이런 분들께 이 논문을 추천드립니다.
- Weakly Supervised Temporal Action Localization의 최신 방법론이 궁굼하신 분
- Weakly Supervised Learning에 Text label을 Training signal로 사용하는 방식에 흥미가 있으신 분
- 상호 보완적인 objective를 가진 두 모델의 collaborative learning을 수행하는 과정에 흥미가 있으신 분
이 논문을 깊게 이해하려면 다음 지식이 필요합니다.
- CAS를 활용한 W-TAL의 근본 중 하나인 BaSNet 방법론 (리뷰)
- CLIP에 대한 이해 (CLIP 리뷰 파트 1, 파트 2)
- GloVe 텍스트 임베딩에 대한 지식 (ratsgo님 블로그)
안녕하세요. 백지오입니다.
열다섯 번째 X-REVIEW는 Weakly Supervised Temporal Action Localization 관련 논문입니다. CLIP에서 사용한 것과 유사하게, natural language text label을 training signal로 사용한 것이 인상깊은 논문인데요. 리뷰 시작하겠습니다.
Temporal Action Localization (TAL)은 영상에서 어떤 액션의 종류와 액션이 발생하는 시간을 예측하는 task입니다. TAL을 지도학습하기 위해서는 어떤 영상에 등장하는 액션의 종류와 액션의 시간을 annotation 해줘야 하기 때문에, annotation 비용이 큰 task에 속하는데요. 이러한 한계를 극복하기 위하여, 액션이 등장하는 시간에 대한 annotation 없이 TAL을 수행하는 Weakly-Supervised Temporal Action Localization (WTAL)이 제안되게 됩니다.

WTAL은 몇 년간의 연구를 거쳐 많이 발전해 왔으나, 근본적으로 영상에 등장하는 액션의 temporal annotation이 없기 때문에 액션의 발생 시간을 정확히 예측하지 못하고, 실제 액션보다 더 넓은 영역을 액션으로 예측하는 over-complete 문제나 실제 액션보다 더 적은 영역을 액션으로 예측하는 incomplete 문제가 흔히 발생하였습니다.
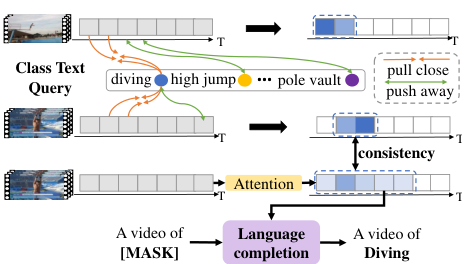
이 논문에서는 over-complete를 최소화하기 위하여 클래스 내부의 차이(inter-class difference)를 늘리는 discriminative objective와 incomplete를 최소화하기 위하여 클래스 간 integrity를 증가시키는 generative objective 두 가지 상호보완적인 objective를 함께 수행하는 신경망 통해, WTAL을 개선하고자 하였습니다.
먼저, Discirminative Objective로는 Text-Segment Mining (TSM)을 제안하였는데, 이는 액션의 설명 텍스트와 유사한 세그먼트를 찾는 task로, 액션의 설명 텍스트와 유사한 세그먼트를 찾아야 하기 때문에 영상과 최대한 유사한 세그먼트들에 집중하여 over-complete를 줄일 수 있었습니다.
또한, 액션의 설명 텍스트에서 빈칸으로 주어지는 액션을 맞추는 Video-text Language Completion (VLC)를 제안하였는데, 이를 통해 의미론적으로 최대한 많은 세그먼트로부터 정보를 찾아내어 액션을 맞춰야 하기 때문에, incomplete를 줄일 수 있었습니다.
이렇게 제안된 두 가지 task를 상호보완적으로 학습시킴으로써, THUMOS14와 ActivityNet1.3에서 SOTA를 달성하였으며, 이 방법은 다른 방법론들에 쉽게 적용할 수 있다는 강점이 있다고 합니다.
저자들이 제안하는 본 논문의 contribution은 다음과 같습니다.
- text information을 통해 WTAL을 boost 한 첫 사례이며, 기존 SOTA 모델에 적용할 수 있는 방법임
- text information을 잘 사용하기 위해, inter-class difference를 키워 over-complete를 줄이는 discriminative objective와 intra-class integirty를 늘려 complete temporal boundary를 찾는 generative objective 제안
- 여러 실험에서 이 방법이 기존 방법들을 앞선다는 것을 보이고 ablation study 수행
The Proposed Method
Overall Architecture
$N$개의 untrimmed video $\{ V_j \}^N_{j=1} $와 video-level category labels $\{ y_j \}^N_{j=1}$이 주어질 때, 각 영상은 다시 segment의 집합으로 $V = \{ v_t \}^\mathcal{T}_{t=1}$과 같이 나눌 수 있습니다. ($\mathcal T$는 비디오에 포함된 세그먼트의 개수)
모델은 각 세그먼트들을 3D CNN에 입력하여 RGB feature $X_r \in \mathbb R ^{\mathcal{T} \times 1024}$와 Optical Flow feature $X_f \in \mathbb R ^{\mathcal{T} \times 1024}$를 생성하여 예측을 수행하고, 추론 단계에서는 액션의 종류 $c_i$, 액션의 시작과 끝 시간 $s_i, e_i$, confidence score $conf_i$로 구성된 시퀀스 $\{ c_i, s_i, e_i, conf_i \}$를 생성하게 됩니다.

먼저, 영상의 RGB와 Optical Flow를 사전학습된 3D 합성곱 신경망 백본 모델에 입력하여 feature를 추출합니다.
그다음 TSM을 먼저 살펴보면, 각 액션 클래스의 라벨에 학습 가능한 prompt를 붙여 text description을 만들고, 이를 텍스트 인코더에 입력하여 Class Text Query를 생성해 줍니다. Video-Text matching 모듈을 통하여 각 세그먼트들과 text query들을 비교하여 Query Responses를 생성하고, 앞서 생성한 feature를 사용해 어텐션 가중치를 생성하여 background 세그먼트들을 억제하도록 합니다.
한편, VLC에서는 추출된 feature를 FC Layer에 입력하여 video feature embedding을 얻은 후, “A video of [mask]” 형태의 텍스트 프롬프트에서 masking 된 부분을 복원합니다. 이때, 어텐션을 통해 feature에서 불필요한 세그먼트들을 억제(=mask 복원에 필요한 세그먼트들은 남기기)하도록 합니다.
이러한 두 가지 objective에서 필요한 프레임을 선별하는 어텐션 가중치가 self-supervised constraint $\mathcal L_{con}$ 손실함수를 통해 유사해지도록 하여 학습을 진행합니다.
Text-Segment Mining (TSM)
TSM은 주어진 텍스트 쿼리와 최대한 유사한 세그먼트들을 찾아야 합니다.
비디오 임베딩 모듈은 다른 WTAL 모델과 유사하게 1D Conv와 ReLU, Dropout으로 구성됩니다. CO2Net에서 사용한 방법과 유사하게 RGB / Optical Flow feature를 합쳐 video feature $\mathbf X \in \mathbb R^{\mathcal T \times 2048}$를 얻은 후, 이를 입력 삼아 video feature 임베딩 $\mathbf X_e \in \mathbb R^{\mathcal T \times 2048}$을 얻습니다.
한편, CO2Net, HamNet과 동일한 구조를 통해 어텐션 가중치 $\text{att}_m \in \mathbb R^{\mathcal T\times 1}$를 얻습니다.
$$\text{att}_m = \sigma (\mathcal A (\mathbf X))$$
텍스트 임베딩 모듈은 각 액션 라벨 텍스트(“Long Jump”, “Pole Vault” 등)에 learnable prompt를 붙여 각 라벨에 대한 description 텍스트를 생성하고, 이를 임베딩합니다. 이때, 텍스트 임베딩 모듈의 입력 $Lq$는 다음과 같습니다.
$$ \textbf L_q = [\textbf L_s; \textbf L_p; \textbf L_e]$$
$\textbf L_s$는 랜덤 하게 초기화되는 [START] 토큰, $\textbf L_p$는 $N_p$ 길이의 learnable textual context이고 $\textbf L_e$는 GloVe로 임베딩된 action label text feature입니다. 이때, $C+1$ 번째 추가 background class의 임베딩은 0으로 초기화합니다.
이렇게 생성된 $\textbf L_q$를 트랜스포머 인코더 $trans()$ 형태의 텍스트 임베딩 모듈에 입력하여 텍스트 쿼리를 생성합니다.
$$\mathbf X_q = trans(\textbf L_q), \mathbf X_q \in \mathbb R^{C+1)\times 2048}$$
Video-text feature matching은 주어진 각 클래스에 대한 텍스트 쿼리들과 의미론적으로 유사한(semantic-related) 비디오 세그먼트의 임베딩을 매칭합니다. 먼저, 비디오 임베딩 feature $\mathbf X_e$와 텍스트 쿼리 $\mathbf X_q$의 내적을 통해 segment-level video-text similarity matrix $\mathbf S \in \mathbb R ^{\mathcal T\times (C+1)}$를 얻습니다.
이때, background suppression-based method를 참고하여, 어텐션 가중치 $\text{att}_m$을 통해 background segment의 response를 억제한 $\bar S = att_m * S$를 얻습니다. 여기서, TSM의 어텐션 가중치는 텍스트 쿼리와 무관한 background 세그먼트를 억제하는 역할을 하게 되는 것을 기억해야 합니다.
마지막으로 top-k multi-instance learning을 통해 matching loss를 계산합니다. $j$번째 액션 카테고리에 대하여 video-level similarity $v_j$와 $\bar v_j$를 생성해 줍니다.
$$ v_j = \max_{l\subset \{ 1, \cdots , \mathcal T \} \\ |l| = k } \frac{1}{k} \sum_{i\in l} S_i(j)$$
$l$은 $j$번째 텍스트 쿼리에 대하여 가장 유사도가 높은 top-k 세그먼트의 인덱스를 가지고 있는 집합이며 $k$는 선택된 세그먼트의 개수입니다. $v_j, \bar v_j$에 각각 소프트맥스를 적용하여 video-level similarity score $p_j, \bar p_j$를 얻습니다. video-text category matching의 postivie score가 1에 수렴하고, negative score가 0에 수렴하도록 학습을 BCE Loss를 통해 학습을 진행합니다.
$$\mathcal L_{mil} = -(\sum^{C+1}_{j=1} y_j \log (p_j)+\sum^{C+1}_{j=1}\hat y_j \log (\hat p_j))$$
Video-Text Language Completion
VLC는 video description의 빈칸을 채워야 하기 때문에 텍스트와 연관된 비디오 세그먼트들을 최대한 포괄적으로 참고하여야 합니다.
비디오 임베딩 모듈은 앞선 모듈과 같은 video feature $\mathbf X \in \mathbb R^{\mathcal T \times 2048}$을 입력받아, video feature embedding $\mathbf X_v \in \mathbb R^{\mathcal T \times 512}$를 만드는 FC layer로 구성됩니다.
video feature를 이용하여 앞선 모듈과 같은 방법으로 VLC 어텐션 가중치를 생성합니다. 이때, VLC의 어텐션 가중치는 텍스트 복원에 위하여 액션과 의미론적으로 관계가 있는 세그먼트들을 최대한 보존하는 역할을 수행합니다.
$$ \text{att}_r = \sigma (\mathcal A (\mathbf X))$$
텍스트 임베딩 모듈은 “a video of [mask]”를 GloVe로 임베딩한 후, FC layer를 거쳐 $\hat{\mathbf X}_s\in \mathbb R^{M\times 512}$로 만듭니다. 이때, $M$은 문장의 길이입니다.
트랜스포머 reconstructor는 문장의 1/3을 랜덤 하게 마스킹하고, 이를 복원합니다. 먼저, 트랜스포머 인코더는 foreground video feature $\mathbf F \in \mathbb R^{\mathcal T \times 512}$를 생성합니다.
$$\mathbf F = E(\mathbf X_v, att_r) = \delta(\frac{\mathbf X_v \mathbf Wq (\mathbf X_v \mathbf W_k)^\top}{\sqrt D_h}* att_r)\mathbf X_v \mathbf W_v$$
$E()$는 트랜스포머 인코더, $\delta$는 소프트맥스 함수를 의미합니다. 이어서 트랜스포머 디코더는 마스킹된 텍스트 임베딩 $\hat{\mathbf X}_s$, foreground video feature $\mathbf F$, 어텐션 가중치 $\text{att}_r$를 입력받아 multi-modal representation $\mathbf H \in \mathbb R^{M\times 512}$를 생성하여 마스킹된 문장을 복원합니다.
$$ \mathbf H = D(\hat{\mathbf X}_s, \mathbf F, \text{att}_r)$$
$i$번째 단어 $w_i$의 확률 $\mathbf P \in \mathbb R^{M\times N_v}$는 다음과 같습니다.
$$\mathbf P(w_i | \mathbf X_v, \hat{\mathbf X}_{s[0:i-1]}) = \delta(FC(\mathbf H))$$
VLC는 아래와 같은 reconstruction loss로 학습됩니다.
$$\mathcal L_{rec} = -\sum^M_{i=1} \log \mathbf P (w_i| \mathbf X_v, \hat{\mathbf X}_{txt[0:i-1]})$$
여기에 추가로, 추출된 positive area들을 강화하기 위해 contrastive loss를 도입합니다. $\text{att}_r$로 추출된 postivie area들이 영상 전체나 $1-\text{att}_r$로 추출된 negative area보다 문장과 연관성이 있어야 하기 때문에, $\text{att}_r$ 대신 $1$이나 $1-\text{att}_r$을 이용해 계산된 $\mathcal L_{rec}$에 해당하는 $\mathcal L_{rec}^e$, $\mathcal L_{rec}^n$을 이용하여 아래 completion loss를 정의합니다. ($\gamma$는 하이퍼 파라미터입니다.)
$$\mathcal L_c = \max(\mathcal L_{rec} – \mathcal L_{rec}^e + \gamma_1, 0) + \max(\mathcal L_{rec} – \mathcal L_{rec}^n + \gamma_2, 0)$$
Self-supervised Consistency Constraint
앞서 설명한 것처럼, TSM의 어텐션은 텍스트와 유관한 것이 명백한 foreground 세그먼트들에 집중하고, VLC의 어텐션은 텍스트를 복원하는데 조금이라도 의미가 있는 세그먼트들에 집중합니다. 이러한 두 가지 어텐션이 유사해지게 함으로써, 결과적으로 over-complete와 incomplete 없이 정확히 액션에 맞는 temporal boundary를 만드는 어텐션 가중치를 얻을 수 있습니다.
$$\mathcal L_{con} = MSE(att_m, \psi(att_r)) + MSE(att_r \psi(att_m))$$
$\psi$는 gradient를 삭제하는 함수입니다.
Model Training and Inference
최종적으로 모델 학습에는 앞서 설명한 손실함수들을 합친 손실함수를 사용합니다.
$$\mathcal L = \mathcal L_{mil} + \alpha \mathcal L_{rec} + \beta\mathcal L_c + \lambda \mathcal L_{con}$$
추론 단계에서는 임계값 이상의 스코어를 갖는 category들에 대하여 proposal들을 만들고, 선택된 액션 클래스들에 대하여 class-agnostic 한 action proposal들을 어텐션 가중치의 임계값 연산을 통해 얻습니다. 마지막으로 연속된 proposal들을 조합하여 예측을 생성합니다. 이때 confidence score는 AutoLoc을 통해 계산합니다. 마지막으로 중복되는 예측들을 NMS로 제거하여 최종 예측을 생성할 수 있습니다.
Experiments
데이터셋은 THUMOS14 데이터셋과 ActivityNet1.3 데이터셋을 사용하여 진행되었으며, THUMOS14에서 제공되는 200개의 validation 영상과 ActivityNet에서 제공되는 10,024개의 학습 영상을 학습에 사용하였으며, 각 데이터셋의 test 영상으로 평가를 진행하였다고 합니다.
평가는 IoU 임계값에 따른 mAP를 이용하여 진행하였으며, 특성 추출에는 TV-L1 알고리즘으로 생성된 Optical Flow와 Kinetics 데이터셋에서 사전학습된 I3D 신경망을 사용하여, 파인튜닝 없이 RGB와 Optical Flow feature를 추출하였습니다.
학습은 Adam optimizer를 사용하였고, THUMOS14에서는 lr=0.0005, weight_decay=0.001에서 5천 iteration, ActivityNet에서는 lr=0.00003에서 5만 iteration 학습을 진행하였습니다. 하이퍼 파라미터는 $\gamma_1 =0.1, \gamma_2 = 0.2$를 사용하였고, THUMOS에서는 $\alpha=1.0, \beta=1.0, \lambda=1.5$를 사용하고 ActivityNet에서는 $\alpha=1.0, \beta=1.0, \lambda=0.25$를 사용했습니다. 구현은 우분투 18.04에서 파이토치 1.8로 진행했다네요.
Comparison with the SOTAs
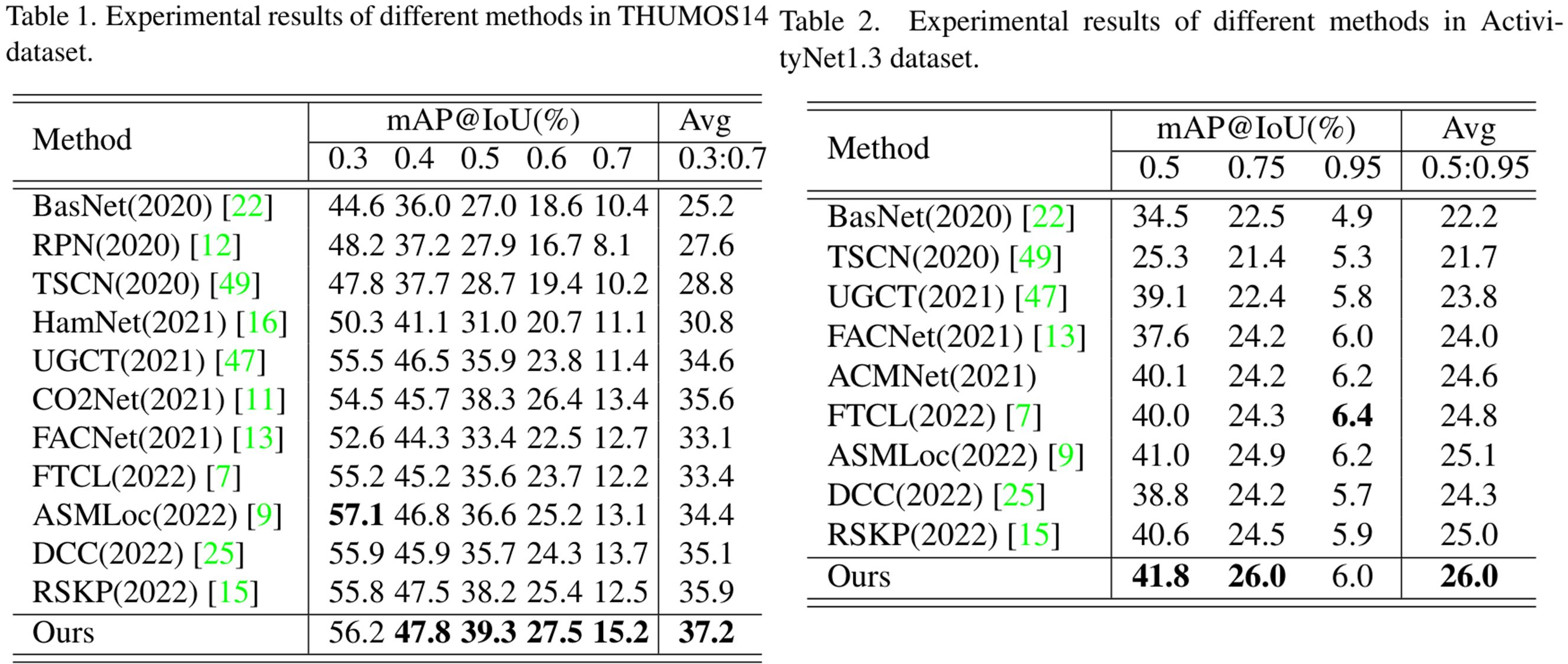
기존 W-TAL 방법들과 비교하였을 때, 저자들이 제안한 방법은 두 데이터셋 모두에서 SOTA를 달성할 수 있었으며 특히 높은 IoU threshold에서 높은 성능을 보였습니다. (이는 temporal localization이 한층 정확하게 수행되었음을 의미합니다.)
Ablation Study

먼저 각 모듈의 효과를 확인하기 위한 실험입니다. TSM에서 video-text matching 대신 단순한 합성곱 계층을 통한 예측을 수행한 Baseline과, 여기에 추가적으로 VLC 브랜치를 추가하고($\mathcal L_{rec}$), VLC와 TSM이 유사한 어텐션 가중치를 갖도록 한 Baseline + $\mathcal L_{rec}$ + $\mathcal L_{con}$, 여기에 video-text language complements 구조를 더한 Baseline + $\mathcal L_{rec}$ + $\mathcal L_{con}$ + $L_c$, 최종적으로 TSM까지 더한 TSM + $\mathcal L_{rec}$ + $\mathcal L_{con}$ + $L_c$를 비교하였는데요. 각 요소가 추가됨에 따라 성능이 향상되는 것을 확인할 수 있습니다.
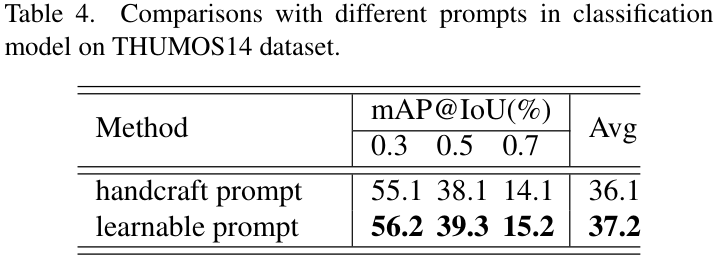
이어서, TSM에 학습 가능한 프롬프트 대신 “a video of [CLS]” 형태의 handcraft 프롬프트를 사용하여 학습 가능한 프롬프트의 효과를 확인하였는데, 학습 가능한 프롬프트가 확연히 좋은 성능을 보이고 있습니다.

TSM과 VLC가 생성한 어텐션 가중치가 유사해지게 만드는 cosistencty constraint loss $\mathcal L_{con}$으로 어떤 손실함수를 사용하느냐에 따른 성능 비교입니다. 개인적으로 왜 MSE를 사용하였나 궁금했는데, MSE가 가장 좋군요.

VLC의 Language Reconstructor로 사용되는 모델에 따른 성능 비교입니다. 트랜스포머가 가장 좋은 모습입니다.

VLC에서 사용하는 복원해야 할 target 문장의 템플릿에 따른 성능 차이입니다.
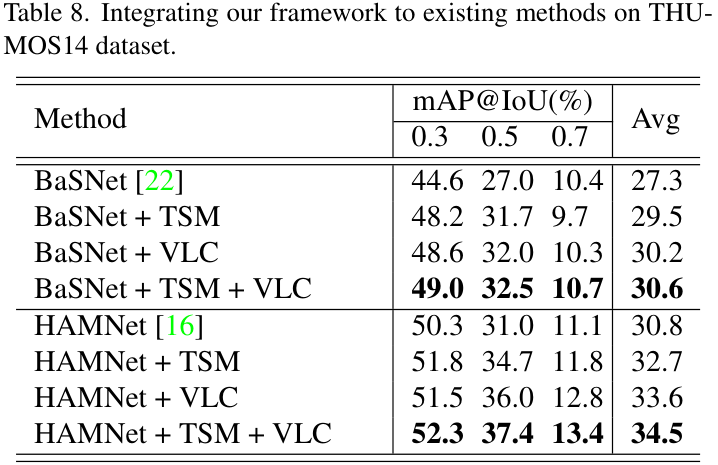
기존의 W-TAL 모델들에 제안하는 구조를 적용한 결과 실험입니다. TSM과 VLC를 추가함에 따라 성능이 향상되는 것을 확인할 수 있습니다.
Qualitative Analysis

정성적인 결과입니다. cherry-pick이야 했겠지만 참 깔끔하게 예측이 잘 되는 모습이네요.
Conclusion
저자들은 W-TAL의 over-complete 문제에 잘 대처할 수 있도록 distinct 한 세그먼트들에 집중하는 TSM과 incomplete 문제에 잘 대처할 수 있도록 최대한 많은 세그먼트들에 집중하는 VLC 두 상반된 task를 수행하며 모델이 균형 잡힌 어텐션 가중치를 학습하도록 하여 W-TAL의 temporal annotation 부재로 인한 localization의 품질 저하 문제를 개선하였습니다.
이를 통해 THUMOS14와 ActivityNet1.3에서 SOTA를 달성할 수 있었으나, 저자들은 결론에서 이 모델이 TSM과 VLC를 수행하는 각 브랜치를 같이 학습시켜야 하기에 모델 크기가 두 배가량 커지는 한계를 밝히고 있습니다.
논문이 제안하는 방법이 단순하기도 하고, 서술이 깔끔해서 읽기 좋은 논문이었다는 생각이 듭니다. SOTA와의 비교보다 Ablation Study에 집중한 것도 인상 깊었습니다.
CLIP의 등장 이후로 꼭 CLIP을 사용하지 않더라도 text를 training signal로 쓰는 연구가 수행되고 있는데, 그러한 연구 중 하나로 심플하면서도 좋은 연구였던 것 같습니다.
감사합니다.
안녕하세요 백지오 연구원님 리뷰 잘 읽었습니다.
Clip은 원래부터 이미지-텍스트 페어로 학습해서 두 임베딩 스페이스가 동일하다고 볼 수 있을 것 같은데요.
Glove같은 경우에는 학습 기반이 아니라서 Glove로 생성한 텍스트 임베딩과 비디오의 I3D의 임베딩의 유사성이 떨어질 것 같습니다.
물론 Text Encoder를 태우기는 하겠지만, 이러한 표현력 차이에서 발생하는 문제는 없을까요?
이 task를 보면서 항상 드는 생각이라, 백지오 연구원님의 생각을 듣고싶습니다.
안녕하세요. 이광진 연구원님.
좋은 댓글 감사합니다.
정확한 것은 결국 실험을 통해 정량적인 비교를 해봐야 알겠지만, 제 생각을 말씀드리자면 CLIP에 비하여 결론적으로 각 모달 임베딩의 유사성이 크게 떨어지지는 않을 것이라 생각합니다.
그 이유는, CLIP은 학습 데이터에 존재하는 4억 개의 다양한 텍스트가 각각 구별력을 갖도록 text를 임베딩해야 하는 반면 본 모델은 4억 개에 비하면 훨씬 적으며 그 다양성도 action으로 한정된 C개의 action label에 대한 임베딩만을 수행하면 되기 때문에, transformer를 이용한 임베딩과 linear projection을 수행하는 CLIP과 달리, GloVe로 임베딩한 후 projection을 수행하는 text encoder와 learnable prompt 만 학습시켜도 충분히 구별력 있는 text embedding들을 만들 수 있을 것으로 보이기 때문입니다. (더불어 본 모델의 text encoder 역시 크기는 작지만 transformer 형태이기에, 구조적으로 CLIP과 그리 다른가 싶기도 합니다.)
확실하게는 본 모델의 text encoder가 생성하는 C개의 text label embedding이 서로 구별력이 있는지 유사도를 찍어보면 어느 정도 경향을 알 수 있지 않을까 싶습니다.
감사합니다!