Abstract
3차원의 object pose를 annotation하는 것은 2D bounding box를 라벨링하는 것에 비해 어렵고, depth정보가 주어지지 않을 경우에는 더 어려운 문제입니다. 본 논문에서는 depth 이미지를 사용하지 않고, 2D bounding box와 RGB 이미지를 이용하여 object의 pose를 예측하는 방식입니다. 제안하는 방법은 2-step의 과정으로 구성되며, 먼저 weakly supervised 방식으로 object 영역을 segmentation을 합니다. 그 다음, dual-scale pose estimation 네트워크인 DSC-PoseNet을 이용하여 pose를 예측합니다. DSC-PoseNet은 원본 이미지 scale에서 segmentation 마스크와 렌더링된 visible object mask를 비교하여 pose를 예측합니다. 그 다음, 객체 영역의 크기를 고정된 scale로 변경하여 pose를 다시 추정합니다. 이렇게 2 scale에서 추정하는 과정을 통해 variation을 제거할 수 있고, rotation에 더 집중할 수 있다고 합니다. 이를 통해 당시 real pose annotation 정보를 이용하지 않은 방법론 대비 SOTA를 달성하였으며, supervised 방식과 비교하였을 때도 좋은 성능을 보이는 것을 확인하였습니다.
Introduction
6D pose estimation은 translation과 rotation을 예측하는 task입니다. object는 occlusion이나 조명 변화에 의해 정확한 pose를 예측하기 어려우며, 최근에는 딥러닝을 통해 상당한 발전을 이루었습니다. 그러나, 딥러닝 네트워크를 학습하기 위해서는 대량의 학습 데이터가 필요합니다. 그러나 6D pose에 대한 라벨링 작업은 굉장히 어려우며, 3차원 정보가 주어지지 않으면 정확한 라벨링을 수행하기 어려워집니다.
합성 데이터의 경우, pose 정보는 구하기 쉬워지지만, 실제 데이터와 합성 데이터 사이의 차이로 인해 성능 저하가 발생합니다. 이러한 이유로, 저자들은 최소한의 annotation(2D bounding box)을 통해 real 이미지와 합성 이미지 사이의 gap을 줄이고자 하였습니다.
본 논문에서는 2D annotation 정보를 이용하여 object의 pose를 예측하는 2-step 프레임워크를 제안합니다. 먼저, object 픽셀과 background 픽셀을 구분하기 위해 weakly-supervised 방식의 segmentation을 이용합니다. 합성 이미지로 segmentation 네트워크를 학습하여 네트워크를 초기화합니다. 학습된 segmentation 네트워크를 이용하여 unlabeled real 데이터에 대해 pseudo mask를 생성하고, 이렇게 구한 real-data와 합성 데이터를 함께 이용하여 segmentation 네트워크를 재학습시킵니다. 이때 2D bounding box를 활용하여 배경이 foreground로 예측되는 이상치를 제거하여 보다 정밀한 학습이 가능하도록 하였다고 합니다. 이렇게 학습된 네트워크는, pose를 예측할 때 사전 정보를 제공하는 역할을 하게 됩니다.
그 다음, dual-scale pose estimation 네트워크인 DSC-PoseNet을 제안하여 pose를 추정합니다. DSC-PoseNet도 합성 이미지를 이용하여 네트워크를 초기화 한 후, 원본 scale에서 object의 pose를 추정합니다. DSC-PoseNet은 각 픽셀과 keypoint의 offset을 regression으로 예측하며, 이때 keypoint는 attention map을 이용하여 구합니다. 그 다음, 랜더링된 object mask를 구하여 앞서 구한 segmentation과 비교하여 교집합된 영역을 이용하여 real 데이터로 DSC-Pose 네트워크를 학습시킵니다. real 이미지의 pose가 구해지면, object 영역을 정해진 크기로 resize하여 self-supervised 방식으로 DSC-PoseNet을 학습시킵니다. 이를 통해 DSC-PoseNet의 feature extractor는 다양한 scale에서 pose 예측 결과가 일정하도록 학습합니다.
DSC-PoseNet은 2 scale에서의 pose 추정 결과로, 이 두 결과에 대한 앙상블을 통해 예측의 일관성을 높였으며, 3개의 밴치마크에서 real pose annotation을 이용하지 않는 방법론들 대비 SOTA를 달성하였습니다.
본 논문의 contribution을 정리하면
- 비교적 구하기 쉬운 2D bounding box를 이용하여 단일 RGB 이미지에서 object의 pose를 예측하기 위한 weakly-/self-supervised 기반의 pose estimation 프레임워크를 제안
- self-supervised 방식의 DSC-PoseNet을 제안하여 합성 데이터와 real 데이터 사이의 gap을 줄일 수 있는 pose estimation을 제안
- 저자들에 따르면, 3D pose annotation과 depth 정보를 사용하지 않고 RGB 이미지에서 object pose를 추정한 것은 저자들이 처음이었으며, 단순히 합성 데이터를 이용한 방법론들과 비교했을 때 더 우수한 성능을 보임
Proposed Method
Overview
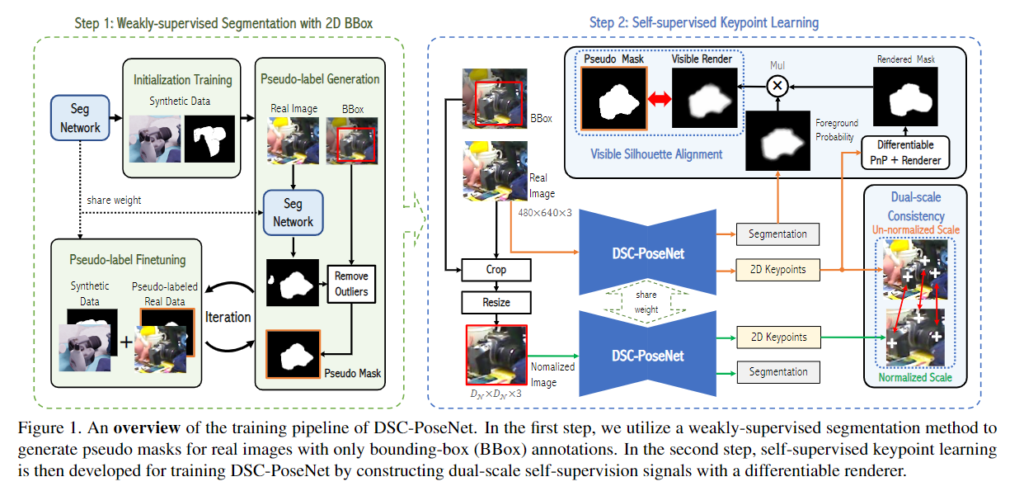
위의 Figure 1은 2-step의 pose estimation 프레임워크로 해당 파트에서는 segmentation과 pose estimation 두 단계에 대해 설명합니다.
1. Weakly-supervised Segmentation with BBox
먼저 첫번째 단계는 2D bounding box를 이용하여 weakly-supervised Segmentation을 학습하고, segmentation 네트워크를 통해 object의 대략적인 윤곽 정보를 구하고자 합니다. 이때 제공되는 2D BBox 정보는 object 영역을 완전 타이트하게 맞추었다고 가정하지 않아, 라벨링의 제약을 완화하였습니다.
본 과정에서는 반복적으로 segmentation 네트워크를 학습하는 방식을 이용합니다. 먼저 합성 데이터로 segmentation 네트워크를 초기화 한 후, Bbox를 이용하여 실제 이미지에 대한 pseudo mask를 생성하고, pseudo-label을 구한 real 데이터를 이용하여 segmentation 네트워크를 fine-tuning합니다.
Pseudo-label generation and fine-tuning
합성 데이터를 이용하여 초기화된 segmentation 네트워크를 이용하여 전체 real 데이터에 pseudo mask를 구합니다. 이때, BBox를 이용하여 배경 영역이 전경으로 예측되는 outlier를 제거하고 fine-tuning을 수행합니다. 그 다음 낮은 신뢰도를 갖는 픽셀은 불확실한 픽셀로 설정하여 loss를 계산할 때 영향을 주지 않도록 합니다. x는 이미지, y는 segmentation map이라 할 때, m∈\{ 1, ... ,M \}은 불확실한 픽셀 집합으로, 아래의 식(1)으로 정의한 것입니다.
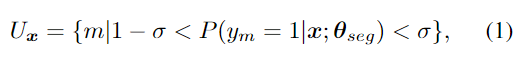
- y_m∈\{ 0,1 \}: 픽셀의 class (전경, 배경)
- \theta _{seg} : segmentation 네트워크
- P: confidence score
- \sigma: threshold로, 본 논문에서는 실험적으로 0.7로 설정
아래의 식은 pseudo-labeled real 이미지 x_{real}을 이용하여 fine-tuning을 할 때 사용하는 segmentation의 loss function으로, 아래의 식(2)으로 정의됩니다.
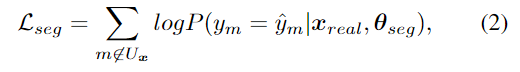
\hat{y}_{m}은 pseudo label을 의미하며, 불확실한 픽셀 집합에 대해서는 loss를 계산하지 않도록 설계되어 있습니다.
이 과정은 네트워크가 수렴될 때 까지 T번 반복하며, 저자들은 실험적으로 T=5일 때가 학습 효율과 성능을 비교했을 때 적절하였다고 합니다.
본 논문에서 제안된 방식은, 기존의 합성 데이터를 이용하는 6D pose estimation 방법론과 비교하였을 때, 기존 합성 데이터를 이용하는 방식은 사실적인 합성 데이터를 생성하도록 하지만, 저자들은 2D bounding box를 이용하여 합성 데이터와 real 데이터 사이의 domain gap을 줄일 수 있었다고 합니다.
2. Self-supervised DSC-PoseNet
본 논문은 기존 연구들이 많이 사용하는 keypoint 기반의 pose estimation 방식을 이용합니다. pose를 추정하기 위해 2D-3D correspondence를 구하고 PnP 알고리즘을 이용하여 pose를 추정하는 방식이지만, 해당 방법론은 3차원 GT Pose가 없으므로 real 데이터에서는 실제 keypoint 위치를 알 수 없습니다. 따라서, 저자들은 keypoint의 위치를 예측하기 위해 self-supervised dual-scale consistency pose estimation 방법론인 DSC-PoseNet을 설계하였습니다. 추정된 keypoint를 이용하여 pose를 예측하는 방식으로, 정규화된 scale과 정규화되지 않은 scale 모두에서 keypoint를 예측하며, 두 scale의 keypoint의 일관성을 갖도록 학습을 시킵니다.
Differentiable keypoint regression
먼저 기존 연구를 살펴보면, DSNT[1]는 spatial heatmap의 좌표 평균을 이용하였지만, 가려진 keypoint에 대해서는 대응하지 못하였고, PVNet[2]은 각 keypoint에 대한 vector field를 예측하고 voting을 이용하여 keypoint를 결정하지만 voting이 미분 불가능하여 vector field representation을 학습하지 못하였습니다.
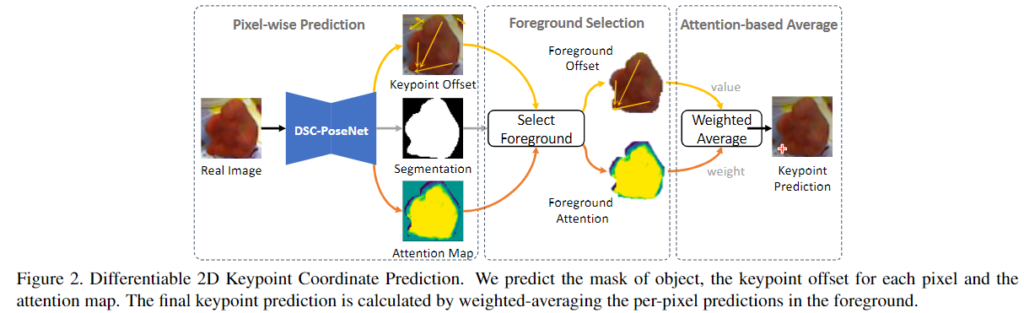
이를 해결하고자 2D keypoint 좌표를 regression하는 방법을 제안합니다. 과정은 Figure 2에 도식화 되어 있으며, 각 2D keypoint k_n(n=1, ..., N)와 m 위치에서의 각 object 픽셀의 좌표 p_m에 대해 DSC-PoseNet은 attention 가중치 a_{nm}를 생성하고 keypoint offset \Delta k_{nm}를 예측합니다. 이렇게 예측된 keypoint \tilde{k}_{n}은 아래의 식으로 나타낼 수 있습니다.
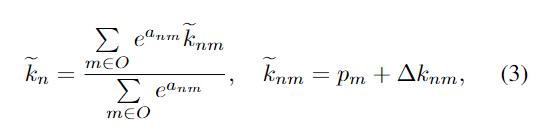
- O: DSC-PoseNet에서 예측된 전경영역
- \tilde{k}_{nm}: 픽셀 p_m에서 예측된 keypoint
합성 데이터에 대해서는 정확한 keypoint k_n를 구할 수 있고, smooth l1을 이용하여 k_n를 학습합니다.
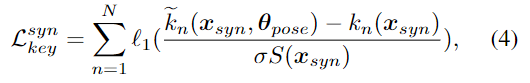
- \theta _{pose} : DSC-PoseNet의 파라미터
- \sigma: scale factor
- S: BBox의 가장 긴 변의 길이로 정의된 object scale
객체가 클 수록 keypoint 예측시 분산이 커지므로, keypoint 예측 오차를 정규화하기 위해 S를 이용하여 정규화를 수행한다고 합니다. 이를 통해 네트워크가 안정적으로 학습이 되는것을 관찰하였다고 합니다.
또한, keypoint에 대한 loss 외에 추가로 offset에 대한 loss도 도입하였으며 loss 식은 아래와 같습니다.
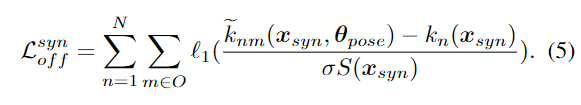
해당 식을 통해 DSC-PoseNet이 모든 전경 픽셀에서 정확한 keypoint를 regression할 수 있도록 하여, DSC-PoseNet을 초기화합니다.
Dual-scale keypoint consistency
real 데이터에 대해서는 pseudo label만을 가지고 있으므로, self-supervised 방식을 이용하여 pose annotation 없이 real 데이터에 대한 keypoint를 학습합니다. DSC-PoseNet은 2개의 scale에서 keypoint를 예측하지만, 예측된 keypoint는 크기에 상관 없이 일관성을 가져야 합니다. 따라서 keypoint 추정의일관성을 위해 제약조건을 도입하였습니다.
이미지 x가 주어졌을 때, 객체 영역을 잘라내고 고정된 크기인 D_{\mathcal{N}} ⨉D_{\mathcal{N}} 로 scale을 조정하여 정규화된 크기로 변환합니다. 2D keypoint는 아래의 변환 식을 따라야 합니다.(수식에 대한 의미를 풀어보자면, 정규화된 이미지로 구한 keypoint에 대하여 원본 크기로 다시 변환시켰을 때, 원본크기의 이미지로부터 구한 keypoint와 동일해야한다는 것입니다.)
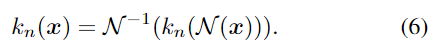
예측 오류를 줄이며 3차원 구조 정보를 활용하기 위해 예측된 2D keypoint에서 object pose를 구한 뒤, CAD 모델의 3D keypoint를 앞서 구한 pose를 이용하여 2D 이미지로 투영시킵니다.
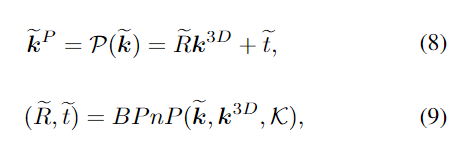
- 투영된 keypoint는 ^P, CAD 모델에서 구한 3D keypoint는 ^{3D}
- \mathcal{K}: 카메라 intrinsic 파라미터
real 데이터에 대한 DSC-PoseNet의 loss는 아래의 식으로 정의되며, keypoint error를 정규화하기 위해 객체의 scale S를 이용합니다.
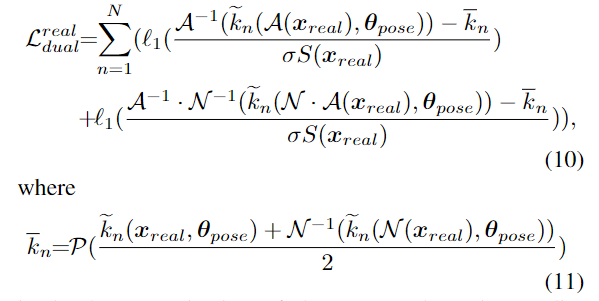
Visible silhouette alignment supervision
object의 pose를 추정하기 위해, 예측된 object pose의 윤곽을 실제 이미지의 pose와 정렬하여 DSC-PoseNet을 학습합니다. 예측된 rotation[ latex]\tilde{R}[/latex]과 translation \tilde{t}, CAD 모델 \mathcal{M}, intrinsic 파라미터 \mathcal{K}가 주어졌을 때, object를 렌더링하여 mask \tilde{y}^F=\mathcal{R}( \tilde{R},\tilde{t}, \mathcal{M}, \mathcal{K} )를 구합니다. pseudo mask와 렌더링 object mask를 비교해야 하지만, semgnetaion으로 구한 mask는 가려진 부분은 제외되어있고 렌더링으로 구한 object mask는 object의 모든 영역이 표현된다는 차이가 있습니다. 따라서, 렌더링한 object mask에 대해서 보이는 영역의 집합을 따로 구해주는 과정이 필요합니다.
이에 DSC-PoseNet의 segmentation을 이용하여 visible 영역을 선택합니다. \tilde{y}_m = P (ym = 1 | x; \theta_{pose} )가 전경 영역에 대한 확률을 나타낼 때, visible mask는 전경의 확률과 렌더링된 mask의 결합으로, 아래의 식으로 정의됩니다.
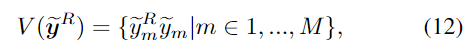
visible rendered mask를 구한 뒤, IoU 기반의 Dice loss[3]를 이용하여 pseudo segmentation mask와 정렬합니다.
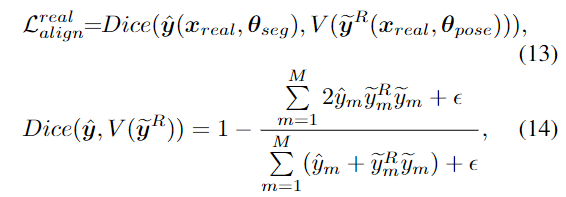
- \epsilon: 0이 나눠지는 것을 막기 위한 작은 숫자
DSC-PoseNet을 self-supervised 방식으로 학습하기 위한 total loss는 아래의 식으로 정리됩니다.
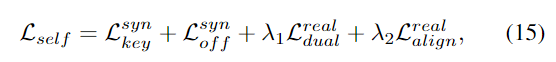
- 합성 데이터에 대한 keypoint/offset loss, real 데이터에 대한 dual-scale consistency loss와 visible 영역에 대한 alignment loss
- \mathcal{L}^{syn}_{key}, \mathcal{L}^{syn}_{off}, \mathcal{L}^{real}_{align}은 원본 크기와 normalized 크기 모두 적용
Experiments
학습에 Synthetic PBR training dastaset을 이용하였으며, LINEMOD, Occluded LINEMOD, HomebrewedDB에 대하여 평가를 진행하였고, 평가지표는 ADD(-S)를 이용하였습니다. (평가에 사용된 벤치마크 데이터와 평가지표는 6D pose estimation에 대한 이전 리뷰들에 작성해두었습니다.)
- Synthetic PBR training dastaset
- LINEMOD 데이터를 렌더링한 50만개의 PBR 이미지
- LINEMOD와 domain gap이 존재함
Comparison with SOTA
- LINEMOD
아래의 Table 1에서 결과를 확인할 수 있으며, 합성 데이터만을 이용할 경우 LINEMOD에서 성능이 크게 하락합니다.(합성데이터는 LINEMOD를 렌더링한 데이터임) 이를 통해 합성 데이터와 real 데이터 사이에 domain gap이 있다는 것을 확인할 수 있습니다. 또한, Depth 정보를 이용할 수 있으면 pose 예측 성능이 개선되는 것을 확인할 수 있습니다.
Table 1을 통해 본 논문에서 제안한 방식이 실제 RGB 기반의 방법론들과 비교했을 때 가장 좋은 성능을 보이는 것을 확인하였으며, Depth 정보를 이용하는 방법론들과 비교했을 때는, 경쟁력 있는 성능을 보이는 것을 확인하였습니다. 여기에 추가적인 합성 데이터(^+)를 이용할 경우 보다 좋은 성능을 보이는 것을 확인하였습니다.
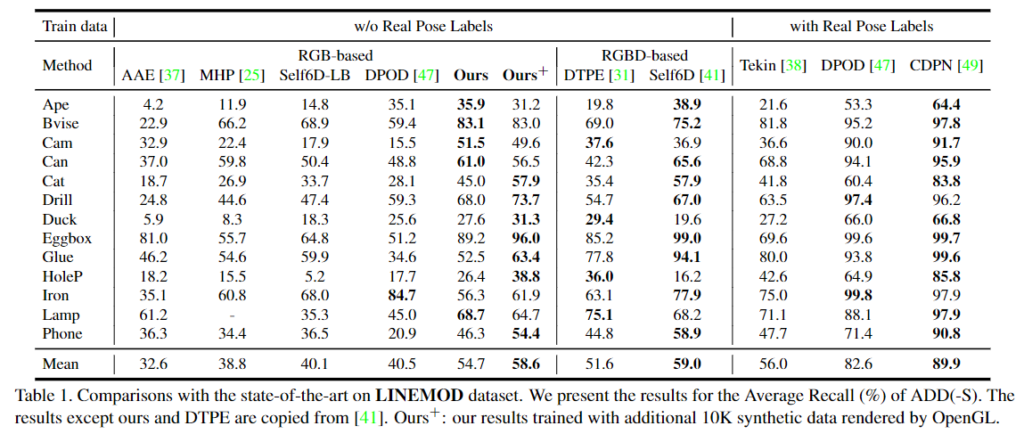
- Occluded LINEMOD
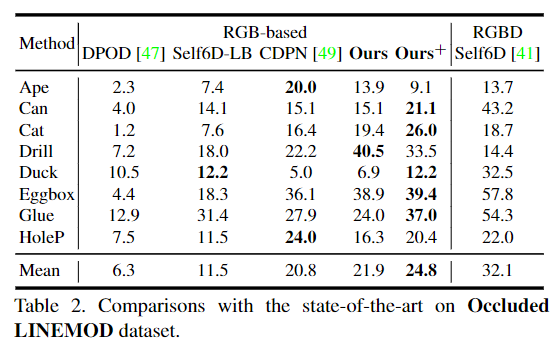
아래의 Table 2에서 결과를 확인할 수 있으며, RGB 기반 방법론들과 비교했을 때는 가장 좋은 성능을 보이는 것을 확인할 수 있습니다. 여기서 Self6D-LB는 depth 정보를 이용하지 않는 Self6D입니다. 추가로 아래의 Figure 3을 통해 Occluded LINEMOD에서 정성적 결과를 확인할 수 있습니다. 시각화한 결과는 occlusion이 발생한 경우에 대한 시각화 결과로, 초록색은 GT, 빨강과 노랑은 두 스케일의 예측 결과, blue는 두 결과를 앙상블(평균을 이용함)하여 구한 pose 예측 결과입니다.

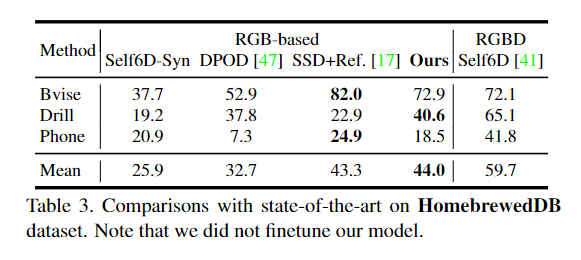
- HomebrewedDB
Self6D는 homebrewedDB에서 모델을 재학습하였으며, Self6D-Syn은 합성 RGBD 데이터만을 이용하여 모델을 학습한 버전입니다. Table 3을 통해 HomebrewedDB에 대한 결과를 확인할 수 있으며, 마찬가지로 RGB 이미지만을 이용하는 방법론들과 비교했을 때, 가장 좋은 성능을 보이는 것을 확인할 수 있습니다.
Ablation Study
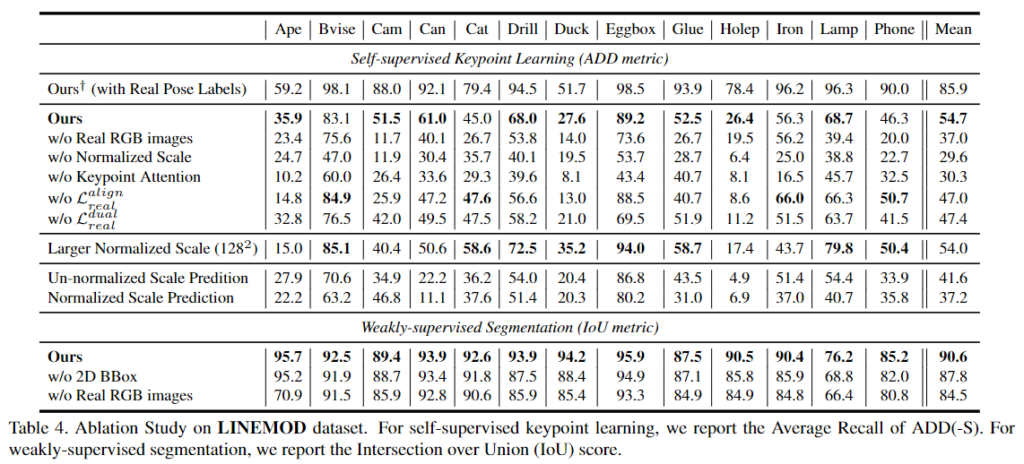
- Training data
w/o Real RGB images 와 Ours 결과 비교를 통해, real 데이터를 이용하지 않을 경우 성능이 크게 저하되며, 이를 통해 domain gap을 확인할 수 있습니다. 또한, Ours^+는 본 논문의 상한선 결과로, real pose 정보를 이용할 경우의 성능을 나타내었습니다. - Attention map
w/o Keypoint Attention을 통해 attention map을 제거하고 모든 offset의 평균을 이용할 경우의 성능을 확인할 수 있습니다. 해당 실험을 통해 attention map의 효용을 확인하였습니다. - Impacts of different losses
w/o \mathcal{L}^{align}_{real}과 w/o \mathcal{L}^{dual}_{real} 실험을 통해 두 loss 중 하나라도 없을 경우 성능이 크게 하락하는 것을 확인하였습니다. - Effects of the normalized scale
w/o Normalized Scale을 통해 정규화된 scale을 사용하지 않을 경우 성능이 크게 저하되는 것을 확인하였습니다. 또한, 정규화 scale의 크기가 큰 경우(Larger Normalized Scale 128×128)에도 강인하게 작동하는 것을 확인할 수 있습니다. - Importance of 2D annotations
2D bounding box의 영향을 확인하고자, w/o 2D BBox에 대한 실험을 진행하였습니다. 이를 위해 segmentation 단계에서 불확실한 픽셀 집합을 구해 loss에 반영하는 과정을 제외하고 네트워크를 학습시켰습니다. 그 결과 segmentation의 성능(IoU metric)이 저하되는 것을 확인하였고, 보다 정확한 segmentation 예측을 위해서는 bbox를 이용하는 것이 중요하다는 것을 확인하였습니다.
Reference
[1] Nibali, Aiden, et al. “Numerical coordinate regression with convolutional neural networks.” arXiv preprint (2018).
[2] Peng, Sida, et al. “Pvnet: Pixel-wise voting network for 6dof pose estimation.” CVPR (2019).
[3]Sudre, Carole H., et al. “Generalised dice overlap as a deep learning loss function for highly unbalanced segmentations.” Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support: Third International Workshop, DLMIA 2017, and 7th International Workshop, ML-CDS 2017, Held in Conjunction with MICCAI 2017, Québec City, QC, Canada, September 14, Proceedings 3. Springer International Publishing (2017).
안녕하세요 ! 좋은 리뷰 감사합니다.
‘기존의 합성 데이터를 이용하는 6D pose estimation 방법론과 비교하였을 때, 기존 합성 데이터를 이용하는 방식은 사실적인 합성 데이터를 생성하도록 하지만, 저자들은 2D bounding box를 이용하여 합성 데이터와 real 데이터 사이의 domain gap을 줄일 수 있었다고 합니다.’에서 저자들이 제안한 반복적인 segmentation 네트워크를 학습하는 방식으로 두 데이터에 대한 domain gap을 줄이는 방식은 이해가 가지만, 기존 합성 데이터에서 사실적인 합성 데이터를 생성한다는 것은 어떤 것인가요? 두 방법의 차이점이 와닿지 않아 질문 드립니다.
그리고 2D keypoin k_n이라고 정의된 것은 k^~_n과 다른 것을 의미하는 것 같은데 gt keypoint인가요 .. ? 만약 맞다면 2D에서는 어떤 정보를 keypoint로 제공하는것인가요 ? 3D처럼 object의 중심점이나 bounding box의 conrner 점 같은 것 keypoint라고 정의하는 것인지 궁금합니다.
질문 감사합니다.
기존 데이터에서 사실적인 합성 데이터를 생성하려 한다는 것은, object의 3D 모델을 이용하여 렌더링을 통해 합성 데이터를 만들고, 이때 조도나 조명 등이 사실적으로 표현되도록 한다는 것입니다. 즉, 기존의 방식은 합성 데이터가 더 사실적이 이미지가 되도록 하여 real 데이터와의 domain gap을 줄이고자 하였고, 저자들은 2D bounding box 정보를 이용하여 segmentation 네트워크를 반복적으로 학습함으로써 domain gap을 줄이고자 한 것입니다.
또한, k_n는 2D 이미지에서의 keypoint를 의미하며, k^~_n은 3차원에서 예측된 keypoint를 의미합니다. keypoint는 CAD 모델의 point를 이용하는 것으로 보입니다.
안녕하세요 ! 좋은 리뷰 감사합니다.
bbox를 가지고 배경 영역이 전경으로 예측되는 outlier를 제거하고 fine-tuning을 했다고 하셨는데, 저는 bbox안에 해당하지 않는 예측 결과는 가져가지 않는 것으로 이해했습니다. 근데, 이 2d bbox가 object 영역을 완전히 잘 맞추고 있지 않기 때문에 그 bbox 내에서의 배경 영역을 전경으로 예측한 경우에는 outlier로 판단할 수 없을 것같은데 이때는 어떻게 동작하게 되나요 ? 그냥 outlier를 안고 갈수밖에 없는건지 궁금합니다.
또, 비교적 구하기 쉬운 2d bbox를 이용하여 weakly supervised segmentation을 학습하여 object의 대략적인 윤곽 정보를 구하고자 하였고, 이때 2d bbox는 object 영역을 완전 타이트하게 맞추지않닸다고 가정하여 라벨링 제약을 완호ㅏ하였다고 하셨습니다. 여기서 라벨링 제약을 완화하였는게 잘 와닿지가 않는데, 좀 더 구체적으로 설명해주실 수 있을까요 !? !?
질문 감사합니다.
bbox 내에서의 배경 영역을 전경으로 예측한 경우에 대해서는 outlier를 제거한 뒤 이후에 불확실한 픽셀을 고려하지 않는 방식으로 대응할 수 있을 것이라 생각합니다. foreground 영역에 대한 GT segmentation mask가 없으므로, 불확실한 영역을 pseudo GT로 사용하는 것은 모델의 학습을 방해할 수 있으므로, 예측 신뢰도가 높은 영역들만 포함하여 segmentation 모델을 학습하는 것입니다.
또한, 라벨링 제약을 완화하였다는 것은 2D bounding box를 annotation 할 때 드는 노력을 조금 더 완화하였다고 생각하시면 될 것 같습니다. 해당 방법론에서는 2D bounding box의 정보를 예측하는 것이 목표가 아니라, bounding box는 보조적인 역할을 하는 것이므로 이러한 제약이 완화될 수 있었다고 생각합니다.
좋은 리뷰 감사합니다.
몇가지 이해가 안되는 부분이 있어 질문 남기고 가겠습니다.
1. Differentiable keypoint regression에서 p_m은 오브젝트가 존재하는 픽셀 좌표로 이해하면 될까요?
2. 합성 데이터에서 정확한 키포인트를 구할 수 있다고 하셨는데 어떤 기준으로 키포인트를 선정하는지 궁금합니다.
3. N과 A에 대한 notation이 궁금합니다.
질문 감사합니다.
1. 여기서 p_m은 object의 3차원 좌표를 의미합니다.
2. 본 논문에서의 keypoint를 명확히 밝히지는 않았으나, 어떠한 방식을 이용하더라도(3차원 boudning box를 이용하거나 FPS를 이용하여 N개의 keypoint를 이용거나 상관 없이) 합성데이터는 3D object 모델에서 선정된 keypoint가 여러 viewpoint에서 어떻게 변환 되는지를 정확히 알 수 있으나, 실제 데이터는 pose 정보에 대한 annotation이 필요하고 annotation 정보를 활용하여야 한다는 점에서 합성 데이터를 이용한다는 것을 표현한 것으로 보입니다.
3. 식 (10),(11)에서의 N은 normalize를 수행하는 함수를 의미하며, A는 augmentation을 수행하는 함수를 의미합니다.