최근에 distilation 기반 모델 경량화 논문을 읽으면서 모델의 knowledge를 학습에 활용하는 방법론에 관심이 생겼는데요, 논문 서베이를 진행하다 Label distribution Training이라는 task가 있어 한 번 공부해볼 겸 리뷰를 진행해보려고 합니다.
Introduction
논문에서 다루는 task는 facial expression recognition, 다른 표현으로는 facial emotion recognition 이미지(영상)에서 사람의 얼굴 표정에 묘사된 감정 표현을 인식하는 task입니다. 단일 이미지, 혹은 영상 클립이 하나 주어졌을 때 사람의 얼굴을 crop해서 그 얼굴이 어떤 감정을 표현하는지 알아내는 것이라고 이해하시면 될 것 같습니다.
이러한 FER은 다양한 application에 사용된다고 하는데요, 예를 들어보자면 Human-Computer Interaction에서 user의 상태를 판단하는 데 사용하거나, 교육 분야에서는 학생의 frustration을 detect하여 e-learning 컨텐츠를 학생에 맞게 조정하여 experience를 증진시키는 데 사용될 수 있습니다. 의학 분야에서는 pain detection으로 환자의 경과를 모니터링하기도 하며 운전자 보조 분야에서는 운전자의 졸음이나 집중도, 감정 상태 등을 파악할 수 있다고 합니다.
연구실의 감정 인식 과제와 연관지어 생각해보면 영상 데이터에 나타난 얼굴을 감지하여 해당 인물의 감정 상태를 파악하는 것과 비슷하다고 할 수 있습니다.
최근에 FER은 주로 딥러닝 기반의 모델로 추출한 visual semantic feature를 분류하는 방식으로 진행됩니다. 그러나 이 논문의 저자들은 딥러닝 기반의 FER모델들이 과도한 parameter와 연산량을 가지며, 이는 실제 application에 적합하지 않다고 지적합니다.
FER모델을 real-time에 잘 동작하도록 최적화(경량화)하려는 시도는 기존에도 활발히 이루어졌으며 temporal 측면에서는 [Miao et al. 2019], [Koujan et al.2020]이, spatial 측면에서는 mobilenet이나 shufflenet과 같은 경량 백본을 사용한 연구 등이 있었습니다. 그러나 경량 네트워크 자체가 작은 크기의 모델로 인해 이미지의 표현을 충분히 학습할 수 없다는 한계점이 있고, wild 환경에서는 occlusion, pose variation가 발생하기 때문에 real world에서의 FER모델 성능은 좋지 못했습니다.
computational overhead를 줄이는 것과 성능 향상의 딜레마를 해결하기 위해 저자들은 경량 네트워크를 특징 추출과 학습 전략이라는 두 가지 관점에서 개선한 EffecientFace를 제안합니다.
특징 추출 관점에서는 channel-spatial modolated와 locality-aware light Network를 제안하여 backbone에서 이미지의 local한 특징과 global한 맥락을 잘 파악하도록 하였으며 실험을 통해 FER 모델의 성능이 향상된 것을 확인할 수 있습니다. 그러나 무시할 수 있을 정도의 compitatonal overheads가 발생하였습니다.
학습 방법 관점에서는 Label Distribution Learning을 FER에 적용할 것을 제안하였습니다. 대부분의 감정은 여러 기본 감정들이 복합적으로 조합되어 발생합니다. 예를 들면 찡그린 얼굴 이 disgust로 라벨링 되어 있다고 할 때, 라벨은 disgust로 표시되어 있지만 분노, 슬픔 두려움 등 부정적인 감정이 복합적으로 포함되어 있다고 보는 것이죠. [그림 2]는 real-world이미지를 분류 모델에 통과시킨 예측값, 즉, sofrmax output을 나타내며 여러 감정에 대한 확률값이 복합적으로 나타나는 것을 볼 수 있습니다. 이렇듯 이미지에 따라 여러 감정 분포가 발생할 수 있는데요, 특히 real world에서는 이미지 각각에 항상 다른 감정 분포가 나타나게 된다고 합니다.

따라서 FER모델의 성능을 향상시키기 위해 단일 라벨로 학습시키지 않고 Lable distribution training을 진행하였습니다.
각 모듈에 대한 자세한 설명은 아래에서 진행하도록 하고 일단 저자들이 밝힌 논문의 contribution을 소개하고 넘어가도록 하겠습니다.
Contribution
- wild 환경에서 강인하게 동작하는 경량 FER모델인 EfficientFace를 제안하였다. EfficientFace는 적은 파라미터 수와 연산량을 가지며, feature extraction과 training-strategy관점에서 설계되었다.
- local-feature extractor and a channel-spatial modulator를 설계하여 모델이 local facial feature와 global-salient feature를 학습할 수 있도록 하였으며, 이미지의 label distribution을 생성하는 LDG모델을 통해 LDL학습을 진행하였다.
- 실험을 통해 occlusion과 pose variance에 대한 강인성을 보였으며, RAF-DB, CAER-S, AffectNet-7데이터셋에서 sota를 달성하였다.
Method
EfficientFace는 논문에서 제안하는 CNN기반의 FER네트워크로, 모델의 computational overhead를 줄이기 위해 경량 네트워크의 sota 모델인 ShuffleNet-V2를 backbone으로 사용하였고, 여기에 2가지 모듈을 추가하여 아래의 [그림3]과 같이 EfficientFace를 설계하였습니다.
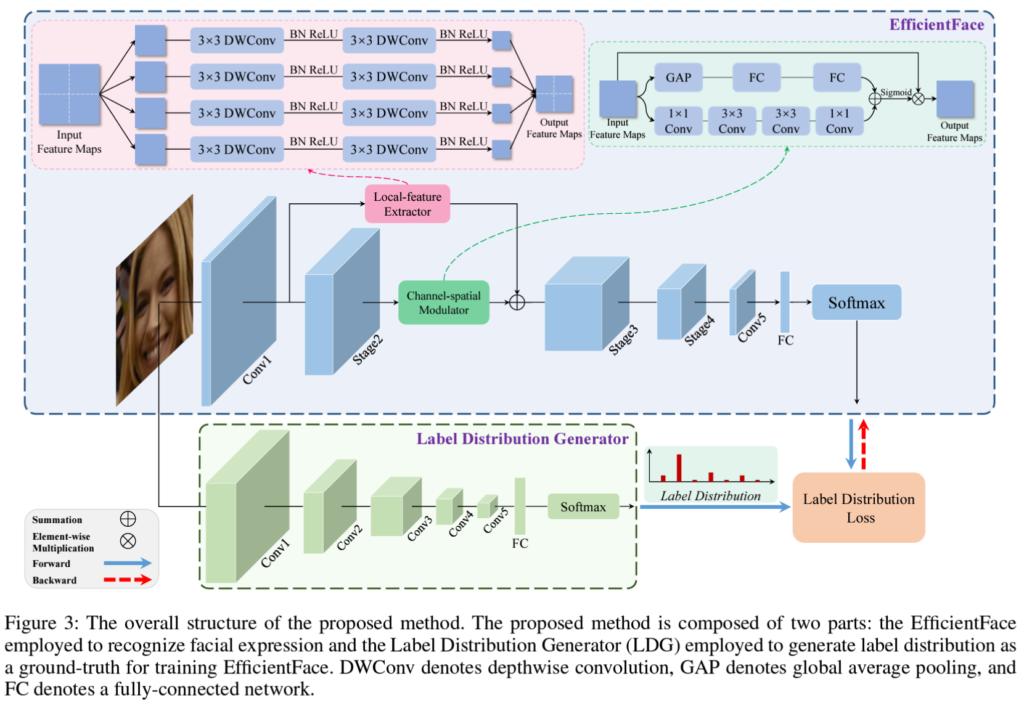
대략적인 pipeline을 먼저 설명드리자면, 얼굴이 crop된 [224, 224, 3]이미지를 입력하면, EfficientFace를 통해 감정을 예측하게 됩니다. 그리고 아래의 pretrained Label Distribution Generator를 통해 이미지의 감정 분포를 추출합니다. 마지막으로 감정 분포로 EffecientFace를 학습시키는 것입니다.
먼저 EffecientFace의 두 모듈에 관한 설명을 진행하고, LDL을 설명드리도록 하겠습니다.
Channel-Spatial Modulated and Locality-Aware Lightweight Network
FER에 관한 연구 중 [Li et al. 2019c]와 [Wang et al. 2020b]에서는 얼굴의 감정을 인식하는 데 local한 특징이 중요하게 작용한다는 것을 밝혔는데요, 그러나 저자들은 해당 연구들이 facial landmark를 바탕으로 수행되었기 때문에 비효율적이라고 지적하였습니다. FER을 수행하기 전에 이미지를 전처리하는 과정에서 face이미지의 특징을 바탕으로 정해진 landmark의 위치를 먼저 찾는 수고를 들여야 하기 때문인데요, 따라서 저자들은 raw 이미지에서 직접 작용하는 local-feature extractor를 제안하였습니다.
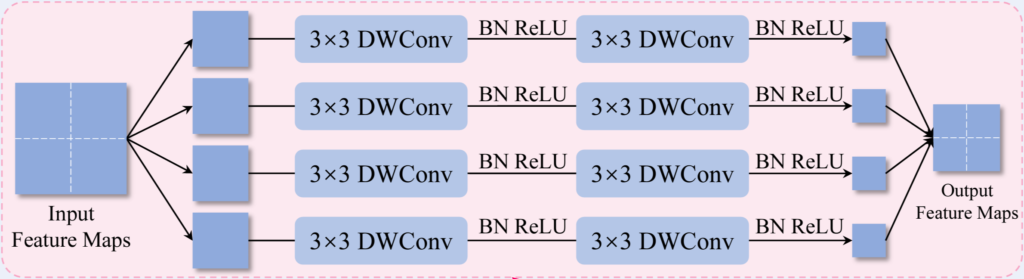
Local feature extractor의 구조는 위의 그림과 같습니다.
ShuffleNet-V2의 Conv1에서 추출한 low level feature map을 4개의 patch로 분할한 뒤 각 patch에 각각 3\times 3depthwise conv를 태워주게 됩니다. 여기서 conv가 아닌 depthwise conv를 사용한 이유는 연산량을 줄이기 위해서라고 합니다. 다음으로는 각 patch를 본래의 위치에 맞게 concat합니다. 크기가 H’/2 \times W’/2\times C’인 4개의 patch를 H’ \times W’\times C’로 합쳐주는 것이죠. 논문에서 4개로 분할된 patch는 감정과 관련된 표현이 존재하는 단위에 해당합니다.
다음으로는 global 정보를 고려하기 위한 channel-spatial modulator를 제안하였습니다.
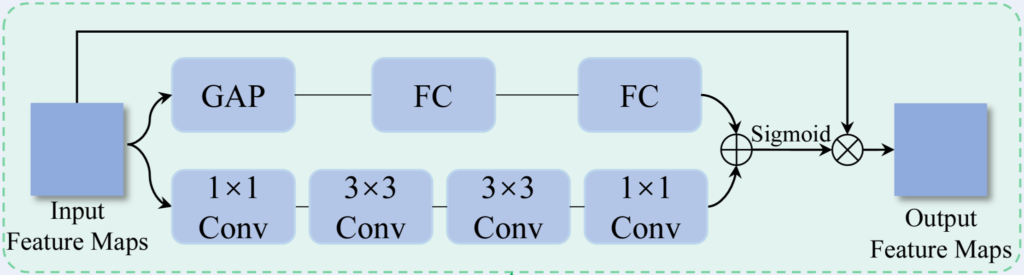
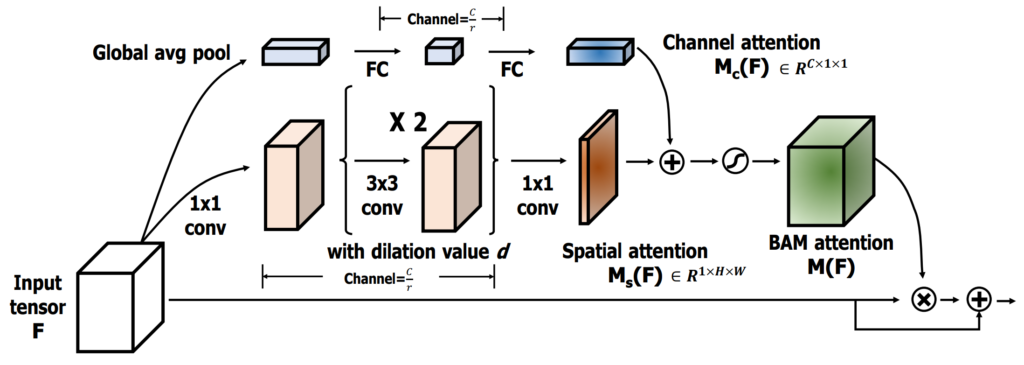
위 그림이 channel-spatial modulator의 구조인데요, 사실상 아래 그림에 나타난 BAM의 구조를 그대로 가져왔습니다. Input으로 H\times W\times C형태의 가 입력되었을 때 두 개의 parallel branch에서 각각 channel attention과 spatial attention을 생성하는데요, Global Average Pooling과 두 개의 FC를 사용하여 1\times 1\times C 크기를 가지는 channel attention M_c를 만들고, conv 연산을 통해 H\times W\times 1의 spatial attention M_s을 생성한 뒤 M_c + M_s에 sigmoid를 취해 input에 element-wise를 취해주게 됩니다.
Constructing Label Distribution and Loss Function

대부분의 일반 감정들은 basic감정들이 복합적으로 얽혀있습니다. 예를 들면 찡그린 얼굴 같은 경우 라벨은 disgust로 표기되어 있지만 해당 데이터는 분노, 슬픔 두려움 등 부정적인 감정이 복합적으로 포함되어 있다고 볼 수 있다는 것이죠. 이에 학습 시 [0 1 0 0]과 같이 하나의 라벨로 학습을 진행하는 것이 아닌 이미지에 포함된 복합적인 감정 정보를 함께 학습시키고자 하였습니다. 이를 Label Distribution Learning(LDL)이라고 하며 학습 시 GT를 [0 0.8 0.2 0]과 같이 데이터의 정답에 해당하는 1번 class 뿐 아니라 다른 라벨의 정보도 함께 학습시키는 방식을 의미합니다.
이를 위해 입력 이미지에서 label distribution을 생성해주는 네트워크를 제안하였는데요, 이것이 위 그림의 LDG에 해당합니다. LDG는 pretrained된 분류 모델을 사용하며, 학습 도중에는 freeze되어 여기서 출력된 softmax output을 정답값으로 main 모델을 학습하게 됩니다. knowledge distilation에서 teacher network의 knowledge와 비슷한 맥락이라고 이해하셔도 좋을 것 같습니다.
loss는 CrossEntropy를 사용하였으며, 수식으로 나타내면 아래와 같습니다.
\mathcal{L}=-{1\over N\times c}\sum^{N-1}_{i=0}\sum^{c-1}_{j=0}d^i_j\log{(\tilde d^i_j)} \tag{1} 샘플의 개수가 N이면, \tilde d는 EffecientFace의 예측값이고, d는 위와 마찬가지로 LDG가 생성한 label distribution입니다. 따라서 위의 [수식1]은 batch가 n이고 class의 개수가 c인 CE와 동일한 구조이며, 일반적인 classification task와 다른 점은 정답에 해당하는 d^i_j값이 0또는 1이 아닌 softmax 출력값이라는 차이가 있습니다.
Experiments
Ablation Studies
Effectiveness of each component of EfficientFace
먼저 EffecientFace에 추가된 local-feature extractor, channel-spatial modulator의 효용성을 알아보기 위한 ablation을 진행하였습니다. 이 실험은 LDL를 포함하지 않고 단일 라벨로 supervised learning을 진행한 결과를 리포팅하였으며, baseline은 ShuffleNet-V2 사용하였습니다.
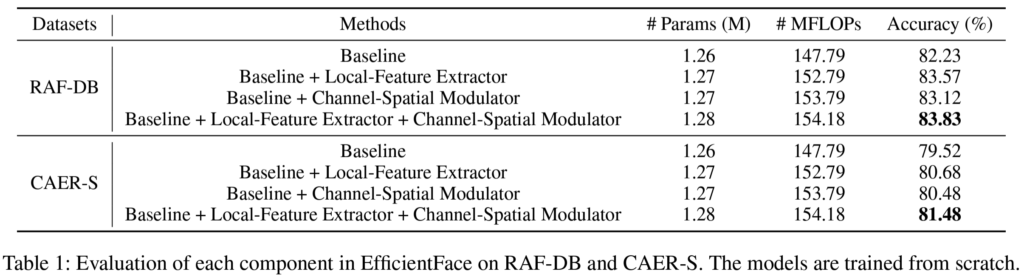
baseline모델이 local-feature extractor, channel-spatial modulator를 붙여가면서 실험을 지행하였고 그 결과는 [표1]과 같습니다. 두 모듈 모두 depthwise conv로 이루어졌기 때문에 baseline에 추가했을 때 약간의 파라미터 증가만이 발생했음을 언급하였습니다. 개인적으로 이 논문에서 경량화를 시도한 부분은 새로 추가한 모의 conv연산을 depthwise conv로 진행하였다는 부분인 것 같으며, standard CNN과의 비교가 없어 아쉬웠습니다.
local feature extractor를 추가했을 때는 각각 1.34, 1.16%의 정확도 향상이 발생했으며 channel spatial modulator를 추가했을 때는 0.89, 0.96%의 정확도 향상된 것을 확인할 수 있습니다.
논문에서는 두 모듈을 추가하였을 때 성능 향상이 발생한 이유로 baseline feature에 face의 local feature를 보완함과 동시에 global 한 정보에 attention을 주었기 때문이라고 합니다. 또한 local한 정보와 global한 맥락을 모두 고려함으로써 얼굴 feature의 일관성을 파악하는 데 유용할 뿐 아니라 face에 occlusion이 발생하거나 face의 pose variance에도 강인하게 작용할 수 있었다고 합니다.
Effectiveness of Label Distribution Learning
다음으로는 Label Distribution Learning의 효용성을 증명하기 위해 단일 라벨로 학습을 진행하는 것(Single label learning, SLL)과, label distribution learning을 진행하는 것의 비교 실험을 진행하였습니다.
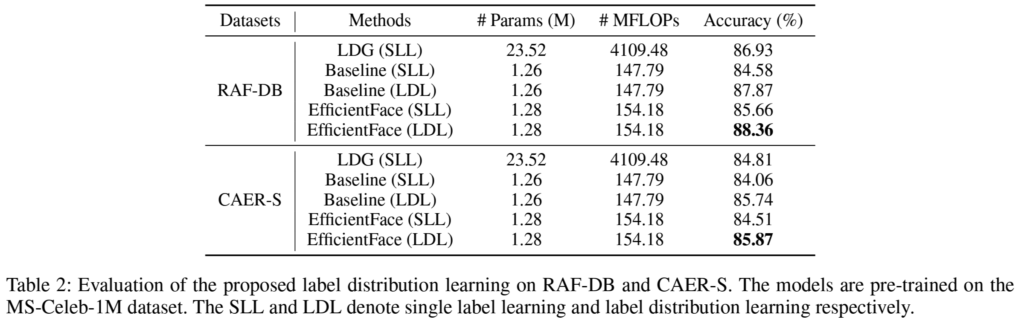
[표2]를 보면 두 데이터셋에서 모두 LDL이 더 좋은 성능임을 확인할 수 있으며, CAER-S는 약 1.3%, RAF-DB는 약 2.7% 향상되었습니다. 논문에서는 이러한 성능 향상의 이유가 single label보다 label distribution이 real-world의 human expression에 가깝기 때문이라고 하였습니다. 얼굴의 표정에는 하나의 감정만 딱 존재하는 게 아니라 기본 감정이 복합적으로 발생하기 때문이라는 것이죠.
Comparison with State of the Arts
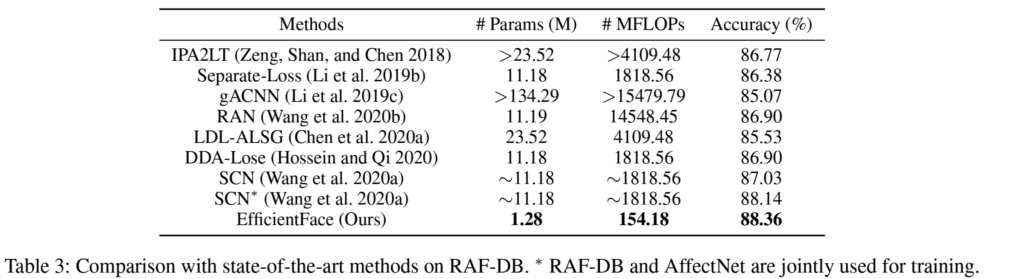
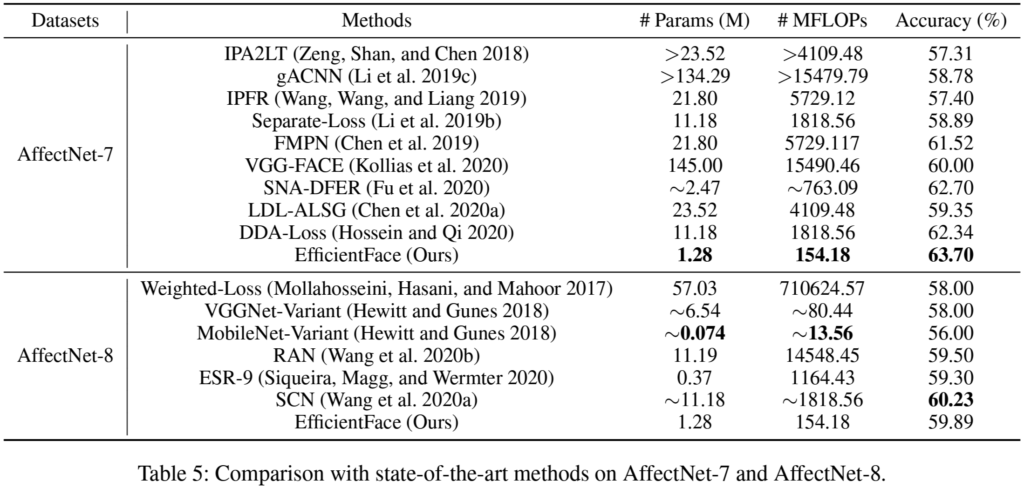
본 실험으로는 RAF-DB, CAER-S, AffectNet-7, AffectNet-8 데이터셋에서 sota 방법론과의 비교를 진행하였습니다.
저자들은 FER분야의 이전 방법론들은 computation overhead에 관심을 기울이지 않았다고 언급하며 동일 세팅으로 실험하여 기존 모델의 파라미터 수와 연산량을 측정하였습니다. [표3]의 MLOPs를 통해 확인 할 수 있듯이 연산량의 차이가 꽤 크게 발생하는 것을 볼 수 있습니다.
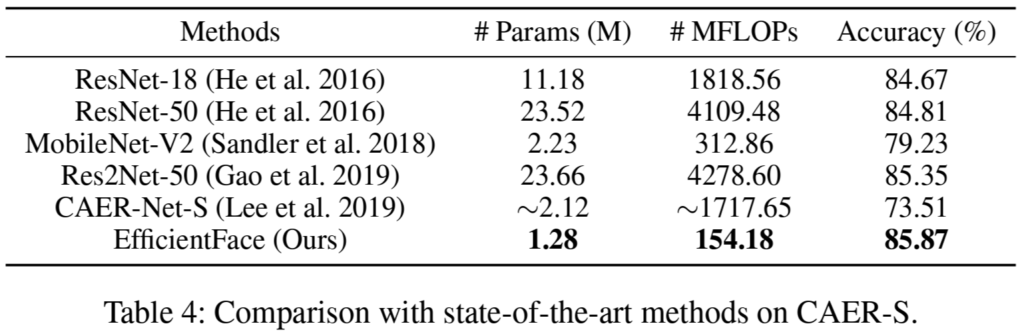
[표4]는 CAER-S데이터셋에서 실험 결과인데요, 해당 데이터셋이 이 논문을 작성할 당시 나온 지 얼마 안 된 데이터라 관련 연구가 Lee et al.2019의 CAER-Net-S뿐이었음을 언급하며, 이에 다른 여러 backbone을 적용하여 실험한 결과를 추가로 리포팅하였습니다. 결론은 EfficientFace가 가장 정확도, 모델 크기와 연산량 측면에서 우수하다는 것입니다.
[표5]에서 EfficientFace가 AffectNet-7에 비해 AffectNet-8 약 4%정도의 성능 드랍이 발생한 것을 볼 수 있습니다. 이에 대해 저자들은 AffectNet-8이 AffectNet-7에 ‘contempt’(경멸)이라는 class을 추가하는 과정에서 annotation에 noise가 많이 포함되어 있기 때문이라고 언급하였습니다. 영상 데이터를 수집하고, 라벨링할 때 ‘contempt’와는 상관없는 이미지를 ‘contempt’라고 라벨링하여 데이터셋 자체에 노이즈 데이터가 추가되었기 때문이라고 하는 것인데요, 아래 [그림4]가 A-8에서 새로 추가된 ‘contempt’ 라벨의 데이터를 무작위로 뽑은 것입니다.

Robustness Under Realistic Occlusion and Pose Variation Conditions
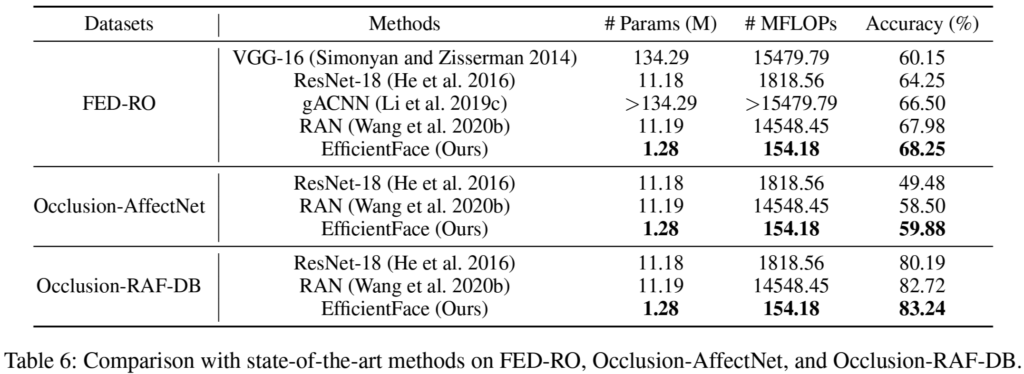
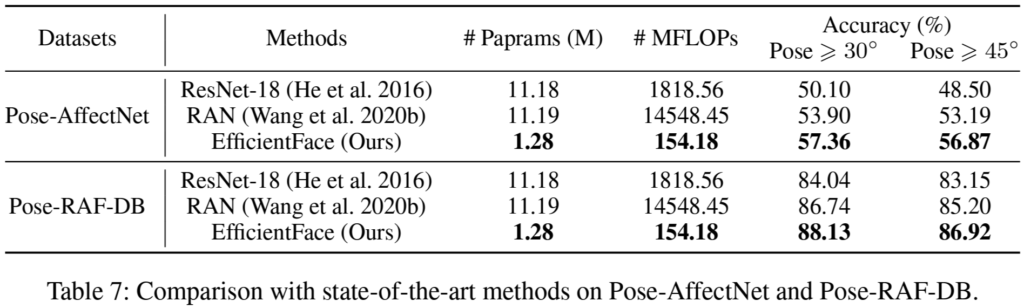
실제 사람을 촬영하여 표정을 통해 감정을 인지한다고 할 때 occlusion이 발생하거나 얼굴의 방향이 정면이 아닌 경우가 발생하므로 각 상황에 따른 데이터에서도 실험을 진행하였습니다. [표6]occlusion, [표7]은 pose variance가 포함된 데이터셋에서의 평가 결과로, 기존 방법론들보다 정확도가 높고, 가벼운 모델임을 확인할 수 있으며, 이를 통해 real-world에서의 강인성을 확인할 수 있습니다.
좋은 리뷰 감사합니다.
감정에 대한 단일 라벨을 사용하지 않고,label distribution을 이용한다면 학습용 데이터를 구축하는 것이 더욱 어려울 것이라 생각됩니다. 본 논문에서는 pretrained 모델을 이용하여 학습용 분포를 구축한 것으로 이해하였습니다. 그렇다면 pretrained 모델의 영향이 클 것이라는 생각이 드는데, 라벨 분포를 만드는 pretrained Label Distribution Generator의 성능은 실험 중 baseline 성능이 되는 것인가요?
또한, 본 논문은 label distribution을 학습하기 위해 다른 모델의 예측 값을 활용하는 것으로 이해하였는데, 그렇다면 그렇게 생성된 label distribution은 신뢰할만한 것인지도 궁금합니다.
안녕하세요 이승현 연구원님. 좋은 댓글 감사합니다.
LDL은 평가에 사용된 각 데이터셋으로 fine tuning된 모델이 아니라 약 100만 장의 large scale 데이터로 pre-train된 것이기 때문에 baseline은 아닙니다. fine-tiuning에 사용된 데이터셋은 각각 약 10,000장, 40,000장, 20만 장의 소규모 데이터셋으로, 데이터의 일반적인 표현을 학습한 모델인 LDG가 입력 이미지의 distribution을 출력하는 것이라고 생각하시면 될 것 같습니다.
일단 학습 및 평가에 사용되는 FER 데이터셋들에 비해 large scale로 학습된 사전학습 모델이기 때문에 어느 정도의 domain이 겹치게 되고, 실제 LDG의 평가 성능과 label distribution에 의한 성능 향상폭을 보았을 때 충분히 신뢰할 만하다고 생각됩니다.
안녕하세요. 리뷰 잘 읽었습니다.
FER에 관한 연구중 Li et al. 2019와 wang et al. 2020에서는 얼굴의 landmark점을 바탕으로 수행되었기에 비효율 적이라며, face 이미지의 특징을 바탕으로 정해진 랜드마크의 위치를 먼저 찾는 수고를 들여야하는 것이 그 이유라고 하셨는데 여기서 landmark가 무엇을 의미하는 것인가요 ?
또, locat feature extractor에서 이전 shufflenet의 conv1에서 추출한 feature map을 4개로 분할한 뒤 conv 거치고 다시 concat해주는데 이 4개의 patch가 감정과 관련된 표현이 존재하는 단위에 해당한다는 것이 헷갈리는데,, 단순히 feature map을 동일한 크기로 4개의 patch로 분할한 것 아닌가요 . . ? 왜 이 patch들이 감정 관련 표현이 존재하는 단위가 되는지 궁금합니다.
마지막으로 label distribution을 생성해주는 네트워크인 LDG는 사전학습한 분류 모델이라고 하셨는데 이 LDG는 어떤 데이터셋으로 사전학습 한 것인가요 ? LDG 학습할 때 입력으로 label distribution이 들어간 것인지 궁금합니다.
감사합니다.
안녕하세요 정윤서 연구원님 좋은 댓글 감사합니다.
facial landmark란 눈, 코, 입, 눈썹, 턱 등 사람의 얼굴에 존재하는 특징점들을 의미하는데요, 주로 아래와 같이 일정한 개수와 지점을 정해놓은 hand-crafted feature를 의미합니다. 아래의 이미지가 facial landmark의 예시입니다.
논문에서는 dividing the feature maps into four patches conforms the action units related to expression.이라고 언급하여 해당 내용을 작성하였는데요, 관련 레퍼런스 없이 저자가 임의로 4분할한 것을 expression의 unit이라고 정한 것으로 이해하였습니다. 입력 데이터셋이 224*224로 얼굴 부분만을 crop한 것이다 보니 각 눈의 형태와 양쪽 입꼬리의 형태 등을 감정을 결정하는 데 주요한 요소로 가정한 것이라고 생각하였는데요… 해당 부분에 대한 설명이 더 이상 존재하지 않아 정확한 답변은 드리기 어려울 것 같습니다.
마지막으로 LDG의 사전 학습에는 MS-Celeb-1M 데이터셋을 사용하였으며, LDG는 단순 분류 모델로써 일반적인 Single label 로 학습되었습니다.
안녕하세요 천혜원 연구원님 몇 가지 질문이 있어 댓글 남깁니다.
1. introduction에 real-time을 다루기에 속도 측면을 다루나 싶었는데요. 해당 논문에는 속도를 다룬 테이블은 리포팅 안하나요?
2. landmark의 개수가 워낙 많고 위치를 다 찾아야 하니 복잡할 수는 있다고 생각이 드는데, 얼마나 차이가 나는지 해당 논문에서 비교실험을 하나요? 다시 말해 저자가 리포팅한 여러 테이블에 landmark 기반의 방법론이 있는지 궁금합니다.
3. 마지막으로 결국 pre-trained의 출력을 soft-pseudo-label로 학습하겠다는 것 같은데요. 이 soft-pseudo-label이 부정확하면 오히려 모델은 전혀 다른 결과를 도출할 것은 뭐 당연할 것 같습니다. 따라서 어떤논문은 이런 soft-pseudo-label의 정확도 혹은 에러율을 보이면서 충분히 신뢰할만하다라는 주장을 하는데, 본 논문에는 그런 리뷰가 있는지 궁금합니다.
+ 추가로 리뷰에 [ 저자명 연도 ] 를 사용하여 레퍼런스를 걸어주셨는데, 해당 논문에서 사용한 레퍼런스를 그대로 사용하면 리뷰만 읽는 독자는 해당 논문이 정확히 어떤 논문인지를 확인하기 어렵습니다. 어떤 제목의 논문인지를 알기 어려워서, 해당 레퍼런스가 필요하다면 명확한 제목을 각주 형식으로라도 달아주시면 좋을 듯 싶습니다.
안녕하세요 홍주영 연구원님 좋은 댓글과 피드백 감사합니다.
1. 저도 real-time application이라는 워딩을 보고 inference time에 대한 결과가 있을 것으로 생각했으나 아쉽게도 속도에 관한 리포팅은 없었습니다.
2. sota방법론과의 비교 중 [표3], [표5]의 gACNN과 RAN모델이 landmark기반 방법론에 해당합니다.
3. LDG의 단독 성능은 86.93%로 리포팅되어 있으나 이와 관련된 별도의 언급은 없이 psudo-label로 학습했을 때의 성능 향상만을 리포팅하고 있습니다.
마지막으로 본문의 레퍼런스에 논문 링크를 걸어두었습니다. 원래 하려고 했었는데 해당 부분이 누락되었던 것 같습니다. 다음부터는 주의하도록 하겠습니다.