이번에 리뷰할 논문은 FastViT라는 논문입니다. 논문 제목에서 보실 수 있다시피 모델의 경량화에 초점을 맞추고 있습니다. 그리고 해당 논문을 쓴 저자들이 애플 소속이라서 단순히 GPU 뿐만 아니라 iPhone12 pro에서도 속도를 측정하는 모습을 보여줍니다.
Intro
지난 주 리뷰에서, Self-supervised monocular depth estimation task를 빠르고 효율적으로 추론하기 위해 Transformer와 CNN을 하이브리드로 활용하는 방법론에 대해 소개드렸었습니다. 그 때 리뷰에서도 언급을 했지만, Transformer의 Self-attention 방식은 상당히 코스트가 많이 들어가는 연산이라고 했었죠.
그 이유는 self-attention이 영상을 패치로 나누고, 패치들간에 채널축에 대해 내적 연산을 통하여 공간적 정보들 간에 상관관계를 계산하고 있는데, 이는 곧 영상의 해상도에 따라서 Self-attention의 연산량이 제곱해서 늘어날 수 밖에 없기 때문입니다.
실제로 224×224 영상을 입력으로 활용하는 영상 분류 테스크와 달리, downstream task에서는 영상의 해상도가 상대적으로 고해상도이기 때문에 이러한 Self-attention 연산을 수행하는 것은 상당히 많은 비용을 초래하고 있습니다.
그래서 지난 주 리뷰와 비슷하게 CNN과 Transformer를 잘 조합해서 hybrid 형식으로 가보자 라는 연구들도 많이 진행이 되기도 하였고, 아니면 Pyramid ViT처럼 Key와 Value의 차원을 크게 줄이거나, Swin Transformer처럼 local attention을 수행하도록 하는 식으로 방법론들이 꾸준히 제안되어 왔습니다.
FastViT는 굳이 따지자면 Hybrid 구조로 볼 수 있습니다. 논문에서 제안하는 부분들은 모두 Conv Layer와 관련이 있어서 처음에는 ConvNeXt처럼 pure CNN인줄 알았습니다만 마지막 stage에서는 Self-attention을 사용하기 때문에 모델의 명칭을 FastViT라고 지은 것 같네요.
아무튼 이러한 FastViT의 Contribution에 대해서 간략하게 알아보도록 하겠습니다. FastViT의 네트워크 구조적 관점에서 contribution은 다음과 같습니다.
- Skip Connection을 제거한 RepMixer라는 구조를 제안합니다.
- Linear train-time overparameterization을 사용하여 성능을 향상시킵니다.
- Self-attention의 연산량이 많이 소모되는 early stage에서는 Large Kernel Conv layer로 대체하자.
각각에 대해서 자세한 얘기는 바로 밑에 방법론에서 알아보시죠.
Method
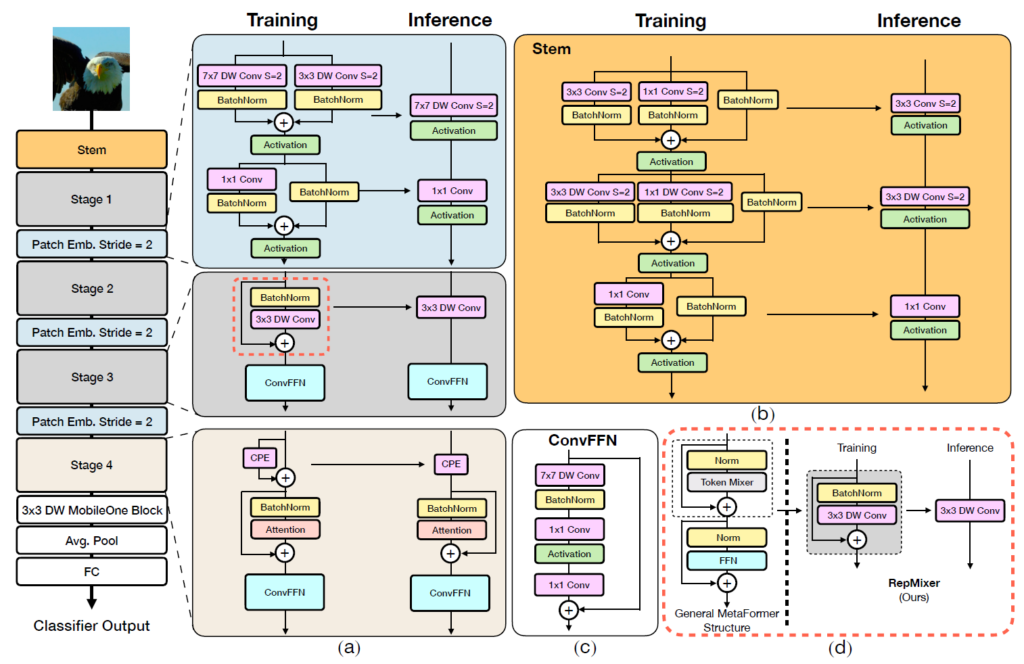
먼저 FastViT의 전체적인 구조는 그림1에서 확인할 수 있습니다. 한가지 눈에 띄는 점은 Training/ Inference 2개로 나누어 표기가 되어 있는 것을 보실 수 있는데, 이는 뒤에서 소개드릴 train-time overparameterization에 대한 결과물입니다. 즉 학습 때는 더 많은 파라미터로 학습을 하고 추론 단계에서는 이들을 제거해버리는 것이죠.
아무튼 그림1에서 a,b,c,d 각각이 의미하는 바에 대해 다뤄보겠습니다.
Reparameterizing Skip Connections
먼저 그림1-d에 대한 내용입니다. FastViT가 구성하고 있는 기본이 되는 block의 전반적인 틀은 MetaFormer라고 하는 방법론에서 차용을 했다고 합니다. MetaFormer의 구조는 그림1-d 점선 기준 좌측에서 확인하실 수 있는데, 해당 구조에서 가장 눈여겨 보실 점은 저 Token Mixer라고 하는 부분입니다.
저 Token Mixer라고 하는 부분이 ViT에서는 Self-attention이 되는 것이며, 작년 CVPR2022 Oral paper에서 PoolFormer라고 하는 방법론은 저 Token Mixer 단에 Pooling을 단순히 수행하는? 식으로 진행이 되었다고 합니다. 제가 PoolFormer라는 방법론을 읽어보지는 못해서 디테일하게 설명을 할 수는 없지만 실제로 논문 그림을 살펴보면 그냥 Token Mixer 부분을 Pooling으로 대체한 것 뿐입니다.
FastViT의 경우에는 저 Token Mixer 부분을 ConvMixer라는 방법론을 조금 수정하여 RepMixer라는 것으로 새롭게 바꾸어 사용했다고 합니다. 먼저 ConvMixer에 대해서 살펴보시죠.
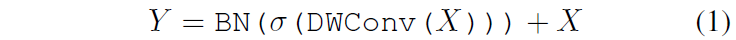
X가 input Patch이면 Depth-Wise(DW) Conv layer를 태우고 비선형 활성화 함수 \theta 를 처리한 후 BatchNorm(BN)을 적용한 뒤 Residual 연산을 진행해주는 매우 단순한 구조입니다.
저자는 이러한 수식1의 ConvMixer를 다음과 같이 수정하였습니다.
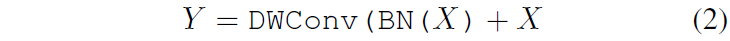
쉽게 말해서 BN을 먼저 수행한 후 DW Conv을 처리하고 Residual 연산을 하는 것이죠. 여기서 활성화 함수는 제거한 것을 볼 수 있습니다. 이렇게 변경하게 된 이유에 대해서 저자는 추론 단계에서 해당 연산들을 reparameterize 할 수 있도록 변경하였다고 하며, 실제로 추론 단계에서는 수식3과 같이 단순히 DW Conv layer만으로 추론이 진행된다고 합니다.
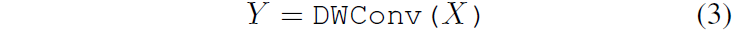
저자는 여기서 수식3의 연산이 Residual Connection이 없다는 것에 대하여 상당히 강조를 하고 있습니다. 사실 저희가 생각했을 때 residual connection은 단순히 element-wise로 더하기만 하면 되기 때문에 연산량도 그리 크지 않고 괜찮지 않나?라는 생각이 드실 수도 있습니다.
하지만 이러한 skip connection은 메모리 액세스 비용을 크게 증가시켜 latency를 크게 하는 원인이 된다고 합니다. 실제로 PoolFormer와의 비교 실험을 통해서 Latency 증가가 얼마나 큰지에 대해서 확인하실 수 있습니다.(그림2 참조)
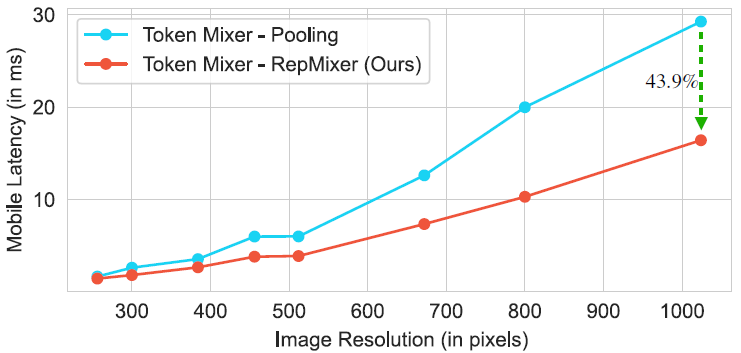
보시면 Token Mixer를 단순히 Pooling을 사용하는 PoolFormer와 Depth Conv를 사용하는 RepMixer에 대하여 연산량 자체는 그리 크지 않겠지만, RepMixer의 경우 Reparameterize를 통해 skip connection이 제거된 반면 Poolformer의 경우에는 Skip Connection을 여전히 활용하기에 latency 차이가 크게 나는 것을 볼 수 있습니다. 특히 이러한 경향성은 영상의 해상도가 커질수록 더 크게 나타나는데 이는 더 많은 메모리를 액세스해야하기 때문이라고 보실 수 있습니다.
Linear Train-Time Overparameterization
다음은 Linear Train-Time Overparameterization과 관련된 내용입니다. 먼저 FastViT는 보다 효율적인 모델을 만들고자 k x k dense convolution들을 모두 factorize하였다고 합니다. 즉 standard CNN을 DW Conv와 Point-Wise Conv layer의 조합으로 변경하는 것이죠.
하지만 이러한 변경점은 사실 MobileNet에서 이미 활용되고 있는 기법이기 때문에 사실 참신성이 많이 떨어지기도 합니다. 하지만 FastVit에서는 기존의 MobileNet에서 사용하는 해당 방식을 그대로 적용할 경우 성능의 드랍이 많이 발생한다고 주장합니다. 즉 너무 적은 수의 파라미터를 factorization하는 것은 모델의 성능을 크게 감소시킨다는 것이었죠.
따라서 factorized layer들의 성능적인 측면을 향상시키고자, 저자는 linear Train-Time Overparameterization이라는 기법을 적용하였다고 합니다. 저기서 overparameterization은 그림1에서 Training / Inference 라는 명칭으로 두 갈래로 표현된 것을 의미한다고 보시면 됩니다.
즉 학습때는 더 많은 레이어와 연산으로 학습을 수행하여 레이어들의 capacity를 늘리고, 이를 추론 단계에서는 간소화함으로써 factorized layer들의 capacity는 최대한 유지한 채 효율성은 크게 향상시킬 수 있다는 것이죠.
다만 이러한 train-time overparameterization은 학습 단계에서 더 많은 연산과 레이어를 사용하기 때문에 학습 시간 및 메모리를 더 많이 잡아먹게 됩니다. 이러한 training cost는 backbone 및 learning 연구에서 상당히 중요하게 여겨지는 요소이기 때문에, 저자들도 이를 의식하였는지 overparameterization 기법을 Stem, Patch Embedding, Projection(RepMixer를 의미하는듯?)에 대해서만 적용하였다고 합니다.
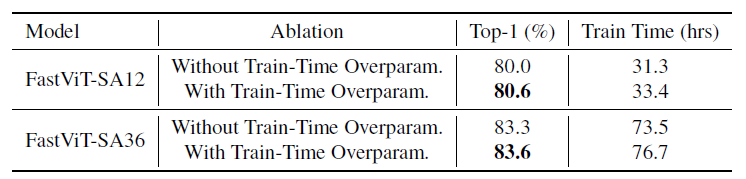
해당 블록들은 스테이지 별로 거의 한번만 연산이 되거나 혹은 연산량이 극히 일부이기 때문에 실제 training cost를 크게 올리지도 않으면서 성능 향상에 많은 이점을 가져온다고 합니다. 예를 들어서, FastViT-SA12라는 모델의 경우 6.7% 밖에 학습 시간이 더 오래 걸리지 않았지만 성능은 0.6 증가한 것을 확인하실 수 있습니다. (아래 표 참조)
Large Kernel Convolution
마지막으로 Large Kernel Convolution에 대한 내용입니다. 해당 부분에 대해서 간략하게 소개를 드리면, Self-attention이 많은 연산량, 특히 고해상도 feature map에 대해서 해상도의 제곱에 해당하는 연산량을 소모하기 때문에 early stage에서는 Self-attention 연산을 수행하기가 부담이 된다고 말씀을 드렸습니다.
이러한 관점에서 DW Conv layer를 large kernel로 연산을 허용하게 될 경우 receptive field를 키우면서도 연산량은 줄일 수 있다고 얘기하는 부분입니다. 사실 이러한 컨셉은 2년전부터 많이 나왔기 때문에 조금은 진부하다고 느껴질 수 있습니다.
실제로 해당 방법론에서 Conv FFN이라는 모듈(그림1-c)을 참고하면 7×7 Depth Conv와 1×1 conv 2개로 구성되는 것을 보실 수 있습니다. 처음에 딱 보았을 때 이거 그냥 ConvNeXt 모듈아닌가?라는 생각이 딱 들었는데 저자도 ConvNeXt와 사실상 거의 유사하다. 다만 LayerNorm을 BatchNorm으로 바꿨다 수준이었습니다. 그래서 구조적 관점에서는 딱히 더 설명드릴 내용은 없을 것 같습니다.
저자는 아래 표와 같이 Self-Attention(SA)과 Rep-mixer FFN(RM)에 대한 ablation을 진행하였습니다.
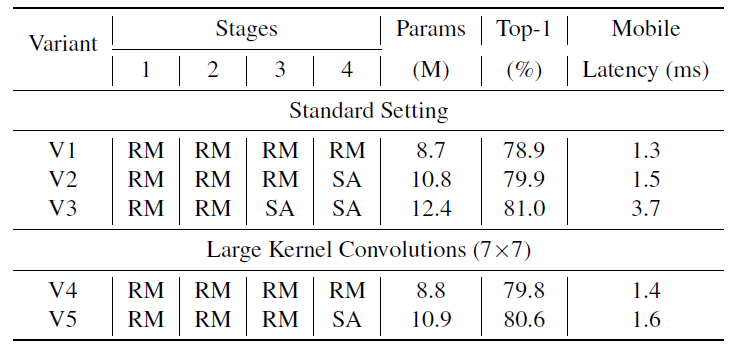
여기서 먼저 V1~V3을 살펴보시면 확실히 Self-Attention이 많이 들어있을수록(즉 V3) 파라미터 수나 latency는 크게 증가하지만 성능이 그 만큼 많이 오른다는 것을 확인하실 수 있습니다.
그리고 아래 Large Kernel Convolution에 해당하는 V4와 V5의 경우에는 각각 V2와 V3끼리 비교를 진행하였을 때 파라미터 수와 latency는 줄면서 성능은 크게 차이가 없는 것을 확인하실 수 있습니다. 특히 V3와 V5의 경우에는 latency 차이가 2배가 넘는 반면에 성능은 0.4% 밖에 차이가 나지 않는다고 저자는 주장합니다.
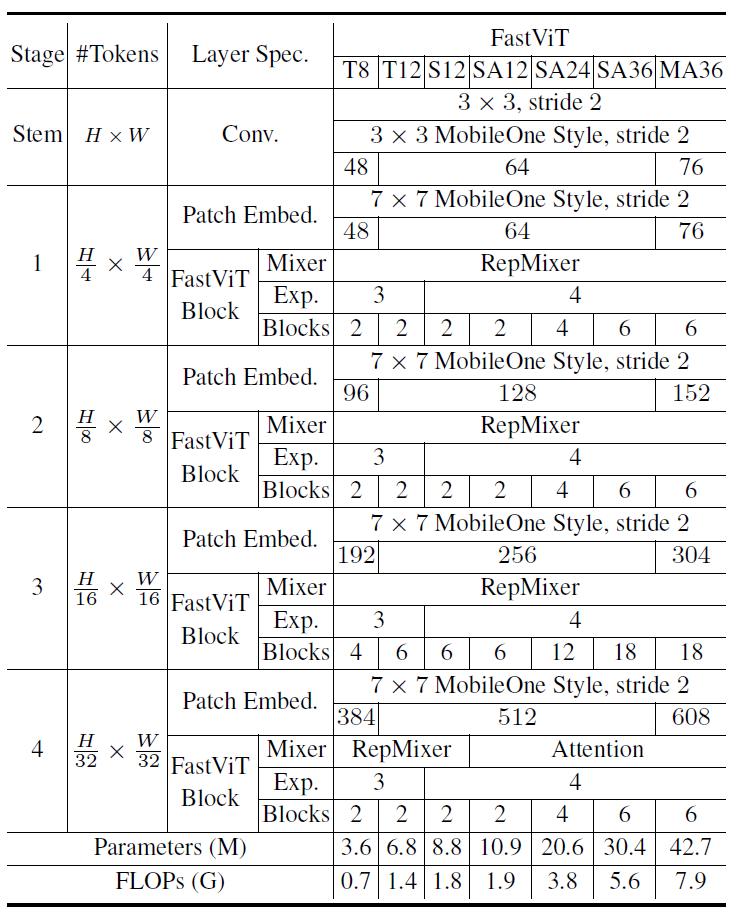
아무튼 이러한 FastViT의 구체적인 모델의 정보는 아래 표를 참고해주시면 좋을 것 같습니다.
Experiments
다음은 실험 결과입니다. 백본 논문들이 대표적으로 보이곤 하는 ImageNet Classification, ADE20K Semantic Segmentation, COCO의 object detection에 대한 결과 정도를 담고 리뷰 마무리 짓도록 하겠습니다.
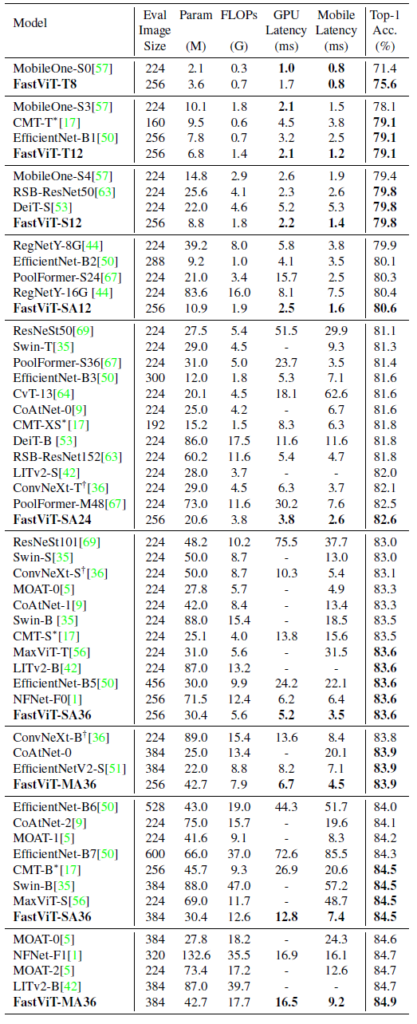
테이블이 일단 너무 길어서 죄송?합니다. 아무래도 경량화에 초점을 맞췄기 때문에 기존 논문들의 Tiny보다도 더 작은 모델들에 대한 결과를 비교하려다보니 비교군이 많아진 것으로 보입니다.
일단 전반적으로 성능은 비슷하면서 모델의 크기와 latency를 크게 줄였다고 설명하는 것이 대부분입니다. 구체적으로 FastViT-MA36은 ConvNext-B와 비교하여 iphone pro12와 PC GPU에서 약 2배 더 빠르고, NFNet-F1과는 66.7%더 작은 모델 크기와 42.8% 더 빠른 속도로 동일한 성능을 달성한다는 것을 보여주고 있습니다.
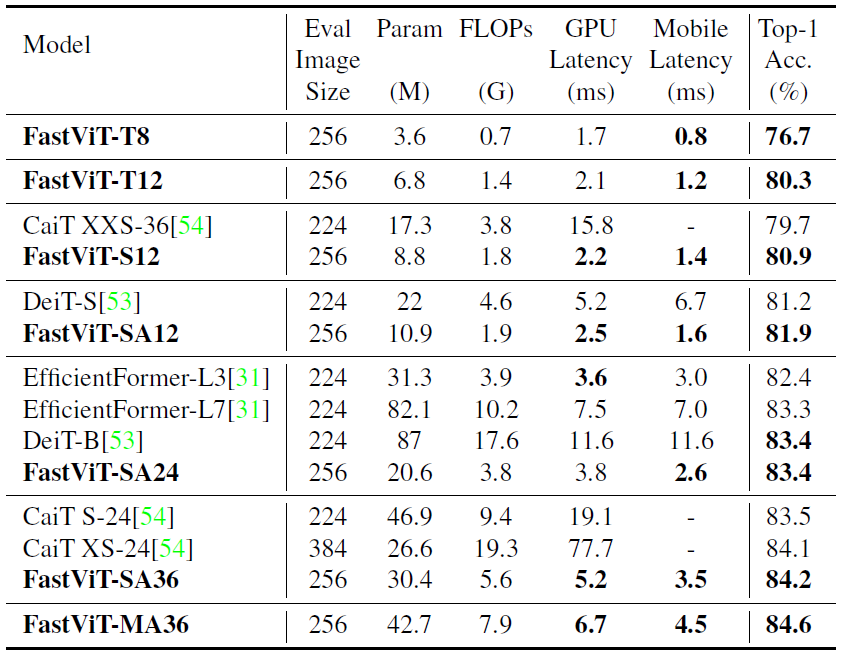
위에 표는 Knowledge Distillation에 대한 결과표입니다. 실험 세팅을 간략히 소개드리면, DeiT 모델을 Teacher model로 삼아서 DeiT의 prediction을 hard label로 만들어 knowledge Distillation을 수행한 것으로 보면 됩니다. 이러한 실험은 보통 잘 안하는 것으로 아는데, 경량화 모델쪽에서는 최근에 수행하는 것 같아 보입니다. 확실치는 않지만, 제가 예전에 듣기로 모델의 크기가 너무 차이가 나면 distillation이 잘 안되더라 라는 결과가 있었는데, 자신들이 경량화한 모델들은 distillation도 잘된다 라는 것을 보여주기 위함이 아닐까 합니다.
결과적으로 더 적은 latency를 가지면서 distillation 성능은 더 좋다 라는 것을 보여주는 표입니다.
Downstream task
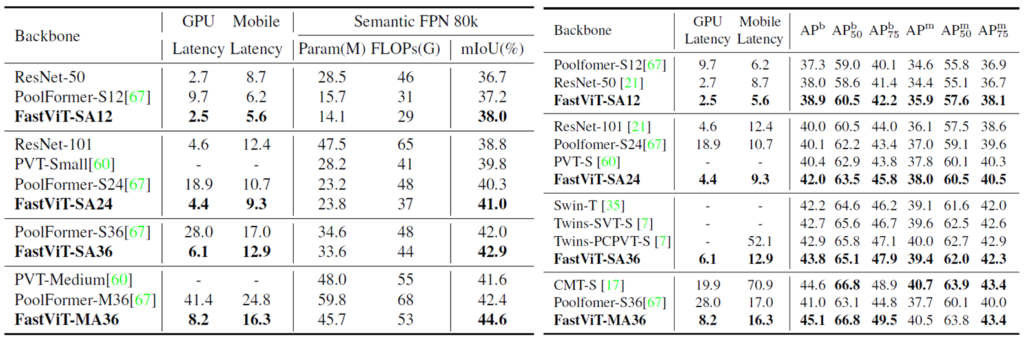
다음은 Semantic Segmentation(좌측)과 Object Detection(우측)에 대한 결과입니다. 보시다시피 성능적은 측면은 물론이고 GPU와 Mobile Latency 역시 상당히 작은 것을 볼 수 있습니다. 특히 PoolFormer랑 비교하였을 때 latency가 GPU에서 5배나 차이가 남에도 불구하고 성능은 훨씬 더 좋은 것을 볼 수 있습니다.
결론
해당 논문의 contribution은 새롭게 고안했다기 보다는 기존의 방법론들을 가져다 활용한게 상당히 많습니다. 하지만 자신이 마주한 문제에 대해서 해결하기 위해 기존의 연구들을 잘 조합하여 만들었으며, 이를 통해 유의미한 성능을 달성했다는 점에서 높은 평가를 받은 것이 아닐까 싶습니다.
리뷰 잘읽었습니다.
생소한 분야라서 잘 모르는 부분이 많았던 것 같아요.
1. 우선 Overparameterization에서 train과 동일한 inference block에서 생략되는 weight들이 어떻게 처리되는 건지 궁금합니다.
2. 그림 2에서 skip connection의 연산량이 많다는 것을 증빙하기 위해 Pooling과 RepMixer를 Mobile latency 측정값으로 비교했는데요. 이게 skip connection 영향에 대한 근거로 보기에는 논리적 비약이 있는 것 같습니다. 다른 실험 결과는 없는 건가요?
3. 쭉 읽어보니 왜 ViT를 붙인건지 이해가 안갑니다. MHA이 있는 것도 아니고… 왜 붙인걸까요?