저rotation matrix R∈ SO(3)와 translation T를 통해 카메라 좌표계의 (x, y, d)로 이동됩니다. 그 다음, 카메라의 intrinsic matrix K를 이용하여 이미지 평면의 (u,v) 픽셀로 투영됩니다. 카메라 관점에서 3D 모델의 3차원 구조는 depth 값인 (d)와 해당 포인트의 픽셀 좌표 (u,v)로 보존됩니다. 일반적인 UV는 3D 구조를 보존하는 데 사용할 수 있으며, 이를 변경할 경우 3D projection이 깨지게 됩니다.
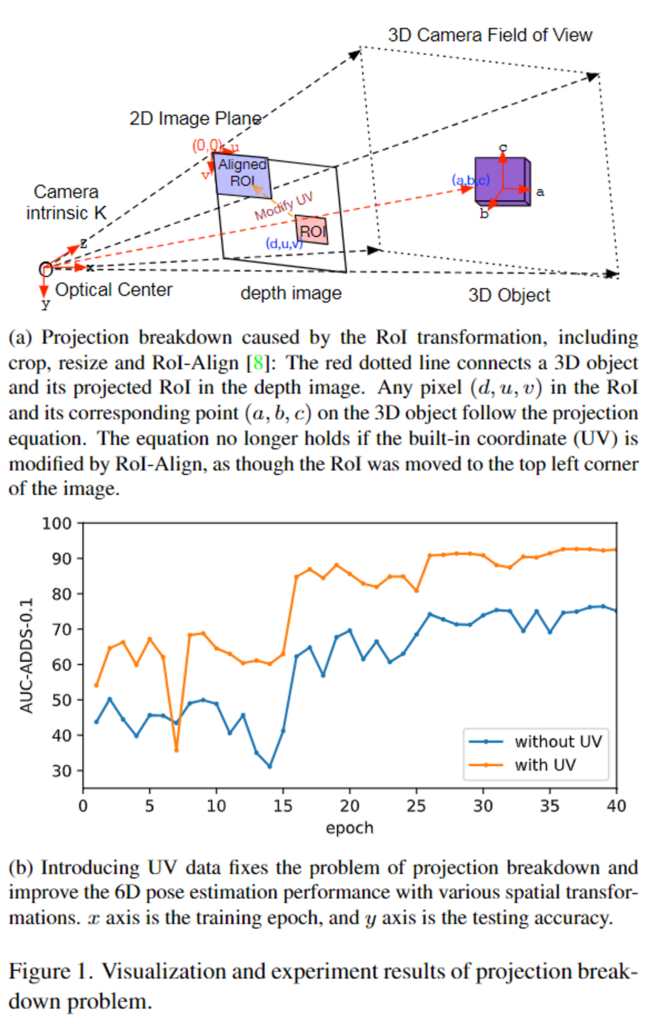
그러나, 전통적인 CNN 파이프라인은 pooling, corp, ROI-Align 등의 spatial transformation을 통해 UV를 변경하게 됩니다. 위의 그림 Figure 1-(a)에서 확인할 수 있듯이 이러한 spatial transformation이 적용될 경우 projection 식이 깨지며, 이를 projection breakdown이라 합니다. projection breakdown으로 인해 전통적인 CNN 파이프라인은 RGB 이미지와 depth 데이터를 동시에 처리하기 어렵습니다.
본 논문에서는 projection breakdown을 해결하기 위한 간단하고 효과적인 방법을 제안합니다. 2D CNN에 depth와 UV 데이터를 함께 입력으로 제공하여 Depth와 UV가 3D 데이터로 작동하여 각 픽셀마다 (d, u, v)를 만들고 depth인 d를 이미지 평면으로부터 분리합니다. self-complete 정보가 주어지면 spatial transformation이 적용된 후에도 prjoection 방정식이 유지됩니다. 위의 Figure 1-(b) 그래프는 UV 데이터의 사용에 따른 6D Pose Estimation 정확도를 나타낸 것으로 UV map을 활용하면 정확도를 크게 올릴 수 있습니다.
식 (1)은 RGB-D 이미지의 visible한 piont들을 3D 모델의 원좌표로 매핑해야한다는 것을 나타내며, 기존의 keypoint기반의 방법론들은 visible 영역에서 keypoint까지의 3D offset을 학습하고 SOTA 정확도를 제공합니다. 그러나 이러한 방식은 후처리 작업으로 voting과 regression 방식이 필요하며, 이 과정은 많은 시간이 걸리는 작업입니다. (FFB6D에서는 전체 프레임 중 92.9%의 시간이 이 후처리 과정에 걸렸다고 합니다.) 정확하고 빠른 파이프라인을 구축하기 위해, 저자들은 통합된 백본을 사용하여 RGB-D 이미지에서 feature를 추출하고, Mask R-CNN 기반의 end-to-end 방식으로 6D Pose를 예측하는 Uni6D를 제안합니다.
Mask R-CNN은 2개의 병력적인 head를 이용하여 detection과 instance segmentation을 수행합니다. 이를 바탕으로 해당 논문에서는 rotation matrix와 translation vector를 직접 예측하는 RT head를 추가하고, 시간이 많이 걸리는 후처리를 대신하여 visible point의 3D mapping을 위해 abc head를 추가하였습니다. Uni6D는 YCB-Video데이터에서 ADDS-0.1의 AUC 성능 95.2를 달성하였으며 최신 방법론대비 7.2배 빠른 25.6FPS의 inference 속도룰 달성하였습니다.
본 논문의 contribution을 정리하면,
- CNN 기반의 이미지 처리과정에 의해 발생하는 projection breakdown 문제를 보이고 UV 데이터를 활용하여 이를 해결
- 간단하고 효과적인 Uni6D 제안
- 확장실험과 ablation studies를 통해 제안한 방법론이 빠르고 높은 성능을 달성하는 것은 보임
Methodology of thd Uni6D
본 논문은 정확하고 real-time으로 작동이 가능한 6D pose estimation 방식을 제안하기 위해 RGB-D 이미지의 특징을 추출하기 위해 통합 백본을 이용하는 end-to-end 프레임워크 Uni6D를 제안하였습니다. Mask R-CNN을 활용하여 객체의 분류와 검출, segmentation 및 pose estimation을 모두 수행하는 멀티태스킹 학습을 수행합니다. 이제 각 요소에 대해 자세히 알아보도록 하겠습니다.
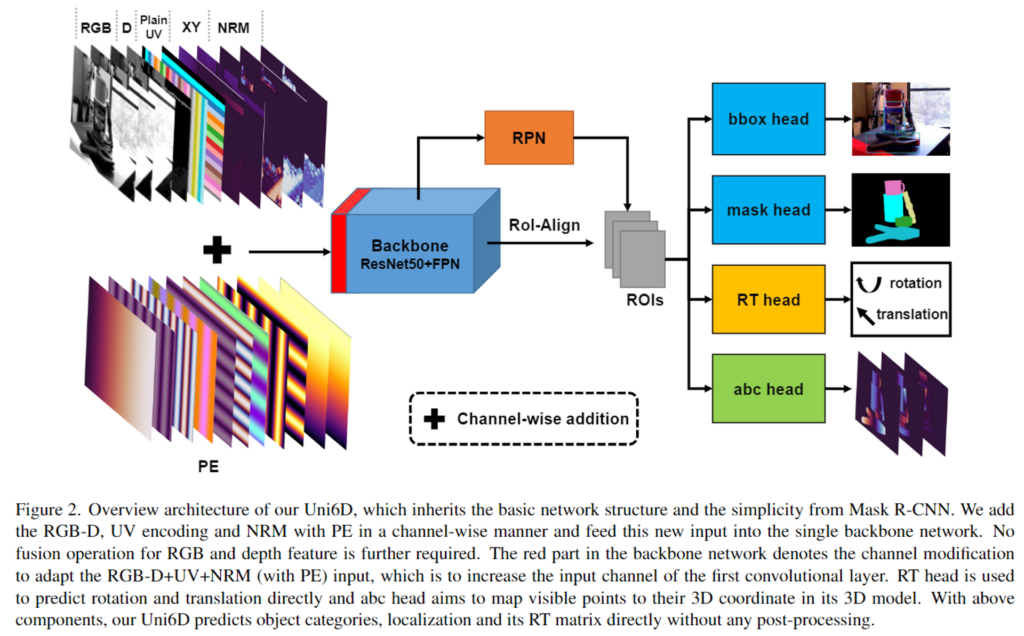
1. Legacy of Mask R-CNN
detection과 segmentation은 6D pose estimation에 초반에 많이 사용됩니다. Mask R-CNN으로 충분한 대응이 가능하므로 Mask R-CNN을 기본 네트워크로 활용하였다고 합니다. Figure 2와 같이 Uni6D는 Mask R-CNN의 구조인 ResNet 백본, feature pyramid를 위해 RPN, object가 존재하는 RoI를 찾기 위한 RPN, segmentation을 위한 mask head, 객체 검출 및 분류를 위한 bbox head를 사용합니다. 서로 다른 두 데이터에 동일한 백본을 사용하기 위해서는 projection breakdown 문제를 해결해야 합니다. 따라서 Mask R-CNN을 살짝 변경하여 RGB와 Depth 데이터를 함께 통합된 백본에 입력으로 사용합니다. 이처럼 함께 백본에 입력할 경우 feature를 융합하는 과정이 불필요해집니다. 여기에 6D Pose를 예측하기 위한 RT head와 3D 모델과 visible point를 매핑시키는 abc head를 추가합니다.
2. Encoding UV Data as Input
projection breakdown 문제를 해결하기 위해 저자들은 UV data를 활용하여 RGB-D 데이터를 백본 네트워크에 입력으로 사용합니다. RGB-D 데이터는 RGB 이미지와 depth 정보를 채널 축으로 직접 융합합니다. position 정보를 인코딩하는 방법은 3가지가 있습니다.
- Plain UV coordinates UV
UV 좌표 정보를 채널 차원에 따라 RGB-D 데이터와 직접 연결하는 방식으로, RGB-D 이미지와 UV 정보는 높이와 너비가 동일하고 U 채널과 V 채널에서 각각 u, v 픽셀 값을 가지게 됩니다. - Inverse projected XY
카메라 내부 파라미터 K와 depth 이미지가 주어졌을 때, 식 (1)을 이용하여 UV 좌표 (u,v)를 역투영된 XY (x,y)로 인코딩합니다. XY도 두개의 채널로 구성되며 XY와 RGB-D를 채널축으로 결합합니다. - Positional encoding PE
positional encoding은 vision transformers 등 다양한 분야에서 활용되는 방식으로, 삼각함수를 이용하여 위치 정보를 인코딩하여 입력 데이터에 추가합니다.
이렇듯 3가지 encoding 정보는 plain UV는 직접적이고, XY는 내부의 reference 정보를 의미하며, PE는 다른 input 채널에 추가하여 통합할 수 있다는 장점이 있습니다. 또한, depth 이미지에서 널리 사용되는 depth의 법선벡터는 입력 데이터에 “NRM”으로 추가됩니다.
3. RT head and abc head for Multitask Learning
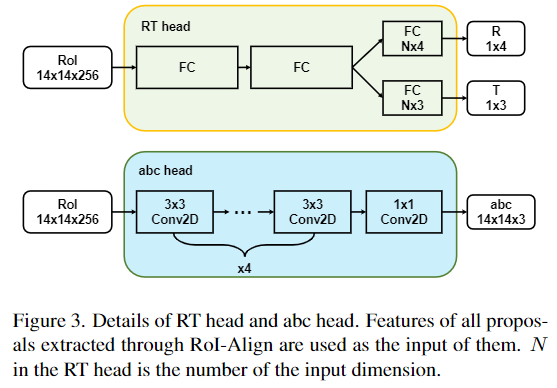
본 논문은 RT matrix와 3D 모델의 point를 예측하기 위해 RT head와 abc head를 제안하였습니다. R은 쿼터니안 형태의 rotation matrix, T는 translation matrix이며, RT head와 abc head를 mask R-CNN에 추가하여 RoI-Align을 통해 추출된 모든 RoI feature를 입력으로 사용합니다. Figure 3는 이 두 head를 도식화한 것으로, RT head는 RT matrix를 구하기 위해 2개의 shared FC layer와 2개의 독립적인 FC layer로 구성되며, abc head는 3D Point cloud를 출력하기 위해 4개의 3×3 Conv layer와 1개의 1×1 Conv layer로 이루어진 FCN 구조(fully convolutional network 구조로, FC layer를 이용할 경우 공간적 정보가 소실되고 입력 크기가 제한된다는 문제를 해결하고자 모든 레이어를 convolution 레이어로 표현한 것입니다)로 이루어져있습니다.
4. Loss Function
mask R-CNN의 classification, detection, segmentation loss function에, 본 논문에서 제안한 RT head와 abc head에 대한 2가지 loss가 추가됩니다. 먼저 RT head의 loss \mathcal{L}_{rt}는 아래의 식 (2)로 정의됩니다. 참고로 식(2)는 pose 정보에 대한 손실함수로 많이 사용되는 loss로, 3D 모델의 각 vectex에 GT pose와 예측 pose를 적용하여 이동시킨 뒤, 거리를 측정하는 방식입니다.
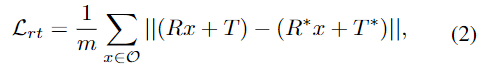
- \mathcal{O}: object의 3D 모델의 vertex 집합
- R: rotation matrix
- T: translation vector
abc head의 loss는 아래의 식 (3)으로 정의됩니다.
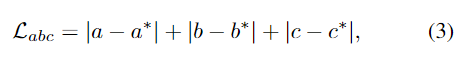
- (a,b,c): point의 좌표
따라서 본 논문의 total loss는 아래의 식으로 표현됩니다.
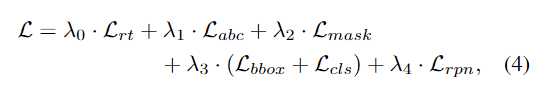
Inference
기존의 SOTA 6D pose estimation 방법론과 다르게 시간이 많이 소요되는 후처리를 거치지 않고, RT head에서 예측한 결과를 바로 이용합니다.
Experiments
Dataset
6D Pose Estimation에서 많이 사용하는 밴치마크인 YCB-Video와 LineMOD, Occlusion LineMOD를 이용하여 실험을 진행합니다.
- YCB-Video
- 21개의 YCB object에 대해 92개의 비디오로 구성된 RGBD 데이터
- 모든 데이터에 6D pose가 annotation 되어있고 instance level의 mask가 있음
- 기존 연구와 동일하게 train/test셋을 구성함
- Pose CNN이라는 기존 방법론의 방식으로 합성 데이터를 만들어 네트워크를 학습함
- LineMOD
- 13개의 low-textured object에 대한 13개의 비디오가 포함
- 기존 연구와 동일하게 train/test 셋을 구성함
- Pose CNN이라는 기존 방법론에서 사용한 방식으로 합성데이터를 만들어 학습
- Occlusion LineMOD
- LineMOD에서 확장된 데이터
- 심하게 occlusion 된 상황에서의 강인성 평가에 사용
Evaluation Metrics
평가지표는 6D Pose estimation에서 사용하는 ADD(-S)를 이용합니다. 아래의 식으로 정의가되며, 3D 모델의 vertex에 GT와 예측된 transformation matrix를 적용하여 거리를 측정하는 방식입니다. (앞서 RT head의 loss를 구하는 것과 동일) 이때 물체가 symmetric할 경우 거리가 가까운 vertex에 대한 값을 이용합니다.
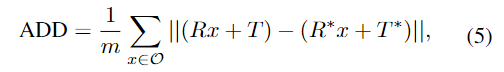
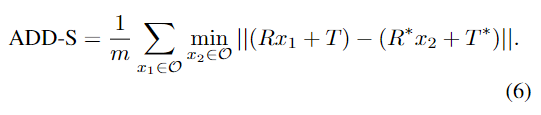
YCB-Video의 경우 거리의 threshold(최대 0.1 m)를 변경하여 얻은 accuracy-threshold 곡선에서 ADD-S와 ADD(S)를 계산합니다. LineMOD는 대상 object의 직경에 0.1% 미만인 거리의 accuracy를 측정합니다.
Comparison with Other Methods
1. Evaluation results on YCB-Video dataset
YCB-Video 데이터에 대한 정량적 결과는 Table 1에서 확인할 수 있습니다. 다른 방법론과 비교했을 때, ADD-S에 대해서 95.2%, ADD(S)에 대해 88.8%를 달성하였습니다. DenseFusion와 다르게 후처리를 거치지 않았고, 하나의 백본을 이용하여 더 좋은 성능을 보였습니다. SOTA 방법론에 비해서는 조금 낮은 성능을 보였지만 이는 반복적인 refinement를 수행하지 않고 달성하였다는 점에서 유의미한 결과입니다.(시간에 대해서는 아래에서 다시 다룹니다.)
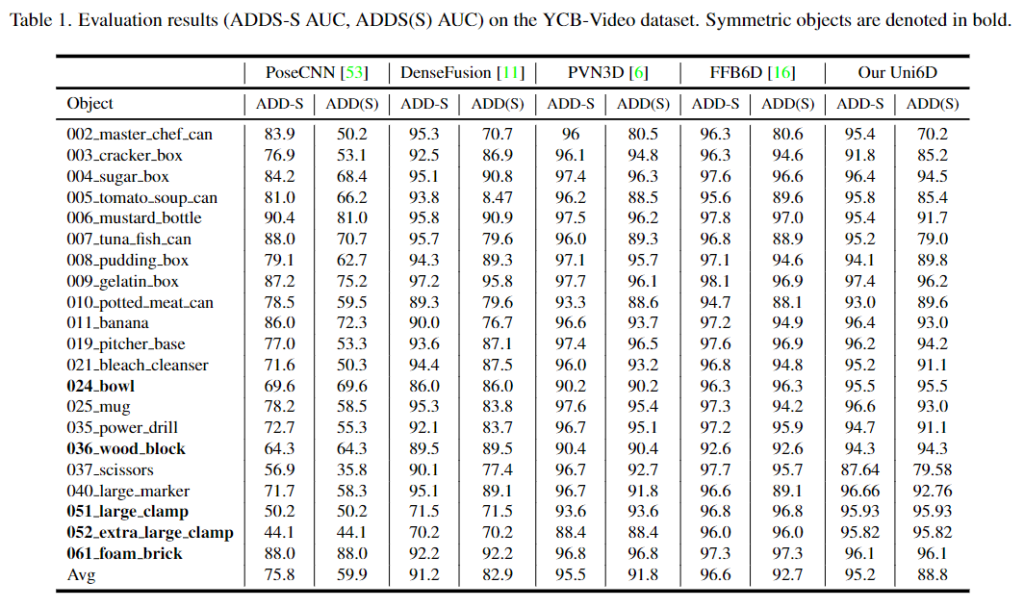

또한, 아래의 Figure 4를 통해 occlusion이 발생할 경우의 정확도를 확인해 본 결과, 저자들의 방법론이 강인하게 작동한다는 것을 확인할 수 있습니다.
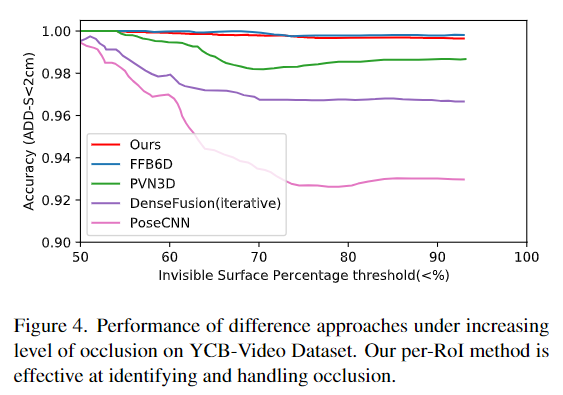
Time Efficiency
본 논문은 단순한 파이프라인으로 이루어졌으며, 후처리 과정을 거치지 않는다는 점도 포함하여 inference 속도에 큰 강점이 있습니다. 아래의 Table 2에서 다른 방법론과의 비교를 확인할 수 있습니다. 후처리과정은 FFB6D에서는 전체 시간의 92.9%, PVN3D에서는 79.2%의 시간을 차지할 만큼 시간이 많이 소요되는 과정입니다. 이를 줄임으로써 Uni6D는 FFB6D에 비해 7.2배, PVN3D에 비해 13.6배 더 빠른 속도를 달성하였습니다.
inference 시간과 성능에 대한 결과는 아래의 Table 5로 나타낼 수 있습니다.
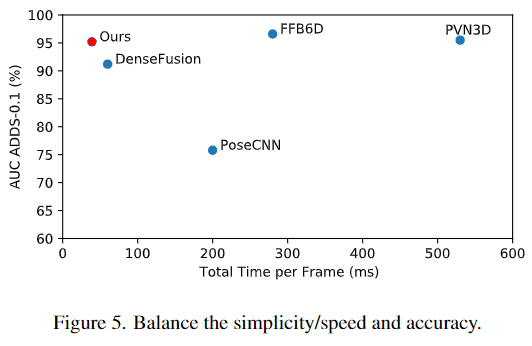
Ablation Study
1. Projection Breakdown Saved by UV
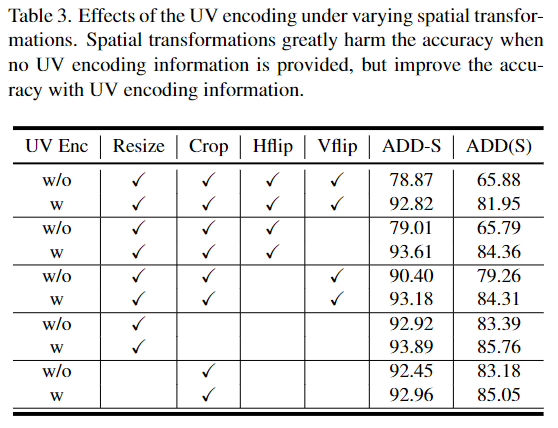
아래의 Table 3은 projection breakdown 문제에서 UV encoding이 영향을 확인하기 위한 실험 결과로, YCB-Video에 대해 spatial transformation을 수행하여 성능을 확인한 것입니다. random resize, crop, horizontal flip, vertical flip과 같이 공간적인 변형을 주는 증강방식을 사용할 경우, ADD-S가 최대 15%, ADD(s)는 최대 20% 성능이 감소합니다. 이를 해결하기 위해 저자들은 하나의 백본으로 모든 것을 해결할 수 있도록 UV encoding 정보(UV,XY,PE)를 추가하였습니다. 표를 보시면 UV Encoding을 사용하였을 때 성능이 개선되는 것을 확인할 수 있습니다.
2. UV Encoding Methods
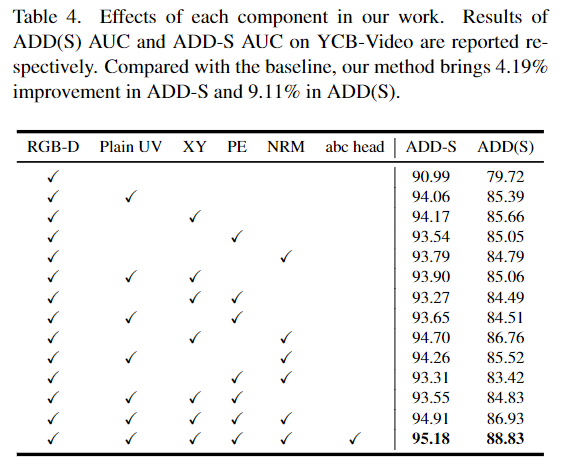
UV encoding 방식의 효과를 확인하기 위해 실험을 진행하였으며, 결과는 Table 4에서 확인할 수 있습니다. RGB-D는 RGB-D 데이터만을 이용한 경우이고 각 UV encoding 요소들의 사용 여부와 abc head는 학습에 abc head를 이용하는지 여부를 나타낸 것입니다. UV encoding 정보의 사용 여부에 따라 성능이 크게 변하는 것을 확인할 수 있으며, 모두 사용할 경우 가장 좋은 결과를 얻을 수 있다는 것을 확인할 수 있습니다.
Limitation Analysis
- For the performance of 6D Pose Estimation
- 기존 SOTA 방법론과 비교했을 대 약간의 성능 하락이 있음
- 이는 기존 방법론에서 정확도를 높이기 위해 사용하는 후처리 과정을 사용하지 않기 때문
- 이를 통해 추론 효율성이 크게 향상되었으며, real-time 작동이 가능해짐
- For the RoI-Align operation
- RoI-Align 작업은 RT head의 성능을 제한하고, 정확도 하락을 일으킴
- 단순성을 해치지 않으면서도 더 좋은 결과를 얻기 위해 RoI feature에 노이즈를 제거하는 연구 필요
Conclusion
다시 정리하자면, 본 논문은 projection breakdown이라는 문제를 확인하고, 이를 해결하기 위해 RGB-D 데이터에 UV 데이터를 추가하여 projection breakdown를 추가하여 하나의 백본으로 feature를 추출하는 방법을 제안하였습니다. 단순화된 네트워크와 후처리를 사용하지 않음으로써 빠른 inference가 가능하며, end-to-end로 학습이 가능하다는 장점도 확보하였습니다.
본 논문은 Mask R-CNN을 이용하여 단순화된 네트워크로 Pose를 추정할 수 있다는 것이 인상적입니다. 또한 서로 다른 정보로 이루어진 데이터를 하나의 네트워크로 feature를 추출하였음에도 큰 문제가 발생하지 않는다는 것이 흥미롭습니다.
안녕하세요, 좋은 리뷰 감사합니다.
전체적인 파이프라인을 봐도 지금까지 본 방법론들에 비해 매우 효율적일 것 같은 방법론인 것 같습니다.
간단한 질문을 드립니다.
1. Mask R-CNN에서 수행되는 bbox head와 mask head를 통해 나온 결과를 가지고 RT/abc head를 거치는 건가요? 아니면 그림과 같이 병렬적으로 수행되는 건가요?
2. abc head의 역할을 단지 point cloud만 계산하고 끝인건지 궁금합니다. abc head는 어떻게 사용되는지 궁금합니다.
감사합니다.
질문 감사합니다.
1. RT/abc head 도 bbox/mask head와 같이 병렬적으로 수행됩니다.
2. abc head의 역할은 출력으로 point cloud 값을 반환하는 것으로, 이미지의 visible한 영역이 3D 모델의 어디인지를 매핑하는 것입니다. 이 과정을 통해 모델이 얼만큼 transformation 되어야 하는 지를 네트워크 자체에 정보로 제공할 수 있습니다.
안녕하세요 ! 좋은 리뷰 감사합니다.
projection breakdown을 해결하기 위해 depth인 d를 이미지 평면으로부터 분리한다고 하셨는데 분리라는 것이 정확하게 어떤 의미인가요 ? ? 그리고 self-complete 정보가 주어진다는 것은 어떤 정보가 주어지는 것인지 추가적인 설명해주실 수 있나요 .. ? 또 한가지 궁금한 점은 3D 모델과 visible point를 매핑시키는 abc head를 추가한다고 말씀하셨는데 abc head의 어떤 부분에서 매핑이 진행되는 것인지 잘 이해가 되지 않아 자세하게 설명해주시면 감사하겠습니다 !
질문 감사합니다.
우선, projection breakedown은 depth 정보를 이미지 평면으로 부터 분리한다는 것은, 이미지 자체에 포함되는 depth 정보에 의존하지 않고, 각 픽셀마다 만든 (d, u, v)를 이용하여 depth 정보를 제공한다는 것입니다. 또한 이러한 관점에서 (d, u, v)를 이용하여 3차원 정보를 보완적으로 제공한다는 것이 self-complete 정보를 준다는 것입니다.
abc head의 어떤 부분이 매핑되는 지에 대해서 설명을 드리자면, 우선 입력 데이터로부터 3d point cloud를 출력하는 것으로, 입력 데이터인 이미지의 visible한 영역과 3차원 모델을 매핑하는 것입니다.