본 논문은 2023년 arXiv에 올라온 논문입니다. Mixup과 같은 augmentation 방법론을 다양한 task에 적용을 고려한 논문을 찾다가 읽게 되었는데, 소개를 시작해보겠습니다.
What’s the starting point of your idea?
본 논문을 읽으면서 느낀점은 새로운 인사이트의 제시라기 보다는, Mixup idea의 일반화를 통한 해당 방법론의 지평의 확장의 성향이 강하다는 것이였습니다. 다만 object detection을 위한 다양한 고찰이나 실험이 기대한 바에 비해 부족했는데요, 제목 그대로 “for object detection” 이라기 보다 object detection으로 시작해 다양한 다른 영역으로 아이디어를 확장하는 데, 주목한 논문이라 느낍니다 즉, 제목의 “for beyond”에 강세를 주는게 좋겠네요.
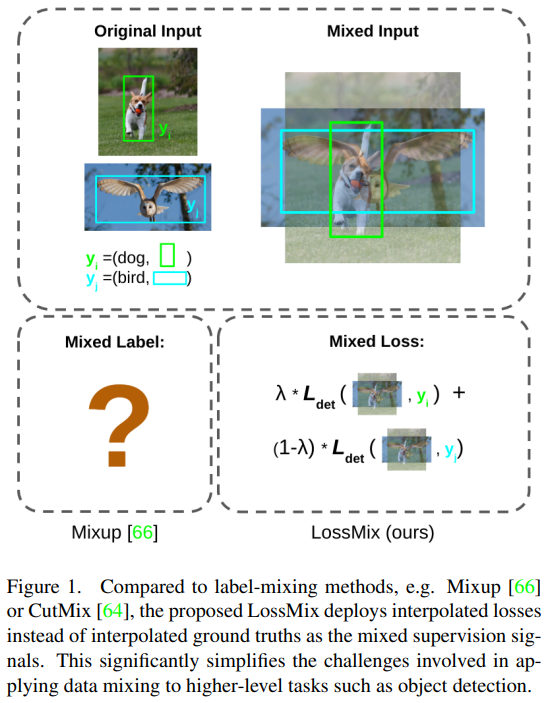
아마도 Figure1에서 볼 수 있듯이 논문의 시작은 “그 좋다는 Mixup을 Object detection에는 어떻게 붙이지?” 인 것 같습니다. 왜 object detection에 mixup을 붙이지 못할까요? 아래의 수식은 Mixup의 모든것을 두 줄로 표현합니다.
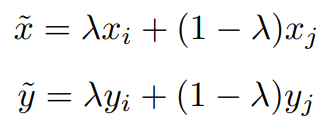
mixup은 input과 target의 쌍을 생성하여 interpolation을 진행합니다(input-target dual interpolation). 그러나 object detection task에서 y는 classfication처럼 모든 example이 동일한 형식을 취하지 않습니다. 따라서 dual interpolation이 불가능하죠. 예를 들어 강아지 2마리가 있는 이미지 A와 고양이 한마리가 있는 이미지 B를 하나의 쌍으로 하여 augmentation한 이미지를 생성한다고 합시다. 이때 이미지A의 ground truth bounding box인 YA는 {(loc1_a, cls1_a), (loc2_a, cls2_a)} YB는 {(loc1_b, cls1_b)}입니다(loc는 bounding box 위치, cls 는 해당 인스턴스의 카테고리). 인스턴스 갯수부터 다르기 때문에 가중치합을 통한 통합 라벨을 구하기가 쉽지 않습니다. 몇몇 방법론은 이러한 어려움 때문에 label 을 가중치 통합하지 않고 uniform한 결합(uniform strategy)을 이용했다고 합니다. 위의 예시라면 AB 통합 이미지에 대한 라벨로 {(loc1_a, cls1_a), (loc2_a, cls2_a), (loc1_b, cls1_b)}를 모두 사용하는 방식이죠. 이러한 방식의 문제점은 0(혹은 1)에 가까운 결합상수를 통한 mixed image에 대해 대응하지 못한다는 것입니다. 이러한 데이터 혼합에 대한 예시가 아래에 있는데, 두 이미지 중 하나에 이미지에 치중하여 생성된 augmented image에 대해 가중치 페널티 없이 모든 bounding box를 uniform한 중요도로 학습하면, 과도하게 noise를 추가한 것처럼 작동할 수 있다는 것입니다. 실제로 좌측과 우측의 이미지에서는 사람 혹은 비행기의 형체를 인식하기 어렵습니다. 이러한 경우에 각 인스턴스에 대한 bounding box를 ground truth로 학습하면 noise로 작동할 확률이 크겠죠.

이러한 문제점을 해결하기 위해 논문에서는 conceptual한 framework인 Supervision Interpolation(SI)를 설계하고 이러한 개념 안에서 새로운 target interpolation 방식인 LossMix를 소개합니다. 본 논문을 간단하게 정리하자면 Task-free하게 mixup을 적용하기 위한 새로운 interpolation 방안으로, 기존의 label mix를 lossmix로 확장. 제안한 설계를 활용하여 mixup을 다양한 task에 대한 적용하여 해당 augmentation방법의 다양한 테스크에 미칠 수 있는 영향력을 실제로 보인 논문으로 정리하고 싶네요.
아쉬운 점은 mixup을 object deteaction에 적용을 하기 위해 논문에서 말하는 방식으로 이미 적용을 하고 있었고(하지만 좋은 베이스라인 레퍼런스가 되겠네요), object detection task에 대한 다양한 고찰, 예를 들면 이미지에 포함된 각각의 바운딩 박스에 대한 중요도, localization task 에 mixup augmentation이 미치는 영향에 대한 다양한 실험은 없었습니다. 대신 domain adaptation에 까지 확장하여 해당 분야 SOTA인 CVPR2022의 Adaptive Teacher를 뛰어넘는 훌륭한 다른 실험이 있는 좋은 논문이기도 했습니다. 여러분은 해당 논문을 Mixup이 Classification 뿐 만 아니라 다른 Task에도 충분히 적용될 수 있는 범용성있는 아이디어임을 대신 증명해준 논문으로 기억하셨다가, 필요하실 때 참고하시면 되겠습니다.
Introduction to the proposed method.
논문에서 제시하는 아이디어는 2개 입니다: Mixup 과 같은 augmentation 방법론을 일반화하기 위한 conceptual framework 인 Supervision Interpolation(SI)와 실질적으로 제시하는 input-target interpolation 방식인 LossMix. 자세한 소개는 아래에서 진행하겠습니다.
- What is SI(Supervision Interpolation)
SI는 실제 제안하는 메커니즘인 lossnet을 이해하기 위한 일종의 conceptual framework입니다. SI는 Mixup 뿐 만 아니라 기존의 object detection에 적용되었던 uniform strategy를 모두 통틀어서 설명하도록 문제 정의를 했습니다. supervision 메커니즘에서 새로운 데이터를 학습하려면 입력과 출력에 대한 데이터쌍이 있어야 합니다. Mixup의 경우 input에 대한 interpolation과 이에 대한 pair로 label interpolation 결과를 학습에 이용합니다. 하지만 확장된 LossMix의 경우 interpolated input에 대한 pair로 loss 의 interpolation 을 진행합니다. 이런 방식의 input-target dual interpolation을 통해 mixup 아이디어를 재해석 할 수 있습니다. 즉, mixup은 제안하는 SI 의 세분화된 접근법 중 하나인 것입니다.
- What is the LossMix
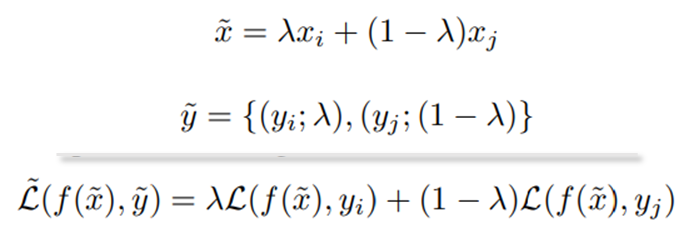
어? 놀라지 마십쇼. Mixup 의 코드 구현[Link]을 아시는 분은 당황하실 수 있습니다. 제가 그랬으니까요. 우선 수식에 대해 간단히 짚어드리겠습니다. mixup의 경우 (mixup의 수식)에서 보셨듯이 input에 대해 가중치 합으로 interpolation 하여 하나의 example을 생성합니다. 이후 label에 대해도 동일한 메커니즘으로 interpolation을 진행해 새로운 example pair (mixed x, mixed y)를 생성합니다. 반면 lossmix는 label을 직관적으로 합쳐 하나의 pair를 만들지 않습니다. 대신 각 라벨에 대한 가중치를 loss에 적용합니다. 즉, loss mix의 label은 수식처럼 ground truth와 해당 라벨의 중요도 가중치 λ를 갖고있습니다. 이후 Backpropagation 연산을 할 때 해당 가중치를 반영한 mixed loss를 이용하는 것 입니다. 나이스한 생각의 전환입니다. 그런데 몇몇 분들이 당황할 것이라 예측한 이유는 mixup의 실제 코드가 이미 loss에 대한 가중치 합을 통해 구현이 되기 때문입니다. 논문 아이디어 그대로 mixed label을 만들어서 Multi label classification 형식으로 해결하는게 아닙니다. 하지만, 언어가 생각을 제한하듯 코드 구현과 별개로 mixup에서 제시한 아이디어는 label을 직접 혼합하는 방법으로, 이러한 상태에서는 다양한 테스크에 대한 확장이 어렵겠죠 (맨 위에 예시를 보인것 처럼요). 본 논문은 이러한 기존 접근법의 한계를 수면 위로 직접 끌어내 해체한 것입니다. 아마 저를 포함한 몇몇 야매-object detection with mixup 구현들이 이미 lossmix에서 제안한 방식으로 설계된 이유가 mixup의 코드 구현 때문인 것 같습니다. 그러나 코드를 보지 않는다면 확장 아이디어가 생각나지 않는게 당연할지도 모릅니다.
Experiments to prove the idea.
본 논문의 제목(Mixup for Object Detection and Beyond)에 나와있듯이 다양한 task에 대한 실험을 진행했습니다. 확장은 object detection과 domain adaptation에 대해 진행되었습니다. classification에 대한 적용은 기존 mixup과 완전히 동일한데요, 그래서 해당 테스크에 대한 실험은 진행하지 않았습니다. 다음으로 object detection에 대한 확장은 다음과 같이 단순하게 detection loss에 가중치합을 적용하여 구현되었습니다. object detection 실험은 Faster R-CNN을 기반으로 진행되었습니다.
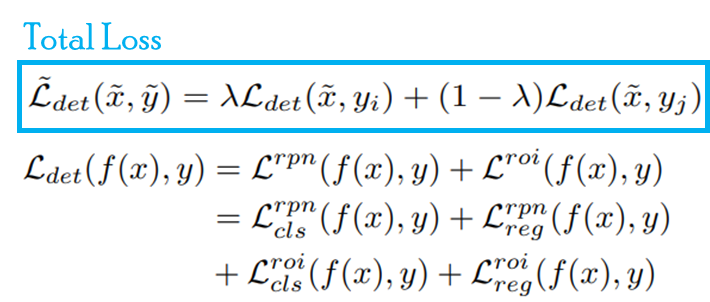
마지막으로 DA에 대한 확장 방식을 말씀드리겠습니다. DA를 위한 프레임워크는 Adaptive Teacher(AT)를 기반으로 구현되었으며, 그 결과 베이스가 된 AT를 개선한 성능을 보였습니다. 프레임워크가 student-teacher 구조를 갖고있는데, student를 학습한 뒤, 학습 파라미터를 EMA 방식으로 teacher와 공유하는 형식입니다. 이때 두 모델, student와 teacher는 source domain의 labeled data로 학습한 파라미터로 초기화하였다고 합니다. source domain data만을 이용하여 학습하는 초기 단계(Warm-up)에서는 (source×source), (source×target) 혼합 데이터를, 이후 teacher model의 pseudo label을 이용하는 Adaptation phase에서는 (source×source), (source×target), (target x target) 혼합 데이터를 생성하여 학습을 진행하였습니다. 학습 방식은 object detection과 같이 loss에 대한 가중치 혼합한 최종 loss를 이용합니다.
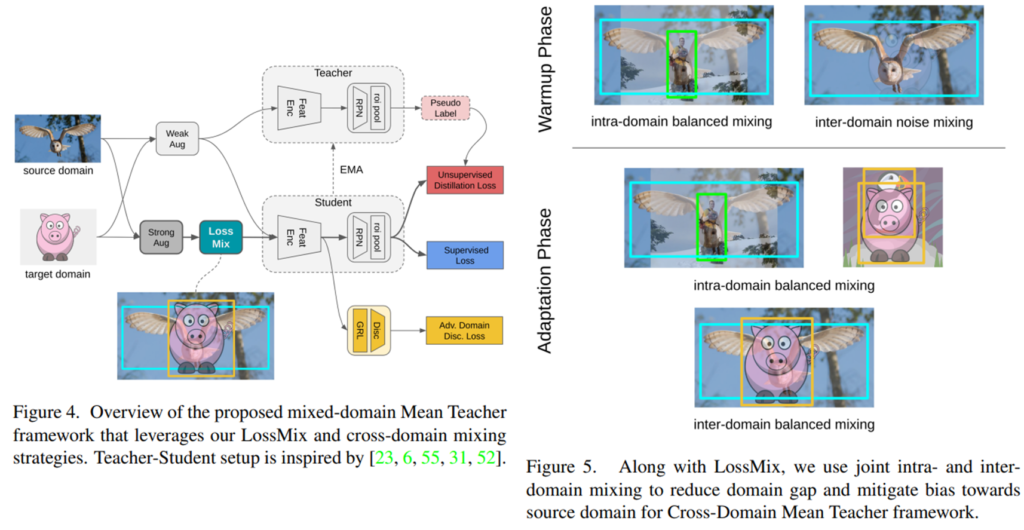
마지막으로 실질적인 성능 테이블 입니다. 성능 비교는 SI 방식의 augmentation을 적용하지 않은 baseline과 uniform strategy으로 interpolation 한 결과, Noise는 두 이미지 A, B를 mix 하되 작은 가중치로 하여 noise로 작용하도록 하는 전략이라고 합니다.(DA 분야에서 주로 사용하는 방식이라고 하는데, 해당 방법론과의 비교가 필수적이였는 가에 대해서는 저도 의문점이 있습니다.) 대부분의 지표에서 제안하는 방식이 효과적임을 보였고, augmentation 적용을 한것이 baseline에 비해 더 성능이 좋다는 점이 인상깊습니다. 아래는 데이터에 대한 혼합 가중치 λ에 대한 실험인 alpha=1.0인 beta 분포를 따를때 가장 성능이 좋다고 합니다.
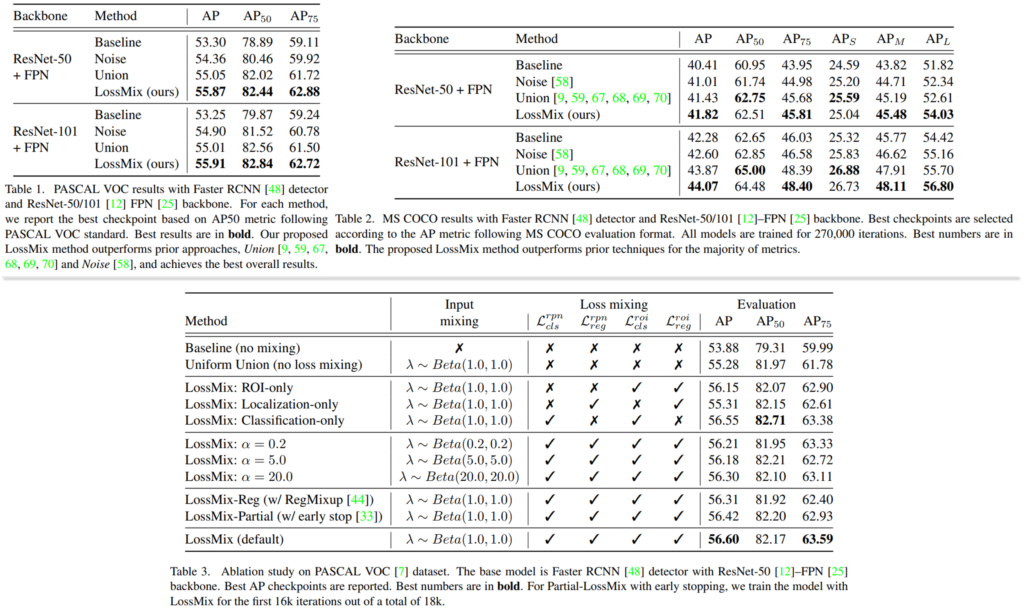
다음은 domain adaptation 결과인데요, 다양한 DA 방법론과도 비교를 진행했습니다. 특히 최신 방법론인 Adaptive Teacher(AT, CVPR2022)와 비교해 SOTA를 달성함을 보였습니다.
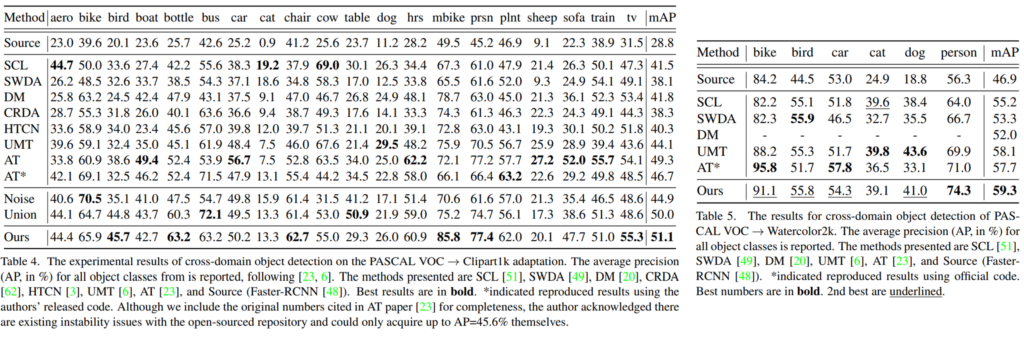
본 논문으로 mixup 방법론의 확장 가능성을 확인할 수 있었습니다. mixup 적용시 해당 논문을 참조하면 좋겠네요. 이상입니다.
안녕하세요. 좋은 리뷰 감사합니다.
Mixup도 알고 있고, Object detection 제목에 이끌려 읽었는데도 Loss 관련된 내용이 주를 이루어 생각보다 이해에 어려웠던 것 같습니다.
질문은 Object detection에서 Mixup augmentation을 사용하고자 한 저자의 진정한 의도가 궁금한데요. 단순히 Classification 측면에서의 성능 향상을 위한 Mixup을 detection에 활용하고자 한 시도인지 의문이 듭니다. 최근 읽은 논문에서는 Object detection 시 Mixup의 방식을 취하되, 오히려 Detection의 여전한 문제로 남은 Truncated, Occlusion, Small object의 성능 향상을 위해 Mixup을 취한 이후 Hard-label을 붙이는 방식을 사용했다는 저자의 말이 있는데, 본 논문에서 저자가 Mixup을 사용하고자 했을 때, 그것이 Localization 시에도 도움이 될지에 대해서도 궁금합니다. (성능이 오른 것이 단순 Classification에 도움이 되었기 때문은 아닐지..)
안녕하세요 이상인 연구원님
해당 논문을 공유해주시면 감사하겠습니다 ㅎㅎ 저한테 도움이 될 것 같아서요.
우선 기존 mixup에서 학습을 위한 pair 생성 시 interpolation 된 x를 학습하기 위해 interpolation한 y를 생성하여 학습을 하였습니다. 본 논문은 학습을 위해 interpolation 된 x를 위한 직접적인 ground truth를 생성하는 것이 아닌, loss 에 가중치를 적용하여 학습을 진행합니다.
해당 접근 법을 통해 이론상 loss 가 있는 모든 deep learning에 mixup을 적용할 수 있으며 추가적인 ablation study는 부족하지만 localization에도 해당 가중치를 통한 보간(interpolation)이 적용되었습니다.
classification task에만 mixup을 적용한 결과와의 비교가 없어서 명확히 localization에 도움이 되는지 확인할 수 없는 점은 아쉽지만, domain adaptation 결과를 통해 mixup이 다양한 task에 도움이 될 수 있다는 점을 해당 논문에서 얻어가시면 좋을 것 같습니다.
안녕하세요 황유진 연구원님 좋은 리뷰 감사합니다.
한 가지 질문이 있는데, object detection에서 mixup을 적용할 때 box 크기와 위치에 대한 가중치는 적용이 되나요?
안녕하세요 홍주영 연구원님
box 위치와 크기 등에 대해 직접적으로 가중치 연산으로 interpolation 된 ground truth를 만들지는 않습니다. 다만, localization loss 에 두 쌍의 이미지에 적용된 가중치 합 연산을 하여 mixup을 확장한 것으로 이해해주시면 됩니다.
감사합니다.
안녕하세요 황유진 연구원님 좋은 리뷰 감사합니다.
결국 LossMix는 mixup을 일반화한 것으로, 이미지에는 가중합을 적용하여 augmentation하되, 라벨 값에 대해서는 loss에서 별도의 가중치를 각각 부여하여 계산하는 것으로 이해하였습니다.
그렇다면 실험 부분에서 baseline을 제외한 나머지 세 method(Noise, Union, LossMix)는 결국 \lambda값만 달라진 ablation study로도 해석할 수 있을 것 같은데요, union이 \lambda=0.5라는 것은 이해하였으나 나머지 두 방법론은 어느 정도의 가중치로 계산된 것인지 궁금합니다.
안녕하세요 천혜원 연구원님
우선 union을 lambda를 이용한 확장으로 생각하려면 lamdba는 1입니다.
noise의 경우 mix 하는 데이터에 대해 0에 가까운 매우 작은 가중치를 이용하며 해당 정보를 노이즈로 간주하도록 학습합니다. 이는 DA 분야에서 주로 사용하는 augmentation 방법으로 DA 비교 실험을 위해 진행한 것으로 이해했습니다.
정리하자면 union은 lamdba = 1, noise ~= 0 으로 이해할 수 있으나, union은 x에 대한 결합 가중치와 y에 대한 결합 가중치가 동일하지 않기 때문에 혼란이 발생할 수 있습니다. 따라서 union에 대해 굳이 lamdba 합으로 이해하기 보다는, 가중치(lamdba)를 고려하지 않고 단순히 결합한 접근법으로 이해하시는 것이 좋을 듯 합니다.