안녕하세요, 허재연입니다. self-supervised learning 중 contrastive learning을 기반으로 하는 방법이 널리 사용되고 있는데, 어떤 방법론이 많이 사용되는 방법인지, 각 장단점은 무엇인지 판단하기 쉽지 않아 관련 자료를 찾아보다 본 논문을 읽어보게 되었습니다. Constravie Learning 기반 Self-Supervised Learning 방법들 중 굵직한 흐름을 파악할 수 있었기에 이 논문을 요약해 보고자 합니다.
Abstract
Self-supervised learning(SSL)은 이미지에서 의미론적 표현(semantic representations) 학습 절차를 발전시켰습니다. SSL는 학습 단계에서 class label에 덜 의존함으로써, 데이터 annotating/labeling 필요성을 줄였습니다. Constrative Learning(CL)을 사용하는 SSL방법은 학습 데이터의 label에 대한 의존도가 갖기 때문에 널리 사용되고 있습니다. 다양한 CL 방법은 supervised learning의 benchmark로 사용되는 다양한 데이터셋에 대해 SOTA를 달성하고 있습니다. 본 논문에서는 SimCLR, MoCo, BYOL, SwAV, SimSiam을 포함해서 CL기반 방법론들에 대해 살펴봅니다. 특히, ImageNet 및 VOC07 벤치마크에서 각 파이프라인의 정확도 측면을 비교합니다. BYOL은 이미지 분류 작업에서 74.30%의 정확도를 달성하는 기본적이고 강력한 모델 구조를 제안합니다. SwAV는 클러스터링 접근법으로 ImageNet 분류에서 75.30% top-1 accuracy를 달성하며 다른 방법론들을 앞질렀습니다. 마지막으로 오늘날 막대한 양의 데이터 사용을 극대화할수 있는 CL 접근법의 중요성을 살펴보고 현재 CL 방법론의 한계를 짚어보고 효율적인 CL 파이프라인 필요성을 강조했습니다.
Introduction
지난 10년동안 AI연구에서는 대량의 labeled data로 모델을 훈련해서 AI기반 시스템의 성능을 높이기 위해 노력했습니다. 이러한 방식은 주석이 달린 데이터에 크게 의존하게 됩니다. supervised learning은 대규모 데이터셋과 좋은 컴퓨팅 리소스로 좋은 결과를 보여주었습니다. 바꿔 말하면, 이 방법은 주석을 달 수 없거나 few-shot 문제를 처리하는 상황에서 잘 동작하지 못합니다.
최근 연구 커뮤니티의 관심사는 Self-Supervised learning으로 알려진 생성(generative) 및 대조(contrastive) 기법의 통합으로 확장되었습니다. 일반적으로, SSL 기반 접근법은 cost가 높은 주석 없이 데이터 자체에서 feature representation을 학습함으로 기존 접근법의 어려움을 완화했습니다. Self-Supervised Learning에서 generative pretext task는 pseudo-label을 가진 input sample에서 feature를 학습합니다(unlabeled data에서 모델이 label을 생성해 downstream task에 유용한 representation을 학습합니다). pretext task 중 표현을 잘 학습하는 방법으로는 Colorizing, super-resolution, image in-painting, 직소 퍼즐 풀기, audio-visual correlation 등이 있습니다.
반대로, Contrastive Learning(CL)은 하나의 객체를 다른 객체와 구변하는 데 도움이 되는 representation을 형성하는 discriminative scheme에 기반합니다. CL의 목적은 의미론적으로 관계가 있는 feature는 끌어당기고, 관계가 없는 feature끼리는 서로 밀어내는 방식으로 representation을 학습하는 것입니다.
Self-Supervised Learning 기반 방법들은 특정한 downstream task를 효율적으로 수행하는데 pretext phase에서 학습된 지식을 활용합니다. 여기서 downstream task로는 classification, detection, segmentation 등이 있을 수 있습니다. Self-Supervised Learning과는 다르게, Semi Supervised Learning은 학습을 위해 적은 양의 labeled data을 필요로 합니다. 반면 Self-Supervised Learning은 데이터의 구조 및 표현 자체를 학습합니다.
Unsupervised learning에서 데이터 없이 사전학습을 진행 시켜서 신경망이 더 잘 동작하고 representation space를 더 의미 있게 만들 수 있습니다(self-supervised learning을 진행할 때 unlabeled data를 이용하므로 unsupervised learning의 일종으로 보는 시각도 있습니다). 이미지를 cropping, 반전 시키거나 생상 및 밝기에 변화를 주는 random augmentation으로 동일한 이미지에서 다른 이미지를 얻을 수 있습니다. CL을 적용할 때, 데이터셋에서 동일 이미지에 속하는(하나의 이미지에서 다른 augmentation을 적용한) 이미지들은 ‘positive’로, 다른 이미지에 속하는 이미지들은 ‘negative’로 설정해서 positive는 서로 끌어당기고 negative는 서로 밀어내게 됩니다. 결국 동일 이미지의 random transformation을 통해 신경망을 일반성을 가지게, 그리고 robust하게 만들어 낼 수 있습니다. 이런 transformation을 기반으로 한 embedding space는 adaptable representation을 만들어내어 상당히 개선될 수 있습니다.
unsupervised pretraining을 위한 contrative 접근법에서 연구자들이 직면한 문제는 동일 클래스에 속해야 할 샘플들을 멀리 떨어지게 만들어서 분류기가 나중에 결정 경계를 잘 만들기 어렵게 한다는 것입니다(contrastive pretraining 과정에서 label 없이 학습하며 동일 이미지를 제외하고는 다 밀어버리니 동일 클래스의 이미지끼리도 negative pair로 간주되죠). Supervised contrastive learning은 이런 문제를 pretraining objetive에 label을 도입해서 해결했습니다. 결국 목적은 방향이나 씬, 특징이 달라도 동일 클래스에 속한 샘플들을 올바르게 분류하는 것이죠. constrative pretraining 목적함수는 cross entropy loss보다 데이터셋의 정보를 더 잘 활용합니다.
최근의 주목할만한 연구로는 CL을 dynamic dictionaruy lookup문제로 간주하는 MoCo, ImageNet dataset에서 지도학습으로 훈련된 SOTA와 비슷한 성능을 내는 SimCLR 및 SimSiam이 있고고, pretext task의 효과와 모델 성능을 향상시킨 방법을 보여준 BYOL와 SwAV이 있습니다.
Importance of Self-Supervised Learning
오늘날 우리는 labeled data를 통해 수많은 task specific 기계 학습 모델을 학습시킬 수 있었습니다. 하지만 이런 모델들은 다른 task로 일반화하기에는 한계가 있고 훈련된 특정 task에서만 잘 동작합니다. 이와 달리 사람과 동물은 몇몇 사례를 통해 학습하고 해당 지식을 일반화해서 다른 영역에 활용할 수 있습니다. 매번 물체를 식별하기 위해 방대한 양의 학습 데이터가 필요하지 않습니다. 인간 및 동물이 하는 방식으로 task를 일반화 시키는 능력은 여전히 인공지능에 있어 열려있고 도전적인 연구 영역입니다. 비교적 쉽게 사용할 수 있는 막대한 양의 데이터 영역에서 많은 task를 일반화할 수 있는 그런 모델을 만드는 방법 중 하나가 바로 일반 지능을 기계학습 모델에 근사시킬 수 있는 SSL입니다. SSL은 레이블에 의존하지 않고 data의 힘을 활용하여 supervised model이 학습하기 어려운 미묘한 표현과 패턴을 학습합니다.
SSL은 좋은 representation을 학습하는 것 외에도 데이터 annotation process에 수반되는 문제와 비용을 완화시킵니다. data annotation은 비용이 많이 드는 작업입니다. 우리가 쉽게 떠올릴 수 있고 자주 드는 예시로 segmentation 데이터셋 annotation이 있겠죠. annotator가 픽셀 단위로 레이블을 지정하고 경계선을 설정해야 하는데 시간이 오래 걸릴 뿐더러 정확하지 않은 annotation에 의해 학습에 악영향을 미칠 수 있습니다.
SSL은 데이터 클래스 레이블에 대한 의존을 완화함으로써 방금 말씀드린 데이터 레이블링의 많은 문제를 해결하는데 도움이 됩니다. SSL을 통해 비지도 방식으로 표현을 학습시키고 각 downstream task에 fine-tuning하면 됩니다.
Existing Models
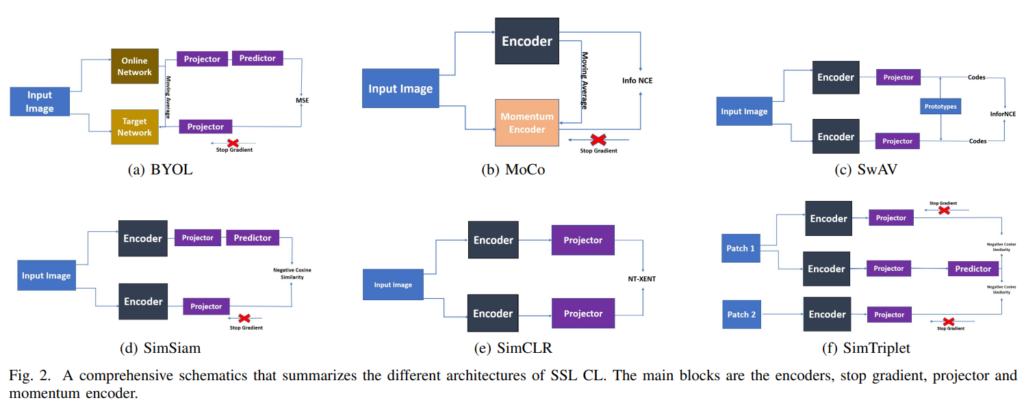
A. MoCo
Momentum Contrast (MoCo)는 쿼리를 positive key encoding과 일치시키고 negative key encoding과 가능한 한 유사하지 않게 하기 위해 contrastive learning을 dictionary 관점에서 봅니다. SimCLR와 같은 end to end 방식은 query와 key를 인코딩하고 gradient를 각 query encoding network와 key encoding network에 통과시켰습니다.
MoCo는query encoder에만 gradient를 전파되게 해서, query encoder의 파라미터에 대한 momentum update를 추가하여 key encoder가 업데이트 될 수 있도록 했습니다.
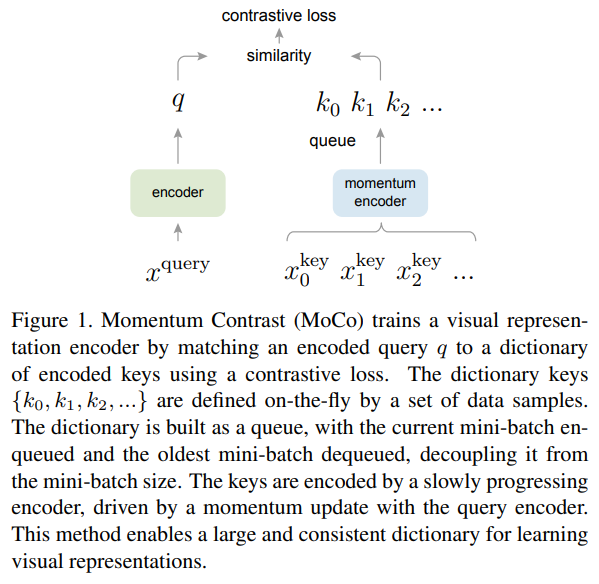
MoCo에서, query가 dictionary의 key와 매칭되므로 loss를 dictionary lookup problem으로 정의될 수 있습니다. 이미지는 query featuers로 encode될 수 있으며, dictionary는 대규모 이미지 셋의 feautures로 구축됩니다.

MoCo의 동작 과정입니다. MoCo의 특징에 대해 보시려면 마지막 부분 momentum update와 dictionary queue에 key가 enqueue, dequeue하는 부분에 집중하시면 됩니다.
MoCo는 크게 두 가지 문제를 해결했습니다. 1)어떻게 대규모 동적 dictionary를 만들 것인지 2)encoder가 업데이트되고 있을 때(SGD training의 맥락에서)어떻게 동적 dictionary를 유지할 것인지. Contrastive SSL framework에서 큰 dictionary를 갖기 위해서, 이전 배치의 features는 queue로서 유지됩니다. dictionary는 현재 및 이전 배치로 구성되며 배치 크기에 의해 제한되지 않습니다. 업데이트된 encoder에서 나온 dictionary의 features는 features의 일관성을 향상시키기 위해 여러 배치를 커버하고, 이들을 느리게 업데이트되는 momentum encoder를 사용할 것을 제안했습니다(dictionary를 배치마다 바꿔버리면 feature 비일관성 문제가 생기는데, MoCo에서는 이를 느리게 업데이트 하면서 일관성을 향상시킨게 contribution이라고 합니다). 저자들은 Ablation study에서 momentum이 중요한것을 밝혔다고 합니다.
B. SimCLR
SimCLR에 대해서는 다음 리뷰에 자세히 설명되어 있습니다 : http://server.rcv.sejong.ac.kr:8080/2023/07/30/iclr-2020a-simple-framework-for-contrastive-learning-of-visual-representations/
SimCLR는 MoCo가 제안된 직후 소개된 논문입니다. SimCLR는 특정 복잡한 구조나 큰 메모리를 요구하지 않고 CL을 통한 visual representation을 이용하는 방법을 제안했는데, framework는 1. 입력 데이터 샘플에서 서로 다른 augmentation을 적용해 positive sample 생성 2. augmented된 데이터에서 representation vector를 추출하는 encoder 3. representation 을 contrastive loss함수가 있는 분류층에 투영시키는 multi-layer projection head로 구성됩니다.
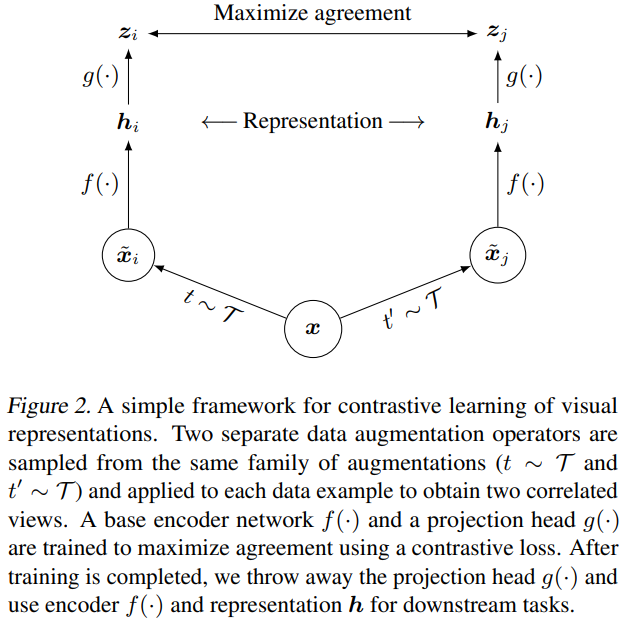
SimCLR에서의 representation은 동일한 데이터의 서로 다른 augmented version(positive pair)의 유사도를 contrastive loss를 이용해 latent space에서 증가시키며 학습됩니다. 유사도는 cosine 유사도를 이용합니다.
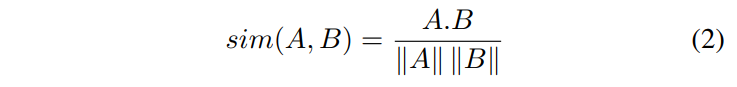
contrastive learning은 비교할 negative pair가 많을수록 학습에 유리한데, SimCLR은 많은 negative pair를 가져가기 위해 매우 큰 배치 사이즈를 사용합니다. contrastive learning은 Noise Contrastive Estimation (NCE)라는 loss를 사용합니다. 저자들은 논문에서 NT-Xent loss라고 부릅니다.

SimCLR의 학습 알고리즘은 다음과 같습니다.

C. BYOL
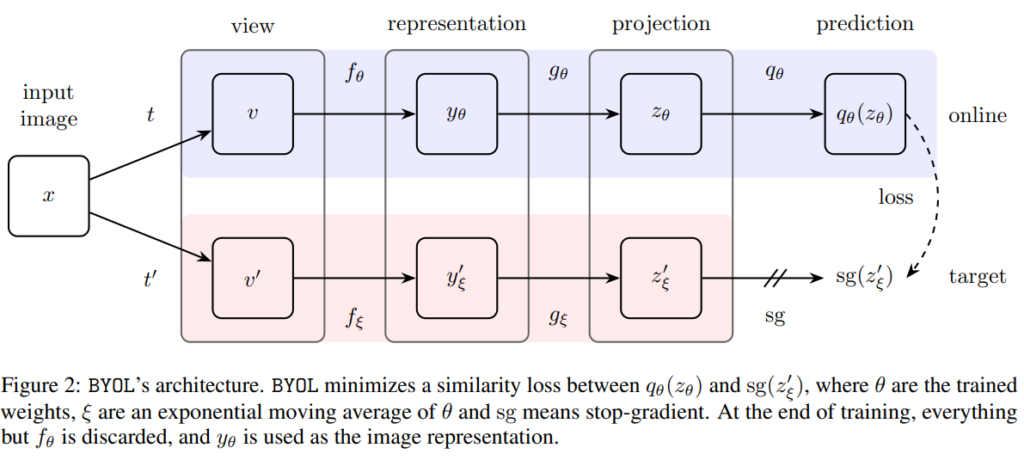
BYOL은 negative pair를 사용하지 않고 기존 Contrastive Learning방식들보다 우수한 성능을 달성했습니다. 양질의 representation을 배우기 위해 image를 2개 쓰는 방식 대신 2개의 network를 사용합니다.
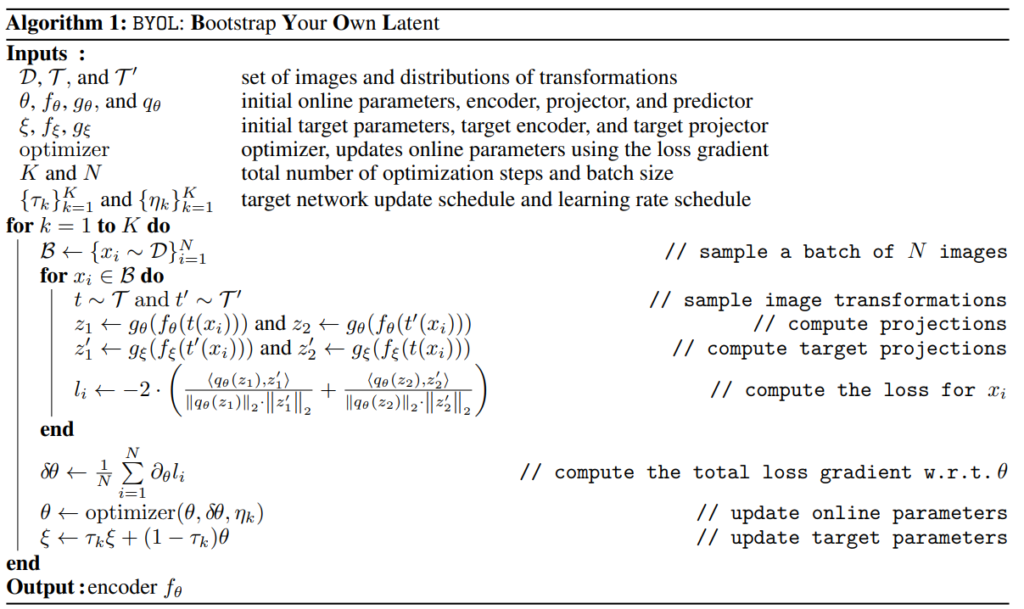
Bootstrap Your Own Latent (BYOL) 는 online network와 target network로 구성되며, 각 network는 encoder, projector, predictor로 구성됩니다. target network는 online network가 배울 regression target을 생성하는데, 간단히 말하자면 어떤 네트워크가 학습한 결과값을 가지고 다른 네트워크를 학습시키는것을 반복합니다. contrastie learning이라고 보긴 어렵죠. loss도 contrastive loss가 아닌 MSE를 사용합니다. loss는 online network를 학습시키는 데만 사용되며, target network는 exponential moving average라는 방법으로 weight가 결정됩니다.
D. SwAV
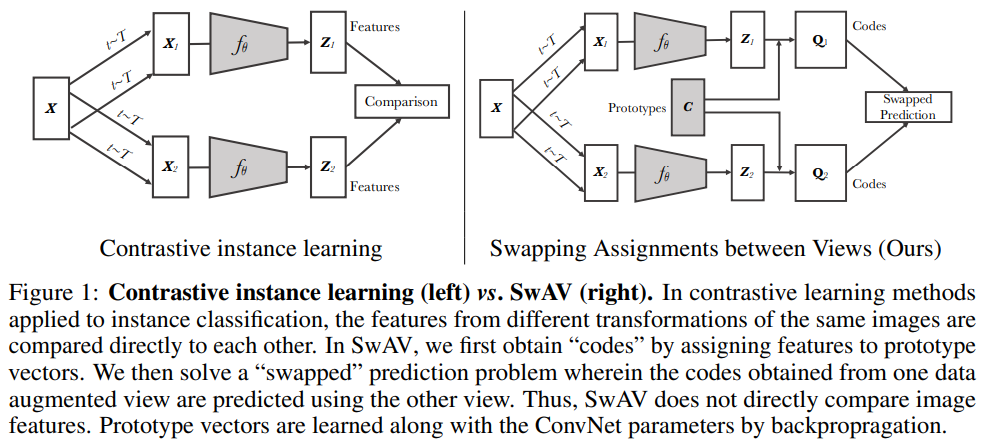
Swapping Assignments between Views (SwAV)는 pairwise 비교 없이 contrastive 방법을 이용하기 때문에 높은 computation을 요구하지 않습니다. 추출한 feature들의 직접적 비교 대신, 같은 이미지에서 파생된 서로 다른 augmented image에 cluster를 할당하여 서로의 cluster를 맞바꾸어 예측합니다. 동일한 이미지에서 나온 2개의 augmented view는 리뷰 상단 Fig2(c)에 나타낸 두개의 feature encoder에 들어가고, 이 특징들은 clusters 집합 안에 있는 nearest neighbours에 매핑됩니다. 이후 한 view의 representation으로부터 다른 view의 code를 예측합니다. 다음 (5)에 나타낸 swap prediction loss는 codes와 features로부터 계산됩니다.
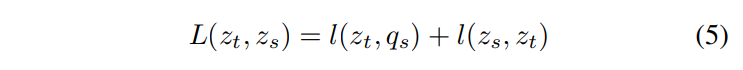
E. SimSiam
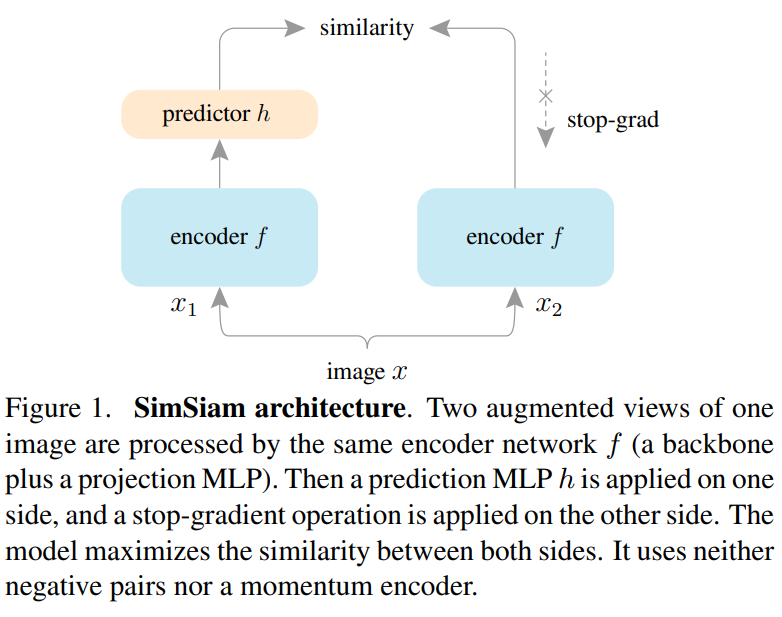
Simple Siamese (SimSiam) 은 contrastive learning에 siamese networks를 사용합니다. SimSiam 구조에서는 두 개의 input augmentation of same image의 유사도를 높이려고 합니다. 증강된 이미지 처리에는 동일한 encoder가 사용되는데, 이 두 encoder는 동일한 weights와 backbone을 사용합니다. encoder 하나의 뒷단에는 predictor가 붙는데, 이 predictor function은 encoder의 output을 변환하고 다른 인코더의 출력과 일치시킵니다. augmented images 간 유사도를 극대화시키는데는 Consine 및 cross-entropy similarity가 사용됩니다. stop gradient는 classification trivial solution인 collapsing solution을 막기 위해 도입되었다고 합니다.
Discussion
위에서 소개한 방법들은 classification, object detection 등에서 상당히 개선된 결과를 보여주었으며, 점점 개선된 버전(SimCLRv2 등)이 등장하고 있으므로 앞으로 더욱 발전할 것으로 보입니다. 맥락상 self-supervised contrastive learning이 등장한지 얼마 되지 않았지만, 데이터의 1% 혹은 10%만을 이용한 성능 비교에서는 supervised learning보다 더 나은 결과를 보여주고 있습니다. 따라서 이 방향에 대한 확장 연구의 동기는 충분할 것으로 보입니다. contrastive learning을 수행할 때 negative pair가 많이 필요해서 batch size가 너무 크거나 memory bank를 이용하는 것을 개선할 필요가 있다고 언급합니다.
Conclusion
제가 꼼꼼히 읽어본 논문은 SimCLR인데, 다른 방법들의 흐름을 훑어보고자 찾아봤던 논문입니다. 논문을 찾다보니 평소에 잘 보이지 않는 학회의 논문을 읽어봤는데, 확실히 팁티어 컨퍼런스에 개제된 논문들보다는 뭔가 글의 흐름이 매끄럽지 않다는 느낌이 확 들었습니다. 읽다 보면 ‘왜 흐름에 맞지도 않은 이런 문장이 갑자기 튀어나오는거지?’ 혹은 ‘대체 왜 문단 구성을 이렇게 해놓은거지?’ 라는 생각이 드는 부분들이 있었는데, 지금까지 읽었던 유명한 논문들에서는 받아본 적 없는 느낌이었습니다. 나중에 제가 글이나 논문을 작성할 때는 흐름이 매끄러운지 확인을 잘 해야겠다는 다짐을 하는 계기가 되었습니다. 확실히 수준 높은 학회에 개제된 논문들에서 (내용 외적으로도)배울 점이 많은 것 같습니다. 논문을 찾아볼 때 좋은 논문 위주로 찾아봐야겠다.. 라는 생각도 하게 되었습니다.
안녕하세요. 허재연 연구원님.
좋은 리뷰 감사합니다.
논문의 흐름이 매끄럽지 않다고 하셨음에도, 정리를 잘 해주셔서인지 큰 어려움 없이 잘 읽을 수 있었습니다.
간단한 (어쩌면 기초적인) 질문이 있는데요, dynamic dictionary lookup 문제라는게 어떤 것인지 설명해주실 수 있을까요?
감사합니다!
MoCo가 제안될 당시 다양한 contrastive learning 방법론들이 dictionary look-up이었습니다. 많은 key가 있는 dictionary에서 query로 들어온 데이터에 대해 contrastive learning을 진행한 것이죠. MoCo는 이 dictionary를 queue 형태로 구현했습니다. 학습이 진행됨에 따라 계속 enqueue와 dequeue를 반복하며 dictionary가 업데이트됩니다. 이 때, momentum을 적용해 dictionary가 너무 빨리 업데이트 되는 것을 방지해서 최대한 일관된 representation을 dictionary에 유지하도록 했습니다. 요약하자면, ‘계속 업데이트 되는 dictionary에 대한 검색’ 정도로 생각 할 수 있을 것 같습니다.
안녕하세요. 좋은 리뷰 감사합니다.
self-supervised learning에 대해서 점점 더 관심이 가서 일게 되었는데 덕분에 저도 흐름 파악을 잘 할 수 있게 되었습니다.
간단한 질문이 있는데요. 저는 negative pair를 사용하지 않은 BYOL가 좀 흥미로웠는데요. 제가 궁금한 점은
1. 재연 연구원님께서는 왜 BYOL를 contrastive learning이라고 보기 어려운지
2. 그럼에도 불구하고 지금 contrastive 방법론으로 서베이 논문에 실렸는데 왜 BYOL가 contrastive 방법론으로 들어가는지 가 궁금합니다.
감사합니다
Self-Supervised learning에서의 contrastive learning은 sample들 간 augmentation을 통해 positive/negative pairing을 하고, InfoNCE 등 contrastive loss를 활용하여 feature space에서 positive pair끼리는 가깝게, negative pair끼리는 멀도록 학습을 반복하는 representation learning 기법입니다. SimCLR나 MoCo를 보시면 이해하기 쉬울 것입니다. 하지만 BYOL은 애초에 파이프라인이 완전 다릅니다. 두 가지 data간 비교를 통해 representation learning을 진행하는것이 아니라, 네트워크 2개를 이용해서 학습합니다. loss도 contrastive loss가 아닌 MSE를 이용합니다. 오히려 약간 knowledge distillation이랑 비슷한 느낌이죠. 과거의 내가 미래 나의 스승이 된다. 라는 느낌입니다. 어떤 네트워크가 학습한 결과물을 다른 네트워크 훈련에 이용하는것을 반복합니다. contrastive learning이라고 보기는 어려울 것 같습니다. BYOL은 contrastive learning으로서 본 survey에 실렸다기보다는 SSL에서 유명한 representation learning 기법이기에 contrastive learning 방법들과 함께 소개된 느낌입니다. 사실 논문 표현을 보면 헷갈리게 작성되어 있긴 합니다. 저도 읽으면서 헷갈리는 부분 중 하나였습니다.
안녕하세요. 리뷰 잘 읽었습니다.
읽다보니 재미있어, 조금 상세한 설명을 요구하는 질문이 주를 이루는 것 같습니다.
1. SSL을 위한 Pretext task에서, Super-resolution과 audio-visual correlation 등은 Input sample에서 Feature representation을 학습하고자 함을 이해했는데, 그렇다면 해당 태스크에서 Feature representation을 다양한 태스크에서 어떤 식으로 활용하나요? 이 점이 항상 궁금했는데, 예를 들어 일반적인 Classification 외에 detection, segmentation 등에서도 Super-resolution과 같은 Pretext task가 힘을 발휘할 수 있는 지 궁금합니다. 혹은 (그렇지 않다면) Task-specific한 Pretext task를 따로 만들어야할 필요도 있나요?
1-1. 이 때, GAN이나 Diffusion 기반의 Super-resolution과 audio-visual correlation은 어떤 방법인지 궁금합니다. 말씀해주신대로라면 Generative pretext task는 pseudo-label을 생성해야하는데, super-resolution은 pseudo-label은 어떻게 정해야하나요?
2. Constrative Learning에서 Feature끼리 밀고 당기는 구조는 알고 있었는데, 그럼 CL은 Generative pretext task와 달리 Pseudo-label은 생성되지 않을 것 같은데 그렇다면 Constrative Loss를 통해 유사한 데이터가 충분히 근처에 있고, 서로 다른 데이터가 충분히 멀리 있어 유의미할 것 같아 학습이 충분히 이루어졌다는 것은 어떻게 판단할 수 있나요? 동일 Feature space에서 데이터 간의 거리에 대한 Threshold를 산정하나요?
3. 단순한 반전이나 색상, 밝기 변화등에 있어, Random augmentation으로 다른 이미지에 대해 Positive-Negative Pair를 구성하고, 학습하며 서로 끌고 밀어내는 과정에서 신경망이 일반성을 가지고 Robust하게 만들어 낸다고 했는데, 이 때 뒤에서 말하는 Adaptable representation은 어떤 의미인가요? 그리고 만약 학습에 있어 그런 단순한 색상, 밝기 변화등은 모델이 오히려 너무 쉬운 태스크를 학습하여 일반적인 표현력을 갖기엔 힘든 일종의 Trivial-task로 읽혀질 것 같은데, 그러한 문제를 지적한 논문들이나 재연님의 생각이 궁금합니다.
4. Constrative learning에 대해 동일 클래스에 속해야할 샘플들이 멀리 떨어지는 문제점을 말씀해주셨는데, 이 때 궁금한 점이 그럼 Pretaining objective(?)에 label, 제가 이해한 바에 따르면 이는 색상, 밝기 변경등을 한 이미지인데, 이 때 pseudo-label을 주는 것이 해결법이라면 이전에는 어떻게 했길래 문제점이 지적되었나요? 그런데 만약 classification 태스크라하면, 90′ 회전을 한 이미지도 당연히 원래의 label과 같게 부여하지 않나요? 이전에는 그러지 않았다면 어떻게 했는지, 어쩌면 당연히 psuedo label도 아닌 일반적인 label을 부여해도 될 것 같은데 왜 그러지 않았는지 궁금합니다.
5. 음.. 억까라고 느끼실 수도 있어 조금 조심스럽지만, 제가 원래 알고있었던 그리고 재연님 리뷰를 통해 읽었던 SimCLR나 SimSiam을 제외하고선 Survey 논문이여서 그런지 사실 저는 베이스 지식이 모자르고 해당 태스크를 직접 접하지 않고 매번 Follow-up하지 않아.. 다른 논문들이 어떤 차이점이 있고 왜 나온거지?하는 것도 이해하는데에 힘들었습니다. 물론 리뷰가 굉장히 좋았으나, 모르는 입장에서 읽었을 때 해당 논문에서 이전 논문을 비교하여 문제로 삼은 지점, 해결 방법 (핵심 Methods) 정도를 더 짚어주셨으면 좋을 것 같습니다. 물론, MoCo나 SwAV, SimSiam 같은 논문들도 앞으로 리뷰 써주신다면 지속적으로 Follow-up하도록 하겠습니다. 아무래도.. Survey 논문의 한계점도 맞는 것 같습니다..ㅎㅎ
좋은 리뷰 감사합니다.
질문이 길어 주중에 대면으로 답변 드렸습니다!
안녕하세요 ! 좋은 리뷰 감사합니다.
MoCo 설명해 주실 때 알고리즘 사진 첨부해 주신 걸 보면 loss가 CrossEntropyloss라고 적혀있던데, 제가 알기로는 MoCo loss는 InfoNCE loss를 사용하는 것으로 알고 있습니다. MoCo의 loss에 대해 보충 설명해주실 수 있으실까요 ?
또, BYOL에서 target network는 exponential moving average로 weight가 결정된다고 하셨는데 이 EMA 알고리즘은 어떻게 동작하는지 궁금합니다.
감사합니다.
MoCo는 Contrastive learning 기법으로서 contrastive loss(InfoNCE)를 사용하는것이 맞습니다. 그림을 다시 확인하시면 contrastive loss라고 써져 있는것을 확인하실 수 있는데, 아마 이를 cross-entropy로 잘못 보신게 아닌가 합니다.
BYOL에서 target network의 weight들은 online network의 weight들의 exponential moving average값을 사용합니다. exponential moving average 방법은 consine annealing을 사용하여 학습이 진행할수록 점점 1에 가까운 값으로 키우는 방법인데, BYOL 알고리즘 사진을 참고하시면 맨 마지막 쪽 update target parameters 부분 식에서 타우 값이 0.996->1로 변화한다고 이해하시면 됩니다.
감사합니다.