Before Review
제가 KCCV 2023에 참석하면서 알게 된 논문 입니다. 그전에도 알고 있긴 했지만 구체적인 내용은 몰랐고 이번 KCCV 다녀오면서 저자에게 직접 설명을 들으면서 궁금한 점도 물어보고 했던 연구 입니다.
확실히 한국인이 논문 저자면 영어라도 뭔가 더 친숙하게 잘 읽히는 것 같습니다.
논문의 내용 자체는 어렵지 않지만 Scene Graph Generation이라는 task 자체는 처음 리뷰 하다 보니 저의 설명이 조금 부족할 수 있다는 점 먼저 말씀 드립니다.
리뷰 시작하도록 하겠습니다.
Preliminaries
Multi Head Attention
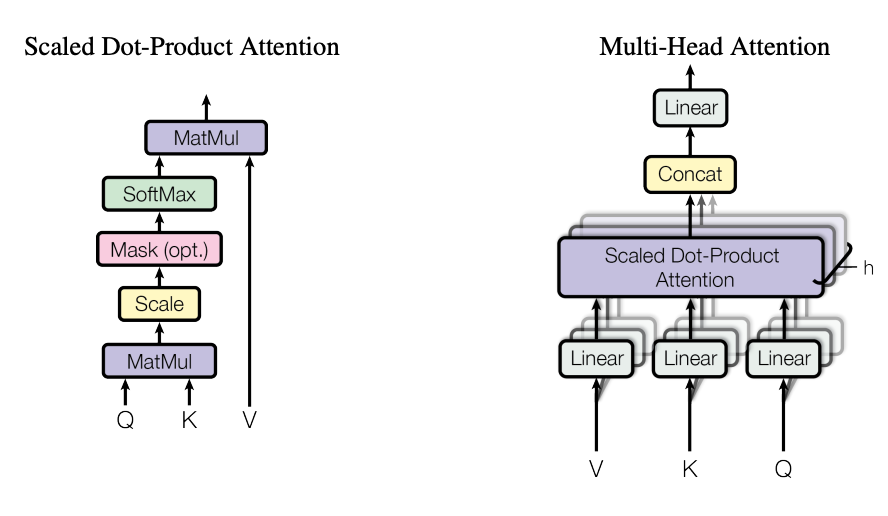
Multi Head Attention(이하 MHA)은 [2017 NIPS] Attention is All you Need 논문에서 제안된 구조로 말 그대로 하나의 Attention Head를 사용하는 것이 아니라 여러 개의 Attention Head를 사용하는 것을 의미합니다.
여러 개의 Attention Head를 사용하는 것은 Attention을 수행할 수 있는 Learnable Matrix를 다양하게 가져가고 이를 통해 더욱 풍부한 표현력을 학습할 수 있음을 의미합니다. 또 다르게 해석하면 정보를 이해하는 관점을 다양하게 가져가겠다는 의미 입니다. 하나의 Head가 하나의 관점을 부여한다면 여러 개 Head가 결국 여러 개의 관점을 제공하는 것이죠.
아래에서 사용하는 그림은 The Illustrated Transformer 에서 가져왔습니다.
Head#0 과 Head#1은 서로 다른 Embedding Matrix로 구성되어 있습니다. 위의 예시는 2개를 사용하고 있지만 Transformer 논문에서 default 값은 8개로 사용합니다.
이렇게 하나의 헤드 마다 하나의 self-attention이 적용된 output이 생성 됩니다. 이를 모두 concat 해주고 또 learnable matrix를 곱해주어 원래의 입력과 차원을 맞춰줍니다.
그래서 이를 시각화 해서 표현을 해보자면 it라는 단어에 대해서 attention을 계산할 때
- 첫 번째 Head는 The animal didn’t cross 에 집중하고
- 두 번째 Head는 it was too tired 에 집중하고 있습니다.
이렇게 MHA는 집중하는 부분에 대한 관점을 더욱 풍부하게 가져갈 수 있도록 해주어 더욱 효과적인 attention 을 가능하게 만든 구조라고 보시면 됩니다.
Introduction
Scene Graph Generation은 이미지를 설명하는 그래프를 생성하는 작업 입니다. 그래프라 함은 node와 edge로 정의가 될 수 있는데 이미지를 설명하는 그래프에서는 node가 object가 되고 edge가 이러한 object들 간의 relation을 나타내게 됩니다.
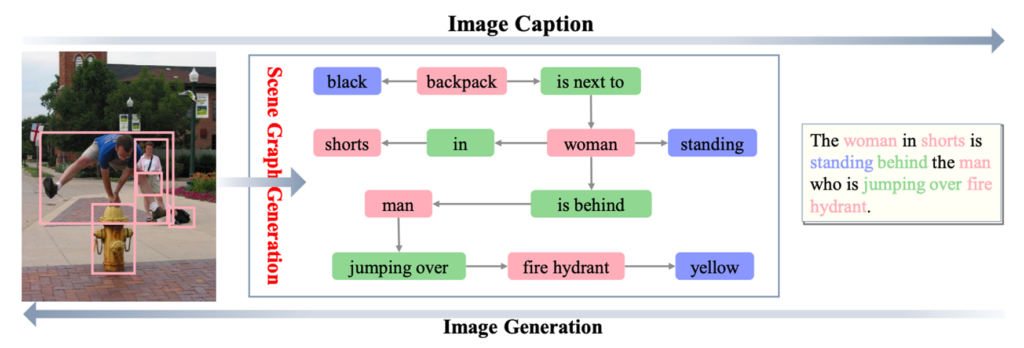
이러한 Scene Graph는 이미지의 의미론적 구조에 대한 높은 레벨의 reasoning을 요구로 하는 task입니다. 특히 Scene Graph를 학습 하는 과정에서 발생하는 representation을 이용해 다양한 vision task (Visual Question Answering, Image Captioning, Image Retrieval…)에서 Graph 구조가 활용 되고 있습니다.
이미지를 이해하는 과정에서 중요한 역할을 하다 보니 computer vision 연구 커뮤니티에서 요즘 활발하게 연구가 되고 있는 추세 입니다. 연구가 많이 이루어지고 있는 상황이지만, 아직 practical usage 까지는 어려운 상황이라고 합니다.
다양한 어려움이 존재하고 있지만 저자가 특히 주목하고 있는 부분은 바로 irrelevant relation이라고 하네요.
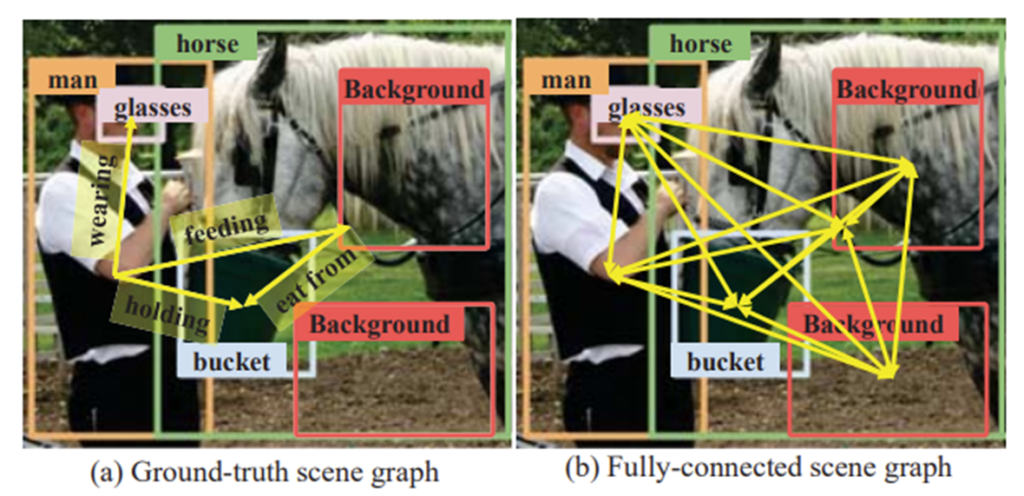
위의 그림을 한번 주목해서 살펴보도록 하겠습니다.
(a) Ground-truth scene graph에서는 4개의 edge가 존재하고 있습니다. 이 장면을 설명하는 relation은 4개로 정의된다는 것 입니다.
(b) Fully-connected scene graph는 무슨 상황이냐면 모든 object 간의 완전한 연결을 가정하고 있는 상황입니다. 학습이 일단 이러한 완전한 연결을 가정하고 신경망을 학습 시켜서 실제 의미 있는 연결만 살리는 방향으로 이루어지는데, 이는 노이즈 할 수 있겠죠.
기존의 연구들이 Fully connected scene graph에서 출발하여 학습이 되었는데 실제로 ground truth edge는 굉장히 sparse 합니다. 결국 이러한 Gap을 줄이는 것이 본 논문의 아이디어라고 보시면 됩니다.
저자는 이러한 이슈를 해결하기 위해 Selective QUad ATtention Network (이하 SQUAT..!!!)를 제안 합니다.
SQUAT는 두 가지 모듈로 구성되어 있습니다.
- Edge Selection Module : Scene Graph를 생성할 때 contextual reasoning을 방해하는 irrelevant object pair를 제거하는 역할을 합니다. 간단하게 설명하면 edge 정보를 토대로 이 relation이 의미가 있는지 없는지 예측하는 모듈이라 보시면 됩니다.
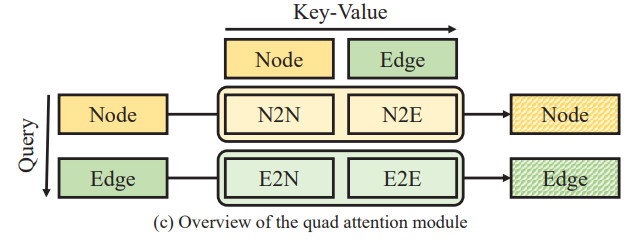
- The Quad Attention Module : Scene Graph를 생성하기 위해서 가장 중요한 것은 edge 정보 입니다. Edge 정보가 결국 의미론적 정보를 담당하기 때문에 올바른 표현력을 가져야 제대로 된 그래프를 생성할 수 있겠죠. 이러한 edge 정보를 update 해주기 위해 많은 연구에서 attention 기법(edge-to-edge, node-to-node)을 사용해주고 있습니다. 본 논문에서는 E2E, N2N 뿐만 아니라 node-to-edge, edge-to-node와 같은 cross attention을 활용하여 contextual information을 더욱 잘 capture할 수 있는 구조를 제안합니다.
이렇게 두 가지 모듈을 통해 SQUAT는 Visual Genome, Open Images v6 benchmarks에서 state-of-the art를 달성하며 특히 SGDet setting(가장 현실적이고 어려운)에서도 주목할만한 개선 정도를 보여준다고 합니다.
논문에 대한 간단한 설명은 여기서 마치고 이제 제안하는 방법론에 대해서 살펴보도록 하겠습니다.
Problem Definition
저 혼자 읽었을 때는 읽지 않고 넘어갔지만 X-Review에는 처음으로 등장하는 주제이다 보니 간단하게 한번 짚고 넘어 가도록 하겠습니다.

결국 Scene Graph Generation의 목적은 이미지 (I가 주어지면 이를 설명하는 graph (G=(O,R))을 생성하는 것이죠. 여기서 O는 object 들의 집합이며 R는 relation 들의 집합입니다.
- 임의의 객체 o_{i} \in O는 객체를 나타내는 bounding box의 좌표인 b_{i} \in [0,1]^{4}와 class label인 c_{i} \in C로 구성되어 o_{i}=(b_{i}, c_{i})로 정의 됩니다.
- 임의의 관계 r_{k} \in R는 subject o_{i} \in O와 object o_{j} \in O 그리고 그들의 관계를 나타내는 predicate label p_{ij} \in P로 구성되는 triplet : r_{k}=(o_{i}, o_{j}, p_{ij})으로 정의 됩니다.
Selective Quad Attention Networks
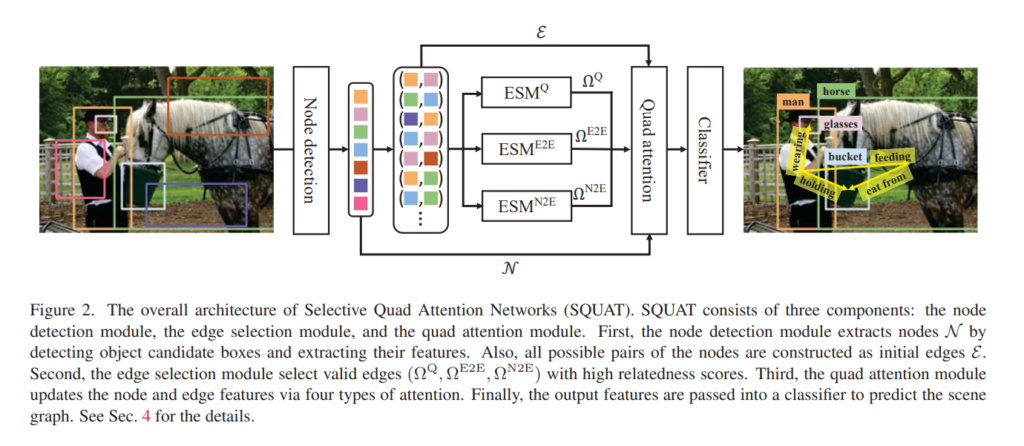
저자는 의미론적으로 유용한 scene graph를 생성하기 위해 세가지 component로 구성된 SQUAT를 제안합니다.
Node detection for object candidates
이미지 I가 주어지면 pre-trained object detector Faster R-CNN을 사용하여 object bounding box와 그들의 class label을 추출합니다.
결국 Faster R-CNN을 통해 임의의 객체 o_{i}에 대해서 bounding box 좌표 b_{i} \in [0,1]^{4}와 visual feature v_{i} \in \mathbb{R}^{d_{v}}에 대한 정보를 추출할 수 있겠죠.
이 때 그래프를 구축할 수 있게 node를 만드는 방법은 간단합니다.
box좌표와 visual feature를 각각 embedding후 concat 하고 다시 embedding 시키는 것 입니다.
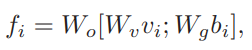
이 때 W_{o}, W_{v}, W_{g}는 linear projection matrix라 보시면 됩니다.
그리고 edge feature는 이러한 node feature를 concat 하고 embedding 시킨 형태로 사용해주곤 합니다.
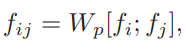
결국 Faster RCNN으로 부터 추출한 object box와 visual feature를 토대로 concat과 linear embedding을 통해 node와 edge feature를 정의해주고 있습니다.
Edge Selection for relevant object pairs
Node feature N와 edge feature E들이 attentive message passing을 통해서 업데이트 되겠지만 대다수의 irrelevant edge들이 attention process를 방해할 수 있습니다.
따라서 저자는 존재하지 않거나 잘못 관계를 예측한 invalid edge를 Quad Attention 직전에 pruning 해주는 방법을 제안합니다. 방법은 굉장히 간단합니다. 임의의 node i, j를 연결해주는 edge feature f_{ij}를 입력으로 받아서 간단한 MLP에 태워서 relatedness score를 계산하는 것 입니다.
그리고 relatedness score에서 상위 top-p%에 해당하는 edge만을 살려서 Quad Attention Module로 넘겨주는 것이죠.
그럼 학습은 어떻게 진행이 되냐면 이진 분류를 통해 학습이 진행 됩니다. 우리가 relation 정보에 대해서는 label이 있으니 edge 들마다 relation이 존재하는지 존재하지 않는지를 사전에 알 수 있습니다.
그리고 edge마다 MLP를 태워서 이 edge가 원래 특정한 relation이 있는 edge 였다면 1, 아니라면 0 이런식으로 BCE Loss를 통해서 학습을 시키고 Sigmoid 처리된 가장 끝단의 score를 relatedness score로 사용해주는 구조 입니다.
저자는 세 가지의 edge selection 모듈 : \textup{ESM}^{Q}, \textup{ESM}^{N2E}, \textup{ESM}^{E2E}을 사용합니다.
목적이 각각 조금 다른 selection module 입니다. \textup{ESM}^{Q}는 Quad Attention 과정에서 Query로써 사용할 edge들을 필터링 하기 위한 모듈이며 비슷하게 \textup{ESM}^{N2E}, \textup{ESM}^{E2E}들은 Quad Attention 과정에서 key, value를 담당해줄 node와 edge들을 필터링 하기 위한 모듈입니다.
각각 목적이 조금씩 다르기에 당연히 다른 MLP를 사용합니다.
Quad attention for relationship prediction
앞서 설명 했지만 Quad Attention은 N2N, E2E, N2E, E2N와 같이 Node와 Edge 간의 모든 맥락을 고려하는 attention 방식이라 했습니다. 전체적인 구조는 Multi-Head Attention(MHA) 과 동일합니다.
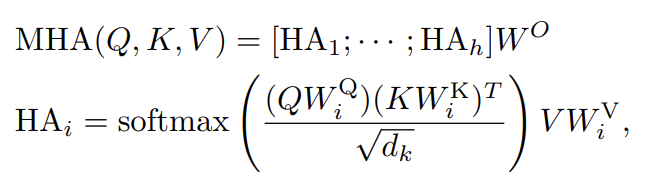
위의 수식은 MHA를 나타내는 수식 입니다. 변형되는 부분 없이 그대로 사용해주고 있네요.
이러한 MHA 연산과 Transformer decoder의 구조를 그대로 차용하여 Quad Attention을 제안해주게 됩니다. Transformer decoder 처럼 t번째 Quad Attention Layer는 t-1번째 Edge feature E_{t-1}과 Node feature N_{t-1}를 입력으로 받고 self-attention을 먼저 진행합니다.
이때 Edge 같은 경우는 모든 possible edge feature를 update 해주는 것이 아니라 \textup{ESM}^{Q}로 부터 추출된 edge feature E_{t-1}^{Q}만을 업데이트 해줍니다.
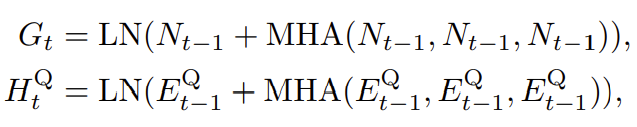
위의 수식은 Node feature N_{t-1}의 self attention된 G_{t}와 필터링 된 Edge feature E^{Q}_{t-1}의 self attention 된 H^{Q}_{t}를 나타내주고 있습니다.
다음으로 N2E, E2E attention을 위한 key-value edge feature들을 정의해주기 위해 아래와 같은 연산을 취해줍니다.
- \mathcal{H}_{t}=\mathcal{H}_{t}^{Q}\cup (\mathcal{E}-\mathcal{E}^{Q})

Node feature N_{t-1}를 가지고 self attention된 G_{t}는 다시금 N2N, N2E attention을 통해서 갱신이 되고 있으며
Edge feature E_{t-1}를 가지고 self attention된 H^{Q}_{t}는 E2N, E2E attention을 통해서 갱신이 되고 있습니다.
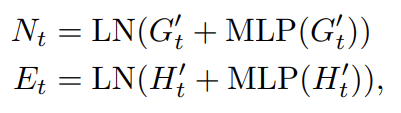
마지막으로 G'_{t}와 H_{t}^{Q'}는 MLP와 residual connection 그리고 Layer Normalization을 통해서 Quad Attention이 마무리 되게 됩니다.
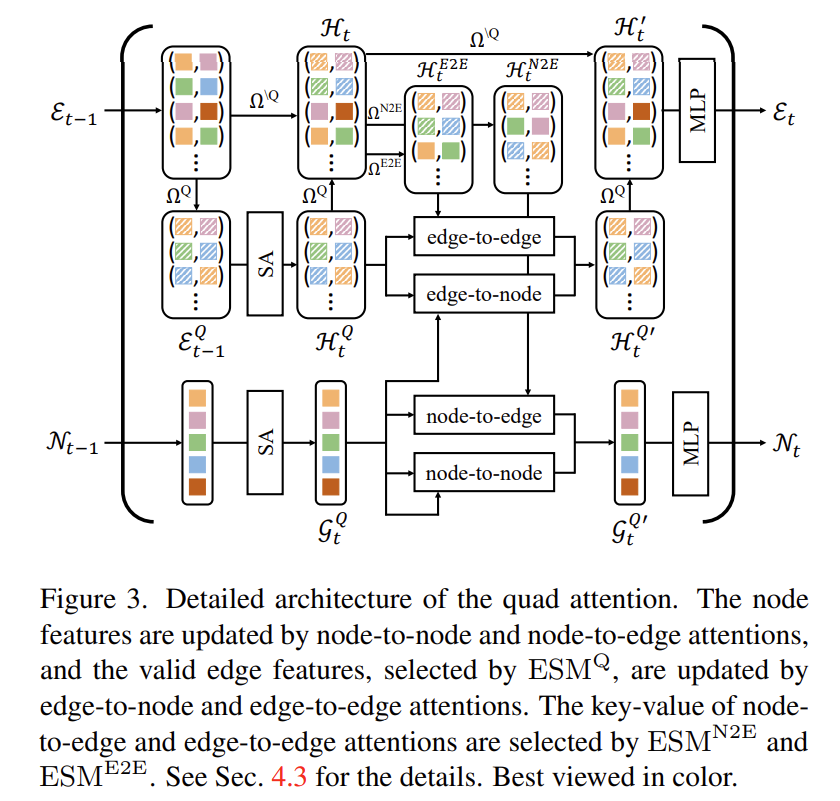
전체적인 그림은 위와 같은데 저는 복잡해서 제대로 보지는 않았습니다..ㅎ
Training Objective
SQUAT를 학습 시키기 위해서는 두 가지 loss 함수를 사용해주고 있습니다.
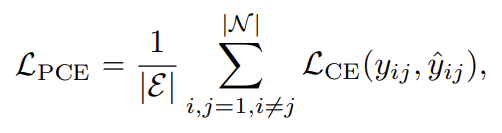
우선 SGG에서 사용하는 가장 기본적인 predicate classification loss 입니다. object i , j 간의 관계를 나타내는 ground truth와 비교하여 올바르게 관계 카테고리 정보를 예측했는지 보는 것이죠.
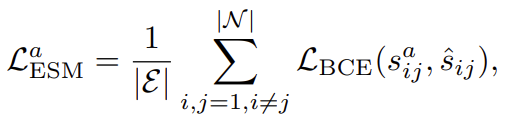
다음으로는 Edge Selection Module을 학습 시키기 위한 Loss 입니다. 여기서 라벨이 \hat{s}_{ij}인데 이는 binray indicator로 두 object i , j 간의 관계가 있는지 없는지를 나타내는 값 입니다.
여기서 \mathcal{L}_{PCE}로 발생하는 gradient는 ESM 학습에 관여하지 않게 됩니다. 왜냐하면 relatedness score를 바탕으로 상위 p%의 edge만을 hard thresholding하기 때문에 미분이 불가능해져 gradient가 끊기는 것이죠.
따라서 Edge Selection Module의 학습은 \mathcal{L}_{ESM}^{a}로만 이루어지게 됩니다.
Experiments
Comparison with state-of-the-art models
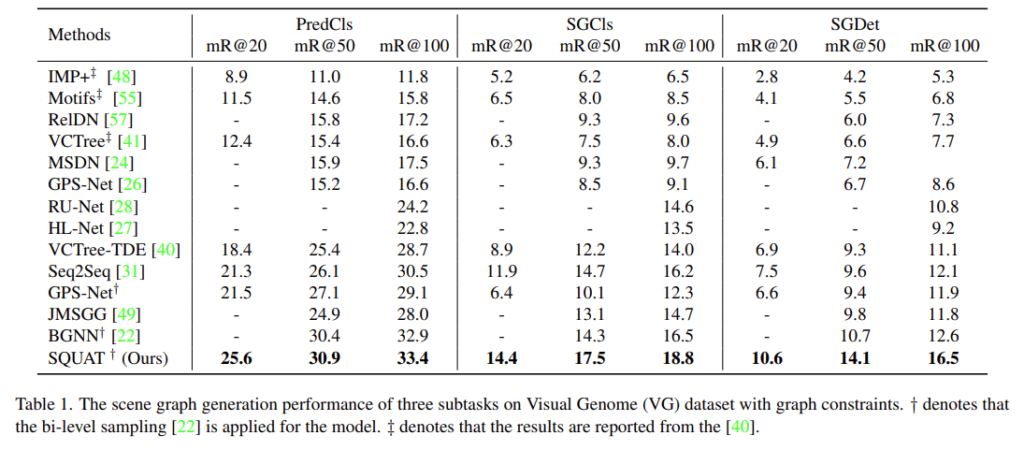
Visual Genome이라는 데이터 셋에서 제안하는 SQUAT가 모든 지표에서 좋은 성능을 보여주고 있습니다. 특히 SGDet mR@100 지표에서 3.9라는 큰 차이로 개선 정도를 보여주고 있는 것은 인상 깊다고 저자가 밝히고 있습니다. 이러한 이유가 SGDet 세팅에서는 다른 세팅에 비해 detected object 끼리의 invalid pair가 더 많은 상황이라 다른 연구들은 이러한 문제를 해결할 방법이 없었지만 SQUAT는 ESM을 통해 이러한 문제를 해결할 수 있어 좋은 성능을 보여준다고 합니다.
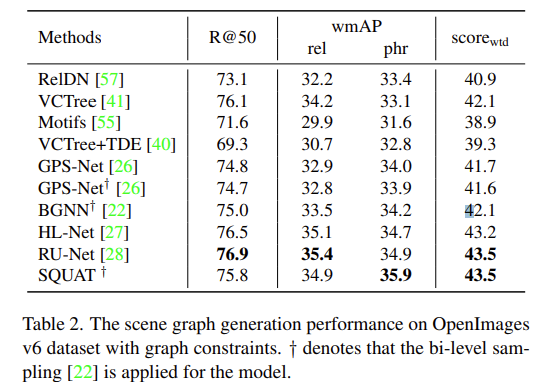
OpenImages v6 dataset에서는 모든 부분에서 sota는 아니지만 비견할만한 성능을 보여주고 있습니다. 이 데이터 셋의 특징은 Visual Genome에 비해 더 적은 object와 relation이 존재하기 때문에 ESM이 그다지 효과적으로 작용하지 못했다고 합니다.
Ablation Study
Model variants on edge selection
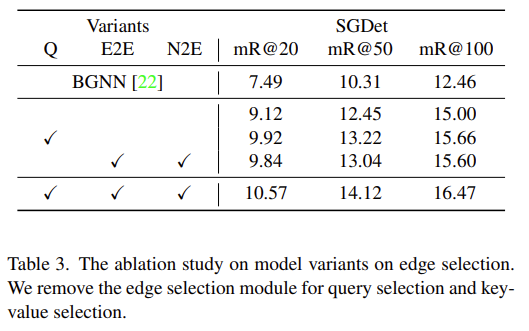
우선 Quad Attention을 수행함에 있어 Edge Selection을 제외 했을 때를 가정하고 실험하고 있습니다. Q, E2E, N2E에 대한 Edge Selection을 모두 하지 않았을 때 성능이 SGDet mR@100 기준에서 16.47 -> 15.00으로 하락하고 있습니다.
SGG 분야를 잘 모르다보니 drop이 많이 일어나는 것인지는 잘 모르겠습니다.
Model variants on quad attention
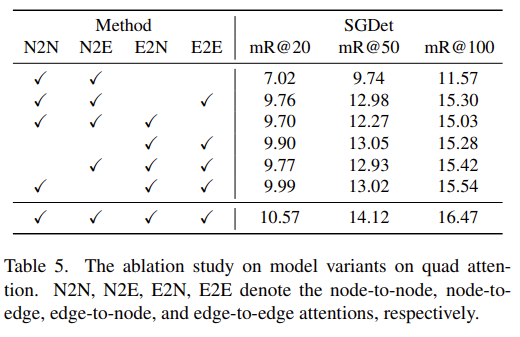
Quad Attention에 대한 ablation 입니다. 결과적으론 다 적용했을 때 가장 좋은 성능을 보여주고 있습니다.
한 가지 알게된 것이 SGG 과정에서는 node feature 보다는 edge feature가 더 중요하게 작용하는 듯 합니다.
Edge feature에 대한 attention을 다 빼버리면 성능 drop이 크게 일어나는 반면, 하나라도 포함을 시키면 성능이 많이 올라가는 것을 보여 SGG의 핵심은 edge에 있는 것 같습니다.
Conclusions
읽으면서 느꼈지만 논문 컨셉이 저희 VVS랑 굉장히 많이 비슷하다고 느꼈습니다. 본 논문은 irrelevant 한 edge를 필터링 하고 이를 활용한 attention 구조를 제안하였고 저희 VVS도 마찬가지로 irrelevent 한 frame을 필터링 할 수 있는 Module과 이를 효과적으로 학습할 수 있는 추가적인 구조를 제안하였습니다.
저희 분야가 Video Retrieval만 아니었더라면 붙었을까요..?? 흑흑..
그와는 별개로 Scene Graph Generation이라는 연구 분야도 참으로 흥미롭게 느껴집니다. 아직 challenging한 포인트도 많고