
안녕하세요.
이번에는 6D pose estimation을 수행하기 위한 방법론이 아닌 데이터셋 논문을 읽어봤습니다. 이번에 처음으로 데이터셋 논문을 읽으면서 느낀 것은 ‘시나리오 구상이 생각보다 쉽지 않다’라는 생각이 많이 들었습니다. 무작정 데이터셋을 만드는 것이 아니라 계획을 꼼꼼하게 세워야 할 것 같습니다. 이번 논문을 읽은 계기는 이승현 연구원님과 함께 데이터셋을 구축하는 방향을 T-LESS와 HomebrewedDB에서의 촬영 환경을 최대한 모사하기 위해 이번 논문을 읽게 되었습니다. 해당 HomebrewedDB 저자는 실제로 T-LESS 데이터셋을 최대한 모방하여 데이터셋을 구성하였고, 최근 6D pose estimation 관련 논문에서 실제로 두 데이터셋이 정확한 pose 정보를 제공하는 데이터셋으로도 언급을 하기 때문에 저희는 데이터셋 구축을 해당 셋업을 최대한 따라가볼 예정입니다.
시작하겠습니다.
Abstract

6D object pose detector를 구성하고 평가하는 것에 대해 가장 중요한 전제 조건 중 하나는 6D pose가 라벨이 지정된 데이터셋이어야 합니다. 딥러닝의 등장으로 이러한 데이터셋에 대한 수요는 지속적으로 증가하고 있습니다. 일부 데이터셋이 존재하지만, 그 수가 적고 일반적으로 시퀀스당 단일 오브젝트 등 설정이 제한적이거나 textureless한 산업용 부품과 같은 특정 오브젝트 유형에 초점을 맞추는 경우가 많습니다. 실제 데이터 대신 사용 가능한 3D 모델만을 사용한 학습과 확장성 이라는 구성 요소는 잘 고려하지 않는 경우가 많습니다. occlusion, light condition의 변화, 물체 외관의 변화와 같은 다른 문제와 정밀하게 정의된 벤치마크는 아직 존재하지 않거나 여러 데이터셋에 흩어져 있습니다. 이 논문에서는 3D 모델(texture가 있는 모델과 없는 모델 모두)의 학습, 확장성, occlusion, light condition 및 오브젝트 외관의 변화 등 위에서 언급한 문제를 해결하는 6D pose 추정을 위한 데이터셋을 소개합니다. 이 데이터셋에는 다양한 난이도의 13개 scene에 걸쳐 33개의 오브젝트(장난감 17개, 가정용품 8개, 산업 관련 오브젝트 8개)가 포함되어 있습니다.
1. Introduction

이미지 내에서 3D object에 대한 6D pose를 추정하는 것은 컴퓨터 비전에서 중요한 역할을 하는 테스크 중 하나입니다. 그 중에서도 로보틱스 분야에서는 6DoF를 결정하는 것이 필수적인 상황이 많은데요. 대표적으로 Augmented Reality(AR)이나 grasping point를 찾는 테스크가 있을 것 같습니다. 이처럼 6D pose RGB 이미지에서의 정밀한 6D pose를 추정하는 것이 중요한 역할을 하게 됩니다. 최근에 나오는 논문들은 딥러닝 방식으로 접근을 많이 하는 추세이기 때문에 적절한 데이터셋을 확보하는 것도 테스크를 수행하기 위한 중요한 과정 중 하나가 되게 됩니다. 6D pose estimation을 수행하기 위한 대표적인 데이터셋인 LineMOD, T-LESS 데이터셋 같은 경우 어떤 특정한 scene에 대해 texture-less하다거나 target 별 오브젝트 유형을 다룹니다.
LineMOD에는 주로 뚜렷한 형상을 가진 장난감과 가정용품이 포함되어 있으며, 존재하지 않거나 사소한 장애물이 있는 복잡한 환경에서 물체를 감지하는 데 집중합니다. 총 15개로 개별 이미지 시퀀스가 포함되어 있지만 각 시퀀스에는 단일 오브젝트에 대해서만 6D pose annotation이 되어있습니다. 그에 비해 T-LESS는 좀 더 큰 데이터셋으로 오브젝트 간 유사성과 대칭성이 강한 texture가 없는 산업용 오브젝트에만 초점을 맞춥니다.
6D pose detector 에서 종종 간과되는 중요한 측면 중 하나는 확장성입니다. 대부분의 데이터셋에는 다소 적은 수의 개체가 포함되어 있습니다. 특히 모든 프레임에 모든 오브젝트의 pose를 사용할 수 있어야 하는 경우 많은 수의 3D 모델과 pose가 annotation 된 scene을 제작하는 것은 쉽지 않은 과정이기 때문에 당연한 결과입니다. 딥러닝을 이용한 detector를 학습하면 좋은 결과를 얻을 수 있는데요. 하지만 3D 모델을 렌더링하여 학습 데이터를 추가적으로 synthetic 데이터를 만들어 사용을 하는 것도 결국 detector를 사용하는 논문에서만 사용이 되어왔습니다. 그리고 6DoF object detector을 사용하는 것을 보면 객체당 하나의 네트워크를 사용하는 점을 저자는 문제로 삼는데요. 이 문제의 주요 원인은 다양한 시퀀스와 잘 정의된 벤치마크가 포함된 적절한 데이터셋을 사용할 수 없기 때문에, LineMOD와 같이 잘 연구된 단순한 데이터셋으로 대체할 수 밖에 없기 때문입니다. 그렇지만, 객체당 하나의 네트워크를 학습하는 것은 심층 신경망의 본질적인 특징인 확장성 측면에서 불리한 결과를 보인다고 합니다. 따라서 저자가 제안한 데이터셋의 목표는 해당 새로운 벤치마크를 도입하여 방법론들에 대한 확장성을 테스트하고 실제 데이터를 사용하는 대신 3D 모델의 렌더링에 대한 detector 학습을 유도하는 것입니다.
2. Related Datasets
T-LESS Dataset
BOP에서 많이 사용되는 벤치마크 데이터셋 입니다. 해당 데이터셋을 구성하기 위해 3대의 동기화된 카메라(PrimeSense Carmine 1.09 및 Kinext 2 RGB-D 카메라, Canon RGB 카메라)로 캡처한 30개의 textureless한 산업 물체와 20개의 RGB-D scene이 포함되어 있습니다. 이 데이터셋의 오브젝트들은 오브젝트 간 유사성이 매우 높습니다. 구성된 scene은 단순(복잡하지 않고 scene당 여러 개의 오브젝트)한 것부터 복잡(복잡하고 오브젝트 더미로 가득 차 있으며 일반적인 로봇이 bin-picking을 하는 시나리오를 모방한 것)한 것까지 다양합니다. 직접 설계한 CAD 모델과 reconstruction된 3D 모델 모두 T-LESS에 포함되어 있습니다. 학습 이미지에는 검은색 배경에 오브젝트만 포함된 반면에 테스트 이미지에는 각 프레임의 각 오브젝트에 대해 라벨이 지정된 6D pose로 전체 scene을 캡처합니다. 해당 데이터셋의 구조는 매우 뛰어나지만 대칭성, 낮은 texture 및 개체의 특성으로 인해 매우 까다로운 데이터셋 입니다. 저자는 T-LESS에서 영감을 받아 구조적인 측면에서 이와 유사한 데이터셋을 구성하였다고 합니다. 저자가 제안한 데이터셋은 장난감, 가정용 물체, 산업용 물체 등 더 광범위한 물체 유형을 포함합니다. 또한 occlusion 문제와 함께 데이터셋을 구축하는 것을 목표로 했으며, 이를 통해 더 많은 frame과 scene을 제공하고자 했다고 합니다.
3. HomebrewedDB Dataset Creation

이번 논문의 데이터셋을 저자는 다음과 같이 소개를 합니다.
- 매우 정확하게 reconstruction한 33개의 3D 모델
- 13개의 시퀀스
- 정확한 6D pose annotation
- 벤치마크 데이터셋
3.1. Calibration of RGB-D Sensors
valid와 test에 대한 시퀀스 영상에는 PrimeSense Carmine 1.09와 Microsoft Kinect2으로 2개의 RGB-D 센서를 사용했다고 합니다. calibration을 수행하기 위해 기존의 체크보드 보다 좀 더 나은 calibration 결과를 제공하기 위해 ArUco 보드를 구성했다고 합니다. calibration 결과는 RMSR(Root-mean Square Reprojection) error는 각 센서에 해당하는 carmine에서는 0.5 픽셀, Kinect2에서는 0.2 픽셀이었다고 합니다.
3.2. Sequence Acquisition
각 RGB-D 센서로 각 scene에 대해 총 1개의 handheld 시퀀스와 2개의 턴테이블 시퀀스를 획득했습니다. 턴테이블 시퀀스는 삼각대에 장착된 카메라를 사용하여 물체가 있는 마커보드의 전체 360^\circ 회전을 캡처합니다. 각 턴테이블 시퀀스에는 30^\circ 및 45^\circ의 각도로 촬영된 170개의 RGB 및 depth 이미지가 있습니다. 이 데이터는 GT 6D pose label과 함께 valid 데이터셋을 구성합니다. 이와 대조적으로 test 시퀀스는 handheld 모드로 recording했습니다. 제가 생각해도 handheld는 뭔가 부정확한 결과를 이룰 것 같다고 생각을 하는데, 저자가 handheld를 사용한 이유에 대해 언급을 합니다.
첫 번째 이유는 명백한 장점으로 일반적인 카메라 사용과 매우 유사하다는 점이며, 두 번째 이유는 평면 내 회전뿐만 아니라 상당한 스케일 변화 측면에서 카메라 pose에 더 많은 변화를 도입할 수 있다는 점입니다. test 시퀀스에서는 각 센서로 각 scene의 총 1000개의 RGB 및 해당 depth 이미지를 캡처했습니다. 각각의 scene을 촬영하는 동안 마커보드 주변을 한 바퀴 돌면서 진행을 했다고 합니다. test 시퀀스 내에서 카메라에서 물체까지의 거리는 0.42~1.43m로 다양했으며, 고도는 11^\circ ~ 87^\circ 이내였다고 하네요.
그림(3)과 (4)를 보시면 사이드에 깔려있는 보드를 ArUco 마커라고 합니다. 카메라의 pose 추정을 좀 더 잘 할 수 있도록 하는 역할이라고 보시면 되겠습니다. 그림(3)에서 의미하는 내용은 데이터셋을 구성하기 위한 몇가지 시나리오를 나타낸 것인데요. 오브젝트를 단색(흰색 or 진한파란색)에 대해 Lambertian surface위에 배치를 한 것도 있고 더 복잡한 시나리오에서는 오브젝트를 multicolor reflective surface 위에 배치하기도 했다고 합니다. Lambertian surface는 모든 viewpoint에서 봐도 똑같은 밝기도 보이는 표면을 의미합니다. 이러한 surface와 다르게 multicolor reflect surface는 다양한 색상으로 반사되도록 하는 표면을 의미로 프리즘과 같은 역할을 하는 장치가 있을 것으로 보입니다. 해당 내용은 그림(4)에 해당하는 것 같은데 어떤 스포트라이트를 다양한 색상과 빛의 강도를 조절하면서 큰 texture 변화에 대한 robust함을 평가하기 위해 domain adaptation 시퀀스를 만들었다고 합니다.
이처럼 HomebrewedDB(HDB) 데이터셋에 대한 새로운 기능(?) 중 하나는 light condition의 큰 변화에 대한 detection 및 pose estimation 방법의 robust함을 test하기 위한 시퀀스라고 이해하시면 되겠습니다.
3.3. 3D Model Reconstruction
HBD에 제시된 3D 모델은 3D scanner를 사용해서 얻었다고 하네요. (좀 많이 비싸보입니다………) 여튼 이러한 스캐너를 이용하여 여러 시점에 대해 물체를 스캔해서 얻었습니다. 결국 좋은 스캐너가 퀄리티가 좋은 3D 모델을 reconstruction하는 데 중요한 역할을 하는 정밀한 depth 측정과 고해상도 texture map을 제공하기 때문에 해당 스캐너를 사용했다고 하네요.
3.4. Depth Correction
저자는 Carmine과 Kinect2의 depth를 뽑는 중 system상의 문제가 있음을 알았다고 합니다. 측정된 depth 값이 calibration된 RGB 카메라로 캡처한 이미지의 마커에서 계산된 depth 값과 항상 조금씩 다르다는 것을 발견했습니다. 이를 해결하기 위해 1차 다항식 즉 Least Square를 사용하는 것이 이 depth 측정의 correction factor로 더 효과적이라는 것을 해당 셋업에서 확인을 할 수 있었다고 합니다. 측정값의 노이즈를 고려하기 위해 정규화된 Least Square을 사용하여 linear depth-correction 모델을 만들어 사용했다고 합니다.
3.5. Creation of Ground Truth Annotation
해당 데이터셋에서 GT pose는 어떻게 annotation을 하였는지 알아보도록 하겠습니다.
첫 번째로 마커보드 pose를 추정하여 scene에 대한 카메라 trajectory를 제공한 다음 모든 이미지를 순서대로 사용하여 scene의 depth map에 대한 signed distance field fusion을 통해 dense한 3D reconstruction을 얻습니다. 이때 Curless and Levoy 방법을 사용했다고 합니다.
두 번째로 3D 모델의 자체의 좌표계에서 scene의 좌표계(즉, 마커보드)로의 rigid-body transformation을 추정하는 것입니다. 마커보드에 대한 오브젝트의 pose는 다른 센서로 이미지를 얻을 때 변경되지 않았으므로 마커보드 좌표계에서 오브젝트의 pose를 가져온 다음, 다른 센서 또는 카메라 좌표계로 전달하면 충분했기 때문에 새로운 센서마다 reconstruction을 수행하지 않아도 됐다고 합니다. reconstruction된 scene에서 3D 모델 pose를 추정하기 위해 축소된 reduced 2D search space에서 효율적인 voting 방식을 통해 local mathcing에 사용되는 타겟 모델의 point-pair feature representation을 기반으로 하는 방법을 사용했습니다. 마커보드에서 추정된 각 이미지의 카메라 pose와 마커보드 좌표계의 객체 pose를 사용하면 각 프레임에 대한 6D 객체 pose를 쉽게 계산할 수 있습니다. 하지만 RGB 이미지 위에 3D 모델을 렌더링한 결과, 사용한 방법이 pose의 초기 추정치를 잘 제공하더라도 많은 경우 대해서 discrepancy가 남아 있어 refinement 과정에서 이를 완화해야 한다는 사실을 알게 됐습니다.
세 번째로 앞서 pose를 개선하기 위해 refinement 과정은 2D edge-based ICP를 통해 refinement를 수행했다고 합니다. 시퀀스의 각 오브젝트에 대해 오브젝트가 occlusion이 되지 않은 RGB 이미지를 자동으로 선택했습니다. 이러한 과정은 scene의 모든 오브젝트를 추정된 초기 포즈로 렌더링하고 대상 오브젝트의 visible 픽셀 비율을 계산하는 방식으로 수행되었습니다. 모든 카메라 pose가 고정되도록 multi-view에 대한 consistency를 적용하고 scene 좌표계에서 오브젝트 pose에 대해서만 optimization 했다고 합니다. depth 측정은 상대적으로 노이즈가 많고, 특히 Kinect2로 캡처한 이미지의 경우 depth와 RGB 이미지 간에 약간의 misregistration이 되는 현상이 발생하기 때문에 RGB 이미지에 대해 edge-based refinement를 수행했습니다.
3.6. Accuracy of Ground Truth Poses
만들어진 GT를 어떻게 평가하는지에 대해 알아보겠습니다.
계산된 기준점 pose를 사용하여 3D 오브젝트를 렌더링하고 렌더링된 이미지와 캡처된 이미지 모두에서 유효한 depth를 가진 각 픽셀 쌍에 대한 차이 \delta = d_{c} -d_{r}을 계산했습니다. 여기서 d_c와 d_r은 각각 캡처 및 렌더링된depth 값을 의미합니다.
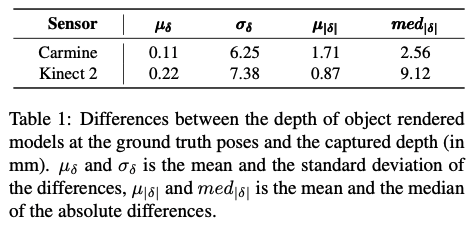
전체 test셋에서 얻은 통계는 표(1)에서 확인할 수 있는데요. 각 depth 값의 residual에 대한 평균과 표준편차 그리고 중간값이 나와있는 것을 확인할 수 있습니다. T-LESS에서와 마찬가지로 5cm를 초과하는 차이는 이상값으로 통계에서는 생략이 되었는데요. 해당 HBD에서는 이상값이 3.7%정도 있었고 이는 오브젝트를 occlusion시키는 clutter 오브젝트, 센서 측정 노이즈 또는 reconstruction된 3D 모델과 실제 오브젝트 간의 minor한 discrepancy로 인해 발생됨을 확인했다고 합니다. 리포팅 된 결과를 보면 렌더링된 depth map이 Camine으로 얻은 depth와 잘 align 되어 평균 깊이 차이가 0에 가깝고 차이의 절대 평균이 2mm 이하라는 것을 알 수 있습니다. Kinect2의 경우 depth 차이에 대한 평균값과 절대 평균값도 0에 매우 가깝게 유지되며, 절대 중앙값이 절대 평균보다 현저히 높아 depth 차이의 분포가 왼쪽으로 치우쳐 있음을 나타냅니다. 이는 Kinect2에서 캡처한 RGB 및 depth 이미지가 약간 misregistration되었을 수 있으며, time-of-filght 원리에 따라 이 depth 센서의 측정에서 노이즈의 크기가 더 크기 때문에 발생할 수 있습니다. time-of-filght는 빛이나 신호가 나가서 다시 돌아오는 시간을 측정하여 거리나 깊이 정보를 파악하는 것을 의미합니다.
4. Benchmarks and Experiments
평가 지표로는 2D detection에서 사용하는 Precision, Recall, mAP를 사용하였고 6D Pose를 평가하기 위해 ADD metrics를 사용했다고 합니다.
Scalability Benchmarks
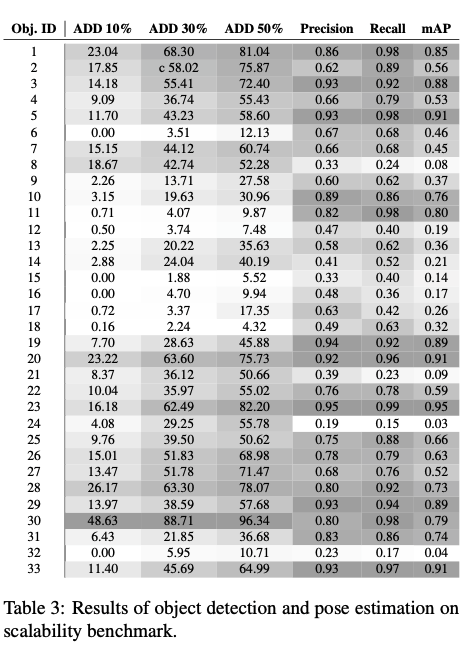
첫 번째 벤치마크는 객체 수에 대한 method의 확장성을 평가하기 위한 목적으로 도입되었습니다. 해당 벤치마크에서 핵심은 데이터셋에서 사용 가능한 모든 객체에 대해 단일 네트워크를 학습하고 모든 객체가 포함된 시퀀스셋에서 테스트하는 것입니다. 구체적으로, 이를 위해 33개의 객체가 모두 존재하는 시퀀스의 minimal subset을 형성하는 1번부터 8번까지의 시퀀스셋에 대해서 평가합니다.
Scene Benchmarks
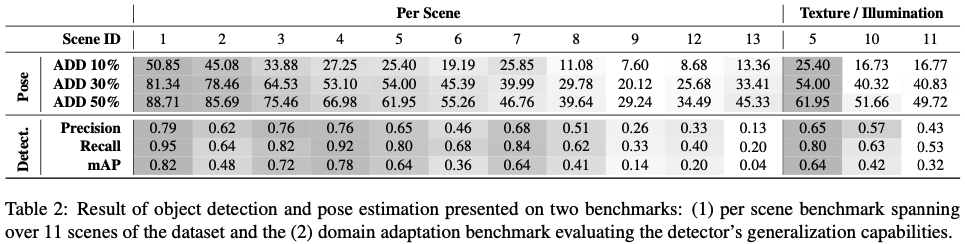
HDB는 다양한 난이도의 13개 시퀀스 형태의 scene들을 제공하며, 각 scene은 별도의 벤치마크를 나타내며, 여기에 포함된 모든 오브젝트는 학습에 사용됩니다. illumination condition이 변경되거나 texture가 변경된 scene(예: 10번 및 11번 시퀀스)을 제외한 나머지 모든 scene을 scene별 벤치마크에 포함했습니다. 모든 오브젝트 detect 및 pose 추정 결과는 scene에 존재하는 모든 오브젝트에 대해 평균을 냅니다. 표(2)에는 scene별 오브젝트 detect 및 pose 추정에 대한 성능이 나와 있습니다. 오브젝트 수가 적고 occlusion이 적고 clutter가 없는 시퀀스에서 두 과정 모두에서 DPOD가 훨씬 더 나은 성능을 보였습니다. 또한 산업 물체로만 구성된 scene 8번의 경우 감지 및 포즈 추정 모두에서 낮은 성능이 리포팅 되었습니다.
Domain Adaptation Benchmark
해당 벤치마크에서의 주요 목표는 light condition과 오브젝트 texture의 큰 변화에 대해서 robust함을 평가하는 것입니다. 해당 평가는 동일한 오브젝트 셋이지만 light와 오브젝트 표면의 색상이 다른 세 가지 scene(5번, 10번, 11번 시퀀스)으로 구성됩니다. scene 5번은 물체의 외관을 변경하지 않고 주변 light condition에서 캡처했습니다. scene 10번에서는 spotlight를 사용하여 다양한 색상과 강도의 빛을 물체에 비추어 조도에 상당한 변화를 주었고, scene 11번에서는 물체 표면에 페인트를 칠하여 질감을 변경했다고 합니다.
5. Conclusion
이번 논문에서는 6D object detection을 위한 새로운 challenge 데이터셋을 제안했으며, 확장성과 occlusion, light condition 및 외형 변화에 대한 robust함 등을 detector가 갖춰야 할 가장 중요한 속성을 다루었습니다. 다양한 난이도의 13개 시퀀스로 scene이 구성되어 있고, 33개의 오브젝트가 포함되어 있습니다. 각 scene 마다 어떤 벤치마크를 다루는지에 대해 알아보았습니다.
좋은 리뷰 감사합니다.
해당 논문은 다양한 시나리오를 포함하고자 surface와 light condition 등에 대해 고려한 것이 인상적입니다.
기존의 체크보드 보다 좀 더 나은 calibration 결과를 제공하기 위해 ArUco 보드를 구성하였다고 하셨는데, 기존의 체크보드와 ArUco 보드의 차이는 무엇인가요?? 여기서 이야기하는 ArUco 보드는 기존 6D dataset에서 사용하던 marker와 같은 것인가요??
또한, annotation 과정에서 초기의 pose를 마커보드를 이용하여 구한 뒤, 여기에 discrepancy를 해결하기 위해 refinement를 수행한다고 이해하였습니다. 그렇다면 앞서 구한 dense한 3D reconstruction은 annotation에는 사용되지 않는 것인가요??
안녕하세요, 리뷰 읽어주셔서 감사합니다.
1. 기존 체크보드 정해진 크기의 흑백 패턴으로 구성되며, 카메라 캘리브레이션 및 객체 추적과 같은 작업에 사용됩니다. 반면 ArUco 보드는 흑백 패턴으로 구성되는 것은 같으나 각 모서리에 고유한 마커를 가지며, 이를 활용하여 객체의 위치 및 방향을 추정하는 데 더욱 용이하게 해준다고 합니다. 그리고 ArUco는 marker board를 의미하는 것이 맞습니다.
2. scene에 대한 depth map을 구하고 SDF fusion을 통해 dense 3D reconstruction을 얻고 reconstruction된 scene에서 3D 모델 pose를 추정하기 위해 축소된 reduced 2D search space에서 효율적인 voting 방식을 통해 local mathcing에 사용되는 타겟 모델의 point-pair feature representation을 기반으로 하는 방법으로 사용했다고 합니다.
감사합니다.
좋은 리뷰 감사합니다.
먼저 초반에 texture가 있는 모델에서 texture가 의미하는게 예를 들어 컵의 손잡이라던가 강아지의 귀라던가 이런 특징들을 의미한다고 이해하는게 맞나요?
그리고 calibration결과를 개선하기위해 사용한 ArUco보드는 기존 marker board와는 다른가요? 다른 보드라고 한다면 가장 크게 다른 점은 어떤 점인지 궁금합니다.
그리고 test sequence에서 카메라로부터 물체까지 거리가 1m 내외로 되게 가까워 보이는데 rgbd camera가 신뢰도 있는 depth를 뽑을 수 있나요?
마지막으로 난이도에 따라 13개의 다양한 sequence scene으로 구성하였는데 이때 난이도는 어떤 기준에 따라 나눈 것인지 궁급합니당
감사합니다.
안녕하세요, 리뷰 읽어주셔서 감사합니다.
1. texture가 있는 CAD 모델의 경우, 도경님이 말씀하신대로 디테일한 정보(색상, 구체적인 모양)를 나타낸다고 이해하시면 되겠습니다.
2. 기존의 마커보드와 같은 의미로 사용이 됩니다. 기존의 마커보드도 비슷한 기능을 할 것으로 보이지만 기존의 마커보드 보다 더 정확한 pose를 제공하도록 만든 널리 알려진 마커보드라고 합니다.
3. 실제로도 0.42 ~ 1.43m 로 다양하게 찍었다고 하는데 가까운 거리에 대해서는 의미있는 depth map을 못 뽑지 않았을까 라고 추측을 하고 있습니다. 해당 내용에 대해서는 어느정도의 거리가 신뢰도를 가지는 거리인지 구체적으로는 언급하지 않아 아쉽기는 하네요.
4. 각 밴치마크가 목표로 하는 기준으로 sequence가 구성되어 있습니다.
감사합니다.
안녕하세요 ! 좋은 리뷰 감사합니다.
제가 6D pose estimation 데이터셋에 대해 잘 몰라서 드리는 질문일 수 있는데요 .. 데이터셋에 대해 다양한 난이도라는 표현을 해주셨는데 데이터셋이 난이도라는 것을 구분하여 제공이 되나요 ?
그리고 기존의 체커보드보다 좀 더 나은 calibration 결과를 제공해주기 위해 ArUco 보드를 구성하였다고 하는데, 각 보드마다 조금씩 다르게 구성되어 있어 그 region에 특징으로 사용할 수 있는건가요 . . ? 어떤 점에서 ArUco 보드를 사용하는 것이 카메라의 pose를 추정하는데 도움이 되는 것인지 와닿지 않아 질문 드립니다.
안녕하세요, 리뷰 읽어주셔서 감사합니다.
1. 난이도라고 표현을 했는데, 간단하게 각 벤치마크에 대한 목표에 따라 시퀀스로 제공되었다고 생각하시면 되겠습니다.
2. 해당 ArUco 보드를 통해 camera의 pose를 추정하는 과정에 대해서는 정확하게는 잘 모르지만, 체크보드의 경우, 회전 정보를 추정할 때 체크보드의 모서리나 라인을 활용하는데, 이 때 정확한 모서리 감지와 패턴 분석이 필요합니다. 그러나 체크보드의 경우 패턴이 덜 구조화되어 있기 때문에 모서리나 라인이 감지되지 않거나 불안정한 경우가 발생할 수 있습니다. 반면에 ArUco 보드의 경우 이미지를 보시면 아시겠지만 패턴 자체가 뚜렷한 각각의 구조를 가지고 있으므로, 패턴을 감지하고 해석하는 과정이 비교적 정확하게 가능하다고 합니다. 그렇다고 무조건 ‘체크보드는 좋지 않은 건가?’ 이렇다기 보다는 최근에는 6D pose estimation 데이터셋을 구성할 때 ArUco 보드를 많이 사용하는 추세로 보입니다.
감사합니다.
안녕하세요, 양희진 연구원님, 좋은 리뷰 감사합니다.
좋은 데이터셋을 어떤 관점에서 찍을지, 데이터셋에서 집중하고 싶은 문제가 무엇인지 고민이 느껴지는 리뷰였습니다. 확실히 task가 이제는 점점 복잡해지다 보니 dataset을 구성할 때도 어떤 점에 집중할지 결정하고 설계하는게 쉽지 않아 보입니다.. 고민 끝에 좋은 돌파구를 찾을 수 있길 바랍니다.
간단한 질문 하나 남기겠습니다. 리뷰 전반에서 3d object의 ‘Texture’가 자주 언급되는데, 이 texture가 구체적으로 무엇인지, dataset에서 어떻게 이루어지는지 이해하기 어렵습니다. 이에 관련된 설명이 가능하실까요?
감사합니다.
안녕하세요, 리뷰 읽어주셔서 감사합니다.
구체적으로 해당 데이터셋을 어떤식으로 구성했는지 말씀을 드리면 instance-level에서의 6D pose estimation을 수행하기 위해서는 이미지 내의 존재하는 물체에 대응하는 3D CAD 모델이 있어야 합니다. 이러한 3D CAD 모델은 자신이 가지고 있는 texture 정보가 있을 것입니다. 즉, 색상, 광택, 재질 등등 디테일한 정보를 가지고 있을텐데 이러한 texture 정보를 기반으로 task를 수행합니다. 하지만 이러한 texture는 여기서 자주 언급되는 light condition(조명 조건)과 같은 환경 변동에 매우 민감합니다. 이러한 문제에 대한 평가를 하기 위해 10번 시퀀스를 보시면 여러가지 조명을 주어 강인함을 평가하는 Domain Adaptation 벤치마크를 구성했습니다.
감사합니다.