안녕하세요, 열두번째 x-review 입니다. 이번 논문은 ICIP 2023에 게재된 TR3D라는 논문으로 RGB와 포인트 클라우드를 fusion하는 방식의 3D Object Detection 논문 입니다. 그럼 바로 리뷰 시작하겠습니다 !

1. INTRODUCTION
현재 3D Object Detection은 크게 3가지로 분류할 수 있는데요, voting 기반과 transformer 기반, 그리고 3D convolution 기반이 그에 해당합니다. 각각의 방법론에 대해 간단히 살펴보자면 먼저 voting 기반은 백본에서 추출한 포인트들을 물체에 대한 박스를 예측하는데 물체의 중심일 것 같은 곳을 voting하여 중심점으로 선택합니다. 그럼 예측한 중심을 기준으로 grouping하여 물체를 검출하게 됩니다. 이런 voting 기반은 scalability가 나빠서 사용을 하는데 제약이 많다는 단점이 존재합니다. 반대로 transformer 기반은 end-to-end로 학습이 가능하고 voting 기반에 비해서는 범용적으로 사용할 수 있지만 large scene의 데이터셋에서 처리할 때는 여전히 scalabtility 이슈가 발생한다고 합니다. 마지막으로 3D Convolution은 포인트 클라우드를 복셀 형태로 처리하여 3D Convolution을 태우는 방법인데요, 포인트 클라우드가 sparse하다는 특성을 가지고 있다보니 raw level로 들어온 포인트 클라우드의 형태를 그대로 복셀로 바꿀 경우에는 비어있는 복셀 그리드가 많이 생기게 됩니다. 복셀로 변형할 경우에 원래도 메모리가 많이 요구되기 때문에 빈 그리드가 만들어지는 것을 방지하기 위해 sparse convolution의 형태로 보통 구성하게 됩니다. dense한 형태에 비해서 3D sprase convolution을 사용하는 방법론은 메모리 사용을 훨씬 줄일 수 있고 large scene으로 구성된 데이터셋으로의 확장 또한 가능하다는 장점이 존재합니다. 그러나 이러한 기존의 saprse 3D convolution에서는 고질적인 단점이 존재하는데, 바로 정확도가 낮다는 것 입니다. 즉 빠르고 scalable하지만 정확도가 다른 방법론들에 비해 낮은 것이죠.
모달리티 관점으로 봤을 때 3D detection 방법론들은 현재 기하학적인 정보, 즉 포인트 클라우드만을 이용하여 의미있는 결과들을 도출하고 있습니다. 그러나 포인트 클라우드라는 것은 LiDART 센서라는 추가적인 센서를 사용해야 하며 포인트 클라우드만으로는 물체의 어떤 semantic한 정보들을 구별해내기가 쉽지 않습니다. 반면에 카메라 이미지인 RGB 영상은 더 접근하기 쉬울 뿐만 아니라 포인트 클라우드 대비 informative한 정보들을 제공할 수 있습니다. 그래서 RGB 이미지와 포인트 클라우드를 fusion 하고자 하는 연구가 계속해서 진행되고 있지만, 현재 연구에서는 RGB 이미지의 데이터를 late stage에 추가하거나 혹은 두 모달리티의 특징을 fusion하는 방식이 너무 복잡하거나 메모리 비용이 많이 드는 구조를 사용하고 있습니다. 그러다보니 속도 또한 느려지고 해당 방법론에서 정의하는 환경에 custom되어 범용적인 사용에 제한이 생긴다고 합니다. 그래서 본 논문에서는 두 모달리티를 early fusion 방식인 TR3D를 제안하게 되는데, 해당 방법론으로 RGB와 포인트 클라우드를 fusion하는 방법들 중 SUN RGB-D, ScanNet V2, S3DIS 데이터셋에서 모두 SOTA를 달성하였다고 합니다.
2. Related Work
RGB 이미지를 3D Object Detection에 사용하는 이유는 기하학적인 정보를 제공하는 포인트 클라우드에서는 얻을 수 없는 추가적인 정보를 얻기 위함입니다. ImVoteNet은 2D detection을 수행한 후에 이를 3d point 사이의 center점을 찾기 위한 voting을 할 때 2D detection의 결과까지 함께 포함하여 voting을 진행합니다. EPNet++은 3D feature extractor로 추출한 3D feature와 2D feature extractor로 추출한 2D feature을 바로 fusion하는 방식 입니다. MMTC는 3D object detection 네트워크의 첫번째와 두번째 stage 사이에 2D segmentation network를 포함시키는 cascading 방식 입니다. 마지막으로 TokenFusion은 transformer 모듈로 포인트 클라우드와 RGB 정보를 합치게 됩니다.
related work에서 rgb와 fusion하는 방식에 대해 설명하는 부분에서 언급한 방법론들이 아래의 method 파트에서 비교군으로 계속 사용이 되어 포함해보았습니다.
3. PROPOSED METHOD
사실 TR3D는 제가 이전에 리뷰했던 FCAF3D을 기반으로 아주 간단한 변형만 추가된 방법이라고 할 수 있습니다. FCAF3D는 최초로 3D Object Detection에서 anchor free 방식을 제안한 논문으로 간단히 설명하면 포인트 클라우드를 입력하는데, 입력으로 들어온 포인트를 voxel로 처리하는 voxel 기반의 방법론 입니다.
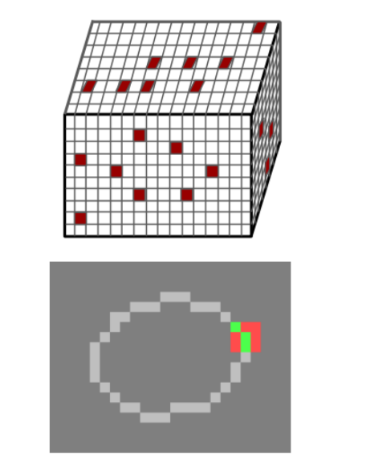
앞선 introduction에서 언급하였듯이 voxel 기반일 경우 raw 포인트 클라우드를 voxel 형태로 변형해주는데, 변형하게 되면 위의 사진처럼 전체 3D grid 공간 내에 빨간색의 매우 sparse한 voxel만이 유의미한 정보를 가지게 되는 것을 볼 수 있습니다. sparse한 포인트 클라우드를 처리하기 위해서 빈 공간에 대한 많은 메모리와 계산비용이 발생하기 때문에 sparse 3D Convolution라는 것을 사용하며 FCAF3D에서도 역시 sprase 3D Convolution을 사용하고 있기 때문에 sparse 3D convolution에 대해 조금 더 자세하게 알아보도록 하겠습니다.
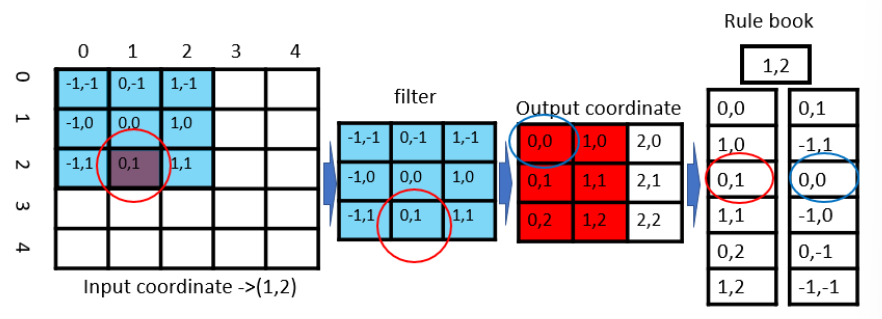
위의 예시 사진에서 맨 왼쪽이 voxel grid이고 빨간색 동그라미가 쳐진 부분만이 dense하게 데이터가 담겨있고 나머지 부분은 sparse하게 아무 정보도 담겨 있지 않은 grid라고 가정해보겠습니다. 이러한 gride에 3×3 filter로 padding 없이 계산한다고 가정하면 세번째의 Output Coordinate라고 표현된 것과 같은 output이 나오게 됩니다. 그런데 한 곳에만 데이터가 존재하는 상황에서 모든 grid에 컨볼루션 계산을 한다는 것은 비효율적이기 때문에 sparse 3D convolution은 그러한 비효율성을 부이기 위해 Rule book이라는 것을 만들었습니다.
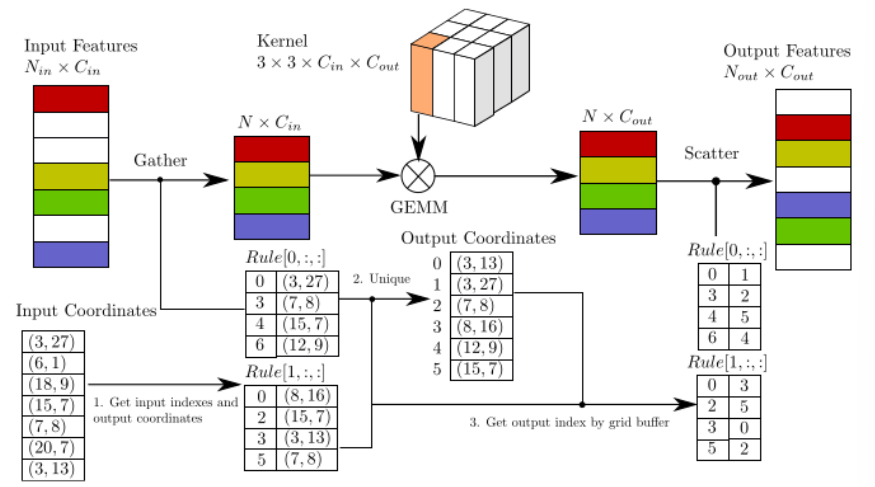
Rule이라는 것은 input point들와 관련한 ouput을 반복적으로 찾아서 해당하는 index를 rul book이라는 곳에 저장하는 방식으로 만들어집니다. 먼저 input의 index와 associated spatial index를 모으게 되고 그 과정에서 중복되는 ouput location을 찾을 수 있습니다. 그리고 모은 spatial index를 통해서 output index와 input과 마찬가지로 associated spatial index를 구할 수 있게 됩니다. 그리고 rool book을 만들기 위해서 spatial index를 사용하여 동일한 spatial 차원을 가진 buffer를 생성하게 되고 앞선 과정을 반복하면서 각각의 input에 해당하는 index와 그에 대응되는 ouput index를 얻을 수 있습니다. 앞선 예시 사진으로 이 과정을 간단하게 설명하면 데이터가 존재하는 좌표 (1, 2)는 필터의 (0,1)과 계산도기 그 결과는 output에서 (0,0)에 저장됩니다. 즉 input과 filter의 특정 좌표에서 계산되면 output의 특정 좌표로 저장이 된다는 하나의 rule이 만들어지고 반복적으로 계산했을 때 결국 input 데이터인 (1,2)에 의해서 결과가 바뀌는 output을 찾으면 (0,0), (1, 0), (0, 1), (1, 1), (0, 2), (1, 2)로 총 6개가 존재하게 됩니다. 기존의 convolution이 3×3의 필터로 9번 grid를 돌아서 총 81번의 계산이 필요했던 것과 비교하여 sparse 3D convolution은 rule book에 존재하는 6개에 대해서만 계산하여 feature을 추출하기에 연산량 측면에서 효율적이기 때문에 voxel 기반의 3D object detection에서 보편적으로 사용되는 것 입니다.
FCAF3D의 다른 구조에 대한 더 자세한 내용은 제 이전 리뷰를 참고해주시면 좋을 것 같습니다. 정리하자면 포인트 클라우드를 입력으로 하는 anchor free based의 FCAF3D → RGB 이미지까지 fusion한 멀티 모달리티의 TR3D 흐름으로 이어지는 것 입니다. TR3D는 FCAF3D과 비교하였을 때 효율성과 정확도 측면에서 성능 향상이 발생하였고 또한 RGB와 포인트 클라우드를 함께 사용하는 멀티 모달리티 모델까지 함께 제안하였습니다.
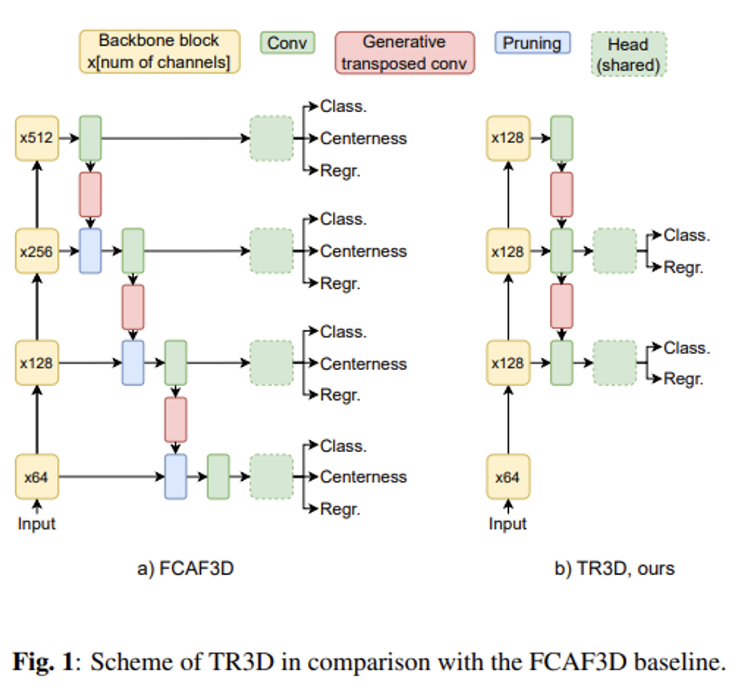
3.1. TR3D: 3D Object Detection
Fig1이 베이스라인 모델인 FCAF3D와 TR3D의 구조를 비교해놓은 것인데, 저자는 TR3D의 구조를 처음부터 바로 설계한 것이 아니라 FCAF3D에서 수정할 모듈들을 하나씩 변형해가면서 해당 모듈들이 성능에 어떤 영향을 주는지 확인 후 추가하는 방식으로 진행하였다고 합니다.
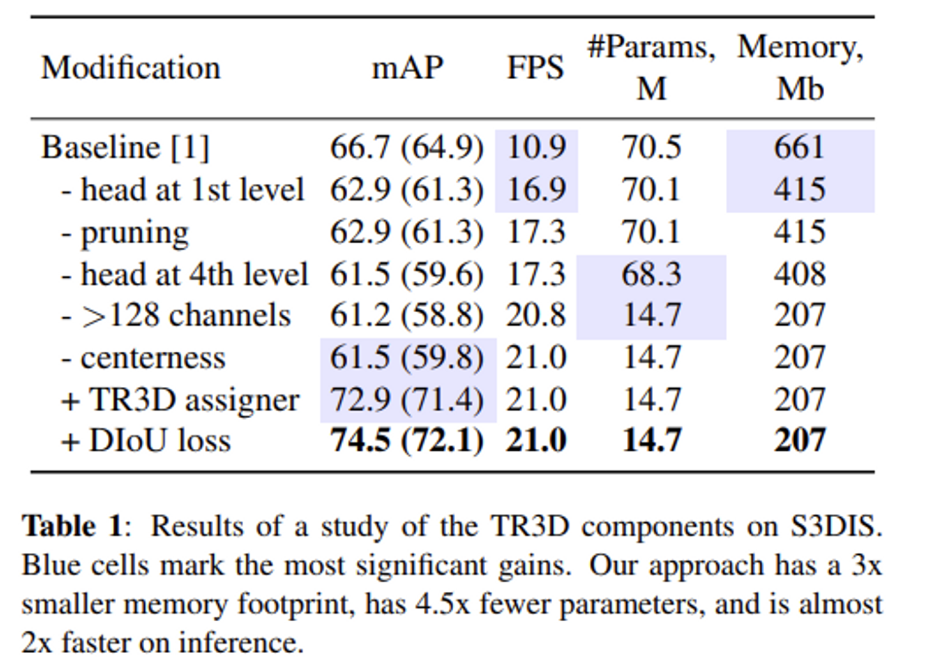
위의 Table1이 S3DIS 데이터셋에서의 실험을 바탕으로 모듈을 추가한 과정 입니다. 첫번째로 목표로 했던 것이 TR3D의 모델을 빠르고 가볍게 바꾸는 것이었습니다. FCAF3D와 GSDN 두 방법론 모두 하나의 transposed 3D convolution이 존재하는데 해당 convolution은 커널 사이즈가 2로 설정되어 있어 한번 transposed 3D Convolution을 통과하게 되면 convolution 내에서 0이 아닌 값이 8배로 증가하여 메모리 증가가 급격하게 발생하게 됩니다. GSDN에서는 이러한 증가를 방지하기 위해서 데이터를 필터링하는 pruning layer을 사용하고, FCAF3D에서도 head에 추가적인 layer을 사용하여 메모리 증가를 줄이고자 하였습니다. 그럼에도 불구하고 실험 결과 첫번째 transposed convolutional layer가 전체 메모리의 1/3을 차지하고 있었다고 합니다. 따라서 저자는 첫번째 layer의 head를 제거함으로써 메모리 용량이 661Mb → 415Mb로 줄일 수 있었습니다. pruning이라는 것도 제거하였다고 서술되어 있는데, FCAF3D에서 직접적으로 pruning을 언급한 적은 없지만 추측해보자면 FCAF3D는 입력으로 들어오는 포인트와 동일한 수의 voxel을 유지하려고 한다는 것을 보아 그런 과정에서 pruning이 작용한 것이 아닐까 싶습니다. 다음으로 4번째 level의 head도 제거하였는데 그 이유는 4번째 level의 경우에는 큰 물체에 집중하여 처리하고 있는데 타겟이 되는 환경이 indoor scene인 만큼 그러한 물체가 흔하지 않기에 필요성이 적다고 판단하여 생략하였다고 합니다.
또한 기존 fusion 모델이 정확도가 낮다는 한계점이 존재하는 만큼, 정확도 향상을 위해서도 FCAF3D 모델 구조를 수정하였습니다. FCAF3D assigner는 3D bounding box 내에 존재하는 포인트만을 detection에 고려하는데 그렇게 되면 얇고 작은 물체는 놓칠 가능성이 높다고 합니다. 따라서 박스라고 할당된 범위 내의 포인트 뿐만 아니라 근처에 존재하는 범위 외의 포인트들까지 detection에 고려하는 새로운 TR3D assigner를 제안합니다. TR3D assigner는 각 물체의 카테고리에 대해 head level을 사전 정의하게 되는데 예를 들면 indoor scene에서 large object로 구별할 수 있는 침대나 소파같은 경우 세번째 head level에서 처리하도록 정의하고 그것보다 더 작은 물체인 의자나 night stand는 두번째 head level에서 처리하도록 하는 것을 의미합니다. 이렇게 물체의 크기에 따라서 어떤 head level에서 처리할지 정의함으로써 놓치는 object의 수를 줄이고자 하였고 기존 assigner에서 TR3D assigner로 변경함으로써 mAP가 615에서 72.9로 향상한 것을 확인할 수 있습니다. 그런데 TR3D assigner에 경우 말씀드렸듯이 박스 근처의 포인트들까지 포함해서 검출하는 것이기 때문에 GT 박스 기준으로 벗어나는 포인트들이 할당될 수 있습니다. 그래서 기존 FCAF3D에서 사용하는 IOU loss는 예측한 박스와 GT 박스 사이의 겹쳐진 경우만 고려하는데, 박스 내에 포함되지 않는 포인트까지 다루는 TR3D에서는 non overlapping한 박스까지 고려해야 하기 때문에 IOU loss는 적합하지 않다고 판단하였습니다. 그래서 IOU와 중심점 좌표를 함께 고려할 수 있는 DIoU loss를 선택하여 사용하게 됩니다.
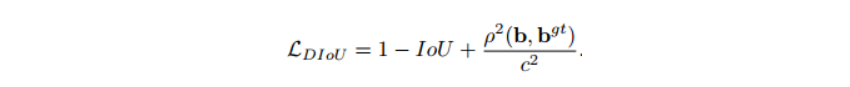
DIoU loss는 Distance IOU를 의미하고 위의 식과 같이 정의할 수 있으며, 기존 IoU loss에 중심점을 고려하는 penalty term을 추가한 형태 입니다. penalty term에서 \rho^2는 유클리디언 거리를 의미하고 b, b^{gt}는 각각 예측한 bounding box와 GT box를 의미합니다. c는 예측한 박스와 GT 박스 모두를 덮을 수 있는 하나의 박스를 만들고 그 박스의 대각 길이를 의미하게 됩니다. DIoU loss는 두 박스의 중심점 거리를 줄이는 방향으로 계산되며 박스의 중심점들 간의 거리를 파라미터로 사용하여 scale의 변화가 크지 않고 타 IOU loss에 비해 빠르게 GT에 수렴할 수 있다는 장점이 존재합니다.
IOU loss를 DIoU loss로 대체하였을 때 mAP가 74.5까지 향상되는 것을 확인할 수 있습니다. 또한 모델을 경량화하는 것이 목표였는데 파라미터 수도 70.5M에서 14.7M로 줄어들었으며 메모리 또한 1/3에 가까운 감소를 보이며 베이스라인 대비 경량화를 이루었다고 볼 수 있다고 합니다.
3.2. TR3D+FF: RGB and Point Cloud Fusion
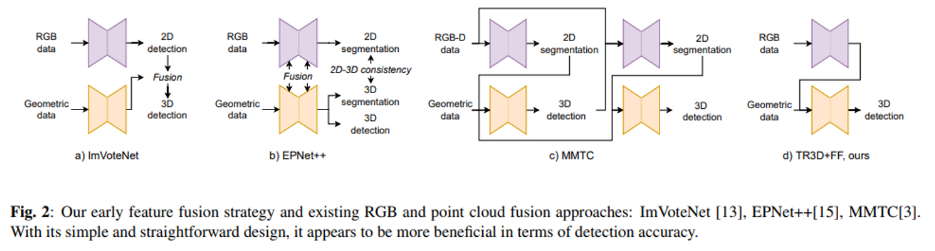
본 논문에서는 RGB 이미지와 포인트 클라우드를 early fusion 하는데요, 먼저 2D 이미지에서 detection을 하기 위해 ResNet+FPN 구조를 사전학습시킨 모델을 사용하였습니다. 그리고 2D feature들을 3D 공간으로 projection 시키고 projection한 2D feature와 3D feature를 element-wise으로 fusion하게 됩니다. 이러한 fusion 구조는 Fig2의 기존의 방식들과 비교하였을 때 훨씬 간단하나, 성능 면에서는 더 뛰어나다고 합니다.
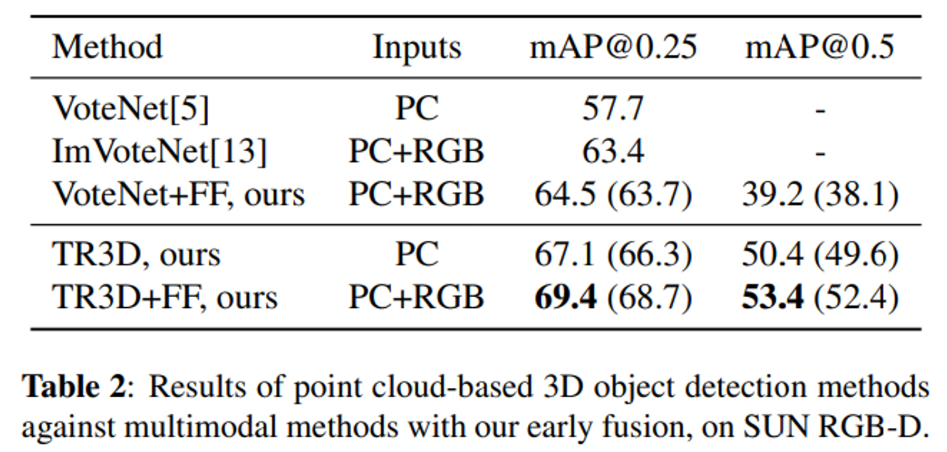
먼저 멀티 모달리티인 ImVoteNet과 TR3D+FF를 비교했을 때 6% 정도의 성능 향상이 있었고 원래 단일 모달리티인 VoteNet에 TR3D에서 제안한 fusion 방식을 붙인 VoteNet+FF와 비교해보았을 때도 성능이 개선된 것을 보아 fusion 구조 뿐만 아니라 TR3D 자체의 구조 또한 성능에 유의미한 영향을 주는 것을 알 수 있습니다. 또한 포인트 클라우드만을 사용하는 VoteNet에 RGB 이미지를 추가적으로 사용한 VoteNet+FF에서 큰 폭으로 성능이 향상되었기에 RGB 이미지가 기하학적인 데이터인 포인트 클라우드와 다른 방면으로 semantic한 정보를 제공하고 있음을 증명하고 있습니다.
4. EXPERIMENTS
4.1. Dataset
실험에 사용한 Dataset은 SUN RGB-D, ScanNet v2, S3DIS 입니다. S3DIS 데이터셋은 6개의 large 공간에 대한 271개의 scene으로 이루어진 데이터셋으로 그 중 5개의 공간과 5개의 semantic한 category에 대해 detection을 진행합니다.
4.2. Comparison to Prior Work
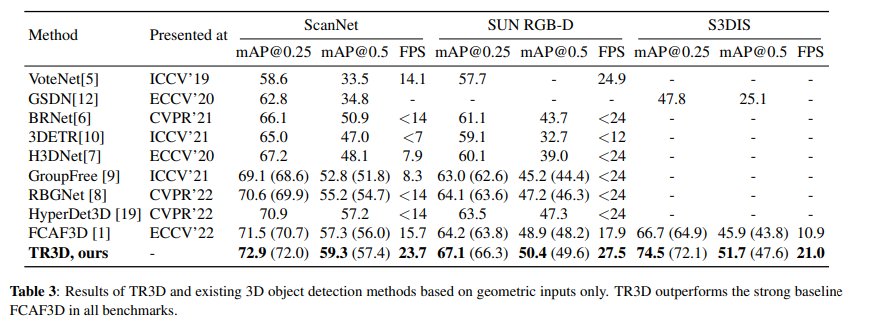
우선 rgb 이미지를 사용하지 않는 단일 모달리티 관점에서 TR3D와 기존 포인트 클라우드만을 입력으로 하는 방법론들을 3개의 데이터셋에서 비교한 실험 결과 입니다.Tabl 3에서 눈여겨 볼 점은 이전 SOTA를 달성했던 FCAF3D에 비해 7.8%의 성능 향상을 보이며 기존 FCAF3D에서 수정했던 구조가 효과적이었음을 알 수 있습니다. 또한 FPS를 비교해보았을 때도 약 2배 정도 빨라짐을 확인할 수 있씁니다. FCAF3D에서 오히려 여러 모듈을 생략한 간단한 모델임에도 불구하고 정확도와 속도, 두 가지 측면에서 모두 향상된 결과를 보여주고 있습니다.
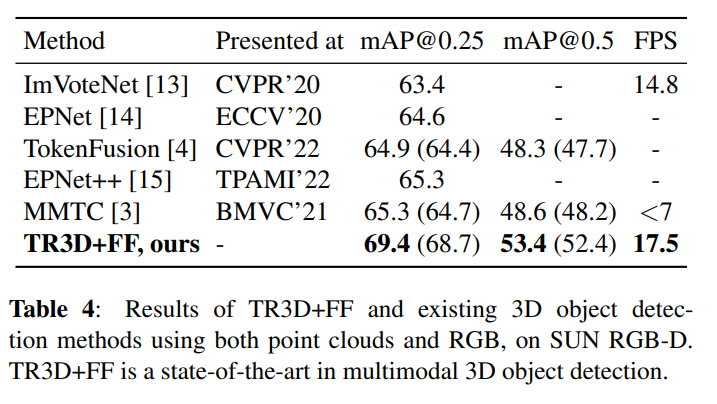
Table 4는 RGB+포인트 클라우드를 모두 입력으로 받는 멀티 모달리티 방법론들과 SUN RGB-D에서의 비교 실험 입니다. TR3D+FF는 원래 SOTA 모델이었던 MMTC 대비 약 4% 정도의 높은 성능을 보이며 SOTA를 달성하였습니다.
좋은 리뷰 감사합니다.
우선 3D detection에서 scalability가 나쁘다는 것은, scale을 반영하기 어렵다는 의미인가요?? scalability가 어떤 의미인지 궁금합니다.
또한, 네트워크를 설계하는 과정 중 indoor 환경에 맞추어 큰 object를 예측하는 데 사용하던 4번째 level의 head를 제거하셨다고 하셨는데, 3D detection에서는 object의 실측 크기를 기준으로 head를 선택하는 것인가요??
마지막으로 물체의 크기에 따라서 어떤 head level에서 처리할지 정의하므로써 놓치는 object를 줄이고자 하였다고 하셨는데, 모든 레이어에서 모든 class를 고려하는 것 보다 특정 레이어에서 특정 class의 object를 detect하는 것이 어떤 점에서 놓치는 object가 줄어들도록 하는 것인지 궁금합니다. 연산량과 관련되는 것일까요?
안녕하세요 ! 리뷰 읽어주셔서 감사합니다.
우선 scalability 이슈란 데이터셋이 large scene으로 갈수록 계산 비용이 높아져 real time의 detection이 불가능함을 의미합니다.
두번째는 object의 실측 기준으로 head를 선택한다기보다는 4번째 level에서 수용 영역이 넓기 때문에 large object에 집중하는 경향이 있기 때문이라고 하는 것이 더 맞을 것 같습니다.
마지막은 하나의 수용 영역을 가진 head level에서 모든 크기의 object를 검출하는 것보다 수용 영역의 크기에 따라서 집중할 물체를 지정하여 놓치는 object를 줄이고자 하였습니다.
안녕하세요. 좋은 리뷰 감사합니다.
TR3D assigner에서 각 head level에 따라서 처리하는 물체의 카테고리가 사전에 나뉘어져 있다고 말씀하셨는데 그럼 이러한 물체의 크기라는 것을 나누는 정량적인 기준이 있는것인가요 ? 나누는 기준이 있다면 4번째 head level을 제거하지 않고 적절하게 indoor scene에 fitting 되도록 category를 나눌수도 있을 것 같은데 첫번째와 네번째 head level을 제거하고 두 개의 head level만을 사용하는 이유가 궁금합니다.
DIoU loss에서 예측한 박스와 GT 박스 모두를 덮을 수 있는 박스를 만들어 그 박스의 대각 길이를 구한다고 하셨는데 이 박스의 대각 길이의 역할이 무엇인가요 ? DIoU의 핵심인 중심점을 고려한다는 것과 연관되어 있는 것 같은데 정확히 이해가 가지 않아 질문 드립니다 .
안녕하세요 ! 리뷰 읽어주셔서 감사합니다.
정량적으로 나누는 기준은 논문에 제시되어 있지 않았습니다만, 첫번째 head는 카테고리의 크기 때문이 아닌 transpose convolution network로 인해 발생하는 메모리 이슈를 해결하기 위해 제거하였습니다. 그리고 네번째 head level은 indoor scene에서 나타나기 어려운 더 큰 물체들이 주로 검출되기 때문에 필수적인 head가 아니기에 생략했다고 이해해주시면 좋을 것 같습니다.
두번째로 DIoU loss에서 대각길이가 의미하는 것은 두 박스 전체의 유클리디언 distance를 의미하기 위해 만들어지는 가상의 박스 입니다. d가 중심점 사이의 유클리디언 거리, c가 전체 박스의 유클리디언 거리로 두 거리가 줄어드는 방향으로 loss가 계산됩니다.
안녕하세요, 손건화 연구원님, 좋은 리뷰 감사합니다. 저자가 TR3D의 구조를 처음부터 제시한게 아니라 하나씩 실험해보며 모듈을 끼워맞춰서 설계했다는 부분이 인상적이네요. 엄청난 노가다였을 것 같습니다..
간단한 질문이 있습니다. 3D object detection에 있어 voting 및 transformer기반 방법은 scalability가 나쁘다는 단점이 있다고 하셨는데, 이 scalability가 무엇을 의미하는지 궁금합니다. 그리고 IoU가 아닌 DUoU 도입 이유가 와닿지 않는데, 추가적인 설명을 해 주시면 감사하겠습니다.
Fig1 위에 (링크) 에 링크가 걸려있지 않은 것 같습니다. 확인 부탁드립니다!
안녕하세요 ! 리뷰 읽어주셔서 감사합니다.
우선 scalability 이슈란 승현님의 질문에 대한 답과 동일하게 드릴 수 있을 것 같은데요, voxel 기반의 방법론에서는 sparse한 포인트 클라우드를 복셀화 시켜 모델의 입력으로 사용하는데 그럴 경우 계산 비용이 높아지기 때문에 데이터셋이 large scene으로 구성되어 있을 경우 real time의 detection이 어려워짐을 이야기합니다. 본 논문에서 제시하는 TR3D assigner 같은 경우에 예측한 박스 내의 포인트 뿐만 아니라 포함되어 있지 않더라도 인접한 포인트까지 예측에 사용하고자 하였습니다. 이럴 경우 일반적인 IOU loss로 계산을 하게 되면 겹치지 않는 영역에 대해서는 고려가 되지 않기 때문에 중심점까지 고려하여 non overlapping 영역까지 예측에 사용할 수 있고 이 결과를 nms threshold에 사용함으로써 IOU에서는 겹치지 않는다고 판단하지만 DIoU에서는 그러한 영역까지 고려하기 때문에 인접한 포인트까지 최정 box proposal에 사용할 수 있게 되는 것 입니다.
그리고 마지막 부분은 제가 링크를 다는걸 깜빡했네요 .. ㅎㅎ .. 수정했습니다 !