안녕하세요. 오늘은 좀 새로운 분야의 논문을 가져왔습니다. 바로 Video Frame interpolation인데요. 요즘 하는 실험과 논문에서 말하는 내용이 도움이 될까 싶어서 읽었는데, 될 것 같기도 하고 안될 것 같기도 하고 코드를 좀 돌려봐야 알 것 같긴 해서 가볍게 다뤄보도록 하겠습니다.
시작하기전에 제가 “불연속”이라는 표현을 계속 사용했는데 길게 풀면 영상 내에서 시간의 흐름에 따라 연속적으로 움직이지 않는 경우를 말합니다. 사실 “부동” 정도로 표현했어야할 것 같은데, 영어로 discontinuous라서 느낌이 안살아서 이렇게 표현했습니다. 참고하고 읽으시면 좋을 것 같습니다.
Introduction
이 논문에서 다루는 video frame interpolation(VFI)는 영상 내의 연속적인 프레임으로부터 중간 프레임들을 생성하는 TASK입니다. (방식의 차이는 있겠지만, 요즘 GPU 회사들에서 게임에도 많이 적용할 만큼 상용화가 많이 된 연구 분야 같네요.) 생성으로 볼 수도 있지만 영상 압축에서도 활용할 수 있는 연구 분야인데요.
많은 이전 연구들은 영상 내의 물체의 움직임에 집중해왔습니다. 하지만 개인방송이나 클라우드 게임 시장이 더 확장되어가면서, 실질적으로 이러한 영상들 안에는 연속적으로 움직이지 않는 요소(로고, 워터마크, 채팅, 제목, 인터페이스 등)이 존재하게됩니다. 따라서 많은 프레임워크에서 이 불연속적인 정보에 강인하도록 학습을 수행하는데요.
본 논문에서는 불연속 정보가 포함된 특이한 영상들만 집중하는 것이 아니라, 움직임의 스펙트럼을 확장하여 연속 정보와 불연속 정보를 함께 효율적으로 처리하는 것이 목표인데요. 논문에서는 3가지 기술을 활용해서 이 문제를 해결합니다.
- Figure-Text Mixing(FTM)을 이용한, 새로운 data augmentation 방식
- Discontinuity map(D-map)이라 부르는, 입력 프레임에서 불연속 픽셀을 추정하는 가벼운 모델
- D-map 학습을 위한 추가 Loss
입니다. 사실 방법론 자체가 그렇게 어렵지는 않습니다. 컨셉도 확실하고, 다양한 방법론에 추가로 붙이는 모듈이라서 모델을 제안하는 것도 아니라서 간단하고 loss도 쉽습니다. 또한 데이터 셋에 변화하는 환경(개인방송 / 클라우드 게임 등)이 모사된 데이터 셋이 없었나봅니다. 그래서 Graphic Discontinuos Motion (GDM) 데이터 셋을 추가로 구성했다고 합니다.
Proposed Approach
프레임 보간 방법론이다 보니 입력으로 두 프레임 I_1, I_2 \in \R^{H \times W \times C}가 들어가게 됩니다. (더 많은 프레임이 입력으로 들어갈 수도 있다고 하네요.) 대부분의 방법론은 이걸 입력으로 중간 프레임 \hat{I}를 네트워크 F를 통해 예측하도록 하는데요. 그래서 정의하면 \hat{I} = F(I_1, I_2)가 되겠죠?
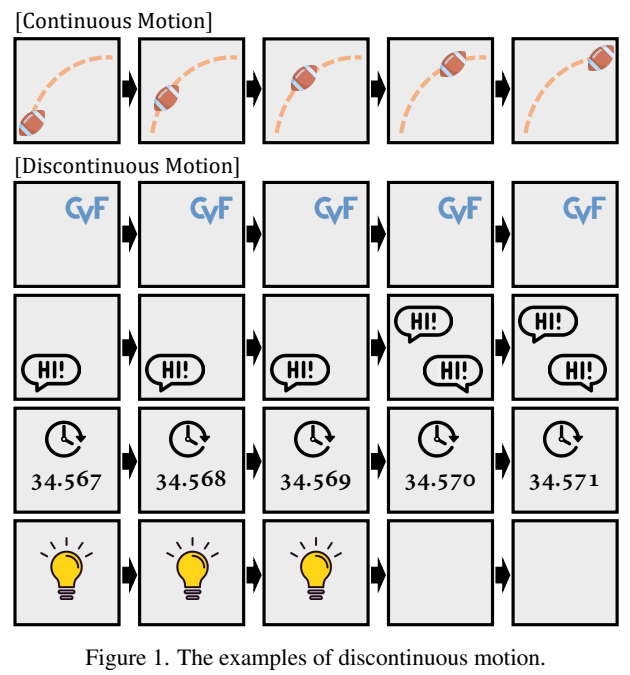
하지만 구조적으로 이런 방법론들은 연속 정보만을 해결하는 것에 집중되어 있는 구조입니다. [그림 1]을 통해, 일어날수 있는 문제점을 고려해보면 불연속적으로 변하는 타이머나 아니면 움직이지 않고 꾸준히 등장하는 로고와 같은 케이스가 존재하는데요. 이러한 경우에 대한 학습 데이터 셋(여기서는 주로 Vimeo90K라는 것을 쓰는데, 이게 연속 정보만 주로 다룬다고 하네요.)이 없기도 하고 다루지 않아서 문제가 생긴다고 합니다. 그럼 이제 문제 정의도 끝났으니 어떻게 해결했는지 보도록 하겠습니다.
Figure-Text Mixing (FTM)
이전 연구에서는 공간축과 시간축에 대한 flip augmentation만 적용되어져 왔는데요. 이 연구에서는 FTM이라고 부르는 새로운 방식을 추가하였습니다. 이건 이제 Figure Mixing(FM)과 Text Mixing(TM)으로 나뉘는데요. 이름을 보시면 아시겠지만… 예상하시는 그 방법들이 맞습니다. 학습은 이렇게 변형한 GT와 원본 GT 사이의 차이를 이용해서 학습을 수행합니다.
Figure Mixing
영상 내에 고정된 물체를 다루기 위해서 임의의 도형을 삽입하는 방법인데요. 모든 프레임에 “같은 위치에 같은 크기”로 넣어줍니다. 불연속적인 정보가 아무래도 부족하기 때문에 임의로 생성해주는 느낌이라고 보시면 될 것 같습니다. 이 방법론이 물체가 연속적으로 움직인다고 하더라도, Edge를 잘 살린다고 하는데…. 이유는 모르겠네요? 정말 이유가 안써져 있어서 잘 모르겠는데, 아마 학습 과정에서 고정된 물체의 형태를 잘 생성하게 되면서 전반적으로 물체들의 표현력이 상승하는 것 같습니다.
Text Mixing
영상에 워터마크나 채팅과 같은 글자들이 종종 등장하는데요. 이러한 텍스트를 불연속 & 연속 움직임에 따라 4가지로 정리했습니다.
- 영상 전체에서 글자의 위치가 고정되어 있을 때
- 이전 프레임에서 존재하지 않았던 텍스트가 다음 프레임에 등장할 때
- 2번의 반대 케이스
- 글자의 위치가 바뀔 때
이렇게 4가지 케이스를 정의하고, 이 케이스들에 따라 augmentation을 수행합니다.
Discontinuity Map (D-map)
[그림 1]에서 등장하는 불연속 정보들은 공통적인 특징을 공유합니다. 바로, “연관된 프레임에서 바로 복사 붙여넣기 하면 프레임 생성이 끝난다”는 특성인데요. 하지만 단순한 이 방식은 문제가 있습니다. 우선, 어떤 프레임을 복사 해야하는지 모릅니다. 프레임 보간의 특성상 앞에서 가져와야하는지 뒤에서 가져와야하는지가 애매하기 때문입니다. 그리고 모델 입장에서는 유사하다고 판단할지언정 [그림 1]의 4번째 예시와 같이 숫자가 변하는 경우에는 보간을 시도하는 것 자체가 잘못되었습니다. 하지만 보다 깨끗한 품질을 얻으려면 어느정도는 앞뒤 프레임에서 가져오는 것이 중요하다고 하네요. (영상 압축에서 새로 압축을 하는 것이 아니라, 이미 압축이 끝난 영역의 패치 정보를 이용하여 끼워넣기 하는 경우가 있는데요. 이 TASK에서도 새로 생성하는 것 보다는 이미 있는 원본 이미지를 끼워 넣는게 시각적으로 더 좋다고 판단하는 것 같습니다.)
따라서 본 TASK에서는 불연속 정보와 연속 정보를 구분하는 1D채널 형태의 Discontinutiy map (D-map)을 추정합니다. 추정 자체는 만약 연속 정보라면 VFI 네트워크에 의해 생성된 것들이고, 불연속 정보라면 이전 프레임에서 복사되어졌다는 정보를 이용하는데요. D \in (0,1)^{H \times W \times 1}이 D-map을 의미한다면, 이 경우에 연속정보로 보간된 프레임은 \hat{I_c} = F(I_1, I_2)와 같이 표현할 수 있습니다.
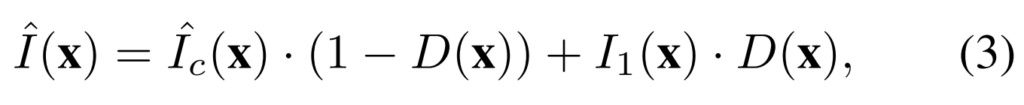
그럼 이제 x \in [1,H] \times [1,W]와 같이 가로&세로 모든 프레임을 지칭한다면 [수식 3]과 같은 연산을 통해서 이 프레임이 연속 정보인지 불연속 정보인지를 계산할 수 있습니다. (생성된 프레임과 원본 프레임 중의 과거 프레임 사이의 일종의 Cross Entropy 연산을 수행한다고 보면 될 것 같습니다.)

실제로는 [그림 3]에서 빨간색 박스로 표시된 영역들이 게임의 UI 들이 불연속 정보이기 때문에 오른쪽 검은색 그림이 D-map의 시각화 결과인데 밝게 표현되고 있는 것을 볼 수 있습니다. 2개의 베이스라인 네트워크에서 공통적으로 드러나는 결과라서 이런 특성은 VFI TASK가 공유하는 특성이라는 것도 알 수 있습니다.
Discontinuity map estimation
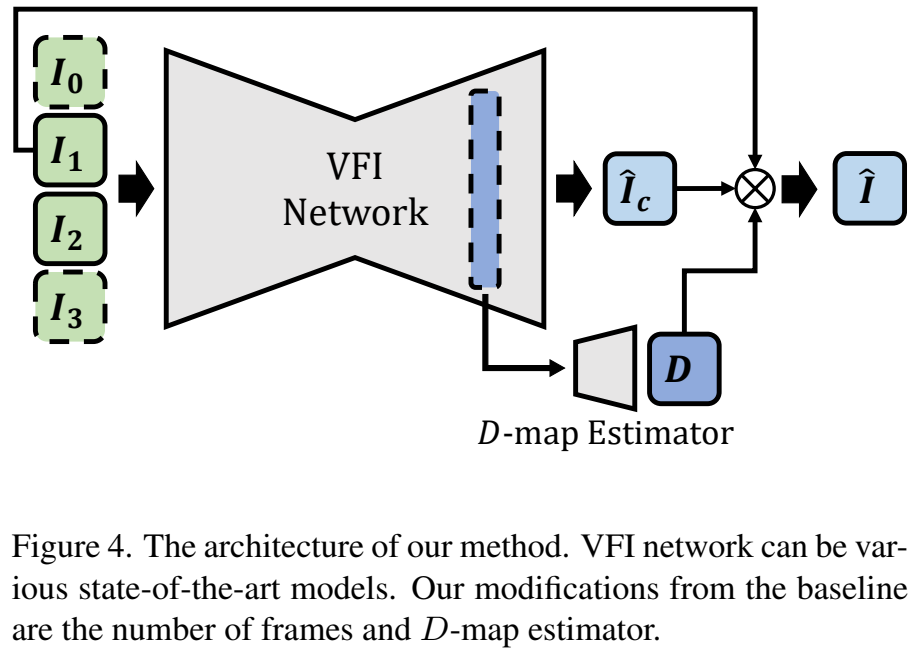
VFI 모델들이 실제로 서비스 되고 있어서 그런지는 몰라도 엄청 간단한 구조를 가지고 있는데요. 보면 그냥 Encoder-Decoder가 끝입니다. 이런 기본적인 구조에서 논문에서 제안하는 D-map을 추정하는 네트워크는 CNN 몇개가 끝인데요. 어떤 모델을 쓰느냐에 따라 최적의 세팅이 달라지는 것 같지만, 기본적으로는 [그림 4]에서 보이는 것과 같이 Decoder의 특정 layer의 ouput을 D-map estimator의 입력으로 하여 D-map을 추정합니다. 추가적으로 단순히 “두 프레임”으로는 이게 변하는지 안변하는지 알 수가 없는 경우가 있는데요. 이를 위해서, 구별하기 위해서 추가 프레임을 입력해줬다고 합니다.
Objective Functions
학습도 엄청 간단한 구조인데요.
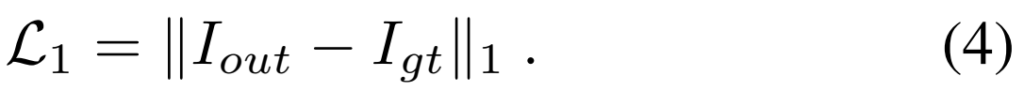
기본적인 VFI의 학습은 [수식 1]이 끝입니다. GT와 출력값 사이의 L1 distance인데요. 생성-복원 관점이라 되게 간단하게 쓰는 것 같네요. 이 L1 distance를 최적화 하기 위해서, Charbonnier loss (x^2 + \epsilon^2)^{1/2}를 추가로 붙이는데요. 찾아보니까 일반적으로 super resolution 쪽에서는 흔하게 쓰는걸 보니 원래 그냥 쓰는 Loss 같네요. (SwinIR에서도 씁니다)
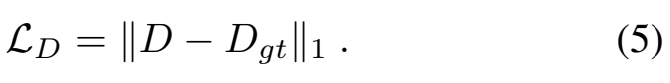
여기에 추가로 Discontinuity map을 추정하는 모델을 학습하기 위한 Loss가 추가됩니다. D_{gt}같은 경우에는 기존 데이터셋에는 없기 때문에, augmetation을 하면서 추가한 figure나 text의 위치 정보를 바탕으로 생성해줍니다. 그런 다음에 L1 distance를 계산하는 매우 간단한 구조입니다. 최종 학습에서는 L_{total} = L_1 + L_D로 더해서 사용합니다.
Experiments
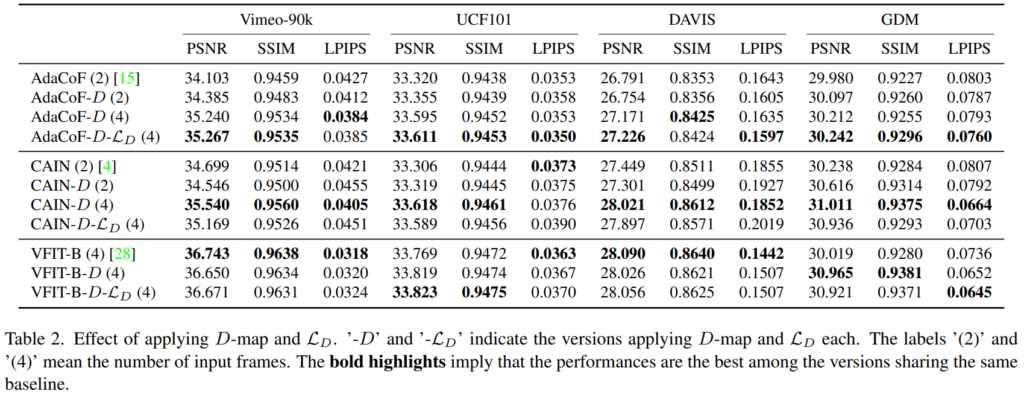
[표 1]을 보면 다양한 VFI 방법론에 제안하는 FTM 모듈을 붙였을 때의 성능을 보여줍니다. 굵은 글씨가 더 높은 성능이라서 그걸 보면 되는데요. (PSNR과 SSIM은 높을 수록 좋고, LPIPS는 낮을 수록 좋습니다.) 사실 성능이 올랐다… 고 보기 애매한 경우도 있고 원래 이 TASK 하던 사람이 아니라 성능 차이가 좋다 나쁘다는 평가하기가 어려운데요.
모든 방법론에서 GDM 데이터 셋을 사용했을 때 확실한 성능 개선이 있었습니다. 이 데이터 셋이 논문 저자들이 제안하는 불연속 정보가 많이 담겨있는 데이터 셋인데요. 당연히 추가로 학습을 했으니까 성능이 좋아야겠죠…? 그것 말고도 사실 Vimeo-90K에서 학습하고 연속 정보만 담겨있는 데이터 셋에서 평가한 것을 감안을 하더라도 좋은 성능을 보이는 경우가 몇개 있으니 좋다고는 하는데… 명확하게 적혀있지는 않지만, [표 2]에 명시되어 있는 성능이랑 또 달라서 입력 프레임을 2개 짜리로 실험한 결과라서 약간의 불이익을 보고 측정한 것이 아닌지… 생각을 하고 있습니다. (이 방법론은 4개로 해야 불연속 정보 추정이 가능해서 제 성능이 나옵니다.)
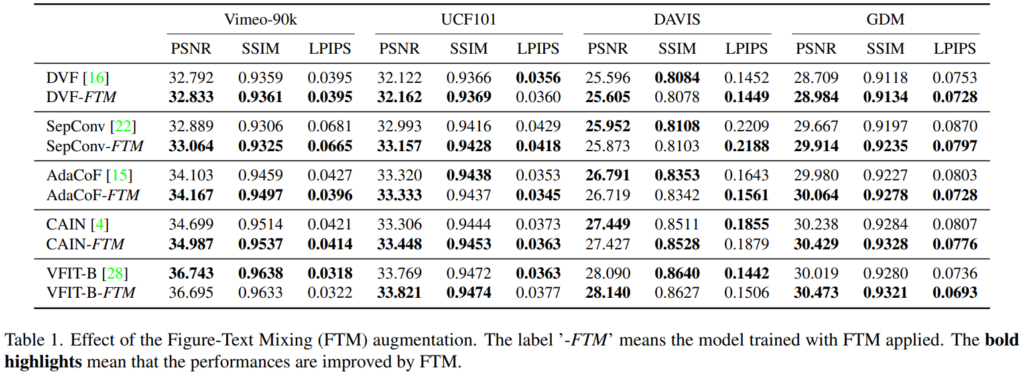
D-map의 효율성에 대한 실험 결과도 보면 위와 같은데요. D가 붙으면 D-map 사용 버전, L_D는 Loss 사용 버전이고 마지막으로 괄호는 입력 프레임의 수입니다. 베이스라인 성능 대비 경향성이 다르긴 하지만, 어쨋든 쓰는 것이 더 좋다는 것을 볼 수 있습니다. 그리고 불연속 추정에 있어서도 정확한 추정을 위해서 2프레임이 아니라, 4프레임을 입력으로 쓰는 것이 더 좋다는 것이 명확하게 보여집니다.
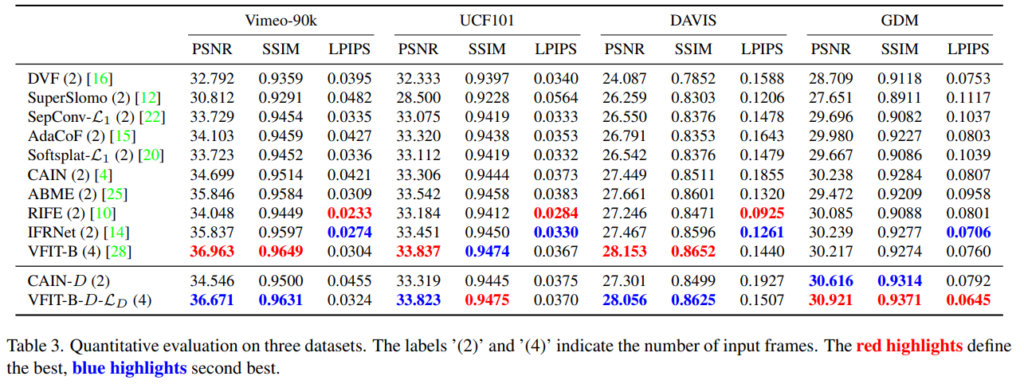
그래서 기존 방법론들과 성능 비교를 해보면, 빨강이 제일 좋았던 성능이고 파랑이 두번째로 좋은 성능을 보여주는데요, 전반적으로 제안하는 방법론이 색칠이 많이 되어 있는 것을 볼 때 전반적인 성능 향상을 보인 것이라고 생각해볼 수도 있습니다. 하지만 제가 생각했을 때는 사실 조금 아쉽지 않나 생각이 되는데요. 논문에서는 연속 정보에도 잘 대응할 수 있다라고 밝히고 있지만, 전반적인 성능(VFIT-B의 케이스를 비교)을 보면 연속 정보에서 손해를 보는 경향성이 있는 것 같습니다. SOTA라고 말하기가 쪼금 애매하지 않나… 싶네요.


실제 예측 결과는 위에 샘플로 몇개를 들고 왔습니다. 사실 체리피킹이겠지만…? 그래도 실제로 어떤 차이가 있는지 확인해보실 분들은 참고해서 보시면 좋을 것 같네요.
Conclusion
현우님이 KCCV에 갔더니, 제가 하는거랑 비슷해보인다면서 논문을 추천해줬는데 처음에는 관계가 없었는데 요즘 하는 실험이랑 비슷한 것 같아서 제대로 읽어봤습니다. 확실히 차용해볼 수 있는 부분이 있는 것 같아 조금 적용을 해볼까? 고민을 했는데, 마침 Augmentation 코드도 제공해서 한번 해볼까 생각중입니다. 그럼 리뷰 마치겠습니다.
안녕하세요. 리뷰 잘 보았습니다.
질문 몇가지 남깁니다.
1. 그림1에서와 같은 연속적이지 못한 모션이 frame interpolation 관점에서 왜 중요한 문제인지 궁금합니다. 기존의 모델 학습 방식으로는 비연속적인 모션 부분을 전혀 고려하지 못해서 성능에 부정확한 영향이 있는 것인가요? 그렇기에는 정량적 테이블을 보면 제안하는 FTM을 붙였을 때 성능 향상이 매우 미미하거나 오히려 떨어지는 경우가 보이는 것 같아서.. 왜 이 문제를 풀어야하는지 의문이 조금 듭니다.
2. 수식에서 \hat{I}_{c}가 보간된 프레임을 말하나요 아니면 \hat{I}이 보간된 프레임인가요? 수식3에서는 \hat{I}를 \hat{I}_{c}와 I_{1}의 조합으로 만드는 것 같아서 \hat_{I}가 보간이 된 프레임으로 보이는데 수식3 바로 위에 리뷰 글에서는 보간된 프레임을 \hat{I}_{c} = F(I_{1}, I_{2})로 표현이 가능하다고 해서 용어에 혼동이 오네요.
밑에 그림 4를 보니 \hat{I}_{c}가 VFI 네트워크의 output인 것으로 보임. 그럼 이 VFI의 output은 어떤 값을 가지는 것? 연속적인 모션 정보만을 가지고 있는 것인가?
3. 수식 5번에서 Discontinuity map을 학습하기 위해 augmentation 해서 추가한 그림이나 텍스트에 대해서 loss를 계산한다고 하셨는데, 그 말은 augmentation으로 생성된 text의 위치에 해당하는 영역만 loss를 계산한다는 의미인가요? 이렇게 될 경우 augmentation이 아닌 실제 데이터 내에서 존재하는 discontinuity는 모델이 고려를 못하는게 아니지 않나요?
4. 마지막으로 해당 논문에서 augmentation을 적용하였을 때의 예시 등은 없는지 궁금하네요.
1. 저도 그렇게 생각해서 리뷰에 언급해두었습니다 ㅋㅋ… 근데 저자의 생각도 잘못된건 아닌게 실제 스트리밍 환경에 적용하려면 기존 방법론들의 한계는 명확하긴 합니다. 아마 그런 부분에서 가점을 받아서 붙지 않았을까? 싶네요. 결국은 제안하는 데이터셋도 스트리밍 환경에서 좋은 성능을 보이는 데이터셋이니까요.
2. \hat{I}_{c}가 보간된 프레임이 맞습니다. \hat_{c} == 그냥 보간된 프레임이고, c 붙으면 연속정보에 해당하게 보간된 프레임입니다.
3. 지적하신 부분이 맞는데. 기존 데이터셋을 연속 데이터셋이라고 정의하고 학습하기 때문에 그런 부분은 넘어가는 것 같습니다. (원본 데이터셋을 제가 그렇게 까본건 아니라서 실제 그런지 안그런지는 모릅니다.)
4. 논문에 예시가 있긴 한데 막 그렇게 엄청난건 아니라서 [그림 1]에 배경 있다고 생각하면 됩니다. (궁금하면 제 자리 오시면 보여드릴게요)
안녕하세요. 이광진 연구원님.
좋은 리뷰 감사합니다.
D-map을 추정하여 보간할 영역과 그렇지 않은 영역을 판단한다는 것이 신기하네요.
D-map GT가 있는 만큼, D-map을 추정하는 estimator의 성능도 측정할 수 있을 것이고, 이게 최종적인 성능과 큰 연관이 있을 것 같은데요. 혹시 논문에 이 성능도 측정이 되어있나요?
감사합니다.
리뷰에서도 언급했다시피 D-map GT가 Augmentation 주는 값에 따라 생성되는 어떻게 보면 Pseudo GT이랑 비슷합니다. 원본 영상에 있는 기본적으로 존재하는 불연속에 대한 GT는 없기 때문이죠. 따라서 그 성능 측정해도 의미가 없을 것 같고, 저자들도 그렇게 생각해서인지는 모르겠지만 성능이 없습니다.