이런 분들께 이 논문을 추천드립니다.
- Image-Text 모델인 CLIP을 Video Understanding에 활용하는 방법이 궁굼하신 분
이 논문을 깊게 이해하려면 다음 지식이 필요합니다.
- CLIP에 대한 이해 (CLIP 리뷰 파트 1, 파트 2)
- Q, K, V 기반의 트랜스포머 스타일 어텐션에 대한 이해 (트랜스포머 리뷰)
- 3D 합성곱을 이용한 Temporal Modeling의 이해 (I3D 리뷰)
안녕하세요. 백지오입니다.
열네 번째 X-REVIEW는 Image-text pretrained model인 CLIP의 강력한 visual representation learning 능력을 video domain에 적용하는 방법을 다룬 논문입니다.
기존에도 많은 연구들이 CLIP을 video retrieval이나 video action recognition과 같은 video understanding task에 적용하고자 하였는데요, 2D 이미지에서 학습된 CLIP 모델을 비디오에 적용하기 위해서는, CLIP의 visual backbone이 생성한 각 프레임의 feature들에 비디오가 가지고 있는 시간적인 관계를 더해주는 temporal modeling 작업이 필요하게 됩니다. 이에 따라 다양한 temporal modeling 방법의 연구가 수행되었는데요. 저자들은 이러한 기존 연구들이 retrieval을 비롯한 high-level semantic task, 혹은 recognition과 같은 low-level visual domain task 중 하나에 너무 맞추어져 있다는 문제를 지적합니다.
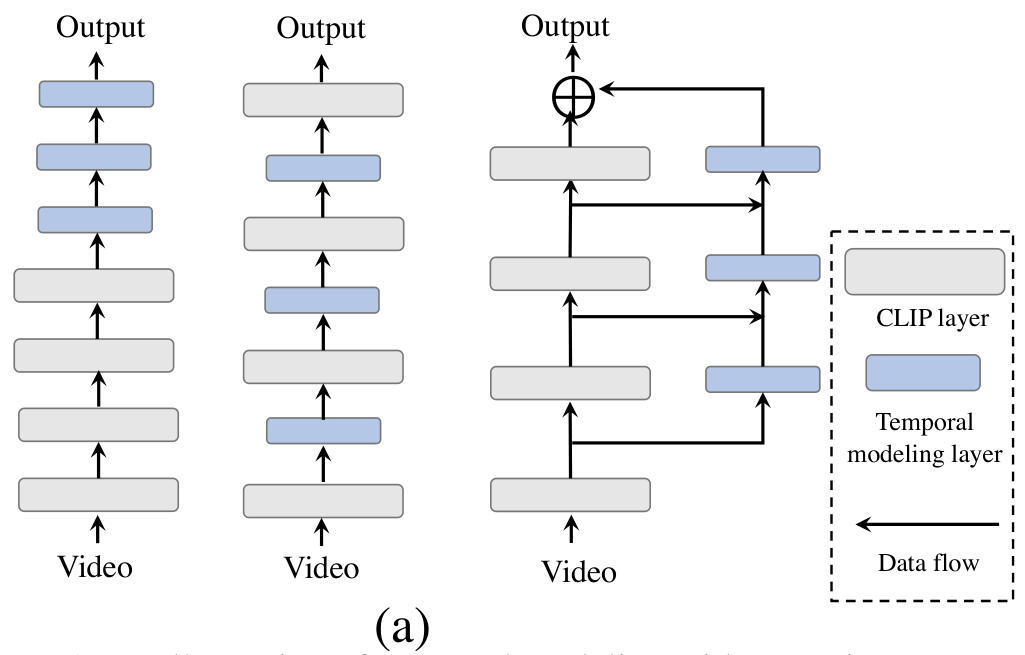
예를 들어, 서로 유사한 영상을 검색해야 하는 retrieval의 경우 영상의 세부적인 시각적 정보보다는 영상이 어떤 내용을 다루고 있는지와 같이 의미론적인 지식이 중요한 경향이 있으며, recognition과 같은 task에서는 영상 속 액션이 무엇인지 알아내야 하기에 디테일한 시각적 패턴이 중요하게 작용하게 됩니다. 따라서 기존의 연구들은 각각의 task에서 필요로 하는 feature에 따라, CLIP의 visual backbone에 temporal modeling layer를 추가하여 temporal modeling을 수행하였습니다.
high-level feature를 중요시하는 task에서는 위 그림의 좌측 모델과 같이, CLIP backbone 뒤에 temporal modeling layer를 추가하는 postprior 구조를 사용하였습니다. (Clip2video, Clip2tv, CLIP4clip 등) 한편, low-level feature가 중요한 task에서는 위 그림의 두 번째 모델과 같이 CLIP backbone 사이 사이에 temporal modeling layer를 추가하여 spatial-temporal visual patterns를 잘 잡아내도록 한 intermediate 구조를 사용하였습니다.
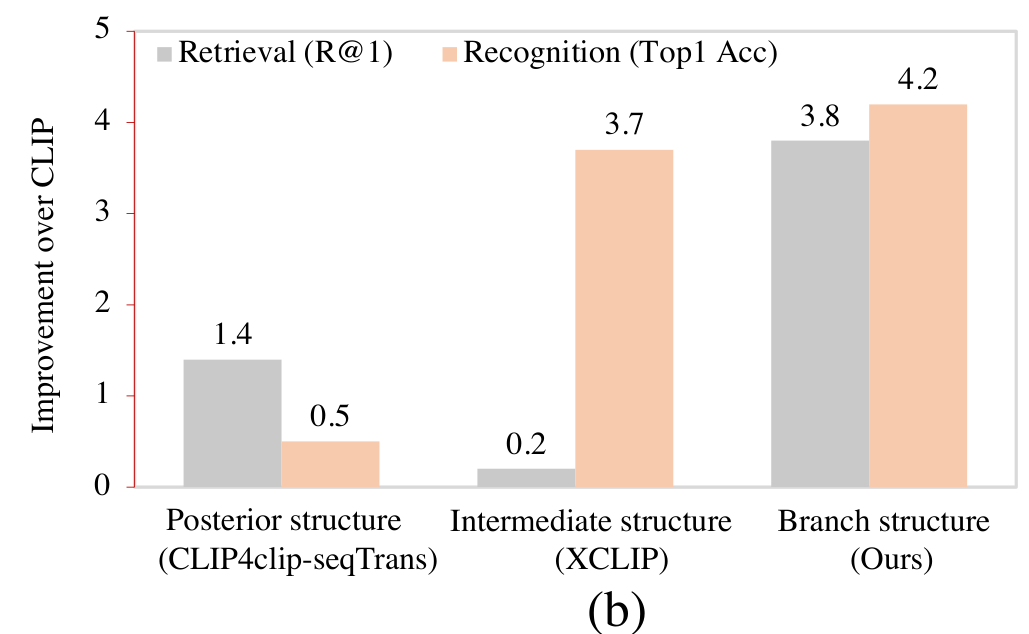
그 결과 posterior 구조는 retrieval과 같은 task에서 성능의 향상을 얻을 수 있었고, intermediate 구조는 recognition에서 성능 향상을 얻을 수 있었지만, posterior 구조는 recognition 성능이 떨어졌고 intermediate 구조는 retrieval 성능이 떨어지는 문제가 있었습니다.
따라서, 저자들은 쉽고 효율적으로 CLIP 모델을 이러한 두 종류 모두의 비디오 task로 확장할 수 있는 temporal modeling 방법인 Spatial-Temporal Auxiliary Network (STAN)를 제안하였는데요. CLIP visual backbone이 생성하는 low-level / high-level feature를 모두 적절히 사용하여, retrieval과 recognition 모두에서 성능 향상을 얻을 수 있었다고 합니다.
또한, STAN 모델은 기존 모델들이 CLIP의 backbone 사이에 temporal modeling layer를 삽입하는 등 모델을 수정한 것과 달리 branch 구조로 CLIP에 부착하여 사용할 수 있는 형태로 설계되어, CLIP의 순전파 과정에 영향을 주지 않고도 CLIP의 다양한 계층에서 다양한 수준의 feature를 추출하고 temporal context를 얻을 수 있습니다. STAN은 spatial-temporal saparated 하게 설계된 여러 계층으로 구성되어 있으며, 각 계층은 intra-frame module과 cross-frame module을 alternatively stacking하는 구조로 구성되어 있는데요. 이때, cross-frame module에 셀프 어텐션 기반의 구조와 3D 합성곱 기반의 구조를 사용한 결과를 비교해보았다고 합니다. STAN의 전체적인 구조는 object detection 모델인 FPN을 참고하였다고 하는데, 제가 URP 기간에 작성한 리뷰가 있으니 궁굼하시다면 참고하셔도 좋을 것 같습니다.
STAN은 video-text retrieval에서 CLIP4clip을 앞서는 성능을 보였으며, video recognition에서는 Swin3D-L 대비 88배 적은 FLOPs로 유사한 성능을 보였다고 합니다. 저자들의 contribution은 다음과 같습니다.
- image-to-video knowledge transferring 관점에서 temporal modeling을 연구하여, high-level 및 low-level knowledge를 모두 잘 transfer 할 수 있는 modeling 방법을 개발하였다.
- 브랜치 구조의 temporal modeling을 통해 CLIP이 가지고 있는 다양한 수준의 풍부한 knowledge들을 잘 video task로 확장할 수 있는 Spatial-Temporal Auxiliary Network (STAN)을 제안하였다.
- STAN은 다양한 video task에서 SOTA 모델들과 견줄만한 성능을 달성하였다.
Methodology
Motivation and Overview
CLIP의 visual encoder는 트랜스포머 기반의 인코더 레이를 쌓은 형태로 구성되며, 이 레이어들은 CNN과 유사하게 낮은 계층에서부터 높은 계층으로 갈 수록, 낮은 수준으로부터 높은 수준의 시각적 패턴을 학습합니다. 그렇게 구성된 CLIP visual encoder의 마지막 계층은 high-level visual embedding을 생성하게 되는데, 이는 text encoder에서 생성한 임베딩과 semantically align 되게 됩니다.
앞서 설명한 것처럼, Video Retrieval과 같은 high-level semantic knowledge dominant task에서는 이러한 고수준의 특성이 중요하고, Action Recognition과 같은 visual pattern dominant task에서는 CLIP 중간 계층에서의 특성들이 중요하게 작용하는데, 기존에 제안된 방법들은 이 특성들을 동시에 사용할 수는 없었습니다.
때문에 저자들은 이러한 multi-level 특성들을 모두 사용할 수 있는 Spatial-Temporal Auxiliary Network, STAN을 제안하는데요. STAN은 $K$개의 spatial-temporal layer들로 구성되며, CLIP visual encoder에 브랜치 형태로 부착되어 활용됩니다
$T$ 프레임의 비디오가 주어졌을 때, 프레임들은 CLIP visual backbone으로 입력되며, $K+1$개의 CLIP 계층을 통과하는데요. $k$번째 CLIP의 계층은 아래 식과 같이 나타낼 수 있습니다.$T, L, D$는 각각 프레임의 수, 프레임당 패치 번호, 임베딩 차원 수를 의미합니다.
$$ V^k = \{ f^k_{i, j} \in \mathcal{R}^D | i\in [1, T], j\in [0, L] \}$$
$V^k$에서, $f^k_{i, 0}$은 $i$번째 프레임의 [CLS] 토큰을 의미하며, 이어지는 $f^k_{i,j}$는 $i$번째 프레임에서 $j$번째 패치의 임베딩을 의미합니다.
CLIP의 각 계층이 생성한 출력은 대응되는 STAN의 각 계층에 입력되어 spatial-temporal modeling을 수행하게 됩니다. 앞서 언급한 것처럼, 기존 모델들이 CLIP에 모듈을 삽입하여 CLIP 모델 자체를 변경한 반면, STAN은 브랜치 구조로 CLIP에 부착되기 때문에 CLIP이 원래 가지고 있는 구조를 변형하거나 파괴하지 않는 장점이 있습니다.
Spatial-Temporal Auxiliary Network
STAN은 $K$개의 spatial-temporal layer로 구성됩니다. 각 계층의 입력은 CLIP visual layer의 출력을 입력받으며, STAN의 $k$ 번째 계층의 입력은 다음과 같이 나타낼 수 있습니다. 이때, $f’^k_{0, 0}$은 전체 비디오에 대한 [CLS] 토큰입니다.
$$ V’^k = \{ f’^k_{0, 0}, f’^k_{1, 1}, \cdots , f’^k_{1, L}, \cdots, f’^k_{T, 0}, \cdots , f’^k_{T, L} \}$$
이어서, STAN 계층의 출력은 다음과 같이 나타낼 수 있습니다.
$$ \tilde{V}^k = \{ \tilde{f}^k_{0, 0}, \tilde{f}^k_{1, 1}, \cdots , \tilde{f}^k_{1, L}, \cdots, \tilde{f}^k_{T, 0}, \cdots , \tilde{f}^k_{T, L} \}$$
먼저, 첫 STAN 계층에 대한 입력 $V^1$을 얻기 위해 각 프레임의 [CLS] 토큰의 임베딩을 평균하여 새로운 $f’^1_{0, 0} = \frac{1}{T} \sum_{i\in T} f^1_{i, 0}$을 얻고, $V^1$의 패치 임베딩에 대한 temporal position embedding을 다음과 같이 구성합니다.
$$f’^1_{i,j} = \text{Dropout}(f^1_{i,j} + \text{Pos}_t(t) + \text{Pos}_s(j))$$
이때, $j>0$에 대하여 $\text{Pos}_t$와 $\text{Pos}_s$는 학습 가능한 임베딩이라고 합니다. 요약하면, 학습 가능한 임베딩에 드롭아웃을 적용하여 사용한다고 볼 수 있겠네요.
첫 계층에 대한 입력만 정의해주면, 나머지 계층에 대한 입력 $V’^k$는 이전 STAN 계층의 출력 $\tilde V^{k-1}$과 CLIP출력 $V^k$에 의하여 다음과 같의 정의됩니다.
$$ f’^k_{0, 0} = \tilde f_{0,0}^{k-1} + W^k_{proj} \frac{1}{T}\sum_{i\in T} f^k_{i,0} $$
$$ f’^k_{i,j} = \tilde f^{k-1}_{i,j} + W^k_{proj} f^k_{i,j}$$
이때, $W^k_{proj}$는 projection layer입니다. 정리하면, 이전 STAN 계층의 출력에 새로운 CLIP 계층의 출력을 Projection 하여 더하면 새로운 STAN 계층의 입력이 된다고 볼 수 있겠군요.
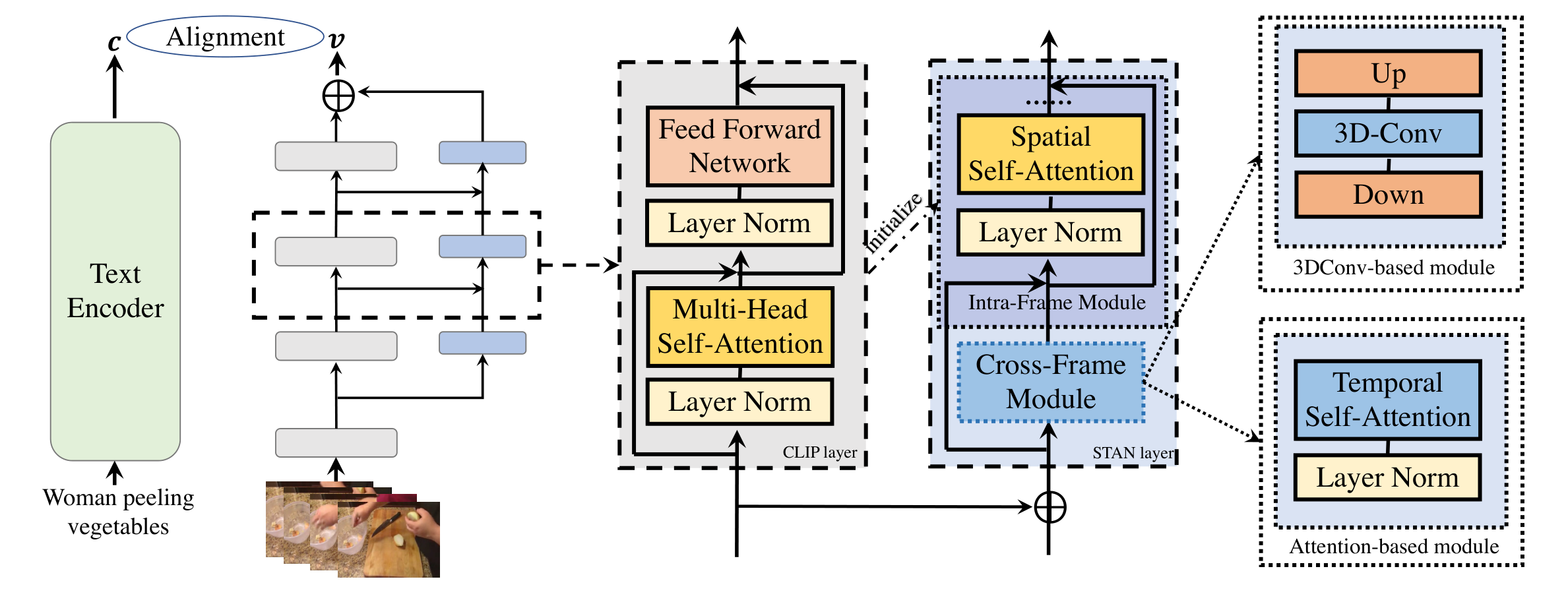
비디오의 임베딩 시퀀스가 입력되면, STAN layer는 비디오 프레임들 사이의 spatial-temporal information을 학습하게 됩니다. 이때, 교대로 쌓아진 intra-frame module과 cross-frame module을 통해 temporal modeling을 수행하게 됩니다. 이러한 분리 구조로 인해, 저자들은 CLIP visual encoder의 구조를 intra-frame spatial module의 설계와 초기화에 재사용하여 downstream task에서의 성능을 향상할 수 있었다고 합니다.
CLIP과 동일하게, intra-frame module은 spatial modeling을 담당하는 셀프 어텐션 블록으로 구성됩니다. 각 프레임에서, spatial module은 셀프어텐션을 통해 임베딩을 업데이트합니다.
한편, cross-frame module은 temporal modeling을 담당합니다. 서로 다른 프레임의 $j$번째 패치 임베딩은 $Y_j \in \mathbf{R}^{T\times D}$와 같이 나타냅니다. 각 spatial position에서 패치 임베딩은 $\hat Y_j = Temp(Y_j)$와 같이 업데이트 됩니다. $Temp()$는 temporal dimension 간 message passing strategy라고 하는데, 아래서 다룰 cross-frame module을 의미합니다. 저자들은 셀프 어텐션 기반의 cross-frame module과 3D 합성곱 기반의 cross-frame module을 설계하여 둘을 비교하였습니다.
Temporal Modeling in STAN
딥러닝에서는 다양한 방법으로 temporal modeling을 수행하는데, 3D 합성곱, temporal 셀프 어텐션, proxy token과 같은 방법이 있습니다. 저자들은 이들 중 가장 많이 사용되는 3D 합성곱과 셀프 어텐션을 비교하였다고 합니다.
Self-attention base module. 셀프 어텐션은 global modeling capability가 있어 시퀀스의 모델링에 적합한 구조입니다. 서로 다른 프레임에서 온 같은 위치의 패치 임베딩들에 대하여 다음과 같이 어텐션을 수행합니다.
$$ \hat Y_i = \text{softmax}(Y_iW_Q(Y_iW_K)^\top / \sqrt D) (Y_iW_V)+Y_i $$
기본적인 트랜스포머 스타일 어텐션이네요. temporal attention을 통해, 각 패치는 같은 위치의 시간적 정보를 잘 contextualize할 수 있다고 합니다.
Convolution based module. 합성곱 연산을 통해 효과적으로 temporal modeling을 수행한 기존 연구들이 있었습니다. (I3D 리뷰) 최근에는 셀프 어텐션이 많은 주목을 받고 있으나, 합성곱 역시 여전히 local modeling에서 장점이 있으며, 어텐션에 비해 훨씬 쉽게 수렴하는 장점이 있습니다. 저자들은 비디오의 패치 임베딩을 쌓아 $Y\in \mathbf R^{T\times W\times H\times D}$형태의 3D feature를 구성하였다고 합니다. 그 다음, 아래와 같은 방법으로 modeling을 수행하였습니다.
$$ Y = Up(Gelu(3DConv(Down(Y))))+Y$$
$Up()$과 $Down()$은 point-wise convolution으로, 각각 $D, \frac{D}{8}$의 채널 크기를 가져 패치 임베딩의 채널 수를 조정해줍니다. 3D 합성곱의 커널 사이즈는 $T,H,W$에 대해 $3,1,1$로 설정하였다고 합니다.
Experiments
저자들은 각기 다른 관점의 feature를 요구하는 video-text retrieval과 같은 high-level semantic-dominant task와 video recognition과 같은 low-level visual pattern-dominant task에서 평가를 진행하였습니다.
STAN 계층은 4개로 설정하였으나, SSv2 데이터셋에서만 6으로 하였고, 파인 튜닝에는 retrieval에는 NCE loss, recognition에는 CE loss를 사용하였으며, CLIP4clip을 따라 MSRVTT, LSMDC, K400, SSv2 데이터셋에서 12개의 프레임과 32의 token length를 사용하였다고 합니다. 더 긴 영상으로 구성된 Didemo 데이터셋에서는 프레임 수와 토큰 길이를 64로 늘려줬다고 합니다. 모든 데이터셋에서 배치사이즈는 128을 사용하였고, Adam optimizer에 0.02 weight decay, STAN 파라미터에는 2e-6, CLIP 파라미터에는 2e-5의 학습율을 사용하였다고 합니다. lr decay는 코사인 annealing 스케쥴링을 사용하였네요.
Comparisons with SOTA
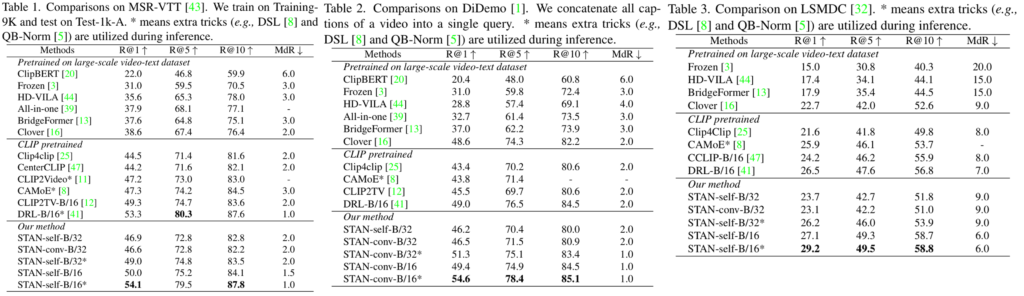
먼저, 저자들은 CLIP 기반의 다른 사전학습 방법들과의 video-text retrieval 성능을 비교하였습니다. 위 표들은 각각 MSR-VTT, DiDemo, LSMDC 데이터셋에서의 비교를 나타냅니다. CLIP 사전학습 방법들에서, B/16으로 표기된 방법 이외에는 CLIP-B/32를 기반으로 합니다. 한편, cross-frame module에 사용된 모델이 어텐션인지 합성곱인지는 -self / -conv와 같이 나타내었네요.
모든 표에서 확인할 수 있듯이 일반적으로 CLIP 기반의 방법론들은 video-text pretrained model 보다 좋은 성능을 보이고 있습니다. 이로부터 image-text 사전학습 모델인 CLIP이 비디오 분야에서도 강력한 잠재력을 가짐을 알 수 있습니다. CLIP 기반 방법론 중, STAN은 모든 벤치마크에서 SOTA를 달성하였으며, 특히 posterior 구조 기반의 모델들(CLIP4clip 등)을 크게 앞서 브랜치 구조의 우수성을 알 수 있다고 합니다.
한편, 저자들은 DRL과 같은 다른 SOTA 모델들과 STAN은 본질적으로 다른 방법을 사용하여 성능을 올렸기 때문에, 두 방법을 조합하면 더 좋은 성능을 보일 가능성이 있다고 하며 미래의 연구 방향을 제안하고 있습니다.
한편, STAN의 셀프 어텐션 버전과 3D 합성곱 버전이 비슷한 성능을 보임을 알 수 있는데, 특히 파인튜닝을 작은 데이터셋에서 수행할 수록 이러한 차이가 좁아졌다고 합니다. DiDemo에서는 오히려 Conv가 self 를 앞서는 성능을 보이네요.
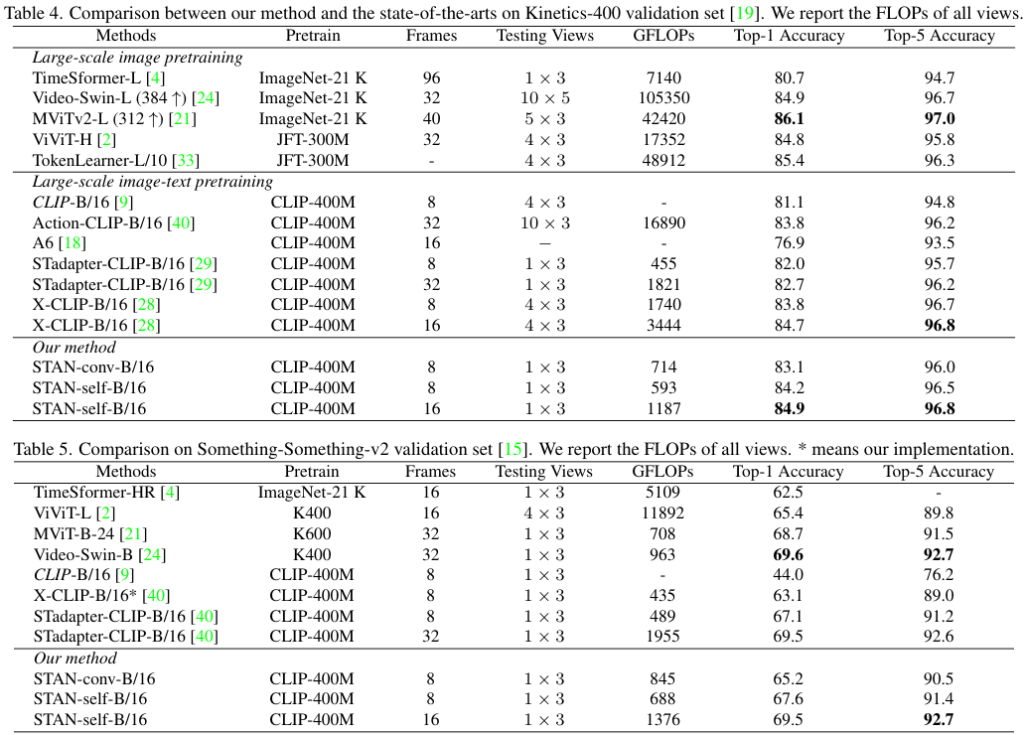
이어서 Video Recognition에서의 비교 결과 입니다. Kinetics-400과 Something-Something-v2 데이터셋에서의 성능 비교를 나타낸 모습입니다.
먼저, image pretraining 모델과 image-text pretraining 모델을 비교해보면, image-text pretraining 모델이 성능은 약간 낮지만 연산량(GFLOPs)은 훨씬 적은 것으로부터, image-text pretraining이 효율적이고 강력함을 알 수 있습니다. 이어서 Kinetics에서는 STAN이 CLIP 기반 방법 중 SOTA를 달성한 것이 보이네요.
한편 SSv2에서는 temporal modeling이 없는 CLIP 모델이 고작 44%의 top-1 정확도를 달성하는 것을 볼 수 있는데요. 이는 SSv2가 temporal 한 관계가 매우 중요한 데이터로 구성되어있기 때문입니다. 그런데 조금 의아하게, 논문에서는 이 결과를 ImageNet-21K에서 사전학습된 TimeSformer와 비교하며 CLIP과 SSv2의 domain gap이 문제라고 하네요…?
아무튼 STAN을 통해 temporal modeling을 수행하자 정확도가 크게 올라간 것을 확인할 수 있습니다.
Ablation Study

저자들은 제안한 각 구조에 대한 ablation study를 수행하였습니다.
정리해보겠습니다.
저자들은 CLIP이 가진 강력한 visual knowledge를 video domain으로 옮겨오고자 하였습니다. 이때, high-level semantic knowledge와 low-level visual knowledge를 모두 가져오기 위해, STAN 구조를 제안하였습니다. STAN 구조는 CLIP backbone에 브랜치 형태로 부착하여, CLIP의 순전파를 변형하지 않으면서 다양한 수준의 feature를 추출하고, temporal modeling을 수행하여 video에 적합하게 활용할 수 있습니다.
이를 통하여, 저자들은 기존 CLIP 기반 비디오 모델들이 retrieval이나 recognition과 같이 상반되는 feature를 요구하는 task 중 하나에서만 잘 작동한 것과 달리, 두 task 모두에서 SOTA이거나 그에 준하는 성능을 달성할 수 있었습니다.
마지막 실험 부분에서 SOTA를 달성한 것도 인상깊지만, CLIP 기반의 다른 방법들이 컴퓨팅 적으로 효율적인 것도 주목할 만한 것 같습니다. CLIP을 꼭 멀티 모달로 활용할 것 없이, CLIP의 backbone만 가져다 쓰더라도 여러 task에서 좋은 결과를 얻을 수 있을 것으로 생각되네요.
그럼, 오늘 리뷰는 이만 마치겠습니다.
다들 좋은 주말 보내시길 바랍니다.
감사합니다!
FPN + CLIP 컨셉을 비디오에 녹여낸 논문인 것 같습니다.
궁금한 건 action recognition 기준으로 입력 데이터의 차원과 출력 데이터의 차웑 좀 알수 있을까요?
몇개의 프레임이 들어가서 몇차원 벡터가 나오는지 궁금합니다.
안녕하세요. 임근택 연구원님.
1. 입력 데이터: 모델 설정에 따라 8프레임 혹은 16을 추출하여 사용합니다. (표 4, 5에 나와있습니다.) 영상 크기는 CLIP vision encoder에 맞게 조정하여 입력하기 때문에, ViT-B/16 인코더의 입력 크기인 224×224로 조정되어 입력 차원은 16(or 8) x 3 x 224 x 224 가 되겠네요.
2. 출력 데이터: Cross Entorpy Loss를 사용하기 때문에, num_class 만큼의 출력을 가지게 됩니다.
감사합니다!
안녕하세요 좋은 리뷰 감사합니다.
1) Cross-frame module의 Temp() 연산이 프레임 temporal dimension 간 message passing strategy라고 말씀해주셨는데, message passing strategy가 정확히 어떠한 연산을 의미하는 것인지 궁금합니다.
2) 소개해주신 연구에서 벤치마킹한 T-V Retrieval이나 Action Recognition은 둘 다 가용한 video 또는 frame level의 text 라벨이 존재하고, 결국 어떠한 visual encoder든 최종 performance에 대해선 CLIP text encoder와의 align에서 오는 기여도를 무시할 수 없을 것으로 생각됩니다.
V-V Retrieval에 CLIP을 접목시켜보시려는 것으로 알고 있는데, V-V Retrieval에서 주어지는 정보 중 활용 가능한 video level의 text가 존재하나요? 또는 유사 연구 중 text가 없을 때 Video captioning을 통해 text를 만들어내고 이를 CLIP과 함께 사용하는 연구는 없는지도 궁금합니다.
안녕하세요. 김현우 연구원님.
1. Temp()는 논문에서 말하는 temporal modeling을 의미합니다. 논문 상에서는 Self-attention과 3D Convolution 두 가지 방법을 이용하여 이를 수행하고 있는데요, 두 방법 모두 방식의 차이가 있을 뿐, 독립된 각 프레임의 feature들이 가진 어떤 맥락(message)를 시간축으로 병합하고 전달하는(passing)하는 기능을 하여 message passing strategy라 한 것 같습니다.
2. 아직 V-V Retrieval에 CLIP을 접목하는 제 연구 주제는 아이디어(?)라기에도 민망한 수준이라 공개하기 좀 부끄럽습니다만.. V-V Retrieval에 어떠한 text를 training signal로 활용하는 것이 아닌, vision-text로 pretraining된 CLIP의 high-level feature를 통해, 기존의 Image 기반 backbone으로 생성한 descriptor보다 더 contextual한 개념을 잘 포함하는 descriptor를 만드는 것이 제 목표입니다. 다만, 단순히 CLIP을 backbone으로 사용하여 retrieval을 수행하는 것은 이 논문을 포함하여 몇 가지 연구가 이미 진행되어 있어서, ImageBind와 같은 모델을 통해 Video – Audio를 통하여 descriptor를 생성해볼까 생각하고 있습니다.
Captioning을 통해 text를 만들고 CLIP과 함께 사용하는 연구는 제가 서베이를 자세히 진행하지는 않아 확실하지 않지만, HowTo100M과 같이 애초에 caption이 text로 주어지는 데이터셋에서 CLIP을 통해 Retrieval을 진행한 연구를 비슷한 맥락으로 볼 수 있을 것 같습니다. 찾아보니 Cap4Video라는 캡션 생성을 수행하는 연구도 있네요.
감사합니다.