AAAI 2024 reference 작업 중 제가 실험하고 있는 방법과 비슷해보이는 연구가 있어 리뷰해보려고 합니다. 역시 항상 리뷰하던 Active Learning 에 대한 연구입니다.

- Title: Cost-Effective Active Learning for Deep Image Classification
- Journal: IEEE Transactions on Circuits and Systems for Video Technology, 2017
- Supplemental: None
- Author Video: None
- Code: GitHub
Introduction
Deep Learning 방법론들이 다양한 태스크에서 놀라운 성능을 보이면서, 데이터에 관심이 많아졌다는 것은 이제 두말하면 입이 아플정도입니다. 데이터는 계속해서 필요로 하지만, 데이터 라벨링 비용이라는 제약이 항상 뒤따르다고 있습니다. 지금 리뷰하는 논문은 Active learning 이라는 접근법으로 이 문제를 풀어나갑니다. 이제는 우리 연구실의 많은 분들이 Active Learning 의 필요성 및 컨셉에 대해 이해하고 있다고 생각됩니다. 해당 논문의 표현을 빌리자면, Active Learning (이하 AL) 은 반복해서 가장 유익한 unlabeled sample 들을 선별하고 라벨링함으로써 모델의 성능을 향상시키는 방법론입니다.
AL의 핵심 단계는 (1) 모델 학습 (2) 유용한 subset dataset 선택 이라고 할 수 있을 것 같습니다. (참고로 아래는 가장 나이브한 방법론을 기준으로 설명하는 것으로, 디테일한 부분은 연구마다 다릅니다. 나아가 최신 방법론들은 더욱 정교하고 복잡한 과정으로 구성되있기도 합니다.)
(1) 모델 학습 단계: 목표로하는 target task (ex. classification, segmentation …) 를 위한 모델 학습입니다. 기본적으로 주어지는 소량의 labeled dataset으로 목표하는 태스크에 맞춰 모델을 학습하는 단계입니다.
(2) 유용한 subset dataset 선택 단계: 앞서 학습이 완료된 모델의 feature 혹은 model output을 기반으로 sampling strategy (선택 기준) 에 따라 유용한 데이터의 하위 집합을 선택하는 단계입니다.
그런데, 저자가 생각하는 기존 연구들의 문제점은 AL 연구에서 대부분의 모델은 unlabeled dataset을 학습에 활용하지 않는다 는 점입니다. 이 문제점을 AL의 핵심 단계와 매핑해서 설명드리자면.. (1) 기존 연구에서는 모델 학습 단계에서 unlabeled dataset을 학습에 사용하지 않습니다. 얻어진 labled sample만으로 모델을 학습하죠. 즉, 소량의 샘플로 CNN을 학습해서 일반적인 feature를 얻는 것은 어렵다는 것이 저자의 주장입니다.
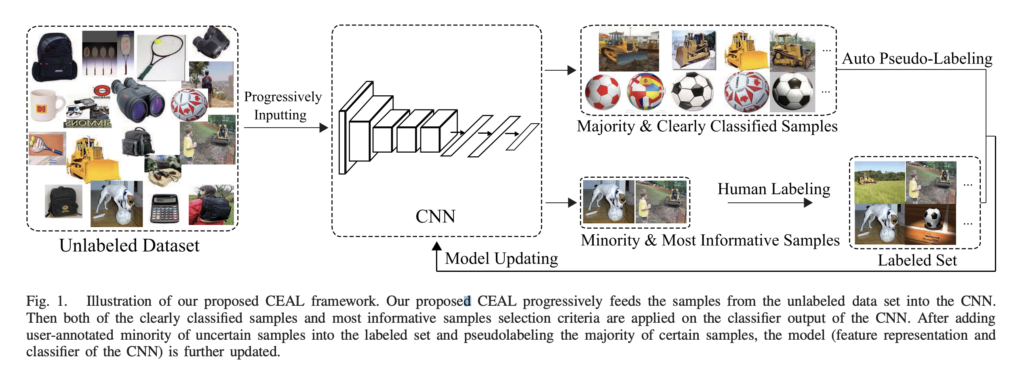
이를 극복하고자 저자는 모델 학습 시 Unlabeled data도 함께 학습하는 cost-effective AL (CEAL) 방법론을 제안하였습니다. 상단 그림을 통해 저자의 방법론을 확인할 수 있습니다.
CEAL은 CNN output 에 따라 데이터 샘플을 크게 두 가지로 분류하였습니다: 예측 신뢰도가 낮은 샘플(minority) vs 예측 신뢰도가 높은 샘플(majority). 예측 신뢰도가 낮은 minority는 모델이 확실하지 않는 예측을 한 경우를 말하며, 흔히 불확실성이 높다고 표현합니다. 이렇게 불확실성이 높은 데이터셋은 라벨링을 해서 labeled dataset에 추가하게 됩니다. 여기까지는 기존 AL 과 다름이 없습니다. 이제 이 부분에서 novelty 가 있는데요. majority 라는 예측 신뢰도가 높은 데이터는 예측값을 pseudo-label로 모델 학습에 사용하였습니다. 결국 unlabeled dataset을 모델 학습에 사용한 것이죠!
Method
결국 CEAL에서는 모델의 예측 신뢰도가 낮은 샘플 말고도, 예측 신뢰도가 높은 unlabeled dataset도 동시에 학습에 사용하기 때문에, 저자가 제안하는 CEAL은 unlabeled 데이터에도 적응 가능한 효과를 보인다고 합니다.
CEAL 은 classification을 대상으로 설계된 네트워크인만큼, 학습도 간단합니다. 단계별로 설명드리겠습니다.
A. Initialization
여느 AL 방법론과 동일하게 초기 Labeled dataset D^L은 D^U 에서 랜덤하게, 정해진 개수만큼, 선택됩니다. 그리고 D^L로 모델을 학습합니다.
B. Complementary Sample Selection
이제 학습이 완료됐으면, AL 기준에 따라 모든 unlabeled dataset에 대해 순위를 매긴 다음, 가장 불확실한 샘플을 골라서 D^L에 추가합니다. 추가한 불확실한 샘플이 introduction에서 말한 minority 입니다. 반대로 가장 확실한 샘플에 대해서는 예측값을 정답값이라 하는 pseudo-label을 할당한 뒤 D^H라고 표기하겠습니다. 여기서 말한 D^H가 바로 introduction에서 언급한 majority 가 되겠네요
그렇다면 AL 기준이 뭘까요? 여기서는 가장 고전적인 불확실성 선택 방법을 사용했습니다. 바로 3가지 기준인 Least Confidence(LC), Margin Sampling(MS), Entropy(EN) 입니다. 각각 수식은 아래와 같습니다.
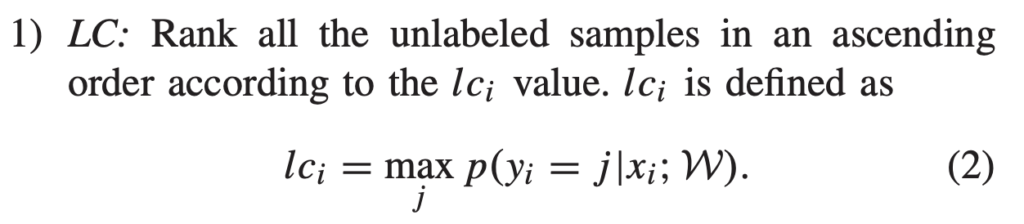
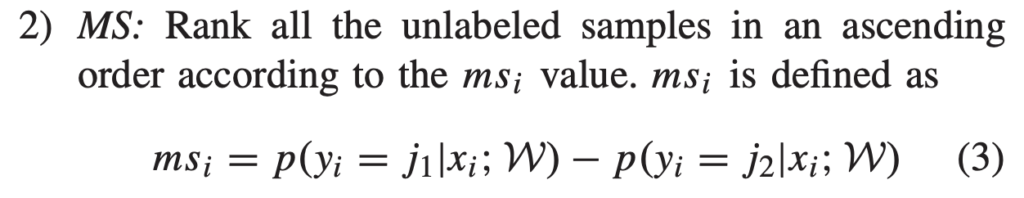
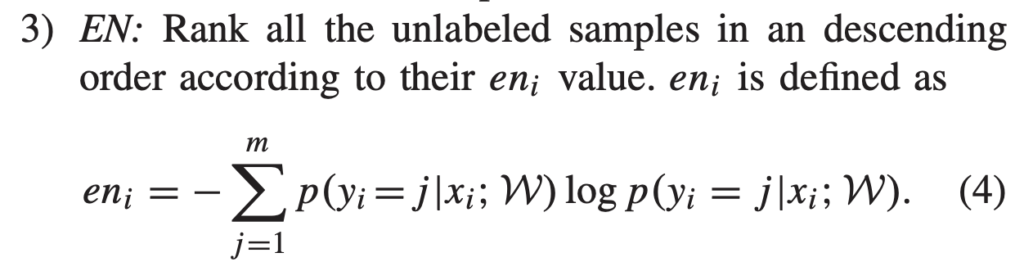
굉장히 간단한 방법론이라 아래 그림을 통해 설명드리겠습니다. 학습이 완료된 모델의 데이터 x_1, x_2, x_3, x_4 출력이 다음과 같다고 가정해봅시다. (-> 이미 이전 리뷰에서 설명한 부분이라 아시는 분들은 넘어가셔도 됩니다.)
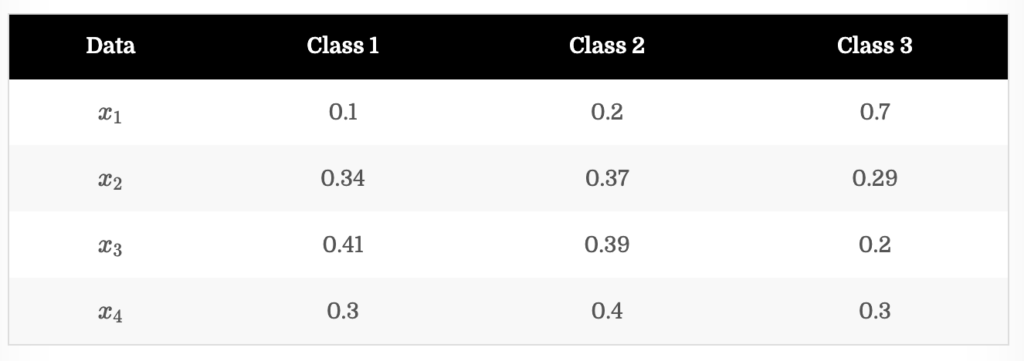
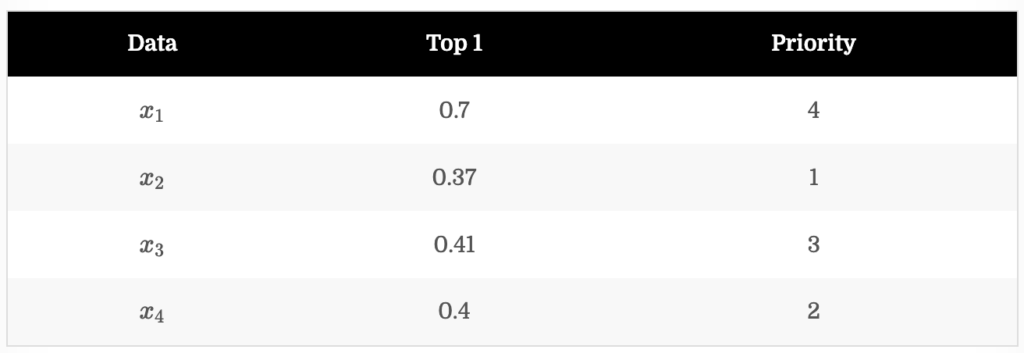
LC는 모델의 예측 확률 중 top1 확률이 가장 낮은 데이터에게 높은 순위를 할당하는 방법론입니다. 그 결과는 아래와 같습니다. 만일 추가되는 데이터 개수가 2개라고 한다면, LC 기준에 대해서는 x_2, x_4가 선택됩니다.
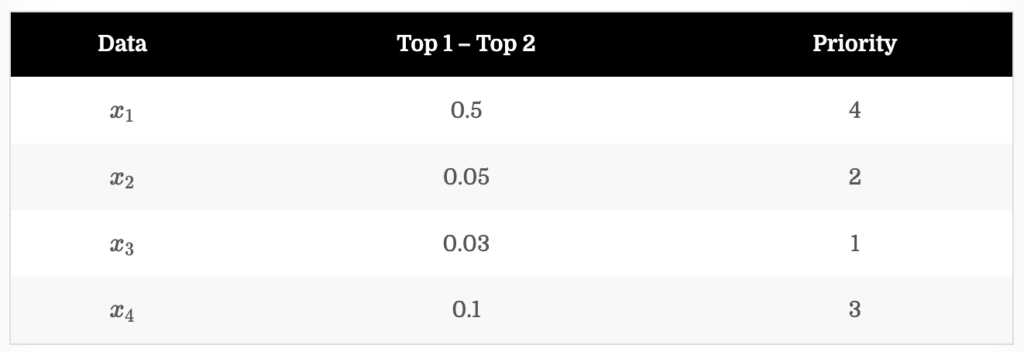
MS는 모델의 각 클래스 예측 확률 중 Top 1 과 Top 2의 확률 차이가 가장 낮은 데이터에 높은 순위를 할당하는 방법론입니다. 만일 추가되는 데이터 개수가 2개라고 한다면, MS 기준에 대해서는 x_3, x_2가 선택됩니다.
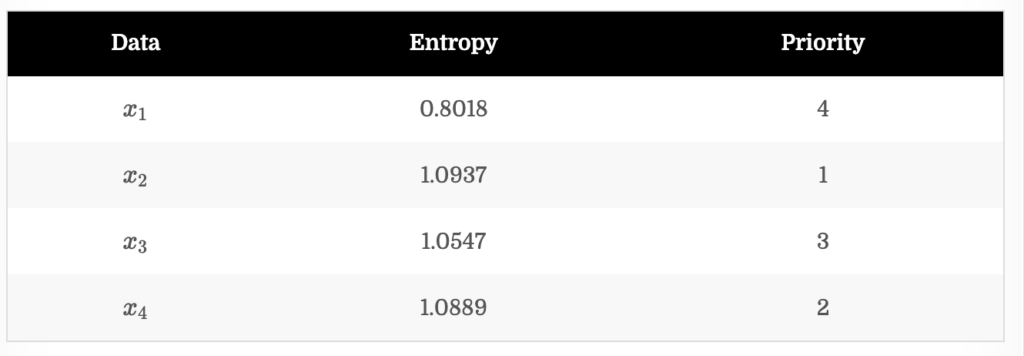
EN은 우리가 흔히 아는 엔트로피로, 엔트로피가 높은 데이터에 높은 순위를 할당하는 방법론입니다. 만일 추가되는 데이터 개수가 2개라고 한다면, EN 기준에 대해서는 x_2, x_4가 선택됩니다.
그럼 이제 데이터를 선택하는 기준에 대해 알아보았으니, psuedo-label을 할당하는 디테일한 과정에 대해 알아봅시다. 앞서, 신뢰도가 높은 데이터에 pseudo-label을 할당한다고 하였는데요. 신뢰도가 높다는 건 EN을 기준으로 설정하였습니다. 정확히는 EN이 δ보다 작을 경우고, 그게 아닐 경우에는 pseudo-label을 할당하지 않습니다.
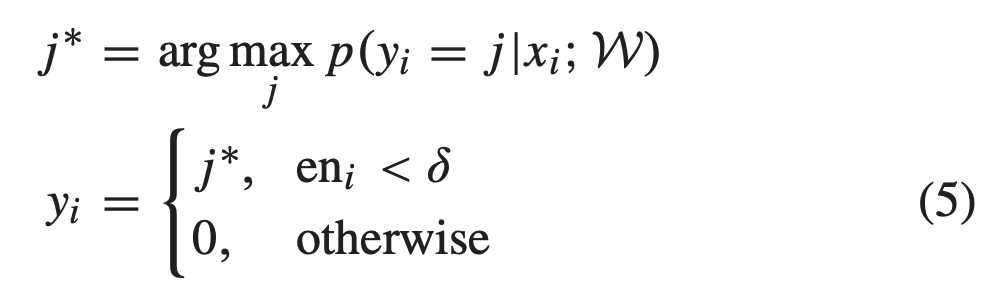
만일 추가되는 데이터가 K개 라면, A.Initialization 단계에서 얻어진 D^L을 D^L_0라고 하겠습니다. 이제 B. Complementary Sample Selection 에서 설정한 AL 기준에 따라 K개를 D^L_1. 그런 다음, EN이 δ보다 작은 신뢰도가 높은 데이터는 D^H로 설정합니다.
C. CNN Fine-Tuning
앞서 얻어진 D^L_0과 D^L_1, 그리고 D^H를 사용하여 모델을 학습합니다. 이 fine-tuning 과정이 종료되면, D^H는 다시 D^U에 넣고 pseudo-label은 삭제합니다.
D. Threshold Updating
AL의 점진적인 학습 과정이 진행될수록 신뢰도가 높은 샘플이 더 많이 선택되면서 잘못된 pseudo-label이 줄어들게 될 것입니다. 이렇게 높은 신뢰도 샘플 선택의 안정성을 보장하기 위해, threshold를 매 cycle 마다 아래 수식에 맞춰 업데이트하였다고 합니다. dr은 threshold를 조절하는 decay rate이라고 합니다.
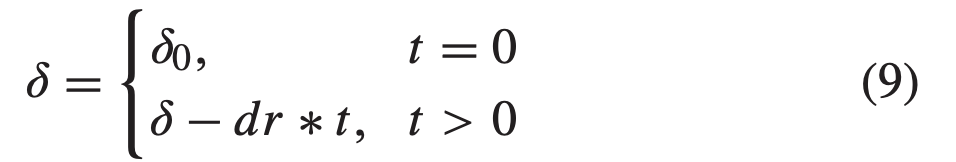
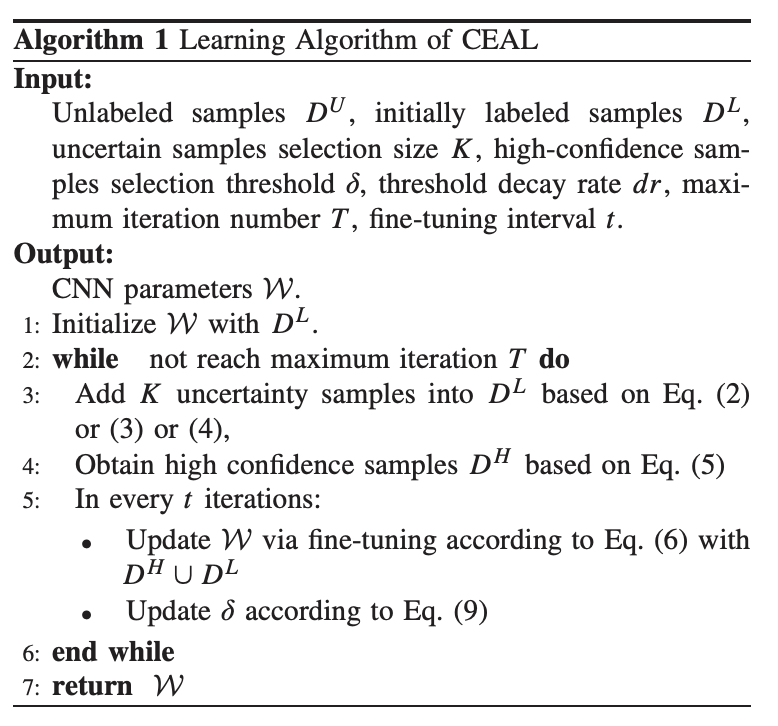
이제 CEAL의 설명은 끝났습니다. 아래가 CEAL에 대해 요약을 나타낸 수도 코드입니다.
Experiments
Dataset으로는 Caltech-256과 CACD을 사용하였습니다. Caltech-256은 다들 아실 것이라 생각되고. CACD는 face identification 과 retrieval problems을 위한 데이터셋으로 2000명의 160,000 이상의 이미지가 포함되어 있습니다. 추가로 age, pose, illumination, and occlusion와 같은 정보가 포함되어 있습니다. 아래 이미지에서 CAltech-256 그리고 CACD 이미지 일부를 확인할 수 있습니다.

이제 본격적인 비교 실험을 아래 나타내도록 하겠습니다. CEAL_MS는 AL 기준으로 Margin sampling을 사용한 것을 의미합니다.
- AL_ALL: 전체 데이터셋을 supervised 로 학습한 upper를 의미합니다.
- AL_RAND: 랜덤 베이스라인으로 데이터 선택 시 랜덤하게 K개를 선택하는 것을 의미합니다.
- TCAL은 다른 연구진의 방법론으로 불확실성과 다양성을 동시에 고려한다고 합니다.
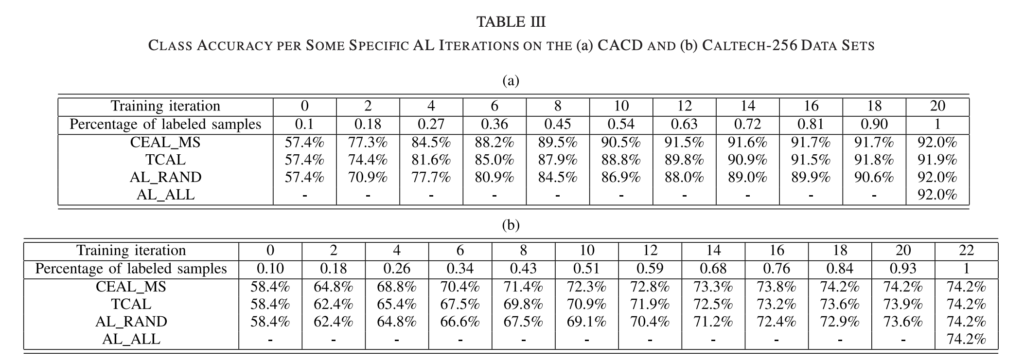
상단 테이블이 실험 결과를 나타내는데요. CEAL이 일관되게 우수한 성능을 보이는 것을 확인할 수 있습니다. TCAL의 경우 학습 시 사용한 소수 데이터에 치중된 샘플만 선택하다 보니, CEAL보다 다소 떨어지는 결과를 보인 것이라고 설명합니다.
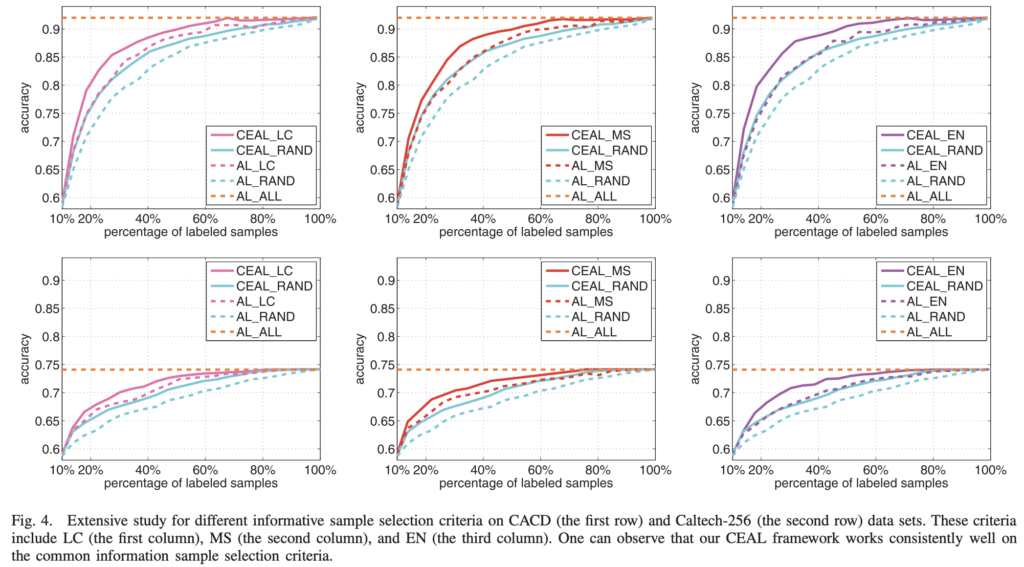
AL_LC, AL_MS, AL_EN은 핵심 contibution인 높은 신뢰도 데이터의 pseudo-label을 통한 finetuning이 없는 방법론입니다. 즉, D^H의 효과를 확인하기 위해 해당 실험을 수행합니다. 상단 그림 4에서 이에 대한 데이터셋 CACD와 Caltech-256에 대한 결과를 보였는데요. 정말 나이브하게 pseudo-label을 사용하기만 해도 CEAL의 성능이 모든 사이클에서 압도적으로 우수한 성능을 보이는 것을 확인하였습니다.
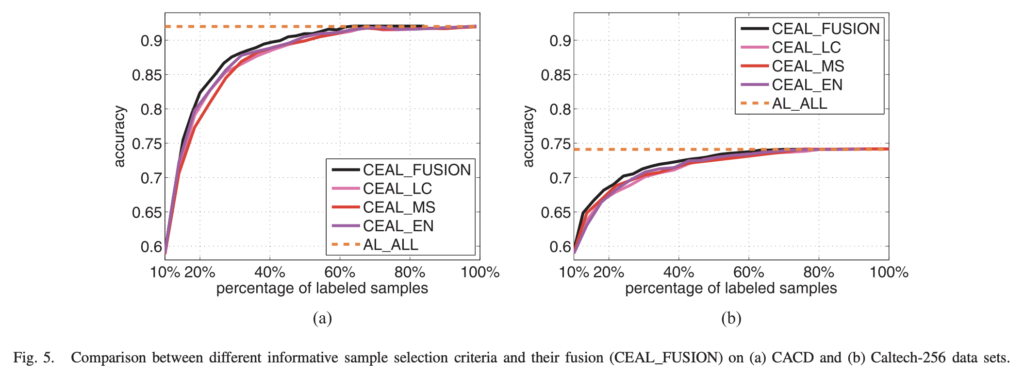
저자는 3가지 AL기준의 영향을 평가하기 위한 비교실험을 수행하였습니다. 그리고 이 기준을 단순하게 결합하는 FUSION 도 시도 했다고 하는데요. 매 cycle에서 각 기준에 따라 top K/2 샘플을 선택하여 얻은 3K/2 중 반복되는 샘플을 제거합니다. 그 다음 K개의 샘플을 랜덤으로 선택한 것이 CEAL_FUSION 입니다. 이에 대한 실험 결과가 상단 그림 5에 나타나있습니다. LC, MS, EN 모두 비슷하지만, CEAL_FUSION의 성능이 더 우수하다는 것을 확인하였다고 합니다. 이를 통해 유익한 샘플을 선택하는 기준이 정확도 향상에 여전히 중요한 역할을 하고 있습니다.
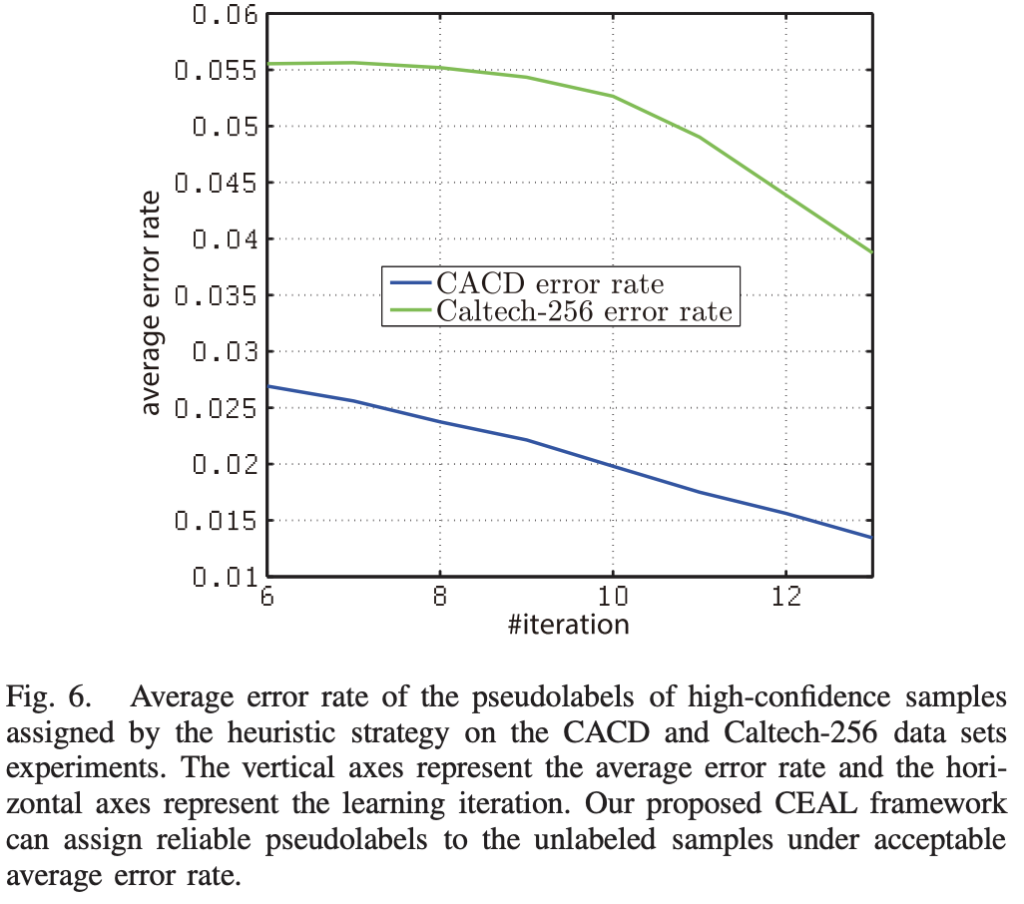
그런데 사실 신뢰도가 높은 샘플에 대한 pseudo-label 의 과신 현상을 무시할 수 없습니다. 모델이 오답임에도 불구하고 높은 신뢰도로 오답을 도출하고 있는 상황을 의미하는데요. 이를 위해 pseudo-label의 오류를 실험으로 보였습니다. 그림 6에서는 학습 cycle에서의 error rate을 나타냅니다. 그 결과 초기 cycle에서도 3%/ 5.5% 미만의 에러율이고 6~12에서는 0.06 이하의 에러율을 보이는 것을 통해 pseudo-label이 오답율이 적다는 것을 보였습니다.
굉장히 간단한 방법론이기에, 처음 Active Learning 이 무엇인지를 접하시는 분들이 공부삼아 보시면 좋을 논문인 듯 합니다.
안녕하세요. 홍주영 연구원님.
설명을 읽다보면 D^L이 minority라고 하고있고, D^L도 majority라고 “B. Complementary Sample Selection”에서 시작하면서 설명하시는데요. D^H인데 잘못 쓰신 거겠죠…?
그럼 얘는 한 사이클에서 학습 3번하는게 맞는거죠? (Sampling된 라벨링 데이터셋 -> Majority -> Minority)
이광진 연구원님 말씀하신 오타 정정 하였습니다 ^^
한 사이클에서는 학습을 두번 하게 됩니다.
1. 선택된 하위셋으로 학습 후 2. majority와 minority 를 선별 및 데이터셋에 추가
그럼 다시 다음 사이클에서 1-2번이 반복되게 됩니다.
안녕하세요 좋은 리뷰 감사합니다.
1. Active learning을 시작하기 위해선 initial labeled set이 필요할 것 같은데, 모델 없이 이를 잘 선택해보자는 방법론도 존재하나요? 랜덤으로 라벨링하고 시작하는 경우, 코드를 공개할 때 이 set을 함께 공개하는지도 궁금합니다.
2. Pseudo label을 만들어줄 대상을 정하기 위한 threshold가 epoch 또는 iteration마다 작아지는 것으로 이해하였는데, 성능이 이에 굉장히 민감할 것 같습니다. 그렇다면 매 epoch 또는 iteration마다 D_H로 선택되는 비율은 실제로 어느정도인가요?
김현우 연구원님 댓글 감사합니다.
1. 네 initial set 을 선별하려는 연구도 많이 있습니다. unsupervised 를 사용하기도 하고, self-supervised 를 사용하기도 합니다. 또한 코드 공개 시, set은 공개하지 않고 있습니다. 이에 따라 AL에서 프로토콜이 필요하다는 의견이 계속 등장하고 있습니다.
2. 비율의 경우 매 사이클 마다, 매 데이터셋마다 다릅니다.
안녕하세요. 좋은 리뷰 감사합니다.
김남일 연구원의 연사 이후 Active learning이 5년 후의 딥러닝 시장에서 필수불가결할 것이란 생각이 들어, Follow해보고자 리뷰를 읽게 되었는데, 초반부 친절한 설명 덕분에 잘 읽을 수 있었습니다.
1. 저자가 문제 삼은 핵심이 결국 AL 모델이 학습 시 Labeled dataset으로 학습한다는 점인데, 실제 환경에선 예를 들어 최근 유행하는 초전도체에 대한 데이터가 없다할지언정, 이전 Labeled dataset은 현재도 충분히 많고(?), 그 데이터만으로 Feature representation만을 학습하여 Unlabeled 초전도체 데이터의 Pool을 정하면 되지 않나요..? 잠시, 질문하다보니 이것이 AL이 맞나 싶기도 하네요. 고가치 Annotation할 데이터를 선별해주는 측면에서만 바라봤을 땐, 결국 어떤 Unlabeled 데이터에 대해 그 데이터가 학습 과정에 없는 클래스여도 AL이 가능하나요?
2. 다시 위의 질문에 연이어, 질문점으로 저자가 소량의 Labeled 데이터 때문에 성능이 떨어지는 것 같으니, Unlabled 데이터를 학습 단계에서 사용해버리면, Labeled 데이터와 Unlabeled 데이터를 Pseudo-label을 만들어 하나의 모델에 학습해버리면 오히려 Labeled 데이터에서 정교한 표현력을 해칠 수 있다고 생각하는데, 마치 1 과 0.5를 평균내어 0.75로 만들어버리는 것 처럼.. 이에 대해 궁금합니다.
고전적이라고 표현하셨지만 모르고 있떤 LC, MS, EN이 예시와 함께 설명해주시니 굉장히 읽기 좋았습니다.
좋은 리뷰 감사합니다.
이상인 연구원님 댓글 감사합니다.
1. 아무래도 실생활 혹은 상업적으로 Active Learning 을 이용하려면, unseen class 혹은 다양한 domain에도 대응가능해야할 것 같지만.. 안타깝게도 Active Learning의 성숙도가 충분치 않아서 unseen class 에 대한 대응은 어렵습니다. (어딘가에는 있을 수도 잇지만 메인 스트림은 아니랄까요?)
2. 아마 pseudo-label 의 부정확함으로 인한 성능 드랍을 염려하시는 것 같습니다. 그런데 AL에서는 워낙 소량의 데이터셋으로 학습을 시작하기 때문에, 다소 부정확할지라도 pseudo-label과 함께 unlabeled dataset을 추가하는 것이 성능 향상에 좋습니다 (즉, 데이터가 워낙 작아서 발생하는 일) 게다가 저자의 실험에 따르면 Fig 6 pseudo-label의 정확도가 크게 나쁘지 않다는 점을 고려하자면, 데이터가 극히 적은 상황에서는 적절한 대응 법이라 생각이 듭니다.