안녕하세요, 열세번째 x-review 입니다. 이번 논문은 CVPR 2022에 게재된 DeepFusion으로 지난 주와 마찬가지로 포인트 클라우드와 카메라 이미지를 fusion하는 3D Object Detection 논문 입니다. 그럼 리뷰 시작하겠습니다 !

1. Introduction
LiDAR에서는 resolution은 낮지만 depth 정보를 얻을 수 있고, 카메라 영상에서는 높은 resolution의 semantic한 정보를 얻을 수 있다는 장점이 존재합니다. 그런데 보통 3D Object Detection task에서 SOTA를 달성하는 방법론의 경우 LiDAR만을 사용합니다. 이는 여전히 두 모달리티의 정보를 fusion하는 방식이 풀어야 할 문제로 남아있다는 것을 의미하며, 본 논문에서는 범용적이고 효과적으로 해당 문제를 해결하고자 하였습니다. 기존의 fusion 모델은 크게 early fusion, mid-level fusion으로 나눌 수 있는데 먼저 early fusion은 포인트 클라우드에 대응하는 카메라 feature을 덮어씌우는, 흔히 point decoration이라 불리우는 방식들을 의미합니다. mid level fusion은 두 입력 데이터를 따로 feature extractor를 거치게 한 후에 출력 특징들을 합치는 방식 입니다. 두 방식에서 풀고자 하는 공통적인 어려움은 포인트 클라우드와 카메라 사이의 대응하는 feature을 찾는 것 입니다.
이러한 기존 fusion 방식의 문제점을 해결하고자 논문에서는 mid level fusion 기반의 InverseAugmentation과 LearnableAlign을 제안하게 됩니다. method에서 더 자세하게 설명하겠지만 간단히 두 가지에 대해 설명해보자면, InverseAugmentation은 RandomRotation과 같은 기하학과 관련된 augmentation을 할 경우에 변화한 두 모달리티의 데이터 사이에서 연관성을 찾기 위해 augmentation 이전의 카메라와 LiDAR 파라미터를 저장합니다. 그리고LearnableAlign은 두 feature 사이의 correlation을 다이나믹하게 찾기 위해 도입하였습니다. 두 모듈이 포함된 본 논문의 모델을 DeppFusion으로 명칭하며 DeepFusion은 기존의 fusion 모델인 PointPillars나 CenterPoint와 같은 detector에 추가할 수 있는 플러그인 역할을 합니다. 그 과정에서 사용되는 하나의 cross attention layer에 대한 최소한의 계산 cost만 추가되며 카메라 이미지를 포인트 클라우드에 효과적으로 align을 맞출 수 있도록 합니다. DeepFusion은 outdoor 3D 데이터셋인 Waymo Open Dataset에서 SOTA를 달성하면서 효과적으로 두 모달리티를 합칠 수 있음을 증명하였습니다. 여기서 본 논문의 contribution을 정리하면 다음과 같습니다.
- 3D 멀티 모달 detector에 대한 deep feature에서의 alignment 영향성에 대해 처음으로 연구
- deep feature alignment를 맞출 InverseAug와 LearnableAlign을 제안
- Waymo Open Dataset에서 SOTA 달성
2. Related Work
LiDAR-camera Fusion
monocular detection에서는 3D bounding box를 2D 이미지에서 먼저 예측합니다. 이러한 방식의 주된 어려움은 2D 이미지에서는 depth 정보를 얻을 수 없기 때문에 2D 이미지 픽셀에서 depth를 임의적으로 예측할 수 밖에 없는데 이는 매우 어려운 task에 해당합니다. 그래서 2D 이미지에서 먼저 물체를 검출하고, 포인트 클라우드에서 더 semantic한 정보를 사용하기 위해 2D 이미지에서의 결과를 추가적으로 이용하는 방식으로 발전하였습니다. 이러한 이전의 방법론은 2 stage 프레임워크를 고수하는 반면에 본 논문에서는 end-to-end로, 존재하는 voxel 기반의 3D detection 방법론에 쉽게 플러그인 될 수 있습니다.
Point Decoration Fusion
PointPainting은 2D 이미지에서 사전학습한 semantic segmentation 네트워크에서 추출한 semantic score와 각 포인트 클라우드를 augment하는 방법론 입니다. PointAugmenting은 PointPainting의 semantic score의 한계를 지적하면서 2D object detector로 추출한 이미지 특징으로 포인트 클라우드를 augment하고자 하였습니다.
Mid-level Fusion
기존 EPNet이나 4D-Net 등은 2D, 3D 백본 사이의 정보를 공유함으로써 두 모달리티를 합치고자 하였습니다. 그러나 중요하지만 놓친 부분이라고 함은 효과적인 alignment 기법이라고 할 수 있습니다. align을 맞추는 것이 중요한 것을 알지만 효과적인 기법을 구축하는 것이 어려운 이유 중 하나는 성능 향상을 위해서 fusion 하기 이전에 포인트 클라우드와 카메라 이미지에서 각각 다양한 augmentation을 적용하기 때문 입니다. 특히 z축을 따라서 회전시키는 포인트 클라우드에서의 RandomRotation은 depth 정보가 없는 2D 이미지에서는 적용할 수 없는 augmentation 기법으로 이러한 augmentation이 포인트 클라우드에서 적용되면 feature을 align 맞추는 것이 더더욱 어려워집니다. 또한 여러 개의 포인트 클라우드가 하나의 복셀에 모아지기 때문에 한 복셀 그리드 내의 포인트가 모두 동일한 중요도를 가진다고 할 수 없습니다. 해당 부분은 사실상 이전 fusion 방식을 언급하면서 InverseAug와 LearnableAlign을 통해 align을 맞춰야 하는 이유를 정의하고 있습니다.
3. DeepFusion
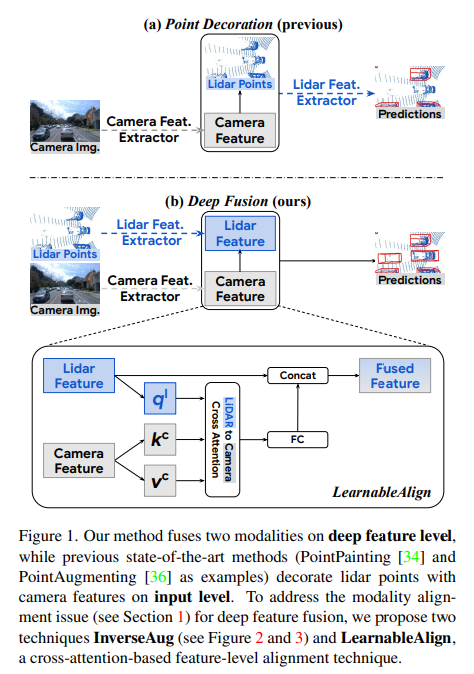
3.1. Deep Feature Fusion Pipeline
Figure1 (a)의 PointPainting이나 PointAugmenting과 같은 이전의 메소드는 보통 2D detector나 segmentation 모델에서 특징을 추출하여서 3D 포인트 클라우드에 덮어 씌우는 방식으로 구성되어있습니다. 그런데 기존 방식은 좀 더 개선될 수 있는 가능성이 남아있는데 그 이유로 먼저 이미지 특징이 3D 포인트 클라우드를 처리하기에는 최적화된 구조로 이루어져 있지만, 이미지 특징을 처리하기에는 적절하지 않는 구조에 함께 들어가게 됩니다. 예를 들어 PointPillar는 이미지 특징을 raw level의 포인트 클라우드와 함께 복셀 형태로 변환하여 BEV pseudo 이미지를 생성하였다고 합니다. 여기서 복셀 형태는 포인트 클라우드를 처리하기 위한 형식으로 카메라 이미지 정보를 처리하기에 적절하지 않다고 하는 것 입니다. 또한 카메라 특징을 추출하기 위한 feature extractor가 2D detection이나 segmentation와 같은 다른 독립적인 task에서 학습이 되었기에 domain gap이 발생하고 추가적인 연산량이 발생하며 3D detection에 최적화 된 feature을 추출하지 못하게 됩니다. 이러한 문제들을 해결하기 위해서 deep feature fusion 파이프라인을 제안하게 된 것이죠. 첫번째 문제를 해결하기 위해서 포인트 클라우드용으로 설계한 모듈을 거치기 이전이 raw level의 포인트 클라우드가 아니라 mid level에서 카메라 feature와 LiDAR feature을 합칩니다. 두번재 문제는 이미지 feature을 추출하기 위해 convolutional layer을 사용하여 end-to-end 방식으로 네트워크의 다른 component들과 함께 학습할 수 있도록 하였습니다. 이러한 DeepFusion의 파이프라인이 바로 Figure1 (b)로 포인트 클라우드는 3D feature extractor로 특징을 추출하고 2D 이미지는 ResNet을 사용한 다음 추출한 두 데이터의 특징을 합치게 됩니다. 이로써 풍부한 context 정보를 가진 high resolution 카메라 특징이 voxel화 되지 않을 수 있고 end-to-end로 domain gap이나 어노테이션 관련 이슈를 줄일 수 있습니다. 그러나 그럼에도 불구하고 아직 해결하지 못한 문제점들이 존재하는데요, 기존 input level의 fusion과 비교할 때 두 특징의 align을 맞추는 것이 쉽지 않습니다. 예를 들면 두 데이터에 대한 서로 다른 augmentation에 의해 aligment가 부정확하다는 것 입니다. 이 문제를 이제부터 설명할 InverseAug와 LearnableAlign으로 해결할 수 있습니다.
3.2. Impact of Alignment Quality
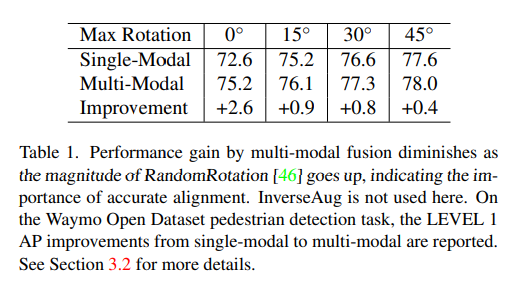
alignment을 위한 두 모듈을 살펴보기 이전에 deep feature fusin에서 align의 영향을 정량적으로 평가하기 위해 random rotation에 따른 실험을 진행하였습니다. 카메라 이미지에는 적용하지 않고 포인트 클라우드에만 적용하였는데, augmentation이 기하학과 관련성이 높을수록 misalign이 강해진다고 합니다. Tabl1에서 멀티 모달에서 rotation의 앵글이 클수록 성능이 오히려 감소하는 것을 확인할 수 있씁니다. rotation을 아예 하지 않았을 때의 2.6% 성능 향상에 비해 최대 각도인 45도에서는 오히려 0.4%만큼의 성능 향상만이 발생하였습니다. 이러한 결과를 바탕으로 저자는 align이 deep feature fusion에서 중요하며 align이 정확하지 않을수록 멀티 모달에서 카메라 이미지의 사용에 대한 영향이 미미해진다고 정의하였습니다.
3.3. Boosting Alignment Quality
deep feature fusion에서 align을 맞추는 것에 대한 중요성을 확인하였기에 이제 InverseAug와 LearnableAlign에 대해 알아보도록 하겠습니다.
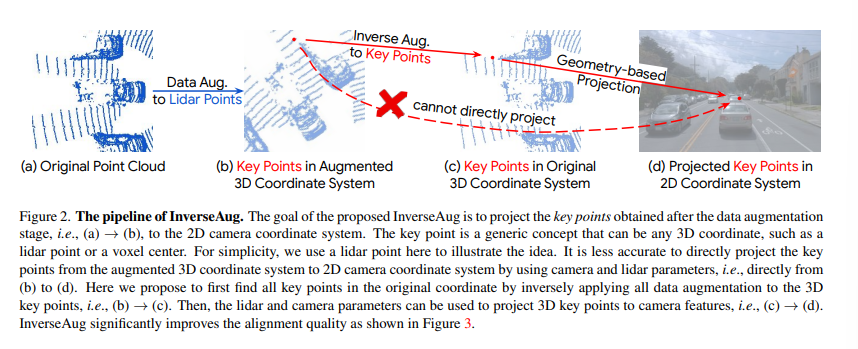
InverseAug
3D Object Detection 모델에서 data augmentation은 중요하게 적용되지만 deep feature fusion에서 augmentation은 간단하게 끝나지 않는 문제 입니다. 이미지에서는 random flip을, 포인트 클라우드에서는 z축으로 rotation을 하는 등 서로 다른 augmentation을 적용하면서 alignment 문제가 더더욱 도드라지게 됩니다. 이를 해결하기 위해 제공하는 것이 InverseAug 입니다. 그런데 근본적으로 augmentation을 하는 것이 왜 align에 문제가 되는 것일까요 ? 이유는 Figure2에서처럼 augmentation이 적용되고 포인트 클라우드에서 3D key point가 주어지면 (3D key point라고 함은 3차원 좌표나 voxel의 센터와 같은 것들이 있습니다.) 그때부터는 3D key point를 단순히 LiDAR와 카메라 파라미터만 사용하고서는 대응하는 2D 공간의 카메라 feature을 위치시킬 수 없게 됩니다.

그래서 InverseAug는 먼저 기하학과 관련된 augmentation을 할 경우 rotation 각도와 같은 augmentation 파라미터들을 저장합니다. 그리고 fusion 단계에서 저장한 파라미터 값들을 이용하여 모든 augmentation을 Figure2 (c)와 같이 3D key point에 대한 원래의 좌표를 얻기 위해서 역으로 돌려놓습니다. 그러면 원래대로 돌아온 좌표를 통해서 2D 공간에서 대응하는 2D 좌표를 찾을 수 있게 됩니다. InverseAug는 Figure2에서의 포인트 클라우드 뿐만 아니라 voxel center와 같은 다른 3D key point에서도 align할 수 있고 포인트 클라우드에만 augmentation을 적용하는 경우와 더불어 두 데이터 모두에 augmentation이 적용되는 경우에서도 적용할 수 있는 범용적인 방식 입니다. 기존의 PointAugmenting과 같은 기존 fusion 방식에서 augmentation을 하지 않는 데이터만 처리할 수 있는 것과 비교하면 augmentation을 하면서 fusion을 할 수 있다는 강점을 가지게 되는 것이죠. Figure 3이 InverseAug 유무에 따른 alignment quality 차이를 보여주고 있습니다.
LearnableAlign
기존 input level fusion의 PointPainting이나 PointAugmenting은 포인트 클라우드에 대응하는 카메라 픽셀을 딱 하나만 찾으려고 하는 ont-to-one 매핑 입니다. 그러나 feature extractor을 지난 feature들끼리 fusion하는 deep feature fusion은 포인트들이 부분 집합으로 각 voxel grid에 포함되어 표현되기 때문에 대응하는 카메라 픽셀이 반드시 하나라고 장담할 수 없습니다. 그래서 align을 맞출 때 ono-to-one 매핑이 아니라 one-voxel-to-many pixel 문제로 정의해야 한다고 합니다. 가장 나이브하게는 주어진 복셀에 대응하는 모든 픽셀의 평균을 내는 것 입니다. 그러나 직관적으로 생각해봐도 평균을 낼 픽셀들이 동일한 중요도를 가지지는 않겠죠. 예를 들면 어떤 픽셀은 검출할 물체의 semantic한 정보를 가지고 있을테지만 한편으로는 background나 단순 road와 같은 덜 중요한 정보가 담겨 있는 픽셀까지 포함되어 있을 수 있습니다. 최대한 정보가 풍부한 픽셀들을 대응시키기 위해서 LearnableAlign을 도입하게 됩니다. LearnableAlign은 Figure1 (b)에서와 같이 cross attention 모듈을 이용하여 두 모달리티 사이의 correlation을 찾고자 하였습니다. 입력으로 voxel grid와 그에 대응하는 N개의 카메라 feature가 있는데, 각각 embedding 하기 위해서 세 개의 FC layer을 각각 사용하여 voxel을 query q^l로, 카메라 feature을 keys k^c, values v^c로 변환 합니다. 각각의 query에 대해 attention affinity matrix을 만들기 위해서 key와의 내적을 합니다. 여기서 attention affinity matrix는 voxel과 N개의 카메라 feature에 대응하는 1 \times N개의 correlation을 포함하고 있습니다. matrix에 softmax로 normalization을 하고 v^c에 가중치로 곱해줍니다. 각각의 가중치가 곱해져 aggregate한 정보는 Fc layer을 거쳐서 기존의 포인트 클라우드 특징과 합쳐지게 됩니다.
4. Experiments
실험에는 large scale의 out door 3D Object 데이터셋을 사용하였습니다. 평가 metric은 AP와 Average Precision weighted by Heading(APH)를 사용하였고 LEVEL_1 (L1)와 LEVEL_2(L2) (object를 검출하는 어려움에 따라 level이 나뉘어져 있습니다.) 두 level 모두에서 평가를 진행하였습니다. LEVEL_2에서의 APH가 Waymo에서 평가하는 주요 metric이라고 합니다.
4.1. Implementation Details
3D detection models
detection 모델로는 널리 사용되는 PointPillars, CenterPoint, 3D-MAN을 사용하였습니다. 또한 3개의 MLP layer을 추가하고 활성화 함수를 ReLU에서 SILU로 바꾸어 개선한 PointPillars++, CenterPoint++, 3D-MAN++도 베이스라인으로 사용하였습니다.
InverseAug
augmentation은 순서대로 RandomRotation → WorldScaling → GlobalTranslateNoise → RandomFlip → Frustum-Dropout → RandomDropLaserPoints를 적용하였다고 합니다.
4.2. State-of-the-art performance on Waymo Data
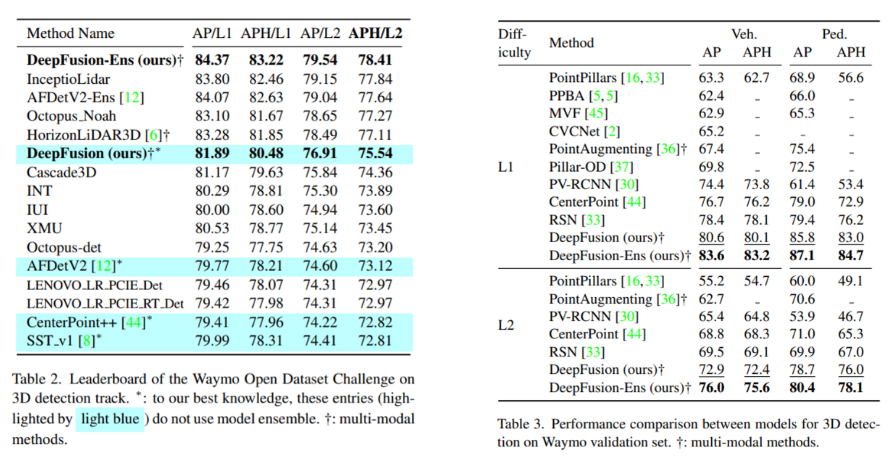
다음은 Waymo에서의 SOTA 방법론들과의 성능을 비교하였습니다. 먼저 Table2는 Waymo challenge 리더보드에 제출한 결과로 당시 SOTA인 AFDetV2에 비해 APH/L2에서 2.42 향상된 결과를 보이며 SOTA를 달성하였습니다. 실험 표에서 Ens는 앙상블 기법을 사용한 것이고 +는 멀티 모달 데이터를 사용한 방법론들을 의미합니다. 그리고 Table3은 Waymo validation 데이터셋에서의 실험 결과 입니다. LEVEL L1와 L2 모두 타 방법론들과 큰 폭으로 성능 향상을 보이고 있습니다.
4.3. DeepFusion is a generic fusion method
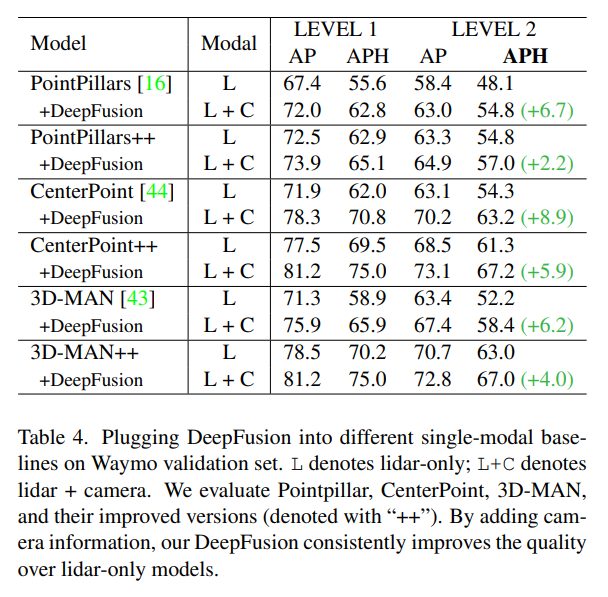
introduction에서 범용적으로 두 모다리티를 합치는 방식을 만드는 것이 목적이라고 언급하였는데, 본 논문에서 제안한 모듈들을 널리 쓰이는 detection 모델에 추가하였을 때의 실험 결과 입니다. 기존 포인트 클라우드만을 입력으로 했던 모델에 DeepFusion으로 카메라 이미지를 합쳤을 때 모든 모델에서 향상된 결과를 보이며 DeepFusion이 여러 모델에 일반적으로 효과적인 성능 향상을 보이며 범용적인 framework로 적용될 수 있음을 알 수 있습니다.
4.4. Impact of InverseAug and LearnableAlign
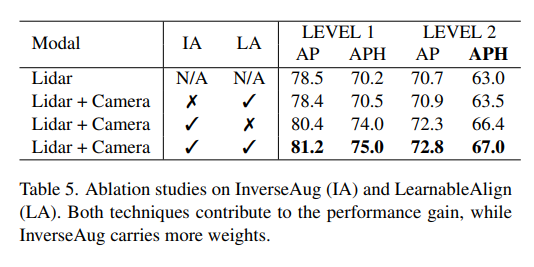
다음으로 main contribution인 InverseAug와 LearnableAlign이 성능에 미치는 영향에 대한 실험 입니다. 실험 결과를 보았을 때 두 모듈을 모두 사용한 67.0에서 하나씩 뺐을 때 InverseAug의 영향이 더 크다는 것을 알 수 있습니다. 그러나 LearnableAlign 역시 적용하였을 때 성능이 개선되기에 저자는 두 모듈을 함께 사용하는 것이 최상의 결과를 낼 수 있다고 합니다.
안녕하세요. 질문이 몇가지 있어 남깁니다.
1. Impact of alignment quality에 대한 실험에서 alignment의 중요성을 보기 위해 Image는 원본 그대로, Lidar point의 경우 rotation을 0,15,30,45도로 적용한 것으로 이해를 하였습니다. 여기서 궁금한 점이 Lidar가 이렇게까지 회전되는 상황까지 고려해야하는 이유가 무엇인가요? 일반적으로 자율주행 센서를 설치하는 상황에서 라이다랑 카메라의 정합이 회전이 45도가 발생할 정도로 깨지는 상황이 연출될 것 같지는 않은데.. 정합의 중요성을 강조하고자 너무 무리하게 성능이 떨어지는 상황을 연출한 것은 아닌가 의문이 듭니다.
2. 그리고 InverseAugmentation에 대해서 제가 제대로 이해한 것이 맞는지 모르겠습니다만 Lidar Feature를 뽑을 때는 rotation과 같은 augmentation을 취해 이동 변환을 시키지만 영상 feature와 fusion을 할 때는 두 모달리티 간에 alignment를 맞추기 위해 다시 augmentation을 역으로 되돌린다는 말씀이신가요?
3. 이렇게 할 경우에 두 모달리티 간에 정합이 맞게 되어서 fusion이 잘 되어 검출을 잘 할 수는 있겠습니다만.. 이러면 처음부터 augmentation을 왜 하는 것인가요? Lidar Feature Extractor가 다양한 상황에서 feature를 잘 뽑도록만 설계하고 싶어서 이렇게 진행하는 것인가요? 애초에 real application 관점에서 정합이 틀어지는 상황에도 강건하게 하기 위해 이러한 augmentation을 넣고 학습을 시키는 것은 아닌가요?
그렇다면 실제 상황에서도 정합이 깨지는 상황이 발생했을 때 모델이 더 강건하게 동작하도록 alignment를 잘 맞춰야하는 모듈이나 방법론이 필요할 것 같은데, 해당 inverse augmentation의 경우에는 단순히 alignment를 깼을 때 사용했던 rotation 파라미터 등을 따로 저장해서 이를 원본으로 되돌리는 행위를 하는 것이기 때문에 모델이 스스로 정합을 잘 맞추기 위한 어떤 수단 및 방법론을 배우지는 못하는 것 아닌가요? (아마 LearnableAlign이라는 밑에서 소개하는 방법론이 모델이 스스로 정합을 잘 맞추기 위한 모듈로 여겨지는데… 해당 방법이랑 InverseAugmentation이랑 어떤 관련이 있는지 잘 모르겠네요)
4. 마지막으로 저자가 제안하는 방식을 통해 학습한 모델은 그러면 alignment가 깨져도 강건하게 동작하는 모델로 이해하면 될 것 같은데, 저자가 제안하는 방식으로 학습한 경우(즉 deepfusion을 사용한 경우) Rotation을 0, 15, 30, 45도로 돌려서 정합을 깼을 때 성능 향상이 베이스라인 대비 얼만큼 향상됐는지에 대한 실험은 없나요?
감사합니다.
안녕하세요 ! 리뷰 읽어주셔서 감사합니다.
1. 음 .. 자율주행 센서를 설치한 상황에서는 회전이 45도 이상 발생할 정도로 정합이 깨지는 상황이 연출된다고는 저도 생각하진 않지만 augmentation 관점에서는 rotation 각도를 45도로 설정할 수 있을 거라 생각이 들긴 합니다. 아무래도 단일 모달리티, 멀티 모달리티를 비교했을 때 회전에 따른 멀티 모달리티의 성능 폭이 미미하다는 것을 강조하기 위해서 45도까지 rotation angle을 발생시킨 것이 아닐까 생각합니다.
2, 3. 넵 일단 InverseAug는 두 모달리티 사이에 서로 다른 augmentation이 적용되었을 경우에 augmentation 이전의 파라미터를 가지고 있는채로 augmentation을 하고, 3D와 2D key point 사이의 projection을 할 때는 이전의 파라미터로 진행하는 것을 의미합니다. 제가 이해하기로는 학습에 들어가는 것은 augmentation이 된 point가 들어가게 되고 그 augmentation된 각각의 포인트에 대응하는 2D key point를 찾는 것이 이미 포인트가 기하학적으로 틀어졌기 때문에 augmentation된 파라미터로는 2D key point를 찾을 수가 없기 때문에 InverseAug를 진행하는 것 입니다.
4. 아쉽게도 각도로 정합이 깨졌을 때 베이스라인 대비 성능 향상을 보여주는 실험같은 경우는 논문에 포함되어 있지 않습니다 ㅎ ㅎ . .
안녕하세요, 좋은 리뷰 감사합니다.
간단한 질문이 있습니다.
1. 실험 섹션에서 언급하신 Precision weighted by Heading(APH)는 어떤 평가지표인지 궁금합니다. 저희가 기존에 알고 있던 Precision과 좀 다른 건가요?
2. 해당 평가지표를 Waymo라는 데이터셋에서만 적용하는 건지도 궁금합니다.
감사합니다.
안녕하세요 ! 리뷰 읽어주셔서 감사합니다.
1. APH 같은 경우에는 각 heading마다 가중치를 두어서 AP를 구한 평가지표 입니다.
2. 일단 이전에 indoor dataset에서는 사용하지 않던 평가지표이고 같은 outdoor dataset인 nuScenes에서도 보지 못했던 평가지표인지라 .. 제 생각에는 Waymo에서 데이터셋을 평가하기 위해 적용한 평가지표인 것 같습니다.
안녕하세요. 리뷰 잘 읽었습니다.
monocular detection에서는 3d bbox를 2d 이미지에서 먼저 예측한다고 하셨고 여기서 주된 어려움이 depth를 임의적으로 예측할 수밖에 없다고 하셨는데 구체적으로 어떻게 depth를 임의적으로 예측하는 것인가요 ? 또, point decoration fusion 방법론인 pointpainting은 semantic score을 어떻게 추출하는지 궁금합니다. .
2d와 3d 사이 align을 맞추기 어려운 이유를 설명해주신 부분에서 여러 개의 point cloud가 하나의 voxel에 모아지기 때문에 한 voxel grid 내의 point가 모두 동일한 중요도를 가진다고 할 수 없다고 하셨는데 이것이 align을 맞추기 어려운 이유와 어떤 관련이 있는지 잘 이해가 되지 않기에 .. 추가 설명 부탁드리겠습니다.
감사합니다.
안녕하세요 ! 리뷰 읽어주셔서 감사합니다.
첫번째 질문 같은 경우에는 본 논문은 두 모달리티의 fusion 방식을 보기 위해 읽은 것이기 때문에 monocular에서 이전 방법론들에 대한 명확한 답변을 드릴 수는 없지만 .. point decoration 방법론에서 semantic score을 추출하는 방식은 2D semantic segmentation 방식에서 추출한 score을 그대로 가지고 오는 것으로 알고 있습니다. 나머지 부분들에 대해서는 추후 follow up을 하게 되면 다시 알려드리도록 하겠습니다.
두 번째 질문은 본래 raw level의 포인트 클라우드와 이미지 픽셀 사이의 align을 맞춘다는 것이 서로 대응하는 일대일 대응을 찾는 것이었는데, 본 방법론처럼 voxel 형태로 변환할 경우에 한 복셀 그리드에 하나의 포인트만이 존재하는 것이 아니라 여러개의 포인트가 있고, 각 포인트마다 대응하는 픽셀이 있을터인데 복셀 그리드 기준으로 대응점을 찾으려고 하면 한 그리드 안에서 서로 다른 대응관계가 발생하기 때문에 이러한 일대다수의 대응 관계가 misalign을 발생시킬 수 있는 것으로 이해해주시면 좋을 것 같습니다.