이번 리뷰 논문은 Diffusion model을 다루고자 합니다. 이번 Diffusion model은 그중 가장 유명한 방법론에 해당하는 stable diffusion을 다루고자 합니다. stable diffusion의 정식 명칭은 Latent Diffusion Model(;LDM)으로 기존 diffusion model들이 pixel-level에서 noise를 예측하는 것과 다르게 이름 그대로 latent feature level에서 noise를 예측함으로써, 연산 비용과 의미론적인 특징을 보다 자세히 볼 수 있다는 특징을 가지고 있습니다.
Intro
Image Synthesis은 최근 가장 눈부신 발전을 이룬 컴퓨터 비전 분야 중 하나이며, 동시에 가장 많은 계산이 필요한 분야이기도 합니다. 특히 복잡하고 자연스러운 장면의 고해상도 합성은 현재 수십억 개의 파라미터가 잠재적으로 포함될 수 있는 likelihood based models (e.g. Auto-Regressor(AR) Transformer)들이 대세를 이루고 있었습니다. 이와 대조적으로 GAN인 경우, adversarial learning process로 인해 비교적 좋은 성능에도 불구하고 multi-modal distribution을 모델링하는데 쉽지 않고, 이는 변동성이 비교적 제한된 데이터에서만 효과적인 결과를 보이는 결과로 알려져 왔습니다.
최근 계층적 구조를 가진 denoising autoencoder로 구성된 Diffusion Models(DM)은 Image Synthesis에서 SOTA를 달성하면서 많은 관심을 받게 되었습니다. 해당 방법론은 ikelihood based models의 특성을 따라, GAN의 문제점인 mode-collapse나 학습 불안정성과 같은 단점들을 가지고 있지 않으며, 파라미터 공유를 적극적으로 활용함으로써, 앞서 언급한 AR 기반 방법론처럼 수십억 개의 파라미터를 사용하지 않아도 된다는 장점을 가지고 있습니다.
Democratizing High-Resolution Image Synthesis.
허나, 기존 DM들은 likelihood based models로 mode-covering 수행 중 데이터로부터 imperceptible details을 모델링하면서 과도한 용량을 소비하는 문제가 있습니다. 이는 RGB 이미지의 고차원 공간에서 반복적인 학습과 평가를 수행하기 때문이라고 주장합니다. 예를 들어, 가장 강력한 DM(e.g. ADM)을 학습시키기 위해선, 150~1000 V100 days가 필요하다고 합니다. 게다가 inference를 수행하기 위해서 50k samples을 생성하는데 약 5 days on a single A100 GPU가 소모된다고 합니다. 저자는 이러한 결과에 대해 아래와 같이 2가지 관점의 결론을 내립니다.
- DM을 학습시키기 위해서는 기업 수준의 컴퓨팅 자원이 필요하다.
- 동일한 모델을 반복적으로 실행해야 하기 때문에 이미 학습된 모델을 평가하는 것조차 비싼 비용이 든다.
이 컴퓨팅 리소스 사용량을 줄이면서도 강력한 모델의 접근성을 높이기 위해선, training과 sampling 둘 모두의 compuatational-complexity를 줄여야할 필요성이 있다고 합니다. 즉, DM의 성능을 유지하면서도 계산량을 줄이는 것이 해당 태스크에 대한 접근성을 향상시키는 방법이라고 합니다.
Departure to Latent Space
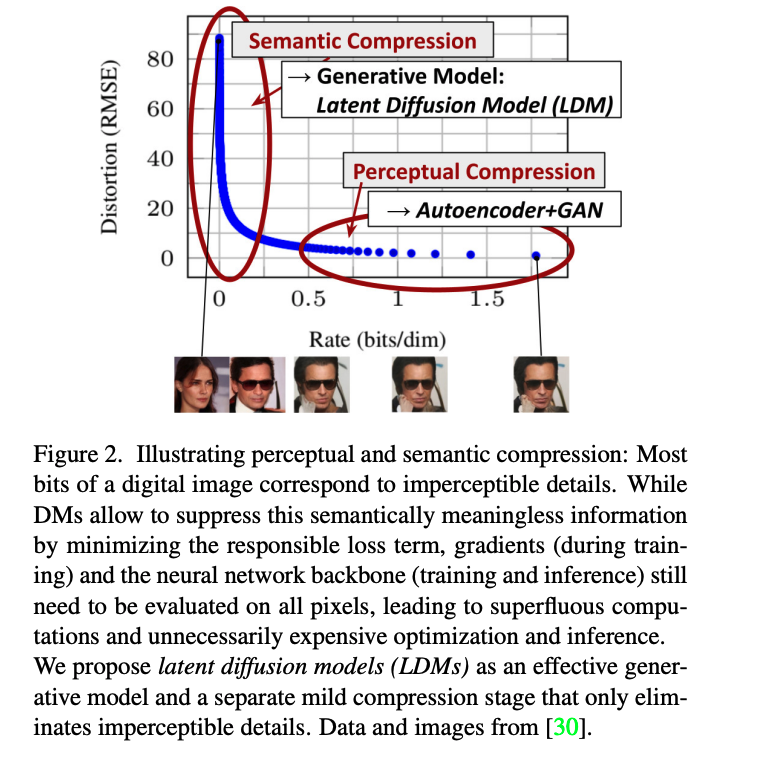
저자는 먼저 Fig 2. Rate-Distortion plot에서 보이는 바와 같이 학습된 모델들을 분석하는 것으로 시작합니다. Likelihood based model의 학습은 대략적으로 두 단계로 나뉘어지는데, 첫 번째 단계는 perceptual compression stage로, high-frequency details를 제거하지만 여전히 semantic variation는 거의 학습하지 않습니다. 두 번째 단계에서는 실제 생성 모델이 semantic, conceptual한 데이터의 composition을 학습합니다(semantic compression). 따라서 먼저 perceptually equivalent하면서 계산적으로 더 적합한 공간을 찾아 고해상도 이미지 합성을 위한 DM을 훈련하는 것이 목표입니다.
++ 정리하자면 위 그림과 같이 perceptual compression과 semantic compression으로 구분 지을 정도로 특징이 두드러지는 것이 보임? perceptual compression에서 높은 rate를 보이는 정보들이 압축됨. 근데 이걸 다시 복원시키면 너무 고연산 아닌가? 라는 이야기를 돌려서 말하고 있는 것이라고 보시면 됩니다.
앞서 제시한 목표를 도달하기 위해 새로운 기법을 제안합니다. 일반적인 관행에 따라 훈련을 두 가지 단계로 구분하면 1. 데이터 공간과 perceptually equivalent한 lower-dimensional representational space을 제공하는 autoencoder를 학습합니다. 중요한 점은 학습된 latent space에서 DM을 훈련하기 때문에 과도한 공간 압축에 의존할 필요가 없다는 점입니다. 2. 복잡성이 감소하여 single network pass로 잠재 공간에서 효율적인 이미지 생성이 가능합니다. 저자는 해당 기법을 Latent Diffusion Model(LDMs)이라고 부릅니다. 추가로 한번 학습한 모델로 여러 task에서 사용 가능한 점을 보였고, transforem를 이용한 token-based conditioning 기법도 제안합니다.
++ 1. perceptual compression만 수행하는 autoencoder를 따로 둬서 2. autoencoder로 추론된 latent space에서 semantic compression만 수행하는 DM을 이용하자. 이것이 Latent Diffusion Model임.
Method
우리의 지각 압축 모델은 이전 연구[23]를 기반으로 하며 지각 손실[106]과 패치 기반[33] 적대적 목표[20, 23, 103]의 조합으로 훈련된 자동 인코더로 구성됩니다. 이를 통해 국소적 사실성을 강화하여 재구성이 이미지 매니폴드에 국한되도록 하고 L2 또는 L1 목표와 같은 픽셀 공간 손실에만 의존하여 발생하는 흐릿함을 방지할 수 있습니다.
Perceptual Image Compression.
Perceptual compression model은 perceptual loss와 patch-based adversarial objective로 훈련된 auto-encoder로 구성됩니다. 이를 통해 reconstructions이 local realism을 살릴 수 있으며, pixel-sapce 손실만 고려하는 L1, L2 loss로 인한 흐릿함 현상을 방지 할 수 있습니다. 자세히 보자면 RGB 공간에 있는 x \in R^{H \times W \times 3} 에 대해 encoder \mathcal{E} 는 x를 latent 표현인 z = \mathcal{E}(x), z \in R^{h \times w \times c }로 인코딩하고, decoder \mathcal{D} 는 latent로 부터 image \tilde{x} = \mathcal{D}(z) = \mathcal{D}(\mathcal{E}(x)) 를 reconstruct합니다. encdoer는 이미지를 factor f = H/h = W/w 에 따라 downsamples 하고, 본 논문에서는 각기 다른 downsampling factors f=2m, m∈N에 대해 실험했다고 합니다. 논문에서는 autoencoder에서 latent space의 high-variance 문제를 피하기 위해 두가지 regularization을 실험했습니다.
- KL-reg: A small KL penalty towards a standard normal distribution over the learned latent, similar to VAE.
- VQ-reg: Uses a vector quantization layer within the decoder, like VQVAE but the quantization layer is absorbed by the decoder.
또한, LDM의 perceptual compression model은 latent space z = \mathcal{E}(x) 에 대해 two-demensional structure로 디자인 되었기 때문에 z가 1차원 구조였던 이전 방법론 대비 영상 x의 디테일을 더 잘 보존할 수 있었다는 장점을 가집니다.
Latent Diffusion Models.
Diffusion Model. DM은 data distribution p(x)를 학습하기 위해 제안된 모델로. 해당 모델들은 denoising autoencoder \epsilon_{\theta}(x_t, t); t=1, ..., T 의 weighted sequence로 볼 수 있으며, x로부터 noise가 가해진 x_t 의 denoisy를 수행하는 방식으로 예측을 진행합니다. 이에 대해 단순화된 수식은 아래와 같습니다.
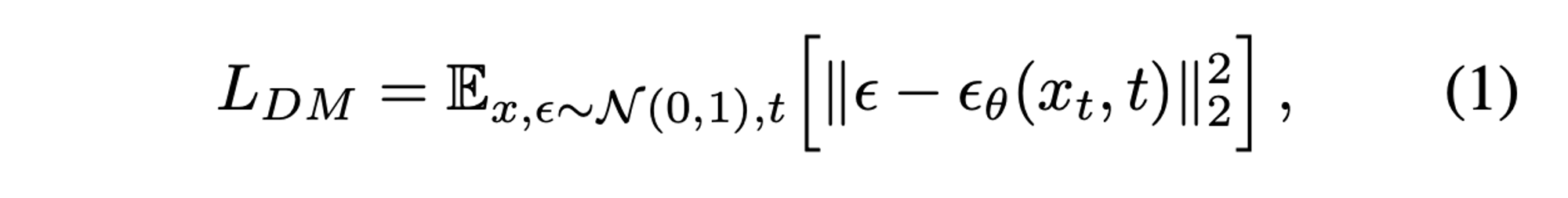
Generative Modeling of Latent Representations. \mathcal{E} 와 \mathcal{D} 로 구성된 perceptual compression model을 통해 high-frequency, imperceptible details이 추상화되는 low-dimensional latent space에 접근할 수 있는데, 이는 pixel-level 방식보다 더 likelihood-based 생성 모델에 더욱 적합하다고 볼 수 있습니다. 이 방식에 대한 장점을 정리하면 (i) 데이터의 중요하고 semantic한 bits에 집중할 수 있고, (ii) 더 낮은 차원에서 학습할 수 있어 computionally 효율적이란 장점을 가집니다. 이를 수식으로 정리하면 다음과 같습니다.
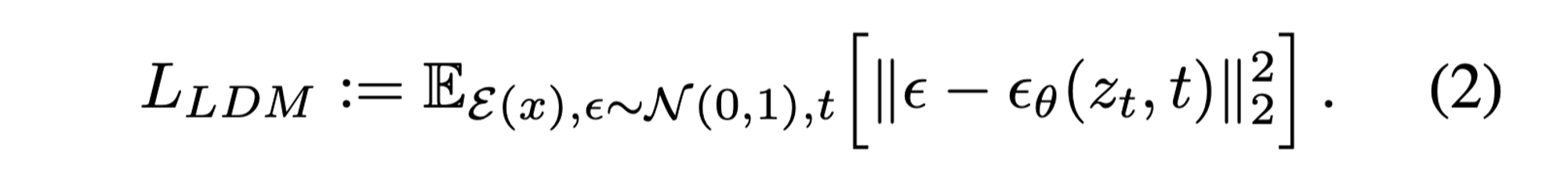
모델에서 neural backbone인 \epsilon_{\theta}(O, t)은 time-conditional UNet으로 구성되며, forward process가 고정되어 있기 때문에, z_t 는 학습 과정에서 \mathcal{E} 에 의해 쉽게 얻어질 수 있고, p(z)로 부터의 sample은 \mathcal{D} 를 통해 single pass로 쉽게 decoding을 수행할 수 있습니다.
++ 추가로 이전 기법 중 VQGAN와 VQVAE가 LDM과 유사한 프로세스를 따른다고 합니다. 허나, 이전 기법들은 벡터 형태로 압축 시킨다음 정보를 디코딩하기에 image-specific inductive bias를 활용하지 못하는 단점을 가진다고 합니다.
Conditioning Mechanisms
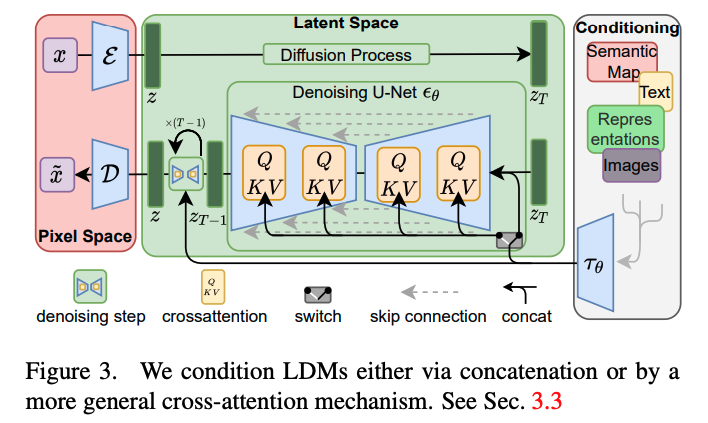
다른 타입의 generative 모델과 유사하게 diffusion model은 conditional distribution을 p(z∣y)로 모델링을 수행합니다. conditional denoising autoencoder \epsilon_{\theta}(z_t, t, y)라고 할때, 이는 이미지 생성을 input y(text, semantic maps)에 따라 컨트롤하거나, image-to-image translation task를 수행할 수 있게 됩니다. 저자는 UNet backbone을 다양한 modality에 대해 conditioning 가능하도록 cross-ateention mechanism로 구성하기를 제안합니다. y를 다양한 modalities(e.g. language prompts)로부터 전처리하기 위해 본 논문에서는 domain specific encoder \tau_{\theta}를 이용하여, [latex] \tau_{\theta}(y) \in R^{M \times d_{\tau} } 로 project 합니다.
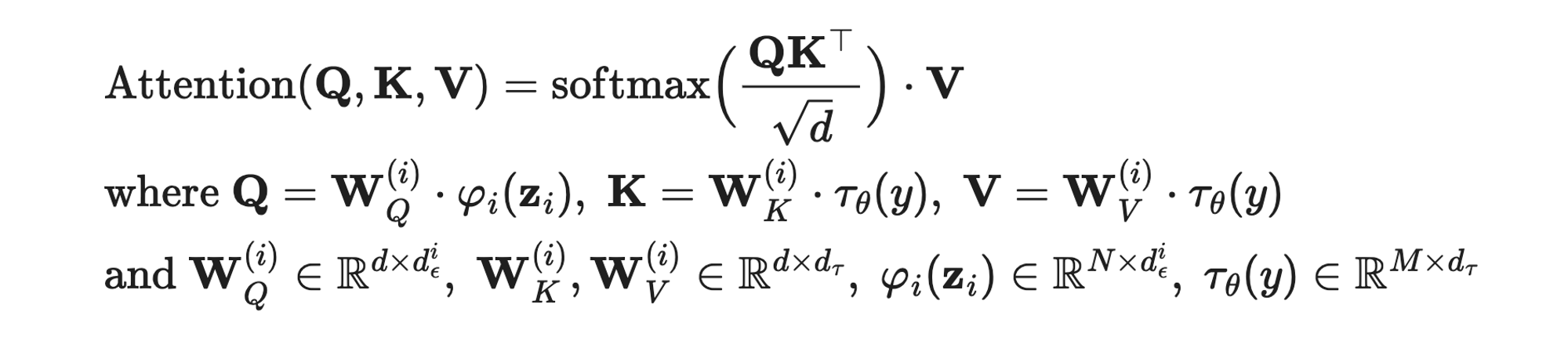
여기서 \varphi(z_t) \in R^{N \times d^i_\epsilon} 은 UNet으로부터 추론된 flattened intermediate representation에 해당하며, 정리하면 query는 UNet, key와 value는 conditional info로 이를 이용하여 cross-attention을 수행합니다. conditional LDM을 정리하면 다음과 같습니다.
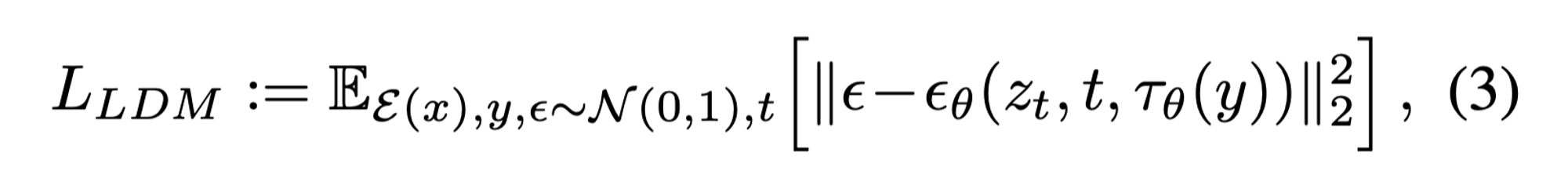
Experiment
On Perceptual Compression Tradeoffs
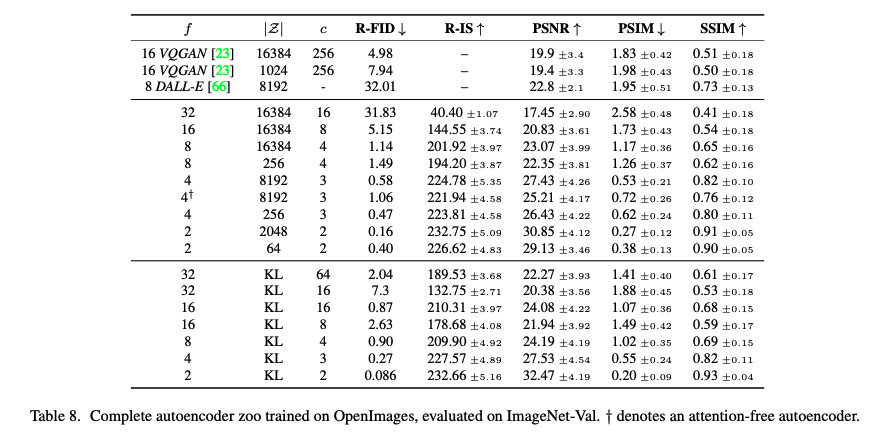
낮은 downsampling을 보이는 f=1~2(기존 DM과 유사한)에서는 느린 학습 속도를 보이며, fidelity가 개선되지 않아 perceptual compression을 Diffusion model에서 수행하게 되면서 semantic 외에도 perceptual 측면에서도 학습 정보량이 많아지는 현상이 발생했기 때문이라고 분석합니다. 실험적은 분석으로는 LDM-4~16에서 적당한 밸런스를 보인다고 합니다.
Image Generation with Latent Diffusion
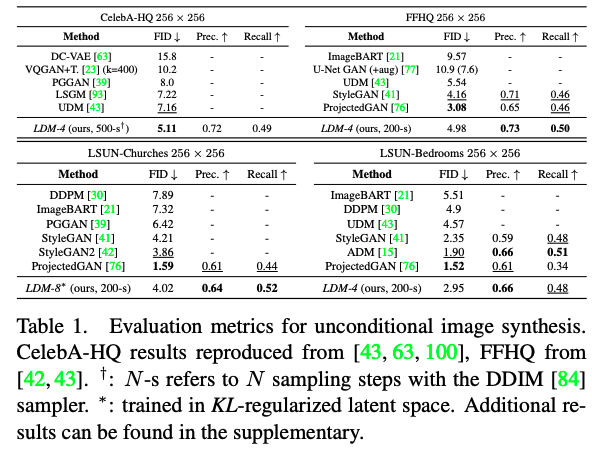
CelebA-HQ에서는 GAN 조차 압도하는 성능을 보여주었고, 다른 데이터 셋에서도 다른 방법론 대비 recall과 precision에서 우세한 성능을 통해 likelihood based model의 mode-covering 측면에서의 장점을 보이고 있습니다.
Conditional Latent Diffusion
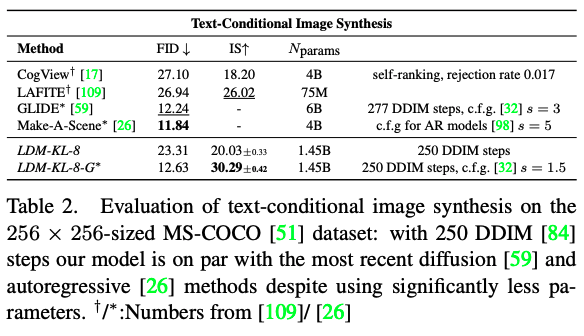
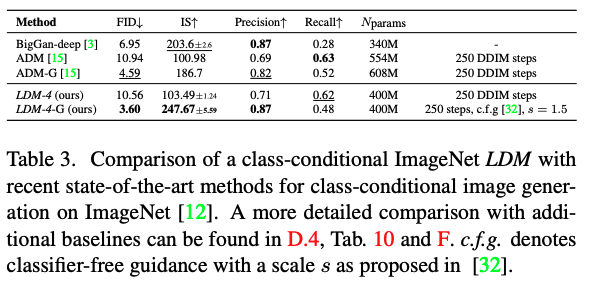

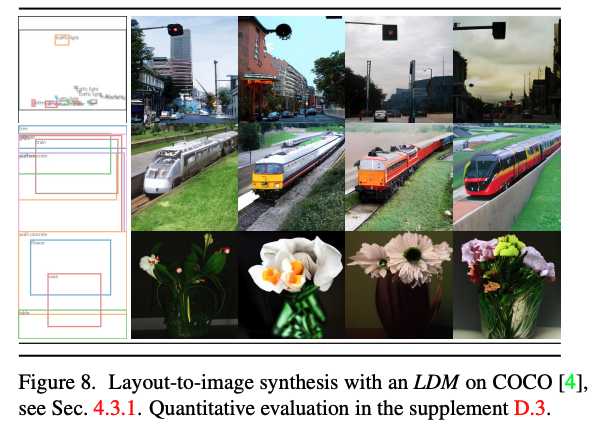
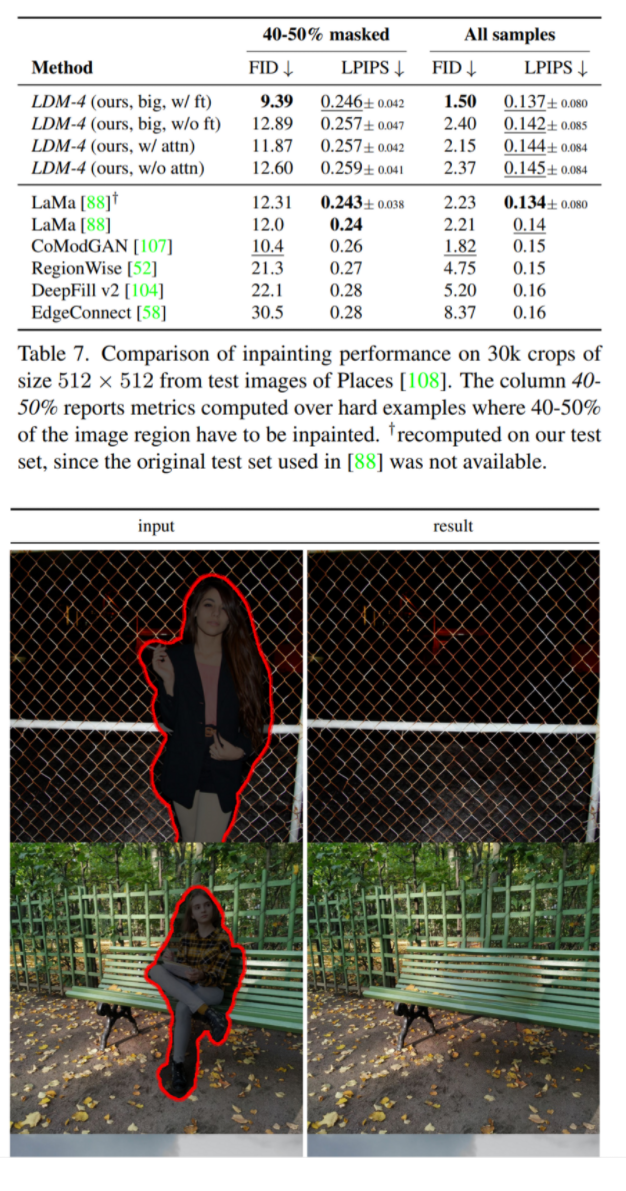
해당 파트는 Text-to-Image, Class-conditional ImageNet, Layout-to-Image, Inpainting 등 다양한 task에 대한 정성/정량적 결과이며, 모두 좋은 결과를 보여줍니다.
다른 생성 모델 대비 Diffusion model은 데이터 분포 자체를 학습하는 Generative model에 해당합니다. 이러한 특성은 같은 시점을 보고 있는 가시 영역의 영상 정보와 비가시 영역의 영상 정보 간의 분포를 포착하고 변형이 가능하지 않을까란 기대가 있습니다. 또한, 픽셀 레벨에서의 가시 영역의 텍스쳐 정보까지 예측하는 것은 주관적인 특징이 포함되어 예측이 어렵겠지만 두 도메인 latent feature 영역에서의 의미론적인 특징에 대한 예측은 충분히 가능할 것으로 판단합니다. 그렇기에 해당 모듈을 이용하여 수행 중인 멀티스펙트럴 연구에 적용해보는 것을 고민해보고 실험을 진행하고 있습니다. 좋은 결과로 선보였으면 좋겠네요...